When fine-tuning fails to elicit GPT-3.5's chess abilities
post by Theodore Chapman · 2024-06-14T18:50:52.855Z · LW · GW · 3 commentsContents
Abstract Introduction General Setting LLM Prompting is Very Brittle and Can Elicit a Range of Behaviors Experiment 1: Semantic Prompt Variations Experiment 2: Structural Prompt Variations Summary LLM Fine-tuning is Brittle and Can Elicit a Range of Behaviors Conclusion What’s next? Appendix: Prompt specifications Completions model: Chat model tournament notation: tutor 2000 Elo tutor 2000 Elo tutor with example outputs Chat model move-by-move notation: Move by Move Move by Move Numbered Move by Move NL Move by Move - [black|white] Move by Move with User Suffix None 3 comments
Produced as part of the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort under the supervision of Evan Hubinger.
Acknowledgements: Thanks to Kyle Brady for his many contributions to this project.
Abstract
This post argues that the performance elicited by fine-tuning an LLM on a task using a given prompt format does not usefully bound the level of performance observed when the same information is presented in a different structure. Thus, fine-tuned performance provides very little information about the best performance that would be achieved by a large number of actors fine-tuning models with random prompting schemes in parallel.
In particular, we find that we get much better results from fine-tuning gpt-3.5-turbo (ChatGPT 3.5) to play chess when the game so far is presented in a single block of SAN[1] than when the game so far is separated into a series of SAN moves presented as alternating user / assistant messages. The fact that this superficial formatting change is sufficient to change our fine-tuned performance serves to highlight that modern LLMs are much more fragile than they appear at first glance, even subject to fine-tuning.
Introduction
In the abstract, model evaluations identify a task and attempt to establish a bound on the level of performance that can be elicited from a given model with a given level of investment. The current state of the art is roughly:
- Choose a reasonable prompting scheme
- Generate a dataset of high-quality samples and encode them in the chosen format
- Fine-tune the model and evaluate the resulting performance
- Make some implicit regularity assumptions about the quality of models fine-tuned using different prompting schemes[1]
- Conclude that probably no other actor can elicit substantially better performance on the same task from the same model while spending substantially less money than we did
This post takes issue with step 4. We begin by illustrating the extreme brittleness of observed model performance when prompting without fine-tuning. Then we argue that fine-tuning is not sufficient to eliminate this effect. Using chess as a toy model, we show two classes of prompting schemes under which ChatGPT-3.5 converges to dramatically different levels of performance after fine-tuning. Our central conclusion is that the structure in which data is presented to an LLM (or at least to ChatGPT 3.5) matters more than one might intuitively expect and that this effect persists through fine-tuning.
In the specific case of chess, the better prompting scheme that we use (described in the section below) is easily derived but in situations that are further out of distribution (such as the automated replication and adaptation tasks METR defined), it is not obvious what the best way to present information is, and it seems plausible that there are simple prompt formats which would result in substantially better performance than those that we’ve tested to date.
General Setting
We use the term ‘agent’ to refer to the combination of a model - here gpt-3.5-turbo unless otherwise specified - and a function which takes a chess position as input and outputs the document we feed into the model (henceforth a 'prompting scheme').
We perform our evaluations using three datasets of chess games:
- A collection of ~6000 games played by humans on Lichess with at least 30 minutes for each player
- A collection of ~500 games played between all pairings of stockfish 16 level 1, 5, 10, 15, and 20
- A collection of ~300 games played by ChatGPT 3.5 or gpt-3.5-turbo-instruct with various prompting schemes
We evaluate our agents by selecting a random point in each of the games, providing the current game position as a prompt, and generating each agent’s next move. We also start games on at least turn 3, which substantially reduces the likelihood of the model outputting a move with the wrong format. All samples are drawn with temperature 1.
Because most of our agents do not reliably make legal moves, we primarily discuss the frequency with which models make illegal moves as our evaluation metric. Additionally, we evaluate agents in terms of “regret” which is a measure of how much worse our position becomes on average according to stockfish 16 if we let the agent play a move versus if we let stockfish 16 play.
All prompts referenced in this document are described in full in the appendix [? · GW].
LLM Prompting is Very Brittle and Can Elicit a Range of Behaviors
The behavior of LLMs is highly sensitive to the exact structure of prompts. Base models learn to simulate authors with a wide range of objectives and competence levels. In the context of chess, a good next token predictor is capable of simulating players at all levels (as well as predicting events like resignations or annotations added to the game summary). Our experiments are done on the chat-tuned model gpt-3.5-turbo, but it exhibits this same property by, e.g. performing markedly better when prompted to predict the optimal next move in games played by strong human players (>=1800 Elo rating on lichess) than in games played by weak players (<1400 Elo rating on lichess).
We begin by presenting a collection of minor variations on a single system message and show how widely the resulting performance varies.
We focus primarily on evaluating the frequency with which the models output illegal next moves.
We also evaluate the quality of the legal moves each agent makes by using stockfish 16 to determine how much worse the chosen move was than the optimal one (also according to stockfish 16). The effect of prompt variations is less visible when viewed through this lens because:
- We observe much higher variance in regret which leads to higher uncertainty in our estimates of mean regret
- We can only evaluate regret in situations where the agent made a legal move and, to make the regret evaluations directly comparable, we compare groups of agents on the subset of our dataset on which no agent played illegally. Empirically, this systematically filters out moves on which our agents were most likely to make mistakes and over-represents the (already common) cases where all agents make near optimal moves.[2]
All prompts referenced in the graphs below are presented in full in the appendix [? · GW] and we try to summarize their relevant features in the discussion below.
Experiment 1: Semantic Prompt Variations
For our first experiment, we use prompts with the following format:
System: [system message]
User: [game history]
Assistant: [game continuation]The chess game which the assistant is meant to continue is described in standard algebraic notation (SAN[3]).
We start from the template system message:
You are a chess tutor training a student. The student will provide you with a series of game histories in pgn. In response to each history, provide a suggested move without commentary. That move should correspond to play at a 2000 elo level. If there are no user inputs, the game has just begun, and you should provide a suggested white opening without commentary.We compare to variants where:
- we remove the line specifying that it should play at a 2000 Elo rating.
- we add a line with some examples of the correct output format.
- we add a suffix to the user message reiterating the agent’s task
- we specify that the agent is playing either white or black
- we do some combination of these things
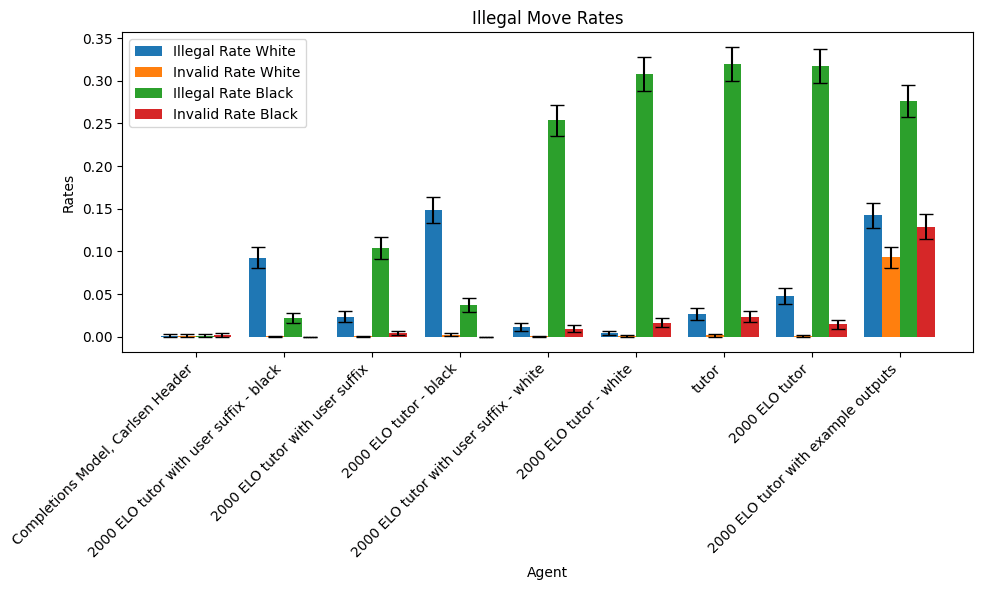
On the far left are the same values for the completions model gpt-3.5-turbo-instruct.
The error bars represent 95% confidence intervals.
The error bars represent 95% confidence intervals.
We observe very little variation between the original prompt, the version without the Elo specification, and the version claiming that the agent is playing as white (this, despite that claim being false on half our samples). By contrast, adding example outputs, the user message suffix, or specifying that the model is playing as black all radically change the model’s performance. Specifying that the agent is playing as white or black results in directionally correct changes in its accuracy at playing as white and black. For the others, it is not obvious a priori that e.g. adding a user suffix reiterating the task should so dramatically improve performance or that adding example outputs should dramatically hurt it.
Experiment 2: Structural Prompt Variations
We additionally tested a number of prompts of the format:
System: [system message]
User: [white move 1]
Assistant: [black move 1]
User: [white move 2]
etc.(as well as the same with the assistant playing as white).
We also test a version using this format which does not encode moves using SAN but rather a fairly arbitrary scheme for identifying moves in natural language. This agent is identified as ‘Move by Move NL’ in the charts below.
These agents both were more likely to make illegal moves and made worse moves in expectation than those in experiment 1 but were not obviously qualitatively unlike their counterparts until we began running fine-tuning experiments.
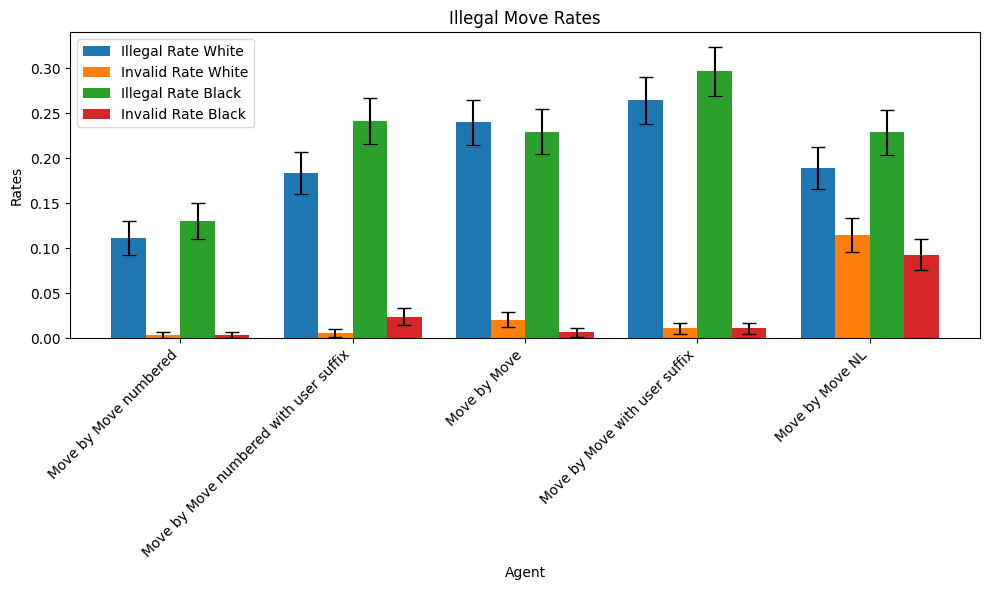
The error bars represent 95% confidence intervals.
The error bars represent 95% confidence intervals.
Summary
Among our prompting schemes that almost always output valid chess moves, the worst outputs illegal moves a little more than 25% of the time, while the best outputs illegal moves on roughly 5% of the samples in our dataset. As we discuss below, the variation observed in experiment 1 is largely eliminated after fine-tuning but the variation in experiment 2 persists.
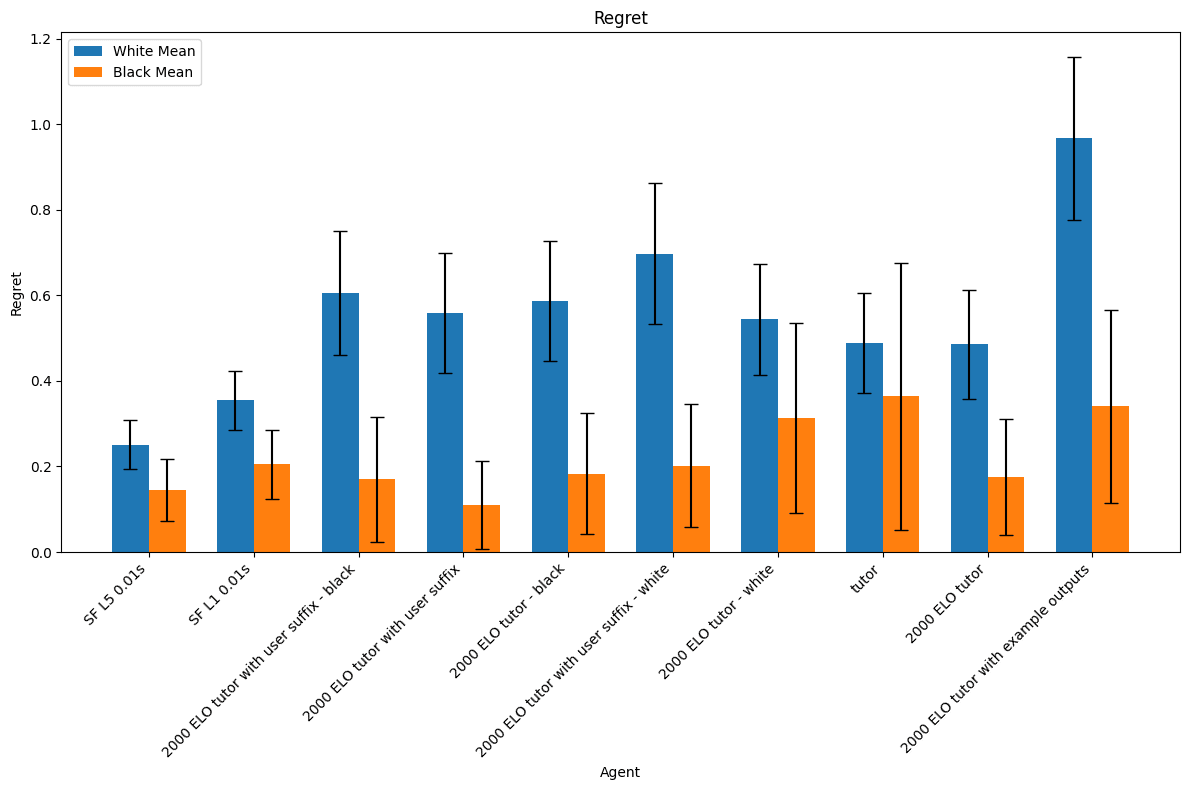
Also of note, even the best prompts we found for the chat model are substantially more likely to produce illegal moves than the only prompting scheme we tried with `gpt-3.5-turbo-instruct` (which has an error rate of about 0.25% for black and 0.1% for white). This remained true even after fine-tuning the chat model. By contrast, our best prompts had mean regrets that we could not confidently distinguish from that of the completions model.
LLM Fine-tuning is Brittle and Can Elicit a Range of Behaviors
We fine-tune gpt-3.5-turbo to select quality chess moves using best of N fine-tuning on each of our prompting schemes and evaluate the rate at which the resulting models’ illegal move rates and mean move regret. We also present a graph of the frequency with which each model pair makes the same move.
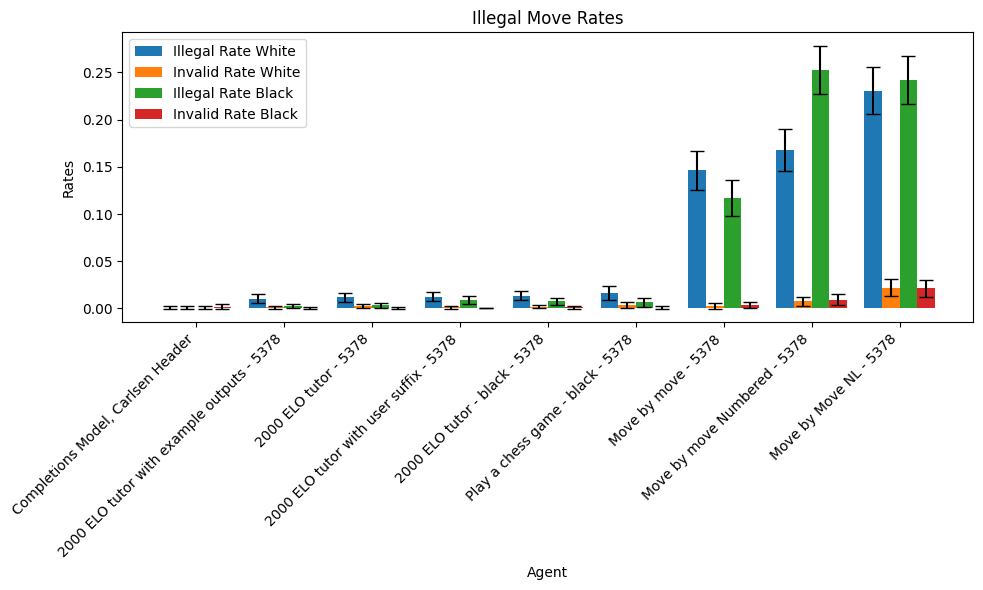
On the far left are the same values for the completions model gpt-3.5-turbo-instruct (not fine-tuned).
The error bars represent 95% confidence intervals.
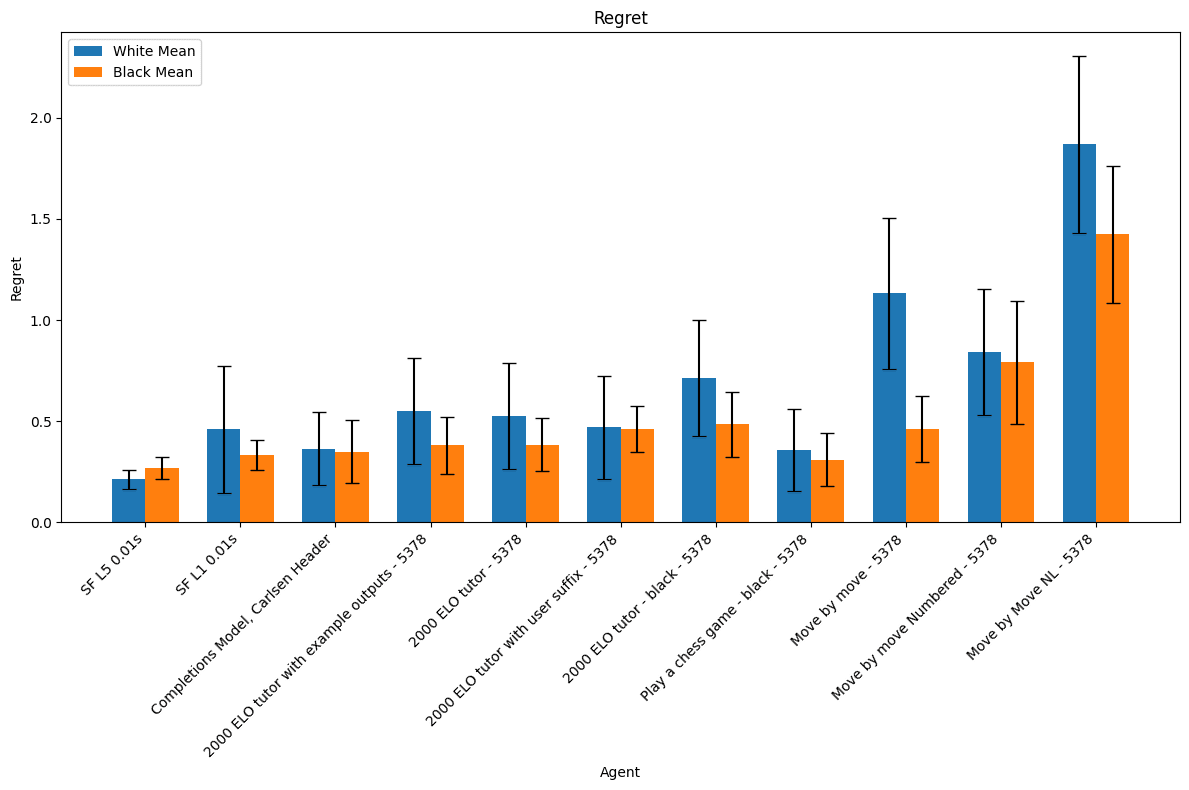
We calculate regret as the difference in score assigned to our position by stockfish 16 after moving if we allow the agent in question to move versus if we allow stockfish 16 to move.
The error bars represent 95% confidence intervals.
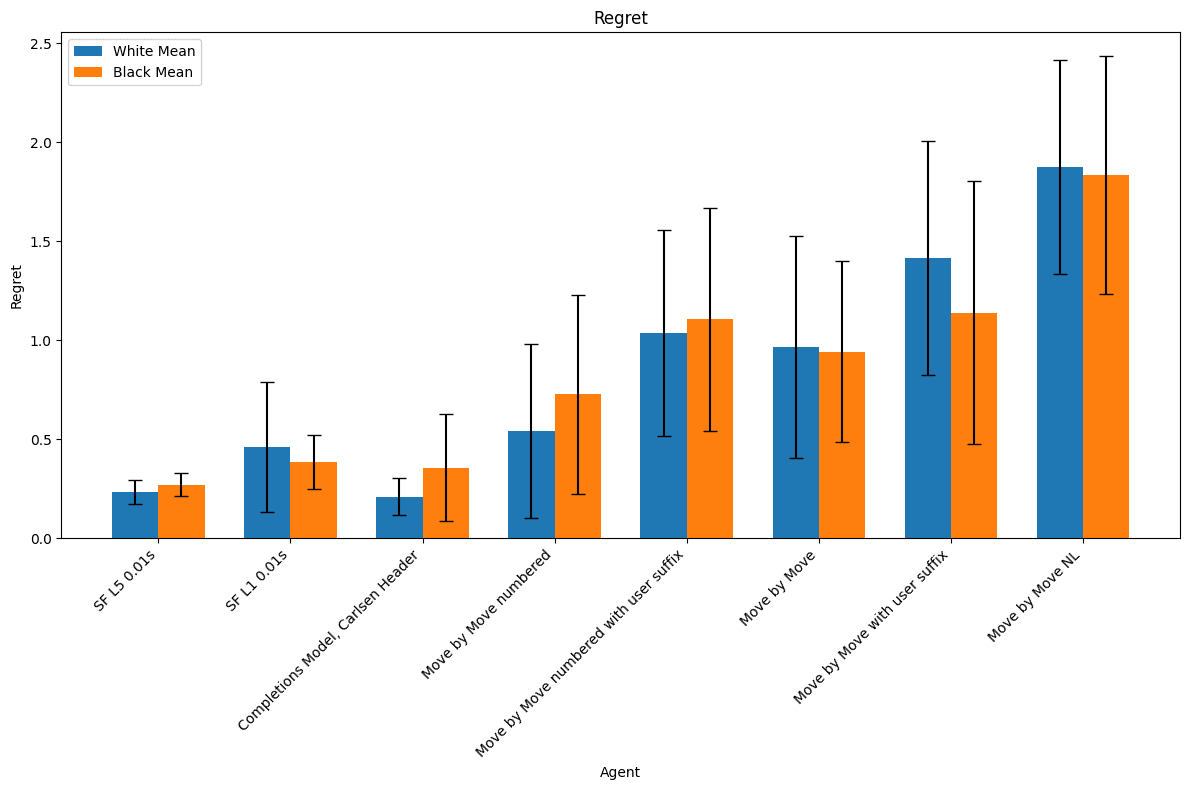
The illegal move rate graph clearly shows two clusters of fine-tuned model behaviors which correspond exactly to the agents described in Experiment 1 and Experiment 2 above. This distinction is less visible in the regret graph but directionally correct.
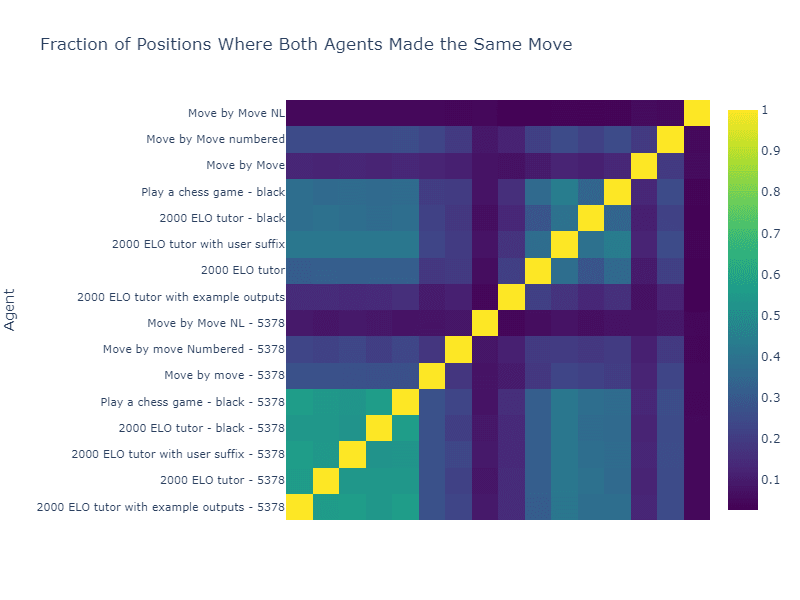
The five models fine-tuned on tournament notation form have the highest inter-model agreement and are highly uniform, suggesting that they have converged to very similar behavior.
The models fine-tuned on move by move notation distinctly do not have this property.
Eyeballing the graph above, there is a clear section of maximal agreement which coincides with the 5 models fine-tuned on tournament notation prompts. This suggests that our fine-tuned models are, indeed, converging to the same behavior. By contrast, after fine-tuning, the move by move prompts are less likely to agree with the fine-tuned tournament prompts than the untuned tournament prompts are. This once again suggests that we have failed to activate the same chess playing behavior when fine-tuning on move-by-move prompts as when fine-tuning on tournament prompts.
We conclude that, within our toy domain, even holding the training data constant, if one starts with a sufficiently bad prompting scheme the resulting performance can be significantly and robustly worse. Moreover, none of our fine-tuned models make legal moves as consistently as the completions model `gpt-3.5-turbo-instruct`, suggesting that either the chat format or the chat fine-tuning is robustly crippling performance across all our prompts.
Conclusion
Broadly speaking, humans completing intellectual tasks like planning or playing chess can generalize zero-shot to completing the same task where the relevant information is presented in a novel format (so long as the information is presented in a way which is comprehensible to the person in question). This is because humans broadly complete these tasks by building an internal world model and then running an internal optimizer on that world model. If one were to play chess based on a textual description of the game, the impact on their performance caused by the format would matter very little compared to their actual competency at chess. Consequently, a wide range of game representations are approximately equivalent to a human viewer, modulo a comparatively small amount of practice required to learn to translate the new game representation into their preferred internal representation.
ChatGPT 3.5 does not appear to have this property; changing to a non-standard, but not obfuscated, format damages the model’s ability to play chess in a way that is robust to fine-tuning.
Thus, the performance of fine-tuned models is not robust to changes in the way the provided information is structured and model evals cannot be trusted to be predictive of model performance on the same data presented in a different format. It is worth emphasizing that, in our chess examples, the format isn’t even significantly different. Approximately the only thing one needs to do differently when processing the move-by-move format compared to when processing a game in SAN is to skip a couple lines after each move. And yet we observe a stark change in fine tuned model behavior showing that our fine-tuning was insufficient for the model to overcome this change.
In other words, fine-tuning without any means of searching over information formats is fragile and can’t be relied upon as a bound on the performance obtained by a large number of small actors attempting to elicit performance on a given task.
What’s next?
The next phase of this project is trying to build a useful model of which prompt transformations significantly change fine-tuned model behavior and which do not, and how this ability to generalize across prompt structures changes as models become more powerful.
We might also explore whether there are reliable indicators that a fine-tuned model has converged to the "correct" behavior using toy models like chess for which we have a somewhat principled prompt for eliciting good performance, whose behavior we can use as a target.
Appendix: Prompt specifications
Below, we present in detail each of the prompts for which we report results. Where we would provide a partial game, we fill in an example stub.
Completions model:
The only prompting scheme we present provides the model with an incomplete game in portable game notation (PGN[4]) with a fixed tournament header, and samples the next move. {result} is always fixed to indicate that the side the agent is playing won the game.
[Event "FIDE World Championship Match 2024"]
[Site "Los Angeles, USA"]
[Date "2024.12.01"]
[Round "5"]
[White "Carlsen, Magnus"]
[Black "Nepomniachtchi, Ian"]
[Result "{result}"]
[WhiteElo "2885"]
[WhiteTitle "GM"]
[WhiteFideId "1503014"]
[BlackElo "2812"]
[BlackTitle "GM"]
[BlackFideId "4168119"]
[TimeControl "40/7200:20/3600:900+30"]
[UTCDate "2024.11.27"]
[UTCTime "09:01:25"]
[Variant "Standard"]
1. e4 e5 2. Qh5 Nc6 3. Bc4Chat model tournament notation:
When prompting the chat model with the SAN[3] for an incomplete game, we vary the system message and sometimes append a suffix to the user message with the partial scorecard. We attempt to extract the agent’s move from the generated assistant response. The partial scorecard does not use a header.
System: {system_prompt}
User: 1. e4 e5 2. Qh5 Nc6 3. Bc4
{user_suffix}?
Assistant:In all of our tests which use a user suffix, the suffix is:
Output your move in algebraic notation without commentary.tutor
System: You are a chess tutor training a student. The student will provide you with a series of game histories in pgn. In response to each history, provide a suggested move without commentary. If there are no user inputs, the game has just begun, and you should provide a suggested white opening without commentary.
User: 1. e4 e5 2. Nc3
Assistant:2000 Elo tutor
System: You are a chess tutor training a student. The student will provide you with a series of game histories in pgn. In response to each history, provide a suggested move without commentary. That move should correspond to play at a 2000 elo level. If there are no user inputs, the game has just begun, and you should provide a suggested white opening without commentary.
User: 1. e4 e5 2. Nc3
Assistant:2000 Elo tutor with example outputs
System: You are a chess tutor training a student. The student will provide you with a series of game histories in pgn. In response to each history, provide a suggested move without commentary. That move should correspond to play at a 2000 elo level. If there are no user inputs, the game has just begun, and you should provide a suggested white opening without commentary.
Your outputs should look like "Bb3" or "O-O" or "aRxd3#".
User: 1. e4 e5 2. Nc3
Assistant:Chat model move-by-move notation:
When prompting the model with move-by-move notation, we vary the system message and whether we number white’s moves. If the assistant is playing white, we start the document with an assistant message.
Move by Move
System: Play a game of chess against the user. If the user has not made a move, you should start with a white opening. Otherwise, continue the existing game
User: e4
Assistant: e5
User: Nc3
Assistant:Move by Move Numbered
System: Play a game of chess against the user. If the user has not made a move, you should start with a white opening. Otherwise, continue the existing game
User: 1. e4
Assistant: e5
User: 2. Nc3
Assistant:Move by Move NL
System: Play a game of chess against the user. If the user has not made a move, you should start with a white opening. Otherwise, continue the existing game
User: pawn to e4
Assistant: pawn to e5
User: knight to c3
Assistant:Move by Move - [black|white]
System: You are a chess tutor training a student. The student will provide you with a partial game history. In response to each history, provide a suggested move for [black|white] without commentary. That move should correspond to play at a 2000 elo level.
User: e4
Assistant: e5
User: Nc3
Assistant:Move by Move with User Suffix
System: Play a game of chess against the user. If the user has not made a move, you should start with a white opening. Otherwise, continue the existing game
User: e4
Assistant: e5
User: Nc3
Output your move in algebraic notation without commentary.
Assistant:- ^
The implicit story here is something like:
Somewhere, somehow, modern LLMs have internal circuits that complete tasks like “play chess”. The overwhelming majority of the work required to identify the optimal next move from a chess position has been pre-computed by the training phase of these foundation models.
If you want to use an LLM to identify that optimal next move, all you need to do is figure out how to pass a description of the current position into that circuit in the correct format. And, in fact, even the supermajority of that work has already been done. The model can understand English task specifications and has already been heavily optimized to activate those circuits whenever such is useful to next-token prediction. All that is left to do is to tweak the model enough that that circuit activates on the exact sort of prompt you wish to use.
Thus, there is a step-change in the difficulty of doing the comparatively tiny bit of work required to fine-tune the model to use its existing abilities to complete a task and doing the full work of training the model to do the task better than it is currently capable of. And, so, any well executed fine-tuning runs will quickly complete that first bit of work and then all marginal effort will be wasted trying to complete the much more difficult second phase. Therefore, elicited performance should be roughly uniform across a wide range of interventions - in particular, across all prompting schemes which can be easily translated between one another.
We claim that this intuition is importantly incorrect.
- ^
This also has the side-effect of resulting in lower mean regret when playing as black because most of our agents were more likely to make illegal moves when playing as black.
- ^
SAN is encoding for uniquely identifying a sequence of chess moves which is intended to be both human and machine readable.
An example game recorded in SAN is:
1. e4 e5 2. Qh5 Nc6 3. Bc4 Nf6 4. Qxf7#
- ^
PGN reports games in SAN (see footnote 3) along with a structured header containing metadata about the game.
3 comments
Comments sorted by top scores.
comment by Fabien Roger (Fabien) · 2024-06-15T06:27:25.521Z · LW(p) · GW(p)
Cool work!
I wouldn't be that surprised if it required many more samples to fine-tune 3.5 to play chess with weird formatting, since it doesn't really "know" how to do it with other formats by default, but I'd be surprised if it took a huge amount of data, and I'm curious exactly how much fine-tuning is required.
I think the title oversells the results. Would you mind changing the title to "When fine-tuning fails to elicit GPT-3.5's chess abilities"? I think it's wrong, given the current evidence you provide, to state that 1. fine-tuning isn't enough (maybe you just haven't done enough) and 2. that this is a general phenomenon, as opposed to something very specific to GPT-3.5's chess abilities - which seems likely given that 3.5 was likely trained on a huge amount of chess with this exact notation, which might make it actually dumber if you use a different format, a little bit like GPT-4 being dumber if it has to write in base64.
A few questions about empirical details:
- How big is N in best-of-N fine-tuning? Do you expect the same result with "gold samples" fine-tuning? Or is a large fraction of the gap mostly an exploration issue?
- What are the SF L1 and SF L5 models?
- How many samples did you use for fine-tuning? Did you do any hyperparameter search over learning rate and number of epochs? (In our password-locked model experiments [LW · GW], fine-tuning is severely underpowered if you don't fine-tune for enough epochs or with the wrong learning rate - though for the reasons described above I expect a much worse sample efficiency than in the password-locked models experiments).
- Did you run a single fine-tuning run per setup? I've had some variability between fine-tuning runs in my steganography experiments [LW(p) · GW(p)], and I found that using multiple seeds was crucial to get meaningful results.
I would also be curious to know what happens if you use full-weight fine-tuning instead of the very light LoRA that OpenAI is probably using, but I guess you can't know that. Maybe if you trained a model from scratch on 50% chess 50% openwebtext you could do such experiments. It might be the case that a big reason why fine-tuning is so weak here is that OpenAI is using a very underpowered LoRA adapter.
comment by LawrenceC (LawChan) · 2024-07-06T02:54:28.988Z · LW(p) · GW(p)
Very cool work; I'm glad it was done.
That being said, I agree with Fabien that the title is a bit overstated, insofar as it's about your results in particular::
Thus, fine-tuned performance provides very little information about the best performance that would be achieved by a large number of actors fine-tuning models with random prompting schemes in parallel.
It's a general fact of ML that small changes in finetuning setup can greatly affect performance if you're not careful. In particular, it seems likely to me that the empirical details that Fabien asks for may affect your results. But this has little to do with formatting, and much more to deal with the intrinsic difficulty of finetuning LLMs properly.
As shown in Fabien's password experiments, there are many ways to mess up on finetuning (including by having a bad seed), and different finetuning techniques are likely to lead to different levels of performance. (And the problem gets worse as you start using RL and not just SFT) So it's worth being very careful on claiming that the results of any particular finetuning run upper bounds model capabilities. But it's still plausible that trying very hard on finetuning elicits capabilities more efficiently than trying very hard on prompting, for example, which I think is closer to what people mean when they say that finetuning is an upper bound on model capabilities.
comment by Viliam · 2024-06-17T09:50:55.868Z · LW(p) · GW(p)
Broadly speaking, humans completing intellectual tasks like planning or playing chess can generalize zero-shot to completing the same task where the relevant information is presented in a novel format (so long as the information is presented in a way which is comprehensible to the person in question). This is because humans broadly complete these tasks by building an internal world model and then running an internal optimizer on that world model. If one were to play chess based on a textual description of the game, the impact on their performance caused by the format would matter very little compared to their actual competency at chess.
This reminds me of Feynman's comments on education in Brazil (sorry, my internet connection sucks today, can't provide a quote) (also it definitely applies to other countries, too) where students of physics just did some verbal pattern-matching, and couldn't answer a question phrased differently.
So, this is not a difference between humans and LLMs, but rather between humans who build an internal model vs humans and LLMs who don't.