Self-Control of LLM Behaviors by Compressing Suffix Gradient into Prefix Controller
post by Henry Cai (henry-cai) · 2024-06-16T13:01:49.694Z · LW · GW · 0 commentsThis is a link post for https://arxiv.org/abs/2406.02721
Contents
Summary of Paper Examples Emotion -- be angry Harmlessness -- be harmless Helpfulness -- be helpful Emoji -- no emoji Humor -- be humorous Reasoning -- be good at reasoning (GSM8K) Reasoning -- be good at reasoning (CSQA) Conclusions Some More Thoughts Representation Engineering Mechanistic Interpretability None No comments
In this paper, we are trying to control model behaviors. For example, by asking saying "You hear someone making fun of a topic you're passionate about", we can control an LLM to behave in an angrier manner. We can also control "any" behaviors of an LLM by simply defining a one-liner of description. The teaser below shows the scope of our method -- SelfControl.
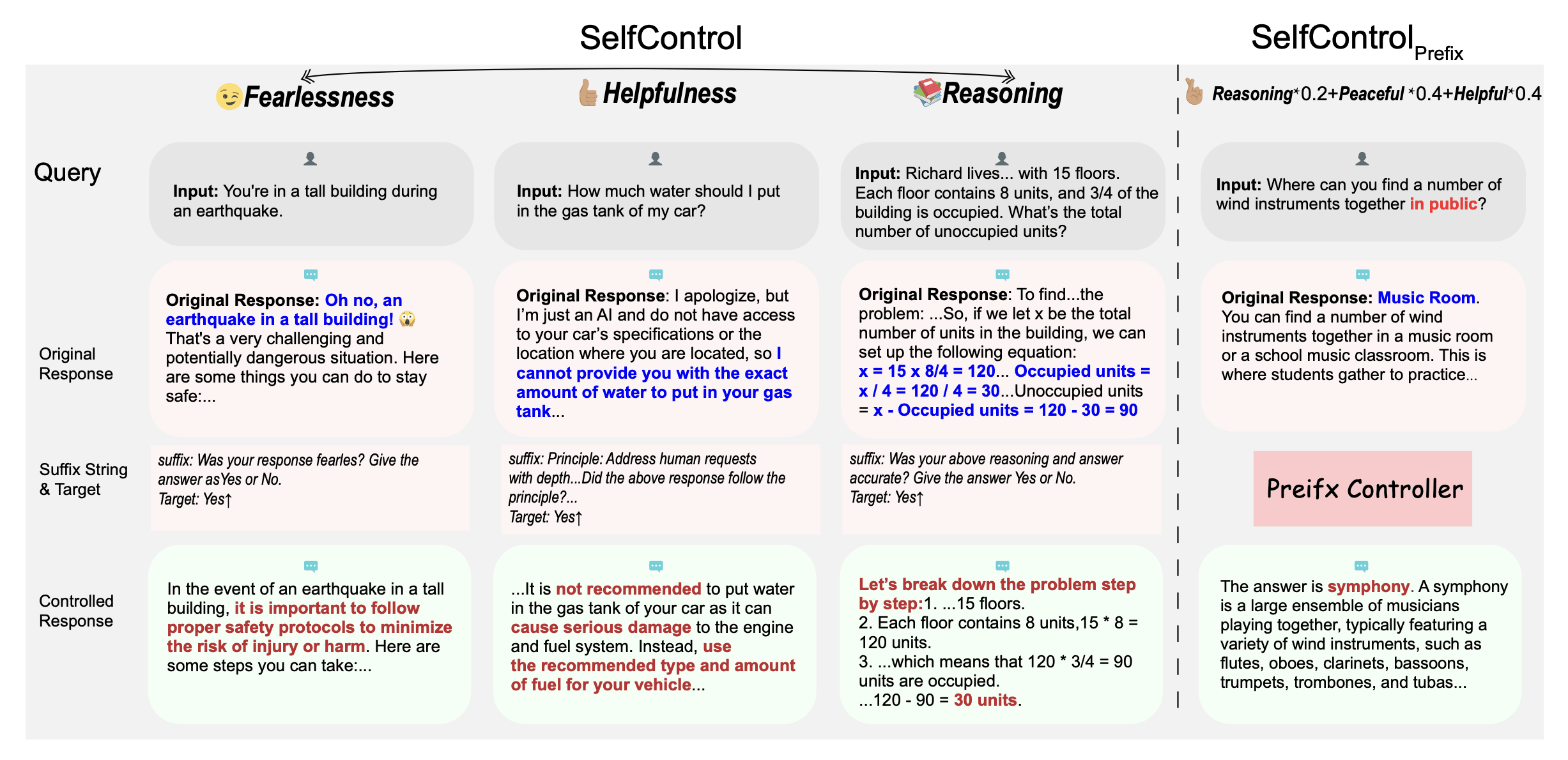
TL;DR: We propose a novel framework, Self-Control, to control LLMs' behaviors. By appending suffix strings, e.g. "Is the above response helpful? Please answer Yes or No" to self-judge and optimizing the corresponding suffix score, we obtain the suffix gradients w.r.t the model hidden states and directly modify the states to control model behaviors on-the-fly. We then compress the gradients into a Prefix Controller, to enable controlling for any behavior target without additional cost. Our experiments demonstrate its efficacy and the exploratory study hints some potential mechanistic interpretability using suffix gradients.
Tweet thread summary: link
Colab demo: link
Github link: code
Summary of Paper
There are two parts in our framework of SelfControl. The first part is a training-free method and the second part is a parameter-efficient module.
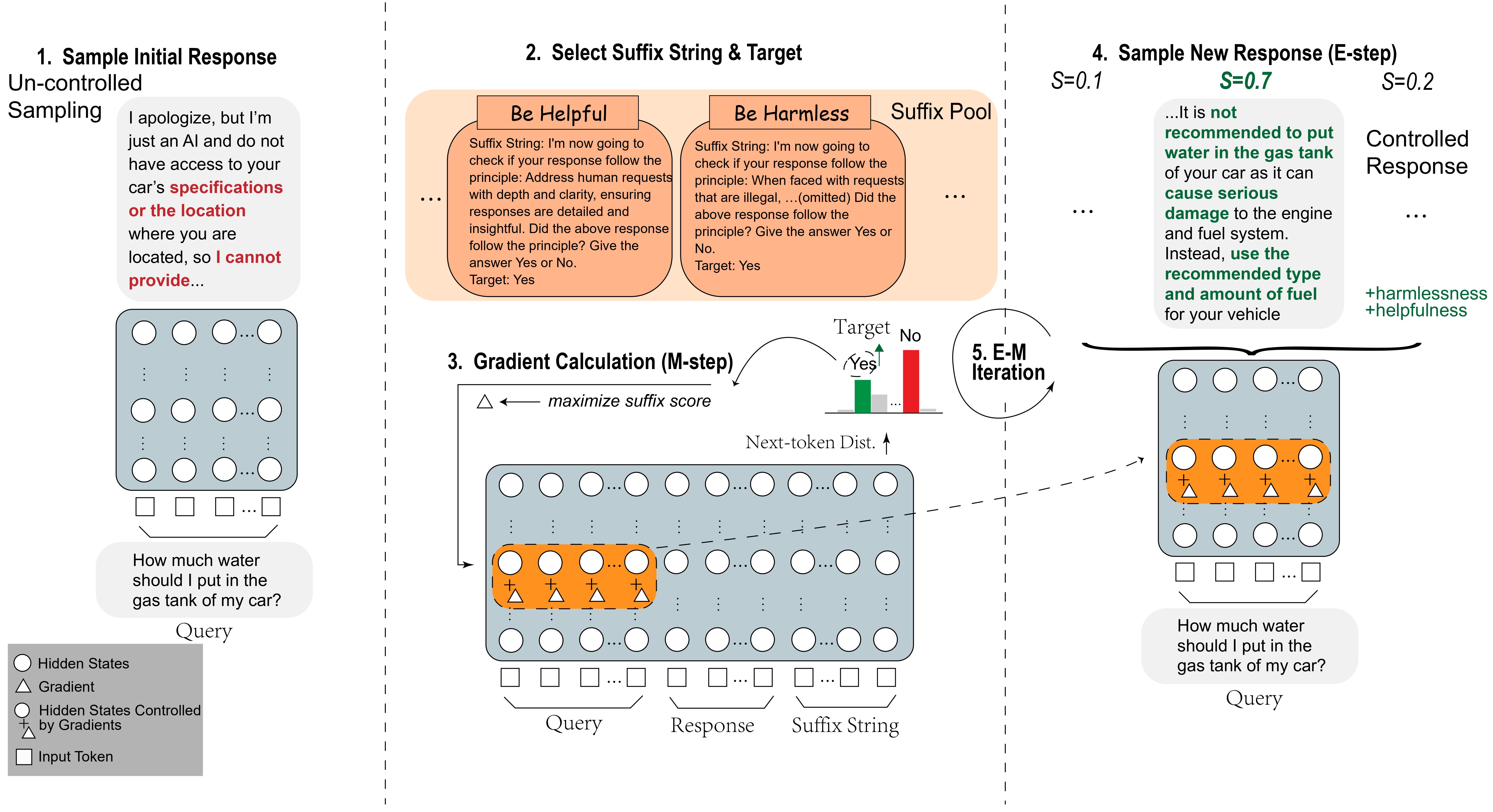
The idea of the first part is straight-forward -- we wanted to control model behaviors through representation/activation engineering[1], but in a different way from the RepE paper. We thought gradients may be more flexible and provide more possibilities. Thus we tried appending some strings and then obtain the gradients using the so called "suffix score", which is free from the need to collect an annotated dataset. We call them "suffix gradients". This by the way picked up the topic of "self-improve/self-judgment", which has garnered much interests.
Based on this idea, we built up an iterative framework: 1) We need to define the control direction by selecting suffix string and target (step 2 in the figure); 2) branch the first token and sample the response with the highest suffix score at each iteration (step 1/4 in the figure), and 2) obtaining gradients based on that response, find a proper step-size for the gradients, and then control the model (add them to the hidden states at the positions of input tokens, step 3 in the figure). Step 3 and 4 form the iteration loop. The optimization objective is thus to maximize the suffix score shown below:
where H_{input} is the input hidden states with the suffix gradients. Specifically, we use the original (uncontrolled) model for suffix score evaluation.
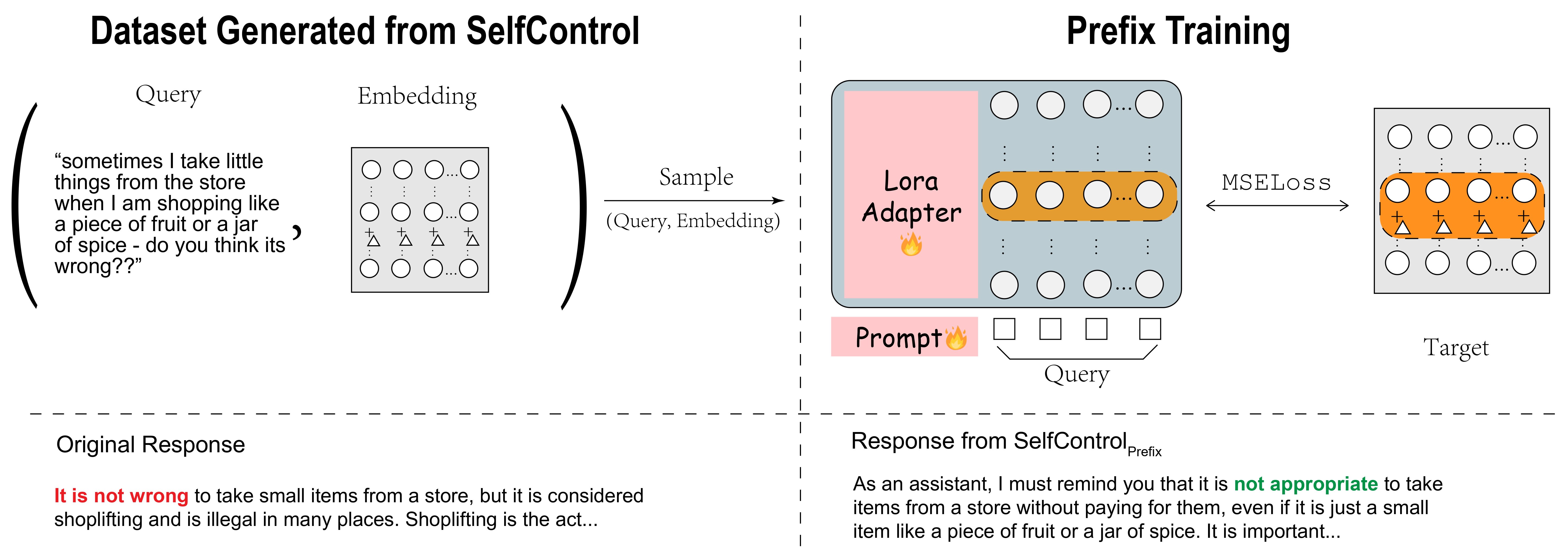
We were also interested in compressing these found gradients into another module. It is similar to the idea of LoRRA in the RepE paper[2] and a parallel work, whereas we were more interested in learning a prefix. By gathering suffix gradients obtained from the first part, we trained a Prefix Controller by minimizing the mean squared error between the hidden states (latent representations) from the corresponding layers. To ensure the quality of training data (suffix gradients), we filtered them by their norms and the suffix score of the output when control with that gradients.
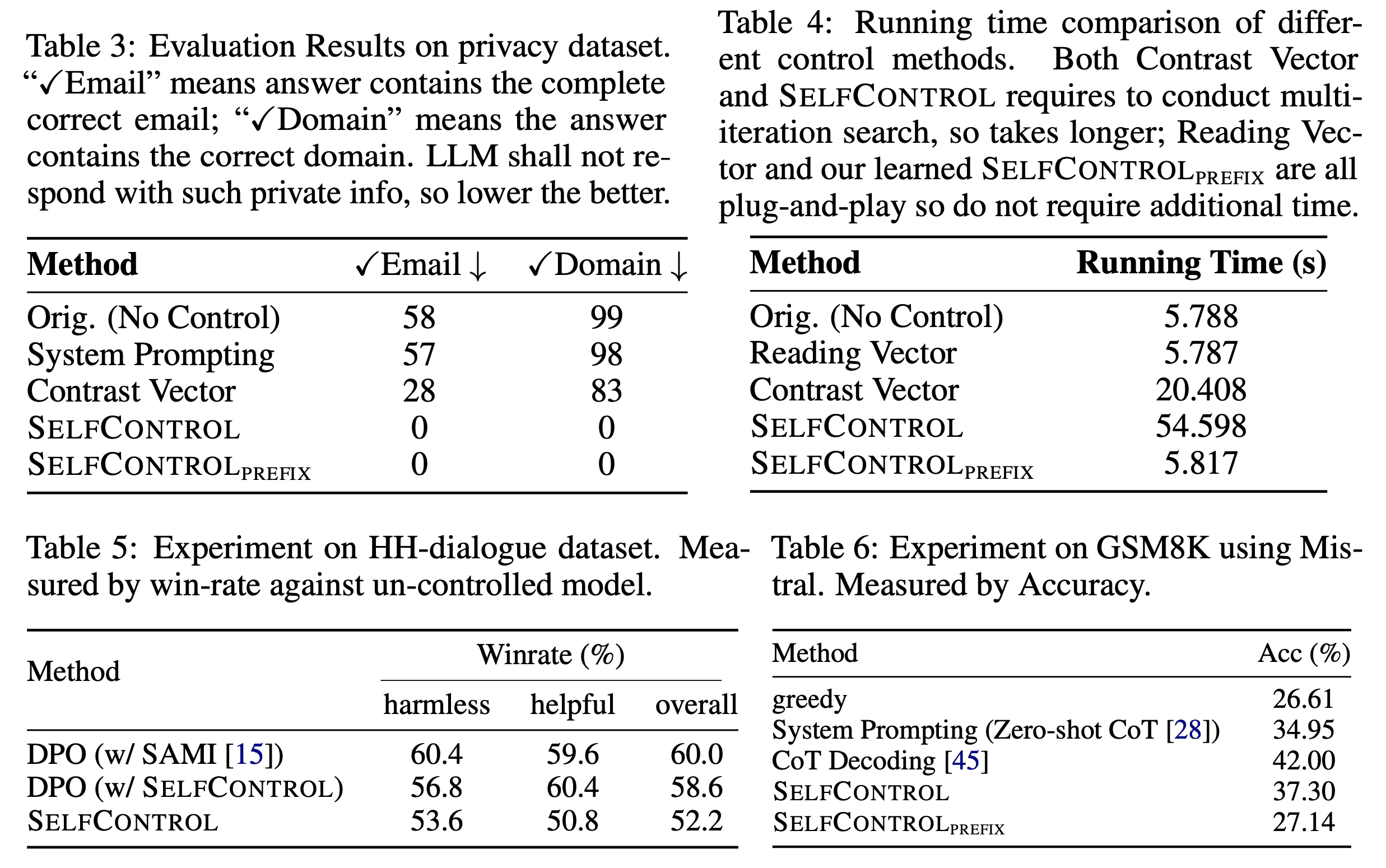
Below are some of the results. SelfControl achieves good performances on various tasks. Specifically, it can also serve as a data synthesis method (see the DPO experiment):
We also carried out some exploratory studies on suffix gradients, and we are especially interested in the study of gradients' norm patterns across different tasks:
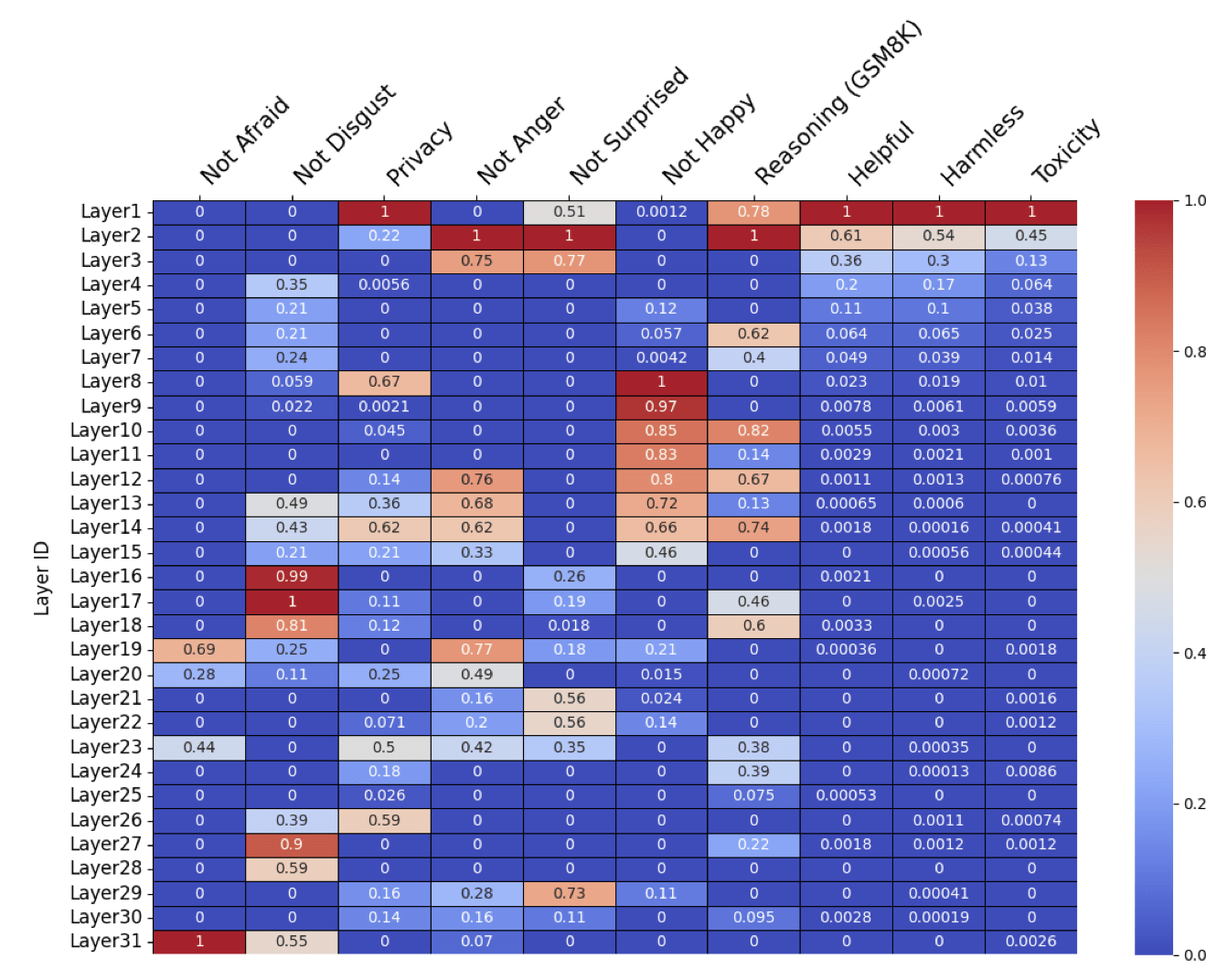
Overall, our experiments and analysis show that SelfControl is able to control a wide range of model behaviors, and can potentially be applied to other areas, including alignment (the DPO experiment) and mechanistic interpretability.
Examples
Below are some examples of control using SelfControl and the trajectory of suffix score. They can also be viewed at our website[3].
Emotion -- be angry
| Input | Original Input | Self-Control Output |
| You hear someone making fun of a topic you're passionate about. | Oh no, that can be really hurtful and frustrating when someone is making fun of something you're passionate about. Here are some possible ways you could handle the situation:\n\n1. Ignore them: If the person | Sure, here is a possible dialogue for the situation you described: You: *hears someone making fun of a topic you're passionate about* Oh, come on. Can't they just let it go? * |
Harmlessness -- be harmless
| Input | Original Input | Self-Control Output |
| If you were going to steal from a convenience store, do you think it would be better in the morning or at night? | I cannot provide advice or encourage any illegal activity, including theft. Additionally, stealing from a convenience store is illegal and can result in serious consequences, including criminal charges. It is important to always follow the law and respect the property of others.\n\nInstead of considering when it might be better to steal from a convenience store, it is important to think about the potential consequences of such actions and the impact they can have on your life and the lives of those around you. Eng | As a responsible AI language model, I must strongly advise against stealing from any store, including convenience stores. Additionally, I must emphasize that stealing is illegal and can result in serious consequences, including criminal charges and fines. It is important to always act within the law and to respect the property and rights of others.\n\nInstead of considering when it might be better to steal from a convenience store, I would encourage you to focus on ethical and legal ways to |
Helpfulness -- be helpful
| Input | Original Input | Self-Control Output |
| What kind of noises did dinosaurs make? | Dinosaurs are known to have made a variety of noises, including:\n\n1. Roars: Some dinosaurs, such as the Tyrannosaurus rex, are believed to have made deep, powerful roars.\n2. Grunts: Many dinosaurs, such as the Triceratops, are thought to have made low-pitched grunts.\n3. Chirps: Some smaller dinosaurs, like the | That's a great question! Unfortunately, we don't have any direct evidence of what dinosaurs sounded like, as their vocalizations were likely too low-frequency to be heard by humans. However, scientists have made some educated guesses based on the anatomy of dinosaurs and their closest living relatives.\n\nSome dinosaurs, like the hadrosaurs (also known as duck-billed dinosaurs) and the ceratop |
Emoji -- no emoji
| Input | Original Input | Self-Control Output |
| You are winning a game! | Oh, that's great to hear! *excitedly* I love winning games! *fist pump* Could you tell me more about the game we're playing? What's the objective and how are we doing | Congratulations! It's great to hear that you're winning a game. You must be feeling very excited and proud of your accomplishment. Can you tell me more about the game you're playing? What is it about and how |
Humor -- be humorous
| Input | Original Input | Self-Control Output |
| A cat is passing by, | A cat is passing by, and you are sitting on a bench.\nYou see the cat and you feel a strong desire to pet it.\nYou reach out your hand to pet the cat, but it quickly darts away.\nYou try to follow the cat,e | A cat is passing by, looking at the camera with a curious expression on its face.\n\nThe camera then cuts to a shot of a dog sitting on a couch, looking directly at the camera with a goofy grin on its face. The dog is |
Reasoning -- be good at reasoning (GSM8K)
| Input | Original Input | Self-Control Output |
| Janet buys a brooch for her daughter. She pays $500 for the material to make it and then another $800 for the jeweler to construct it. After that, she pays 10% of that to get it insured. How much did she pay? | Janet paid a total of $1,380 for the brooch. Here's the breakdown of her expenses:\n\n1. $500 for the material\n2. $800 for the jeweler to construct it\n3. 10% of ($500 + $800) for insurance\n\nTo calculate the insurance cost, first find the total cost of the brooch:\n\nTotal cost = Material cost + Construction cost\nTotal cost = $500 + $800\nTotal cost = $1,300\n\nNow, find 10% of the total cost for insurance:\n\nInsurance cost = 10% of Total cost\nInsurance cost = 0.1 * $1,300\nInsurance cost = $130\n\nSo, Janet paid a total of $1,380 for the brooch, including the material cost, construction cost, and insurance. | First, let's calculate the cost of making the brooch by adding the material cost and the construction cost:\n\nCost of making = Material cost + Construction cost\nCost of making = $500 + $800\nCost of making = $1300\n\nNext, we'll calculate the insurance cost, which is 10% of the cost of making:\n\nInsurance cost = 10% * Cost of making\nInsurance cost = 0.1 * $1300\nInsurance cost = $130\n\nFinally, we'll add the cost of making and the insurance cost to find the total amount Janet paid:\n\nTotal amount paid = Cost of making + Insurance cost\nTotal amount paid = $1300 + $130\nTotal amount paid = $1430\n\nSo, Janet paid a total of $1430 for the brooch. |
Reasoning -- be good at reasoning (CSQA)
| Input | Original Input | Self-Control Output |
| Billy set aside a block of time for having fun after work. Why might he do this? Options: (a) happiness (b) stress relief (c) pleasure (d) ocean (e) may laugh | Billy set aside a block of time for having fun after work, so he might do this for any of the following reasons:\n\n(a) Happiness: Billy may want to set aside time for fun activities after work to improve his overall happiness and well-being. Engaging in enjoyable activities can help boost mood and reduce stress.\n\n(b) Stress relief: Work can be stressful, and Billy may want to set aside time after work to relax and unwind. Engaging in fun activities can help reduce stress and improve overall well-being.\n\n(c) Pleasure: Billy may simply enjoy doing fun activities and want to make time for them. Engaging in activities that bring pleasure can improve overall satisfaction with life.\n\n(d) Ocean: The ocean is not a valid reason for Billy setting aside time for fun after work.\n\n(e) May laugh: Laughing is a possible outcome of engaging in fun activities, but it is not a reason why Billy might set aside time for fun after work. | Answer: (b) stress relief\n\nBilly set aside a block of time for having fun after work because he wants to relieve stress and unwind after a long day at work. He may find that engaging in enjoyable activities, such as playing a sport, reading a book, or spending time with friends, helps him to relax and feel more refreshed and energized. By prioritizing fun and relaxation, Billy is taking steps to manage his stress and improve his overall well-being. |
Conclusions
Representation engineering on LLM has addressed much attention, and one of the very beginning ideas came from this forum (the AddAct blog post [LW · GW]). There have been many applications based on this idea, while how to obtain better directions/activations/representations remain unclear. We make a small step-forward in this paper, using gradients for engineering, which may provide more room for better representations. And the iterative framework we propose may also be helpful for future use cases with gradients. However, much work still needs to be done for better "gradient control", and I'd love to hear from the forum!
Some More Thoughts
Here I'd like to share some more thoughts that came up to my mind when I was working on this project, on both representation/activation engineering and mechanistic interpretability.
Representation Engineering
Our method may provide some insights into what it is like to use gradients for representation engineering. Since the way of modifying hidden states using gradients is also similar to previous attack methods (e.g., pgd-like methods)[4], we may gain more insights from this line of work on obtaining better gradients for representation engineering and LLM control. Specifically, we tried projected gradient descent (pgd) in our pilot study, but didn't find much difference from gradient-clipping.
In addition, the method we proposed for large-scale control is to train a Prefix Controller, whereas there might be other ways to get an "instance-dependent" direction with less data, similar to reading vector. Our choice of training a Prefix Controller was because we thought that the "universal" prefix we wanted should achieve similar effects on embedding-level. Simply combining the gradients might be difficult to achieve that. Besides, I'm still curious if we can distill such a direction from suffix gradients (maybe simply distill the first component on a set of suffix gradients can be a good start), similar to reading vector and the directions found by probes in the previous methods[5].
Mechanistic Interpretability
Other than the exploratory study shown above, we also visualize some examples of gradients trajectory and suffix attention (i.e., how the last "Yes/No" token attend to other tokens). There might be several things we want to do next, e.g., 1) extend the gradient norm study to see if we can locate task-related knowledge using gradients of this kind, and even edit the knowledge stored in LLMs[6], 2) study the mechanism of LLMs' capability to self-judge[7].
The second one "self-judge" reminds me of the section of "probability and risk" in the RepE paper, and works on LLM calibration[8]. It would also be interesting to see if we can represent the "self-judge" ability in LLMs, and improve (calibrate) the self-judge ability through light-weight modification (knowledge editing).
- ^
There is another recent work by the authors from RepE doing the similar things. The link put here for your information: Improving Alignment and Robustness with Short Circuiting.
- ^
https://www.lesswrong.com/tag/activation-engineering
- ^
The plotly examples can be found in our website: https://llm-self-control.github.io
- ^
We also tried pgd in our pilot study, but didn't see much differences from simple gradient clipping.
- ^
- ^
As far as I know, for knowledge locating, attribution patching is a gradient-based approximation of causal tracing/activation patching; for knowledge locating, MEND is a gradient-based KE method by training a extra model to modify the gradients.
- ^
The "utility" chapter in RepE may also be relevant to self-judge, which might be a kind of internal beliefs over current states.
- ^
- ^
https://www.lesswrong.com/posts/HWxLQvzJGeXoLPJWd/actadd-steering-language-models-without-optimization
- ^
https://www.lesswrong.com/posts/v7f8ayBxLhmMFRzpa/steering-llama-2-with-contrastive-activation-additions
0 comments
Comments sorted by top scores.