Searching for outliers
post by benkuhn · 2022-03-21T02:40:17.296Z · LW · GW · 16 commentsContents
16 comments
Shortly after I started blogging, because I was a college student and had nothing better to do, I set a goal to write every week. I started in September 2013 and wrote around 150 posts between then and when I started working at Wave. (At that point I stopped having nothing better to do, so my blogging frequency tanked.)
The outcomes of these 150 posts were extremely skewed:
- Two made it big on the Hacker News frontpage (What happened to all the non-programmers and Readability, hackability, and abstraction).
- After seeing the second post on HN, Dan Luu subscribed to my blog and started submitting lots of my posts. This caused an additional ~5 posts to get decent traction, which resulted in my first wave of subscribers that I didn’t know personally, and provided a lot of motivation to keep writing. Dan and I also eventually became good friends.
- The other ~95% of posts were completely forgettable.
This is a pretty typical spread of outcomes for blog writers: a few smash hits and a lot of clunkers. Eight years later, I’ve built a good enough intuition for what posts will resonate with people that I can now mostly avoid writing complete clunkers, but even so, my few best recent posts (In defense of blub studies and You don’t need to work on hard problems) have been much more successful than the others, both in terms of being shared widely, and getting feedback like “this really influenced how I think.”1
This type of statistical distribution of outcomes is called heavy-tailed, because outcomes in the “tail” (i.e. ones that are far better than the typical outcome) have a relatively high chance of occurring, making the tail “heavy.” When I write blog posts, each post is a sample from the heavy-tailed distribution of blog post outcomes.
You can most easily see the difference between a heavy-tailed and light-tailed distribution on a plot. Here’s a plot comparing a heavy-tailed and light-tailed distribution with identical means and standard deviations, chosen to be similar to the distribution of household income in the US (median = $60,000; p99 = $600,000):
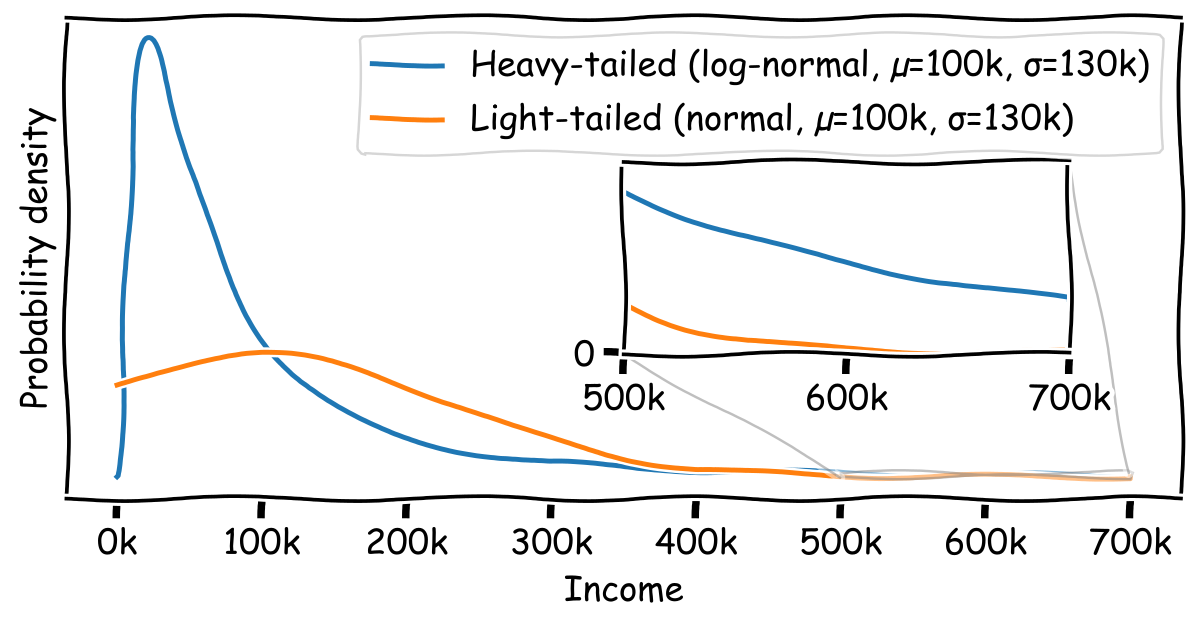
Heavy-tailed distributions are really unintuitive to most people, since all the “action” happens in the tiny fraction of samples that are outliers. But lots of important things in life are outlier-driven, like jobs, employees, or relationships, and of course the most important thing of all, blog posts.
Because heavy-tailed distributions are unintuitive, people often make serious mistakes when trying to sample from them:
- They don’t draw enough samples
- They underestimate how good of an outcome it’s possible to get
- They find it hard to tell whether they’re following a strategy that will eventually work or not, so they get incredibly demoralized.
If you’re aware of when you’re working on something that involves sampling from a heavy-tailed distribution, you can avoid those mistakes and end up with much better outcomes.
As a rule of thumb, a heavy-tailed distribution is one where the top few percent of outcomes are a large multiple of the typical or median outcome. A classic example would be Vilfredo Pareto’s finding that about 80% of Italy’s land was owned by 20% of the population. It turns out that this happens across many other domains, too—a phenomenon called the Pareto principle or the 80-20 rule. In contrast, distributions that don’t follow an 80-20 or similar rule are called “light-tailed.” Some examples:
-
Income is heavy-tailed: the median person globally lives on $2,500 a year, while the top 1% live on $45,000, almost 20× more.
-
Height is light-tailed: the tallest people are only a few feet taller than average. If height followed the same distribution as income, Elon Musk, who made $121b in 2021, would be about 85,000 km tall, or about ¼ of the distance from the earth to the moon.
-
Twitter followers are heavy-tailed: in 2013, the median active Twitter poster had 61 followers, while the top 1% had almost 3,000.
-
Performance at most athleticism-based sports is light-tailed. For the 100m sprint, the current world record from Usain Bolt is 9.58 seconds, while “a non-elite athlete can run 100m in 13-14 seconds.”2
-
The cost-effectiveness of global health interventions is heavy-tailed: as measured by the Disease Control Priorities project, the most cost-effective intervention was about 3x as cost-effective as the 10th-most cost-effective, and 10x the 20th-most cost-effective.3
Light-tailed distributions most often occur because the outcome is the result of many independent contributions, while heavy-tailed distributions often arise from the result of processes that are multiplicative or self-reinforcing.4 For example, the richer you are, the easier it is to earn more money. The more Twitter followers you have, the more retweets you’ll get, and the more you’ll be exposed to new potential followers. The cost-effectiveness of a global health intervention comes from multiplying many different variables (how bad the disease you’re fighting is, how much of an impact the intervention has on the disease, how costly doing the intervention for one person is), each of which itself is the product of several other factors.
Notably, in a light-tailed distribution, outliers don’t matter much. The 1% of tallest people are still close enough to the average person that you can safely ignore them most of the time. By contrast, in a heavy-tailed distribution, outliers matter a lot: even though 90% of people live on less than $15,000 a year, there are large groups of people making 1,000 times more. Because of this, heavy-tailed distributions are much less intuitive to understand or predict.
That’s unfortunate, since according to me (and the Pareto Principle), most important things in life are heavy-tailed. For example:
-
Goodness of jobs. This is clearest for dimensions like salary that are measurable, but in my experience it’s also true of less-measurable dimensions like how much you’ll learn or whether you’ll be miserable because of dysfunctional company culture. (Note that which jobs are outliers for you depends on your values, which differ a lot from person to person! For example, working at Wave was an outlier for me, but hasn’t been for everyone.)
-
Effectiveness of (many types of) knowledge workers. Dan Luu writes: “At places I’ve worked, I track what causes decisions to happen, who’s actually making things happen, etc., and there are a very small number of people (on the order of a few percent), who are really critical to the company’s effectiveness.”
-
Influentialness of ideas. The top 100 most-cited papers have over 12,000 citations each, while the median paper seems to have about one citation.
-
Quality of romantic partnerships. For example, in the US today, almost 50% of partnerships end in divorce, whereas the 99th percentile probably involves the couple being (on average) extremely happy with each other for 50+ years. In other contexts, this seems likely to be even more true; for example, in some low-income countries with regressive gender norms, over 25% of women who have ever had a partner experience domestic violence each year, which probably makes the average partnership extremely bad.5
-
Success of startups. In November 2021, the total value of all 3,200 Y Combinator-funded companies was $575b, and the top 5 (or top 0.2%) were worth ~65% of that (Airbnb: $100b, Stripe: $100b, Coinbase: $80b, Doordash: $50b, Instacart: $40b). The mean non-top-5 company was worth ~$60m, or ~1% of a top-5, so the median was likely even less than that.
-
Business outcomes of projects within a company. The clearest data on this comes from software companies measuring effect sizes of A/B tests. For example, a team at Microsoft Research measured the distribution of impact of experiments on Bing and found that “many experiments have very small measured deltas, while a handful show substantial gains.” An analytics company, Optimizely, also found that their customers' A/B tests followed a similarly heavy-tailed distribution.
Anecdotally, based on my experience at Wave, the same effect seems to hold for longer-running projects that are less easy to quantify.6 The dynamics here are similar to those for startups, since many projects within companies are like mini-startups.
-
Impact of philanthropic projects. The Open Philanthropy Project argues for a “hits-based giving” approach: “We suspect that high-risk, high-reward philanthropy could be described as a ‘hits business,’ where a small number of enormous successes account for a large share of the total impact — and compensate for a large number of failed projects.”
-
Life decisions like where to live. For example, at least pre-COVID, if you were a software engineer, moving to San Francisco would have been likely to put you on a very different career trajectory than almost any other city because there are so many more jobs available, and also would have made you much more likely to e.g. start a company.7 If you were a rationalist, effective altruist or other weird Internet intellectual, it was likely to have a similar effect due to being “global weird HQ.”
-
Usefulness of new activities to try. In my teens and early 20s, I tried a large number of different activities. Most of them were completely forgettable, but the top few were extremely valuable. For example, one time I allowed a housemate to convince me to go to a contra dance. I really liked it and became a serious contra dancer, which was probably the activity that contributed the most to my happiness and wellbeing from ages ~13-21 as well as helping me meet a large number of friends and multiple romantic partners.
Hopefully that’s enough examples to convince you that heavy-tailed distributions are absolutely everywhere.
The most important thing to remember when sampling from heavy-tailed distributions is that getting lots of samples improves outcomes a ton.
In a light-tailed context—say, picking fruit at the grocery store—it’s fine to look at two or three apples and pick the best-looking one. It would be completely unreasonable to, for example, look through the entire bin of apples for that one apple that’s just a bit better than anything you’ve seen so far.
In a heavy-tailed context, the reverse is true. It would be similarly unreasonable to, say, pick your romantic partner by taking your favorite of the first two or three single people you run into. Every additional sample you draw increases the chance that you get an outlier. So one of the best ways to improve your outcome is to draw as many samples as possible.
As the dating example shows, most people have some intuition for this already, but even so, it’s easy to underrate this and not meet enough people. That’s because the difference between, say, a 90th and 99th-percentile relationship is relatively easy to observe: it only requires considering 100 candidates, many of whom you can immediately rule out. What’s harder to observe is the difference between the 99th and 99.9th, or 99.9th and 99.99th percentile, but these are likely to be equally large. Given the stakes involved, it’s probably a bad idea to stop at the 99th percentile of compatibility.
This means that sampling from a heavy-tailed distribution can be extremely demotivating, because it requires doing the same thing, and watching it fail, over and over again: going on lots of bad dates, getting pitched by lots of low-quality startups, etc. An important thing to remember in this case is to trust the process and not take individual failures, or even large numbers of failures, as strong evidence that your overall process is bad.
When I was doing my first systematic engineering hiring process for Wave—before we’d hired any great people in a non-ad-hoc way—I found it exhausting to give candidates the same interview over and over again and rejecting every one. As a result, we originally set our bar lower than we should have. After hiring some really great folks through that process, I finally became intuitively convinced that the hiring work we were doing was valuable, and became much happier to spend a lot of time and effort on hiring, because I knew it would eventually pay off. After that, we ended up raising our hiring bar over time.
Often, you’ll have a choice between spending time on optimizing one sample or drawing a second sample—for instance, editing a blog post you’ve already written vs. writing a second post, or polishing a message on a dating app vs. messaging a second person. Some amount of optimization is worth it, but in my experience, most people are way over-indexed on optimization and under-indexed on drawing more samples.
This is similar to how venture capitalists are often willing to invest in the best companies at absurd-seeming valuations. The logic goes that if the company is a “winner,” the most important thing is to have invested at all and the valuation won’t really matter. So it’s not worth it to the VC to try very hard to optimize the valuation at which they invest.
Another consequence of the numbers game is that the strategy that you use to filter your samples is very important: for example, as an investor, one of the silliest ways you can lose money is to get pitched by a startup, pass on them because you think they’re bad, and then see them get 100x more valuable. Because of this, it’s very important for your filters to be as tightly correlated with what you actually care about as possible, so that you don’t rule candidates out for bad reasons.8
A subtlety here is that the traits that make a candidate a potential outlier are often very different from the traits that would make them “pretty good,” so improving your filtering process to produce more “pretty good” candidates won’t necessarily increase the rate of finding outliers, and might even decrease it. Because of this, it’s important to filter for “maybe amazing,” not “probably good.” For example, this is why Y Combinator doesn’t filter very much on whether a startup’s idea seems good. Bad-sounding startup ideas are probably less-successful on average, but more likely to be outliers:
[T]he best startup ideas seem at first like bad ideas. I’ve written about this before: if a good idea were obviously good, someone else would already have done it. So the most successful founders tend to work on ideas that few beside them realize are good. Which is not that far from a description of insanity, till you reach the point where you see results.
The first time Peter Thiel spoke at YC he drew a Venn diagram that illustrates the situation perfectly. He drew two intersecting circles, one labelled “seems like a bad idea” and the other “is a good idea.” The intersection is the sweet spot for startups.
This concept is a simple one and yet seeing it as a Venn diagram is illuminating. It reminds you that there is an intersection—that there are good ideas that seem bad. It also reminds you that the vast majority of ideas that seem bad are bad.
Instead, Y Combinator mostly ignores idea quality and tries to find high-quality founding teams who can iterate on the idea quickly in response to user feedback.
This has worked well for them: when the Airbnb founders pitched them on an app for hosting strangers in your apartment, the YC partners thought that the idea was terrible and would never work, but were impressed by the team’s determination (in particular making ends meet by selling politically themed cereal) and decided to fund them anyway. In this case, the partners were catastrophically wrong about the idea being bad, but fortunately it didn’t matter because they had correctly decided not to put much weight on that as a signal. With a less disciplined evaluation process, they might have passed on Airbnb, which now comprises about 15% of the value of the YC portfolio ($100b out of $575b). Meanwhile, at least one successful VC passed on Airbnb specifically because they were “very suspect of this idea” and now keeps a box of politically-themed cereal in their office as a “reminder to back great entrepreneurs whenever they walk into our office regardless of what they pitch us on.”
In other contexts, it’s very common for people sampling from heavy-tailed distributions to focus on “ruling out” candidates instead of “ruling in,” which is likely to be a bad approach for similar reasons. In dating, for instance, people often have some sort of checklist they want a potential partner to satisfy, where most of the checkboxes (say, professional background) rule out lots of people but are only weakly correlated with long-term compatibility. Sasha Chapin writes:
Once, on a day where I felt like I knew something, I declared that I would be okay with dating anyone who wasn’t vegan or an actress. It was clear to me that cheeseburgers were crucial to my happiness, and that I’d have a hard time getting close to a professional emotion simulator. Now I have a wife who is both a vegan and an actress, with whom I’m extremely happy.
I can still recall, with shocking clarity, the moment three hours after I met my wife, when I offered her a piece of chicken. “Actually, I’m vegan,” she said. “Well,” I said to myself, “I suppose I am fucked now.” The night air was glimmering, love was all around, and I mentally edited out many chunks of animal protein in the future.
If you think of yourself as having a limited “filtering budget” to “spend” while dating (since you can only apply so many filters before your pool of eligible partners shrinks to zero), filtering for people from a small number of professions that comprise, say, 5% of the population is a poor use of that budget compared to using the same budget to find someone who is >95th percentile in, say, being able to talk through conflicts in a reasonable way.
The difficulty with the latter is that it’s much faster to filter people for profession than being good at reasonably talking through conflicts. In fact, it’s generally true that it’s easier to filter for downsides than upsides, because downsides are more legible. On a dating app, it’s easy to see whether someone is physically unattractive or has poor grammar, but very hard to see whether they’re >95th percentile at talking through conflicts. But in principle, unless you’re overwhelmed by the quantity of people willing to go on dates with you, you’re probably more constrained by filtering budget than by time, so it makes more sense to be less strict on checkboxes and spend that filtering on better-correlated things.9
Similarly, many hiring processes allow any interviewer to veto a hire, which selects for well-rounded people with no serious downsides, but many people I know who are outliers at their jobs have serious downsides that they’ve figured out how to work around. For example, Drew, the CEO of Wave, is by far the strongest leader I’ve worked with, but for a long time he had a way of thinking and communicating that was hard to understand for some people (while being an extremely good fit for others, like me). At Wave, Drew could work around this by only having people report directly to him if they’re good at understanding how he thinks, and having his direct reports act as “interpreters” to the rest of the company if necessary. But if he had interviewed for roles at another company, I think it’s quite likely that at least one of his interviewers would have found him hard to communicate with and would have rejected him based on this.
One tricky thing about heavy-tailed distributions is that it can be difficult to know how good a really great outcome can get.
This matters the most in cases where there’s a trade-off between exploration and exploitation—that is, between getting more value from your current sample, or drawing a new sample from the distribution. For example, this is true of jobs, hires (for some positions), or relationships: they get better over time as you invest in them, so you ideally want to have the same one for a very long time, which means stopping looking at some point. To make that decision, it’s important to know whether your current job/candidate/relationship is just 90th percentile (relatively easy to do better) or 99.9th (quite hard to do better).
When I accepted my first job out of college, I thought it was great. The startup I worked for had a clear explanation of why they’d identified a market inefficiency that nobody else had, so it seemed likely to succeed. The founders seemed like they knew a lot of stuff, and I was getting to learn about cool machine learning and statistics stuff.
Those things were all true, but it also had significant downsides. The company’s constraint wasn’t machine learning, it was sales, so my work wasn’t always very important. Their potential market size was limited unless they could eat many adjacent parts of the value chain. And while the founders were fairly competent, I learned a lot less from them than I did from other mentors I had later.
I don’t think it was super unreasonable even in retrospect to take that job, since I did a relatively systematic search, and it was my first job so I didn’t have a lot of experience knowing what to look for. But my point is that I had no idea how much better stuff there was out there.
I’ve observed many other people who seem like they could achieve an outlier outcome fall into the same trap of “settling”—in job searches, in interviews, in dating, and in any other heavy-tailed situation. On average, I expect most people would benefit from rejecting more early candidates in all of these.
One reason you might be reluctant to do this is the worry that, if your job/candidate/relationship is actually the best you can hope for and you reject them, you’ll never find another equally good one. For this, I think it’s helpful to cultivate an abundance mindset. If you found your current job after two months of searching, then, unless you did something hard-to-replicate during those two months (e.g. call in a bunch of favors that you no longer have the social capital to do again), you should expect to be able to find an equally good opportunity in the future by putting in an equal amount of work.
Of course, that’s just a prior that you should update away from if your current job is an outlier. But most people are much more likely to overestimate the outlierhood of their current job than underestimate it.
Note that this relies on you having a reasonable view on what an outlier would be. For example, if you think that an outlier job would be one in which you never have to do anything boring, you’ll incorrectly have doubts about every job because you’re holding jobs to an unreasonable standard—both in the sense that your expectations of non-boringness are too high, and there are other things that matter in addition to non-boringness.
To avoid this problem, it’s helpful to think ahead about what you’d expect a potential outlier to look like, instead of trying to think ad-hoc about “is this a potential outlier?” for each candidate. Of course, that’s hard! I actually don’t think I’ve done a very good job of this myself, but one thing I’ve found helpful is to ask other people what outliers have looked like based on their experience. If you’re trying to find a romantic partner, you could ask your friends who are the happiest in their relationships what makes their relationship an outlier. If hiring for a new role, you could ask colleagues who have worked with great people in that role.
The other hard part of sampling from a heavy-tailed distribution is that it’s hard to know whether your process is working (in the sense that you’ll eventually end up finding outliers at a good rate). Even if you’re following a good process for, say, interviewing job candidates, you should expect to interview lots of people who don’t meet your bar before finding someone great. Conversely, if you’re making a bad mistake, like screening out candidates who would have been outliers for silly reasons, it’s very hard to notice that you’re doing this since you’ll never get to observe the counterfactual where you hired them.
As a result, often the best you have to go on is your first-principles reasoning: does it seem like the things you’re filtering on are tightly correlated with actual outlier-hood? Are you discarding samples for silly reasons?
To have a working process for sampling from a heavy-tailed distribution, you need to solve two problems:
-
A good way of evaluating whether a sample is an outlier
-
A good way of drawing samples
Solving the first problem is pretty idiosyncratic to the domain you’re operating in, and can be quite hard, although the suggestion above of asking friends/colleagues what outliers looked like to them (and especially what outliers looked like during the evaluation phase, e.g. how did their top hires perform in interviews), seems like it could be generally useful. Other than that, this just requires a bunch of hard domain-specific thinking.
If you do have a fast and accurate way of evaluating a sample, then it becomes much easier to tell how well your sampling strategy is working. You can iterate on different sampling strategies and see whether the candidates coming through seem better or worse. In this case, what matters most is going through samples quickly, so that you can iterate quickly.
Dan Luu, who works on performance optimization at Twitter and discovered several opportunities with outlier impact, noted that this is one area where it’s very easy to evaluate whether a project idea is an outlier. Because the things you care about are relatively easy to measure, you can often make a quick back-of-the-envelope calculation and get a good estimate of how much money your idea will save. This makes it possible to go through a lot of ideas quickly.
For another example, blog posts have a fast feedback mechanism, which is how much engagement (sharing/commenting/social media likes/reading) they get. Because of this, once I committed to writing once a week, I learned a lot very quickly about what types of blog posts would resonate with people, and got a lot better at deciding which blog post ideas to invest in writing. For instance, I noticed that people consistently found my posts on technical topics much less interesting than my general-interest posts, even though most of my readership appeared to be software engineers, so I deprioritized writing technical posts.
For blog posts, this strategy has an obvious potential pitfall: many writers who try to optimize for engagement end up making bad trade-offs (in my opinion) against other values—for example, they’ll use clickbait headlines, write hyperbolically without caveats, or deliberately try to provoke controversy. These work to increase short-term engagement, but writers who lean on clickbait, hyperbole or controversy are less likely to write pieces with long-lasting value. Because of traps like this, if you’re working with a feedback mechanism like blog post engagement that’s only a proxy for what you care about, it’s important to be aware of the limitations of that proxy to avoid falling victim to Goodhart’s Law.
So what does a good process for searching for outliers look like?
-
Take lots of shots on goal. The more samples you have, the more likely you’ll find an outlier.
-
Know what to look for: try to figure out how good of an outcome is possible, so you know when to stop.
-
Find ways to evaluated candidates that are well-correlated with what you care about. Filter for “maybe amazing,” not “probably good.”
-
When possible, try to sample and evaluate candidates quickly, so that you can iterate on your sampling process more quickly.
-
Don’t get discouraged when you do the same thing over and over again and it mostly doesn’t work!
Thanks to draft readers Anastasia Gamick, Applied Divinity Studies, Basil Halperin, Carrie Tian, Dan Luu, Drew Durbin, Ethan Edwards, Jose Luis Ricon Fernandez de la Puente, Lincoln Quirk, Milan Cvitkovic, and Stephen Malina.
- Also feedback like “this article is MBA-tier horseshit,” but I try to look on the bright side.
- Note that some statistics based on ranking performance can still be heavy-tailed: for example, Usain Bolt has orders of magnitude more Olympic gold medals than a typical non-elite athlete.
- Disease Control Priorities, third edition, page 149, figure 7.1.
- More formally: the central limit theorem means that the sum of independent contributions will be approximately normally distributed, and normal distributions are extremely light-tailed. An easy extension of the theorem says that the product of independent variables will be log-normally distributed, which is much more heavy-tailed. The type of self-reinforcing process I’m referring to is a preferential attachment process which usually generates a power law distribution, which is even heavier-tailed than the log-normal.
- Several draft readers suggested that arranged-marriage societies have similar rates of marital satisfaction to love marriages, which was evidence against this. I couldn’t immediately find high-quality studies on the topic; every study I found had a very small sample size and many had severe grammatical errors in their abstracts, which, while not directly related to the study’s quality, did not inspire confidence. Either way, even if it’s the case that arranged and love marriages lead to similar satisfaction on average, this isn’t very good evidence against heavy-tailed-ness since the average person in a love marriage almost certainly hasn’t found a partner who’s top-1% for them.
- In fact, I’d expect these to be more heavy-tailed since in regimes where it’s hard to quantify results, people end up working on more things that have basically no impact. People who start doing A/B tests commonly say that they learn that the things that move their metrics are very different from what they would have expected a priori.
- Much like jobs or partners, different cities are outliers for different people, and there are probably many people for whom the distribution is more thin-tailed, for instance because they’re in a less-concentrated industry.
- To some extent, it’s useful not to rule out candidates for silly reasons regardless of whether the distribution you’re sampling from is heavy-tailed. But it’s much more important in a heavy-tailed context, because the difference between the best and second-best candidate is likely to be much larger, so if you pass on the best candidate, you’re giving up more value.
- If you’re a woman on a dating app, you’re much more likely to be in the “overwhelmed by the quantity” scenario, which changes the trade-off. It seems to me like it should probably still be worth putting in effort to make sure your filters are highly-correlated with what you actually care about, but I can’t speak from personal experience here.
16 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2022-03-21T13:30:18.474Z · LW(p) · GW(p)
Liked this post overall, though
Quality of romantic partnerships. For example, in the US today, almost 50% of partnerships end in divorce,
is apparently untrue, e.g.:
The historical belief that 50 percent of all marriages end in divorce and that over 60 percent of all second marriages end in divorce appear to be grossly overstated myths. Not only is the general divorce rate most likely to have never exceeded 40 percent but the current rate is probably closer to 30 percent. A closer look at even these lower rates indicate that there are really two separate groups with very different rates: a woman who is over 25, has a college degree, and an independent income has only a 20 percent probability of her marriage ending in divorce; a woman who marries younger than 25, without a college degree and lacking an independent income has a 40 percent probability of her marriage ending in divorce.
comment by gwern · 2022-03-21T15:21:23.421Z · LW(p) · GW(p)
An interesting example of extremely cheap screening of large numbers being optimal is apple breeding: https://www.newyorker.com/magazine/2011/11/21/crunch Because non-clonal sexually-reproducing apple varieties are incredibly heterogeneous, and because you are screening for new apple varieties which can beat the old ones who are themselves the survivors of screening countless millions of varieties, the screening is as cheap as possible: 1 bite and you're done. If you aren't so fantastic that you can grab the taster with 1 bite, you probably weren't good enough to potentially make it all the way to market anyway. And if a great variety simply happened to get unlucky with that one seedling, oh well, it's not worth it to retest or plant multiple instances compared to generating several fresh new ones (because failing even a very noisy test bumps the expected value below that of a new one which is ~free to sample, you'd only retest if testing were free or if you had a much smaller pool and had some 'running out' going on).
Replies from: Insub↑ comment by Insub · 2022-03-25T18:03:05.483Z · LW(p) · GW(p)
A few more instances of cheap screening of large numbers:
- I've seen people complain about google-style technical interviews, because implementing quicksort in real-time is probably not indicative of what you'll be doing as a software engineer on the job. But google has enough applicants that it doesn't matter if the test is noisy; some genuinely good candidates may fail the test, but there are enough candidates that it's more efficient to just test someone else than to spend more time evaluating any one candidate
- Attractive women on dating apps. A man's dating profile is a noisy signal of his value as a partner, but it's extremely cheap for an attractive woman to just "swipe left" and try the next one. This strategy will certainly pass up people who would have made good partners, but the cost of evaluating a new profile is so low that it makes sense to just ignore any profiles that aren't obviously great
comment by Raemon · 2022-03-28T18:35:09.717Z · LW(p) · GW(p)
This post gave me a crisp update and inspired some conversations about how many samples you need.
Around the office, the concept of how the first sample gives the most information [LW · GW] has come up a bunch, and has worked its way into my thinking in a fairly deep way. It changed how I think about the LessWrong review, and which hypotheses are worth expensively testing. There's a sense in which "an exploratory blogpost" is "the first sample" from a distribution of "what it's like to think about a topic." If I'm trying to find high-value concepts, it's maybe more useful to only bother grabbing "the first sample" from a given concept. (some thoughts on this here [LW · GW], although not spelled out in that language)
But I feel like this post gave me another angle on this, that I'm still chewing on, where some distributions are heavy-tailed, and then you to very crudely sample from lots of them to find the high-yield samples. Sometimes the first sample isn't the most informative because the most important things are heavy tailed.
When it comes to writing blogposts, I guess the two previous paragraphs are saying the same thing, framed differently. I have an intuition that there's an overarching frame that'd be helpful to me. Still chewing on it.
I wanted to jot down this comment for now to say "thanks for contributing" – I at first thought this post was just gonna be a "a nicely written up summary of stuff I already knew about heavy tails", but I feel like I got something deep out of it.
comment by hold_my_fish · 2022-03-24T05:21:14.384Z · LW(p) · GW(p)
This got me wondering how to distinguish "maybe amazing" from "probably good". Mathematically, in both cases higher mean is good, but "maybe amazing" prefers higher variance whereas "probably good" prefers lower variance.
For the purpose of recognizing these, what's the gut feeling associated with variance? My guesses:
- High variance: unfamiliar, novel, unpredictable. Negative emotion: confusion. Positive emotion: excitement.
- Low variance: familiar, conventional, predictable. Negative emotion: boredom. Positive emotion: comfort.
I've many times made the mistake of rejecting "sounds bad, but is unfamiliar" ideas in favor of "sounds good, but is predictable" ideas in environments where the former is preferable (thick upper tail distribution, as the article describes).
comment by Cedar (xida-ren) · 2022-03-28T19:10:44.653Z · LW(p) · GW(p)
About footnote #5 on arranged vs love marriages...
While the distribution for compatibility when finding a partner is long tailed, if the distribution for marginal gain on investing into an existing relationship is also as long tailed, then the comparative advantage sorta cancels out and you're not as much better off looking harder vs developing the relationships you already have.
This sorta fits my experience too, where being vulnerable and putting in the work is occasionally given me large improvements in relationship satisfaction that I never expected based on the median improvement I get for each unit of work.
comment by metachirality · 2023-12-24T02:22:51.938Z · LW(p) · GW(p)
Practically useful and expands/words coherently intuitions I already had. Before I had said intuition, I tended to take a lower-than-optimal amount of risks so I think this post will be similarly useful to careful people like me.
comment by TLW · 2022-03-27T05:15:59.357Z · LW(p) · GW(p)
This is perhaps a silly question:
Why do there appear to 'almost' never be any super-light-tailed distributions? The tail of a normal distribution decays ~exponentially. The only thing that decays super-exponentially offhand that I can think of is aging[1].
- ^
Double-exponential in the tail - https://en.wikipedia.org/wiki/Gompertz%E2%80%93Makeham_law_of_mortality.
↑ comment by gwern · 2022-03-27T14:43:47.192Z · LW(p) · GW(p)
I'd suggest at least part of it is that any super-light-tailed distribution more light-tailed than the normal works out in practice to simply looking like it has a hard bound or a range due to rarity and the resulting difficulty of verifying any such rare instance. You would not see them, and you would not know if you did: so for almost all intents and purposes, any super-light-tailed distribution's "tail" is just a hard cutoff or threshold or range or bound. And we see those all the time.
Even for the normal or Gompertz, there's a point at which you can safely say "the upper bound is X; you can wait the age of the universe, and you'll still never see a >X". Where are the 10-foot tall people, much less the 20-foot tall people? If you didn't have enormously detailed and large records of human life-expectancies, who would blame you for saying "the Almighty hath ordained the postdiluvian span of man's year at naught more than six score of years"?
Now, suppose life-expectancies were ultra light-tailed; this would mean in practice something like a 'Jeanne Calment'-level outlier would not survive into her 120s, instead, she would drop dead 2 minutes after her 80th birthday instead of, like her rivals, dropping dead 1 minute after their 80th birthday. How would you know that, instead of saying, "hm, I guess the watch of the nurse recording her birth certificate was a bit slow" (as you would correctly say in the 99 other such cases which were false positives)?
Perhaps in a physics experiment which has been exactly quantified and where you've spent decades systematically eliminating every source of noise, you can go 'oh my god, a particle decayed after 1.01 picoseconds instead of 1.00 picoseconds! This changes everything - it's not a hard bound, it's a super-light-tailed distribution, just as predicted by Katz et al 1971!' But not anywhere else.
Replies from: TLWcomment by adamk · 2022-03-26T16:01:10.903Z · LW(p) · GW(p)
I would honestly be interested to see a detailed writeup with good examples of this "maybe amazing" vs "probably good" distinction.
A subtlety here is that the traits that make a candidate a potential outlier are often very different from the traits that would make them “pretty good,” so improving your filtering process to produce more “pretty good” candidates won’t necessarily increase the rate of finding outliers, and might even decrease it.
Most important point I'd still want to grok is what this "might even decrease it" looks like. What are industry examples of metrics or filtering processes that can differentiate 95th percentile samples from 99.9th percentile samples? And what are some of the qualitative shifts you see between them? I suspect the art of identifying 99.9th percentile samples goes beyond looking for "really, really good" 95th-percentile-ish things.
Replies from: gwern↑ comment by gwern · 2022-03-26T19:29:06.689Z · LW(p) · GW(p)
https://www.lesswrong.com/posts/dC7mP5nSwvpL65Qu5/why-the-tails-come-apart [LW · GW] is relevant.
comment by jmh · 2022-03-24T01:23:42.585Z · LW(p) · GW(p)
Two things that came to mind for me while reading were:
- Patients is most definitely a virtue in heavily tailed setting.
- One might want to keep in mind that rejecting a bad/suboptimal option is not failure so don't let that get to you.
I think the idea of having a target (how good the sought after X should be) is pretty critical in the search activity. But I also think in most situations one finds themself you are not looking for one spot to fill. So sorting one's needs that are to be filled into a distribution (perhaps normal?) with something of a targeted mean/median might be good too. For instance in a hiring case once you're past a rather small size multiple positions will likely be open -- particularly in a growth stage. Looking for those "best" fits for everything might not allow success of the organization.
comment by Alex K. Chen (parrot) (alex-k-chen) · 2024-01-29T16:38:24.426Z · LW(p) · GW(p)
Has anyone considered.. spiritual outliers?
ALSO outliers in neurodevelopmental trajectories/cross-correlations in how fast one region of their brain develops relative to another region of their brain.
[there was someone at USC who presented at https://web.cvent.com/event/82cd3c8a-5f63-4fb2-b394-b0b7feb49093/summary who had a talk on outliers at a more neurophysiological level]. Maybe not QUITE the level of outlier we're looking for, but more directionally so
19. Title: PoserDeep Isolation Forest Outlier Analysis of Large Multimodal Adolescent Neuroimaging Data
Presenting Author: Eric Silberman
↑ comment by Mo Putera (Mo Nastri) · 2024-01-30T11:35:44.554Z · LW(p) · GW(p)
Say more? (e.g. illustrative / motivating examples, related reading etc)