Reinforcement Learning: A Non-Standard Introduction (Part 2)
post by royf · 2012-08-02T08:17:08.744Z · LW · GW · Legacy · 7 commentsContents
7 comments
Followup to: Part 1
In part 1 we modeled the dynamics of an agent and its environment as a turn-based discrete-time process. We now start on the path of narrowing the model, in the ambitious search for an explanation and an algorithm for the behavior of intelligent agents.
The spacecraft is nearing the end of its 9 month journey. In its womb rests a creature of marvelous design. Soon, it will reach its destination, and on the surface of the alien planet will gently land an intelligent agent. Almost immediately the agent will start interacting with its environment, collecting and analyzing samples of air and ground and radiation, and eventually moving about to survey the land and to find energy and interesting stuff to do.
It takes too long, about 14 minutes at the time of landing, for the state of Mars to affect the state of the brains of the people at the NASA mission control. This makes the state of the software of the rover important: it will be the one to decide the rover's actions, to a large degree.
Even after it's landed, the software of the rover can be changed remotely, but not the hardware. This puts some limitations on any brilliant ideas we could have for improving the rover at this late stage of the mission. How can we model these limitations?
Our model so far defined the dynamics of the agent's interaction with its environment through the probabilities:
p(Wt|Wt-1,Mt-1)
q(Mt|Mt-1,Wt)
for the current state of the world (Mars) and the agent (the rover), given their previous state.
At some point the rover will take a sample of the air. Could we choose q to be such that Mt at that time will reflect the oxygen level around the rover? Yes, the rover has hardware that, subsequent to analyzing the sample, will have one of a number of possible states, depending on the oxygen levels. It is wired to the rover's central controller, which can then have its state reflect that of the oxygen analyzer.
At some point the rover will take a sample of the ground. Could we choose q to be such that Mt at that time will reflect Mars' sweetness? Probably not any more than it already does. The rover is probably not equipped with any hardware sensitive to substances perceived by living creatures on Earth as sweet. This was a design choice, guided by the assumption that these organic molecules are extremely unlikely to be found on Mars. If they are, the rover cannot be made to reflect their concentration level.
In other words, the rover is not omniscient. The scope of things it can possibly know of the state of Mars is strictly (and vastly) smaller than the scope of things which are true of the state of Mars. We call O for Observation the aspects of the environment that the agent can perceive.
Similarly, p cannot take any value, because the rover is not omnipotent. It has engines, so it can cause Mars (relative to the rover's own point of view) to rotate under its wheels. But it cannot (I dare hope) blast Mars out of existence, nor plant a rose there. We call A for Action the operation of the rover's actuators.
This more detailed model is illustrated in the Bayesian network:
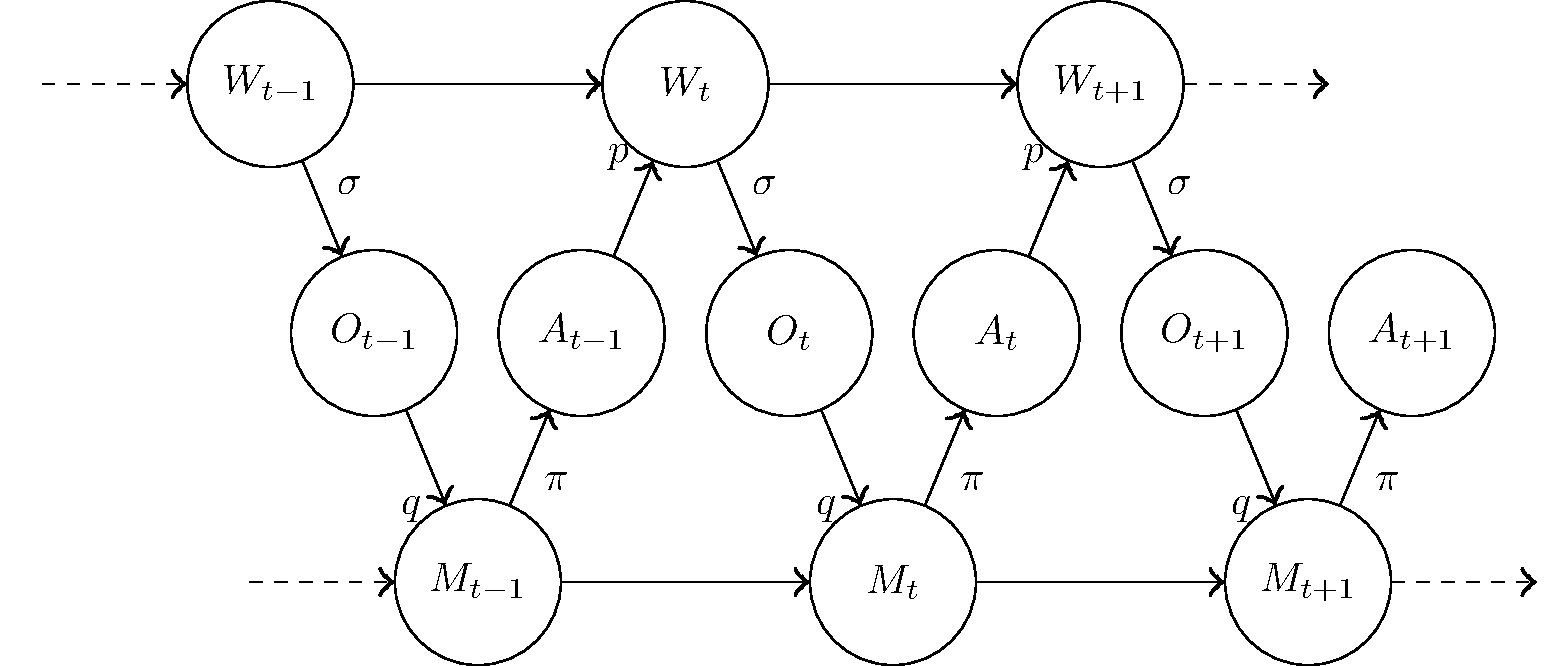
The dynamics of the model are (pardon my Greek)
p(Wt|Wt-1,At-1)
σ(Ot|Wt)
q(Mt|Mt-1,Ot)
π(At|Mt)
Now Mt can only depend on the state of the world Wt through the agent's observation Ot. When designing the rover's software, we can choose the memory update scheme q, thereby deciding how the rover processes the information in Ot and what part of it it remembers. But we cannot change σ, which is how the rover's sensory input depend on the truth of the Martian world.
To clarify: the agent can change, through action, the kind of observations it gets. The quality of the ground sample can greatly improve if the correct appendage actually goes down to the ground. But that's not changing σ. That's changing the position of Mars with respect to the appendage (a part of Wt), and through that affecting the observation.
Similarly, the rover can only change the state Wt of Mars through an action At. The software controls what command is sent to the engines in any state of its execution, which is summarized in π. But it cannot change p, which is how the chosen action and the laws of physics cause Mars to change.
So by adding detail to the model we have introduced further independences, which help narrow the model. Not only is the future independent on the past given the present, but now the dependence between the two parts of the current state, Mt and Wt, is completely explained by the previous memory state Mt-1 and the observation Ot. This means that everything the agent knows about the world must come from the memory and the senses - no clairvoyance!
The symmetric independence - no telekinesis! - can be found by flipping the Bayesian network. Its details are left as an exercise for the reader.
As a final note, the inability to change p or σ is only with respect to that specific rover which is now 14 light minutes away from here. Future rovers can easily have sweetness gauges or rose-planting devices, but they will still not be omniscient nor omnipotent. We can exemplify this principle further on 3 different scales:
1. If we try to improve humans through training and education, but without changing their biology (nor enhancing it with technology), we will probably be limited in the kinds of things we can make the brain notice, or remember, or decide to do.
2. Suppose that some senses (for example, the eye) have reached a local maximum in their evolution, so that any improvement is extremely unlikely. Suppose further that the brain is not in such a local maximum, and can easily evolve to be better. Then the evolution of the brain will be constrained by the current suboptimal properties of the senses.
3. Even if we are allowed to design an intelligent agent from scratch, the laws of physics as we know them will limit the part of the world it can perceive through observations, and the part it can influence through actions.
Continue reading: Reinforcement, Preference and Utility
7 comments
Comments sorted by top scores.
comment by Johnicholas · 2012-08-02T15:25:12.109Z · LW(p) · GW(p)
It might be valuable to point out that nothing about this is reinforcement learning yet.
Replies from: royf↑ comment by royf · 2012-08-03T22:02:29.169Z · LW(p) · GW(p)
I'm not sure why you say this.
Please remember that this introduction is non-standard, so you may need to be an expert on standard RL to see the connection. And while some parts are not in place yet, this post does introduce what I consider to be the most important part of the setting of RL.
So I hope we're not arguing over definitions here. If you expand on your meaning of the term, I may be able to help you see the connection. Or we may possibly find that we use the same term for different things altogether.
I should also explain why I'm giving a non-standard introduction, where a standard one would be more helpful in communicating with others who may know it. The main reason is that this will hopefully allow me to describe some non-standard and very interesting conclusions.
Replies from: Richard_Kennaway, Johnicholas↑ comment by Richard_Kennaway · 2012-08-04T07:35:48.674Z · LW(p) · GW(p)
Please remember that this introduction is non-standard, so you may need to be an expert on standard RL to see the connection.
But since we are not, we cannot.
And while some parts are not in place yet, this post does introduce what I consider to be the most important part of the setting of RL.
Well, there you are. The setting. Not actual RL. So that's two purely preliminary posts so far. When does the main act come on -- the R and the L?
↑ comment by Johnicholas · 2012-08-03T22:19:20.373Z · LW(p) · GW(p)
As I understand it, you're dividing the agent from the world; once you introduce a reward signal, you'll be able to call it reinforcement learning. However, until you introduce a reward signal, you're not doing specifically reinforcement learning - everything applies just as well to any other kind of agent, such as a classical planner.
Replies from: royf↑ comment by royf · 2012-08-04T01:20:33.079Z · LW(p) · GW(p)
That's an excellent point. Of course one cannot introduce RL without talking about the reward signal, and I've never intended to.
To me, however, the defining feature of RL is the structure of the solution space, described in this post. To you, it's the existence of a reward signal. I'm not sure that debating this difference of opinion is the best use of our time at this point. I do hope to share my reasons in future posts, if only because they should be interesting in themselves.
As for your last point: RL is indeed a very general setting, and classical planning can easily be formulated in RL terms.
comment by Matvey_Ezhov · 2013-02-06T14:23:12.147Z · LW(p) · GW(p)
It seems that sufficiently intelligent agent should be able to change sigma. Sufficiently advanced rover might be able to design and assemble new sensors in place, or advanced trading algorithm might look for a new relevant streams of data on the net, or strong AI might modify its sensory mechanisms in various ways. After all, human intelligences do it when they need new tools to make scientific discoveries.