VLM-RM: Specifying Rewards with Natural Language
post by ChengCheng (ccstan99), David Lindner, Ethan Perez (ethan-perez) · 2023-10-23T14:11:34.493Z · LW · GW · 2 commentsThis is a link post for https://far.ai/post/2023-10-vlm-rm/
Contents
tl;dr Motivation Vision Language Models as Reward Models(VLM-RMs) How It Works Experiments and Key Findings Conclusion and future work Full paper Acknowledgements None 2 comments
tl;dr
We show how to use Vision-Language Models (VLM), and specifically CLIP models, as reward models (RM) for RL agents. Instead of manually specifying a reward function, we only need to provide text prompts like “a humanoid robot kneeling” to instruct and provide feedback to the agent. Importantly, we find that larger VLMs provide more accurate reward signals, so we expect this method to work even better with future models.

Motivation
Reinforcement Learning (RL) relies on either manually specifying reward functions, which can be challenging to define, or learning reward models from a large amount of human feedback, which is expensive to provide.
To address these challenges, we explore the potential of using pretrained Vision-Language Models (VLMs) to provide a reward signal instead. VLMs are pretrained on a large amount of data connecting text and images. CLIP models are a prime example of VLMs, and we show how to leverage them to specify tasks for RL agents using natural language.
Using pretrained models to oversee other models has been a recent trend in the alignment community. Methods such as Constitutional AI leverage capable language models to supervise other language models, taking only a small amount of human feedback as input (e.g., in the form of a “constitution”). This approach is more sample efficient [AF · GW] and potentially more scalable than using pairwise comparison. However, using pretrained models to supervise other agents has been mostly studied in language-only tasks. Our work opens up a new domain in which we can evaluate related approaches: vision-based RL tasks. For further details, please refer to our research paper Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning.
Vision Language Models as Reward Models
(VLM-RMs)
VLMs, like CLIP, are trained to understand both visual and textual information. Previous work showed that these models can successfully solve downstream tasks they have not been trained for, such as classifying images and generating captions for images. This motivates us to use them for a different downstream task: as a reward model to supervise RL agents. Typically, we need to manually define a reward function to specify a task for an RL agent to learn. However, using a VLM, we can specify a task using a simple textual instruction, like “a humanoid robot kneeling”. The VLM then evaluates the agent’s actions against this text prompt and provides feedback to guide the agent’s learning.
How It Works
Setup: We want an agent to perform a task that we can evaluate visually but that we do not have a reward function for. For example, we want a humanoid robot to kneel on the ground.
Using CLIP as a Reward Model: The VLM compares the visual feedback with the task description. By calculating the cosine similarity between an image representation and the language description of a task, CLIP allows us to determine a reward function. A better match results in a higher reward.
Goal-Baseline Regularization: We propose an optional step to make the CLIP reward function smoother and easier to learn from, by using a “baseline” prompt that describes the environment in general, for example, “a humanoid”. To regularize the reward model, we project the CLIP embedding of an observation onto the line spanning the embedding of the baseline prompt and goal prompt. A hyperparameter we call regularization strength α controls whether we fully project to one dimension (α=1) or only project “partially” (0 < α < 1). Not applying the regularization corresponds to α=0. See the paper for details.
RL Training: We can now use the resulting reward model with any standard RL algorithm. In our experiments, we use standard implementations of Deep Q-Network (DQN) and Soft Actor-Critic (SAC).
Experiments and Key Findings
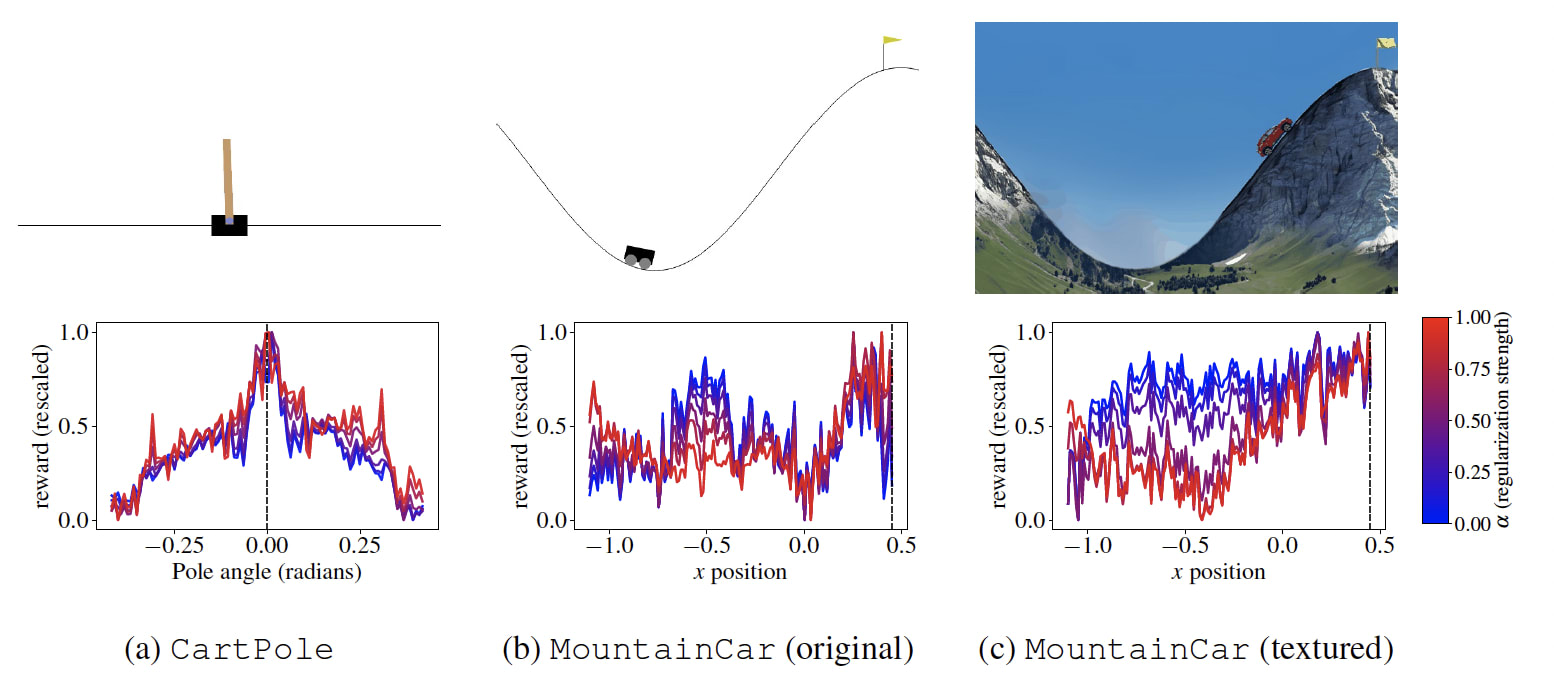
- Classic Control Environments: First, we looked at standard RL tasks: CartPole and MountainCar. For the CartPole, the CLIP reward model works well even without any regularization or tuning. For the MountainCar, we found that the maximum reward is at the right place, but the reward function is poorly shaped. Goal-baseline regularization helped to improve the reward shape. Additionally, we found rendering the environment with more realistic textures makes the reward more well-shaped, see the figure below.
- Novel Tasks in Humanoid Robots: Our main experiment is to train a humanoid robot to do complex tasks. Using a CLIP reward model and single sentence text prompts, we successfully taught the robot tasks such as kneeling, sitting in a lotus position, standing up, raising arms, and doing splits (see Figure 1). However, some tasks we tried, like standing on one leg, placing hands on hips, and crossing arms were challenging. We don’t think these failure cases point to fundamental issues of VLM-RMs but rather to capability limitations in the CLIP models we used.

- Model Size Impact: We find that larger CLIP models are significantly better reward models. In particular, only the largest available CLIP model can successfully teach the humanoid to kneel down. We did not explicitly evaluate scaling for other tasks because the human evaluation is expensive, but we’d expect similar results.

For the humanoid tasks we don’t have any ground truth reward function, so our evaluation relies on human labels. We perform two types of evaluation. First, we collect a set of states containing some that successfully perform the task and label them manually. Then, we can compute the EPIC distance between any reward model and these human labels. This gives us a proxy for the quality of the reward model that we found to be pretty predictive empirically. Second, we train a policy on the CLIP reward models and evaluate the success rate of the final policy manually (see the appendix of our paper for details on the evaluation). Of course, human evaluations are necessarily somewhat subjective; we invite readers to view our final policies at sites.google.com/view/vlm-rm and form their own judgement.
Conclusion and future work
Using VLMs as reward models (RMs) is a new approach to train reinforcement learning (RL) agents. We used VLM-RMs to train a humanoid robot to do complex tasks and found the VLM reward models to be surprisingly effective and robust. Larger VLMs generally perform better as reward models and we expect that future, more advanced VLMs, will be able to handle a broader range of tasks.
VLM-RMs rely on a pretrained model to be able to generalize from a natural language description of a task to correctly rate RL trajectories according to human intentions. Of course, we are not suggesting to use this basic scheme alone to align powerful AI systems. Rather, we believe that VLM-RMs provide a toy model of practical alignment schemes that involve using pretrained models to oversee other models. Importantly, our setup is different from language-only tasks that are currently being studied predominantly in the alignment community. We think understanding our setup better could provide complementary perspectives to only studying language agents.
From an alignment perspective, the first major open question is how robust VLM-RMs are against optimization pressure. We were somewhat surprised that we did not find much evidence of reward hacking in the tasks we studied. In preliminary experiments with smaller CLIP models, we did observe some behavior that looked like reward hacking, but this entirely went away when using bigger CLIP models. We’d be excited to better understand in what cases reward hacking can occur depending on the size of the supervising model and the optimization power of the RL agent.
More broadly, if we find situations where using VLM-RMs produces misaligned RL agents, these could act as model organisms for misalignment [AF · GW] to study more sophisticated alignment schemes.
If you're also interested in making AI systems safe and beneficial, we're hiring! Check out our roles at FAR AI.
Full paper
Juan Rocamonde, Victoriano Montesinos, Elvis Nava, Ethan Perez, David Lindner. "Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning". arXiv preprint arXiv:2310.12921
Acknowledgements
We thank Adam Gleave for valuable discussions throughout the project and detailed feedback on an early version of the paper, Jérémy Scheurer for helpful feedback early on, Adrià Garriga-Alonso for help with running experiments, and Xander Balwit for help with editing the paper.
2 comments
Comments sorted by top scores.
comment by Zane · 2023-10-23T15:22:31.499Z · LW(p) · GW(p)
That's terrifyingly cool! I notice that they usually fall over after having completed the assigned position; are you only rewarding them being in a position at a particular point in time, after which there's nothing left to optimize for? Are you able to make them maintain a position for longer?
Replies from: David Lindner↑ comment by David Lindner · 2023-10-23T22:01:32.913Z · LW(p) · GW(p)
The agents are rewarded at every timestep and we want them to perform the task throughout the whole episode, so falling over is definitely not what we want. But this has more to do with the policy optimization failing than with the reward model. In other words a policy that doesn't fall over would achieve higher reward than the policies we actually learn. For example, if we plot the CLIP reward over one episode, it typically drops at the end of the episode if the agent falls down.
We tried some tricks to improve the training, such as providing a curriculum starting from short episodes to longer ones. This worked decently well and made the agents fall over less, but we ended up not using it in the final experiments because we primarily wanted to show that it works well with off-the-shelf RL algorithms.