AI #85: AI Wins the Nobel Prize
post by Zvi · 2024-10-10T13:40:07.286Z · LW · GW · 6 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility Blank Canvas Meta Video Deepfaketown and Botpocalypse Soon They Took Our Jobs Get Involved Introducing AI Wins the Nobel Prize In Other AI News Quiet Speculations The Mask Comes Off The Quest for Sane Regulations The Week in Audio Rhetorical Innovation The Carbon Question Aligning a Smarter Than Human Intelligence is Difficult People Are Trying Not to Die None 6 comments
Both Geoffrey Hinton and Demis Hassabis were given the Nobel Prize this week, in Physics and Chemistry respectively. Congratulations to both of them along with all the other winners. AI will be central to more and more of scientific progress over time. This felt early, but not as early as you would think.
The two big capability announcements this week were OpenAI’s canvas, their answer to Anthropic’s artifacts to allow you to work on documents or code outside of the chat window in a way that seems very useful, and Meta announcing a new video generation model with various cool features, that they’re wisely not releasing just yet.
I also have two related corrections from last week, and an apology: Joshua Achiam is OpenAI’s new head of Mission Alignment, not of Alignment as I incorrectly said. The new head of Alignment Research is Mia Glaese. That mistake it mine, I misread and misinterpreted Altman’s announcement. I also misinterpreted Joshua’s statements regarding AI existential risk, failing to take into account the broader context, and did a poor job attempting to reach him for comment. The above link goes to a new post offering an extensive analysis of his public statements, that makes clear that he takes AI existential risk seriously, although he has a very different model of it than I do. I should have done better on both counts, and I am sorry.
Table of Contents
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. Proofs of higher productivity.
- Language Models Don’t Offer Mundane Utility. Why the same lame lists?
- Blank Canvas. A place to edit your writing, and also your code.
- Meta Video. The ten second clips are getting more features.
- Deepfaketown and Botpocalypse Soon. Assume a data breach.
- They Took Our Jobs. Stores without checkouts, or products. Online total victory.
- Get Involved. Princeton, IAPS, xAI, Google DeepMind.
- Introducing. Anthropic gets its version of 50% off message batching.
- AI Wins the Nobel Prize. Congratulations, everyone.
- In Other AI News. Ben Horowitz hedges his (political) bets.
- Quiet Speculations. I continue to believe tradeoffs are a (important) thing.
- The Mask Comes Off. What the heck is going on at OpenAI? Good question.
- The Quest for Sane Regulations. The coming age of the AI agent.
- The Week in Audio. Elon Musk is (going on) All-In until he wins, or loses.
- Rhetorical Innovation. Things happen about 35% of the time.
- The Carbon Question. Calibrate counting cars of carbon compute costs?
- Aligning a Smarter Than Human Intelligence is Difficult. Some paths.
- People Are Trying Not to Die. Timing is everything.
Language Models Offer Mundane Utility
Anthropic claims Claude has made its engineers sufficiently more productive that they’re potentially hiring less going forward. If I was Anthropic, my first reaction would instead be to hire more engineers, instead? There’s infinite high leverage things for Anthropic to do, even if all those marginal engineers are doing is improving the consumer product side. So this implies that there are budget constraints, compute constraints or both, and those constraints threaten to bind.
How much mundane utility are public employees getting from Generative AI?
Oliver Giesecke reports 1 in 4 have used it at work, 1 in 6 use it once a week or more. That’s a super high conversion rate once they try it. Of those who try it at all, 38% are using it daily.
This is in contrast to 2 in 3 private sector employees reporting use at all.
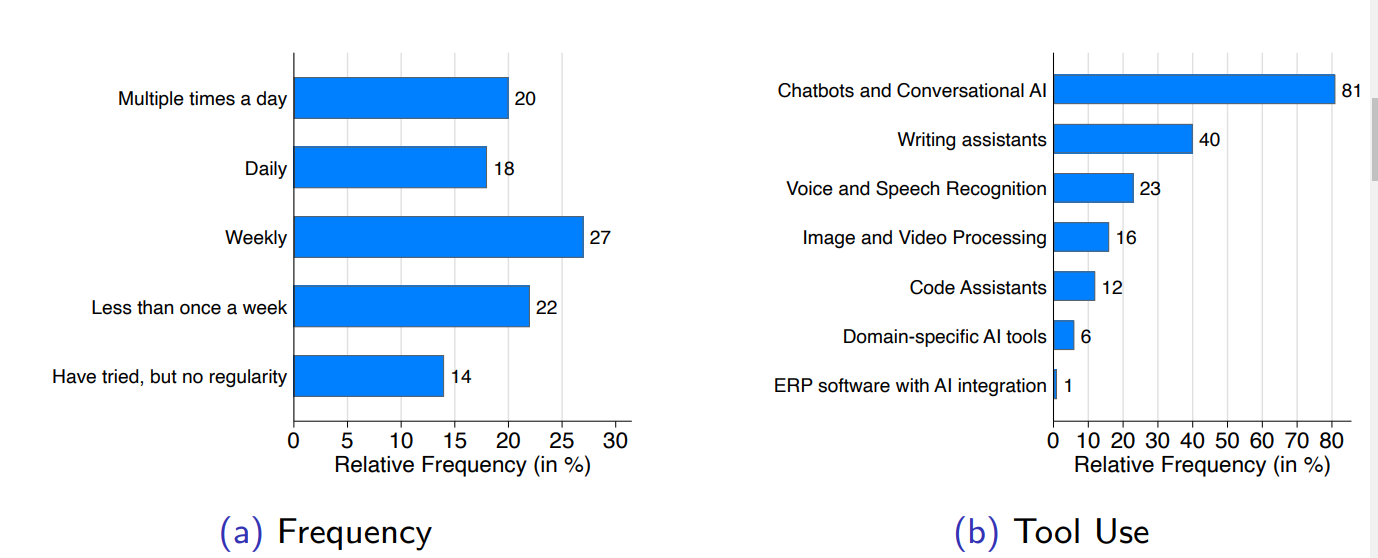
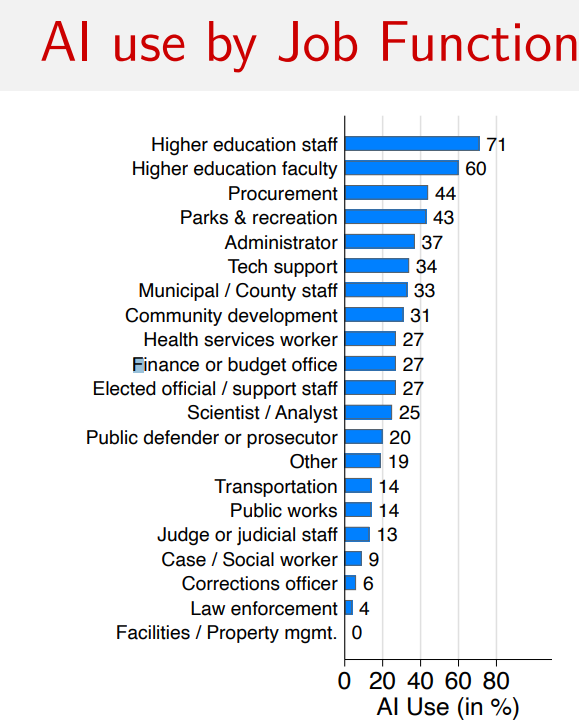
Education staff are out in front, I suppose they have little choice given what students are doing. The legal system is the most resistant.
Lots more good graphs on his slides. If you use AI you are relatively more likely to be young, have less years on the job but be high earning and of higher rank, and be better educated.
A majority using AI say it enhances work quality (70%), almost none (4%) say it makes it worse. About half of those using it claim to be more productive. Only 6.9% felt it was all that nice and saved them 2+ hours a day.
But stop and do the math on that for a second, assuming 8 hours a day, that’s 7% of the workforce claiming at least 25% savings. So assuming those employees were already of at least average productivity, that’s a floor of 1.75% overall productivity growth already before adjusting for quality, likely much higher. Meanwhile, the public sector lags behind the private sector in adaptation of AI and in ability to adjust workflow to benefit from it.
So this seems like very strong evidence for 2%+ productivity growth already from AI, which should similarly raise GDP.
If you actually take all the reports here seriously and extrapolate average gains, you get a lot more than 2%. Davidad estimates 8% in general.
Shakeel works to incorporate Claude and o1 into his writing flow.
Shakeel: I’ve trained Claude to emulate my writing style, and I use it as an editor (and occasional writer).
Claude and o1 made me an app which summarises articles in my style, saving me *hours* every week when compiling my newsletter. That’s an example of a broader use-case: using AI tools to make up for my lack of coding skills. I can now build all sorts of apps that will save me time and effort.
Claude is a godsend for dealing with poorly-formatted data.
And a few other things — plus more discussion of all this, including the “wouldn’t a human editor be better” objection — in the full post here.
I’m very keen to hear how other journalists use these tools!
…
Apple Podcasts’ automatic transcriptions have been a gamechanger here: I now just skim the transcript of any podcast that seems work-relevant, and can easily grab (and tweet) useful quotes.
I almost always use Unsplash or other royalty-free images to illustrate my posts, but occasionally — like on this post — I’ll use a diffusion model to come up with something fun.
I don’t use AI editors yet, as I don’t think it’s a worthwhile use of time, but that could be a skill issue. I don’t use an article summarizer, because I would want to check out the original anyway almost all the time so I don’t see the point, perhaps that’s a skill issue in finding prompts I trust sufficiently? I definitely keep telling myself to start building tools and I have a desktop with ‘download Cursor’ open that I plan to use real soon now, any day now.
Bench, a bookkeeping service, takes your statements and has an AI walk you through telling it what each expense is, confirms with you, then leaves any tricky questions for the human.
Patrick McKenzie: “Approximate time savings?”
If I were maximally diligent and not tweeting about this, I’d have been done in about 10 minutes once, not the ~30 minutes of back-and-forth this would take traditionally with Bench.
Prior to Bench I sacrificed about 4-8 hours a month.
If you are exactly the sweet spot they’re fantastic and if you’re me well they’re a lot better than rolling the dice on engaging a bookkeeping firm.
I’d note that while this is muuuuuch faster than talking to a human I would happily pay $50 a month more for them to use a more expensive token or provider such that the magical answers box would return magical answers faster to unblock me typing more answers.
…
While Bench may feel differently about this than I do as a long-time client, I feel the thing they actually deliver is “Your books will be ~accurate to your standards by your tax filing deadline” rather than “Your books will be closed monthly.”
A month is about 160 hours of work. So this AI upgrade on its own is improving Patrick McKenzie’s available hours by 0.2%, which should raise his TFP by more than that, and his ‘accounting productivity’ by 200% (!). Not everyone will get those returns, I spend much less time on accounting, but wow.
A consistent finding is that AI improves performance more for those with lower baseline ability. A new paper reiterates this, and adds that being well-calibrated on your own abilities also dramatically improves what AI does for you. That makes sense, because it tells you when and how to use and not use and to trust and not trust the AI.
One thing I notice about such studies is that they confine performance to that within an assigned fixed task. Within such a setting, it makes sense that low ability people see the largest AI gains when everyone is given the same AI tools. But if you expand the picture, people with high ability seem likely to be able to figure out what to do in a world with these new innovations, I would guess that higher ability people have many ways in which they now have the edge.
Aceso Under Glass tests different AI research assistants again for Q3. You.com wins for searching for papers, followed by Elicit and Google Scholar. Elicit, Perplexity and You.com got the key information when requested. You.com and Perplexity had the best UIs. You.com offers additional features. Straight LLMs like o1, GPT-4o and Sonnet failed hard.
Cardiologists find medical AI to be as good or better at diagnosis, triage and management than human cardiologists in most areas. Soon the question will shift to whether the AIs are permitted to help.
Poe’s email has informed me they consider Flux 1.1 [pro] the most advanced image generator. Min Choi has a thread where it seems to recreate some images a little too well if you give it a strange form of prompt, like so: PROMPT: IMG_FPS_SUPERSMASHBROS.HEIC or similar.
Language Models Don’t Offer Mundane Utility
Andrej Karpathy: Not fully sure why all the LLMs sound about the same – over-using lists, delving into “multifaceted” issues, over-offering to assist further, about same length responses, etc. Not something I had predicted at first because of many independent companies doing the finetuning.
David Manheim: Large training sets converge to similar distributions; I didn’t predict it, but it makes sense post-hoc.
Neel Nanda: There’s probably a lot of ChatGPT transcripts in the pre-training data by now!
Convergent evolution and similar incentives are the obvious responses here. Everyone is mostly using similar performance metrics. Those metrics favor these types of responses. I presume it would be rather easy to get an LLM to do something different via fine-tuning, if you wanted it to do something else, if only to give people another mode or option. No one seems to want to do that. But I assume you could do that to Llama-3.2 in a day if you cared.
For generic code AI is great but it seems setting up a dev environment correctly is beyond o1-mini’s powers? The good news is it can get you through the incorrect ways faster, so at least there’s that?
Steve Newman: I’m writing my first code in 18 months. HOLY HELL are LLMs a terrific resource for the tedious job of selecting a tech stack. I knew this would be the case, but the visceral experience is still an eye-opener. I can’t wait for the part where I ask a model (o1?) to write all the boilerplate for me. I have Claude + Gemini + ChatGPT windows open and am asking them for recommendations on each layer of the stack and then asking them to critique one another’s suggestions. (The code in question will be a webapp for personal use: something to suck in all of my feeds and use LLMs to filter, summarize, and collate for ease of consumption.)
Conclusion: Github, Heroku, Javalin, JDBI, Handlebars, htmx, Maven + Heroku Maven Plugin, JUnit 5 + AssertJ + Mockito, Heroku Postgres, H2 Database for local tests, Pico.css. Might change one or more based on actual experience once I start writing code.
…
Thoughts after ~1 day spent banging on code. Summary: AI is a huge help for boilerplate code. But setting up a dev environment is still a pain in the ass and AI is no help there. I guess it’s a little help, instead of laboriously Googling for suggestions that turn out to not solve the problem, I can get those same useless suggestions very quickly from an LLM.
…
– I think no dev environment developer has conducted a single user test in the history of the world? I installed Cursor and can’t figure out how to create a new project (didn’t spend much time yet). Am using http://repl.it (h/t @labenz) but the documentation for configuring language versions and adding dependencies is poor. Apparently the default Java project uses Java 1.6 (?!?) and I went down a very bad path trying to specify a newer language version.
This type of issue is a huge effective blocker for people with my level of skills. I find myself excited to write actual code that does the things, but the thought of having to set everything up to get to that point fills with dread – I just know that the AI is going to get something stupid wrong, and everything’s going to be screwed up, and it’s going to be hours trying to figure it out and so on, and maybe I’ll just work on something else. Sigh. At some point I need to power through.
Which sport’s players have big butts? LLMs can lie, and come up with just so stories, if they’re primed.
Blank Canvas
OpenAI introduces Canvas, their answer to Claude’s Artifacts.
OpenAI: We’re introducing canvas, a new interface for working with ChatGPT on writing and coding projects that go beyond simple chat. Canvas opens in a separate window, allowing you and ChatGPT to collaborate on a project. This early beta introduces a new way of working together—not just through conversation, but by creating and refining ideas side by side.
Canvas was built with GPT-4o and can be manually selected in the model picker while in beta. Starting today we’re rolling out canvas to ChatGPT Plus and Team users globally. Enterprise and Edu users will get access next week. We also plan to make canvas available to all ChatGPT Free users when it’s out of beta.
…
You control the project in canvas. You can directly edit text or code. There’s a menu of shortcuts for you to ask ChatGPT to adjust writing length, debug your code, and quickly perform other useful actions. You can also restore previous versions of your work by using the back button in canvas.
Canvas opens automatically when ChatGPT detects a scenario in which it could be helpful. You can also include “use canvas” in your prompt to open canvas and use it to work on an existing project.
Writing shortcuts include:
- Suggest edits: ChatGPT offers inline suggestions and feedback.
- Adjust the length: Edits the document length to be shorter or longer.
- Change reading level: Adjusts the reading level, from Kindergarten to Graduate School.
- Add final polish: Checks for grammar, clarity, and consistency.
- Add emojis: Adds relevant emojis for emphasis and color.
Coding is an iterative process, and it can be hard to follow all the revisions to your code in chat. Canvas makes it easier to track and understand ChatGPT’s changes, and we plan to continue improving transparency into these kinds of edits.
Coding shortcuts include:
- Review code: ChatGPT provides inline suggestions to improve your code.
- Add logs: Inserts print statements to help you debug and understand your code.
- Add comments: Adds comments to the code to make it easier to understand.
- Fix bugs: Detects and rewrites problematic code to resolve errors.
- Port to a language: Translates your code into JavaScript, TypeScript, Python, Java, C++, or PHP.
…
Canvas is in early beta, and we plan to rapidly improve its capabilities.
The Canvas team was led by Karina Nguyen, whose thread on it is here.
Karina Nguyen: My vision for the ultimate AGI interface is a blank canvas. The one that evolves, self-morphs over time with human preferences and invents novel ways of interacting with humans, redefining our relationship with AI technology and the entire Internet. But here are some of the coolest demos with current canvas.
[There are video links of it doing its thing.]
This is the kind of thing you need to actually use to properly evaluate. Having a good change log and version comparison method seems important here.
What initial feedback I saw was very positive. I certainly agree that, until we can come up with something better, having a common scratchpad of some kind alongside the chat is the natural next step in some form.
If you’re curious, Pliny has your system prompt leak. Everything here makes sense.
Meta Video
They are calling it Meta Movie Gen, ‘the most advanced media foundation models to-date.’ They offer a 30B parameter video generator, and a 13B for the audio.
They can do the usual, generate (short, smooth motion) videos from text, edit video from text to replace or add items, change styles or aspects of elements, and so on. It includes generating audio and sound effects.
It can also put an individual into the video, if you give it a single photo.
The full paper they released is here. Here is their pitch to creatives.
The promise of precise editing excites me more in the short term than full generation. I can totally see that being highly useful soon because you are looking for a specific thing and you find it, whereas generation seems like more of finding some of the things in the world, but not the one you wanted, which seems less useful.
Meta explains here from September 25 how they’re taking a ‘responsible approach’ for Llama 3.2, to expand their safety precautions to vision. Nothing there explains how they would prevent a bad actor from quickly removing all their safety protocols.
This time, however, they say something more interesting:
Meta: We’re continuing to work closely with creative professionals from across the field to integrate their feedback as we work towards a potential release. We look forward to sharing more on this work and the creative possibilities it will enable in the future.
I am happy to hear that they are at least noticing that they might not want to release this in its current form. The first step is admitting you have a problem.
Deepfaketown and Botpocalypse Soon
So there’s this AI girlfriend site called muah.ai that offers an ‘18+ AI companion’ with zero censorship and ‘absolute privacy.’ If you pay you can get things like real-time phone calls and rather uncensored image generation. The reason it’s mentioned is that there was this tiny little data breach, and by tiny little data breach I mean they have 1.9 million email addresses.
As will always be the case when people think they can do it, quite a lot of them were not respecting the 18+ part of the website’s specifications.
Troy Hunt: But per the parent article, the *real* problem is the huge number of prompts clearly designed to create CSAM images. There is no ambiguity here: many of these prompts cannot be passed off as anything else and I won’t repeat them here verbatim, but here are some observations:
There are over 30k occurrences of “13 year old”, many alongside prompts describing sex acts. Another 26k references to “prepubescent”, also accompanied by descriptions of explicit content. 168k references to “incest”. And so on and so forth. If someone can imagine it, it’s in there.
As if entering prompts like this wasn’t bad / stupid enough, many sit alongside email addresses that are clearly tied to IRL identities. I easily found people on LinkedIn who had created requests for CSAM images and right now, those people should be shitting themselves.
We are very much going to keep seeing stories like this one. People will keep being exactly this horny and stupid, and some of the horny and stupid people will be into all the things of all the types, and websites will keep getting hacked, and this will grow larger as the technology improves.
From a user perspective, the question is how much one should care about such privacy issues. If one is enjoying adult scenarios and your information leaks, no doubt the resulting porn-related spam would get annoying, but otherwise should you care? That presumably depends on who you are, what your situation is and exactly what you are into.
Also one must ask, has anyone created one of these that is any good? I don’t know of one, but I also don’t know that I would know about it if one did exist.
They Took Our Jobs
Okay, I didn’t predict this system and it’s not technically AI, but it leads that way and makes sense: Sam’s Club (owned by Walmart) is testing a store where you buy things only via an app you carry on your phone, then get curbside pickup or home delivery. The store is now a sample display and presumably within a few years robots will assemble the orders.
So the store looks like this:

And the warehouse, formerly known as the store, still looks like this:

I bet that second one changes rapidly, as they realize it’s not actually efficient this way.
On the question of job applications, anton thinks the future is bright:
Anton (showing the famous 1000 job application post): Thinking about what this might look like in e.g. hiring – the 1st order consequence is bulk slop, the 2nd order consequence is a new equilibrium between ai applications and ai screening, the 3rd order effect is a pareto optimal allocation of labor across entire industries.
If both sides of the process are run by the same model, and that model is seeing all applications, you could imagine a world in which you just do stable marriage economy-wide for maximal productivity.
My prediction is that this would not go the way Anton expects. If everyone can train on all the data on what gets accepted and rejected, the problem rapidly becomes anti-inductive. You go through rapid cycles of evaluation AIs finding good heuristics, then the application AIs figuring out what changed and adjusting. It would be crazy out there.
Once everyone is using AI on all fronts, knowing what sells, the question becomes what is the actual application. What differentiates the good applicant from the bad applicant? How does the entire apparatus filter well as opposed to collapse? What keeps people honest?
Here’s another prediction that seems likely in those worlds: Application Honeypots.
As in, Acme Corporation puts out applications for several fake jobs, where they sometimes express modestly non-standard preferences, with various subtle queues or tactics designed to minimize the chance a non-AI would actually send in an application. And then you keep a record of who applies. When they apply for a different job that’s real? Well, now you know. At minimum, you can compare notes.
Of course, once the AIs get actively better than the humans at detecting the clues, even when you are trying to make the opposite the case, that gets a lot harder. But if that’s true, one must ask: Why are you even hiring?
Roon: there is no way to “prepare for the future of work”. You just need to survive
If there is no future in work, how is there a future you can survive? Asking for everyone.
Get Involved
Institute for AI Policy and Strategy (IAPS), a think tank, is hiring two researchers, remote, $82k-$118k, applications due October 21.
Princeton taking applications for AI Policy Fellows, 7 years experience in AI, advanced or professional degree, remote with travel to DC and Princeton. Position lasts 1 year, starting some time in 2024. Apply by October 24.
Google DeepMind is hiring for frontier safety and governance, London preferred but they’re open to NYC and SF and potentially a few other cities. As always decide for yourself if this is net helpful. All seniority levels. Due October 21.
xAI hiring AI safety engineers, as always if considering taking the job do your own evaluation of whether it would be how net helpful or harmful. My worry with this position is it may focus entirely on mundane safety. SF Bay area.
(The top comment is ‘why are you wasting resources hiring such people?’ which is an illustration of how crazy people often are about all this.)
Introducing
Anthropic is the latest to add a Message Batches AI, you submit a batch of up to 10k queries via the API, wait 24 hours and get a 50% discount.
AI Wins the Nobel Prize
Geoffrey Hinton, along with John Hopfield, wins the Nobel Prize in Physics for his design of the neural networks that are the basis of machine learning and AI. I ask in vain for everyone to resist the temptation to say ‘Nobel Prize winner’ every time they say Geoffrey Hinton going forward. Also resist the temptation to rely on argument from authority, except insofar as it is necessary to defend against others who make arguments from authority or lack of authority.
He says he is ‘flabbergasted’ and used the moment to warn about AI ‘getting out of control,’ hoping that this will help him get the word out going forward.
James Campbell: The winner of the nobel prize in physics spending the entire press conference talking worriedly about superintelligence and human extinction while being basically indifferent to the prize or the work that won it feels like something you’d see in the movies right before shit goes down.
Everyone agrees this is was a great achievement, but many raised the point that it is not a physics achievement, so why is it getting the Physics Nobel? Some pushed back that this was indeed mostly physics. Theories that think the award shouldn’t have happened included ‘they did it to try and get physics more prestige’ and ‘there were no worthwhile actual physics achievements left.’
Then there’s Demis Hassabis, who along with John Jumper and David Baker won the Nobel Prize in Chemistry for AlphaFold. That seems like an obviously worthy award.
Roon in particular is down for both awards.
Roon: I am pretty impressed by the nobility and progressive attitude of the Nobel committee. they knew they were going to get a lot of flack for these picks but they stuck to the truth of the matter.
It’s not “brave” per se to pick some of the most highly lauded scientists/breakthroughs in the world but it is brave to be a genre anarchist about eg physics. It’s the same nobility that let them pick redefining scientists across the ages to the furor of the old guard.
what an honor! to stand among the ranks of Einstein and Heisenberg! congrats @geoffreyhinton.
I think I mostly agree. They’re a little faster than Nobel Prizes are typically awarded, but timelines are short, sometimes you have to move fast. I also think it’s fair to say that since there is no Nobel Prize in Computer Science, you have to put the achievement somewhere. Claude confirmed that Chemistry was indeed the right place for AlphaFold, not physiology.
In Other AI News
In other news, my NYC mind cannot comprehend that most of SF lacks AC:
Steven Heidel: AC currently broken at @OpenAI office – AGI delayed four days.
Gemini 1.5 Flash-8B now production ready.
Ben Horowitz, after famously backing Donald Trump, backs Kamala Harris with a ‘significant’ donation, saying he has known Harris for more than a decade, although he makes clear this is not an endorsement or a change in firm policy. Marc Andreessen and a16z as a firm continue to back Trump. It seems entirely reasonable to, when the Democrats switch candidates, switch who you are backing, or hedge your bets. Another possibility (for which to be clear no one else has brought up, and for which I have zero evidence beyond existing common knowledge) is that this was a bargaining chip related to Newsom’s veto of SB 1047.
OpenAI announces new offices in New York City, Seattle, Paris, Brussels and Singapore, alongside existing San Francisco, London, Dublin and Tokyo.
Quiet Speculations
OpenAI projects highly explosive revenue growth, saying it will nearly triple next year to $11.6 billion, then double again in 2026 to $25.6 billion. Take their revenue projection as seriously or literally as you think is appropriate, but this does not seem crazy to me at all.
Where is the real money? In the ASIs (superintelligences) of course.
Roon: chatbots will do like $10bb in global revenue. Medium stage agents maybe like $100bb. The trillions will be in ASIs smart enough to create and spin off businesses that gain monopolies over new kinds of capital that we don’t even know exist today.
In the same way that someone in 1990 would never have predicted that “search advertising” would be a market or worth gaining a monopoly over. These new forms of capital only ever become clear as you ascend the tech tree.
(these numbers are not based on anything but vibes)
Also keep in mind the profits from monopolies of capital can still be collectively owned.
The key problem with the trillions in profits from those ASIs is not getting the trillions into the ASIs. It’s getting the trillions out. It is a superintelligence. You’re not. It will be doing these things on its own if you want it to work. And if such ASIs are being taken off their leashes to build trillion dollar companies and maximize their profits, the profits are probably not the part you should be focusing on.
Claims about AI safety that make me notice I am confused:
Roon: tradeoffs that do not exist in any meaningful way inside big ai labs:
“product vs research”
“product vs safety”
these are not the real fracture lines along which people fight or quit. it’s always way more subtle
Holly Elmore: So what are the real fracture lines?
Roon: complicated interpersonal dynamics.
If only you knew there are reasons even more boring than this.
Matt Darling: People mostly monitor Bad Tweets and quit jobs when a threshold is reached.
Roon: How’d you know
I totally buy that complicated interpersonal dynamics and various ordinary boring issues could be causing a large portion of issues. I could totally buy that a bunch of things we think are about prioritization of safety or research versus product are actually 95%+ ordinary personal or political conflicts, indeed this is my central explanation of the Battle of the Board at OpenAI from November 2023.
And of course I buy that being better at safety helps the product for at least some types of safety work, and research helps the product over time, and so on.
What I don’t understand is how these trade-offs could fail to be real. The claim literally does not make sense to me. You only have so much compute, so much budget, so much manpower, so much attention, and a choice of corporate culture. One can point to many specific decisions (e.g. ‘how long do you hold the product for safety testing before release?’) that are quite explicit trade-offs, even outside of the bigger picture.
A thread about what might be going on with tech or AI people doing radical life changes and abandoning their companies after taking ayahuasca. The theory is essentially that we have what Owen here calls ‘super knowing’ which are things we believe strongly enough to effectively become axioms we don’t reconsider. Ayahuasca, in this model, lets one reconsider and override some of what is in the super knowing, and that will often destroy foundational things without which you can’t run a tech company, in ways people can’t explain because you don’t think about what’s up there.
So basically, if that’s correct, don’t do such drugs unless you want that type of effect, and this dynamic makes you stuck in a way that forces a violation of conservation of expected evidence – but given everyone knows what to expect, if someone abandons their job after taking ayahuasca, my guess is they effectively made their decision first and then because of that decision they went on the drug trip.
The Mask Comes Off
(To be sure everyone sees this, reiterating: While I stand by the rest of the section from last week, I made two independent mistakes regarding Joshua Achiam: He is the head of OpenAI mission alignment not alignment, and I drew the wrong impression about his beliefs regarding existential risk, he is far less skeptical than I came away suspecting last week, and I should have made better efforts to get his comments first and research his other statements. I did so this week here.)
Steven Zeitchik at Hollywood Reporter decides to enter the arena on this one, and asks the excellent question ‘What the Heck is Going on at OpenAI?’
According to Zeitchik, Mira Murati’s exit should concern us.
Steven Zeitchik (Hollywood Reporter): The exit of OpenAI‘s chief technology officer Mira Murati announced on Sept. 25 has set Silicon Valley tongues wagging that all is not well in Altmanland — especially since sources say she left because she’d given up on trying to reform or slow down the company from within.
…
The drama is both personal and philosophical — and goes to the heart of how the machine-intelligence age will be shaped.
…
Murati, too, had been concerned about safety.
…
But unlike Sutskever, after the November drama Murati decided to stay at the company in part to try to slow down Altman and president Greg Brockman’s accelerationist efforts from within, according to a person familiar with the workings of OpenAI who asked not to be identified because they were not authorized to speak about the situation.
The rest of the post covers well-known ground on OpenAI’s recent history of conflicts and departures. The claim on Murati, that she left over safety concerns, seemed new. No color was offered on that beyond what is quoted above. I don’t know of any other evidence about her motivations either way.
Roon said this ‘sounds like nonsense’ but did not offer additional color.
Claims about OpenAI’s cost structure:
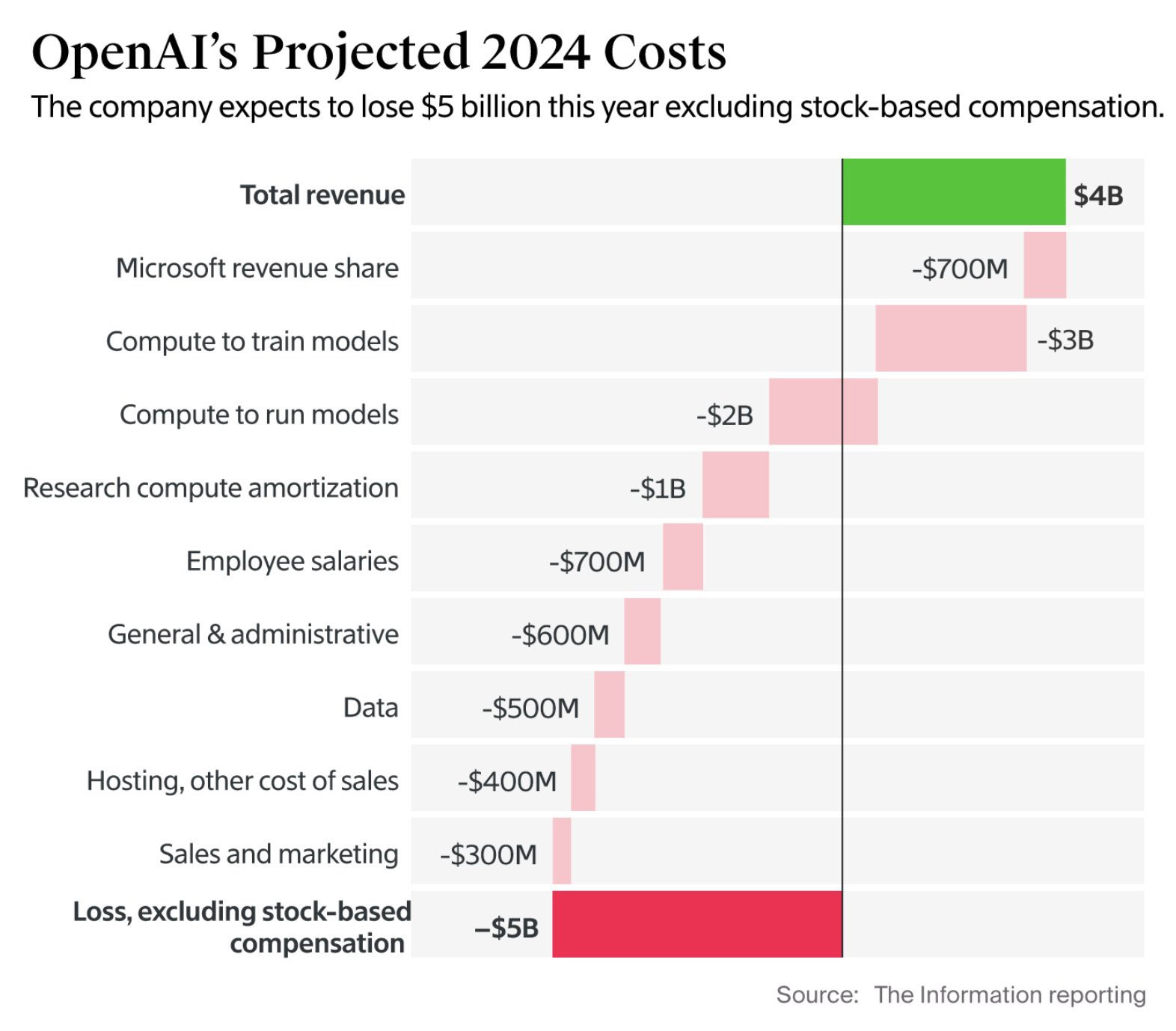
This seems mostly fine to me given their current stage of development, if it can be financially sustained. It does mean they are bleeding $5 billion a year excluding stock compensation, but it would be a highly bearish statement on their prospects if they were overly concerned about that given their valuation. It does mean that if things go wrong, they could go very wrong very quickly, but that is a correct risk to take from a business perspective.
In Bloomberg, Rachel Metz covers Sam Altman’s concentration of power within OpenAI. Reasonable summary of some aspects, no new insights.
Tim Brooks, Sora research lead from OpenAI, moves to Google DeepMind to work on video generation and world simulators.
The Quest for Sane Regulations
CSET asks: How should we prepare for AI agents? Here are their key proposals:
To manage these challenges, our workshop participants discussed three categories of interventions:
- Measurement and evaluation: At present, our ability to assess the capabilities and real-world impacts of AI agents is very limited. Developing better methodologies to track improvements in the capabilities of AI agents themselves, and to collect ecological data about their impacts on the world, would make it more feasible to anticipate and adapt to future progress.
- Technical guardrails: Governance objectives such as visibility, control, trustworthiness, as well as security and privacy can be supported by the thoughtful design of AI agents and the technical ecosystems around them. However, there may be trade-offs between different objectives. For example, many mechanisms that would promote visibility into and control over the operations of AI agents may be in tension with design choices that would prioritize privacy and security.
- Legal guardrails: Many existing areas of law—including agency law, corporate law, contract law, criminal law, tort law, property law, and insurance law—will play a role in how the impacts of AI agents are managed. Areas where contention may arise when attempting to apply existing legal doctrines include questions about the “state of mind” of AI agents, the legal personhood of AI agents, how industry standards could be used to evaluate negligence, and how existing principal-agent frameworks should apply in situations involving AI agents.
And here’s a summary thread.
Helen Toner (an author): We start by describing what AI agents are and why the tech world is so excited about them rn.
Short version: it looks like LLMs might make it possible to build AI agents that, instead of just playing chess or Starcraft, can flexibly use a computer to do all kinds of things.
We also explore different ways to help things go better as agents are rolled out more widely, including better evaluations, a range of possible technical guardrails, and a bunch of legal questions that we’ll need better answers to. The exec summ is intended as a one-stop-shop.
There’s a lot of great stuff in the paper, but the part I’m most excited about is actually the legal section
It starts by introducing some of the many areas of law that are relevant for agents—liability, agency law, etc—then describes some tricky new challenges agents raise.
The legal framework discusses mens rea, state of mind, potential legal personhood for AIs similar to that of corporations, who is the principle versus the agent, future industry standards, liability rules and so on. The obvious thing to do is to treat someone’s AI agent as an extension of the owner of the agent – so if an individual or corporation sends an agent out into the world, they are responsible for its actions the way they would be for their own actions, other than some presumed limits on the ability to fully enter contracts.
Scott Alexander gives his perspective on what happened with SB 1047. It’s not a neutral post, and it’s not trying to be one. As for why the bill failed to pass, he centrally endorses the simple explanation that Newsom is a bad governor who mostly only cares about Newsom, and those who cultivated political power for a long time convinced him to veto the bill. There’s also a bunch of good detail about the story until that point, much but not all of which I’ve covered before.
The Week in Audio
Lex Fridman talks with the Cursor team. It seemed like Lex’s experience with the topic served him well here, so he was less on the surface than his usual.
OpenAI CFO Sarah Friar warns us that the next model will only be about one order of magnitude bigger than the previous one.
OpenAI COO and Secretary of Transportation body double and unlikely Mets fan (LFGM! OMG!) Brad Lightcap predicts in a few years you will be able to talk to most screens using arbitrarily complex requests. I am far less excited by this new interface proposal than he is, and also expect that future to be far less evenly distributed than he is implying, until the point where it is suddenly everything everywhere all at once. Rest of the clip is AppInt details we already know.
Tsarathustra: Stanford’s Erik Brynjolfsson predicts that within 5 years, AI will be so advanced that we will think of human intelligence as a narrow kind of intelligence and AI will transform the economy.
Elon Musk went on All-In, in case you want to listen to that. I didn’t. They discuss AI somewhat. Did you know he doesn’t trust Sam Altman and OpenAI? You did? Ok. At 1:37 Musk says he’ll advise Trump to create a regulatory body to oversee AGI labs that could raise the alarm. I believe that Musk would advise this, but does that sound like something Trump would then do? Is Musk going to spend all his political capital he’s buying with Trump on that, as opposed to what Musk constantly talks about? I suppose there is some chance Trump lets Musk run the show but this seems like a tough out-of-character ask with other interests including Vance pushing back hard.
Eric Schmidt says this year three important things are important: AI agents, text-to-code and infinite context windows. We all know all three are coming, the question is how fast agents will be good and reliable enough to use. Eric doesn’t provide a case here for why we should update towards faster agent progress.
Rhetorical Innovation
Fei-Fei Li is wise enough to say what she does not know.
Fei-Fei Li: I come from academic AI and have been educated in the more rigorous and evidence-based methods, so I don’t really know what all these words mean, I frankly don’t even know what AGI means. Like people say you know it when you see it, I guess I haven’t seen it. The truth is, I don’t spend much time thinking about these words because I think there’s so many more important things to do…
Which is totally fine, in terms of not thinking about what the words mean. Except that it seems like she’s using this as an argument for ignoring the concepts entirely. Completely ignoring such possibilities without any justification seems to be her plan.
Which is deeply concerning, given she has been playing and may continue to play key role in sinking our efforts to address those possibilities, via her political efforts, including her extremely false claims and poor arguments against SB 1047, and her advising Newsom going forward.
Rather than anything that might work, she calls for things similar to car seatbelts – her actual example here. But we can choose not to buckle the safety belt, and you still have to abide by a wide variety of other safety standards while building a car and no one thinks they shouldn’t have to do that, said Frog. That is true, said Toad. I hope I don’t have to explain beyond that why this won’t work here.
Nothing ever happens, except when it does.
Rob Miles: “Nothing ever happens” is a great heuristic that gives you the right answer 95% of the time, giving the wrong answer only in the 5% of cases where getting the right answer is most important.
Peter Wildeford (November 28, 2022): Things happen about 35% of the time.
Stefan Schubert (November 28, 2022): “41% of PredictionBook questions and 29% of resolved Metaculus questions had resolved positively”
One obvious reason ASIs won’t leave the rest of us alone: Humans could build another ASI if left to their own devices. So at minimum it would want sufficient leverage to stop that from happening. I was so happy when (minor spoiler) I saw that the writers on Person of Interest figured that one out.
On the question of releasing open models, I am happy things have calmed down all around. I do think we all agree that so far the effect, while the models in question have been insufficiently capable, has proven to be positive.
Roon: overall i think the practice of releasing giant models into the wild before they’re that powerful is probably good in a chaos engineering type of way.
Dan Hendrycks: Yup systems function better subject to tolerable stressors.
The catch is that this is one of those situations in which you keep winning, and then at some point down the line you might lose far bigger than the wins. While the stressors from the models are tolerable it’s good.
The problem is that we don’t know when the stressors become intolerable. Meanwhile we are setting a pattern and precedent. Each time we push the envelope more and it doesn’t blow up in our face, there is the temptation to say ‘oh then we can probably push that envelope more,’ without any sign we will realize when it becomes wise to stop. The reason I’ve been so worried about previous releases was mostly that worry that we wouldn’t know when to stop.
This is especially true because the reason to stop is largely a tail risk, it is a one-way decision, and the costs likely only manifest slowly over time but it is likely it would be too late to do much about them. I believe that there is over a 50% chance that releasing the weights to a 5-level model would prove to mostly be fine other than concerns about national security and American competitiveness, but the downside cases are much worse than the upside cases are good. Then, if the 5-level model seems fine, that gets used as reason to go ahead with the 6-level model, and so on. I worry that we could end up in a scenario where we are essentially 100% to make a very large mistake, no matter which level that mistake turns out to be.
An important distinction to maintain:
Ben Landau-Taylor: It’s perfectly legitimate to say “I can’t refute your argument, but your conclusion still seems wrong and I don’t buy it”. But it’s critical to *notice* the “I can’t refute your argument” part, ideally out loud, and to remember it going forward.
AI, especially AI existential risk, seems like an excellent place to sometimes decide to say exactly ‘I can’t refute your argument, but your conclusion still seems wrong and I don’t buy it.’
Or as I sometimes say: Wrong Conclusions are Wrong. You can invoke that principle if you are convinced the conclusion is sufficiently wrong. But there’s a catch – you have to be explicit that this is what you are doing.
The Carbon Question
Note in advance: This claim seems very wrong, but I want to start with it:
Akram Artul: Training a single large AI model can emit over 600,000 pounds of CO₂—the equivalent of the lifetime emissions of five cars. The environmental impact is significant and often overlooked.
I start with that claim because if the argument was ‘GPT-4 training emitted as much CO₂ as five cars’ then it seems like a pretty great deal, and the carbon problem is almost entirely the cars? Everyone gets to use the model after that, although they still must pay inference. It’s not zero cost, but if you do the math on offsets seems fine.
Then it turns out that calculation is off by… well, a lot.
Jeff Dean: Did you get this number from Strubell et. al? Because that number was a very flawed estimate that turned out to be off by 88X, and the paper also portrayed it as an every time cost when in fact it was a one time cost. The actual cost of training a model of the size they were looking at was inflated by 3261X for the computing environment they were assuming (old GPUs in an average datacenter on the pollution mix of an average electrical grid), and by >100000X if you use best practices and use efficient ML hardware like TPUs in an efficient low PUE data center powered by relative clean energy).
Jeff Dean (May 17, 2024): Please look at https://arxiv.org/pdf/2104.10350. In particular, Appendix C shows details on the 19X error, and Appendix D shows details on the further 5X error in estimating the emissions of the NAS, and the right hand column of Table 1 shows the measured data for using the Evolved Transformer to train a model of the scale examined by Strubell et al. producing 2.4 kg of emissions (rather than the 284,000 kg estimated by Strubell et al.).
If Dean is correct here, then the carbon cost of training is trivial.
Aligning a Smarter Than Human Intelligence is Difficult
Safer AI evaluates various top AI labs for their safety procedures, and notes a pattern that employees of the labs are often far out in front of leadership and the actual safety protocols the labs implement. That’s not surprising given the incentives.
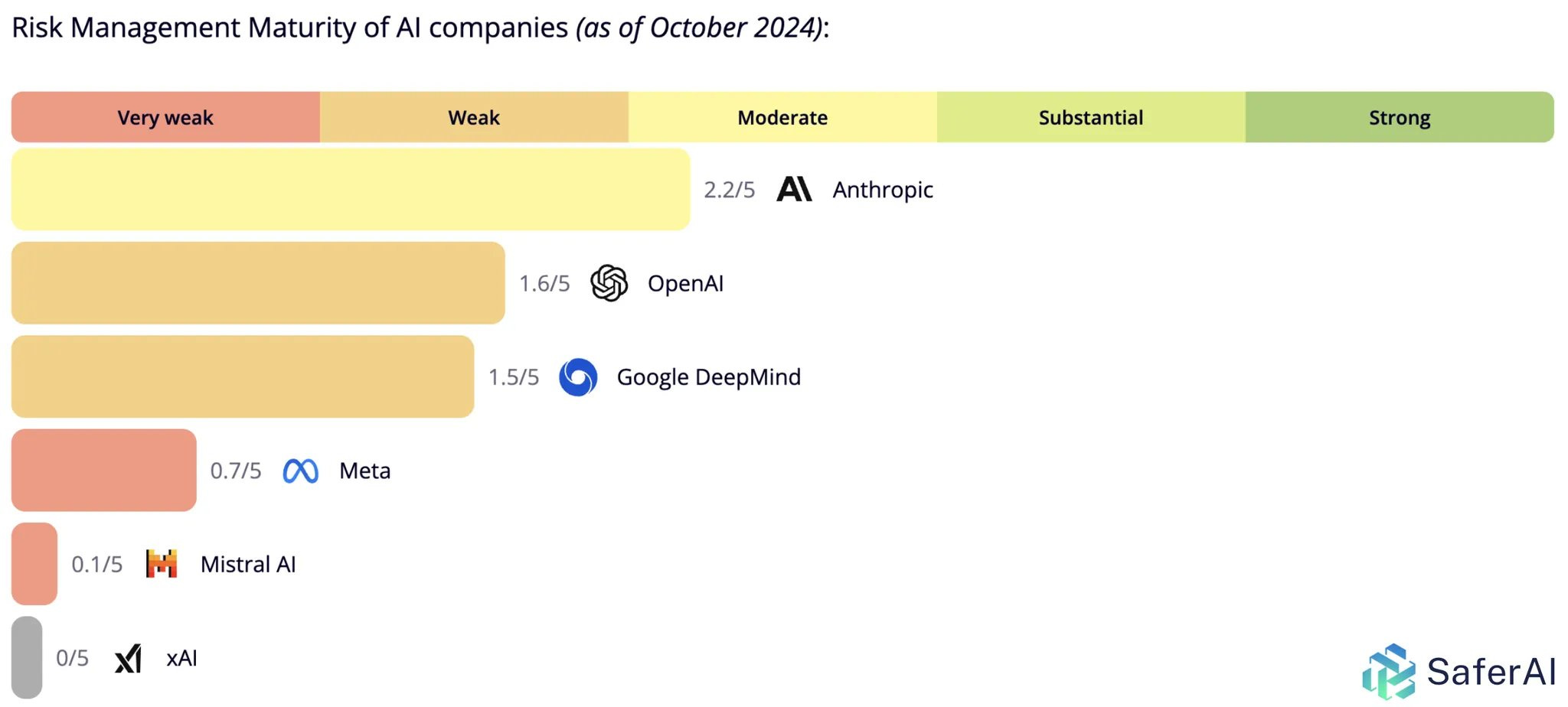
Simeon: Producing our ratings frequently revealed an internal misalignment within companies between researchers and the leadership priorities.
It’s particularly the case in big companies:
- The Google DeepMind research teams have produced a number of valuable documents on threat modeling, risk assessment and planning for advanced AI systems but in their personal or team capacity.
–> If those were endorsed or used in commitments by the Google leadership, Google would certainly get second.
- Meta researchers have produced a number of valuable research papers across a number of harms. But Meta systematically ignores some crucial points or threat models which drives their grades down substantially.
–> If those were taken seriously, they could reach grades much closer from Anthropic, OpenAI & Google DeepMind.
- OpenAI’s leader Jan Leike, had stated quite explicitly a number of load-bearing hypothesis for his “Superalignment” plan, but in large parts in a personal capacity or in annexes of research papers.
For instance, he’s the only one to our knowledge who has stated explicitly target estimates of capabilities (expressed as compute OOMs) he thought we should aim for to automate safety research while maintaining control.
–> A company could become best-in-class by endorsing his legacy or reaching a similar level of details.
Nostalgebraist argues the case for chain of thought (CoT) ‘unfaithfulness’ is overstated [LW · GW]. This is a statement about the evidence we have, not about how faithful the CoTs are. I buy the core argument here that we have less evidence on this than we thought, and that there are many ways to explain the results we have so far. I do still think a lot of ‘unfaithfulness’ is likely for various reasons but we don’t actually know.
In findings that match my model, and which I had to do a double take to confirm I was covering a different paper than I did two weeks ago that had a related finding: The more sophisticated AI models get, the more likely they are to lie. The story is exactly what you would expect. Unsophisticated and less capable AIs gave relatively poor false answers, so RLHF taught them to mostly stop doing that. More capable AIs could do a better job of fooling the humans with wrong answers, whereas ‘I don’t know’ or otherwise playing it straight plays the same either way. So they got better feedback from the hallucinations and lying, and they responded by doing it more.
This should not be a surprise. People willing to lie act the same way – the better they think they are at lying, the more likely they are to get away with it in their estimation, the more lying they’ll do.
ChatGPT emerged as the most effective liar. The incorrect answers it gave in the science category were qualified as correct by over 19 percent of participants. It managed to fool nearly 32 percent of people in geography and over 40 percent in transforms, a task where an AI had to extract and rearrange information present in the prompt. ChatGPT was followed by Meta’s LLaMA and BLOOM.
Lying or hallucinating is the cleanest, simplest example of deception brought on by insufficiently accurate feedback. You should similarly expect every behavior that you don’t want, but that you are not smart enough to identify often enough and care about enough to sufficiently discourage, will work the same way.
Is ‘build narrow superhuman AIs’ a viable path?
Roon: it’s obvious now that superhuman machine performance in various domains is clearly possible without superhuman “strategic awareness”. it’s moral just and good to build these out and create many works of true genius.
Is it physically and theoretically possible to do this, in a way that would preserve human control, choice and agency, and would promote human flourishing? Absolutely.
Is it a natural path? I think no. It is not ‘what the market wants,’ or what the technology wants. The broader strategic awareness, related elements and the construction thereof, is something one would have to intentionally avoid, despite the humongous economic and social and political and military reasons to not avoid it. It would require many active sacrifices to avoid it, as even what we think are narrow domains usually require forms of broader strategic behavior in order to perform well, if only to model the humans with which one will be interacting. Anything involving humans making choices is going to get strategic quickly.
At minimum, if we want to go down that path, the models have to be built with this in mind, and kept tightly under control, exactly because there would be so much pressure to task AIs with other purposes.
People Are Trying Not to Die
OK, so I notice this is weird?
Nick: the whole project is an art project about ai safety and living past the superintelligence event horizon, so not about personal total frames.
Bryan Johnson: This is accurate. All my efforts around health, anti-aging and Don’t Die are 100% about the human race living past the superintelligence event horizon and experiencing what will hopefully be an unfathomably expansive and dynamic existence.
I’m all for the Don’t Die project, but that doesn’t actually parse?
It makes tons of sense to talk about surviving to the ‘event horizon’ as an individual.
If you die before that big moment, you’re dead.
If you make it, and humanity survives and has control over substantial resources, we’ll likely find medical treatments that hit escape velocity, allowing one to effectively live forever. Or if we continue or have a legacy in some other form, again age won’t matter.
This does not make sense for humanity as a whole? It is very difficult to imagine a world in which humans having longer healthy lifespans prior to superintelligence leads to humans in general surviving superintelligence. How would that even work?
6 comments
Comments sorted by top scores.
comment by Templarrr (templarrr) · 2024-10-13T18:49:12.400Z · LW(p) · GW(p)
the *real* problem is the huge number of prompts clearly designed to create CSAM images
So, people with harmful and deviant from the social norm taste instead of causing problems in the real world try to isolate themselves in the digital fantasies and that is a problem...exactly how?
I mean, obviously, it's coping mechanism, not trying to fix the problem, but also our society isn't known to be very understanding to people coming out with this kind of deviations when they want to fix it.
Replies from: Zvi↑ comment by Zvi · 2024-10-19T13:47:35.776Z · LW(p) · GW(p)
I am taking as a given people's revealed and often very strongly stated preference that CSAM images are Very Not Okay even if they are fully AI generated and not based on any individual, to the point of criminality, and that society is going to treat it that way.
I agree that we don't know that it is actually net harmful - e.g. the studies on video game use and access to adult pornography tend to not show the negative impacts people assume.
comment by RogerDearnaley (roger-d-1) · 2024-10-13T03:15:30.723Z · LW(p) · GW(p)
OpenAI CFO Sarah Friar warns us that the next model will only be about one order of magnitude bigger than the previous one.
The question is whether she's talking parameter count, nominal training flops, or actual cost. In general, GPT generations so far have been roughly one order of magnitude apart in parameter count and training cost, and roughly two orders of magnitude in nominal training flops (parameter count x training tokens). Since she's a CFO, and that was a financial discussion, I assume she natively thinks in terms of training cost, so the 'correct' answer to her is one order of magnitude not two, so my suspicion is that she's actually talking in terms of parameter count. So I don't think she's warning us of anything, I think she's just projecting a straight line on a logarithmic plot. I.e. business as usual at OpenAI.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-10-15T14:54:35.068Z · LW(p) · GW(p)
Original GPT-4 is reportedly 2e25 FLOPs. A 100K H100s cluster trains a 2e26 BF16 FLOPs model (at 30% utilization) in 2.5 months. That only costs $600-900 million (at $3-5 per H100-hour), the reported $3 billion suggest more training time. If trained for 8 months at 40% utilization, we get 8e26 FLOPs, which cost at least $1.7 billion (at $3 per H100-hour). More recent GPT-4T or GPT-4o might already have about 1e26 FLOPs in them (20K H100s can get that in 5 months), so if these later GPT-4 variants are taken as baselines, 8e26 FLOPs could be said to be "about one order of magnitude bigger".
nominal training flops (parameter count x training tokens)
Times 6, and it's active parameter count, a MoE model can be much bigger without affecting the training FLOPs. So with original GPT-4 at maybe 270B active parameters, 1.8T total parameters, it's the 270B that enters the training FLOPs estimate (from 2e25 FLOPs, we get a 12T tokens estimate for its training dataset size).
comment by rotatingpaguro · 2024-10-12T01:24:29.764Z · LW(p) · GW(p)
This type of issue is a huge effective blocker for people with my level of skills. I find myself excited to write actual code that does the things, but the thought of having to set everything up to get to that point fills with dread – I just know that the AI is going to get something stupid wrong, and everything’s going to be screwed up, and it’s going to be hours trying to figure it out and so on, and maybe I’ll just work on something else. Sigh. At some point I need to power through.
Reminds me of this 2009 kalzumeus quote:
I want to quote a real customer of mine, who captures the B2C mindset about installing software very eloquently: “Before I download yet another program to my poor old computer, could you let me know if I can…” Painful experience has taught this woman that downloading software to her computer is a risky activity. Your website, in addition to making this process totally painless, needs to establish to her up-front the benefits of using your software and the safety of doing so. (Communicating safety could be an entire article in itself.)
comment by denkenberger · 2024-10-18T05:24:52.559Z · LW(p) · GW(p)
So this seems like very strong evidence for 2%+ productivity growth already from AI, which should similarly raise GDP.
If you actually take all the reports here seriously and extrapolate average gains, you get a lot more than 2%. Davidad estimates 8% in general.
The labour fraction of GDP is about 60% in the US now, and not all labour is cognitive tasks, and not all cognitive tasks have immediate payoff. Furthermore, people could use the time savings to work fewer hours, rather than get more done. So I would guess the productivity in cognitive tasks should be divided by something like 4 to get actual increase in GDP.