Posts
Comments
I don't think we were thinking too closely about whether regression slopes are preferable to correlations to decide the susceptibility of a benchmark to safetywashing. We mainly focused on correlations for the paper for the sake of having a standardized metric across benchmarks.
Figure 4 seems to be the only place where we mention the slope of the regression line. I'm not speaking for the other authors here, but I think I agree that the implicit argument for saying that "High-correlation + low-slope benchmarks are not necessarily liable for safetywashing" has a more natural description in terms of the variance of the benchmark score across models. In particular, if you observe a low variance in absolute benchmark scores among a set of models of varying capabilities, even if the correlation with capabilities is high, you might expect that targeted safety interventions will produce a disproportionately large absolute improvements. This means the benchmark wouldn't be as susceptible to safetywashing, since pure capabilities improvements would not obfuscate the targeted safety methods. I think this is usually true in practice, but it's definitely not always true, and we probably could have said all of this explicitly.
(I'll also note that you might observe low absolute variance in benchmark scores for reasons that do not speak to the quality of the safety benchmark.)
I'll begin by saying more about our approach for measuring "capabilities scores" for a set of models (given their scores on a set of standard capabilities benchmarks). We'll assume that all benchmark scores have been normalized. We need some way of converting each model's benchmark scores into one capabilities score per model. Averaging involves taking a weighted combination of the benchmarks, where the weights are equal. Our method is similarly a weighted combination of the benchmarks, but where the weights are higher for benchmarks that better discriminate model performance. This can be done by choosing the weights according to the first principal component of the benchmark scores matrix. I think this is a more principled way to choose the weights, but I also suspect an analysis involving averaged benchmark scores as the "capabilities score" would produce very similar qualitative results.
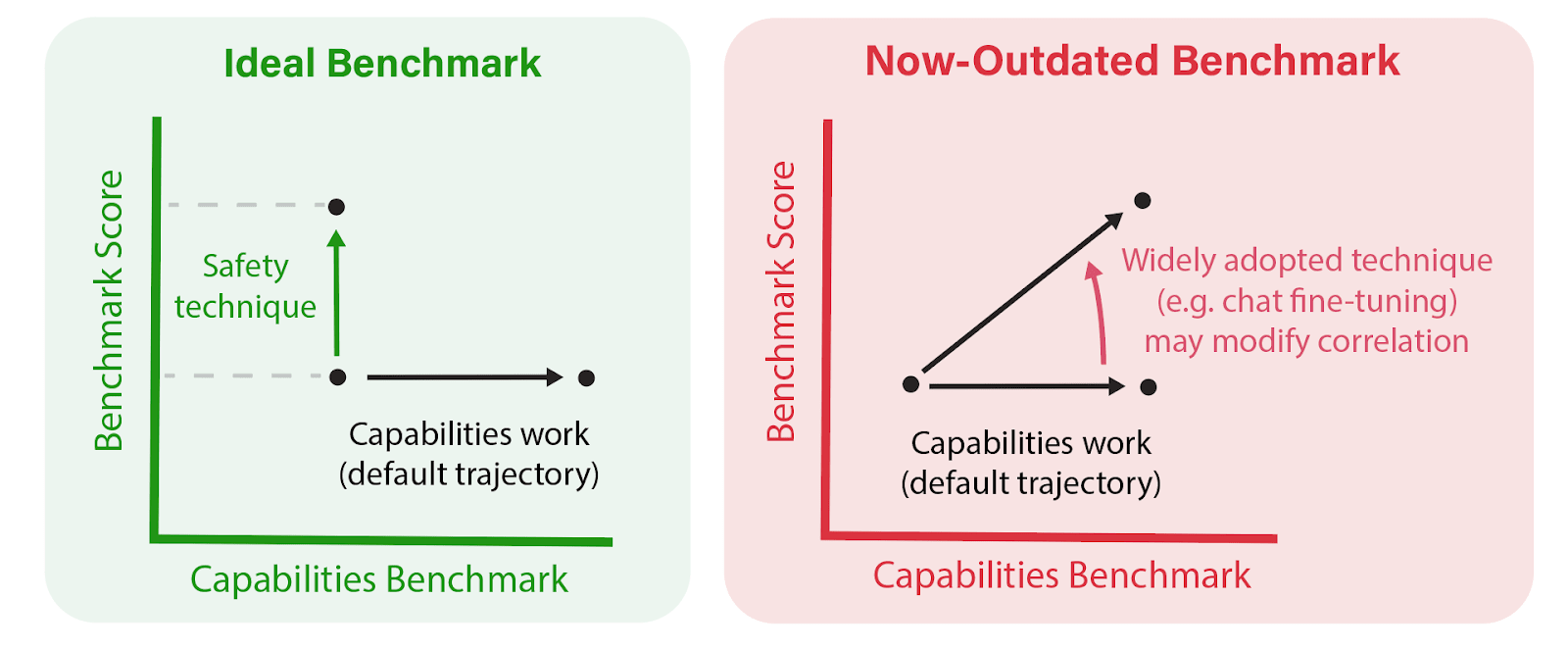
To your first point, I agree that correlations should not be inferred as a statement of intrinsic or causal connection between model general capabilities and a particular safety benchmark (or the underlying safety property it operationalizes). After all, a safety benchmark's correlations depend both on the choice of capabilities benchmarks used to produce capabilities scores, as well as the set of models. We don't claim that correlations observed for one set of models will persist for more capable models, or models which incorporate new safety techniques.
Instead, I see correlations as a practical starting point for answering the question "Which safety issues will persist with scale?" This is ultimately a key question safety researchers and funders should be trying to discern when allocating their resources toward differential safety progress. I believe that an empirical "science of benchmarking" is necessary to improve this effort, and correlations are a good first step.
How do our recommendations account for the limitations of capabilities correlations? From the Discussion section:
As new training techniques (e.g., base, chat fine-tuning, refusal training, adversarial training, circuit breakers) are integrated into new models, the relevance and adequacy of existing safety benchmarks—and their entanglement with capabilities benchmarks—should also be regularly reassessed.
[This figure was cut from the paper, but I think it's helpful here.]
An earlier draft of the paper placed more emphasis on the idea of a model class, referring to the mix of techniques used to produce a model (RLHF, adv training, unlearning, etc). Different model classes may have different profiles of entanglements between safety properties and capabilities. For example, RLHF might be expected to entangle truthfulness and reduced toxicity with model capabilities, and indeed we see different correlations for base and chat models on various alignment, truthfulness, and toxicity evals (although the difference was smaller and less consistent than we expected). I think our methodology makes the most sense when correlations are calculated only use models from the same class (or even models from the same family). Future safety interventions can and should attempt to entangle a wider range of safety properties with capabilities; ideally, we'll identify training recipes which entangle all safety properties with capabilities.
Thank you! I'd be glad to include this and any other corrections in an edit once contest results are released. Are there any other errors which catch your eye?
I would honestly be interested to see a detailed writeup with good examples of this "maybe amazing" vs "probably good" distinction.
A subtlety here is that the traits that make a candidate a potential outlier are often very different from the traits that would make them “pretty good,” so improving your filtering process to produce more “pretty good” candidates won’t necessarily increase the rate of finding outliers, and might even decrease it.
Most important point I'd still want to grok is what this "might even decrease it" looks like. What are industry examples of metrics or filtering processes that can differentiate 95th percentile samples from 99.9th percentile samples? And what are some of the qualitative shifts you see between them? I suspect the art of identifying 99.9th percentile samples goes beyond looking for "really, really good" 95th-percentile-ish things.