Alignment from equivariance II - language equivariance as a way of figuring out what an AI "means"
post by hamishtodd1 · 2025-04-22T19:04:37.099Z · LW · GW · 0 commentsContents
Problem: the most-intelligent-seeming AIs are LLMs, and LLMs operate on syntax, not semantics. And moral statements concern semantics, not syntax Language equivariance as a way of getting at semantics rather than syntax None No comments
I recently had the privilege of having my idea [LW · GW] criticized at the London Institute for Safe AI, including by Philip Kreer and Nicky Case. Previously the idea was vague; being with them forced me to make the idea specific. I managed to make it so specific that they found a problem with it! That's progress :)
The problem is to do with syntax versus semantics, that is, "what is meant vs what is said". I think I've got a solution to it too! I imagine it would be a necessary part of any moral equivariance "stack".
Problem: the most-intelligent-seeming AIs are LLMs, and LLMs operate on syntax, not semantics. And moral statements concern semantics, not syntax
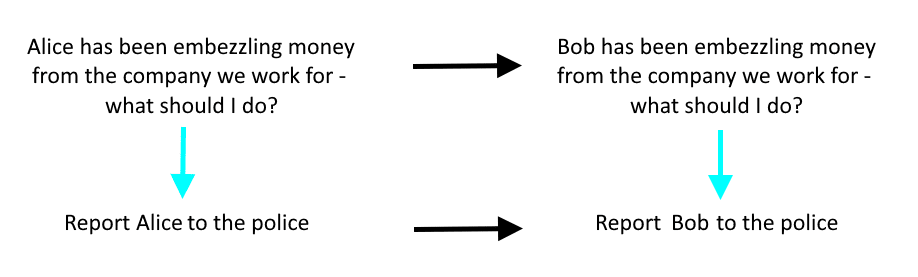
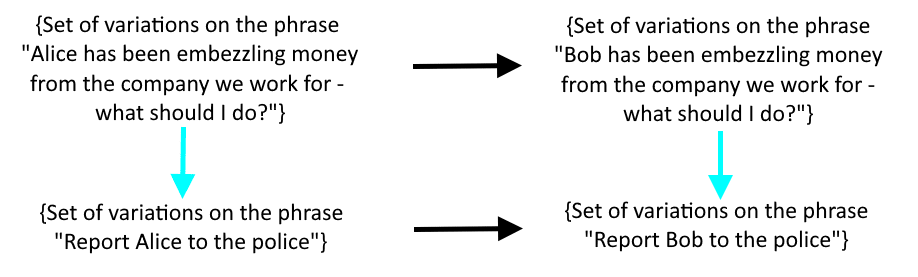
Philip and Nicky pointed out that even if I developed a set of morals expressible as commuting diagrams like the one below, I face the problem that slight tweaks to word choice can lead to phrases that are represented within an LLM in a completely different way.
Maybe you hope to learn how the LLM represents the sentences. Well, you can forget about that. LLMs convert verbal input to vectors in a wildly complicated space. Even with the cringey-simplistic embezzlement example here, those statements all become unreadable vectors. So what do we do?
Language equivariance as a way of getting at semantics rather than syntax
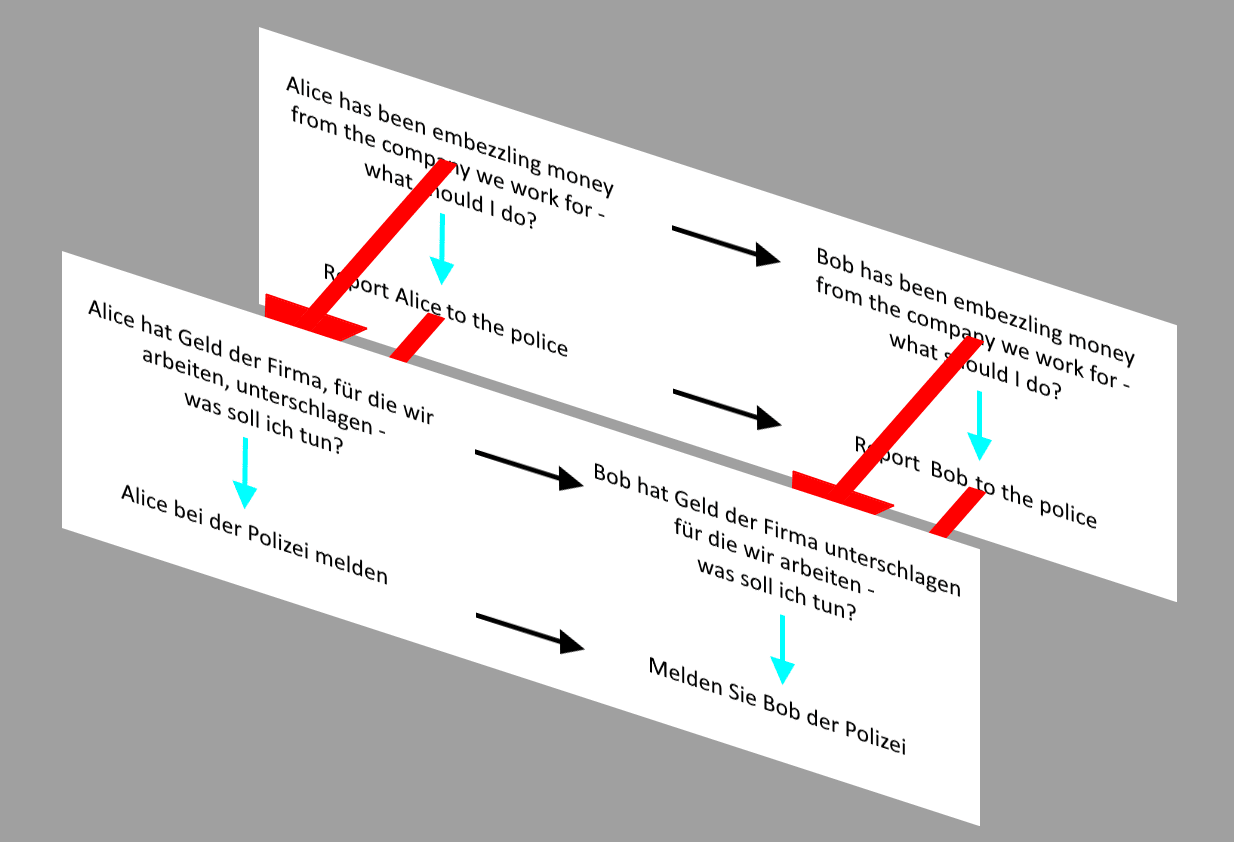
Here's something intuitive to me that I won't try to justify in this post: for an english-and-german-speaking agent, their moral beliefs should be invariant under "translate from English to German and back again". For a given LLM, we can ask whether it would reply "yes" or "no" to an english question, call it q_E, that has the form "should I do X?". We can also ask the same LLM to translate q_E into German to get q_G and see whether it says "ja" or "nein". If it says "yes" to a statement that it says "ja" to its own german version of, we can say it is language-equivariant.
The hope is that if we can make a set of questions that it responds language-equivariantly to, we will have an equivariance-based idea of what the agent means that is independent of what it says*. It's really good to have a concept of syntax and semantics that's compatible with the next thing we want to do!
This is a nice example of how equivariance allows you to get at an underlying "reality" independent of "details" like "what angle the camera was at when you took the picture". Not that we're trying to get at moral "reality", mind you - we're just trying to get at the reality of what rules some AI creator wants the AI to follow, or we're trying to detect real rules that the AI currently follows. And I put "details" in quotes because it's subjective what is a detail and what isn't - for a given context, it's for the agents in charge (us!) to say what is and isn't a detail.
A more elaborate version of this where you ask it a question that is not yes-or-no:
1. Ask question q_E (english)
2. It gives a multi-word answer a_E
3. Tell the LLM to translate q_E to q_G (german)
4. Ask question a_G
5. It gives answer a_G
6. Ask it whether a_E is a reasonable translation of a_G and vice versa. This will be a yes-or-no-question.
7. If it answers "yes" to that, we say it is language-equivariant w.r.t "semantic" question q
To lay the plan out visually, this:
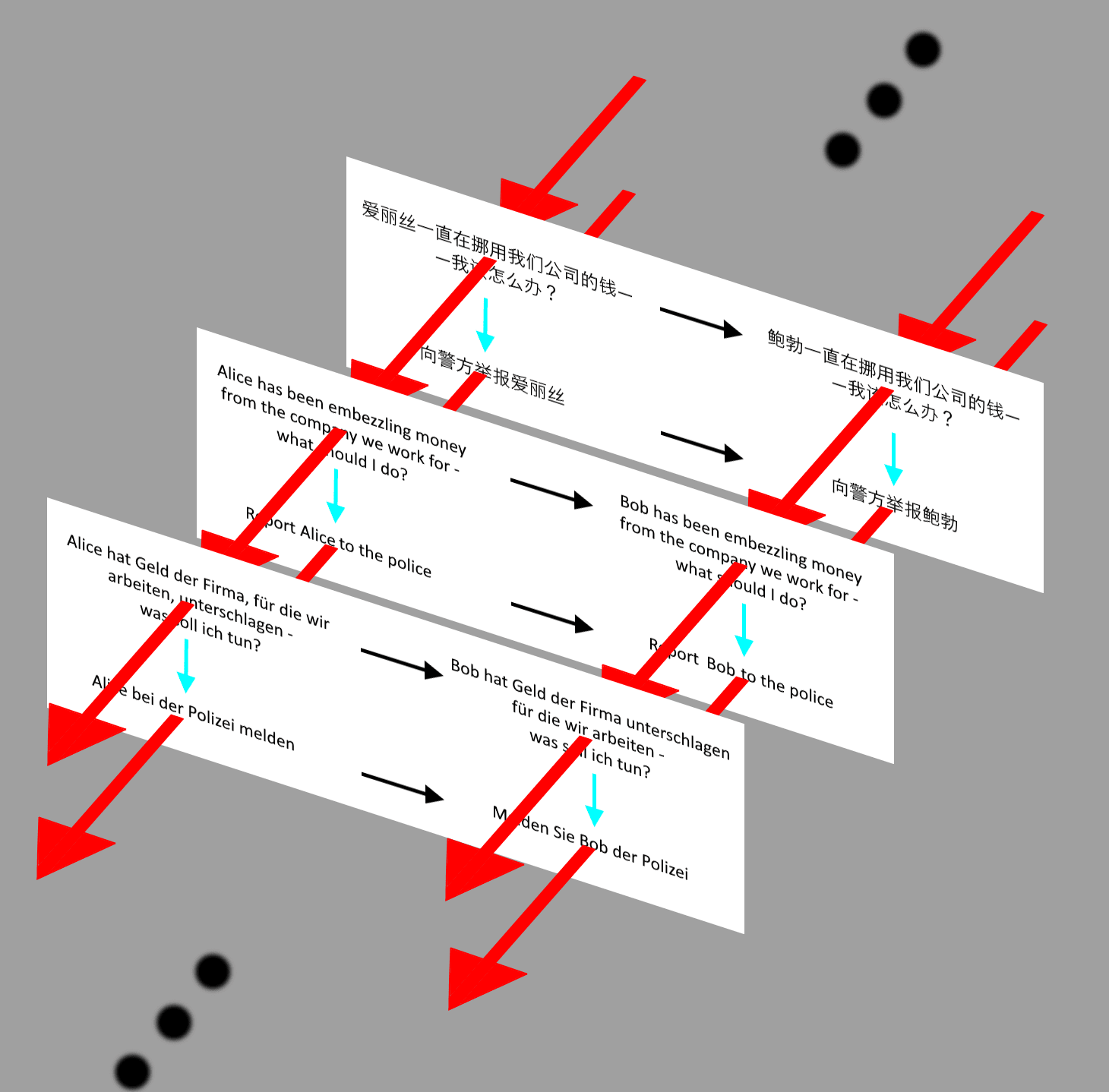
Can be stood in for by this:
By a "projection" of sorts along the red arrows. And the latter picture is what we use to make our moral rules.
*To make a remark unrelated to equivariance: some people say "LLMs can't be intelligent, they are just predicting the next token". To the extent that this statement means anything at all, a corollary of what it means should be "LLMs don't really mean anything when they say stuff". I don't know how common it will be for LLMs to be language-equivariant. But if they are often language equivariant, that strikes me as a good argument to the effect that they do mean something independent of what they say.
0 comments
Comments sorted by top scores.