"LLMs Don't Have a Coherent Model of the World" - What it Means, Why it Matters
post by Davidmanheim · 2023-06-01T07:46:37.075Z · LW · GW · 2 commentsContents
Humans What is Understanding? What is a Model of the World? Multiple models and Physics. Large Language Models, Multiple Models, and Improv Improv is partly a failure to have a consistent model Many other issues are related Conclusion None 2 comments
There are a variety of problems with LLMs, and I want to argue that they are all somewhat related, and are related to the idea of having a model of the world. This seems useful both as a conceptual model for thinking about why AI is unsafe, and to better explain why proposals like Davidad's [AF · GW] are focused on the idea of a world-model.
What are the problems I'm referring to?
Machine learning models are often said to not be causal, to have only correlational understanding. This is partly true; their causal reasoning in LLMs exists, but at a different level than the model itself. Similarly, most machine learning systems fail to operate well outside of situations that resemble their training data. LLMs are known to hallucinate facts, and will also contradict themselves without noticing, or will confuse fact and fiction. They are also able to be induced to be racist, sexist, or malicious. In this post, I try to explain what a coherent world model is, and gesture towards why it could be a missing ingredient for addressing all these problems.
Humans
Humans are a good place to start when thinking about what works or does not work. And humans have largely coherent world models, and are largely rational[1], goal-seeking agents. We expect things to work in certain ways. We can be wrong about the world, but usually do so in ways that are coherent. We can predict what will occur in a variety of domains. When asked questions about the world, we may not know the answer, but we know when we are guessing. Humans can discuss fiction while knowing that it is not a factual description of the world, since part of our world model is the existence of fiction. Obviously, these world-models are imperfect, because humans understand the world imperfectly, but there are a variety of things we do well that machine learning systems do not. Some argue that these models, and the failures they exhibit, are central to AI risks as well.
What is Understanding? What is a Model of the World?
It is, of course, clear that machine learning models do little similar to what humans have. Scientific or statistical models, for example, might correctly predict outcomes in some specific domain, but they don't "understand" it. A human might know how orbital mechanics works, the same way an algebraic expression or computer program can predict the positions of satellites, but the human's understanding is different. Still, I will adopt a functionalist view of this question, since the internal experience of models, or lack thereof, isn't especially relevant to their performance.
Still, can a stochastic parrot understand? Is having something that functions like a model enough? Large language models (LLMs) do one thing: predict token likelihoods and output one, probabilistically.
But if an LLM can explain what happens correctly, then somewhere in the model is some set of weights that contain information needed to probabilistically predict answers. GPT-2 doesn't "understand" that Darwin is the author of On the Origin of Species, but it does correctly answer the question with a probability of 83.4% - meaning, again, that somewhere in the model, it has weights that say that a specific set of tokens should be generated with a high likelihood in response. (Does this, on its own, show that GPT-2 knows who Darwin was or what evolution is? Of course not. It also doesn't mean that the model knows what the letter D looks like. But then, neither does asking the question to a child who memorized the fact to pass a test.)
Multiple models and Physics.
But what more is needed? In theory, an ideal reasoner would have a consistent, coherent model of the world on which to base its actions. It would answer questions in ways that are consistent with that model, and know which parts of the model are relevant and when. And humans sometimes have trouble with this. For example, on a physics test, students might be given 4 or 5 pieces of information - say, mass, material volume, temperature, velocity, and position, and asked to derive some quantity, say, how much energy it will transfer to the ground on impact. Students then need to figure out which equation(s) to use and need to realize they need to ignore some of the values provided. Students who understand the topic somewhat well will presumably hone in on velocity, position, and mass, and notice this is a ballistics question. (Those who understand physics very well might also consider convective heat transfer on landing.) Students that understand the topic less well might simply pattern match to find which equations have some of the variables they were given.
This is inevitable, because a single model for everything isn't useful. From a reductionist standpoint, at least, everything is physics. If you want to choose a good restaurant, you can just simulate the world at the level of quantum physics in different scenarios, run a few billion scenarios for each restaurant choice, and choose the one with the best outcomes on average. This doesn't work, of course. In reality, you want to use a different model, for example, by comparing the Yelp reviews of different restaurants. And in a similar way, when thinking about a physics problem like the one above, you choose to use a simplified ballistics model, or a slightly more complex heat transfer model.
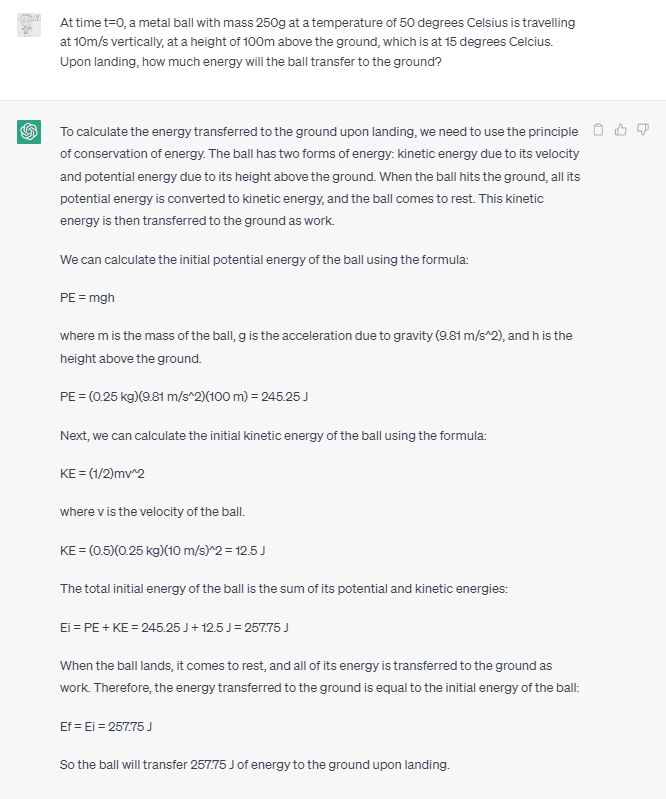
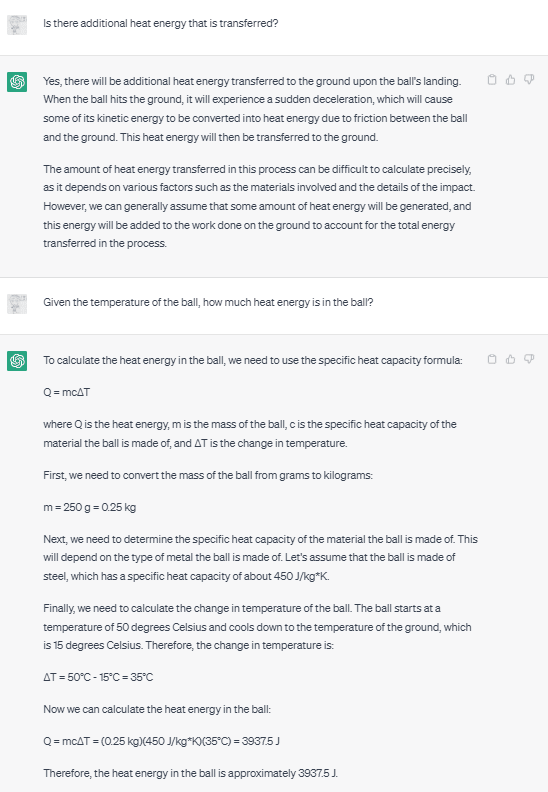
One framing for the idea of model switching is that LLMs are in some sense simulating different characters. When asked a question from a physics test, they simulate a physics student. We can think about this as something like improv - at each point, they pick which character they are playing, and adapt to the situation. And given the initial framing, they simulated a beginning physics student, but when pushed to talk about heat energy, they will simulate a slightly different character. (An amusing example of this type of roleplaying is the "granny" jailbreak.)
Large Language Models, Multiple Models, and Improv
As mentioned above, LLMs are just predicting tokens and outputting words. That means that in some sense, they just know human language, and that is not a model of different people, or of physics. But again, their ability to output meaningful answers to questions means that the LLM also contains an implicit "understanding" of many specific topics, and an implicit representation of the types of things different people say. Given the complexity of the things LLMs can talk about, the implicit models which exist are, in a very relevant sense, equivalent to the types of models that humans use to explain the world. However, the fact that the equivalent models are implicit also means they are deeply embedded within the poorly understood LLMs themselves.
For humans, or anything else expected to reason about the world, part of having a coherent world model is understanding when and how to use different models, or different parts of the model. This happens in multiple ways. For example, biologists have an understanding of chemistry and physics, but when thinking about how a hormone is affecting a person, they will use their heuristic models about hormonal effects rather than trying to think through the chemical interactions directly. They use a different model.
On the other hand, sometimes models are used in ways that are less about prediction. When asked about a question that is sensitive in some way, for better or for worse, many humans will switch from using a model that is primarily intended to maximize predictive accuracy to one which is about sensitivity to others, or about reinforcing their values or opinions. When asked whether something is possible, they will use a model for whether it is desirable, or when asked whether they can succeed, they will switch to a model of affirmation rather than a model of the likelihood of success.
Like humans, LLMs will switch between their different models of the world. When the scenario changes, they can adapt and change which conceptual models they are using, or thinking about them as playing improv, they can switch characters.


And large language models, like humans, do the switching so contextually, without explicit warning that the model being used is changing. They also do so in ways that are incoherent.
Improv is partly a failure to have a consistent model
One failure of current LLMs is that they "hallucinate" answers. That is, they say things that are false, trying to look competent. For example, if they say something and think there should be a citation to a journal article, they will put one in, and if they don't have an actual article, they will make up a plausible seeming one. Improv isn't about accuracy, it's about continuing to play. And because they are trained to play improv based on human data, like humans, they will pretend to know the answer. Even when confronted, they don't usually just say "whoops, I made that up, I don't actually know."
This is implicit in the way that LLMs switch between conceptual models or roles. I suspect the mindsets, and therefore the roleplaying attempts, are coherent only because human thinking is often similar, and the language used often indicates which thought modes are relevant. But this means changes can quickly shift the model's roleplaying behavior. For example, an LLM that can answer a question about the kinetic energy of a bludger probably doesn't have a clear boundary between models of fantasy and models of reality. But switching seamlessly between emulating different people is implicit in what they are attempting to do - predict what happens in a conversation.
It is clear that RLHF can partially fix that, but it's limited - remember, the roleplaying and implicit models are deeply embedded in the LLM, since the implicit models are learned from a diverse dataset. Fine-tuning the model can greatly move the distribution of which mindsets are going to be represented. Prompt design can also bias the model towards (at least initially) representing a specific type of character. These methods cannot, however, override the entirety of the initial training.
Asking it to roleplay granny, or any other "escape" method, is pushing it to no longer work with the part of the model that learned not to talk about dangerous or problematic things.
Many other issues are related
Racism, sexism, and bias are also (partly) failures to use the right roleplaying character, and that potentially comes from the inability to separate the implicit world models and mindsets used by those characters. When an LLM that isn't fine-tuned is playing its typical role, it simulates a typical person or interaction from its dataset, or at least one from the subset of its dataset that is likely conditional on the text so far, as weighted by the fine-tuning that was performed. But many of the people or interactions from the training data are biased, implicitly or explicitly. Adding to the difficulty is that we want the system to do something that most people don't often do, and which therefore isn't well represented in the training data; be incredibly careful to avoid offending anyone, even implicitly, while (hopefully) prioritizing substantive responses over deferring completely on anything that touches on race, gender, or other characteristics[2].
Even if the proper behavior is present in the training data in sufficient quantities to allow it to emulate the behavior, LLMs don't clearly separate the different people. Instead, they are implicitly training to some weighted mixture of the implicit models - so they aren't necessarily roleplaying someone careful about avoiding bias. RLHF and fine-tuning can modify the distribution, but don't erase the parts of the model that represent biased thinking - and it's not even clear that they can.
Conclusion
Hopefully, this is useful for people trying to understand what exactly people care about when they talk about whether LLMs and other systems have a world model. Even if not, it was useful for me to think through the issues. I'd be happy if people think that this is obvious, in which case I'd appreciate hearing that. I'd also appreciate hearing if I'm confused in some way, or haven't stepped through the arguments clearly enough.
- ^
Even human irrationality is mostly about deviation from otherwise very good reasoning.
- ^
Otherwise, GPT-5 could consist entirely of the code: print("As an AI model trained by OpenAI, I wish to refrain from implicitly or explicitly upsetting anyone, and you should consult a different source.")
2 comments
Comments sorted by top scores.
comment by __RicG__ (TRW) · 2023-06-01T16:29:28.109Z · LW(p) · GW(p)
I am quite confused. It is not clear to me if at the end you are saying that LLMs do or don't have a world model. Can you clearly say on which "side" do you stand on? Are you even arguing for a particular side? Are you arguing that the idea of "having a world model" doesn't apply well to an LLM/is just not well defined?
Said this, you do seem to be claiming that LLMs do not have a coherent model of the world (again, am I misunderstanding you?), and then use humans as an example of what having a coherent world model looks like. This sentence is particularly bugging me:
For example, an LLM that can answer a question about the kinetic energy of a bludger probably doesn't have a clear boundary between models of fantasy and models of reality. But switching seamlessly between emulating different people is implicit in what they are attempting to do - predict what happens in a conversation.
In the screenshots you provided GPT3.5 does indeed answer the question, but it seem to distinguish it being not real (it says "...bludgers in Harry Potter are depicted as...", "...in the Harry Potter universe...") and indeed it says it doesn't have specific information about their magical properties. I also, in spite of being a physicist with knowledge that HP isn't real, I would have gladly tried to answer that question kinda like GPT did. What are you arguing? LLMs seem to have the distinction at least between reality and HP or not?
And large language models, like humans, do the switching so contextually, without explicit warning that the model being used is changing. They also do so in ways that are incoherent.
What's incoherent about the response it gave? Was the screenshot not meant to be evidence?
The simulator [LW · GW] theory (which you seem to rely on) is, IMO, a good human-level explanation of what GPT is doing, but it is not a fundamental-level theory. You cannot reduce every interaction with an LLM as a "simulation", somethings are just weirder. Think of pathological examples of the input being "££££..." repeated 1000s of times: the output will be some random, possibly incoherent, babbling (funny incoherent output I got from the API inputting "£"*2000 and asking it how many "£" there were: 'There are 10 total occurrences of "£" in the word Thanksgiving (not including spaces).'). Notice also the random title it gives to the conversations. Simulator theory fails here.
In the framework of simulator theory and lack of world model, how do you explain that it is actually really hard to make GPT overtly racist? Or how the instruct finetuning is basically never broken?
If I leave a sentence incomplete why doesn't the LLM completes my sentence instead of saying "You have been cut off, can you please repeat?"? Why doesn't the "playful" roleplaying take over, while (as you seem to claim) it takes over when you ask for factual things? Do they have a model of what "following instruction means" and "racisms" but not what "reality" is?
To state my belief: I think hallucinations, non-factuality and a lot of the problems are better explained by addressing the failure of RLHF and not from a lack of a coherent world model. RLHF apparently isn't that good at making sure that GPT-4 answers factually. Especially since it is really hard to make it overtly racist. And especially since they reward it for "giving it a shot" instead of answering "idk" (because that would make it answer always "idk"). I explain it as: in training the reward model a lot of non-factual things might appear, and even some non-factual thing are actually the preferred response that human like.
Or it might just be the autoregressive paradigm that once it make a mistake (just by randomly sampling the "wrong" token) the model "thinks": *Yoda voice* 'mhmm, a mistake in the answer I see, mistaken the continuation of the answer should then be'.
And the weirdness of the outputs after a long repetition of a single token is explained by the non-zero repetition penalty in ChatGPT and so the output will kinda resemble the output of a glitch token.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2023-06-01T17:05:33.458Z · LW(p) · GW(p)
Yes, I'm mostly embracing simulator theory here, and yes, there are definitely a number of implicit models of the world within LLMs, but they aren't coherent. So I'm not saying there is no world model, I'm saying it's not a single / coherent model, it's a bunch of fragments.
But I agree that it doesn't explain everything!
To step briefly out of the simulator theory frame, I agree that part of the problem is next-token generation, not RLHF - the model is generating the token, so it can't "step back" and decide to go back and not make the claim that it "knows" should be followed by a citation. But that's not a mistake on the level of simulator theory, it's a mistake because of the way the DNN is used, not the joint distribution implicit in the model, which is what I view as "actually" what is simulated. For example, I suspect that if you were to have it calculate the joint probability over all the possibilities for the next 50 tokens at a time, and pick the next 10 based on that, then repeat, (which would obviously be computationally prohibitive, but I'll ignore that for now,) it would mostly eliminate the hallucination problem.
On racism, I don't think there's much you need to explain; they did fine-tuning, and that was able to generate the equivalent of insane penalties for words and phrases that are racist. I think it's possible that RHLF could train away from the racist modes of thinking as well, if done carefully, but I'm not sure that is what occurs.