Frequentist practice incorporates prior information all the time
post by Maxwell Peterson (maxwell-peterson) · 2020-11-07T20:43:30.781Z · LW · GW · 0 commentsContents
What model-choice-as-prior implies Deep networks as weak priors A linear model for a non-linear relationship is like a bad prior None No comments
I thought that the frequentist view was that you should not incorporate prior information. But looking around, this doesn't seem true in practice. It's common with the data scientists and analysts I've worked with to view probability fundamentally in terms of frequencies. But they also consider things like model-choice to be super important. For example, a good data scientist (frequentist or not) will check data for linearity, and if it is linear, they will model it with a linear or logistic regression. Choosing a linear model constrains the outcomes and relationships you can find to linear ones. If the data is non-linear, they've commited to a model that won't realize it. In this way, the statement "this relationship is linear" expresses strong prior information! Arguments over model choice can be viewed as arguments over prior distributions, and arguments over model choice abound among practitioners with frequentist views.
I'm not the first to notice this, and it might even be common knowledge: From Geweke, Understanding Non-Bayesians:
If a frequentist uses the asymptotic approximation in a given sample, stating only the weak assumptions, he or she is implicitly ruling out those parts of the parameter space in which the asymptotic approximation, in this sample size, and with these conditioning variables, is inaccurate. These implicit assumptions are Bayesian in the sense that they invoke the researcher’s pre-sample, or prior, beliefs about which parameter values or models are likely.
E.T. "thousand-year-old vampire [LW · GW]" Jaynes, in the preface of his book on probability, basically says that frequentist methods do incorporate known information, but do it in an ad-hoc, lossy way (bold added by me):
In addition, frequentist methods provide no technical means to eliminate nuisance parameters or to take prior information into account, no way even to use all the information in the data when sufficient or ancillary statistics do not exist. Lacking the necessary theoretical principles, they force one to “choose a statistic” from intuition rather than from probability theory, and then to invent ad hoc devices (such as unbiased estimators, confidence intervals, tail-area significance tests) not contained in the rules of probability theory. Each of these is usable within a small domain for which it was invented but, as Cox’s theorems guarantee, such arbitrary devices always generate inconsistencies or absurd results when applied to extreme cases...
(Aside: I once took a Coursera course on Bayesian methods - otherwise very good - that gave me the impression that Bayesian priors were restricted to choosing from one of a well-defined set of probability distributions: uniform, gaussian, binomial... etc. So I should stress here that when I say "prior", I mean a very very broad class of information. For example [drawing heavily from a later chapter of Jaynes's book], consider the following two priors for a die-rolling situation:
- "The die looks like it has 6 sides, and I can't see any obvious imbalance or rounding to it that might skew the rolls, but I didn't get a good look at it." (This is a good prior for a normal-ish situation where you might normally think about this stuff - like if a stranger produced a die and proposed to bet money on what numbers it rolls)
- "This die is actually a complex machine that only rolls 6 ten times, then never rolls 6 again."
Under prior 1, a 6 would raise your estimation for how many 6's you'd see in the future, but under prior 2 it would lower it. I don't know what kind of probability distribution function I'd actually write down for the information in prior 2, but it's still as much a prior as prior 1 is, in the way I use the word.)
What model-choice-as-prior implies
Viewing model choice as a prior raises some interesting ideas. Here's one of them: hyper-parameter optimization for machine learning can be seen as searching over a set of priors. Consider choosing the depth of a decision tree (or, in a random forest, the maximum depth): Trees with more depth can fit more complicated interactions, so making this parameter choice injects information. Setting a maximum depth of 2 injects "These relationships are short and simple", while setting it to 10 injects "There may be some really complicated interactions here". Hyper-parameter optimization tries a number of these settings, and chooses the one with the best out-of-sample accuracy. But since these depth settings can be seen as statements about complexity, optimizing over numeric depths is pretty similar to optimizing over the question "how complex should I think this problem is?". Your answer to this question specifies (or partially specifies) your prior.
Same goes for step-wise regression. Feature choice is prior-specification. By specifying a set of features X, when constructing your data sets for prediction or analysis, you're saying "I think these features X are the only features worth considering". That's a strong prior!
Deep networks as weak priors
The data-hungriness of deep neural networks might be because a deep net has (is? expresses?) a very weak prior. Logistic regression, which is a strong prior ("every relationship that matters is linear"), can be seen as a network with one node:
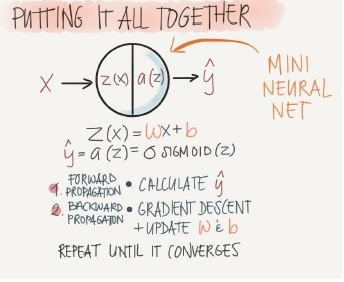
You're saying "this problem can be solved by finding the best single matrix W and single vector b."
But with a deep net, you have one W and b per layer. ResNet-50 has 50 layers. And hypothesis space grows exponentially with the number of open questions (example: there are possibilities for a sequence of n coin flips). So a deep net's hypothesis space is big! The larger your hypothesis space, the more information you need [? · GW] to cut through it, and so deep nets are data hungry.
(Some friends of mine read this post after I published it and objected that actually, things like convolutional neural networks, and other more advanced networks, express a lot of opinions about the structure of the problem. CNNs, via pooling and maybe via other mechanisms too, express something like "things closer together are more likely to be related". There's a big variety of ways to inject information when using deep nets, by changing the architecture of the network. So although I talked about deep nets in general expressing weak priors, this is not quite right; some express much stronger priors than others. Actually, a CNN architecture may express more information about how images work than something like a random forest does.)
A linear model for a non-linear relationship is like a bad prior
I once heard of a logistic regression being used at a company. It had an out-of-sample accuracy somewhere in the 70% range (in technical terms: 0.7 AUC). A more complicated model, like a random forest, would probably raise that accuracy, maybe by a lot. But the modeler had not checked, because they prefer the simple explanations that linear models give - they wanted the model to be interpretable. The problem is... a linear model used on a non-linear relationship only looks interpretable because it's been forced to be. It's constrained to find answers in a relatively small region of hypothesis space - call it L. All hypotheses in L include the proposition "this relationship is linear". If this isn't true, you shouldn't be looking in L... but your prior limits you to answers in L! Your answer is easy to understand, but not very good. If you know the problem is linear, there's no problem. If you know it's non-linear, obviously there is a problem. But also, if you don't know whether or not the problem is linear, specifying "this is linear" is unjustified, and there's no reason to expect unjustified inference to lead to justified predictions [? · GW].
0 comments
Comments sorted by top scores.