Standard SAEs Might Be Incoherent: A Choosing Problem & A “Concise” Solution
post by Kola Ayonrinde (kola-ayonrinde) · 2024-10-30T22:50:45.642Z · LW · GW · 0 commentsContents
TL;DR Structure 1. The Setup 2. The Problem AutoInterp is not Robust to Choice of Explanatory Mediator No Principled Way to Choose a Canonical Representative The Upshot Incoherency in the Wild with Gemma Scope 3. A Potential Solution - MDL-SAEs 4. Conclusion 5. Epilogue[14] Comments on MechInterp research Practical Relevance for SAEs None No comments
This work was produced as part of the ML Alignment & Theory Scholars Program - Summer 24 Cohort.
TL;DR
The current approach to explaining model internals is to (1) disentangle the language model representations into feature activations using a Sparse Autoencoder (SAE) and then (2) explain the corresponding feature activations using an AutoInterp process. Surprisingly, when formulating this two stage problem, we find that the problem is not well defined for standard SAEs: an SAE's feature dictionary can provide multiple different explanations for a given set of neural activations, despite both explanations having equivalent sparsity (L0) and reconstruction (MSE) loss. We denote this non-uniqueness, the incoherence property of SAE. We illustrate this incoherence property in practise with an example from Gemma Scope SAEs. We then suggest a possible well-defined version of the problem using the Minimum Description Length SAE (MDL-SAE) approach, introduced here [LW · GW].
Structure
- We begin in Section 1 by outlining how SAE-style feature-based explanation is done.
- In Section 2, we identify the incoherence problem in the current two-step approach to interpreting neural activations and show that there is no simple solution to this problem within the standard SAE setting.
- In Section 3, we suggest a possible solution in terms of MDL-SAEs.
- We close with a discussion and some meta-reflections on MechInterp research in sections 4 and 5.
1. The Setup
In interpretability, we often have some neural activations that we would like for humans to understand in terms of natural language statements[1].
Unfortunately, the neurons themselves are not very amenable to interpretation due to superposition and the phenomena of polysemantic neurons. It is now customary to use sparse autoencoders (SAEs) in order to aid in the interpretation process by working in some more disentangled feature space rather than directly in the neuron space. We will denote this the Feature Approach to explaining neural activations - explaining neural activations via the feature space.
We can contrast the Feature Approach with previous work like Bills et al. (2023) and Olah et al. (2020) who focused on interpreting neurons directly. In the Feature Approach to explanations however, we explain neuron activations by explaining the features which correspond to those neuron activations. Lee Sharkey [AF · GW] refers to these two steps as the Mathematical and Semantic [Explanation] phases, respectively.
The strategy is as follows:
- Mathematical Explanation Phase: Use the SAE to uncover (sparse) feature activations from the input neuron activations. These feature activations should be such that when paired with the feature dictionary (i.e. the decoder directions), they produce a close approximation to the neural activations we're trying to explain[2].
- Semantic Explanation Phase: Label the features in semantic terms using a (possibly human-assisted) AutoInterp process. AutoInterp is a process which, using language models, feature activations and optionally steering interventions, produces a natural language explanation of each feature direction in the feature dictionary. AutoInterp maps "feature directions" (vectors in ) into "concepts" (strings in English with a semantic meaning). If the feature activations are sufficiently monosemantic and disentangled then they admit a nice conversion to natural language by some AutoInterp procedure. By Independent Additivity [LW · GW] assumption[3] which is required for SAE-based interpretability, we can then naturally understand a feature activations as a combination of the concepts that each feature represents[4].
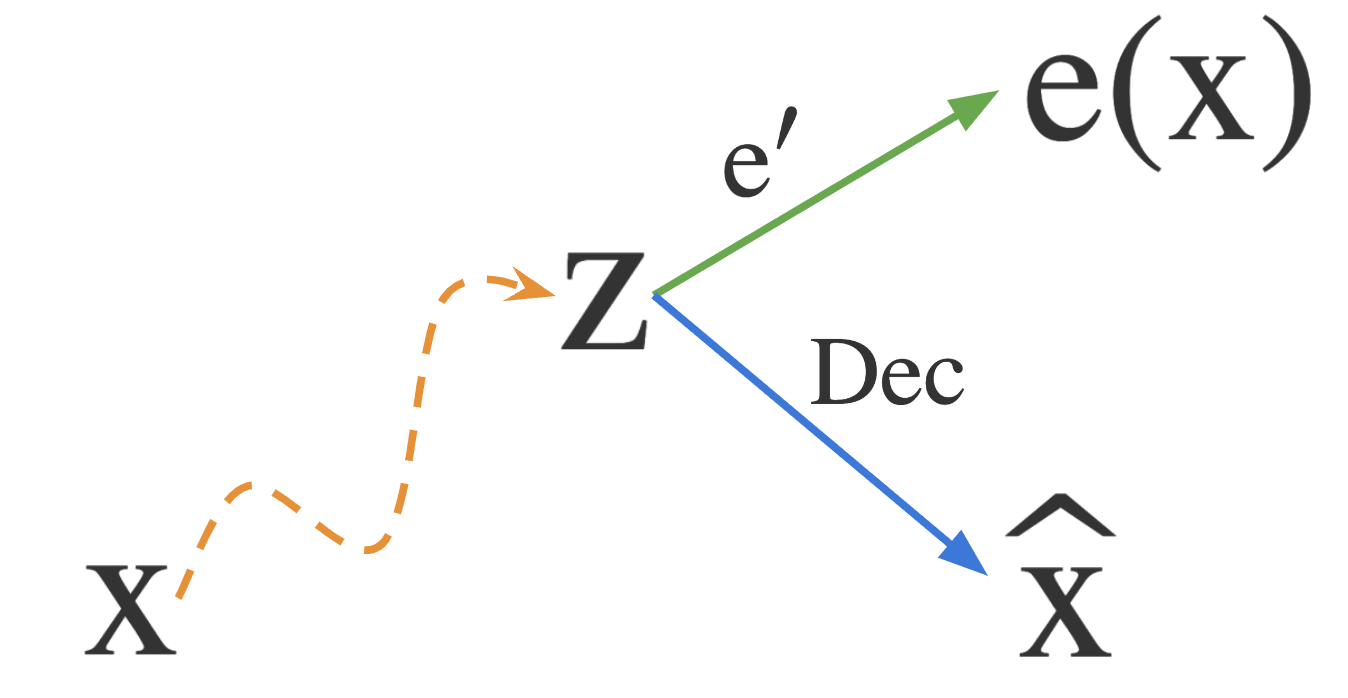
In what follows, we are discussing interpreting neural activations. We assume that we have a trained feature dictionary and that we have some map to semantic explanations which we got from doing AutoInterp on this feature dictionary. We are interested in the process of explaining neural activations using these tools. This is, for example, the problem that we're faced with at inference time when we're trying to understand the activations of our model with our pretrained SAE. And at train time, we're hoping to train our SAE such that it will be good at the above task.
When we're doing our interpreting, we use the feature activations to get our semantic explanation. However, we don't care for the feature activations in themselves per se; the feature activations are simply intermediate variables which are implementation details of our explanation function. In this way we can think of the feature activations as a vanishing mediator, as in Frederick Jameson (1973)[5] , Slavoj Žižek (1991). In what follows, we will call the feature activations explanatory mediators - they are vanishing mediators used in the process of explanation.
We can write this out more explicitly in the following form:
for , ,
where is the set of natural language explanations (e.g. English strings).
Here, explain is the function which takes in the neural activations and gives a natural language explanation of those activations. explain_features is the inner function which takes feature activations and gives a natural language explanation of those feature activations. is the decoder function which maps feature activations to neural activations.
We shorten this notationally to .
2. The Problem
But wait, as we write this more explicitly, we realise there's a potential problem in this formulation: what happens if the feature activations, z, which correspond to our neural activations, x, are not unique?
In other words, is there a single z here? Might there be many collections of feature activations which are all explanatory mediators for the neural activations x?
As it turns out, yes. In our current formulation, there will be many options for z for two reasons:
- We're not necessarily looking for a z (feature activations) which exactly has x = Dec(z); we have some tolerance for acceptable inaccuracy. So there will likely be a subset of an -ball around any solution z which also works to explain x.
- The feature space is (the set of elements in with at most k non-zero elements) where forms an overcomplete basis for the neuron space . Hence there can be many different options for z that all map to the same x. Even for sparse subsets of the decoding map for is generally not injective.
We can describe the situation by noting that the Pre-Image of x under the decoder Dec (the set of all elements in which maps to x) does not form a singleton set but rather a class of feature activations {z}.
If we are seeking a unique z for a given x, we might try to eliminate Reason 1 above by restricting to the subset of z which have minimal distance from x when decoded (i.e. those z which map to some maximally close to x within the sparsity constraint). Now any elements within this {z} subset naturally form an equivalence class under the relation of being mapped to the same x.
Now we can reframe our explain function as:
where is the equivalence class of feature activations which all map maximally close to x for some k-sparsity constraint on z. We call the set of minimal explanatory mediators for x.
For this explain function to be well-defined, we would like one of two properties to hold:
- Either explain_features can take any element of and give (at least approximately) the same answer (i.e., explain_features acts on the quotient space induced by the equivalence class rather than on the directly). In other words, AutoInterp should be robust to the choice of explanatory mediator.
- Or we should have some way of ensuring that is a singleton set so that we can simply pass this element to the explain_features function. This can be seen as an equivalent problem to restricting by choosing a natural canonical representative of . Then the output of explain_features on is the output of explain_features on that representative. In other words, there should be a principled way to choose a canonical representative.
We will now show that for standard SAEs, neither of these properties hold. Firstly, we show that if the explain_features function (i.e. AutoInterp) is not perfect, then we can find elements of and which map to very different semantic explanations. Secondly, we show that there is no principled way to choose a representative of for standard autoencoders.
Consider the following example of a set of feature directions: for
Note that the set of feature directions is overcomplete and hence that is a valid feature direction in the feature dictionary[6].
Now consider two sets of feature activations: and .
It is immediate to see that both and map to the same x under the decoder Dec. That is to say that they are both valid explanatory mediators for x. Similarly note that they have the same sparsity level (in this case ). So we have two elements of which are both valid, minimal explanatory mediators for x. We do not have uniqueness of minimal explanatory mediators.
AutoInterp is not Robust to Choice of Explanatory Mediator
Now, any small error in the explain_features function will result in wildly different explanations for z and z', for sufficiently large , since z and z' will be arbitrarily far apart. In other words, an AutoInterp function which is anything less than perfect in mapping to natural language can result in arbitrarily different explanations for the same neural activations x. We would instead like to have some way of ensuring that the explanations we get out of our explain function are robust to the choice of explanatory mediator z.
Obtaining this invariance property seems difficult with current AutoInterp methods.
No Principled Way to Choose a Canonical Representative
Okay, suppose we would like to avoid this problem by choosing a representative of the equivalence class . How might we do this? We already have that the z and z' admit the same description accuracy (reconstruction error). And we also note that they have the same sparsity level. Since SAEs are supposed to choose between feature activations based on these two criteria, we have a tie.
We could begrudgingly add an additional criterion for SAEs to optimise, for example we might choose the representative with the lowest L1 norm. But why L1? Why not L2? We don't seem to have a principled way of choosing which norm to use here. And we're now introducing other criteria rather than just accuracy and sparsity (L0) [7], the standard SAE criteria. Standard SAEs are widely understood to only be using L0 and MSE to choose the explanatory mediator for a given x. However it now seems that we would need to add in an extra tie-breaker in order for standard SAEs to work as described.
One other way to choose some feature activations z would be to choose "the z that comes out of our Encoder". But with a fixed decoding dictionary, we could plausibly have many different encoders (imagine for example, training an encoder against a fixed decoder with different random seeds). We can reframe our "choosing problem" here as stating that we don't seem to have a way to choose between different s which come from different encoders (with the same feature dictionary and AutoInterp strategy).
When we have some feature dictionary and some set of activations, however we acquired the activations, we should be able to perform the same analysis. Again, we don't seem to have a principled way of choosing which encoder to use. We shouldn't privilege the z that comes out of our encoder just because it's the encoder that we happen to have - this would be a somewhat arbitrary choice.
The encoder can be seen simply as "some convenient (possibly black box) way to generate the feature activations that correspond to our neural activations under some feature dictionary". In the terms of the Communication Protocol framing for Explanations [LW · GW], the encoder is merely a way to generate the feature activations; the encoder is not really a fundamental part of the communication protocol.
We might speculatively suggest that researchers have been implicitly privileging the encoder generated feature activations as the "correct" explanatory mediators.
The Upshot
It seems that x admits two valid explanatory mediators - z and z' - which both lead to arbitrarily different semantic explanations. And we have no principled way of choosing between them. In other words, we might say that the explain function is not well-defined for standard SAEs[8].
In some sense, the sparsity function is just not a powerful enough discriminator because it can only discriminate between integer sparsity values. It forms a partial ordering over the feature activations but not a total ordering. We would like a total ordering so that we can specify a natural canonical representative of the equivalence class .
Incoherency in the Wild with Gemma Scope
We showed above that there was a potential inconsistency problem theoretically but does this actually appear in real SAE-AutoInterp explanatory systems? Consider the following example from the Gemma Scope SAEs and corresponding Neuronpedia AutoInterp explanations:
We examine Gemma-Scope's 16K SAE for Gemma 2 layer 16 with canonical hyperparameters. Here we find that with feature indices 2861, 12998, 16146 as respectively, we approximately have the relationship for . This leads to z and z' which are both (approximately) minimal explanatory mediators for the same x as described above[9].
Neuronpedia's AutoInterp explanations for are:
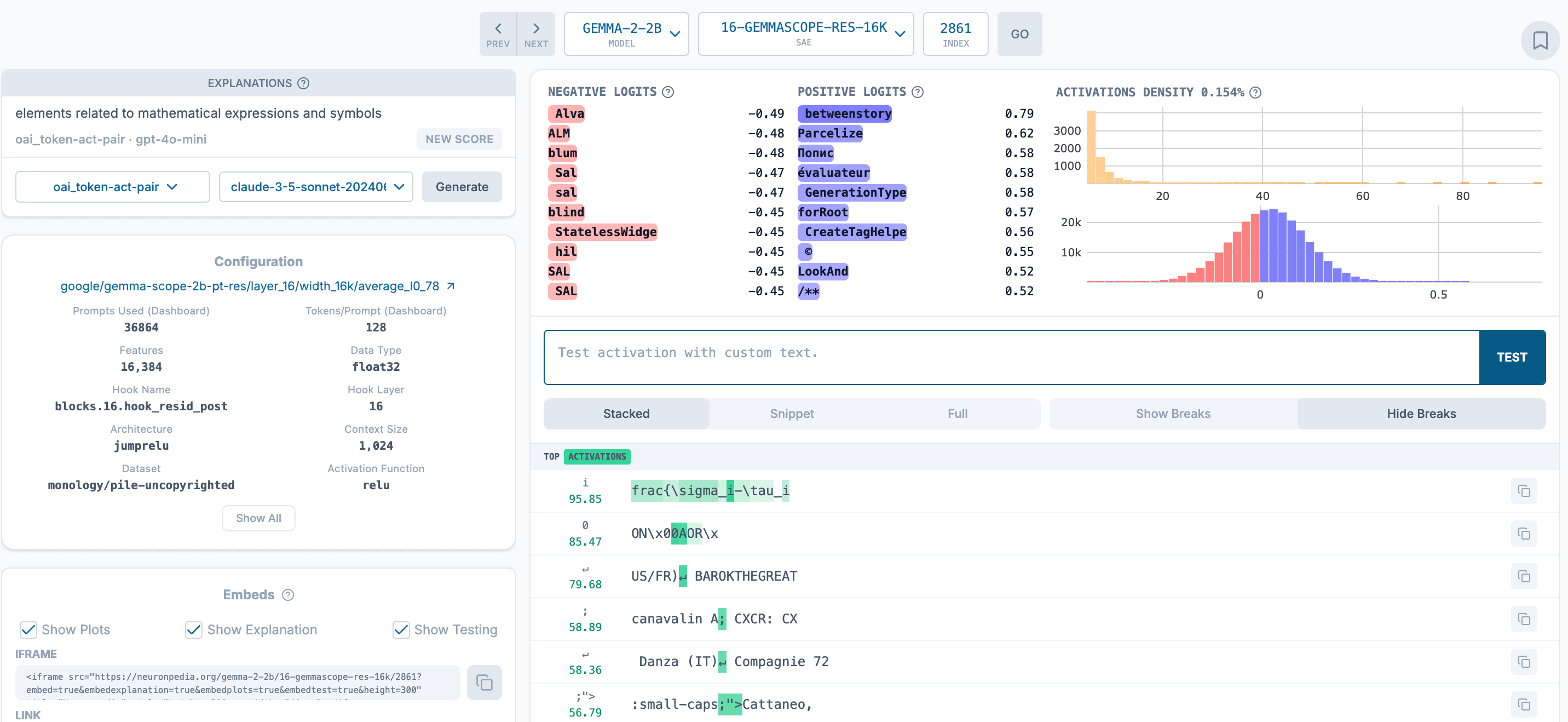

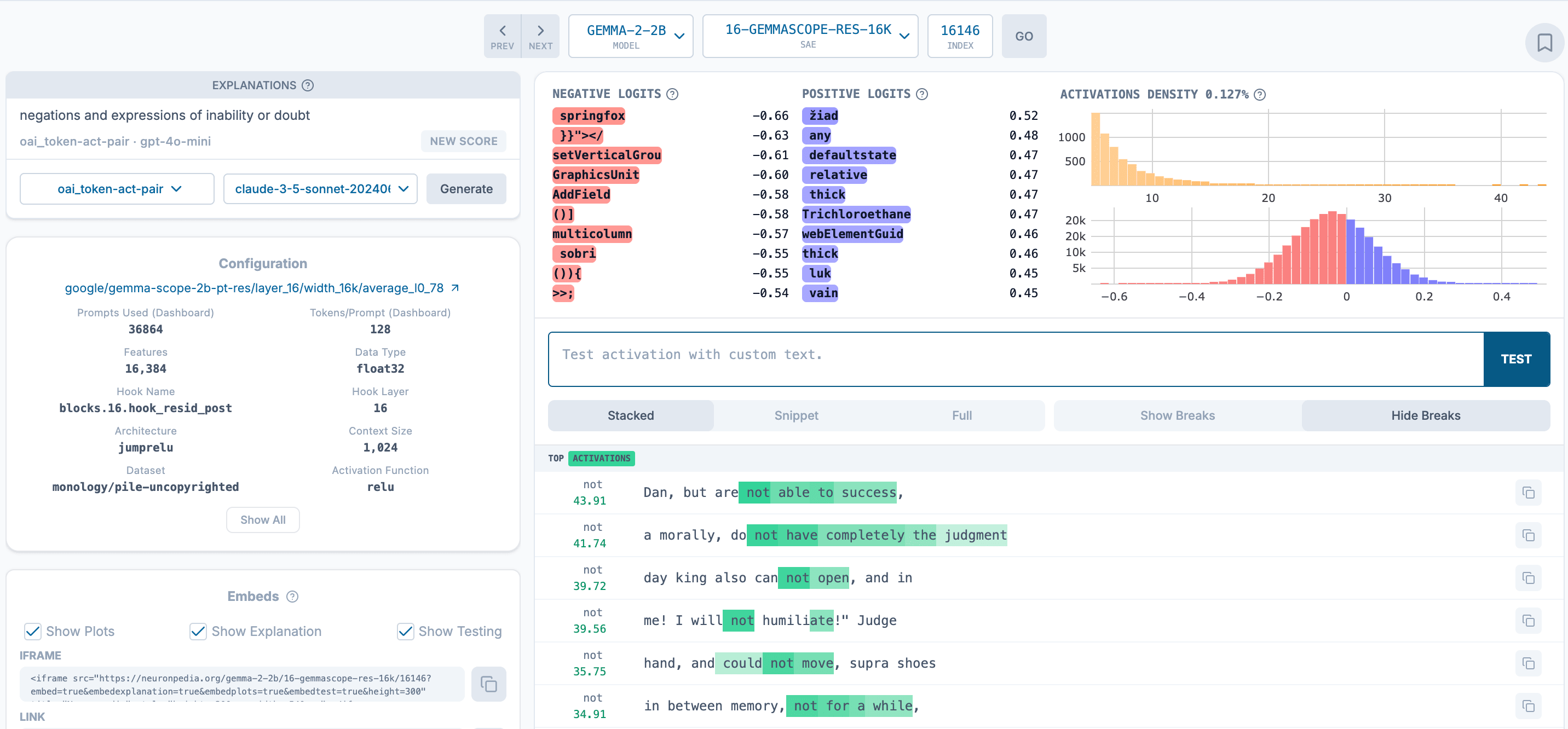
The semantic explanation via z ( is purely in terms of symbols, whereas the semantic explanation via z' ( is in terms of expressing inability in language. Given this difference in semantic explanations, we might say that the AutoInterp explanations are inconsistent with respect to the choice of explanatory mediator[10]. In this sense, the abstract argument above seems to play out in SAEs that practitioners may use in real life.
3. A Potential Solution - MDL-SAEs
(Minimum Description Length SAEs) MDL-SAEs (defined in Interpretability as Compression [LW · GW]) say that instead of optimising for the (accuracy, sparsity)-Pareto frontier, we should be optimising for the (accuracy, description length)-Pareto frontier. That is, we swap out sparsity for description length (or equivalently conciseness) in the Information Theoretic sense. Some theoretical motivation is given here [LW · GW] for why description length could be a principled criteria to choose[11].
This seems to give us a more principled way to choose z and z'. Suppose the distribution of the activation magnitudes for , , are given as follows for :
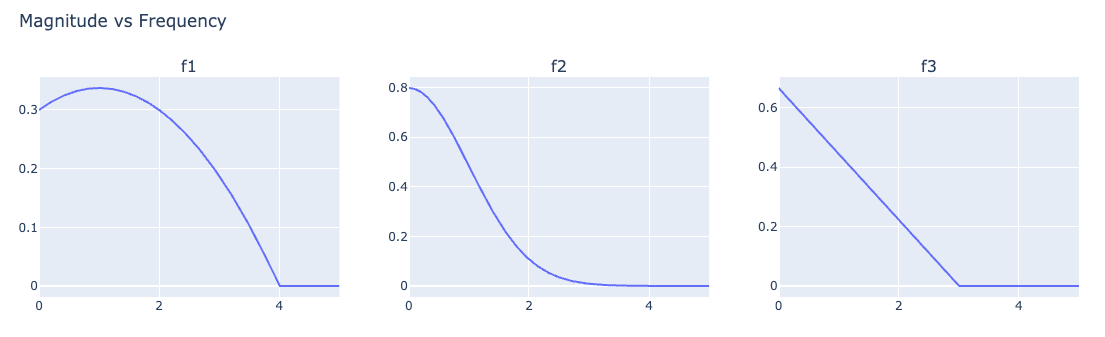
We now have good reason to choose z over z'. z is genuinely a more concise explanation, in that 1 is a less surprising (i.e. more likely) activation magnitude for than is. Great! Under the MDL-SAE instead of (sparse) SAE formulation, we have a principled way to choose between different explanatory mediators.
We also note that we have exactly two criteria (description length and reconstruction accuracy) in order to obtain a unique solution, where using standard SAEs and adding an additional criteria would give three criteria for a unique solution.
We might see this as reason to switch from thinking in terms of sparsity to thinking in terms of description length for SAEs[12]. Working in terms of sparsity may not admit a unique explanation for a given x, neuron activations, via the Feature Approach[13], but the description length formulation generally provides uniqueness.
4. Conclusion
We showed that for any non-optimal AutoInterp process, the explain function implicitly defined by standard SAEs is not well defined and can give unboundedly different explanations for the same neuron activations. If we would like to explain neural activations with the Feature Approach, i.e. via using feature activations as an explanatory mediator, this leads to the incoherence problem of non-unique explanations. MDL-SAEs do not in general suffer from the same incoherence problem and hence may be a natural formulation to use rather than standard SAEs.
Even with the MDL-SAE formulation, we note that this does not mean that we will always find the optimal explanation; there is still the task of learning good representations (learning the decoder), mapping effectively to those representations (learning the encoder and specifying the sparsifying activation function) and also the Relational Composition Problem from Wattenberg et al. to consider. These considerations are all open problems for future work.
5. Epilogue[14]
This argument only occurred to me recently in the middle of a different project (paper forthcoming) which, on the surface, had nothing to do with MDL-SAEs. I was incredibly surprised when MDL-SAES, the suggestion we'd put forward to solve another problem with SAEs (feature splitting), and which we later realised also provided a way to choose SAE widths, also seemed to solve this third problem (choosing minimal explanatory mediators) too!
Comments on MechInterp research
Epistemic status: More speculative
Are there any meta-lessons about MechInterp research here?
Firstly, it's promising when a solution designed for one problem happens to also solve other problems too. If the object-level product of MechInterp research is explanations of neural networks, then one of the goals of MechInterp as a scientific field would be developing a methods for explaining which explanations are better ones. In other words, one goal of the MechInterp field is to provide explanations (i.e., doing science) on how we create effective explanations (the object-level task). In the Philosophy of Science, one desirable quality is Consilience: the principle that evidence from different sources can converge on the same approaches. In this spirit, it's encouraging that the MDL-SAE approach appears to resolve multiple challenges associated with SAEs at once.
Secondly, we should be careful in MechInterp that our quantities and methods are well defined. It hadn't really occurred to me that SAE explanations weren't well defined, despite using them almost every day, and I imagine it likely hadn't occurred to many others too. It would probably be interesting and helpful for us to more clearly write out what MechInterp is aiming for and what the type signatures of the objects involved are. I have an upcoming project to more clearly write out some basis for a "Philosophy of Interpretability"; please reach out if you'd be interested in collaborating on this - especially if you have any background in Philosophy of Science, Philosophy of Mind, Category Theory or Functional Analysis.
Thirdly, although I presented MDL-SAEs as a solution to this problem, it's not clear that this is the only solution. MechInterp seems to be somewhat pre-paradigmatic at the moment and I would be wary of the community choosing individual methods as gospel at this stage yet. I do think we should have slightly higher credence in MDL-SAEs being sensible but I'd very much welcome critique of this approach. There may be some datum that is awkward for our story here and I'd love to know about it so we can further refine (or if necessary completely switch) our story.
Practical Relevance for SAEs
Epistemic status: Moderately confident
What does this mean for SAE users?
Honestly, probably nothing dramatic. But here are two takeaways:
- If you were thinking in terms of sparsity, maybe pivot to thinking in terms of conciseness (description length). At most times, sparsity and conciseness agree and are analogous. We give examples of where they come apart here [LW · GW] and why that's important.
- If you're building on top of SAEs, you'd probably be okay to think of the feature activations that you have as being the "correct" ones, even if they currently aren't guaranteed to be. Hopefully, your techniques should just generalise (in fact, even more hopefully, your techniques might magically get better as the underlying SAEs improve!). In practise, we might hope that the difference in resulting explanations between the feature activations that your SAE is likely to find and the true explanatory mediators given your feature dictionary is fairly small.
This post mostly focuses on "Is the role of SAEs as explanatory aids well defined?" rather than practical methodological concerns. I'd be excited about future work which explores SAE methods using these ideas.
Thanks to Michael Pearce, Evžen Wybitul and Joseph Miller for reading drafts of this post. Thanks to Jacob Drori and Lee Sharkey for useful conversations.
Thanks to the Google DeepMind Interpretability team for open-sourcing the Gemma Scope suite of SAEs and thanks to Neuronpedia for being the online home for visual model internals analysis.
- ^
Here we're using "natural language" as something of a placeholder for any human-understandable form of communication. This argument should apply equally to drawings or pictographs or any other form of human communication.
- ^
See the MDL-SAEs post [LW · GW] for a more detailed explanation of this process.
- ^
- ^
In reality, this process is theoretically unable to fully explain neuron activations as it doesn't account for the relations between features. This is known as the Relational Composition Problem in Wattenberg et al.. Future work should focus on how to understand the relations between features (as in Wattenberg et al.'s Call To Action) but we present how current methods work here.
- ^
RIP to Jameson (1934-2024) who died last month (at the time of writing); one of the truly great literary critics and philosophers.
- ^
In fact, since the feature dictionary vectors are unit norm, will need to be normalised. But we can set appropriately to account for the normalisation.
- ^
In practise people often optimise with the norm (e.g. for p=1) but this is a convenience since the norm is not differentiable. The norm is often used as a proxy for the norm in this case, rather than as a genuine objective.
- ^
Another way to put this is as follows. Suppose we have a standard SAE and I have an x and ask you what the best z would be for that x. This question is the question that we might take the Feature Approach with SAEs as trying to answer. However it is not a question you can answer; there is not generally a single answer.
We can think of this analogously to if I asked you the question "what is the integer that is larger than 5?". The question wouldn't be well-posed.
In fact it's somewhat worse than this because the purpose of finding the corresponding z, the explanatory (vanishing) mediator, is to use the z in order to generate a semantic explanation. So it's more like I told you to come to my house and I tell you that I live on Church Street at the house who's number is the integer greater than 5 - which house do you go to?
We'd really like (and the MDL-SAE approach seems to provide) a way to change the question into something which is well-posed and has a single answer.
We might think that the current approaches to relying on our encoder are something like saying "okay so this problem isn't actually well posed but we just have this unwritten convention that we roll a die ahead of time and agree that we go to the house at number 5 + {die_roll}". In a sense this could be reasonable as long as we all agree but it's worth explicitly saying that this is what we're doing when we privilege the encoder that we have which could have plausibly been different, even for the same feature dictionary (decoder).
Privileging low L1 norm solutions is similar to taking the convention that we always go to the house which is at number 5 + 1. Again this is plausibly reasonable but we should explicitly say if that's an implicit assumption of how SAEs are being set up.
- ^
This example was found by a simple, unoptimised search on a consumer laptop for a couple of minutes rather than an extensive search. It is likely that there are many even more salient examples of this incoherence in the wild. We would also expect this incoherence problem to be worse for larger SAEs than the small size we show here and much worse for feature decompositions with k=32 or a typical k value rather than the small k=2 case we show.
- ^
Note that this is not at all intended to be a criticism of the Gemma Scope SAEs in particular, we suggest that with any non-optimal SAEs we would see the same phenomena.
- ^
Briefly, we might frame the problem of SAEs as rate-distortion style problem of producing an accurate yet concise representation of our neural activations, supposing that we were trying to communicate the neural activations to another observer.
We then note that description length (or conciseness) corresponds to "simplicity" as the value to minimise and that this differs from mere sparsity as we also have to consider specifying which features are active as well as just what the values of the active features are.
- ^
This acts as an additional reason that we might want to consider using the MDL formulation. But there are ways around this. For example one move to stick with the standard sparsity version of MDL would be to have a reason for using the L1 norm as a tie-breaker. One such reason might be as follows: we want to think of features of linear but they're actually not generally linear - at best they're locally linear. We might say that what's going on here is that linearity is a reasonable approximation to the true feature activations function in some neighbourhood around the origin. In this telling, we have a good reason to use the L1 norm as a tie-breaker - it's choosing solutions that are closer to being linear. Readers may decide if this alternative story is compelling. It does however have the downside that in order to specify an SAE you need 3 properties (accuracy, sparsity, l1) rather than just 2 (accuracy, description length).
- ^
Note that if these explanations are not unique, it's hard to understand why we should trust them - if depending on the setup, the same neuron activations can admit two totally different explanations under the same feature dictionary, we should doubt the relevance of either explanation!
- ^
Cue jarring switch from first person plural to first person singular.
0 comments
Comments sorted by top scores.