A Survey of Foundational Methods in Inverse Reinforcement Learning
post by adamk · 2022-09-01T18:21:10.559Z · LW · GW · 0 commentsContents
Introduction MDP Overview The IRL Problem Maximum Margin Methods Bayesian Methods Maximum Entropy Methods Summary Conclusion None No comments
Introduction
Inverse Reinforcement Learning (IRL) is both the name of a problem and a broad class of methods that try to solve it. Whereas Reinforcement Learning (RL) asks “How should I act to achieve my goals?” IRL asks “Looking at an agent acting, what are its goals?”
The problem was originally posed by Stuart Russell in 1998, where he pointed to a few key motivations for wanting to solve IRL. First, humans and animals don't have directly visible reward functions; IRL may be able to reverse engineer the complex rewards of real-world actors. Second, it may be useful in apprenticeship learning, where an agent learns how to perform a task based on demonstration. Learning the demonstrator's reward can be a useful intermediate step. Third, there are often cases where agents or demonstrators weigh carefully between multiple attributes, striking a balance between speed, cost, etc. We may know these factors, but not their relative tradeoff weights. IRL is well-suited to solve for these.
Since Russell’s initial question, a broad class of IRL methods have appeared to tackle and extend the problem, and apply solutions. My goal in this post is to survey a few key methods and applications of IRL, considering the technical roadmap, strengths, and weaknesses of different approaches. I have elected to mostly discuss seminal early works for each method, as I am mostly interested in giving context for further study. My hope is that a broad, rather than deep, survey will be both more accessible and encourage readers to investigate areas of interest for themselves.
I’m assuming some familiarity with linear algebra and probability. I’ll briefly overview the mathematical setup of Markov Decision Processes, but I’ll mainly assume the reader is familiar with the basic ideas of reinforcement learning.
MDP Overview
A Markov Decision Process (MDP) is the normal formalization for the environment of a reinforcement learning agent. (The reference I would recommend is Barto and Sutton's Reinforcement Learning: An Introduction, Chapter 3. Wikipedia also works.) An MDP consists of:
- A set of states (usually finite, but we can extend to infinite state spaces)
- A set of actions available to the agent (some formulations make the set of available actions dependent on state, but most IRL papers do not consider this generalization)
- A set of transition probability functions that tell the system how to update the state based on the current state and the action taken. The Markov Property is usually assumed, meaning that the current state and action alone determine state transition. There is varying notation: one might see or or —all of them refer to the probability of transitioning to state given the agent took action in state
- is the discount factor, basically parametrizing how much the agent prefers short-term versus long-term reward
- A function representing the rewards the agent receives based on its state. The assumed type signature of this function varies—sometimes the state alone determines how much reward is received, and sometimes both the state and the chosen action are used. The IRL literature prefers reward functions based on state alone since "IRL problems typically have limited information about the value of action and we want to avoid overfitting" (Ramachandran and Amir 2007)
- Sometimes we are given a distribution over states, , from which the initial state of the MDP is sampled
The IRL Problem
In the formal statement of an IRL problem, we are given the entire dynamics of the MDP except the reward function—MDP\R. We’re also given the policy of an “expert,” and we’re told that this policy is optimal for the unseen reward function. Alternatively, we might be given empirical trajectories of state-action pairs , which follow the unseen policy. (This is akin to empirically observing the behavior of the expert). We, the "learner," are then supposed to reverse-engineer the expert's reward function, or at least find a reward function under which the expert's behavior is "meaningfully" optimal (I will clarify this later). In the case of apprenticeship learning, we want the optimal policy of to perform well with respect to the original unseen reward .
In fact, just specifying the MDP\R and the expert policy/trajectory tends not to be enough. We also need to know a bit about the class of possible reward functions. Even in relatively small state spaces, the space of all possible reward functions can grow too quickly for tractable optimization. With an infinite number of states, occupying a space like , searching the full space of possible reward functions is a non-starter.
Instead, the convention in IRL is that we are given feature functions , with . These are stacked into a feature vector . Each of these feature functions could be pretty much anything. If our environment is a hilly surface, for example, one state feature might be how high up we are, another might be the slope of the hill in the positive x direction, and so on. We get to assume that the true reward function is a weighted combination of these features, and we are simply asked to find the weights. This is usually written as a weight vector of the same dimension as the number of features. And our reward function is just .
Already, one may notice that assumptions we are making in order to make IRL tractable are stacking up:
- We are given the entire dynamic of the environment
- The environment satisfies the Markov property
- The environment contains no uncertainty or hidden variables
- We are told the expert is acting optimally
- We are certain of the reliability of our observations of the expert’s behavior
- The features we are given for the reward function already encode a lot of the “hard work” of reverse-engineering reward. (Alternatively, if the features are poorly chosen, we might not be able to represent the true reward at all.)
Each additional assumption makes it harder for us to approach Russell’s vision of practical applicability to real agents in real environments. In many cases where we would like to apply IRL, almost none of these assumptions are satisfied. However, various methods can relax the importance of some of these conditions, and applications of IRL are now numerous. With that said, let us consider a few foundational results.
Maximum Margin Methods
Consider the reward function which is identically zero. Under this reward, every policy, including any input expert policy or behavior, is optimal. This is an issue, since I earlier framed the IRL problem as finding a reward function for which the expert's behavior is optimal. Since we don't care about "degenerate" rewards like , we must provide further specification on what makes a learned reward function good.
In one of the first published IRL Methods, (Ng and Russell 2000) demonstrated this problem of degenerate solutions by providing an analytical condition (given known expert policy) for reward functions which have the expert's policy as optimal. In practice, many reward functions satisfy this condition. To discriminate between reward functions and choose one which meaningfully captures the expert's behavior, the authors propose a maximum margin approach. Of the set of reward functions for which the expert policy is optimal, we choose maximizing
where is the expert behavior in state , and is the Q-function of the expert policy with respect to . This is basically saying that we prefer reward functions which not only make the expert policy look optimal, but also make it better than any other policy. (In other words, we make the expert policy look good by the maximum margin). More work is required to extend this notion to stochastic policies and cases where we are given an expert trajectory rather than a policy, but the general idea stays the same.
Ng and Russel end up with a set of linear conditions for each IRL variant they consider, meaning they can use linear programming algorithms to find reward functions, and indeed their approach works well in small environments.
(Abbeel and Ng 2004) improve on this approach and apply IRL to apprenticeship learning (AL), or learning an expert's policy from demonstration. AL can be significantly more sample efficient than methods like imitation learning, which simply memorize the expert's behavior at each state. IRL is not necessary in all AL methods: see (Adams et al. 2022), Section 2.2 for discussion. However, incorporating IRL to model an expert for AL has become a key approach.
If an expert is in fact following an policy that is optimal or nearly-optimal with respect to a true value function , and IRL finds an approximate reward function , then standard RL methods can be used to find an optimal policy with respect to . The hope is that this learned policy can match expert performance. A further benefit of the IRL approach is that reward functions are more transferrable than policies: if the MDP environment changes slightly, we can reapply to much greater effect than simply recycling the learned policy.
Recall that in this IRL setup, we are given a vector-valued feature function and must find weights approximating the expert's reward function . The authors point out a key simplification in this framework for evaluating the value function of a policy with respect to weights for a reward function :
The LHS is the expected value of the starting state of the MDP (recall that is the starting distribution of the MDP), and refers to the expected value with state trajectories weighted by their likelihood of occurring when following policy . The first equality applies the definition of the value function. The second equality uses the definition of our reward function to pull out the weights. The final equality defines .
is called the feature expectations vector: for each feature in , and given a policy , represents the expected discounted cumulative value of that feature when following . The reason why this is important is twofold: first, since the value of a policy is expressible in terms of feature expectations, matching the value of the expert policy can be reduced to finding a policy that matches their feature expectations. Second, the feature expectation vector of an observed expert trajectory is easy to calculate:
where is the 'th state of the 'th sample trajectory.
With this in hand, Abbeel and Ng develop two iterative algorithms that each (1) generate a new policy, (2) compare all generated policies' feature expectations to the expert's, (3) find reward function weights that are closer to the expert's, and return to (1) by using forward RL to find the optimal policy of the new weights. In this way, the algorithms provably converge to an understanding of both the expert reward and policy. Step (3) is what makes these algorithms maximum margin techniques, since it searches for weights that make the expert policy look better than any previously-generated policy.
In one test environment, much larger than those studied in (Russel and Ng 2000), Abbeel and Ng's algorithm shows impressive performance:
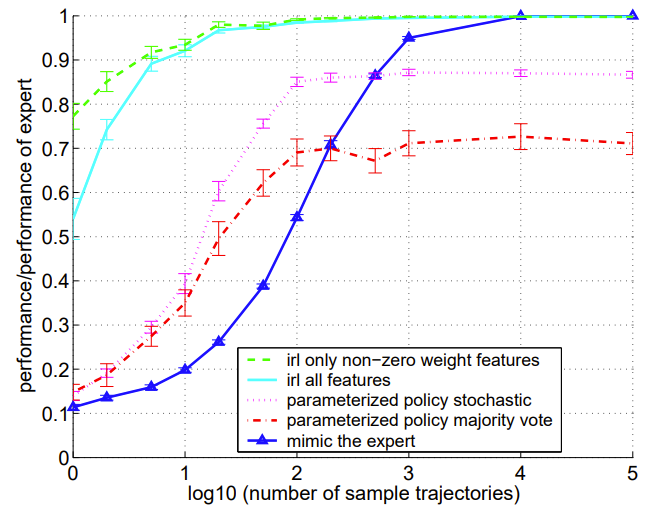
[The above is Figure 4 from Abbeel and Ng 2004. "Plot of performance vs. number of sampled trajectories from the expert...Averages over 20 instances are plotted, with 1 s.e. errorbars. Note the base-10 logarithm scale on the x-axis."]
One drawback of Abbeel and Ng's method is that it is not good at outperforming a suboptimal expert. An adapted approach by (Syed and Schapire 2007) allows the AL learner to become even better than the expert in some cases. They take a game-theoretic approach, making the key observation that Abbeel and Ng's feature expectation-matching between the expert and learned policies can be reframed as a two-player zero-sum game:
The min-player is choosing feature weights for a reward function that makes the expert's behavior look better than any other policy (following the spirit of margin maximization), and the max-player is choosing a policy that does as well as possible under these weights.
If the expert was playing optimally with respect to some reward function with weights , then since the min-player will choose and the max-player can do no better than choosing a policy which is also optimal, so that . This is still a good result for AL, since the output policy has managed to be optimal in the original reward function!
But the even better case comes when , which might happen if the expert's behavior is very suboptimal, or if there is no expert at all. In that case, the max-player finds a policy which outperforms the expert for any weights in the domain that the min-player can choose from. In other words, this formulation allows the learner to unilaterally outperform the expert. This is possible in part because the authors restrict the weight domain by assuming that all features have positive impact.
Syed and Schapire's algorithm approximating this game is both faster and provably outperforms Abbeel and Ng's.
Bayesian Methods
(Ramachandran and Amir 2007) take a Bayesian approach to IRL, which manages to avoid the problem of degenerate reward functions through a probabilistic approach. The idea is to construct a probability distribution over reward functions, and use the observed behavior of the expert to make updates. For instance, as we observe the agent, it might become unlikely that they are maximizing , but perhaps their behavior remains consistent with , and so on for every reward function we are considering.
Two immediate advantages of this framework are its built-in handling of expert suboptimality as well as its prior distribution. An expert acting suboptimally with respect to a reward function is still evidence of that reward function, although admittedly not as strong of evidence as optimal behavior. Meanwhile, if we have prior knowledge about reward functions, we can encode this knowledge directly into our prior. These both are classic advantages of a Bayesian approach that reappear in many domains.
If we observe a trajectory , we have that is our likelihood factor. When we assume that agents do not change their policy over time, and that their policy only depends on the current state, we get the nice result that . Basically, we can update for every state-action pair we see.
Ramachandran and Amir propose the following likelihood factor:
where is the Q-function of the optimal policy with respect to the reward function . The above says that action is likely in state under the reward function when is a high-value action for the expert, if it were acting optimally under . The parameter represents the learner’s confidence that the expert is acting optimally. If we believe the agent is suboptimal, we set lower and our general confidence distribution over reward functions becomes more uncertain.
Taking a product over exponentials turns into a sum in the exponent, so we have where . Finally, we have
where is the prior probability of . Note the (proportional to) symbol in the above. In reality, every probability is normalized; calculating the true probability is intractable since we would have to consider every reward function. Luckily, estimating the posterior with Markov Chain Monte Carlo (MCMC) methods makes this factor unimportant. I can recommend this resource on the general ideas behind MCMC.
To actually turn the reward distribution into a learned reward function, we could take the maximum a posteriori (MAP) reward function in the distribution as our output, but better is to output the mean reward function of the posterior. Meanwhile, Theorem 3 of Ramachandran and Amir shows something similar for apprenticeship learning: the policy which minimizes the expected policy loss over the reward distribution is the optimal policy for the expected reward function.
Later extensions of Bayesian IRL have allowed for active learning: the Bayesian framework is well-suited to allow the learner to seek and update strongly on expert behavior in the states it is least certain about. One disadvantage of this technique is its computational cost and reliance on forward RL to compute optimal Q-functions, although new work is addressing this.
Maximum Entropy Methods
The Maximum Entropy Principle (Maxent) is a very general notion that has seen use in diverse fields. The idea is that when we want to find a distribution given particular information or constraints, then among all distributions which meet the constraints, we ought to choose the one with the maximum information-theoretic entropy. This condition encodes the idea that we are making no implicit assumptions beyond the given information. This video is a nice introduction.
The main draw of Maxent—that it chooses one distribution among many, under a constraint, which is the "least wrong" in some sense—should sound quite familiar and applicable in the context of IRL and AL. We are choosing between many behaviors, constrained by compatibility with the expert trajectory, and we need a method of resolving ambiguity between these behaviors and the reward functions which explain them.
(Ziebart et al. 2008) marked the first application of Maxent to IRL, demonstrating the method's computational efficiency. The algorithm is friendly to gradient methods, and avoids using forward RL. Ziebart et al.'s approach is to create a maximally entropic probability distribution over trajectories , parametrized by reward weights.
Although the justification is outside the scope of this survey, in the case where the MDP is deterministic, this maximum entropy distribution looks like
where is the empirical feature expectations of some input trajectory . (I have changed some notation from the paper to maintain consistency with earlier sections.) Notice how this expression encodes the constraint that probable behavior should maximize reward. The formula becomes trickier when we have stochastic state transitions, but ultimately leads to a distribution that is also parametrized by the state transition function.
All of the above has held fixed, but for IRL we want to tune our weights to match the expert. It turns out that the best reward weights are those which maximize the probability of the expert trajectory:
where is the 'th demonstrated expert trajectory. This becomes a convex optimization problem which is friendly to gradient methods! Using particular RL-approximation techniques, the gradient of the above loss can be found quickly.
The authors flex this efficiency by performing IRL on real-world road data. They model a large road network as an MDP with hundreds of thousands of states, and use GPS driving data as expert demonstration. By running IRL on around 20 common-sense features, the authors reverse-engineered the route preferences of drivers. Their system recommends good driving routes, and even predicts driving destinations given only a partial path.
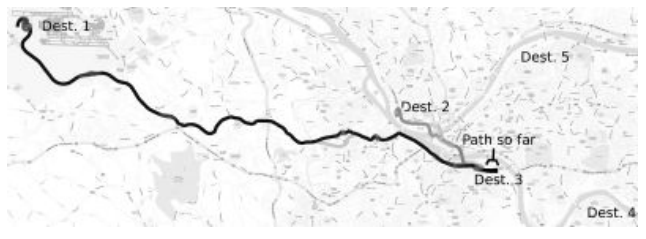
[Figure 4 from (Ziebart et al. 2008): "Destination distribution (from 5 destinations) and remaining path distribution given partially traveled path."]
Maxent methods have proven to be one of the most reliable implementations of IRL. They can avoid subtle problems from other paradigms where highest-probability paths are not always highest-value (so-called "label bias"). Finally, Maxent is compatible with deep learning implementations, which are excellent at working with large expert demonstrations, among other things.
Summary
We saw how the tagline goal of IRL, "finding reward functions given behavior," underspecifies the problem due to degenerate solutions. Distinct IRL paradigms address this gap differently, each with particular strengths and weaknesses.
In their survey of the IRL literature, Arora and Doshi elaborate on other challenges inherent in many IRL techniques:
- Measuring success is difficult, especially in cases where we can't evaluate the true expert value function of a state. It is also sometimes unclear what we should compare: reward functions? Policies? Value functions? Different classes of metrics are also hard to cross-compare
- Many IRL techniques generalize poorly to unobserved states, and especially poorly to nonstationary dynamics. Newer methods are specifically attempting to address the latter
- Solving IRL can be very computationally expensive, and cost grows quickly with number of states. Also, many methods require repeated calls to forward RL and other expensive subtasks. Over the years, the usual story of algorithmic improvement has played out, and we can now handle much larger environments
- Many IRL techniques do poorly without fully-known MDP dynamics, or without fully noiseless observations of the expert. A subset of the literature is trying to address this, for instance by considering occlusion of expert trajectories, or doing IRL in a Partially Observable MDP
Many subtopics of IRL are quite relevant to safety. For Value Learning, IRL holds promise as a technique to bridge the gap between our behavior and our implied values. Easily the most important version of IRL in this regard is Cooperative IRL, which points out that active teamwork between learner and expert can greatly improve communication of the expert's reward function. Although I am enthused by CHAI's research, we still have a long way to go. The current paradigm of IRL is simply unable to (a) robustly apply (b) sufficiently complex rewards in (c) sufficiently complex environments.
Conclusion
This was my final project for MLSS Summer 2022. I would like to thank Dan Hendrycks, Thomas Woodside, and the course TAs for doing a thoroughly excellent job. I would also like to thank Rauno Arike for his comments. I feel that MLSS has helped prepare me for entry into the world of research, and has given me critical experience with ML and key concepts in Safety.
From this project, I have a better idea of why research is a social activity, and why mentorship is important for aspiring researchers. Learning a subject alone is hard partly because you might get stuck on the material, but it is also hard to know where to direct your focus without guidance. Having a community that can point you to the most important results and prerequisites is critical.
I also have a better picture of what the process of research looks like, or at least the part where you try to catch up with an established literature. Fluency in a technical subject can’t be shortcut; you just have to find a wall of references and read as much as you can. This project has helped me realize just how much further I still have to go.
0 comments
Comments sorted by top scores.