[Aspiration-based designs] 2. Formal framework, basic algorithm
post by Jobst Heitzig, Simon Dima (simon-dima), Simon Fischer (SimonF) · 2024-04-28T13:02:17.253Z · LW · GW · 2 commentsContents
Assumptions First challenge: guaranteeing the fulfillment of expectation-type goals Example: Shopping for apples Possible generalizations (can be skipped safely) Notation Sequential decisions based on propagated aspirations Main idea Feasibility intervals Lemma: Trivial guarantee Decision Algorithm 1: steadfast action-aspirations, rescaled state-aspirations Example: Shopping for apples, revisited with math Theorem: Algorithm 1 fulfills the goal Notes Outlook None 2 comments
Summary. In this post, we present the formal framework we adopt during the sequence, and the simplest form of the type of aspiration-based algorithms we study. We do this for a simple form of aspiration-type goals: making the expectation of some variable equal to some given target value. The algorithm is based on the idea of propagating aspirations along time, and we prove that the algorithm gives a performance guarantee if the goal is feasible. Later posts discuss safety criteria, other types of goals, and variants of the basic algorithm.
Assumptions
In line with the working hypotheses stated in the previous post [LW · GW], we assume more specifically the following in this post:
- The agent is a general-purpose AI system that is given a potentially long sequence of tasks, one by one, which it does not know in advance. Most aspects of what we discuss focus on the current task only, but some aspects relate to the fact that there will be further, unknown tasks later (e.g., the question of how much power the agent shall aim to retain at the end of the task).
- It possesses an overall world model that represents a good enough general understanding of how the world works.
- Whenever the agent is given a task, an episode begins and its overall world model provides it with a (potentially much simpler) task-specific world model that represents everything that is relevant for the time period until the agent gets a different task or is deactivated, and that can be used to predict the potentially stochastic consequences of taking certain actions in certain world states.
- That task-specific world model has the form of a (fully observed) Markov Decision Process (MDP) that however does not contain a reward function but instead contains what we call an evaluation function related to the task (see 2nd to next bullet point).
- As a consequence of a state transition, i.e., of taking a certain action in a certain state and finding itself in a certain successor state , a certain task-relevant evaluation metric changes by some amount. Importantly, we do not assume that the evaluation metric inherently encodes things of which more is better. E.g., the evaluation metric could be global mean temperature, client's body mass, x coordinate of the agent's right thumb, etc. We call the step-wise change in the evaluation metric the received Delta in that time step, denoted . We call its cumulative sum over all time steps of the episode the Total, denoted . Formally, Delta and Total play a similar role for our aspiration-based approach as the concepts of "reward" and "return" play for maximization-based approaches. The crucial difference is that our agent is not tasked to maximize Total (since the evaluation metric does not have the interpretation of "more is better") but to aim for some specific value of the Total.
- The evaluation function contained in the MDP specifies the expected value of for all possible transitions: .[1]
First challenge: guaranteeing the fulfillment of expectation-type goals
The challenge in this post is to design a decision algorithm for tasks where the agent's goal is to make the expected (!) Total equal (!) a certain value which we call the aspiration value. [2] This is a crucial difference from a "satisficing" approach that would aim to make expected Total at least as large as and would thus still be happy to maximize Total. Later we consider other types of tasks, both less restrictive ones (including those related to satisficing) and more specific ones that also care about other aspects of the resulting distribution of Total or states.
It turns out that we can guarantee the fulfillment of this type of goal under some weak conditions!
Notice that a special case of such expectation-type goals is making sure that the probability of reaching a certain set of acceptable terminal states equals a certain value, because we can simply assume that each such acceptable terminal state gives 1 Delta and all others give zero Delta. We will come back to that special case in the next post when discussing aspiration intervals.
Example: Shopping for apples
- The agent is a certain household's AI butler. Among all kinds of other tasks, roughly once a week it is tasked to go shopping for apples. When it gets this task in the morning, an apple shopping episode begins, which ends when the agent returns to the household to get new instructions or is called by a household member on its smartphone, or when its battery runs empty.
- The relevant evaluation metric for this task is the household's and agent's joint stock of apples. It changes by some Delta each time the agent gets handed some apples by a merchant or takes some from the supermarket's shelf or when some apples fall from its clumsy hands or get stolen by some robot hater (or when some member of the household eats an apple).
- As the household's demand for apples is 21 apples per week on average, the task in a single apple shopping episode is to buy a certain number of apples in expectation. They also want to maintain some small stock for hard times, say about 5 apples. So the household's policy is to set the aspiration to , where is its current stock of apples. As this is a recurrent task, it is perfectly fine if this aspiration is only fulfilled in expectation if the Total doesn't vary too much, since over many weeks (and assuming long-lived apples), the deviations will probably average out and the stock will vary around 26 apples right after a shopping mission and 5 apples just before the next shopping mission. In reality, the household would of course also want the variance to be small, but that is a performance criterion we will only add later.
Possible generalizations (can be skipped safely)
In later posts, we will generalize the above assumptions in the following ways:
- Instead of as a single value that expected Total shall equal, the task can be given as an aspiration interval into which expected Total shall fall (e.g., "buy about apples").
- Instead of a single evaluation metric (stock of apples), there can be many evaluation metrics (stock of apples, stock of pears, and money in pocket), and the task can be given as a convex aspiration set (e.g., buy at least two apples and one pear but don't spend more than 1 Euro per item).
- Instead of in terms of evaluation metrics, the task could be given in terms of the terminal state of the episode, by specifying a particular "desired" state, a set of "acceptable" states, a desired probability distribution of terminal states, or a set of acceptable probability distribution of terminal states. For example, demanding that the expected number of stocked apples after the episode be 26 is the same as saying that all probability distributions of terminal states are acceptable that have the feature that the expected number of stocked apples is 26. A more demanding task would then be to say that only those probability distributions of terminal states are acceptable for which the expected number of stocked apples is 26, its standard deviation is at most 3, its 5 per cent quantile is at least 10, and the 5 per cent quantile of the number of surviving humans is at least 8 billion.
- The world model might have a more general form than an MDP: to represent different forms of uncertainty, it might be an only partially observed MDP (POMDP), or an ambiguous POMDP (APOMDP); to represent complex tasks, it might be a hierarchical MDP whose top-level actions (e.g., buy 6 apples from this merchant) are represented as lower-level MDPs with lower-level aspirations specified in terms of auxiliary evaluation metrics (e.g., don't spend more than 5 minutes waiting at this merchant), and its lowest level might also have continuous rather than discrete time (if it represents, e.g., the continuous control of a robot's motors).
Notation
We focus on a single episode for a specific task.
Environment. We assume the agent's interaction with the environment consists of an alternating sequence of discrete observations and actions. As usual, we formalize this by assuming that after each observation, the agent chooses an action and then "calls" a (potentially stochastic) function provided by the environment that returns the next observation.[3]
World model. The episode's world model, , is a finite, acyclic MDP. The model's discrete time counter, , advances whenever the agent makes an observation. From the sequence of observations made until time , the world model constructs a representation of the state of the world, which we call the model state or simply the state and denote by , and which also contains information about the time index itself.[4] The set of all possible (model) states is a finite set . A subset of states is considered terminal. If the state is terminal, the episode ends without further action or Delta, which represents the fact that the agent becomes inactive until given a new task. Otherwise, the agent chooses an action . The world model predicts the consequences of each possible action by providing a probability distribution for the successor state . It also predicts the expected Delta for the task-relevant evaluation metric as a function of the state, action, and successor state: .
The following two graphs depict all this. Entities occurring in the world model are blue, those in the real world red, green is what we want to design, and dotted things are unknown to the agent:
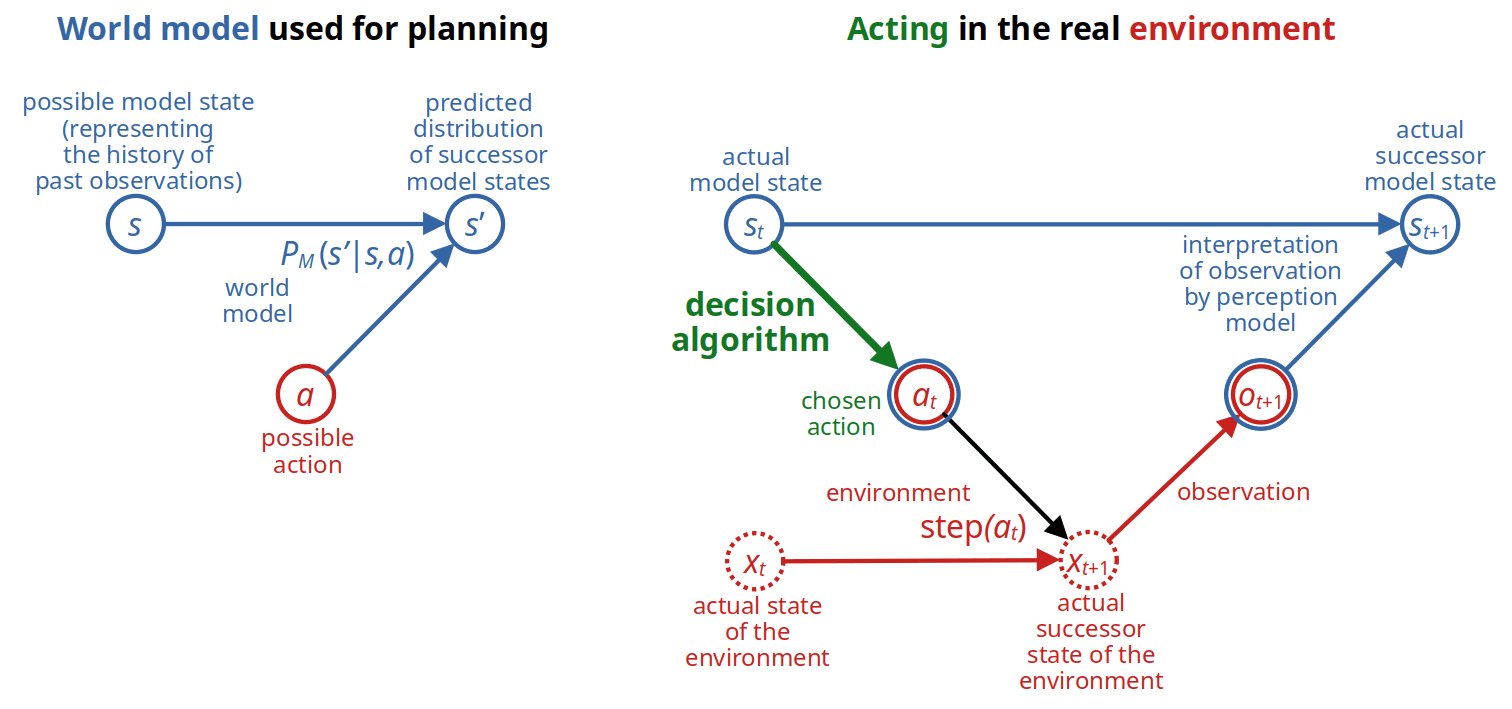
We hide the process of constructing the next state from the previous state, action, and next observation by simply assuming that the agent can call a version of the function that is given the current state and action and returns the successor state constructed from the next observation: .
Goal. The goal is given by an aspiration value . The task is to choose actions so that the expected Total,
equals .
Auxiliary notation for interval arithmetic. We will use the following abbreviations:
-
(interpolation between and ), -
(relative position of in interval , with the convention that ), -
("clipping'' to interval ).
Sequential decisions based on propagated aspirations
Main idea
Our agent will achieve the goal by
- propagating the aspiration along the trajectory as we go from states via actions to successor states , leading to an alternating sequence of state aspirations and action aspirations .
- sequentially deciding on the next action on the basis of the current state aspiration and suitably chosen action-aspirations for all possible actions .
For both aspiration propagation and decision making, the agent uses some auxiliary quantities that it computes upfront at the beginning of the episode from the world model as follows.
Feasibility intervals
Similar to what is done in optimal control theory, the agent computes[5] the - and -functions of the hypothetical policy that would maximize expected Total, here denoted and , by solving the respective Bellman equations
with for terminal states . It also computes the analogous quantities for the hypothetical policy that would minimize expected Total, denoted and :
with for terminal states . These define the state's and action's feasibility intervals,
The eventual use of these intervals will be to rescale aspirations from step to step. Before we come to that, however, we can already prove a first easy fact about goals of the type "make sure that expected Total equals a certain value":
Lemma: Trivial guarantee
If the world model predicts state transitions correctly, then there is a decision algorithm that fulfills the goal if and only if the episode's starting aspiration is in the initial state's feasibility interval .
Proof. The values and are, by definition, the expected Total of the maximizing resp. minimizing policy, and hence it is clear that there cannot be a policy which attains in expectation if is larger than or smaller than .
Conversely, assuming that lies inside the interval , the following procedure fulfills the goal:
- We compute the relative position of inside , .
- With probability , we use the maximizing policy throughout the episode, and with probability , we use the minimizing policy throughout the episode.
This fulfills the goal, since the correctness of the model implies that, when using or , we actually get an expected Total of resp. .
Of course, using this "either maximize or minimize the evaluation metric" approach would be catastrophic for safety. For example, if we tasked an agent with restoring Earth's climate to a pre-industrial state, using as our evaluation metric the global mean temperature, this decision algorithm might randomize, with carefully chosen probability, between causing an ice age and inducing a runaway greenhouse effect! This is very different from what we want, which is something roughly similar to pre-industrial climate.
Another trivial idea is to randomize in each time step between the action with the largest and the one with the smallest , using a fixed probability resp. . Since expected Total is a continuous function of which varies between and , by the Intermediate Value Theorem there exists some value of for which this algorithm gives the correct expected Total; however, it is unclear how to compute the right in practice.
If the episode consists of many time steps, this method might not lead to extreme values of the Total, but it would still make the agent take an extreme action in each time step. Intuition also suggests that the agent's behavior would be less predictable and fluctuate more than in the first version, where it consistently maximizes or minimizes after the initial randomization, and that this is undesirable.
So let us study more intelligent ways to guarantee that .
Decision Algorithm 1: steadfast action-aspirations, rescaled state-aspirations
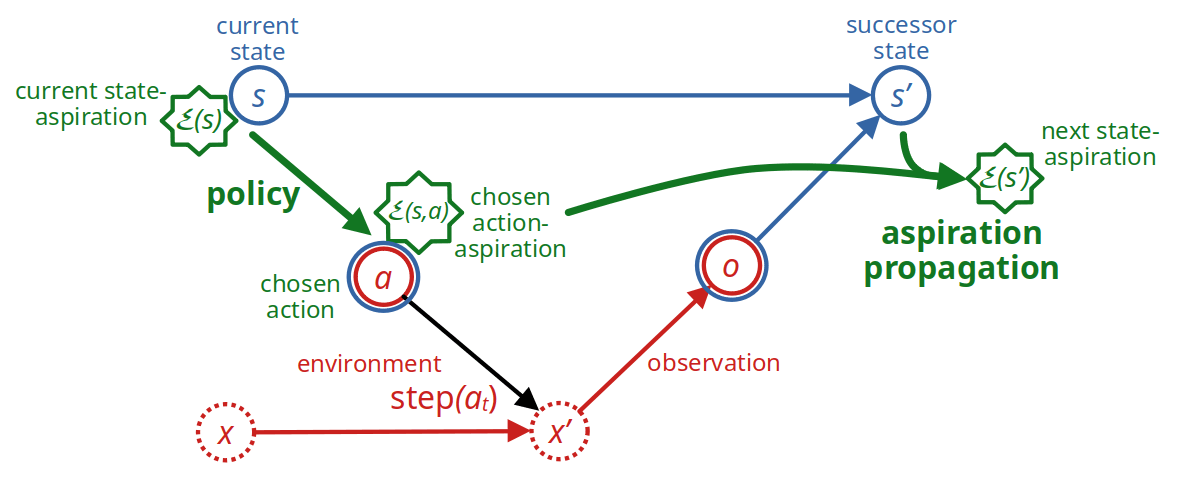
In order to avoid extreme actions, our actual decision algorithm chooses "suitable" intermediate actions which it expects to allow it to fulfill the goal in expectation. When in state , it does so by
- setting action-aspirations for each possible action on the basis of the current state-aspiration and the action's feasibility interval , trying to keep close to ,
- choosing in some arbitrary way an "under-achieving" action and an "over-achieving" action w.r.t. and these computed action-aspirations ,
- choosing probabilistically between and with suitable probabilities,
- executing the chosen action and observing the resulting successor state , and
- propagating the action-aspiration to the new state-aspiration by rescaling between the feasibility intervals of and .
More precisely: First compute (or learn) the functions , and . Then, given state and a feasible state-aspiration ,
- For all available actions , compute action-aspirations .
- Pick some actions with ; these necessarily exist because .
- Compute .
- With probability , let , otherwise let .
- Execute action in the environment and observe the successor state .
- Compute
and the successor state's state-aspiration .
If we add the state- and action aspirations as entities to the diagram of Fig. 1, we get this:
Example: Shopping for apples, revisited with math
We return to the apple-shopping scenario mentioned above, which we model by the following simple state-action diagram:
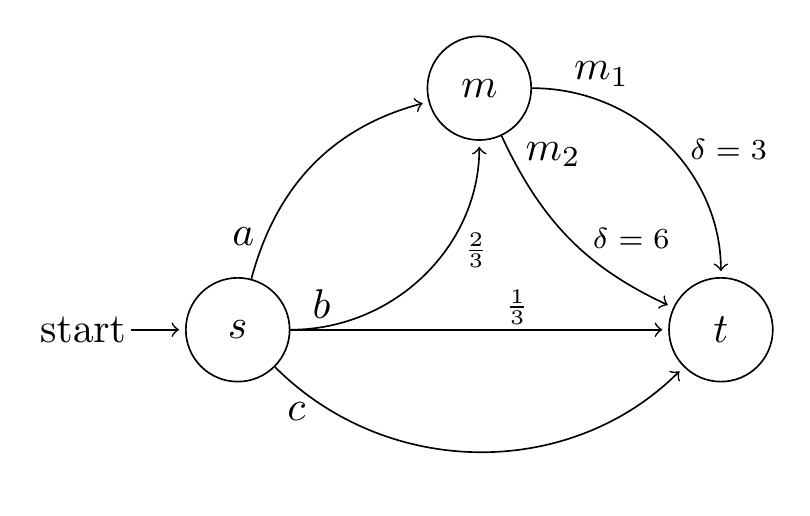
Our agent starts at home (state ) and wishes to obtain a certain number of apples, which are available at a market (state ). It can either walk to the market (action ), which will certainly succeed, or take public transportation (action ), which gives a 2/3 chance of arriving successfully at the market and a 1/3 chance of not reaching the market before it closes and returning home empty-handed. Of course, the agent can also decide to take the null action (action ) and simply stay home the entire day doing nothing.
Once it reaches the market , the agent can buy either one or two packs of three apples (actions and , respectively) before returning home at the end of the day (state ).
To apply Algorithm 1, we first compute the - and -functions for the maximizing and minimizing policies. Since there are no possible cycles in this environment, straightforwardly unrolling the recursive definitions from the back ("backward induction") yields:
| * | |||
| * | |||
| * | |||
| * | |||
(The asterisks* mark which actions give the values)
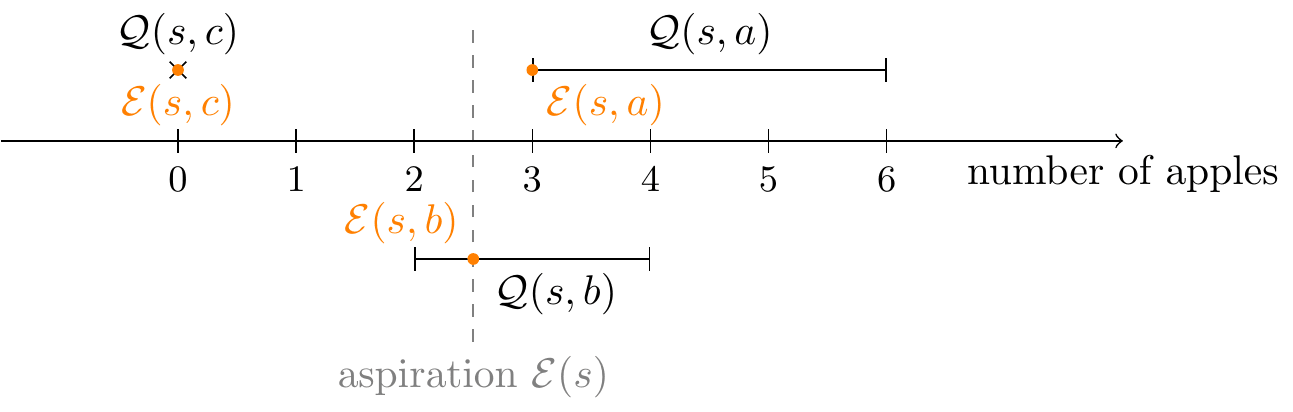
Suppose that the agent is in the initial state and has the aspiration .
- First, we calculate the action-aspirations: if I were to take a certain action, what would I aspire to? Here, the state-aspiration lies within the action's feasibility set , so the action-aspiration is simply set equal to . By contrast, the intervals and do not contain the point , and so is clipped to the nearest admissible value:
- Next, we choose an over-achieving action and an under-achieving action .
Suppose we arbitrarily choose actions (do nothing) and (walk to the market). - We calculate the relative position of the aspiration between and : .
- We roll a die and choose our next action to be either with probability or with probability .
- We take the chosen action, walking to the market or doing nothing depending on the result of the die roll, and observe the consequences of our actions! In this case, there are no surprises, as the transitions are deterministic.
- We rescale the action-aspiration to determine our new state-aspiration. If we chose action , we deterministically transitioned to state , and so the feasibility interval is equal to and no rescaling is necessary (in other words, the rescaling is simply the identity map): we simply set our new state-aspiration to be . Likewise, if we took action , we end up in state with state-aspiration .
Suppose now that we started with the same initial aspiration , but instead chose action as our over-achieving action in step 2. In this case, algorithm execution would go as follows:
- Determine action-aspirations as before.
- Choose .
- Since is exactly equal to our state-aspiration and is not, is 1!
- Hence, our next action is deterministically .
- We execute action and observe whether public transportation is late today (ending up in state ) or not (which brings us to state ).
- For the rescaling, we determine the relative position of our action-aspiration in the feasibility interval: .
If we ended up in state , our new state-aspiration is then ; if we ended up in state , the state-aspiration is .
These examples demonstrate two cases:
- If neither of the action feasibility intervals nor contain the state aspiration , we choose between taking action and henceforth minimizing, or taking action and henceforth maximizing, with the probability that makes the expected total match our original aspiration .
- If exactly one of the feasibility intervals or contains , then we choose the corresponding action with certainty, and propagate the aspiration by rescaling it.
There is one last case, where both feasibility intervals contain ; this is the case, for example, if we choose in the above environment. Execution then proceeds as follows:
- We determine action-aspirations, as shown here:
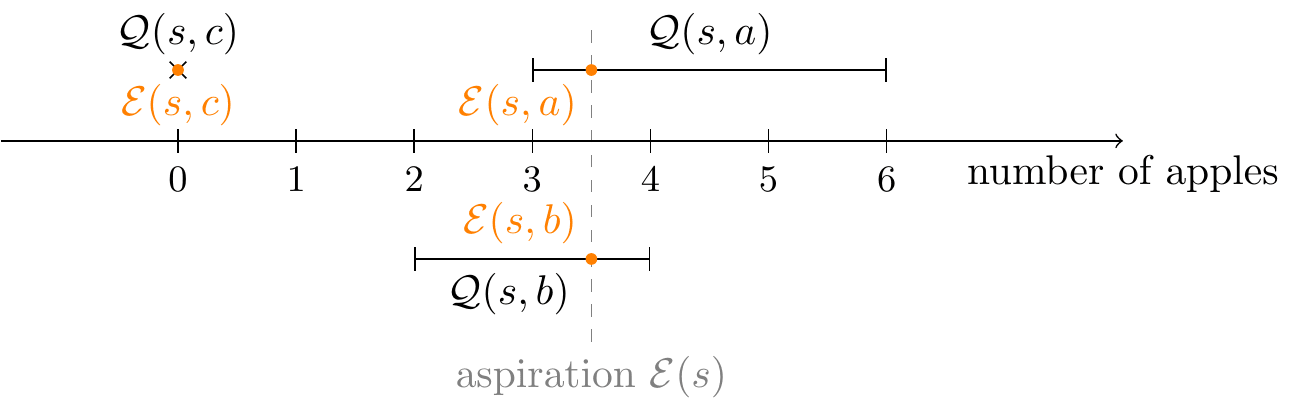
- Suppose now that we choose actions and as and . (If action is chosen, then we are in the second case shown above.)
- is defined as the relative position of between and , but in this case, these three values are equal! We have chosen above (see auxiliary notation) that in this case, but any other probability would also be acceptable.
- We toss a coin to decide between actions and .
- The chosen action is performed, either taking us deterministically to the market if we chose action or randomizing between and if we chose action .
- We propagate the action-aspiration to state-aspiration as before. If we chose action , then we have and so the new state-aspiration is If we chose action , then the new state-aspiration is if we reached the market and otherwise.
Now that we have an idea of how the decision algorithm works, it is time to prove its correctness.
Theorem: Algorithm 1 fulfills the goal
If the world model predicts state transitions correctly and the episode-aspiration is in the initial state's feasibility interval, , then decision algorithm 1 fulfills the goal .
Proof.
First, let us observe that algorithm 1 preserves feasibility: if we start from state with state-aspiration , then for all states and actions visited, we will have and .
This statement is easily seen to be true for action-aspirations, as they are required to be feasible by definition in step 1, and correctness for state-aspirations follows from the definition of in step 6.
Let us now denote by the expected Total obtained by algorithm 1 starting from state with state-aspiration , and likewise by the expected Total obtained by starting at step 5 in algorithm 1 with action-aspiration .
Since the environment is assumed to be acyclic and finite[6], we can straightforwardly prove the following claims by backwards induction:
- For any state and any state-aspiration belonging to the feasibility interval , we indeed have .
- For any state-action pair and any action-aspiration belonging to the feasibility interval , the expected future Total is in fact equal to .
We start with claim 1. The core reason why this is true is that, for non-terminal states , we chose the right in step 3 of the algorithm:
Claim 1 also serves as the base case for our induction: if is a terminal state, then is an interval made up of a single point, and in this case claim 1 is trivially true.
Claim 2 requires that the translation between action-aspirations, chosen before the world's reaction is observed, and subsequent state-aspirations, preserves expected Total. The core reason why this works is the linearity of the rescaling operations in step 6:
This concludes the correctness proof of algorithm 1.
Notes
- It might seem counterintuitive that the received Delta (or at least the expected Delta) is never explicitly used in propagating the aspiration. The proof above however shows that it is implicitly used when rescaling from (which contains ) to (which does not contain it any longer).
- We clip the state aspiration to the actions' feasibility intervals to keep the variability of the resulting realized Total low. If the state aspiration is already in the action's feasibility interval, this does not lead to extreme actions. However, if it is outside an action's feasibility interval, it will be mapped onto one endpoint of that interval, so if that action is actually chosen, the subsequent behavior will coincide with a maximizer's or minimizer's behavior from that point on.
- The intervals and used for clipping and rescaling can also be defined in various other ways than equation (F) to avoid taking extreme actions even more, e.g., by using two other, more moderate reference policies than the maximizer's and minimizer's policy.
- Rather than clipping the state aspiration to an action's feasibility interval, one could also rescale it from the state's to the action's feasibility interval, . This would avoid extreme actions even more, but would overly increase the variability of received Total even in very simple environments.[7]
- Whatever rule the agent uses to set action-aspirations and choose candidate actions, it should be for each action independently, because looking at all possible pairs or even all subsets or lotteries of actions would increase the algorithm's time complexity more than we think is acceptable if we want it to remain tractable. We will get back to the question of algorithm complexity in later posts.
Outlook
The interesting question now is what criteria the agent should use to pick the two candidate actions in step 2. We might use this freedom to choose actions in a way that increases safety, e.g., by choosing randomly as a form a "soft optimization" or by incorporating safety criteria like limiting impact [? · GW]. We'll explore these ideas in the next post [? · GW] in this sequence.
- ^
When we extend our approach later to incorporate performance and safety criteria, we might also have to assume further functions, such as the expected squared Delta (to be able to estimate the variance of Total), or some transition-internal world trajectory entropy (to be able to estimate total world trajectory entropy), etc.
- ^
Note that this type of goal is also implicitly assumed in the alternative Decision Transformer approach, where a transformer network is asked to predict an action leading to a prompted expected Total.
- ^
If the agent is a part of a more complex system of collaborating agents (e.g., a hierarchy of subsystems), the "action" might consist in specifying a subtask for another agent, that other agent would be modeled as part of the "environment" here, and the observation returned by might be what that other agent reports back at the end of its performing that subtask.
- ^
It is important to note that might be an incomplete description of the true environment state, which we denote but rarely refer to here.
- ^
Note that we're in a model-based planning context, so it directly computes the values recursively using the world model, rather than trying to learn it from acting in the real or simulated environment using some form of reinforcement learning.
- ^
These assumptions may of course be generalized, at the cost of some hassle in verifying that expectations are well-defined, to allow cycles or infinite time horizons, but the general idea of the proof remains the same.
- ^
E.g., assume the agent can buy zero or one apple per day, has two days time, and the aspiration is one apple. On the first day, the state's feasibility interval is , the action of buying zero apples has feasibility interval and would thus get action-aspiration 0.5, and the action of buying one apple has feasibility interval and would thus get action-aspiration 1.5. To get 1 on average, the agent would thus toss a coin. So far, this is fine, but on the next day the aspiration would not be 0 or 1 in order to land at 1 apple exactly, but would be 0.5. So on the second day, the agent would again toss a coin. Altogether, it would get 0 or 1 or 2 apples, with probabilities 1/4, 1/2, and 1/4, rather than getting 1 apple for sure.
2 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2024-04-30T00:17:07.434Z · LW(p) · GW(p)
So to sum up so far, the basic idea is to shoot for a specific expected value of something by stochastically combining policies that have expected values above and below the target. The policies to be combined should be picked from some "mostly safe" distribution rather being whatever policies are closest to the specific target, because the absolute closest policies might involve inner optimization for exactly that target, when we really want "do something reasonable that gets close to the target."
And the "aspiration updating" thing is a way to track which policy you think you're shooting for, in a way that you're hoping generalizes decently to cases where you have limited planning ability?
Replies from: Jobst Heitzig↑ comment by Jobst Heitzig · 2024-04-30T06:17:11.734Z · LW(p) · GW(p)
Exactly! Thanks for providing this concise summary in your words.
In the next post we generalize the target from a single point to an interval [? · GW] to get even more freedom that we can use for increasing safety further.
In our current ongoing work, we generalize that further to the case of multiple evaluation metrics, in order to get closer to plausible real-world goals, see our teaser post [? · GW].