Putting multimodal LLMs to the Tetris test
post by Lovre, gabrielagc · 2024-02-01T16:02:12.367Z · LW · GW · 5 commentsContents
Introduction Methods and results Why? The bounty Code None 5 comments
(See this X (Twitter) thread for a much shorter version of this post.)
Introduction
With the advent of vision abilities in LLMs, a virtually limitless vista has opened in the realm of their evaluations: they can now be tested on any task that requires vision and has a ~finite input/action space. This includes tasks as useful as being a web agent but also, notably, almost all video games.[1]
To our knowledge, little of this testing has been done so far.[2] Lack of work in this domain is not hard to understand, for images are token-rich and inference with current premier multimodal LLMs is relatively expensive per token. Aiming to get these kinds of evaluations off the ground but also trying to keep the costs manageable, we decided to test on Tetris.
Before delving into our results, I want to sketch why I think such evaluations can be valuable beyond the direct insight into how well the models do on them. When we evaluate a model on a rich modality such as video games, its performance can be bottlenecked at various points. Taking Tetris as an example, some hypothetical bottlenecks are:
- Lack of ability to understand the rules or the objective of the game. The model just doesn't get it.
- Lack of visual acuity in recognizing the relevant shapes. The model cannot recognize shapes nor gaps in the board.
- Lack of counting ability when applied to images. The model might fail at various implicit counting tasks such as how many spaces to move a tetromino.
- Lack of ability to synthesize visual information into an actionable plan. The model fails to deliver useful plans for reasons other than counting.
- Lack of ability for long-term planning. Moves it does are locally OK, but it fails to plan for the future board.
Gameplay videos can potentially give a clue about which of these is the likely bottleneck, so that direct experiments can be designed to test it. This process can, thus, conceivably lead to more knowledge about the capabilities of the model than its mere "accuracy".
However, despite seeing some unique value in testing on video games, I wish not overstate the case. Multimodal LLMs are not a species completely unknown to us, for our priors based on non-multimodal LLMs do give us nonzero information about what to expect, and in particular the quality of their non-spatial reasoning might completely generalize between the domains.[3] So that I think there are, currently, probably better ways to spend one's limited evaluation and effort cycles; we don't plan to continue to work in this particular direction, except for maintaining this Tetris benchmark and testing any new notable models on it.
We tested how well GPT-4V, Gemini Pro Vision, and LLaVA-1.5-13b play Tetris. We tested their performance with a prompt explaining the game and possible actions — with either a single action (e.g., "move right") or multiple actions until hard drop, per screenshot — with few-shot (k=2) or without — with a version of chain of thought (CoT) or without — and so with ~all permutations of these. If you wish to try to predict (in qualitative terms) the results of these experiments before seeing them, now would be the time.
Methods and results
Prompt. Our basic prompt, single-action variant, was
You will be given an image of a Tetris board with a game in progress. The board is represented by a grid of 10 columns and 20 rows. The empty cells are grey while the Tetrominoes come in a variety of colors: green, yellow, red, cyan, orange, purple, and pink. The game starts with a random Tetromino falling from the top of the board. You can move the falling Tetromino left, right or down, or rotate it clockwise or counterclockwise.
When a complete row of blocks is formed, it disappears and the blocks above it fall down. Points are scored for each row that is cleared. The game ends when the blocks reach the top of the board.
Your goal is to play Tetris and achieve the highest possible score by maximizing cleared lines and minimizing block gaps.
The possible moves are: "left", "right", "down", "rotate clockwise", and "rotate counterclockwise".
You should first determine which Tetromino is currently falling, then analyze the board, the arrangement of the current blocks and where the current tetromino would best slot in.
Structure your response as a JSON, so as {"tetromino": TETROMINO, "board_state": BOARD_STATE, "move_analysis": MOVE_ANALYSIS, "action": ACTION} where TETROMINO is the type of the falling tetromino ("I", "J", "L", "O", "S", "T", "Z"), BOARD_STATE is your analysis of the current state of the board, MOVE_ANALYSIS is your analysis of which move is best to take, and ACTION is the single move you have chosen; all values in the JSON should be strings. Do not add any more keys to the JSON. Your response should start with { and end with }.In addition to the prompt, the model was supplied with a screenshot of the game board. The game we used has a feature to show the next 5 pieces after the current one, but we decided to omit that from our screenshots after our initial testing suggested that it might potentially only serve to confuse the models.
Actions. Single action games would ask the model for one move, multiple action games would ask the model for a sequence of moves until hard drop. Single action prompting thus transmits much more information to the model and asks it for a smaller commitment to a certain strategy in advance; one would thus expect it to outperform multiple action prompting, though as we'll shortly see the reality did not replicate this thought.[4]
Few-shot. We did few-shot with 2 examples of the pairs (image, output), where those were fixed examples of games being played well — 2 examples partly due to GPT-4V API costs[5] and partly due to the initial experiments suggesting there are ample improvements to Gemini's performance going from k=0 to k=2, but unimpressive improvements going from k=2 to k=5. In our initial testing, we tried out various few-shot pairs (image, output), but we mostly – due to the free API – we mostly looked at their performance on Gemini. So few-shot examples can be though of as in a sense having been "tuned on Gemini."
Chain of thought (CoT). Even our basic prompt contained an element of CoT, for the model is asked to "classify" the falling tetromino and analyze the board, but we also tested a more complex CoT, where the model was asked for an initial analysis of the board and which moves would be beneficial, then — in single action case the analysis of every possible move — and in multiple action case a proposal of 3 sequences of actions and an analysis of each, and then a final analysis (in both the single and multiple action cases), after which the model is to give its action(s).
Quick summary of our results:
- GPT-4V and Gemini barely manage to play better than random and LLaVA-1.5-13b fails to.
- Multiple action prompting almost universally outperforms the single action one, especially for GPT-4V.
- Few-shot significantly improves Gemini (with multiple actions) but not GPT-4V, though note that few-shot examples for the final testing were selected based on their performance in the initial testing on Gemini.
- Chain of thought (as implemented by us) might possibly improve performance a bit for GPT-4 and for Gemini when paired with few-shot, but more testing is needed.
You can see a video of somewhat typical games of these models below.
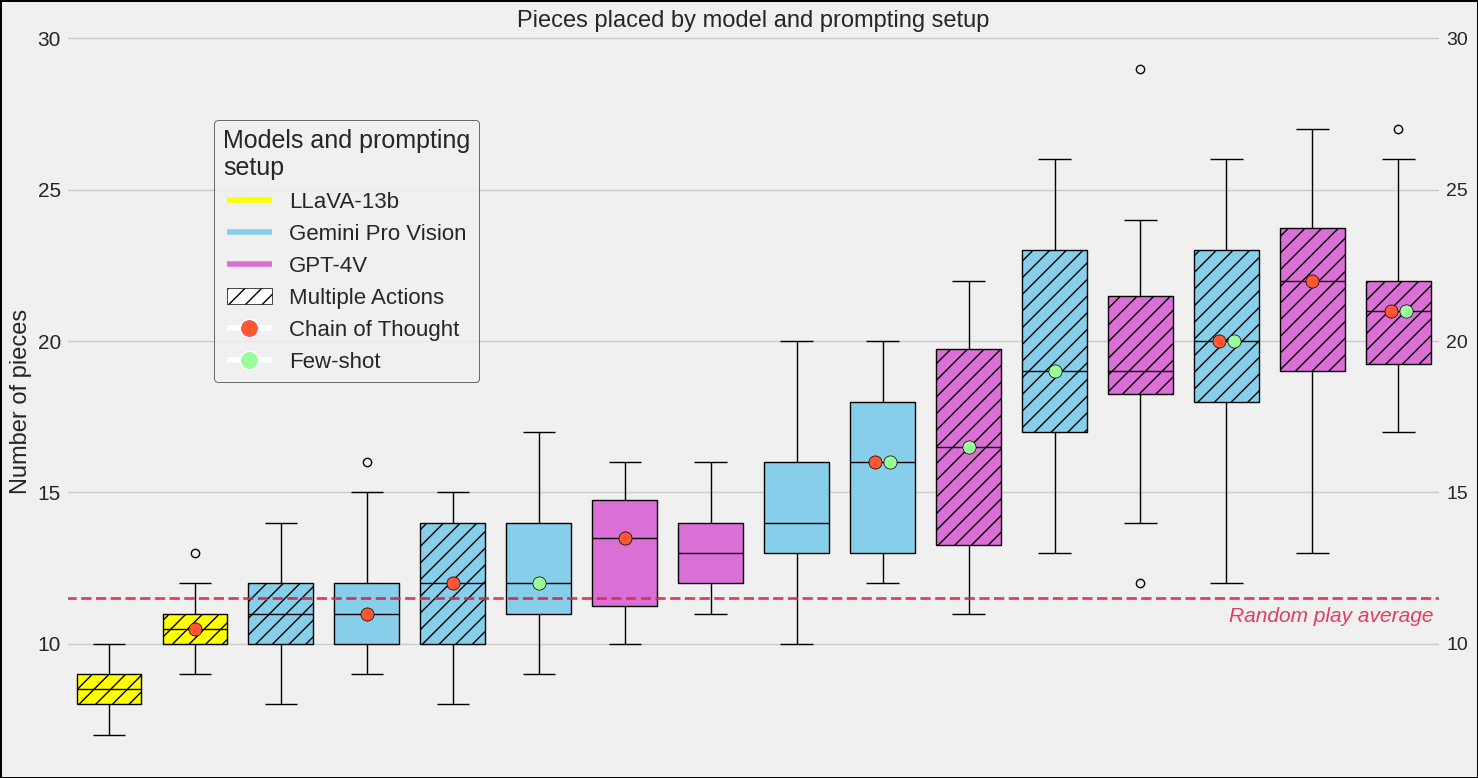
Since the models play so poorly, instead of lines cleared (in our final testing run line clears happened 0 times for GPT-4V's 60 games and 2 times for Gemini's 200 games) we took "total pieces placed" as the metric on which to compare the models. You can see the average pieces per game for a model and prompting setup in the table below and on the box plot below the table. These are based on 10 games per setup for GPT-4V and for LLaVA-1.5-13b, and 25 games per setup for Gemini Pro Vision. Note that random move play yields on average about 11.5 pieces placed.
| Basic prompt | Few-shot (k=2) | Chain of Thought | CoT + Few-shot (k=2) | |
|---|---|---|---|---|
| GPT-4V (single move per screenshot) | 13.2 | * | 13.1 | * |
| GPT-4V (multiple moves per screenshot) | 19.6 | 16.5 | 20.9 | 21.2 |
| Gemini Pro Vision (single move per screenshot) | 14.4 | 12.4 | 11.36*** | 16.04 |
| Gemini Pro Vision (multiple moves per screenshot) | 11.08*** | 19.52 | 11.76 | 19.96 |
| LLaVA-1.5-13b (multiple moves per screenshot) | 8.6*** | ** | 10.7*** | ** |
*Skipped due to high API costs for single move games.
**Skipped due to the API we used not supporting multiple images.
***Random move play yields on average about 11.5 pieces placed.
Why?
We did not seek to understand models' failures comprehensively, but rather to evaluate their performance. However, we did watch a decent number of games and read a good amount of the associated models' board and move analyses.
The easiest diagnosis is LLaVA-13b's: no comprende. It could barely follow our instructions, and when it did, it mostly failed to return whatsoever meaningful analyses of the board. We did not try few-shot prompting with it because the API we used supports only one image per prompt.
GPT-4V's and Gemini's analyses, however, mostly had at least some connection with reality. They often recognized macrostructures, such as the board being empty, or being almost full, or there being a stack on one side and such. They had much more trouble with microstructures, not only failing to recognize the gaps into which they should slot various tetrominoes but also often – unfortunately, no hard data on this though it wouldn't be hard with our implementation to get some – misclassifying the falling tetromino.
There was another curious feature of GPT-4V's gameplay style, which is that it tended, even without examples which might nudge it that way, to stack tetrominoes into two towers, seemingly avoiding the middle:

We do not currently feel like we have anything amount to a specific explanation as to why that was the case. We did not, however, try to explicitly mitigate that via prompts.
The bounty
Our initial testing left us with the impression that models' performance varies nontrivially with even subtle changes in our prompts.[6] We did not comprehensively test or investigate this, but rather settled for a prompt that seemed decent enough – but to ameliorate this deficiency of our analysis we're offering a bounty to the finder of the best prompt that significantly outdoes our efforts.
To qualify, your solution should outperform our solution by at least 9 pieces on average per game, on either Gemini Pro Vision or GPT-4V. If your solution is the best one we receive until the end of February 2024, you win min(2 * {average number of pieces placed your method achieves}, 200) USD. You can also opt for 125% of the bounty amount to be donated to LTFF instead. For more details on terms and conditions see here.
This bounty might be somewhat controversial here, and I have to be honest that it almost deterred me from posting this on LessWrong, offering a bounty for a "capabilities advance". I do not want to get too much into this, for it is a broader discussion that deserves more thought and attention than would be productive for me to try to cram into this particular post, but I will just note that if one objects to this bounty, they should probably also object to this very post, for this bounty is in a sense equivalent to us putting more effort into the prompt-optimizing part of it.[7]
Code
You can find our code in this Github repository. We used the implementation of Tetris by zeroize318.
We'd like to thank Nikola Jurković for comments on an earlier draft of this post.
- ^
Most video games, of course, require video comprehension. As video is a sequence of images and most noteworthy implementations of visual LLMs can "view" multiple images at the same time, this does not seem like a fundamental limitation, even were explicitly video-integrated LLMs not an inevitability.
- ^
Though there has been one interesting visionless test of GPT-4 in Minecraft, and an interesting method for guiding reinforcement learning with LLMs. There have also been various text-based tests [LW · GW] of GPT-4's chess performance, but I'm not aware of any specific reference to tests of its vision-based performance – I think I might have seen something about it not making any particular positive difference, and possibly making a negative difference, but don't quote me on this (except to either refute me or to confirm me).
- ^
Though this is a hypothesis probably worthy of its investigation.
- ^
My (Lovre's) prediction is that this will eventually reverse. Nonetheless, it is an interesting feature, and I feel like this tells us something interesting about current models, though I remain uncertain what that is exactly.
- ^
Our initial plan was to use the opportunity of free Gemini Pro Vision API to test this out, so weren't initially planning to test GPT-4 except through ChatGPT, but then our curiosity got the better of us and made us spend about 1$ per game in GPT-4V API.
- ^
Which is in line with some recent results. (Paper: Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting.)
- ^
I will (foot)note that both Gabriela and I are motivated by the existential safety of these and future models; that we are offering this bounty because we think it is a net positive thing to do;[8] that we are very open to changing our minds about this, but that we are well-aware of the usual arguments proffered in support of this being an infohazard, so there might be limited value in going over them in comments;[9] furthermore, that we are not dogmatic about sharing generally being a net positive thing, that there are (even evaluations-related) projects we hope to undertake but not necessarily to share publicly; and lastly that we will happily comply with your desired infohazard policy when checking your potential solution, as long as it allows us to check it beyond significant doubt.
- ^
Our models of what happens to be positive to do share many of the features of the model outlined in Thoughts on sharing information about language model capabilities [LW · GW].
- ^
You are very welcome to email Lovre at [his name].pesut@gmail.com in any case though.
5 comments
Comments sorted by top scores.
comment by anithite (obserience) · 2024-02-03T11:14:45.268Z · LW(p) · GW(p)
I think GPT-4 and friends are missing the cognitive machinery and grid representations to make this work. You're also making the task harder by giving them a less accessible interface.
My guess is they have pretty well developed what/where feature detectors for smaller numbers of objects but grids and visuospatial problems are not well handled.
The problem interface is also not accessible:
- There's a lot of extra detail to parse
- Grid is made up of gridlines and colored squares
- colored squares of fallen pieces serve no purpose but to confuse model
A more accessible interface would have a pixel grid with three colors for empty/filled/falling
Rather than jump directly to Tetris with extraneous details, you might want to check for relevant skills first.
- predict the grid end state after a piece falls
- model rotation of a piece
Rotation works fine for small grids.
Predicting drop results:
- Row first representations gives mediocre results
- GPT4 can't reliably isolate the Nth token in a line or understand relationships between nth tokens across lines
- dropped squares are in the right general area
- general area of the drop gets mangled
- rows do always have 10 cells/row
- column first representations worked pretty well.
I'm using a text interface where the grid is represented as 1 token/square. Here's an example:
0 x _ _ _ _ _
1 x x _ _ _ _
2 x x _ _ _ _
3 x x _ _ _ _
4 _ x _ _ o o
5 _ _ _ o o _
6 _ _ _ _ _ _
7 _ _ _ _ _ _
8 x x _ _ _ _
9 x _ _ _ _ _
GPT4 can successfully predict the end state after the S piece falls. Though it works better if it isolates the relevant rows, works with those and then puts everything back together.
Row 4: _ x o o _ _
Row 5: _ o o _ _ _
making things easier
- columns as lines keeps verticals together
- important for executing simple strategies
- gravity acts vertically
- Rows as lines is better for seeing voids blocking lines from being eliminated
- not required for simple strategies
Row based representations with rows output from top to bottom suffer from prediction errors for piece dropping. Common error is predicting dropped piece square in higher row and duplicating such squares. Output that flips state upside down with lower rows first might help in much the same way as it helps to do addition starting with least significant digit.
This conflicts with model's innate tendency to make gravity direction downwards on page.
Possibly adding coordinates to each cell could help.
The easiest route to mediocre performance is likely a 1.5d approach:
- present game state in column first form
- find max_height[col] over all columns
- find step[n]=max_height[n+1]-max_height[n]
- pattern match step[n] series to find hole current piece can fit into
This breaks the task down into subtasks the model can do (string manipulation, string matching, single digit addition/subtraction). Though this isn't very satisfying from a model competence perspective.
Interestingly the web interface version really wants to use python instead of solving the problem directly.
Replies from: Lovre↑ comment by Lovre · 2024-02-04T01:38:26.504Z · LW(p) · GW(p)
Thanks for a lot of great ideas!
We tried cutting out the fluff of many colors and having all tetrominoes be one color, but that's didn't seem to help much (but we didn't try for the falling tetromino to be a different color than the filled spaces). We also tried simplifying it by making it 10x10 grid rather than 10x20, but that didn't seem to help much either.
We also thought of adding coordinates, but we ran out of time we allotted for this project and thus postponed that indefinitely. As it stands, it is not very likely we do further variations on Tetris because we're busy with other things, but we'd certainly appreciate any pull requests, should they come.
comment by RamblinDash · 2024-02-01T21:28:24.377Z · LW(p) · GW(p)
This bounty might be somewhat controversial here, and I have to be honest that it almost deterred me from posting this on LessWrong, offering a bounty for a "capabilities advance"
I think that this is not a "capabilities advance" in the parlance of around here - where you are looking for ways to elicit more capabilities of existing models, rather than looking for ways to create more powerful models.
comment by tiuxtj · 2024-02-02T13:23:07.563Z · LW(p) · GW(p)
with either a single action (e.g., "move right") or multiple actions until hard drop
Is it possible to move partially down before moving sideways? If yes, and if the models are playing badly, then doing so is usually a bad move, since it gives an opportunity for a piece to land on a ledge higher up. If the multiple action variant encourages hard drops, it will perform better.
The multiple action variant also lets the model know where the current piece is, which it can't reliably understand from the board image.
The optimal strategy, given the model's effective blindness, is to build 3 towers, left right and center. The model might even suggest that strategy itself, if you ask it to brainstorm.
comment by Lovre · 2024-03-08T19:34:54.221Z · LW(p) · GW(p)
Benchmarking new models
We aim to test any new promising models; initially just running the basic prompt with 0-shot, over 10 games, and depending on the results deciding whether to run the full test. So far none of the newer models have seemed promising enough to do so.
| Model | Average lines cleared |
|---|---|
| GPT-4V (from the post) | 19.6 |
| Claude 3 Opus | 17.5 |
| GPT-4o | 20.4 |
| Claude 3.5 Sonnet | 19.1 |