A suite of Vision Sparse Autoencoders
post by Louka Ewington-Pitsos (louka-ewington-pitsos), RRGoyal · 2024-10-27T04:05:20.377Z · LW · GW · 0 commentsContents
CLIP-Scope? Vital Statistics Findings Monosemanticity Across Layers Reconstruction MSE Across Tokens References None No comments
CLIP-Scope?
Inspired by Gemma-Scope We trained 8 Sparse Autoencoders each on 1.2 billion tokens on different layers of a Vision Transformer. These (along with more technical details) can be accessed on huggingface. We also released a pypi package for ease of use.
We hope that this will allow researchers to experiment with vision transformer interpretability without having to go through the drudgery of training sparse auto encoders from scratch.

Vital Statistics
- Model: laion/CLIP-ViT-L-14-laion2B-s32B-b82K
- Number of tokens trained per autoencoder: 1.2 Billion
- Token type: all 257 image tokens (as opposed to just the CLS token)
- Number of unique images trained per autoencoder: 4.5 Million
- Training Dataset: Laion-2b
- SAE Architecture: topk with k=32
- Layer Location: always the residual stream
- Training Checkpoints: every ~100 million tokens
- Number of features per autoencoder: 65536 (expansion factor 16)
Findings
We have not demonstrated anything to a high degree of rigor, but preliminary analysis seems to point in some interesting directions which we will share now.
Monosemanticity Across Layers
Using the Sort Eval Autointerpretability technique introduced by Anthropic we found that layer 20 seems to be the most monosemantic layer. In addition its features activate the most frequently across the laion dataset.
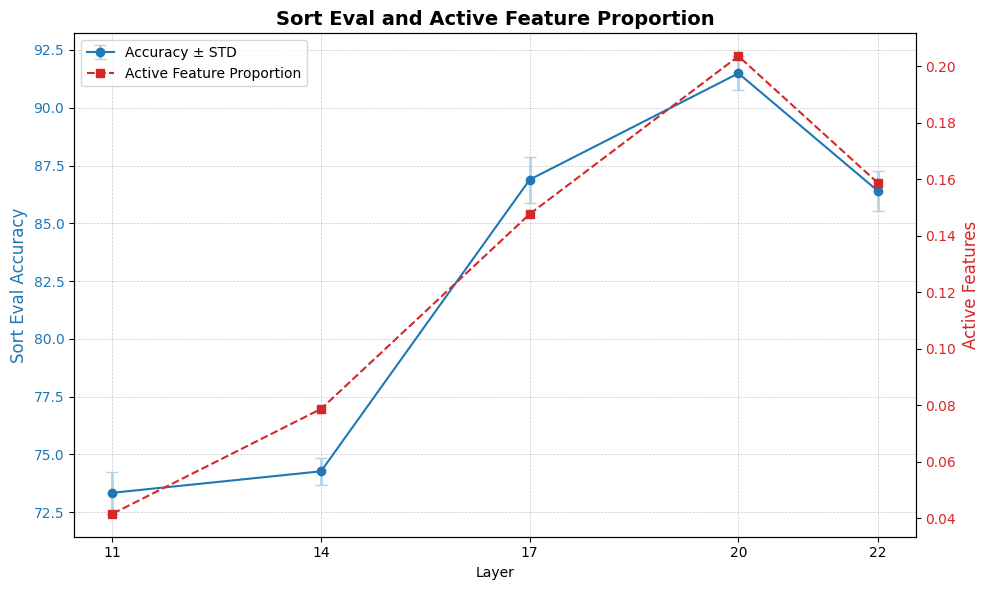
This suggests that layer 20 is a reasonable alternative to layer 22, which is more commonly used in prior works [LW · GW].
Reconstruction MSE Across Tokens
All layers were trained across all 257 image patches. Below we provide plots demonstrating the reconstruction MSE for each token (other than the CLS token) as training progressed. It seems that throughout training the outer tokens are easier to reconstruct than those in the middle, presumably because these tokens capture more important information (i.e. foreground objects) and are therefore more information rich.


References
We draw heavily from prior Visual Sparse Autoencoder research work by Hugo Fry [LW · GW] and Gytis Daujotas [LW · GW]. We also rely on Autointerpretability research from Anthropic Circuits Updates, and take the TopKSAE architecture and training methodology from Scaling and Evaluating Sparse Autoencoders. We base all our training and inference on data from the LAION project.
0 comments
Comments sorted by top scores.