(tentatively) Found 600+ Monosemantic Features in a Small LM Using Sparse Autoencoders
post by Logan Riggs (elriggs) · 2023-07-05T16:49:43.822Z · LW · GW · 1 commentsContents
Dictionary Learning: Short Explanation Feature Case Study Top-activating Examples for feature #52 Ablate Context Ablate Feature Direction Uniform Examples Created Examples Comparing to the Neuron Basis Range of MCS Features Failures Conclusion None 1 comment
Using a sparse autoencoder, I present evidence that the resulting decoder (aka "dictionary") learned 600+ features for Pythia-70M layer_2's mid-MLP (after the GeLU), although I expect around 8k-16k features to be learnable.
Dictionary Learning: Short Explanation
Good explanation here & original here [LW · GW], but in short: a good dictionary means that you could give me any input & I can reconstruct it using a linear combination of dictionary elements. For example, signals can be reconstructed as a linear combination of frequencies:
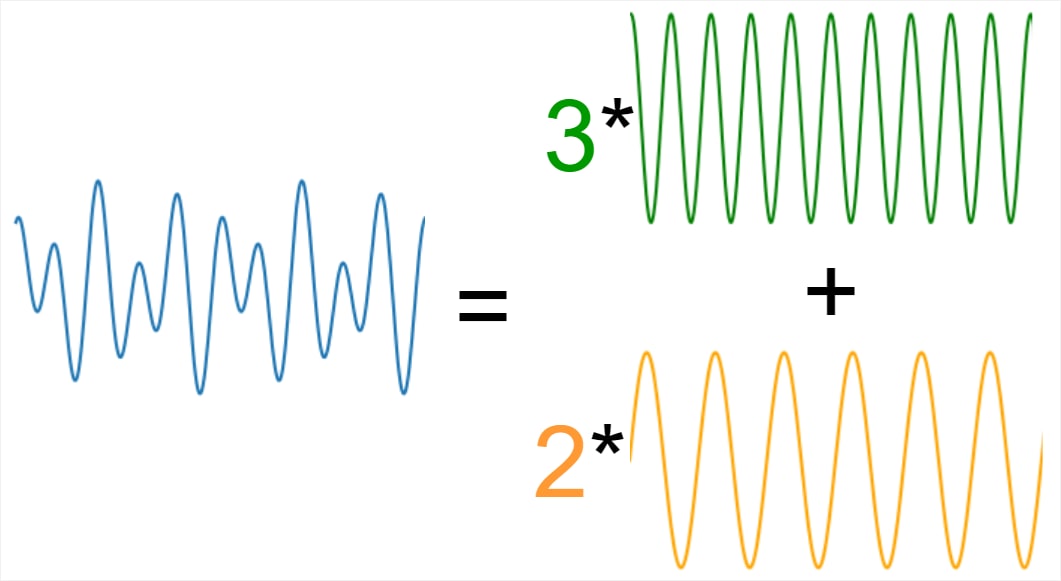
In the same way, the neuron activations in a large language model (LLM) can be reconstructed as a linear combination of features. e.g.
neuron activations = 4*([duplicate token] feature) + 7*(bigram " check please" feature).
Big Picture: If we learn all the atomic features that make up all model behavior, then we can pick & choose the features we want (e.g. honesty)
To look at the autoencoder:
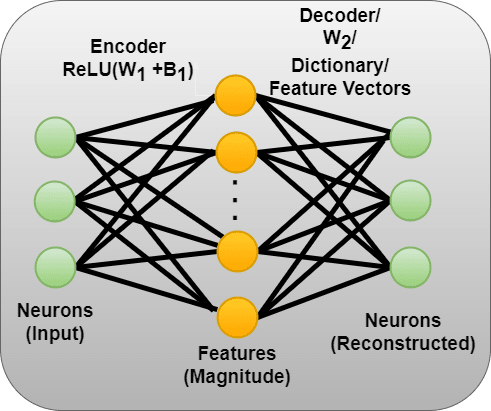
So for every neuron activation (ie a 2048-sized vector), the autoencoder is trained to encode a sparse set of feature activations/magnitudes (sparse as in only a few features "activate" ie have non-zero magnitudes), which are then multiplied by their respective feature vector (ie a row in the decoder/"dictionary") in order to reconstruct the original neuron activations.
As an example, an input is " Let u be f(8). Let w", and the decomposed linear combination of features are:
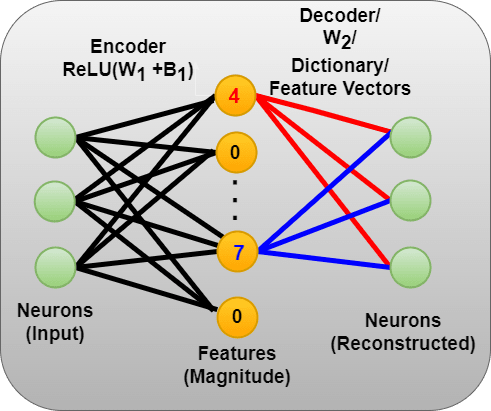
[" Let u be f(8). Let w"] = 4*(letter "w" feature) + 7*(bigram "Let [x/w/n/p/etc]" feature)
Note: The activation here is only for the last token " w" given the previous context. In general you get 2048 neuron activations for *every* token, but I'm just focusing on the last token in this example.
For the post, it's important to understand that:
- Features have both a feature vector (ie the 2048-sized vector that is a row in the decoder) & a magnitude (ie a real number calculated on an input-by-input basis). Please ask questions in the comments if this doesn't make sense, especially after reading the rest of the post.
- I calculate Max cosine similarity (MCS) between the feature vectors in two separately trained dictionaries. So if in dictionary 0 is "duplicate tokens", and in dictionary 1 has high cosine similarity, then I expect both to be representing "duplicate tokens" and for this to be a "real" feature [Intuition: there are many ways to be wrong & only one way to be right]
Feature Case Study
Top-activating Examples for feature #52
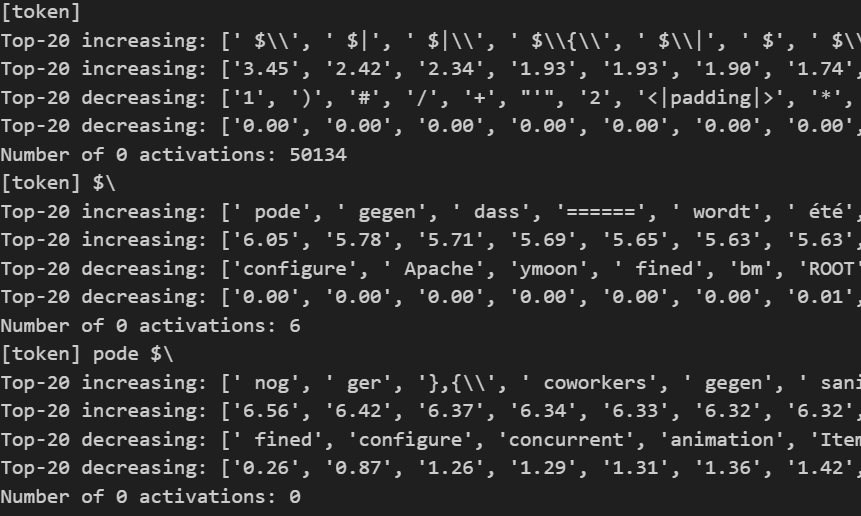
I ran through 500k tokens & found the ones that activated each feature. In this case, I chose which had an MCS of ~0.99. We can then look at the datapoints that maximally activate this feature. (To be clear, I am running datapoints through Pythia-70M, grabbing the activations mid-way through at layer 2's MLP after the GeLU, & running that through the autoencoder, grabbing the feature magnitudes ie latent activations).

Blue here means this feature is activating highly for that (token,context)-pair. The top line has activation 3.5 for the first " $" & 5 for the second. Note that it doesn't activate for closing $ and is generally sparse.
Ablate Context
Ablate the context one token at a time & see the effect on the feature magnitudes on last token. Red means the feature activated less when ablating that token.

To be clear, I am literally removing the token & running it through the model again to see the change in feature activation at the last position. In the top line, removing the last " $" makes the new last token to be " all" which has an activation of 0, so the difference is 0-5 = -5, which is value assigned to the dark red value on " $" (removing " all" before it had no effect, so it's white which means 0-difference)
Proposed Meaning: These detect $ for latex. Notably removing token )$ makes the final “ $” go from 5 to 3.5 activation. Similarly for “where/let/for”.
For reference: The darkest blue (ie “ =”) makes it go up by 0.08, so there really isn't much of an effect here.
Ablate Feature Direction
We can ablate the feature direction by subtracting the original neuron activation by the feature’s (direction*magnitude), and see the effect on the model's output logits on the actual tokens. To clarify, the dictionary features are supposed to reconstruct the neuron activation using a sparse linear combination of features; I am removing one of those feature directions.

As an example, removing this feature direction means the model is worse at predicting the tokens in red & better at predicting the tokens in blue.
Ablating this feature direction appears to only affect latex-related tokens, but the direction can both increase & decrease the log-prob. It will trivially not affect any tokens before the first feature activation (because I subtract by direction*magnitude, and the magnitude is 0 there).
Uniform Examples
Maybe we’re deluding ourselves about the feature because we’re just looking at top-activating examples. If this is *truly* a monosemantic feature, then the entire activation range should have a similar meaning. So I look at datapoints across the bins of activations (ie sample a feature with activation [1,2], another from [2,3], ...)

It does seem to be mainly latex. See the second to last line which barely activates (.14), and is a dollar sign ("$ 100 billion tariff"). Maybe the model is detecting both math words & typically money words. Let's check w/...
Created Examples

Notably, including the word “sold” immediately shoots down the activation! Also, it seems that combining math words increases it.
To verify this, I’ll run the sentence “ for all $”, but prepend it w/ a token & see the effect on the feature activation. Instead of choosing a specific token, I can simply run ALL tokens in the vocab, printing the top-increasing & top-decreasing tokens.

The most-increasing are definitely ending $ latex, but I’m not quite sure what all of them are. Like detecting an ending $ is most indicative?
The most-decreasing are indeed more related to the money-version of $, and there’s only 97 of them!
Checking with appending or prepending to the word “ tree”:
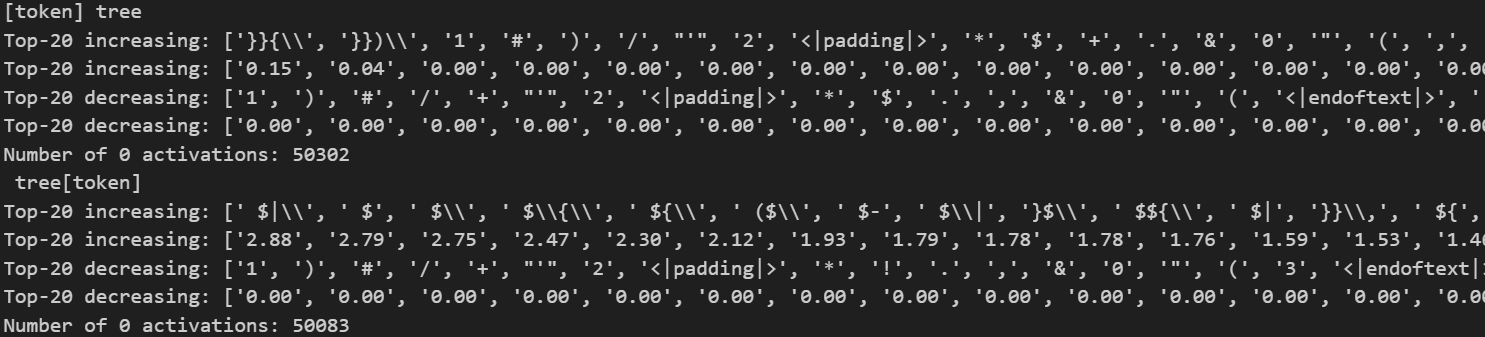
Yep, this fits within the hypothesis.
We can also just check the most activating tokens on its own
Comparing to the Neuron Basis
Does this feature net us anything over using the normal neuron basis? If this is only learning a monosemantic neuron, then that's pretty lame!
We can first check how many neurons activate above a threshold for the top-10 feature activating examples (ie a neuron must activate above threshold for all 10 examples)gh-MCS Features
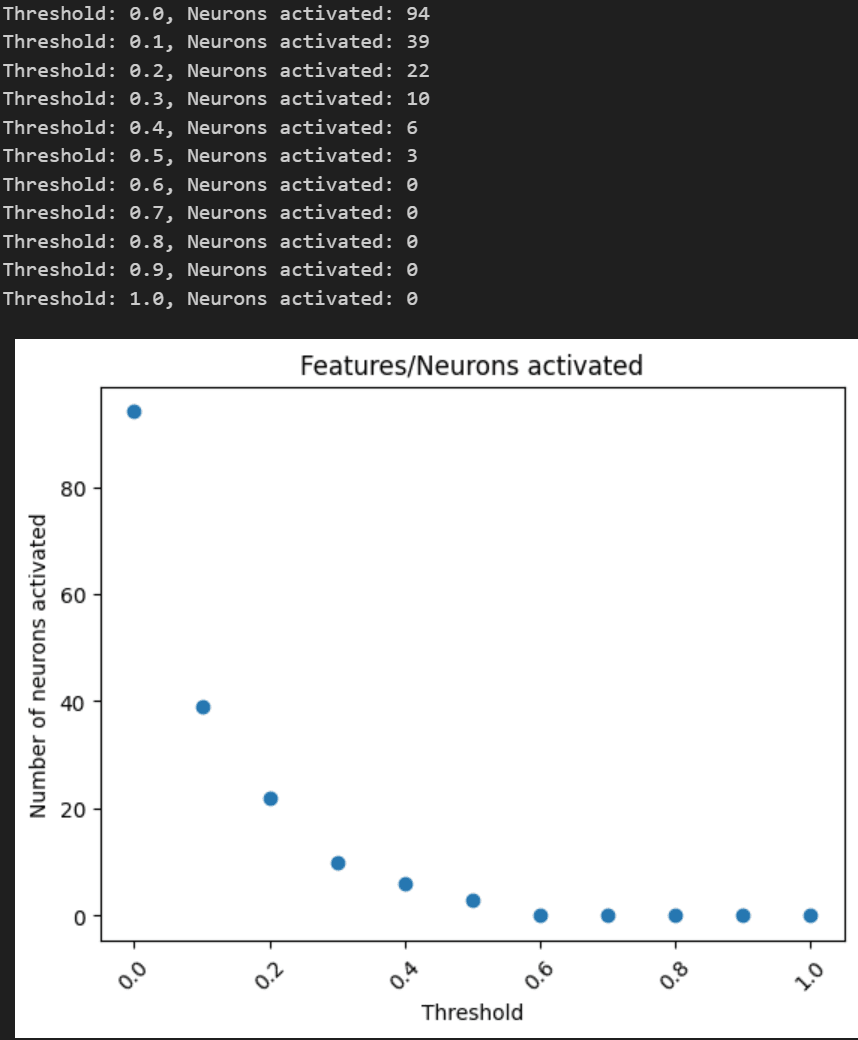
Notably it's a lot of neurons for above 0, but then goes to 3 for 0.5. However, we don't really know the statistics of neuron activations. Maybe some neuron's entire range is very tiny? So, we can see how many neurons are above a threshold determined by that neuron's quantiles.
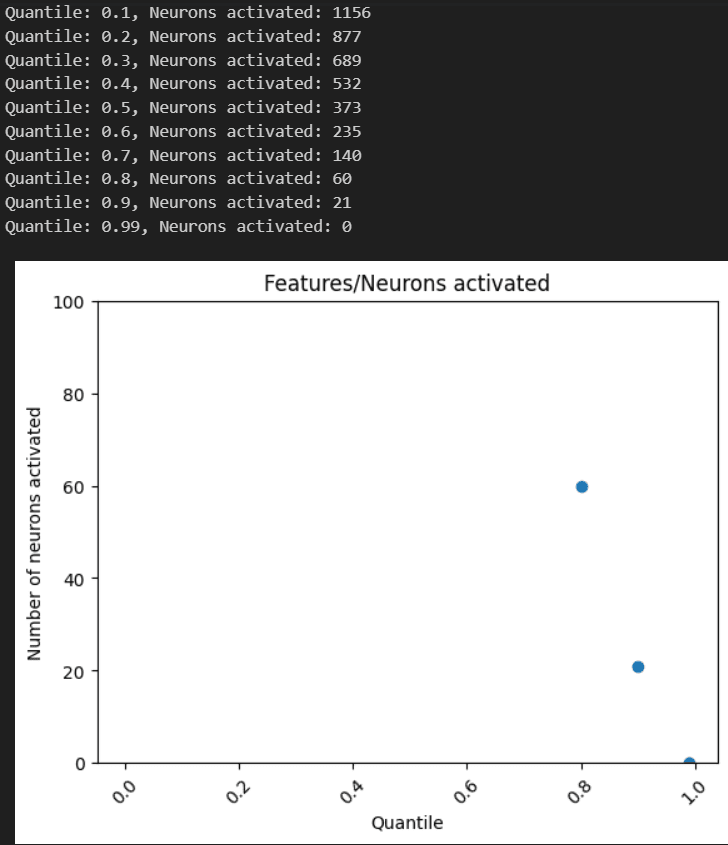
Here, 60 neurons are activating in above their 80th quantile, but it's unclear where to draw the line still.
Another way is to look at the feature vector associated w/ this feature. It is 2048 numbers representing how much it affects each neuron, so if it's 0, it doesn't affect a neuron at all. Additionally, I'll multiply by the max-activation of that feature to show the scale of the effect on the neurons.
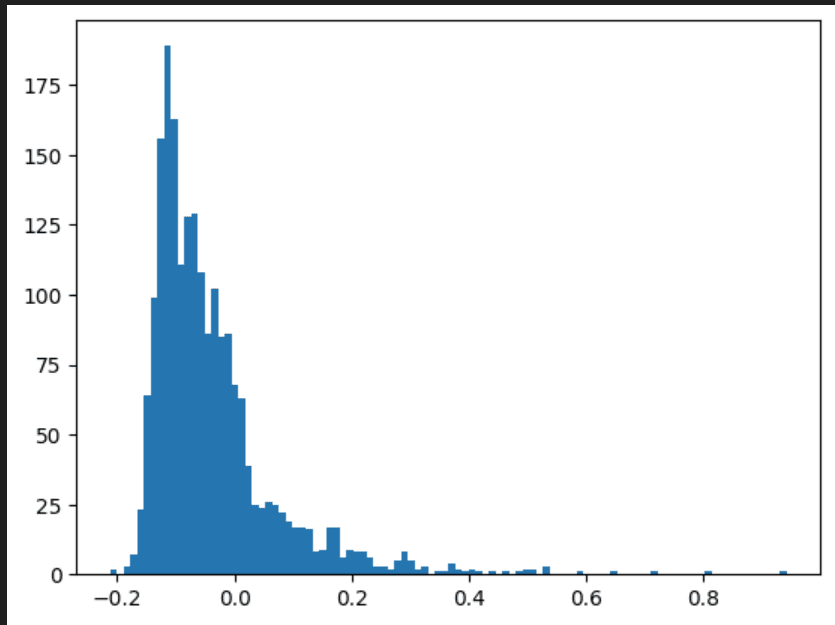
So a few datapoints to indicate somewhere between 3 & 80 neurons, maybe several hundred depending on how you interpret it.
We can also check across the top-50 high MCS features for activations
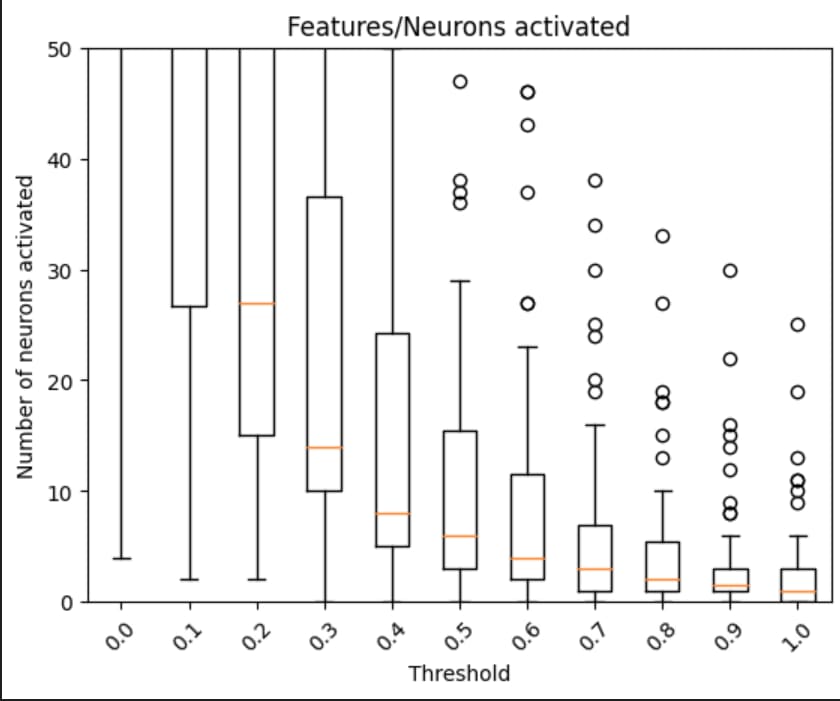
As a contrast, I will also being showing an equivalent graph, but from a different dictionary that seems to have learned the identity (ie we're just looking at the neuron basis)
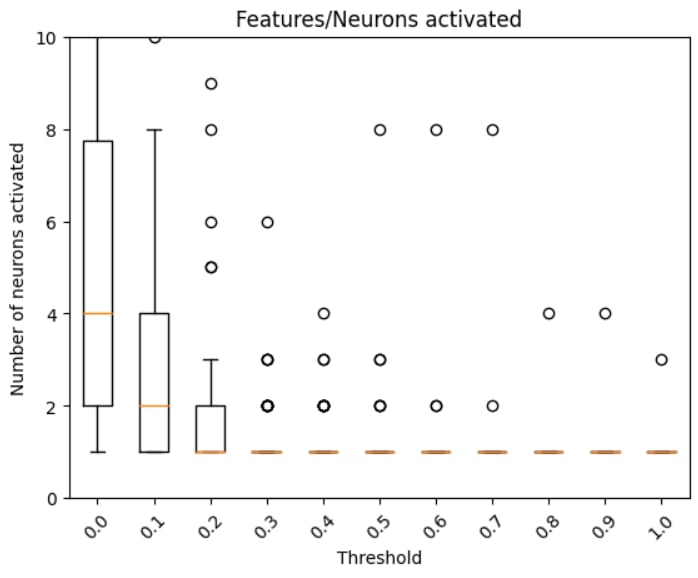
Here, the vast majority of features correlate w/ only 1 neuron activation (at least above 0.3).
Going through the images quickly for a "feature" here:
Max activation:

Ablating context:

Logit Diff:

Uniform Examples:

I'm really unsure on what this feature could even represent to even come up w/ a testable hypothesis
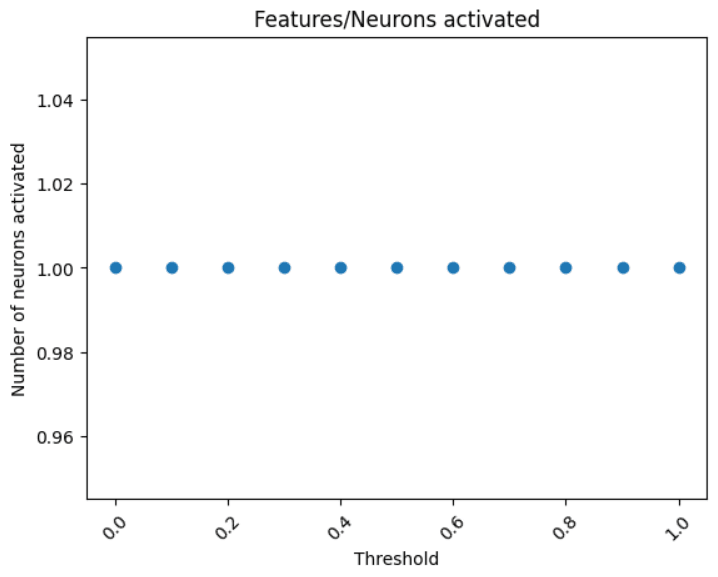
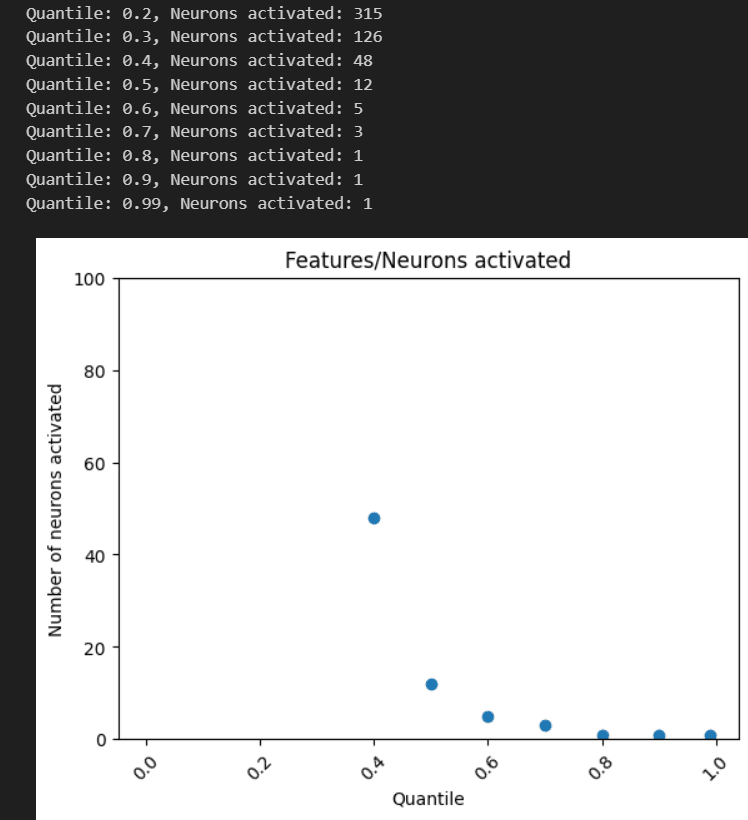
Notably, it drops to 1 neuron after 0.8, so w/ a threshold of 0.8, so some evidence for the original dictionary feature representing ~60 neurons.
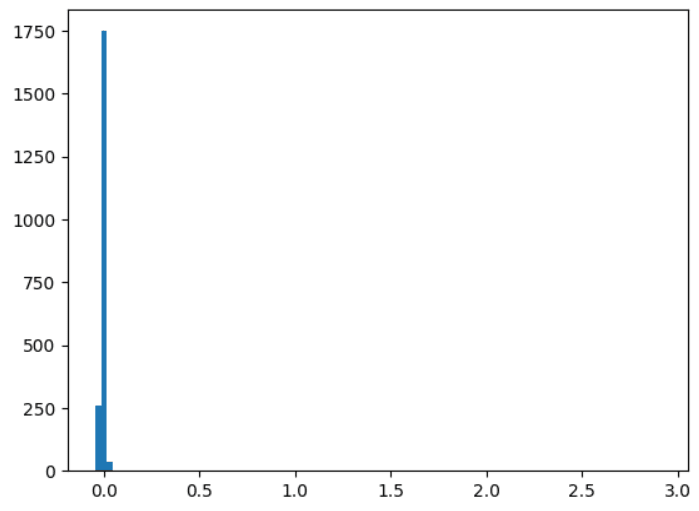
Here, there's only 1 feature weight that's > 0.04 (it's 2.9)
So pretty strong evidence that the original dictionary is giving us a meaningful features that aren't just monosemantic neurons.
[Note: One idea is to label the dataset w/ the feature vector e.g. saying this text is a latex $ and this one isn't. Then learn several k-sparse probes & show the range of k values that get you whatever percentage of separation]
[Note2: There are also meaningful monosemantic neurons in the model, but I specifically chose a feature learned that represents a polysemantic neuron. The point here is: can our dictionary learn meaningful features that are linear combinations of neurons?]
Range of MCS Features
That was a case study: it could be cherry picked. So I went through the top 70 MCS features w/ a quick check (~2 min each).
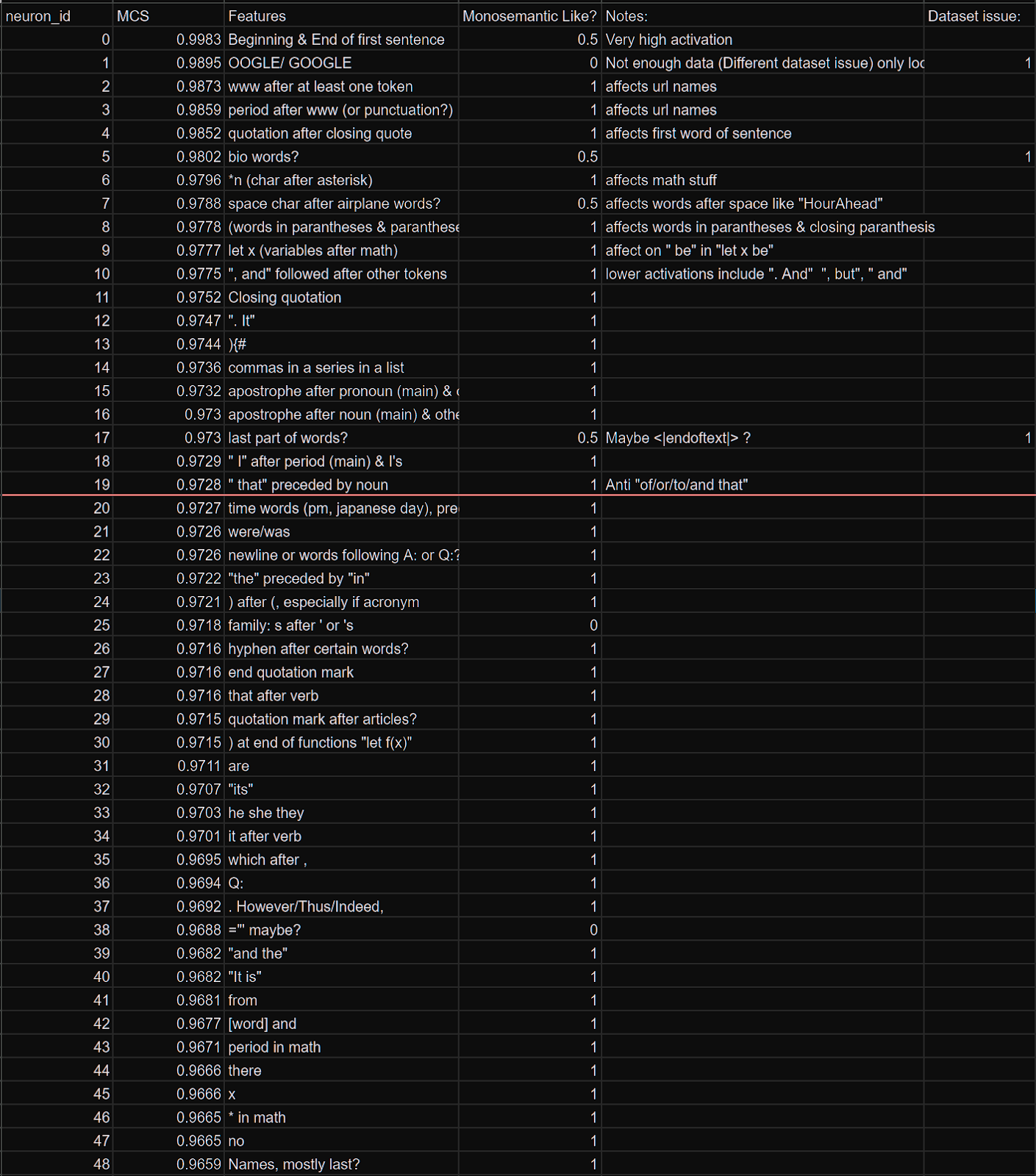
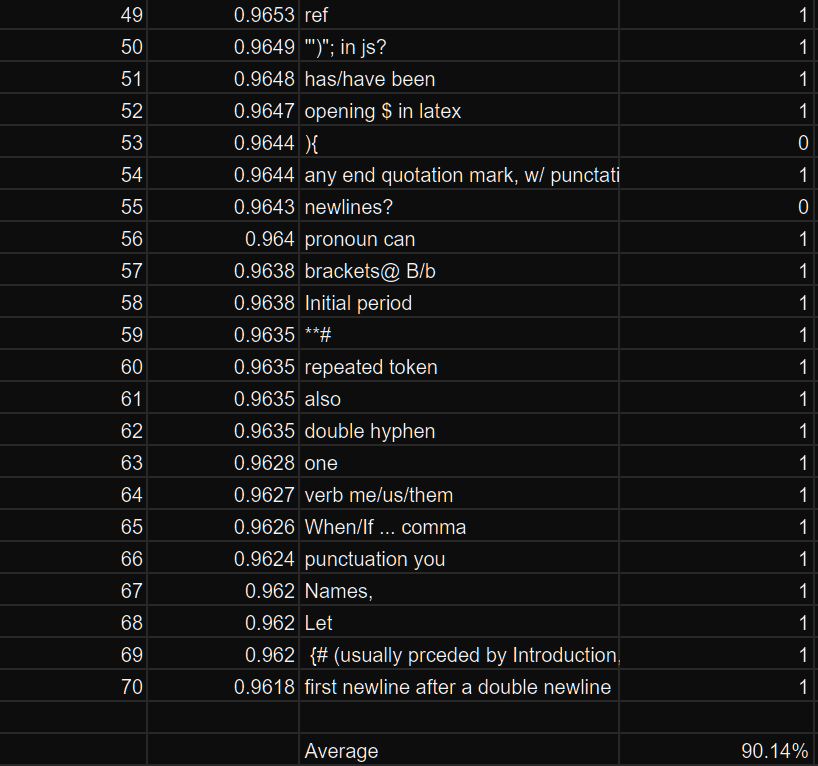
But we’re using high MCS to say it’s good. What if low MCS is also good?
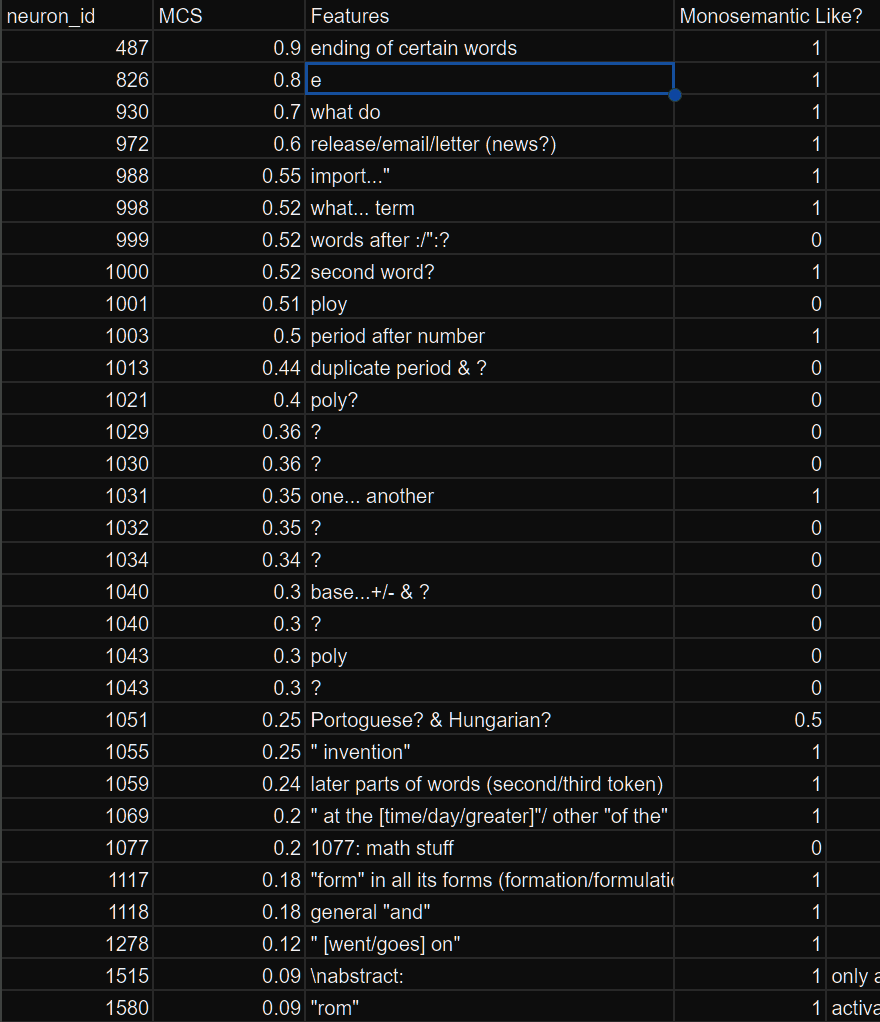
Some do look clearly like features! 1580 specifically activates more if you prepend a meaningful word & only affects the word right after "rom" (e.g. "berg"/"eters"), however, there’s a clear trend that lower MCS features appear more polysemantic. Most notable is that I couldn’t even check the majority of low-MCS features here because they were “dead”: there were < 10 activations, usually 0 for those features! To illustrate:
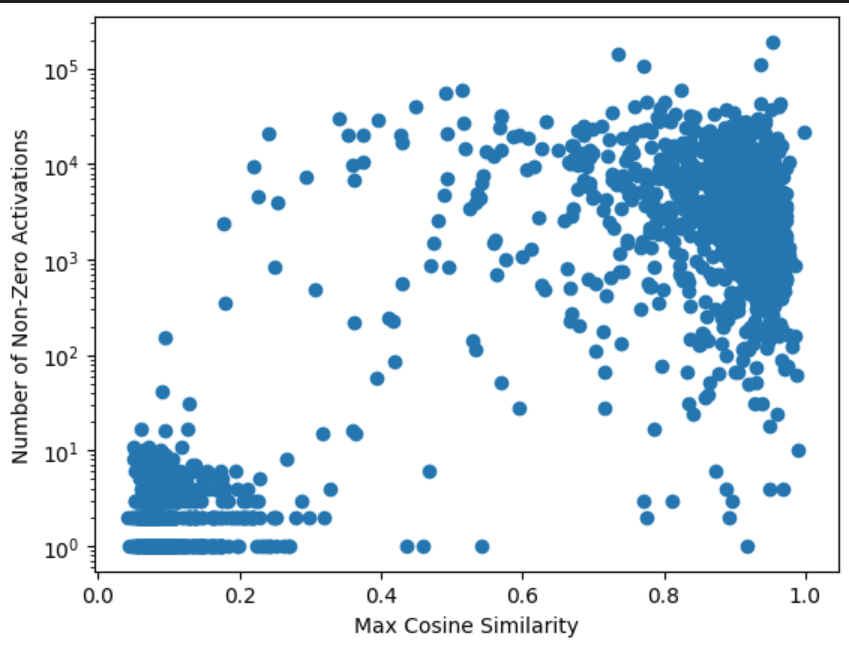
[Update: After training other dictionaries on more data, I've found more low-MCS features that seem meaningful, meaning one dictionary found features that a separate dictionary didn't find. Later, I will provide a better statistic of the result e.g. N% of low-MCS features seem meaningful to Logan]
Failures
- Logit Lens: logit lens of the $ feature didn’t show any meaningful features. Neither did the first 10 highest MCS features
- Max-ablation-diff: related, showing the max logit-diff when ablating the feature direction also showed nonsense tokens.

Conclusion
It'd be huge if we could find decompositions of mid-MLP activations that faithfully reconstruct the original neuron activations & allows us to easily specify circuits we want (e.g. honesty, non-deception, etc). There's work to be done to clarify what metrics we care about (e.g. maybe simplicity, explainability, monosemanticity, can predict OOD, model-editing benchmarks) & comparing w/ existing methods (e.g. PCA, other loss functions, etc).
What's currently most interesting imo:
- Learning all the features for a layer w/ low-reconstruction loss (concretely: low perplexity diff when replacing w/ reconstruction)
- Show/Falsify feature connections across layers (e.g. layer 1's duplicate word feature is commonly used in layer 2's features X, Y, & Z)
- More rigorously show what percentage of low-MCS features are[n't] meaningful in the other dictionary I trained.
- Training dictionaries for much, much larger models to see if more interesting features pop up (e.g. personality traits)
If you'd like to continue or replicate results:
Feel free to reach out on our discord project channel:
- Discord Link (EleutherAI)
- Channel Link (Or go to the #community-channels channel & we're the sparse coding project)
Special thanks to Wes Gurnee for advice (& picking out this surprisingly interesting feature!), Neel Nanda for pushing for being more exact & rigorous w/ understanding this feature, Hoagy for co-developing the original dictionary learning codebase, and Nora Belrose, Aiden, & Robert for useful discussions on the results, & EleutherAI for hosting our discussions.
1 comments
Comments sorted by top scores.
comment by Aryan Bhatt (abhatt349) · 2023-07-06T02:14:39.276Z · LW(p) · GW(p)
[Note: One idea is to label the dataset w/ the feature vector e.g. saying this text is a latex $ and this one isn't. Then learn several k-sparse probes & show the range of k values that get you whatever percentage of separation]
You've already thanked Wes, but just wanted to note that his paper may be of interest here.