What will the first human-level AI look like, and how might things go wrong?
post by EuanMcLean (euanmclean) · 2024-05-23T11:17:03.135Z · LW · GW · 2 commentsContents
How to read this post What will the first human-level AI look like? Will HLAI be a scaled-up LLM (with tweaks)? 7 people said roughly “yes”[1] 4 people said roughly “no” How might HLAI look different to LLMs? Will HLAI at least be a neural network? How fast will the transition be? What will transformative AI be good at? Human-level AI when? How could AI bring about an existential catastrophe? The sources of risk Takeover by misaligned AI Objections to the takeover scenario Other disaster scenarios Going the way of the apes Extreme inequality A breakdown of trust A vague sense of unease The probability of an existential disaster due to AI Conclusion Appendix Participant complaints about Q1 Participant complaints about timelines question None 2 comments
This is the first of 3 posts summarizing what I learned when I interviewed 17 AI safety experts about their "big picture" of the existential AI risk landscape: how will AGI play out, how things might go wrong, and what the AI safety community should be doing. See here [LW · GW] for a list of the participants and the standardized list of questions I asked.
This post summarizes the responses I received from asking “what will the first human-level AI (HLAI) system look like?” and “what is the most likely way AI could bring about an existential catastrophe?”
Many respondents expected the first human-level AI to be in the same paradigm as current large language models (LLMs), probably scaled up, with some new tweaks and hacks, and scaffolding to make it agentic [? · GW]. But a different handful of people predicted that reasonably large breakthroughs are required before HLAI, and gave some interesting arguments as to why. We also talked about what those breakthroughs will be, the speed of the transition, and the range of skills such a system might have.
The most common story of how AI could cause an existential disaster was the story of unaligned AI [? · GW] takeover [LW · GW], but some explicitly pushed back on the assumptions behind the takeover story. Misuse [LW · GW] also came up a number of times. Some took a more structural [EA · GW] view of AI risk, emphasizing threats like instability, extreme inequality, gradual disempowerment, and a collapse of human institutions.
How to read this post
This is not a scientific analysis of a systematic survey of a representative sample of individuals, but my qualitative interpretation of responses from a loose collection of semi-structured interviews. Take everything here appropriately lightly.
Results are often reported in the form “N respondents held view X”. This does not imply that “17-N respondents disagree with view X”, since not all topics, themes and potential views were addressed in every interview. What “N respondents held view X” tells us is that at least N respondents hold X, and consider the theme of X important enough to bring up.
What will the first human-level AI look like?
Q1: What is your modal guess of what the first human-level AI (HLAI) will look like? I define human-level AI as an AI system that can carry out roughly 100% of economically valuable cognitive tasks more cheaply than a human.
There were a number of possible ways I could ask roughly the same question: I could have defined human-level AI differently, or instead asked about “artificial general intelligence” or “transformative AI”, “superintelligence” or the “first AI that poses an existential risk”.
Participants would often say something like “this is a dumb definition, I prefer definition x”, or “the more interesting question is y”, and then go on to talk about x or y. In the answers I report below, you can assume by default that they’re talking about roughly “human-level AI” as I defined above, and I’ll mention when they’re pointing to something substantially different.
Will HLAI be a scaled-up LLM (with tweaks)?
7 people said roughly “yes”[1]
7 respondents gave answers roughly implying that the first HLAI will not be radically different from today’s transformer-based LLMs like GPT-4.[2] It’ll almost certainly need, at minimum, some tweaks to the architecture and training process, better reinforcement learning techniques, and scaffolding to give it more power to make and execute plans.
2 of those 7 thought we should focus on the possibility of HLAI coming from the current paradigm regardless of how likely it is. This is because we can currently study LLMs to understand how things might go wrong, but we can’t study an AI system from some future paradigm or predict how to prepare for one. Even if a particular end is statistically more likely (like heart disease) it's worth concentrating on the dangers you can see (like a truck careening in your direction).[3]
4 people said roughly “no”
4 respondents leaned towards HLAI being quite different to the current state-of-the-art.
Adam Gleave pointed out that we can’t simply continue scaling up current LLMs indefinitely until we hit HLAI because we’re going to eventually run out of training data. Maybe there will be enough data to get us to HLAI, but maybe not. If not, we will require a different kind of system that learns more efficiently.
Daniel Filan pointed out that not so long ago, many people thought that the first generally intelligent system would look more like AlphaGo, since that was the breakthrough that everyone was excited about at the time. Now that language models are all-the-rage, everyone is expecting language models to scale all the way to general intelligence. Maybe we’re making the same mistake? AlphaGo and LLMs have a number of parallels (e.g. both include a supervised foundation with reinforcement learning on top), but they are overall qualitatively different.
“I'm inclined to think that when we get AGI, its relation to the smart language models is going to be similar to the relation of smart language models to AlphaGo.” - Daniel Filan
Daniel also offered a thought experiment to illustrate that even human-level LLMs might not be flexible enough to be transformative. Imagine Google had access to human-level LLMs, which is kind of like being able to hire an infinite number of graduates. Could you automate all of Google with this infinite pool of graduates? Probably not. You would quickly run out of supervisors to supervise the graduates. And LLMs can’t build phones or maintain servers. Humans will still be necessary.
Adam highlighted a key uncertainty in answering whether LLMs will scale up to HLAI: can training on short-horizon tasks generalize to long-horizon tasks? We train today’s LLMs to solve short tasks like solving a textbook math problem. Can the skill of solving such short tasks be bootstrapped to longer tasks like writing the math textbook? If so, perhaps LLMs can eventually achieve human-level at any task.
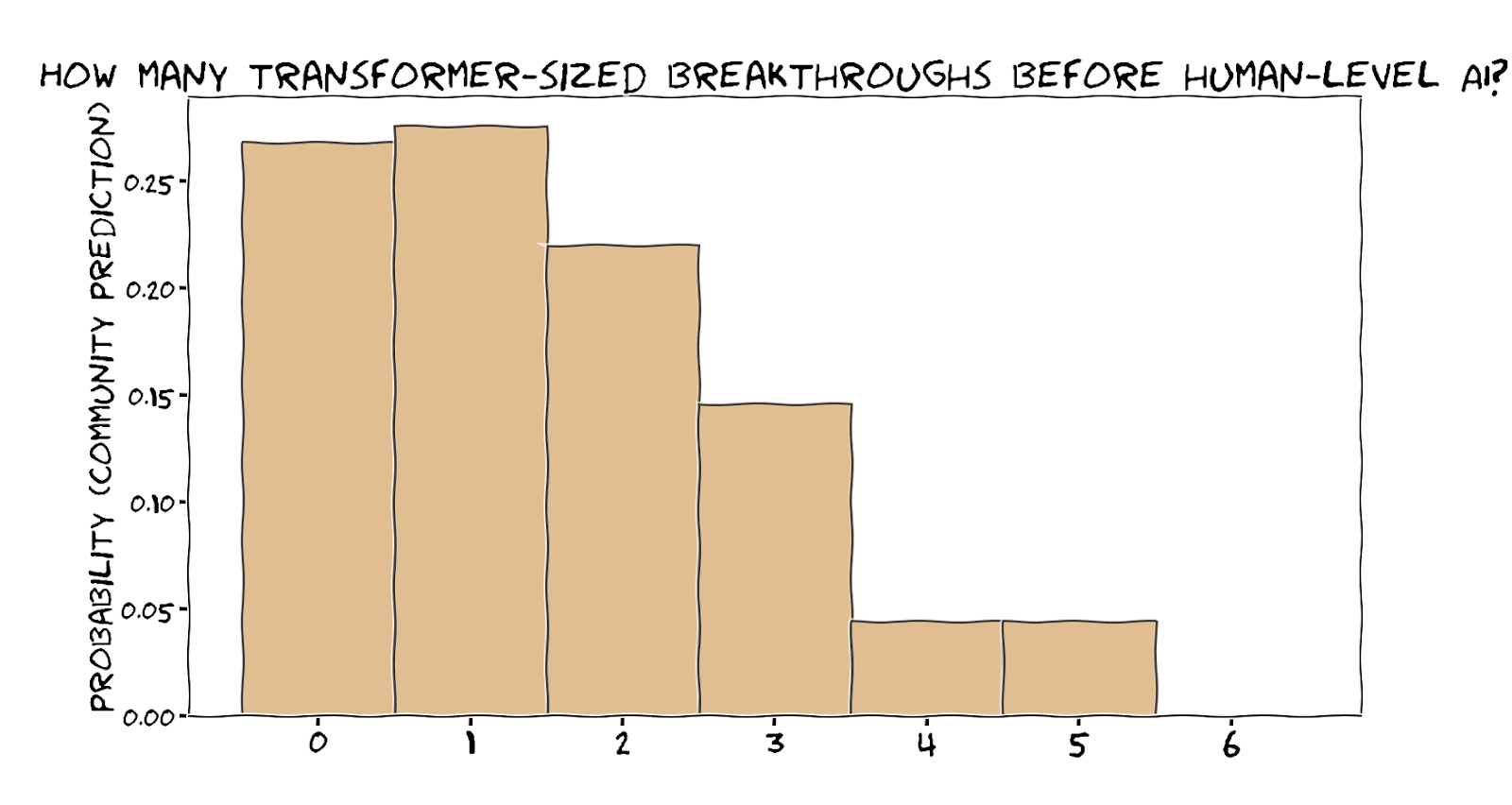
How might HLAI look different to LLMs?
Ryan Greenblatt [AF · GW] reckoned that, to be general and transformative, models may require reasoning beyond natural language reasoning. When a human thinks through a problem, their thought process involves a combination of linguistic reasoning (“if I do x then y will happen”) and more abstract non-linguistic reasoning (involving intuitions, emotions, visual thinking and the like). But serial LLM reasoning is mostly limited to chains of thought built from language. Models will likely require a deeper recurrent architecture to store and manipulate more abstract non-linguistic tokens.
David Krueger speculated that, while transformer-like models may constitute the plurality of an HLAI system or its building blocks, the first HLAI will likely involve many other components yet to be invented.
“Instead of one big neural net there might be a bunch of different neural nets that talk to each other – sometimes they're operating as one big neural net. Think about mixture-of-experts but way more in that direction. [...] Sometimes when people explore ideas like this mixture-of-experts they don’t pan out because they're too fiddly to get working, they require a researcher to spend time tuning and tweaking them, thinking about the particular problem and the issues that come up. I think we can automate all of that and that'll mean these sorts of ideas that are a little bit too complicated to get used much in practice will become real candidates for practical use.” - David Krueger
Will HLAI at least be a neural network?
Could HLAI require something even more different, like something beyond deep learning? 3 of the 4 respondents who discussed this question predicted that HLAI will most likely be made of neural networks of one kind or another.
“Deep learning is not just a phase. I think that deep learning works in part because it has actually distilled some of the major insights that the brain has.” - Nora Belrose
Adrià Garriga-Alonso pointed out that deep learning has been delivering all the breakthroughs since 2010, and there’s no reason to expect that to change before HLAI.
David was less sure about the place neural networks will have in HLAI. He predicted a 60-80% chance that we will build HLAI primarily from deep learning, but doesn’t find the alternative implausible:
“Deep learning is the most important part of it. But it might not be even close to the whole story.” - David Krueger
How fast will the transition be?
Some have speculated that, once we build an AI that can perform AI research (or at least automate it to a large degree), AI progress will become extremely fast, catapulting us to HLAI and superintelligence within a matter of months, days or even hours. This is sometimes called a “hard takeoff”.
4 respondents see a hard takeoff as likely (at varying degrees of hardness), and 1 finds it unlikely. Ajeya Cotra, David and Evan all emphasized the point in time when AI systems become able to do AI research as a “critical threshold”.
“Right now we're seriously bottlenecked by human bandwidth, which is very limited. We make a very small number of decisions within a day. I think if humans were sped up by a factor of a million or something, we could optimize our architectures much more, just by thinking more intelligently about how to do things like sparsity and stuff.” - David Krueger
David finds it highly plausible that it takes less than 1 month to transition between “the status quo is being preserved, although we may have tons of very smart AI running around making disruptive-but-not-revolutionary changes to society” and “superhuman AI systems running amok”; this could happen because of recursive self-improvement, or other reasons, such as geopolitical tensions leading to the abandonment of safeguards, or systems rapidly gaining access to more resources such as compute, data, or physical systems such as robots. Ajeya expected the transition to be between several months and a couple of years.
What will transformative AI be good at?
As many participants brought up, my definition of human-level AI is simplistic. AI doesn’t get better at each kind of task at the same rate, and current AI systems are superhuman at some things and subhuman at others. AlphaZero is lightyears ahead of any human at Go, but that approach cannot solve tasks that are not zero-sum procedurally defined games. So my stupid definition prompted some interesting discussion about the rate of improvement of AI at different kinds of tasks.
Daniel expects AI to become very superhuman at most relevant tasks but still struggle with some edge cases for a long time. Ryan finds it plausible (around 40%) that the first AI systems to automate the majority of human labor will appear much stupider than humans in some ways and much smarter in other ways:
“It's plausible that the first transformatively useful AIs aren't qualitatively human level but are able to do all the cognitive tasks as well as a human using routes that are very different from humans. You can have systems that are qualitatively much dumber than humans but which are able to automate massive fractions of work via various mechanisms.” - Ryan Greenblatt
Richard Ngo emphasized the time horizon of a task as a key factor in the difficulty of a task for AI. Current LLMs can solve a 5-minute math puzzle but are nowhere near able to write a math textbook. By the time AI can do tasks as long as a human can, it will be obscenely good at short-term tasks.
“Current AI is wildly good at a bunch of stuff on short horizons and then just gets worse and worse for longer horizons. I think if you just extrapolate that, then when we get the first human-level system (by your definition) we’ll be like: okay, great – we finally managed to get it to run autonomously for a month, but before that point it would have already published a bunch of theoretical physics papers.” - Richard Ngo
Richard goes into more detail about time horizons in this post [LW · GW].
Human-level AI when?
“The field of AI has existed for 80 years or something, depending on when you want to start counting. Are we halfway there? It feels like we might be. Especially if we just increase inputs a ton in the future. It would be pretty weird if we were more than a hundred years away. Could we get it in the next ten years? Yeah, I think that's possible. I don't know, I could try to put numbers on that, but you're not gonna get tons more info from the numbers than just from that.” - Daniel Filan
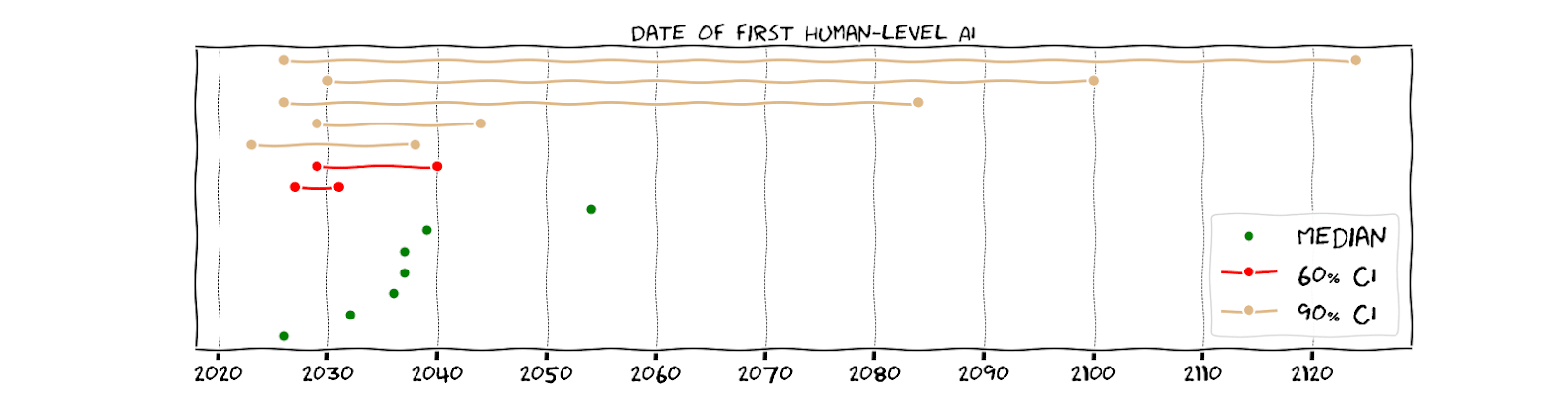
I received a number of estimates about the date of the first human-level AI, at varying degrees of confidence, in the form of medians and confidence intervals. There exist larger-N aggregates of this kind of prediction: for example the AI impacts survey (N=1714, median=2047), this metaculus question (N=154, median=2031) and manifold market (N=313, median=2032).[4] But I’ll show you what I learned here anyway to give you some context about the background assumptions of my sample of respondents, as well as some extra information on AI safety expert’s opinions.
How could AI bring about an existential catastrophe?
Q2: Could AI bring about an existential catastrophe? If so, what is the most likely way this could happen?
In this section, I present a summary of my qualitative discussions on this topic. Readers may also be interested in a more rigorous N=135 survey on a similar question from a couple of years ago by Sam Clarke et al [AF · GW], and for a comprehensive literature review by David Manheim [? · GW].
The phrase “existential catastrophe” contains a lot of ambiguity [EA · GW]. Most commonly the respondents interpreted this to be Toby Ord’s definition: An existential catastrophe is the destruction of humanity’s long-term potential. This does not necessarily involve humans going extinct and doesn’t require any dramatic single event like a sudden AI coup. Some respondents talked about takeover, others talked about permanent damage to society.
The sources of risk
“We're really bad at solving global coordination problems and that's the fundamental underlying issue here. I like to draw analogies with climate change and say, hey - look at that - we've had scientific consensus there for something like 40 or 50 years and we're still not taking effective coordinated action. We don't even understand what it means or have any agreements about how to aggregate preferences or values, there's a lot of potential for various factors to corrupt preference elicitation processes, and preference falsification seems to run rampant in the world. When you run this forward, at some point, out pops something that is basically an out-of-control replicator that is reasonably approximated by the conventional view of a superintelligence.” - David Krueger
What kinds of AI systems should we be most worried about? 2 respondents emphasized that the only AI systems we need to worry about are those with a sufficient amount of agency. A myopic LLM by itself is not particularly scary, since it doesn’t have any long-term goals, and most of the stories of how things go wrong require such long-term goals.
One source of disagreement was whether the risk mainly came from proprietary models of big AI companies (the descendants of ChatGPT, Claude or Gemini) or open-source models.
“It's an open question whether or not a reasonably careful AI company is enough to prevent a takeover from happening” - Adam Gleave
4 respondents emphasized the role of recklessness or a lack of care in the development of proprietary models in their extinction scenarios.
One respondent was instead more worried about the misuse [LW · GW] of open-source models as an existential threat. There’s currently a big debate about whether open-sourcing the cutting edge of AI is good or bad.
Takeover by misaligned AI
Unsurprisingly, the most common vignette theme was that of takeover by a misaligned AI system (see for example here [? · GW] or here [LW · GW]). 7 respondents bought into this story to some degree, while 2 explicitly disagreed with it. As the story usually goes: someone builds an agentic [? · GW] AI system that is highly capable of getting things done. Its goals are not totally aligned with its operator. Maybe it pretends to be aligned [? · GW] to make sure we don’t modify it. Because of instrumental convergence [? · GW], it reasons that it can achieve its goals better if it seizes control of the world.
Adam addressed a common objection that an AI system by itself couldn’t possibly take control of the world:
“If you think “so what, it’s just a brain in a vat, what happens next?” It seems like the world is sufficiently vulnerable that it’s not that hard for even an Adam-level AI system that can make copies of itself and run fairly cheaply to pose a serious risk to humanity. Imagine what a thousand copies of yourself, working constantly, could do. That’s bigger than most academic departments. The team behind stuxnet probably had no more than 100 people. You could at the very least do a significant amount of damage.
We’ve seen single humans come close to taking over entire continents in the past, so I don’t find it very far-fetched that a very smart AI system, with many copies of itself, could do the same, even without superintelligence.”
- Adam Gleave
Will the transition to HLAI result in a unipolar (a single AI agent with control of the world) or multipolar (many AI agents) world? I talked to 2 respondents about this, and both expected a unipolar scenario to be more likely.
Nora Belrose anticipated that if such a takeover were to happen, the AI that takes over wouldn’t be some commercial model like ChatGPT but a military AI, since such an AI would already have access to military power. You don’t need to imagine the extra steps of an AI seizing power from the ground up.
“I say Terminator and Skynet specifically because I'm being literal about it. I literally mean the Skynet scenario where it's a military AI.” - Nora Belrose
Objections to the takeover scenario
2 respondents explicitly pushed against the takeover scenario. Alex Turner argued that a lot of the assumptions behind the misaligned takeover scenario no longer hold, given the way AI is currently going. Namely, AI systems have not turned out to be “literal genies” who always misinterpret the intent of your requests.
“LLMs seem pretty good at being reasonable. A way the world could have been, which would have updated me away from this, is if you can’t just be like ‘write me a shell script that prints out a cute message every time I log in’. You would have to be like: I'm using this operating system, you really need to be using bash, I don't want vsh, I don't want fish. And this should be low memory, you shouldn't add a lot of extra stuff. Make sure it's just a couple of lines, but don't count new lines. Imagine if it was like this. It's totally not like this. You can just say a couple of words and it'll do the thing you had in mind usually.” - Alex Turner
Alex does consider an AI takeover possible, but not because of misaligned intent. If an AI takes over, it will be because a human asked it to.
“If North Korea really wanted to kill a lot of people and somehow they got their hands on this really sophisticated AI, maybe they'd be like, okay, kill everyone in the United States, don't make it obvious that it's on our behalf. Maybe this could happen. But I don't think it would spontaneously build order proteins that would self-assemble into nanofactories or whatever. That's just a really weird kind of plan” - Alex Turner
Other disaster scenarios
Going the way of the apes
An existential catastrophe, by Toby Ord’s definition, doesn’t necessarily require all humans to die out, it just requires AI to curtail most of the value in the future (by our human lights). Daniel offered a vignette of humans going the way of the apes:
“Let's say the AIs have an economy that minimally relies on human inputs. They're making the factories that make the factories and make the chips. They're able to just run the world themselves. They do so in a way that's roughly compatible with humans but not quite. At some point, it stops making sense to have humans run the show. I think my best guess for what happens then is like: the humans are just in a wildlife preserve type thing. We get Australia. And we're just not allowed to fuck anything up outside of Australia.” - Daniel Filan
Extreme inequality
While Nora considered an AI takeover possible (around a 1% chance), she was much more concerned about the potential centralization of wealth and power caused by transformative AI. Such inequality could become locked in, which could curtail humanity’s long-term potential, or be a “fate worse than death” for the world. Nora gave this around a 5% chance of happening.
“Currently most humans have the ability to contribute something to the economy through their labor, this puts some floor on how poor the average person can get. But if humans are Pareto-dominated by AI it's less clear that there's a floor on how poor the average human can get.” - Nora Belrose
To Nora, a world where everyone can have their own AI system, rather than elites controlling AI, is better because it empowers everyone to gain from the AGI revolution. For this reason, Nora is broadly pro the development of open-source AI.
Nora conceded that AI will likely cause a big surplus of economic wealth, and there’s some chance this prevents the poorest from becoming arbitrarily poor. Whether or not the poorest in society are allowed the fruits of superintelligence will come down to politics.
A breakdown of trust
Gillian Hadfield viewed AI safety from a different angle: she is interested in the issue of normative competence. Roughly, will AI systems be trustworthy members of society? Will they be able to learn the rules of society and follow them? If AI systems are not normatively competent, this could cause a collapse of the economy which is hard or even impossible to recover from.
Her story goes like this. We deploy AIs broadly, and they become embedded in our human systems, like banking, law, and so on. But these AIs do not have normative competence: we cannot trust them to follow social and legal rules. This breaks our trust in these systems. And since these systems are built on trust, the systems themselves break down.
“It's a bit like bank runs. If I lose confidence that an institution is going to be stable then I run to take my money out. In the developed world we take for granted high levels of trust. You can leave your car parked on the street. You can send your kids to school and you can eat whatever they're serving in the restaurant. It may not take too much to break those systems.” - Gillian Hadfield
Such a breakdown of institutions could lead to a collapse of our economy. Gillian painted a picture of a world where humans opt out of interacting with the rest of the world. They stay at home and grow their own crops because they don’t feel safe to interact with the rest of the world.
Gillian argued that this will be hard to recover from. A big reason that today’s developing countries are still relatively poor is a lack of trust in institutions. It’s hard to get a loan to start a business because banks don’t trust that you’ll pay them back. And there’s no recipe for building trust, otherwise, the Middle East wouldn’t be in the mess it’s in now.
A vague sense of unease
Many respondents expressed high uncertainty about the future. I often had to push people to say anything concrete – I often found myself saying “ok, can you at least give me some plausible-sounding vignette?”
4 respondents leaned particularly strongly towards uncertainty and a sense that whatever happens with AI, it will be some complicated chain of events that we can’t capture in a simple story like I’m trying to do here. Jamie, for example, said that he was following a heuristic that AI could be destabilizing for the world, so regardless of what a prospective catastrophe looks like, we should approach with caution. Alex predicted some complicated combination of shifts in capital and wealth, job displacement, the commodification of cognition, and a gradual loss of human control and autonomy. Richard reckoned the line between misalignment and misuse will become blurred. Holly Elmore wasn’t so interested in what concrete story is most likely to play out, but rather focussed on a lack of reassuring stories:
“If I don't know how it's impossible for AI to cause problems then I'm just going to assume that they're possible, and that is unacceptable.” - Holly Elmore
The probability of an existential disaster due to AI
I talked with some of the respondents about how likely they find an existential disaster due to AI. Lots of people had low confidence in their estimates, and many complained that this is not a helpful question to ask. Someone could spend a whole career trying to estimate the probability of disaster until they have a precise and robust percentage, but it won’t help us solve the problem. The important thing is that it’s not zero!
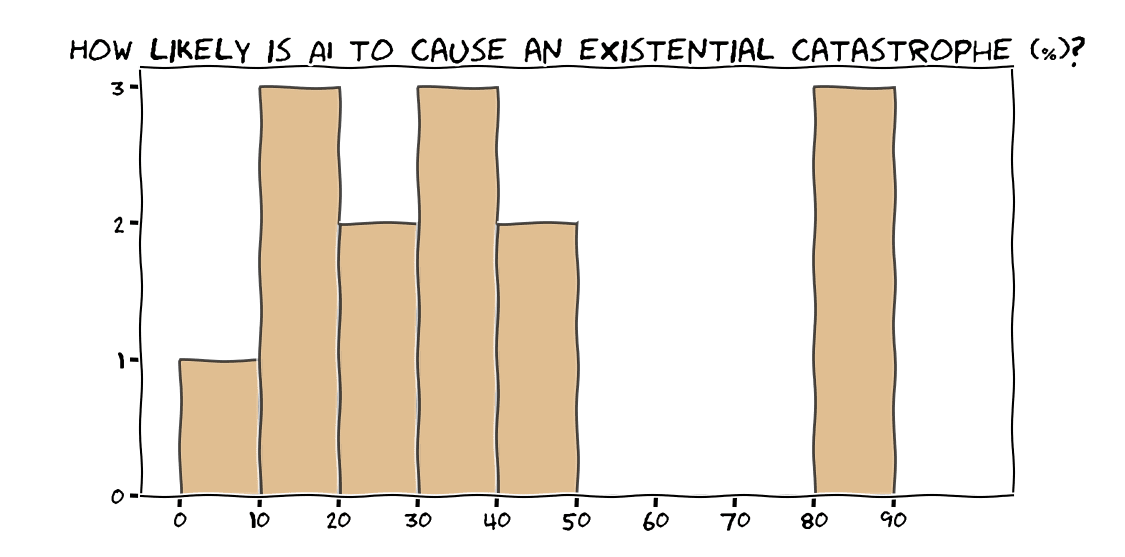
For a larger-N treatment of roughly this question, see the AI impacts survey: 2704 machine learning researchers put a median 5% chance of HLAI being “extremely bad (e.g. human extinction)”.
Conclusion
While a lot of the answers were pretty unsurprising, there was in general more disagreement than I was expecting. While many expect the first human-level AI to be quite similar to today’s LLMs, a sizable minority gave reasons to doubt this. While the most common existential risk story was the classic AI takeover scenario, there were a number of interesting alternatives argued for.
Personally, I walked away from this project feeling less concerned about the classic AI takeover scenario and more concerned about more complicated or structural risks, like inequality or institutional collapse. When I discuss AI risk with friends, I’m going to stop emphasizing AIs pursuing alien goals (e.g. “paperclip maximizers”) and recursive self-improvement, and focus more on the high-level argument that “AI is going to be a huge deal, it’s going to transform the world, so we need to proceed with extreme caution!”.
Appendix
Participant complaints about Q1
The most common complaint was: It’ll be hard to get to 100% of human cognitive tasks, there will be edge cases that AI struggles with even when it’s very superhuman at a number of important tasks.
“Under this definition, are humans dog-level intelligent?” - Daniel Filan
Alex Turner pointed out that this bar is way too high for the label of “human-level”, since no human can do anywhere close to 100% of cognitive tasks! David Krueger was concerned that my definition is a moving target since what we consider to be economically valuable will likely change as HLAI transforms the economy.
Ryan Greenblatt [AF · GW] finds it plausible that the first AI systems that can automate the majority of human labor appear much stupider than humans in some ways and much smarter in other ways
“It's plausible that the first transformatively useful AIs aren't qualitatively human level but are able to do all the cognitive tasks as well as a human via using routes that are very different from humans. You can have systems that are qualitatively much dumber than humans but which are able to automate massive fractions of work via various mechanisms.” - Ryan Greenblatt
David suggested a definition that captured this ambiguity:
“My definition of human-level AI is a little bit different, I say that it’s human-level AI if it has no significant qualitative or quantitative cognitive deficits compared to humans.” - David Krueger
Ryan preferred to focus on “transformative AI”, defined as “the first AI which is so useful that it greatly changes the situation from a safety perspective.” For example, an AI that can speed up AI research & development by 15 or 20 times.
Alex reckoned that the first HLAI isn’t so important since that won’t be what might be an existential risk: the first existentially risky AI system, which will be the first highly agential system, will come some time later.
Evan Hubinger suggested that the nature of the first HLAI isn’t very strategically important:
“Most of the action is in what the world looks like at the time. How crazy is the world? What stuff is happening in the world around that time? Those are the sort of interesting questions where there's disagreement.” - Evan Hubinger
Daniel emphasized that we can’t have high confidence at all about any predictions we make here, so you should take discussions about this with a big grain of salt.
Participant complaints about timelines question
Ben Cottier pointed out an ambiguity in the question “what will the date of the first HLAI be?” Is this question asking about when HLAI is first developed, when it was widely deployed, or when it actually has its transformational effect? There could be a multi-year gap between these. For example, it took years to find out and use all the different capabilities GPT-3 had.
- ^
I’m oversimplifying things here - in reality there is a spectrum of “how much HLAI will look like an LLM”.
- ^
By LLMs I really mean transformer-based multimodal models, the state-of-the-art do not just work with language. But these multimodal models are still typically referred to as LLMs, so I will use that terminology here too.
- ^
Thanks to Quintin Tyrell Davis for this helpful phrasing.
- ^
Figures from time of writing, April 2024.
2 comments
Comments sorted by top scores.
comment by Joseph Miller (Josephm) · 2024-05-23T14:06:28.020Z · LW(p) · GW(p)
4 respondents see a hard takeoff as likely (at varying degrees of hardness), and 1 finds it unlikely
Do people who say that hard takeoff is unlikely mean that they expect rapid recursive self-improvement to happen only after the AI is already very powerful? Presumably most people agree that a sufficiently smart AI will be able to cause an intelligence explosion?
Replies from: euanmclean↑ comment by EuanMcLean (euanmclean) · 2024-05-29T11:52:50.276Z · LW(p) · GW(p)
Interesting question! I'm afraid I didn't probe the cruxes of those who don't expect hard takeoff. But my guess is that you're right - no hard takeoff ~= the most transformative effects happen before recursive self-improvement