Interpretability as Compression: Reconsidering SAE Explanations of Neural Activations with MDL-SAEs
post by Kola Ayonrinde (kola-ayonrinde), Michael Pearce (michael-pearce), Lee Sharkey (Lee_Sharkey) · 2024-08-23T18:52:31.019Z · LW · GW · 8 commentsContents
Abstract 1. Intro 2. Background on SAEs 3. SAEs are Communicable Explanations 4. Independent Additivity of Feature Explanations Connection to Description Length 5. SAEs should be sparse, but not too sparse 6. Experiment: Finding the MDL solution for SAEs MNIST Case Study 7. Divergence between the Sparsity and MDL Criteria Limits to Feature Splitting More efficient coding schemes for hierarchical features 8. Related Work 9. Conclusion None 8 comments
This work was produced as part of the ML Alignment & Theory Scholars Program - Summer 24 Cohort, under mentorship from Lee Sharkey and Jan Kulveit.
Note: An updated paper version of this post can be found here.
Abstract
Sparse Autoencoders (SAEs) have emerged as a useful tool for interpreting the internal representations of neural networks. However, naively optimising SAEs on the for reconstruction loss and sparsity results in a preference for SAEs which are extremely wide and sparse.
To resolve this issue, we present an information-theoretic framework for interpreting SAEs as lossy compression algorithms for communicating explanations of neural activations. We appeal to the Minimal Description Length (MDL) principle to motivate explanations of activations which are both accurate and concise. We further argue that interpretable SAEs require an additional property, “independent additivity”: features should be able to be understood separately. We demonstrate an example of applying MDL by training SAEs on MNIST handwritten digits and find that SAE features representing significant line segments are optimal, as opposed to SAEs with features for memorised digits from the dataset or small digit fragments. We argue that MDL may avoid potential pitfalls with naively maximising sparsity such as undesirable feature splitting and suggests new hierarchical SAE architectures which provide more concise explanations.
1. Intro
Sparse Autoencoders [? · GW] (SAEs) provide a way to disentangle the internal activations of a neural network into a human-understandable representation of the features. They have recently become popular for use in Mechanistic Interpretability in order to interpret the activations of foundation models, typically language models (Sharkey et al 2022 [AF · GW]; Cunningham et al., 2023; Bricken et al. 2023). It has been speculated that the features that SAEs find may closely map onto the constituent features that the model is using.
Human interpretability, however, is difficult to optimise for. Evaluating the quality of SAEs often requires potentially unreliable auto-interpretability methods since human interpretability ratings cannot be efficiently queried. And since neither naive human nor LLM-as-judge interpretability methods are differentiable at training time, researchers often use the or "sparsity" as a proxy for interpretability. We provide an alternative and more principled proxy for human interpretability.
In this post, we discuss an information theoretic view of the goals of using SAEs. This view suggests that sparsity may appear as a special case of a larger objective: minimising description length. This operationalises Occam's razor for selecting explanations - the idea that more concise explanations are better.
We start by framing SAEs as an explanatory and communicative tool. We discuss the importance of linear additivity and partial explanations for human-interpretability and the constraints this imposes on SAEs. We find that sparsity (i.e. minimizing ) is a key component of minimizing description length but in cases where sparsity and description length diverge, minimizing description length directly gives more intuitive results. We demonstrate our approach empirically by finding the Minimal Description Length solution for SAEs trained on the MNIST dataset.
2. Background on SAEs
Sparse autoencoders (SAEs) (Le et al 2011) were developed to learn an over-complete basis, or dictionary, of sparsely activating features.
The typical objective for an SAE is minimising the reconstruction error while activating a small number of dictionary features. Because the number of non-zero latent features
() is not easily differentiable, SAEs typically use auxiliary loss functions such as an penalty to encourage sparse latent activations[1].
is often treated as a proxy for interpretability, with lower representing a more interpretable model. It's acknowledged in the SAE literature that this proxy isn't the actual thing we're interested in. To get around this problem, the main way to evaluate the quality of the explanations is through manual Human Interpretability Rating Studies (HumanInterp) (Bricken et al. 2023) and AutoInterp (Bills et al.).
3. SAEs are Communicable Explanations
The goal of Mechanistic Interpretability is to provide explanations of the internals of neural networks. SAEs, in particular, aim to provide explanations of neural activations in terms of "features"[2]. We often desire for these explanations to be human-understandable (though for some purposes machine-understandable explanations are also useful).
We define explanations as follows:
Definition 1: An explanation of some phenomena is a statement for which knowing gives some information about [3].
Definition 2: The Description Length (DL) of some explanation e is given as , for some metric . The metric we'll consider is the number of bits needed to send the explanation through a communication channel.
SAEs are feature explanations. An SAE encoding of features and Decoder network together provide an explanation of neural activations x. We would like the features to have meaning as both the causal result of some previous events (i.e. the feature should help us understand the model input and/or previous model computation) and as the cause of later events (i.e. the feature should be causally relevant to later model computation and/or the model output).
Given the above we can reformulate the SAE as solving a communication problem. Suppose that we would like to transmit the neural activations x to a friend with some tolerance ε, either in terms of the reconstruction error or change in the downstream cross-entropy loss. Using the SAE as an encoding mechanism, we can approximate the representation of the activations in two parts:
- First, we send them the SAE encodings of the activations
- Second, we send them a decoder network that recompiles these activations back to (some close approximation of) the neural activations,
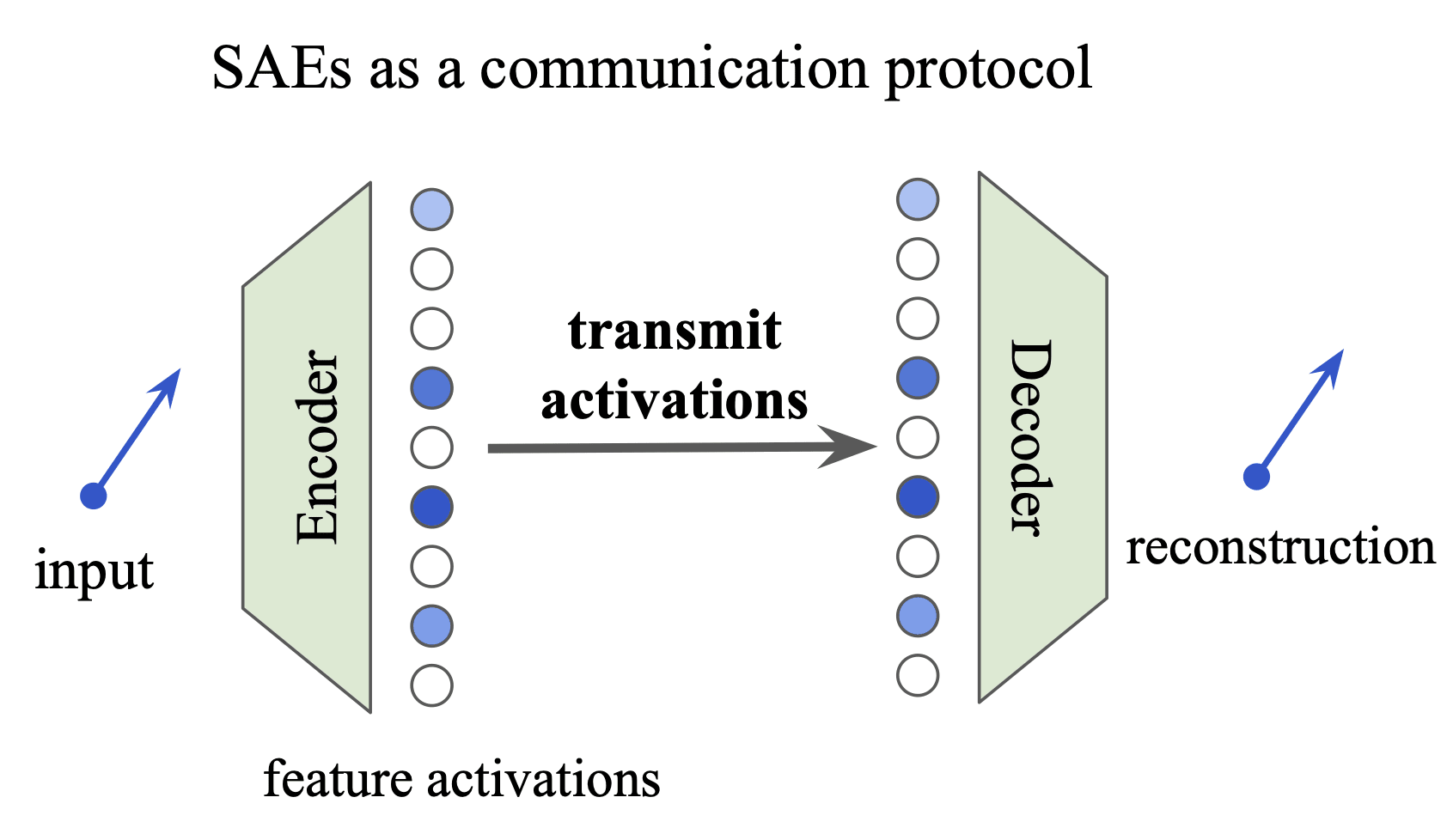
Note that this formulation is known as a two-part code (Grünwald, 2007) and closely tracks how we might consider communicating the binaries for a computer program (or a piece of data):
- We must first share the source code e.g. Python code (or the data e.g. mp3 file)
- Then we must share the compiler to translate the source code into the executable representation. In this case, we might naturally say that the description length of some program is given by DL(program) = |source_code| + |compiler_program|. The first term represents the fit of the model to data; as the model fits better this term shrinks. The second term represents the complexity of the model; it grows as the model becomes more complex (for example as the SAE width grows).
The large data regime: When we are communicating many neural activations using our encoding scheme, we send the description of the decoder network exactly once (as it is reused) but we must send the SAE encodings for each set of activations separately. Therefore we may amortise the cost of sending the decoder network and our expression for the description length reduces to approximately just DL(z), the cost of sending the feature activations. For our analysis, we assume that the dataset size is sufficiently large for this assumption to hold in our MDL analysis.
Occam's Razor: All else equal, an explanation is preferred to explanation if . Intuitively, the simpler explanation is the better one. We can operationalise this as the Minimal Description Length (MDL) Principle for model selection: Choose the model with the shortest description length which solves the task. It has been observed that lower description length models often generalise better (MacKay ch.28).
More explicitly, we define the Minimum Description Length as:
Definition 3 - Minimal Description Length (MDL): where and We say an SAE is ε-MDL-optimal if it obtains this minimum.
4. Independent Additivity of Feature Explanations
Following Occam's razor we prefer simpler explanations, as measured by description length (if the explanations have equal predictive power). Note, however, that SAEs are not intended to simply give compressed explanations of neural activations - compression alone is not enough to guarantee interpretability. SAEs are intended to give explanations that are human-understandable. We must also account for how humans would actually make sense of feature activations.
SAE features are typically understood in an independent manner. For example, we would often like to look at the max activations of a feature without controlling for the activations of the other features.
For human interpretability, there's a good reason for this: given D features there are pairs of features and possible sets of features. Humans can only typically hold a few concepts in working memory, so if features are all entangled such that understanding a single concept requires understanding arbitrary feature interactions, the explanation will not be human-understandable. This is also why the dense neural activations themselves are typically not interpretable.
We would like to understand features independently of each other so that understanding a collection of features together is equivalent to understanding them all separately. We call this property "independent additivity", defined below.
Definition 4 - Independent Additivity: An explanation e based on a vector of feature activations is independently additive if . We say that a set of features are independently additive if they can be understood independently of each other and the explanation of the sum of the features is the sum of the explanations of the features.
Note that here the notion of summation depends on the explanation space. For natural language explanations, summation of adjectives is typically concatenation ("big" + "blue" + "bouncy" + "ball" = "The big blue bouncy ball"). For neural activations, summation is regular vector addition ().
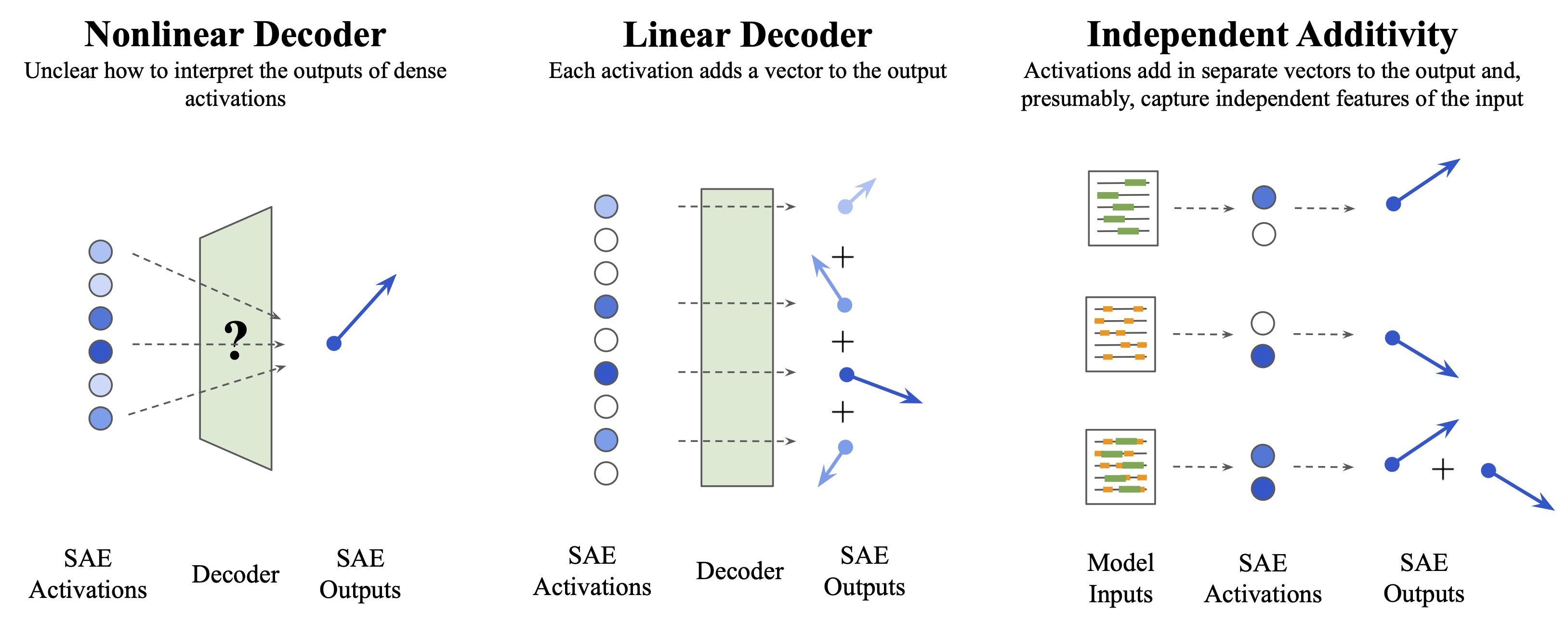
We see that if our SAE features are independently additive, we can also use this property for interventions and counterfactuals too. For example, if we intervene on a single feature (e.g. using it as a steering vector), we can understand the effect of this intervention without needing to understand the other features.
Note that linear decoders have this property. The independent additivity condition is directly analogous to the "composition as addition" property of the Linear Representation Hypothesis discussed in Olah et al. 2024. The key difference is that "independent additivity" relates to the SAE features being composable via addition with respect to the explanation - this is a property of the SAE Decoder.
Whereas in the Linear Representation Hypothesis (LRH), "composition as addition" is about the underlying true features (i.e. the generating factors of the underlying distribution) - this is a property of the underlying distribution.
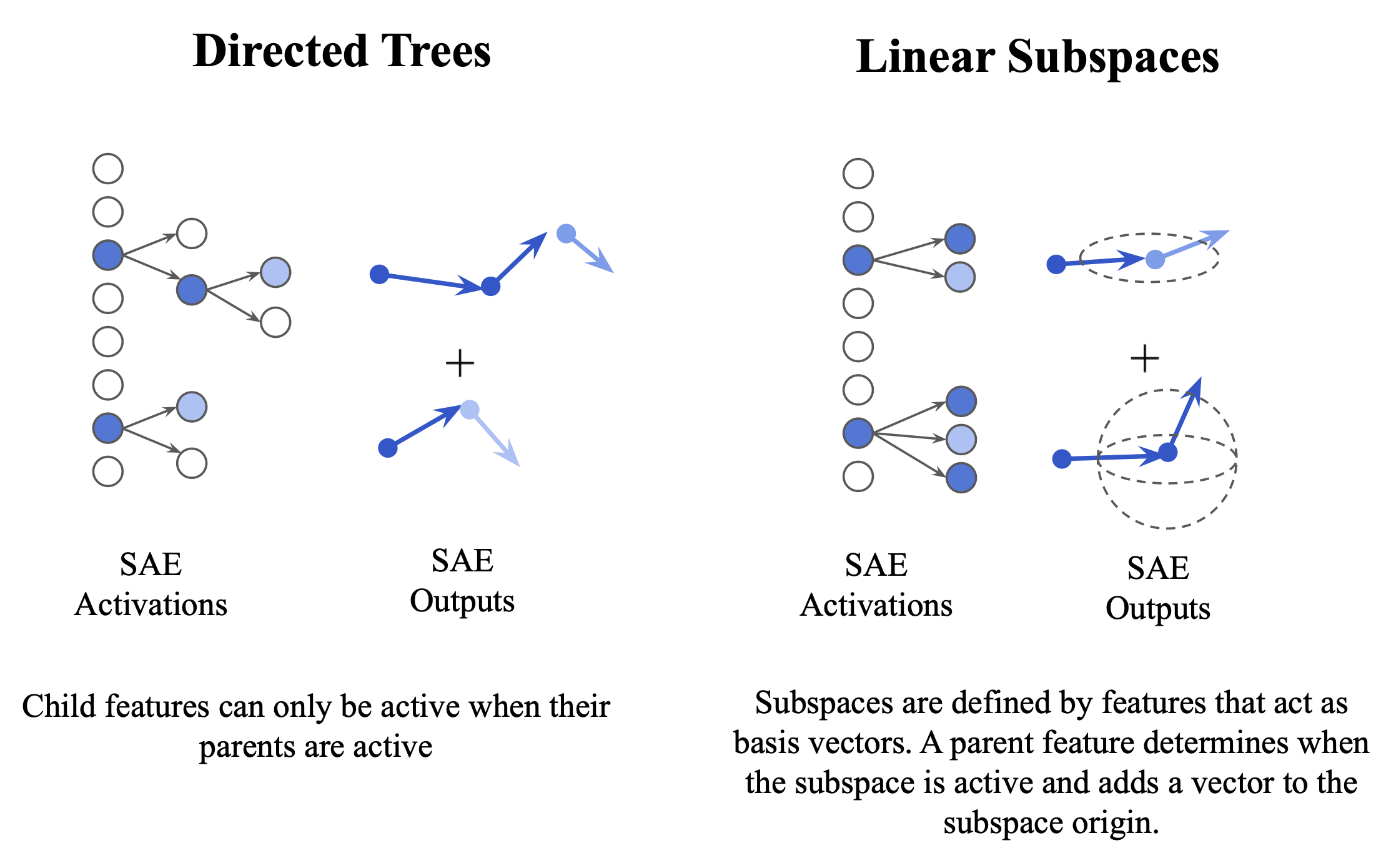
Independent additivity also allows for more general decoder architectures than strictly linear decoders. For example, features can be arranged to form a collection of directed trees, as shown above, where arrows represent the property "the child node can only be active if the parent node is active"[4]. Each feature still corresponds to its own vector direction in the decoder.
Since each child feature has a single path to its root feature, there are no interactions to disentangle and the independent additivity property still holds, in that each tree can be understood independently in a way that's natural for humans to understand. The advantage of the directed-tree formulation is that it can be more description-length efficient.
In practice, we typically expect feature trees to be shallow structures which capture causal relationships between highly related features. A particularly interesting example of this structure is a group-sparse autoencoder where linear subspaces are densely activated together.
Connection to Description Length
An important point is that independent additivity also constrains how we should compute the description length of the SAE activations. Essentially we want the description length of the set of activations, {} to be the sum of the lengths for each feature. That is .
If we know the distribution of the activations, , then it is possible to send the activations using an average description length equal to the distribution's entropy, . For directed trees, the average description length of a child feature would be the conditional entropy,, which accounts for the fact that DL=0 when the parent is not active. This is one reason that directed tree-style SAEs can potentially have smaller descriptions than conventional SAEs.
Powerful nonlinear autoencoders could potentially compress activations further and reduce the minimum description length but are not consistent with independent additivity. The compressed activations would likely be uninterpretable since there are interactions between the that remain entangled. It may not be generally possible to read off the effects of a single feature activation by looking only at that feature. That is, for an arbitrary non-linear decoder, interpreting depends on all [5].
5. SAEs should be sparse, but not too sparse
SAEs are typically seen as unpacking features in superposition from within dense activations, so it's perhaps unclear how SAEs result in compression. Sparsity plays a key role since it's more efficient to specify which activations are nonzero than to send a full vector of activations.
As discussed in the previous section, the description length for a set of SAE activations with distribution pi(z) is the sum of their individual entropies, . A simpler formulation is to directly consider the bits needed without prior knowledge of the distributions. If we know activations are non-zero out of D dictionary features, then an upper bound on the description length is where B is the bits for each non-zero float and is the number of bits to specify which features are active.
We see that increasing sparsity (decreasing ) generally results in smaller description lengths. But achieving the same loss with higher sparsity typically requires a larger dictionary size, which tends to increase description length. This points to an inherent trade-off between decreasing and decreasing the SAE width (dictionary size) in order to reduce description length. We typically find that the minimal description length is achieved when these two effects are balanced and not at the sparse/wide or dense/narrow extreme points.
As an illustrative example, we can compare reasonable SAE parameters to the dense and sparse extremes to show that intermediate sparsities and widths have smaller description lengths. We'll focus on SAEs for GPT-2.
- Reasonable SAEs: Joseph Bloom's open source SAE [LW · GW] for layer 8 has =65, D=25,000. We'll use B=7 bits per nonzero float (basically 8-bit quantization minus one bit for the specified sign). For these hyperparameters, the description length per input token is 1405 bits.
- Dense Activations: A dense representation that still satisfies independent additivity would be to send the neural activations directly instead of training an SAE. GPT-2 has a model size of d=768, the description length is simply bits per token.
- One-hot encodings: At the sparse extreme, our dictionary could have a row for each neural activation in the dataset, so =1 and . GPT-2 has a vocab size of 50,257 and the SAEs are trained 128 token sequences. All together this gives DL=13,993 bits per token.
We see that the reasonable SAE indeed is compressed compared to the dense and sparse extremes. We hypothesise that the reason that we're able to get this helpful compression is that the true features from the generating process are themselves sparse.
The above comparison is somewhat unfair because the SAE is lossy (93% variance explained) and the dense and sparse extremes are lossless. In the next section we do a more careful analysis on SAEs trained on MNIST.
Note the difference here from choosing models based on the reconstruction loss vs sparsity () Pareto frontier. When minimising , we are encouraging decreasing and increasing D until =1. Under the MDL model selection paradigm we are typically able to discount trivial solutions like a one-hot encoding of the input activations and other extremely sparse solutions which make the reconstruction algorithm analogous to a k-Nearest Neighbour classifier[6].
6. Experiment: Finding the MDL solution for SAEs
Lee et al. 2001 describe the classical method for using the MDL criteria for model selection. Here we choose between model hyperparameters (in particular the SAE width and expected ) to choose the optimal SAE under the two-part coding scheme.
The algorithm for finding the minimal description length (MDL) solution for SAEs is as follows (with some additional methodological details):
- Specify a tolerance level, ε, for the loss function. The tolerance ε is the maximum allowed value for the loss, either the reconstruction loss (MSE for the SAE) or the model's cross-entropy loss when intervening on the model to swap in the SAE reconstructions in place of the clean activations. For small datasets using a reconstruction, the test loss should be used.
- Train a set of SAEs within the loss tolerance. It may be possible to simplify this task by allowing the sparsity parameter to also be learned.
- Find the effective precision needed for floats. The description length depends on the float quantisation. We typically reduce the float precision until the change in loss results in the reconstruction tolerance level is exceeded.
- Calculate description lengths. With the quantised latent activations, the entropy can be computed from the (discretised) probability distribution, , for each feature i, as
- Select the SAE that minimizes the description length i.e. the ε-MDL-optimal SAE.
MNIST Case Study
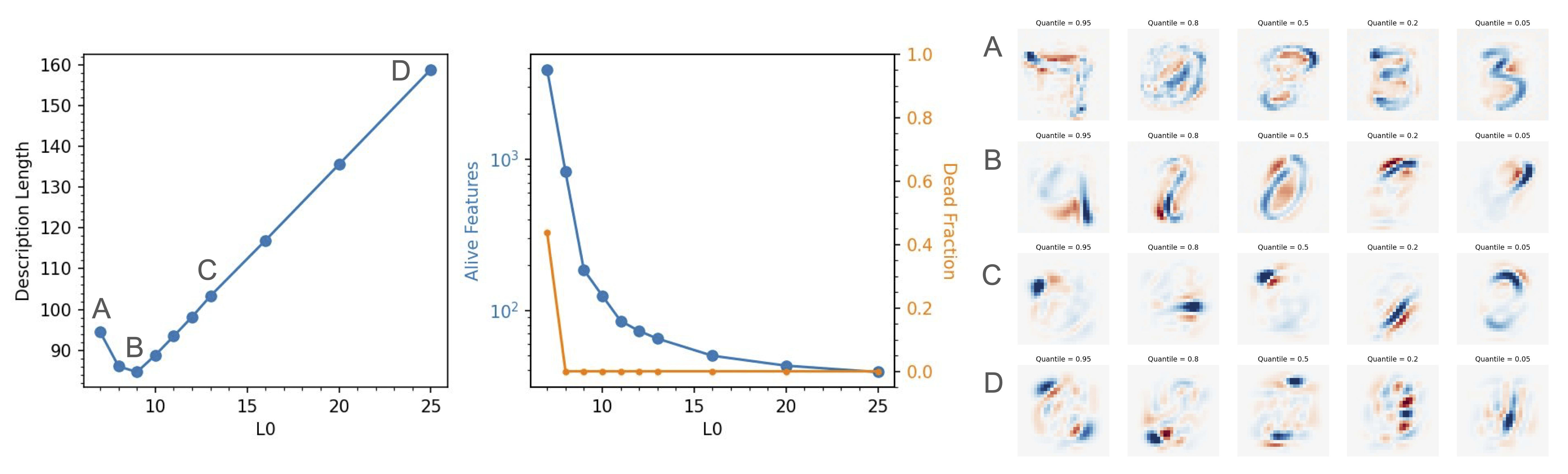
As a small case study, we trained SAEs[7] on the MNIST dataset of handwritten digits (LeCun et al 1998) and find the set of hyperparameters resulting in the same test MSE. We see three basic regimes:
- High , narrow SAE width (C, D in the figure): Here, the description length (DL) is linear with , suggesting that the DL is dominated by the number of bits needed to represent the nonzero floats. The features appear as small sections of digits that could be relevant to many digits (C) or start to look like dense features that one might obtain from PCA (D).
- Low , wide SAE width (A): Even though is small, the DL is large because of the additional bits needed to specify which activations are nonzero when the wide is exponentially larger. The features appear closer to being full digits, i.e. similar to samples from the dataset. Note that the features appear somewhat noisy because early stopping was needed to prevent overfitting to the train set.
- The MDL solution (B): There's a balance between the two contributions to the description length. The features appear like longer line segments for digits, but could apply to multiple digits.
Gao et al. (2024) find that as the SAE width increases, there's a point where the number of dead features starts to rise. In our experiments, we noticed that this point seems to be at a similar point to where the description length starts to increase as well, although we did not test this systematically and this property may be somewhat dataset dependent.
7. Divergence between the Sparsity and MDL Criteria
Below we discuss two toy examples where minimal description length (MDL) and minimal would give different results. We argue that MDL generally gives the more intuitive solutions. For convenience, the toy examples consider boolean features and compare cases with the same reconstruction error.
Limits to Feature Splitting
For LLMs, SAEs with larger dictionaries can find finer-grained versions of features from smaller SAEs, a phenomenon known as "feature splitting" [Bricken et al. 2023]. Some feature splitting is desirable but other cases can be seen as a failure mode of the SAE. We consider two types of feature splitting:
- Desirable Feature Splitting: A novel feature direction is introduced that corresponds to a natural concept that the SAE hadn't yet represented well. This is a desirable form of feature splitting. For example, Bricken et al. 2023 show that a small model learned a feature for "mathematical terminology" whereas larger models learned to distinguish between quantifiers, category theory and prepositions etc.
- Undesirable Feature Splitting: A sparser combination of existing directions is found that allows for smaller . This is a less desirable form of feature splitting for human interpretability. For example Bricken et al. 2023 note one bug where the model learned dozens of features which all represented the letter P in different contexts.
Undesirable feature splitting can waste dictionary capacity and might represent a failure mode of minimizing . We can see this as the SAE Goodharting the sparsity criterion.
A toy model of undesirable feature splitting is an SAE that represents the AND of two boolean features, A and B, as a third feature direction. The two booleans represent whether the feature vectors and are present or not, so there are four possible activations: 0, , , and .
No Feature Splitting: An SAE with only the two boolean feature vectors, and , is capable of reconstructing as the sum , as illustrated in the diagram below. The would simply be the expectation of the boolean activations, so =+ and the description length would be where is the entropy of boolean random variable with probability p.
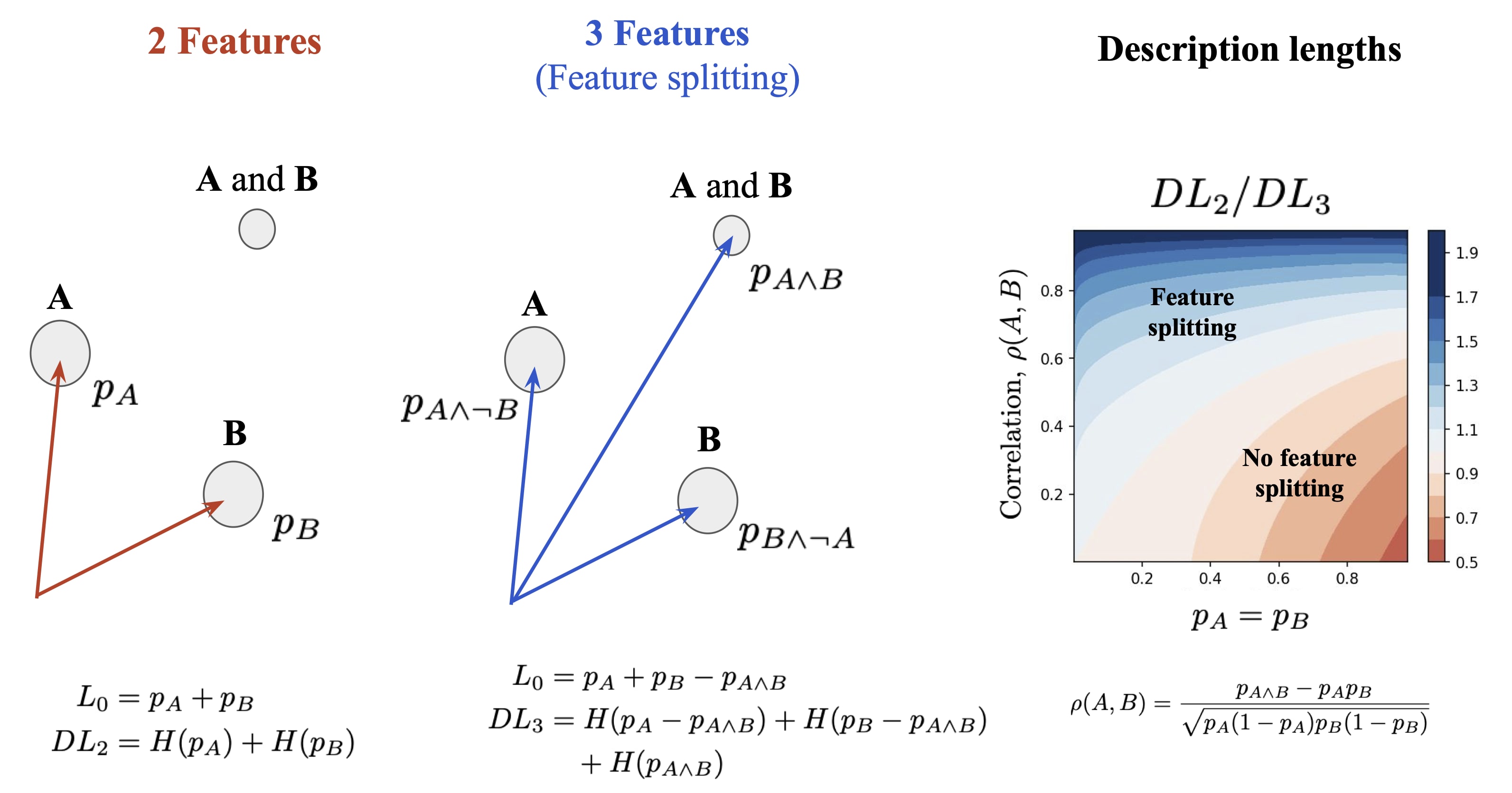
Feature Splitting: For an SAE with three features, is explicitly represented with the vector while the two other features represent and with vectors and [8]. This setup has the same reconstruction error and has lower sparsity, since the probabilities for , say, are reduced as .
Even though the setup with three features always has lower it does not always have the smallest description length. The phase diagram above shows the case where . If the correlation coefficient, , between A and B is large then it takes fewer bits to represent all three features. But if the correlation is small (typically, less than ), then representing only A and B, but not , takes fewer bits. The preferred solution is to not have feature splitting in this case.
Imagine that we have an SAE with fixed width and small ε loss but one of the features is as of yet undecided. We might choose between representing some scarcely used direction which explains some variance or the AND of two features that are already in our feature codebook (an example of feature splitting). This is a problem of deciding which will give the largest improvement on the (loss, DL)-Pareto curve. Adding the novel feature will likely improve the loss but adding the composite feature may improve the description length. This tradeoff will lead to a stricter condition on when to add the composite feature than suggested in the phase diagram above.
More efficient coding schemes for hierarchical features
Often features are strongly related and this should allow for more efficient coding schemes.
For example, consider the hierarchical concepts "Animal" (A) and "Bird" (B). Since all birds are animals, the "Animal" feature will always be active when the "Bird" feature is active.
A conventional SAE would represent these as separate feature vectors, one for "Bird" (B) and one for "Generic Animal" (), that are never active together. This setup has a low equal to the probability of "Animal", , since something is a bird, a generic animal, or neither.
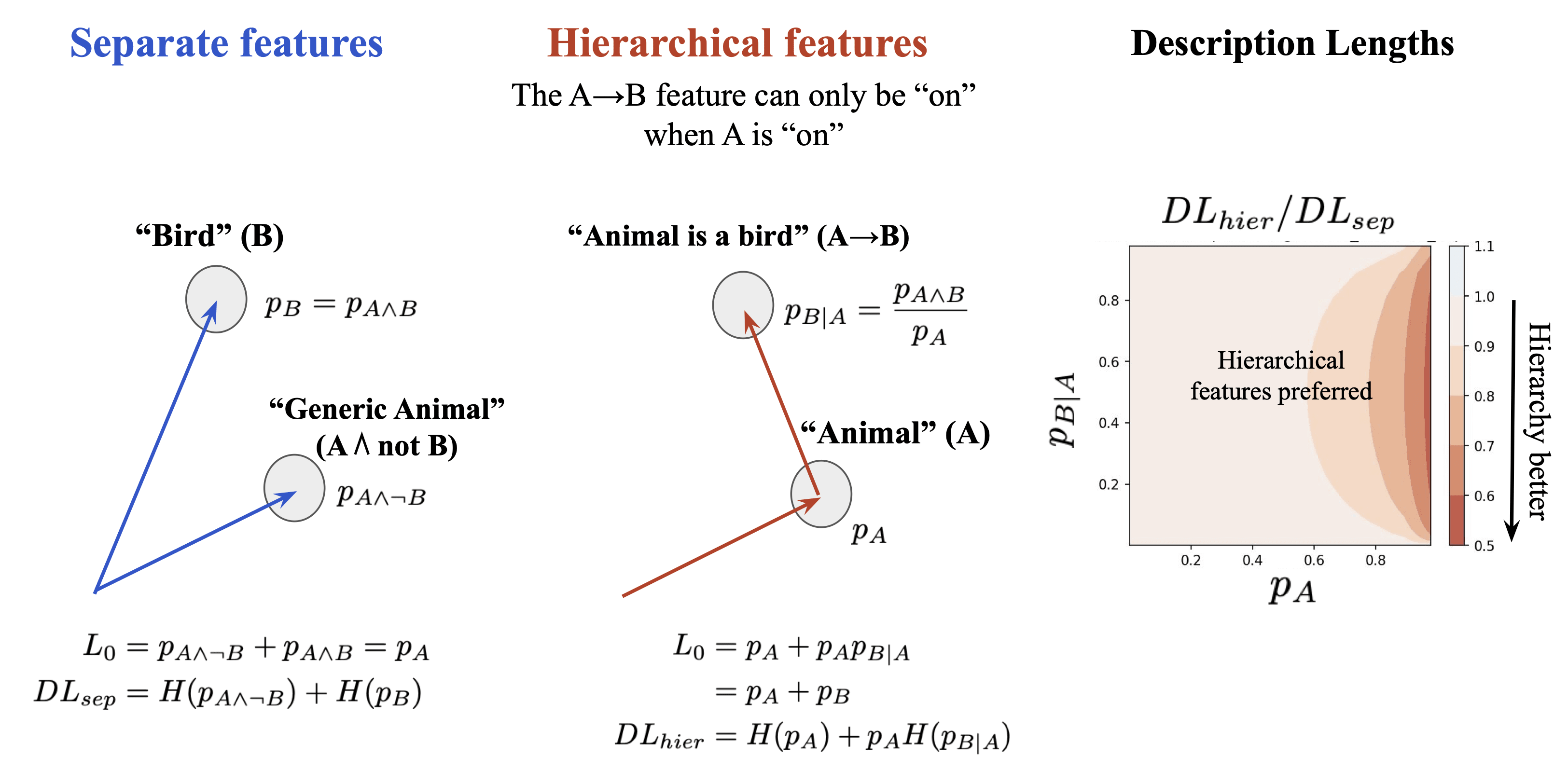
An alternative approach would be to define a variable length coding scheme, meaning that, in the communication setting discussed before, the number of activations sent over can change. One scheme is to first send the activation for "Animal" (A) and only if "Animal" is active, send the activation for "Animal is a Bird" (B→A). This scheme saves bits in description length whenever the second activation is not sent. The overall however is higher because sometimes two activations are nonzero at the same time.
In order to make use of this coding scheme, the encoder and decoder would need to explicitly have the same hierarchical structure. Otherwise, it would not be easy to identify the dependencies between features when assessing the description length.
Note: Hierarchical features are a special case of having ANDs of features, discussed in the Feature Splitting section above. For example, we could define "Bird" in terms of its specific properties as "Bird" equals "Animal" AND "Has Wings" AND "Has Beak" etc. These properties are highly correlated with "Animal" and each other, which is why it's possible to define a more efficient coding scheme.
8. Related Work
Our setting is inspired by rate-distortion theory (Shannon 1944) and the Rate-Distortion-Perception Tradeoff from Blau et al. 2019. Blau et al. note the surprising result that distortion (e.g. squared-error distortion) is often at odds with perceptual quality and suggest that the divergence d() more accurately represents perception as judged by humans (though the exact divergence which most closely matches human intuition is still an ongoing area of research).
As in Ramirez et al. 2011, we use the MDL approach for the Model Selection Problem using the criteria that the best model for the data is the model that captures the most useful structure from the data. The more structure or "regularity" a model captures, the shorter the description of the data, X, will be under that model (by avoiding redundancy in the description). Therefore, MDL will select the best model as the one that produces the most efficient description of the data.
Dhillon et al. 2011 use the information theoretic MDL principle to motivate their Multiple Inclusion Criterion (MIC) for learning sparse models. Their setup is similar to ours but their method relies on sequential greedy-sampling rather than a parallel approach, which performs slower than the SAE methods on modern hardware but is otherwise a promising approach. They present applications where human interpretability is a key driver of the reason for a sparse solution and we present additional motivations for sparsity as plausibly aligning with human interpretability.
Bricken et al. 2023 discuss defining features as "the simplest factorization of the activations". We don't directly claim that this should be the definition of features but we instead argue that features make up explanations, where simpler explanations are preferred. Given our experiments we find similar "bounces" (global minima) in the description length as a function of SAE width, rather than a monotonic function. Larger dictionaries tend to require more information to represent, but sparser codes require less information to represent, which may counterbalance.
Gross et al. 2024 [AF · GW] use Mechanistic Interpretability techniques to generate compact formal guarantees (i.e. proofs) of model performance. Here they are seeking explanations which bound the model loss by some ε on a task. They find that better understanding of the model leads to shorter (i.e. lower description length) proofs. Similar to our work the authors note the deep connection between mechanistic interpretability and compression.
9. Conclusion
In this work, we have presented an information-theoretic perspective on Sparse Autoencoders as explainers for neural network activations. Using the MDL principle, we provide some theoretical motivation for existing SAE architectures and hyperparameters. We also hypothesise a mechanism and criteria to describe the commonly observed phenomena of feature splitting. In the cases where feature splitting can be seen as undesirable for downstream applications, we hope that, using this theoretical framework, the prevalence of undesirable feature splitting could be decreased in practical modelling settings.
Our work suggests a path to a formal link between existing interpretability methods and information-theoretic principles such as the Rate-Distortion-Perception trade-off and two-part MDL coding schemes. We would be excited about work which further connects concise explanations of learned representations to well-explored problems in compressed sensing.
Historically, evaluating SAEs for interpretability has been difficult without human interpretability ratings studies, which can be labour intensive and expensive. We propose that operationalising interpretability as efficient communication can help in creating principled evaluations for interpretability, requiring less subjective and expensive SAE metrics.
We would be excited about future work which explores to what extent the variants in SAE architectures can decrease the MDL of communicated latents. In particular, Section 5 suggests that causal structure may be important to efficient coding. We would also be interested in future work which explores the relationship between the MDL-optimal hyperparameters for a given allowable error rate ε, possibly through scaling laws analysis.
See here for a poster version of this post.
Thanks to Jason Gross and Jacob Drori for reading early drafts of this work. Thanks to Jack Foxabbott, Louis Jaburi, Can Rager, Evžen Wybitul, Lawrence Chan and Sandy Tanwisuth for helpful conversations.
- ^
Given that SAEs are sparse we note the following result which we inherit from theory on Lasso-style algorithms (assuming the irrepresentable condition from Zhao et al 2006):
Top-K sparse dictionary learning is *sparsistent* i.e. satisfies "sparsity pattern consistency".
In other words: as where denotes the indices of the non-zero elements of . Sparsistency here implies that the dictionary learning algorithm is consistently able to identify the correct set of sparse features in the asymptotic limit, given that the true features of the generating process are indeed sparsely linearly represented. Hence our SAE training method provably converges to the correct solution in ideal conditions.
- ^
Here we're using the term "feature" as is common in the literature to refer to a linear direction which corresponds to a member of the set of a (typically overcomplete) basis for the activation space. Ideally the features are relatively monosemantic and correspond to a single (causally relevant) concept. We make no guarantees that the features found by an SAE are the "true" generating factors of the system (though we might hope for this and use this as an intuition pump).
- ^
An explanation is typically a natural language statement. SAEs give outputs which are analogous to explanations since we can simply give an interpretation of individual features with a process like AutoInterp.
- ^
In particular we may be interested in a set-up where the child node is active if and only if the parent node is active as a special case of this.
- ^
One possible middle ground here might be bilinear structures which can be more expressive than linearity but have been shown to maintain some interpretability properties as in Sharkey 2023.
- ^
Note that we cannot always strictly rule out these solutions since there is some dependency on the loss tolerance given and the dataset. We show how this plays out for a real dataset in the following section.
- ^
We trained BatchTopK SAEs (Bussman et al 2024 [AF · GW]), typically for 1000+ epochs until the test reconstruction loss converged or stopping early in cases of overfitting. Our desired MSE tolerance was 0.0150. Discretizing the floats to roughly 5 bits per nonzero float gave an average change in MSE of ≈0.0001.
- ^
With three features in a 2d plane it may seem difficult to find a linear encoder to separate them, but we can find lines that separate each feature from the other two and have the encoder measure the distance away from dividing line.
8 comments
Comments sorted by top scores.
comment by Jacob Dunefsky (jacob-dunefsky) · 2024-09-18T21:44:41.039Z · LW(p) · GW(p)
Really cool stuff! Evaluating SAEs based on the rate-distortion tradeoff is an extremely sensible thing to do, and I hope to see this used in future research.
One minor question/idea: have you considered quantizing different features’ activations differently? For example, one might imagine that some features are only binary (i.e. is the feature on or off) while others’ activations might be used by the model in a fine-grained way. Quantizing different features differently would be a way to exploit this to reduce the entropy. (Of course, performing this optimization and distributing bits between different features seems pretty non-trivial, but maybe a greedy-based approach (e.g. tentatively remove some number of bits from each feature, choose the feature which increases the loss the least, repeat) would work decently enough.)
Another minor question: do the rate-distortion curves of different SAEs intersect? I.e. is it the case that some SAE A achieves a lower loss than SAE B at a low bitrate, but then at a high bitrate, SAE B is better than SAE A? If so, then this might suggest a way to infer hierarchies of features from a set of SAEs: use SAE A to get low-resolution information about your input, and then use SAE B for the high-res detailed information.
Putting these questions aside, this is an area of research that I am extremely interested in, so if you are still working on this or have any new cool results, I would love to see.
Replies from: michael-pearce, kola-ayonrinde↑ comment by Michael Pearce (michael-pearce) · 2024-09-20T23:18:33.594Z · LW(p) · GW(p)
On the question of quantizing different feature activations differently: Computing the description length using the entropy of a feature activation's probability distribution is flexible enough to distinguish different types of distributions. For example, a binary distribution would have a entropy of one bit or less, and distributions spread out over more values would have larger entropies.
In our methodology, the effective float precision matters because it sets the bin width for the histogram of a feature's activations that is then used to compute the entropy. We used the same effective float precision for all features, which was found by rounding activations to different precisions until the reconstruction or cross-entropy loss is changed by some amount.
Replies from: jacob-dunefsky↑ comment by Jacob Dunefsky (jacob-dunefsky) · 2024-09-30T05:13:32.877Z · LW(p) · GW(p)
Computing the description length using the entropy of a feature activation's probability distribution is flexible enough to distinguish different types of distributions. For example, a binary distribution would have a entropy of one bit or less, and distributions spread out over more values would have larger entropies.
Yep, that's completely true. Thanks for the reminder!
↑ comment by Kola Ayonrinde (kola-ayonrinde) · 2024-09-19T20:35:38.920Z · LW(p) · GW(p)
Yeah, we hope others take on this approach too!
have you considered quantizing different features’ activations differently?
Stay tuned for our upcoming work 👀
do the rate-distortion curves of different SAEs intersect? I.e. is it the case that some SAE A achieves a lower loss than SAE B at a low bitrate, but then at a high bitrate, SAE B is better than SAE A? If so, then this might suggest a way to infer hierarchies of features from a set of SAEs: use SAE A to get low-resolution information about your input, and then use SAE B for the high-res detailed information.
This is an interesting perspective - my initial hypothesis before reading your comment was that allowing for variable bitrates for a single SAE would get around this issue but I agree that this would be interesting to test and one that we should definitely check!
With the constant bit-rate version, then I do expect that we would see something like this, though we haven't rigorously tested that hypothesis.
I know that others are keen to have a suite of SAEs at different resolutions; my (possibly controversial) instinct is that we should be looking for a single SAE which we feel appropriately captures the properties we want. Then if we're wanting something more coarse-grained for a different level of analysis maybe we should use a nice hierarchical SAE representation in a single SAE (as above)... Or maybe we should switch to Representation Engineering, or even more coarse-grained working at the level of heads etc. Perhaps SAEs don't have to be all things to all people!
I'd be interested to hear any opposing views that we really might want many SAEs at different resolutions though*
Thanks for your questions and thoughts, we're really interested in pushing this further and will hopefully have some follow-up work in the not-too-distant future
EDIT: *I suspect some of the reason that people want different levels of SAEs is that they accept undesirable feature splitting as a fact of life and so want to be able to zoom in and out of features which may not be "atomic". I'm hoping that if we can address the feature splitting problem, then at least that reason may have somewhat less pull
Replies from: jacob-dunefsky↑ comment by Jacob Dunefsky (jacob-dunefsky) · 2024-09-30T05:23:01.177Z · LW(p) · GW(p)
I know that others are keen to have a suite of SAEs at different resolutions; my (possibly controversial) instinct is that we should be looking for a single SAE which we feel appropriately captures the properties we want. Then if we're wanting something more coarse-grained for a different level of analysis maybe we should use a nice hierarchical SAE representation in a single SAE (as above)...
This seems reasonable enough to me. For what it's worth, the other main reason why I'm particularly interested in whether different SAEs' rate-distortion curves intersect is because if this is the case, then comparing two SAEs becomes more difficult: depending on the bitrate that you're evaluating at, SAE A might be better than SAE B or vice versa. On the other hand, if SAE A's rate-distortion curve is always above SAE B, then it means that the answer to "which SAE is better?" doesn't depend on any hyperparameter (bitrate, or conversely, acceptable loss threshold). I imagine that the former case is probably true, in which case heuristics for acceptable loss thresholds or reasonable bitrates will probably be developed. But it'd be really nice if the latter case turned out to be true, so I'm personally curious to see whether it is.
comment by Seonglae Cho (seonglae) · 2025-03-17T14:39:26.240Z · LW(p) · GW(p)
Interesting! This way of finding a desirable dictionary size and sparsity is fascinating. Also, it's intriguing that the MDL incentivizes SAEs to generate hierarchical features rather than feature splitting.
I have some questions regarding the upper-bound DL computation:
One-hot encodings: At the sparse extreme, our dictionary could have a row for each neural activation in the dataset, so =1 and . GPT-2 has a vocab size of 50,257 and the SAEs are trained 128 token sequences. All together this gives DL=13,993 bits per token.
I can easily compute the above two values following your instruction; however, I'm having trouble computing the 13,993-bit value, or perhaps I've missed something. My calculation results in 1998.98. Could you please clarify which part of my calculation is incorrect?
Another question is about why the sequence length is considered in the extreme sparsity example. It seems to consider all possible token sequences. Is this intended for a fair comparison since the two examples above consider sequence context within relatively dense vectors?
↑ comment by Kola Ayonrinde (kola-ayonrinde) · 2025-03-19T13:22:28.565Z · LW(p) · GW(p)
Hi Seonglae, glad you enjoyed the post!
Yes this is correct, we also multiplied the 1999 number by 7 to represent the number of bits in a float (we assumed 8 bit floats but without specifying the sign as SAE feature magnitudes are always positive which gives 7 bits).
It could be argued that in fact in this case we might not want to think of features as scalars (ie float valued) and use the numbers as you describe them above. In that case note that the value still exceeds the typical description length from the SAEs (1405 bits). This is mostly an illustrative example as it assumes features are uniformly distributed for exposition, in practise we might expect the SAEs to perform even better as we are able to exploit the fact that some features are much more common than others etc
Thanks for your comment!
Replies from: seonglae↑ comment by Seonglae Cho (seonglae) · 2025-03-20T23:29:54.088Z · LW(p) · GW(p)
Thank you for your answer. I understand that in the extreme case and in the illustrative example. The 1999-bit value was derived from binary decisions for each token, as you mentioned, while it exceeds the typical DL.
More importantly, optimizing the tradeoff between sparsity and description length is like solving a convex optimization problem. It would be great to formalize this relationship and observe the trend between sparsity (x-axis) and DL (y-axis), although I have no specific approach in mind. My intuition is that the MDL might serve as a lower bound, with the overall behavior being approximated by the dominant factor's information in each regime.