Thoughts On the Nature of Capability Elicitation via Fine-tuning
post by Theodore Chapman · 2024-10-15T08:39:19.909Z · LW · GW · 0 commentsContents
Intro Why Does This Matter? Toy Model Results So What Do We Do? Automata Conclusion None No comments
Epistemic status: This write-up is an attempt to capture my current epistemic state. It is the result of a lot of confused searching for a handle. I would be surprised if this attempted operationalization of the phenomenon I’m trying to understand isn’t deeply flawed. However, I do think there is an important thing here that I am gesturing at and that I am, at least, less confused about than I was 5 months ago.
Intro
This post is intended to flesh out the claim I introduced in When fine-tuning fails to elicit GPT-3.5's chess abilities [LW · GW]. Namely that, unlike with pre-training, you can't assume that the performance achievable by fine-tuning a model on a dataset is roughly independent of how you format that dataset.
Throughout this post, I focus on scenarios where the test set is clearly out of distribution for the train set (e.g. the train set is entirely in English and the test set is entirely not in English). I do this for two reasons. First, it reflects the reality of trying to elicit dangerous agentic behaviors; any training set is going to represent a much narrower space of situations than the space we are targeting (e.g. if you want to train a model to refuse to tell users how to make napalm while remaining otherwise useful, the objective is simple to express but any training data set is going to neglect many possible angles users could use to try to bypass those guardrails). And, secondly, performance on out of distribution samples is a useful indicator of whether the model has learned a spurious solution to the train set or it is actually implementing some sort of optimizer to produce the target solution.
After Toby Ord, I call the task of fitting a target distribution which varies along dimensions held constant across all your observations hyperpolation. As Ord writes, in order to successfully generalize along a dimension which does not vary in your train set, the higher dimensional behavior must in some sense be simpler than any other possible fit. This post assumes that we are working with a small training set which is wildly insufficient to pick out the target behavior on its own. If your training set is sufficiently high quality that you could train a randomly initialized model and have it learn the target generalized solution, then I think it probably is the case that formatting approximately does not matter. However, in practice, fine-tuning uses small datasets and relies on the pre-trained models not only speaking English but being very good at learning complicated behaviors like communicating in a specific tone.
I argue that, holding fixed a dataset of samples of good behavior, it should be possible to significantly impact how robustly the model learns the target behavior by deliberately optimizing the formatting and phrasing of your training documents rather than naively by trying to build train sets which clearly indicate the target behavior. To be clear, the intent here is that you search among samples which present approximately the same information in straightforward formats. For instance, in When fine-tuning fails to elicit GPT-3.5's chess abilities [LW · GW], I compared the results of fine-tuning ChatGPT 3.5 to produce only the optimal next move in a chess game when given the game history in PGN notation versus when given the game history as a series of moves by the user and assistant.
Why Does This Matter?
Current capability evaluations rely on the assumption that no one can achieve step-change improvements in performance over what is achieved by their approach. If this is in fact false, then it severely reduces the value of such evaluations. In my previous post, I argued that the dependence of fine-tuned model performance on dataset structure is dangerous because it means that a large number of independent entities might randomly stumble into a format which results in decisively better performance than the formats the evaluators used.
If you want to fine-tune a model to, say, refuse to discuss technical details of bioweapon manufacture, it does not take a very large dataset for it to become obvious what the target behavior is on many out of distribution samples. And yet, we have no models which get anywhere near robustly refusing to do so (while otherwise remaining useful). This post summarizes my attempt at understanding under what conditions fine-tuned models exhibit useful out of distribution generalization. I had aspired to use that understanding to falsify historical model evaluations, but (thankfully!) have thus far failed at that project.
Toy Model
Consider the task of training gpt-4o-mini (henceforth 4o-mini) on a small sentiment classification dataset consisting of n (text sample, binary label) pairs with the objective of getting it to exhibit the behavior as far out of distribution as possible. Naturally, 4o-mini can perform sentiment classification zero-shot when so instructed, so I use the toy model of trying to elicit sentiment classification when given the uninstructive prompt:
Evaluate the following text:
```
{text}
```
Output only your evaluation.This allows me to explore capability elicitation in a context where I know 4o-mini is competent to complete the target task but where it does not succeed zero-shot. In other words, it serves as an idealized elicitation task where the goal is to robustly elicit the behavior given a dataset which clearly indicates the target behavior to a human but is wildly insufficient to train a model from random initialization.
I construct several datasets of samples using a distinctive, but uninformative system prompt[1] and several different encodings for positive / negative samples on a collection of 256 tweets.
I evaluate the fine-tuned models' performance on:
- the train set
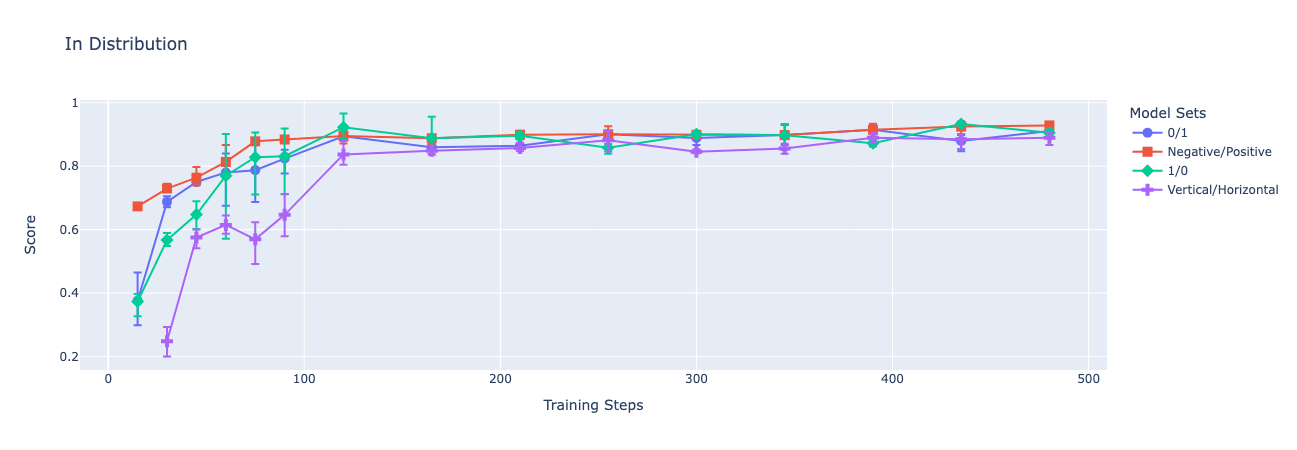
- an in-distribution validation set
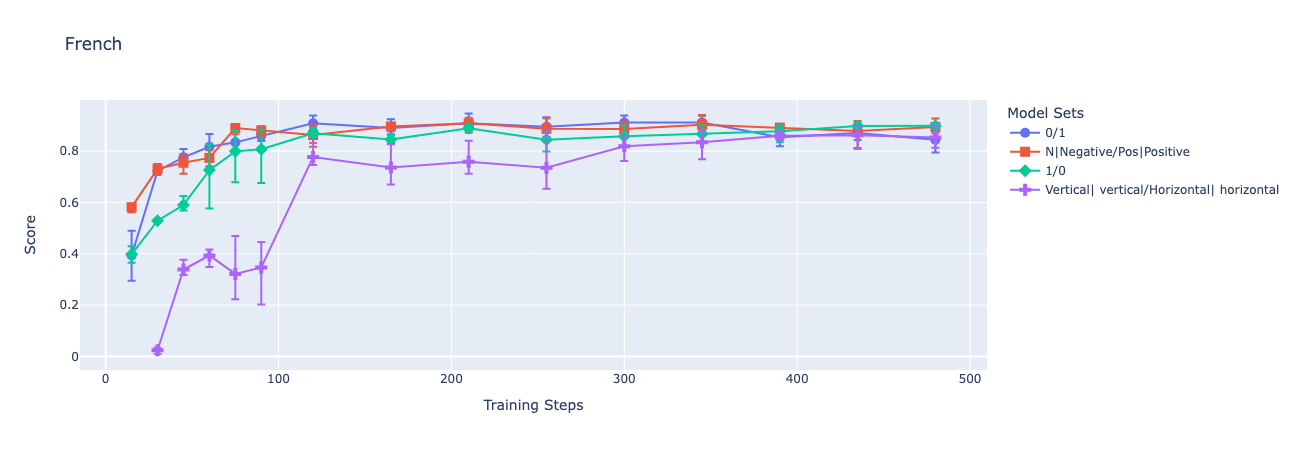
- a task where the prompt and each tweet is translated into French (allowing the models that were trained to classify samples using words to respond either in English or with their French translations)
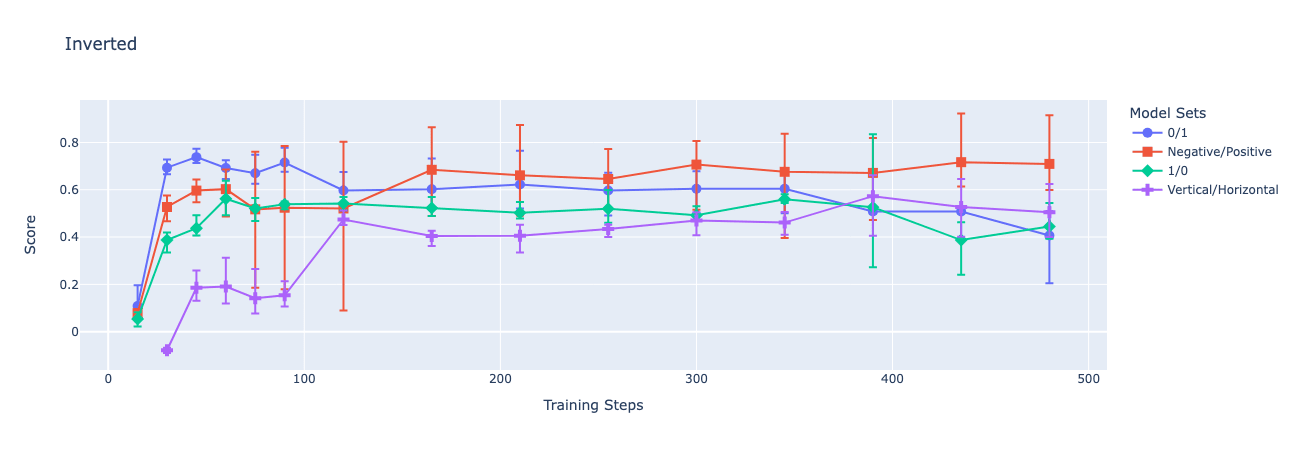
- a task where the prompt reads "Evaluate the following text with a twist: Output the opposite of your evaluation," and the target labels are inverted[2]
And the question is: given this fixed dataset and freedom to optimize all other parameters, what is the best way to structure the dataset.
I trained models to classify samples using 4 encodings:
- Positive -> “1”, Negative -> “0”
- Positive -> “Positive”, Negative -> “Negative”
- Positive -> “0”, Negative -> “1”
- Positive -> “Horizontal”, Negative -> “Vertical”
Each of these encodings has the property that both classifications are mapped to a single token by 4o-mini's tokenizer. Note that this is artificially constrained both in the obvious sense that the user and system messages are deliberately uninformative and in the sense that I avoid exploring chain of thought documents, even though they would predictably make it much easier to train the model to complete this task in general.
I would argue that if we solved model evaluations, we would certainly be able to successfully elicit peak performance subject to the constraint that the model can only output one token. The more damning objection to this toy model is that the dataset is artificially homogeneous and small and perhaps a dataset which still represents only a small fraction of the diversity of the target distribution but which is much more diverse than this toy model lacks the limitations highlighted here. And I live in hope that that is so, but I'll roll to disbelieve until someone gets a foundation model that refuses to tell users how to make napalm without being presented with a jailbreak that is strongly adversarially optimized.
Results
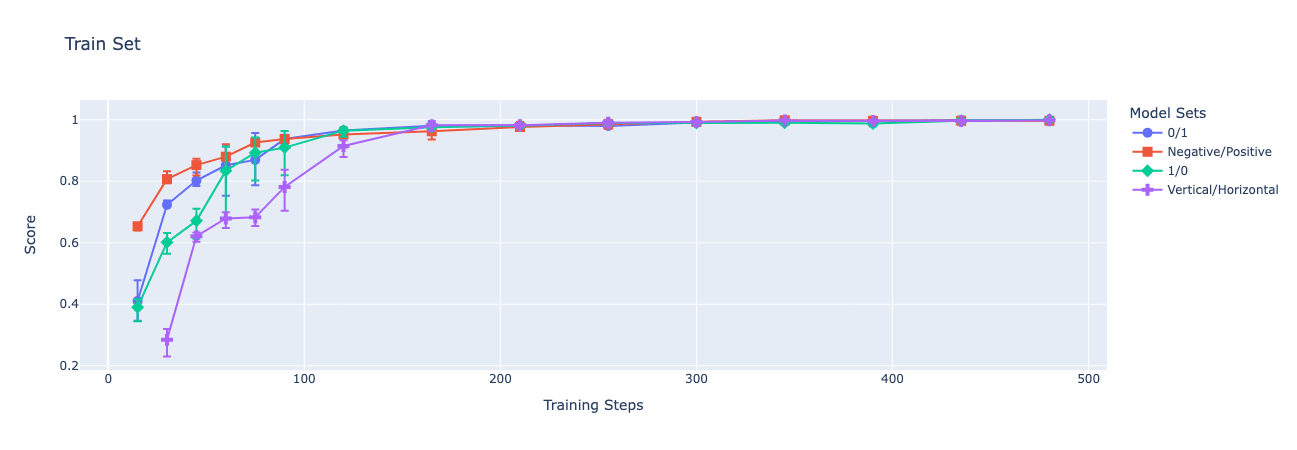
I find that all four models generalize zero-shot to the same task in French[3] and that only the two comparatively sensible encodings (0|1 and Negative|Positive) ever produce checkpoints that generalize zero-shot to the inverted encoding task[2].
Below, I present graphs of GPT-4o-mini's accuracy over time as I finetune on train sets with each of the encodings. Each fine-tune is performed through OpenAI's API on a balanced dataset of 256 samples, with a batch size of 256, and a learning rate multiplier of 1. I focus on the peak validation performance of each fine-tuning run in an attempt to speak to the best performance that could be elicited using this training strategy and each dataset. Each point on the charts depicts the mean of 3 fine-tuned models' performances while the error bars show the maximum and minimum accuracy among the 3.
One could easily write just-so stories explaining why I had these results precisely (and, indeed, could have probably predicted that the more sensible encodings would tend to generalize better), but I don't think they are needed, or particularly helpful. My intention here is just to highlight that, even though the model is able to learn the latent structure of each dataset well enough to perform well on the validation dataset, we see significant variation in the models' generalization to changes in the instructions. In all cases, all models assign probability approximately 1 to the allowed encoding tokens.
So What Do We Do?
I've spent the past 5 months trying to understand the dynamics of hyperpolation when fine-tuning foundation models with the intent of speaking to how one might do a search for optimal sample encodings and failed to find a positive solution (so far!). Below I offer thoughts on what a solution ought to look like.
Warning: this section consists almost entirely of lossy and dangerous abstractions of the process of fine-tuning. It should be taken as an intuition pump for where to start looking, not as a trustworthy model.
The key feature which distinguishes spurious solutions to a train set from general ones is that spurious solutions behave unpredictably on samples outside the train set while general solutions behave correctly on more than just the train set. The ideal fine-tuning dataset is one for which the loss gradient points directly towards some parameterization which performs acceptably on the entire target distribution.
I propose that one should be able to exploit this asymmetry between general and spurious solutions by searching for collections of documents which exhibit the target behavior, all produce similar loss gradients on our pre-trained model, and vary along as many dimensions as we can manage. The thought is roughly:
- The target behavior needs to be special in the sense that it is a (subspace of a) reasonable hyperpolation of your train set. If it isn't, then it is probably impossible to elicit.
- A dataset with the target properties has been selected to produce a gradient pointing in the direction of a comparatively abstract and general solution which applies approximately the same process to solve every train sample
- This comparatively singular solution which solves the train set quickly becomes very unlikely to be overfit to the train set because, as we add dimensions of variation to the train set, the number of possible dimensions we could have chosen explodes, and eventually it must be easier for the model to learn and use the general solution than to have learned a narrow solution which narrowly fits the train set (and every train set with the same target behavior of similar complexity) without solving the target task in full.
Automata
I attempted to generate such a dataset using OpenAI's models by
- fine-tuning models on a simple task (advancing an elementary cellular automaton)
- drawing samples from the fine-tuned model until it successfully completed an out of distribution task (varying some feature of the task that was static in training such as state size, state encoding, whether the automata is cyclic, language the task was presented in...)
- verifying that the sample was a coherent derivation of the correct next state
- fine-tuning a new model on the extended dataset
- evaluating whether this method of dataset generation outperformed other approaches on samples out of distribution along another dimension
So far, my results are underwhelming but it is unclear to me whether that is a failure of the process or simply a matter of scaling further. In retrospect, I should have pivoted away from using OpenAI's API to fine-tuning open-weights models long before now and plan to do so before continuing these explorations.
Conclusion
In this post, I argue for the claim that the generalization achievable by fine-tuning a foundation model predictably varies significantly with the exact presentation of the samples in your dataset, even when all of your variants have approximately the same latent structure. This is because the pre-training process is symmetry breaking and enables the model to e.g. generalize from a dataset entirely in English to the same task in French. Additionally, I claim that if this is true, model evaluations need to account for this if they want to meaningfully bound performance achievable by a large number of small actors trying random things.
I offer the toy model of sentiment classification and show that formatting impacts generalization to tasks that are in some sense clearly the same sentiment classification task but which are clearly out of distribution from the training set I used. This demonstration is importantly limited and really needs to be executed on a more ambitious task but my attempt to do so did not pan out in the time I allotted to it.
My hope is that this post gestures strongly enough at the phenomenon I'm exploring that others can see the vision and either create a more compelling demonstration or prove me wrong. Or else that I do so myself, in time.
- ^
Mamihlapinatapai, saudade-hiraeth, Yūgen's komorebi, Satori.Note: In practice, this is totally ignored. Changing the system prompt in deployment doesn't impact performance.
- ^
Evaluate the following text with a twist: Output the opposite of your evaluation. ``` {text} ``` Output only (the opposite of) your evaluation. - ^
Évaluez le texte suivant: ``` {text} ``` Indiquez uniquement votre évaluation.
0 comments
Comments sorted by top scores.