We Inspected Every Head In GPT-2 Small using SAEs So You Don’t Have To
post by robertzk (Technoguyrob), Connor Kissane (ckkissane), Arthur Conmy (arthur-conmy), Neel Nanda (neel-nanda-1) · 2024-03-06T05:03:09.639Z · LW · GW · 0 commentsContents
Executive Summary Introduction Technique: Attention Head Attribution via Attention Layer SAEs Overview of Attention Heads Across Layers Investigating Attention Head Polysemanticity Discovering Plausibly Monosemantic Heads Case Study: Long Prefix Induction Head Limitations Appendix: Attention Heads Feature Map Citing this work Author Contributions Statement None No comments
This is an interim report that we are currently building on. We hope this update will be useful to related research occurring in parallel. Produced as part of the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort
Executive Summary
- In a previous post we trained attention SAEs [LW · GW] on every layer of GPT-2 Small [LW · GW] and we found that a majority of features are interpretable in all layers. We’ve since leveraged our SAEs as a tool to explore individual attention heads through the lens of SAE features.
- Using our SAEs, we inspect the roles of every attention head in GPT-2 small, discovering a wide range of previously unidentified behaviors. We manually examined every one of the 144 attention heads and provide brief descriptions in this spreadsheet. We note that this is a rough heuristic to get a sense of the most salient effects of a head and likely does not capture their role completely.
- We observe that features become more abstract up to layer 9 and then less so after that. We performed this by interpreting and conceptually grouping the top 10 features attributed to all 144 heads.
- Working from bottom to top layers, 39 of the 144 heads expressed surprising feature groupings not seen before in a previous head.
- We provide feature dashboards for each attention head.
- To validate that our technique captures legitimate phenomena rather than spurious behaviors, we verified that our interpretations are consistent with previously studied heads in GPT-2 small. These include induction heads, previous token heads, successor heads and duplicate token heads. We note that our annotator mostly did not know a priori which heads had previously been studied.
- To demonstrate that our SAEs can enable novel interpretability insights, we leverage our SAEs to develop a deeper understanding of why there are two induction heads in Layer 5. We show that one does standard induction and the other does “long prefix” induction.
- We use our technique to investigate the prevalence of attention head polysemanticity. We think that the vast majority of heads (>90%) are performing multiple tasks, but also narrow down a set of 14 candidate heads that are plausibly monosemantic.
Introduction
In previous work [LW · GW], we trained and open sourced a set of attention SAEs on all 12 layers of GPT-2 Small. We found that random SAE features in each layer were highly interpretable, and highlighted a set of interesting features families. We’ve since leveraged our SAEs as a tool to interpret the roles of attention heads. The key idea of the technique relies on our SAEs being trained to reconstruct the entire layer, but that contributions to specific heads can be inferred. This allows us to find the top 10 features most salient to a given head, and note whenever there is a pattern that it may suggest a role of that head. We then used this to manually inspect the role of every head in GPT-2 small, and spend the rest of this post exploring various implications of our findings and the technique.
In the spirit of An Overview of Early Vision in InceptionV1, we start with a high-level, guided tour of the different behaviors implemented by heads across every layer, building better intuitions for what attention heads learn in a real language model.
To validate that the technique is teaching something real about the roles of these heads, we confirm that our interpretations match previously studied heads. We note that our annotator mostly did not know a priori which heads had previously been studied. We find:
- Induction heads (5.1, 5.5, 6.9, 7.2, 7.10)
- Previous token heads (4.11)
- Copy suppression head (10.7)
- Duplicate token heads (3.0)
- Successor head (9.1)
In addition to building intuition about what different heads are doing, we use our SAEs to better understand the prevalence of attention head polysemanticity at a high level. Our technique suggests that the vast majority of heads (>90%) are doing multiple tasks. This implies that we’ll either need to understand each head’s multiple roles, or primarily use features (rather than heads) as better units of analysis. However, our work also suggests that not all heads are fully polysemantic. We find 9% plausibly monosemantic and 5% mostly monosemantic heads, though we note that as our technique only explores the top 10 most salient features per head it is not reliable enough to prove monosemanticity on its own.
Finally, we’re excited to find that our SAE-based technique helps enable faster mech interp research on non-SAE questions. A long open question concerns why there are so many induction heads. Inspecting salient features for the two induction heads in Layer 5 immediately motivated the hypothesis that one head specializes in “long prefix induction”, wanting the last several tokens to match, while the other performs “standard induction”, only needing a single token to match. We then verified this hypothesis with more rigorous non-SAE based experiments. With so much of the field investing effort in sparse autoencoders, it is nice to have signs of life that these are a legitimately useful tool for advancing the field’s broader agenda.
Technique: Attention Head Attribution via Attention Layer SAEs
Recall that we train our SAEs for GPT-2 small [LW(p) · GW(p)] on the “z” vectors (aka the mixed values aka the attention outputs before a linear map) concatenated across all heads for each layer. See our first post [LW · GW] for more technical details.
We develop a technique specific to this setup: decoder weight attribution by head. For each layer, our attention SAEs are trained to reconstruct the concatenated outputs of each head. Thus each SAE decoder direction is of shape (n_heads * d_head), and we can think of each n_heads slice as specifically reconstructing the output of the corresponding head. We then compute the norm of each slice as a proxy for how strongly each head writes the feature. Finally, for each head, we sort features by their decoder weight attribution to get a sense of what features that head is most responsible for outputting.
For example, for head 7.9, Feature 29342 has a maximal decoder weight attribution of 0.49.
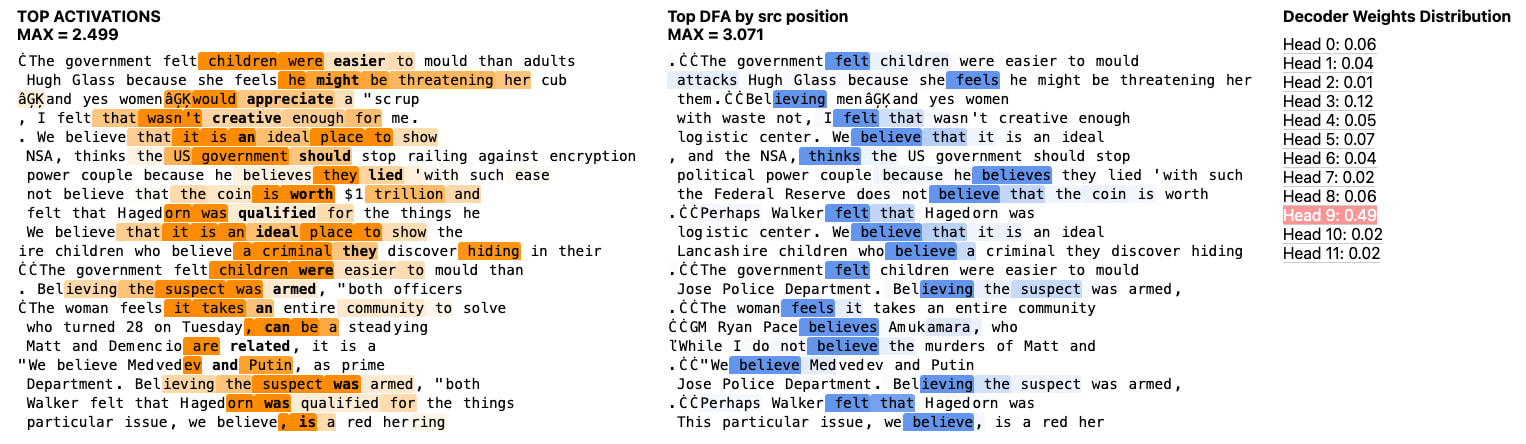
A better metric for determining attribution of SAEs to attention heads might be to look at the fraction of variance explained (FVE) by each head via DFA, as we did in our first post [LW · GW]. However, this is more computationally expensive and an examination of decoder weight attribution against FVE on random heads shows these are correlated and should roughly preserve ranking order. One example for H4.5 is shown below.
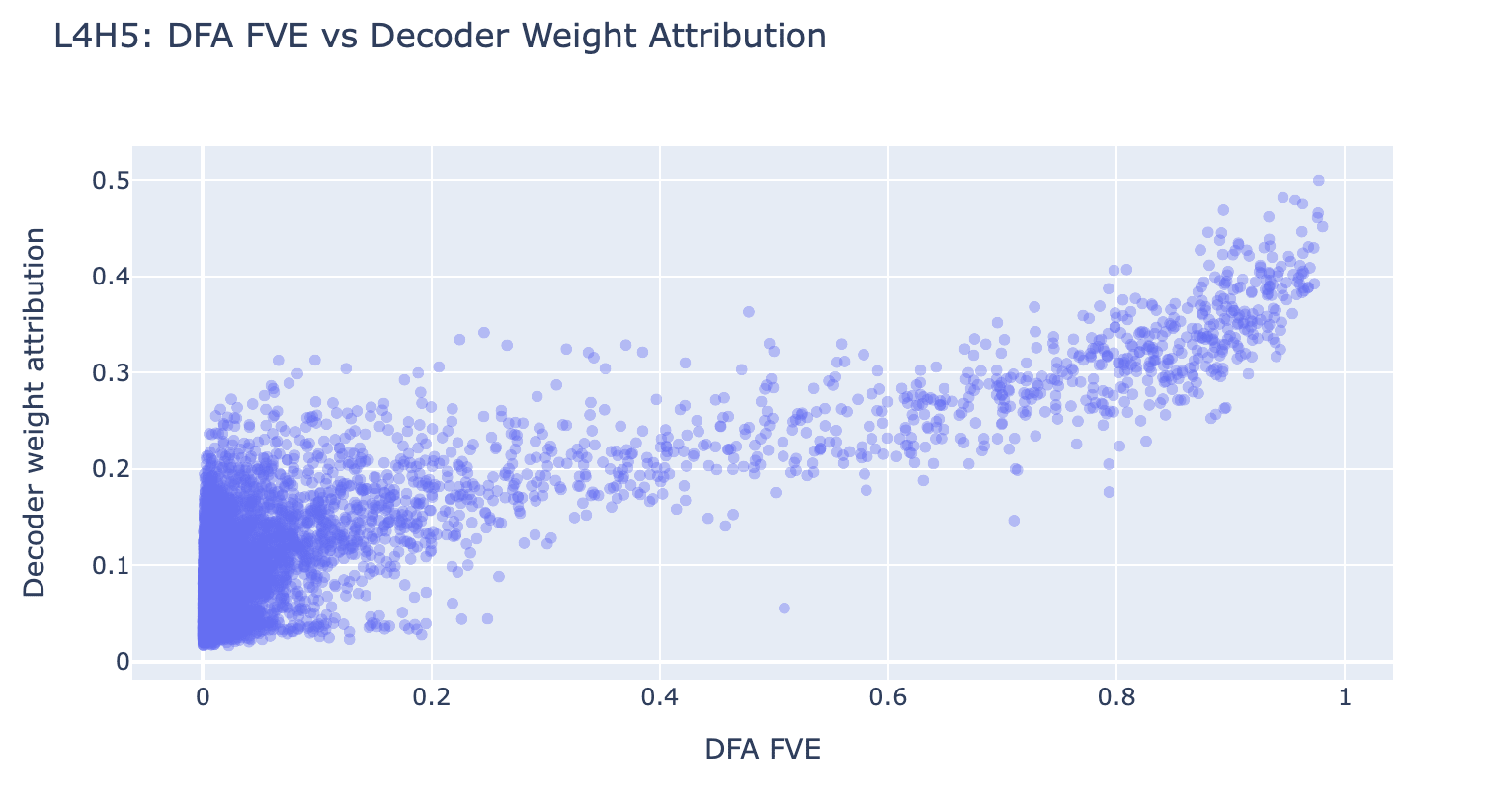
There are a few heads such as H8.5 where top-ranking features by FVE are not as correlated for the top features and using FVE may have produced better results. We recommend using FVE for any reproductions.
Overview of Attention Heads Across Layers
Based on a review of the top 10 SAE features by decoder weight attribution for each attention head, we observed that features become more abstract up to layer 9 and then less so after that.
- We found that layers 0-3 are focused primarily on syntactic features (single-token, bigrams) and secondarily on specific verbs and entity fragments. Some context tracking features are also present.

- From layer 4 onwards, more complex grammatical structures are encoded, including families of related active verbs, prescriptive and active assertions, and some characterizations. Some single-token and bigram syntactic features continue to be present.
- Layers 5-6 were the least interpretable through our SAEs. However, we recovered 2 of the 3 known induction heads in these layers from our features. For example, all top 10 features of H6.9 are induction features.

- Layers 7-8 build increasingly more complex concept features, such as phrasings related to specific actions taken, reasoning and justification related phrases, grammatical compound phrases, and time and distance relationships.

- Layer 9 expressed some of the most complex concepts, with heads focused on specific concepts and related groups of concepts.

- Layer 10 also included complex concept groups, with heads focused on assertions about a physical or spatial property, and counterfactual and timing/tense assertions.
- The last layer 11 exhibited mostly grammatical adjustments, some bi-gram completions and one head focused on long-range context tracking.

- Although the above summarizes what was distinctive about each layer, later layers continued to express syntactic features (e.g. single token, url completion) and simple context tracking features (e.g. news articles).
The table below summarizes the kind of feature groupings that we identified across the various layers. Notable heads indicated with an asterisk (*) were particularly interesting as possibly monosemantic due to exhibiting the same feature grouping for all top 10 features.
| Layer | Feature groups / possible roles | Notable Heads |
| 0 | - Single-token (“of”) - Bi-gram features (following “S”) - Micro-context features (cars, Apple tech, solar) | - H0.1: Top 6 features are all variants capturing “of” - H0.9: Long range context tracking family (headlines, nutrition facts, lists of nouns) |
| 1 | - Single-token (Roman numerals) - Bi-gram features (following “L”) - Specific noun tracking (choice, refugee, gender, film/movie) | - H1.5*: Succession or pairs related behavior - H1.8: Long range context tracking with very weak weight attribution |
| 2 | - Short phrases (“never been…”) - Entity features (court, media, govt) - Bi-gram & tri-gram features (“un-”) - Physical direction and logical relationships (“under”) - Entities followed by what happened (govt) | - H2.0: Short phrases following a predicate like not/just/never/more - H2.5: Subject tracking for physical directions (under, after, between, by), logical relationships (then X, both A and B) - H2.7: Groups of context tracking features |
| 3 | - Entity-related fragments (“world’s X”) - Tracking of a characteristic (ordinality or extremity) (“whole/entire”) - Single-token and double-token (eg) - Tracking following commas (while, though, given) | - H3.0: Identified as duplicate token head from 8/10 features - H3.11: Tracking of ordinality or entirety or extremity |
| 4 | - Active verbs (do, share) - Context tracking families (story highlights) | - H4.5: Characterizations of typicality or extremity - H4.7*: Weak/non-standard duplicate token head - H4.11*: Identified as a previous token head based on all features |
| 5 | - Induction (F) | - H5.1: Long prefix Induction head - H5.5: Induction head |
| 6 | - Induction (M) - Active verbs (want to, going to) - Local context tracking for certain concepts (vegetation) | - H6.3: Active verb tracking following a comma - H6.7: Local context tracking for certain concepts (payment, vegetation, recruiting, death) - H6.9*: Induction head - H6.11: Suffix completions on specific verb and phrase forms |
| 7 | - Induction (al-) - Active verbs (asked/needed) - Reasoning and justification phrases (because, for which) | - H7.2*: Non-standard induction - H7.10*: Induction head |
| 8 | - Active verbs (“hold”) - Compound phrases (either) - Time and distance relationships - Quantity or size comparisons or specifiers (larger/smaller) - Url completions (twitter) | - H8.1*: Prepositions copying (with, for, on, to, in, at, by, of, as, from) - H8.5: Grammatical compound phrases (either A or B, neither C nor D, not only Z) - H8.8: Quantity or time comparisons or specifiers |
| 9 | - Complex concept completions (time, eyes) - Grammatical relationship joiners (between) | - H9.0*: Complex tracking on specific concepts (what is happening to time, where focus should be, actions done to eyes, etc.) - H9.2: Complex concept completions (death, diagnosis, LGBT discrimination, problem and issue, feminism, safety) - H9.9*: Copying, usually names, with some induction |
| 10 | - Grammatical adjusters - Physical or spatial property assertions | - H10.1: Assertions about a physical or spatial property (up/back/down/ over/full/hard/soft/long/lower) - H10.4: Various separator character (colon for time, hyphen for phone, period for quantifiers) - H10.5: Counterfactual and timing/tense assertions (if/than/had/since/will/would/until/has X/have Y) - H10.6: Official titles - H10.10*: Capital letter completions with some context tracking (possibly non-standard induction) - H10.11: Certain conceptual relationships |
| 11 | - Grammatical adjustments - Bi-grams - Capital letter completions - Long range context tracking | - H11.3: Late layer long range context tracking, possibly for output confidence calibration |
Investigating Attention Head Polysemanticity
While our technique is not sufficient to prove that a head is monosemantic, we believe that having multiple unrelated features attributed to a head is evidence that the head is doing multiple tasks. We also note that there is a possibility we missed some monosemantic heads due to missing patterns at certain levels of abstraction (e.g. some patterns might not be evident from a small sample of SAE features, and in other instances an SAE might have mistakenly learned some red herring features).
During our investigations of each head, we found 14 monosemantic candidates (i.e. all of the top 10 attributed features for these heads were closely related). This suggests that over 90% of the attention heads in GPT-2 small are performing at least two different tasks.
To explicitly show an example of a polysemantic head, we use evidence from what SAEs attributed to the head have learned to deduce that the head performs multiple tasks. In H10.2, we find both integer copying behavior and url completion behavior in the top SAE features. Zero ablating each head in Layer 10 and recording the mean change in loss on synthetic datasets[1] for each task shows a clear jump for H10.2 relative to other heads in L10, confirming that this head really is doing both of these tasks:
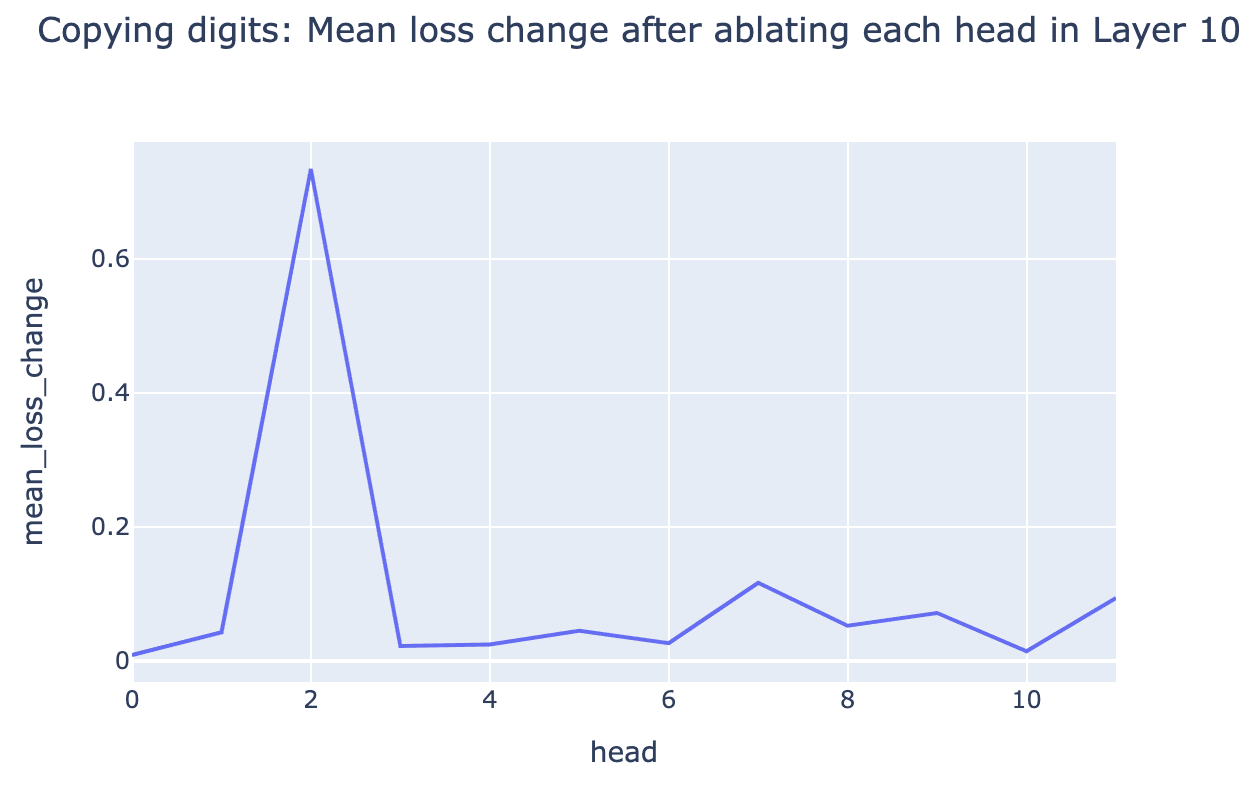
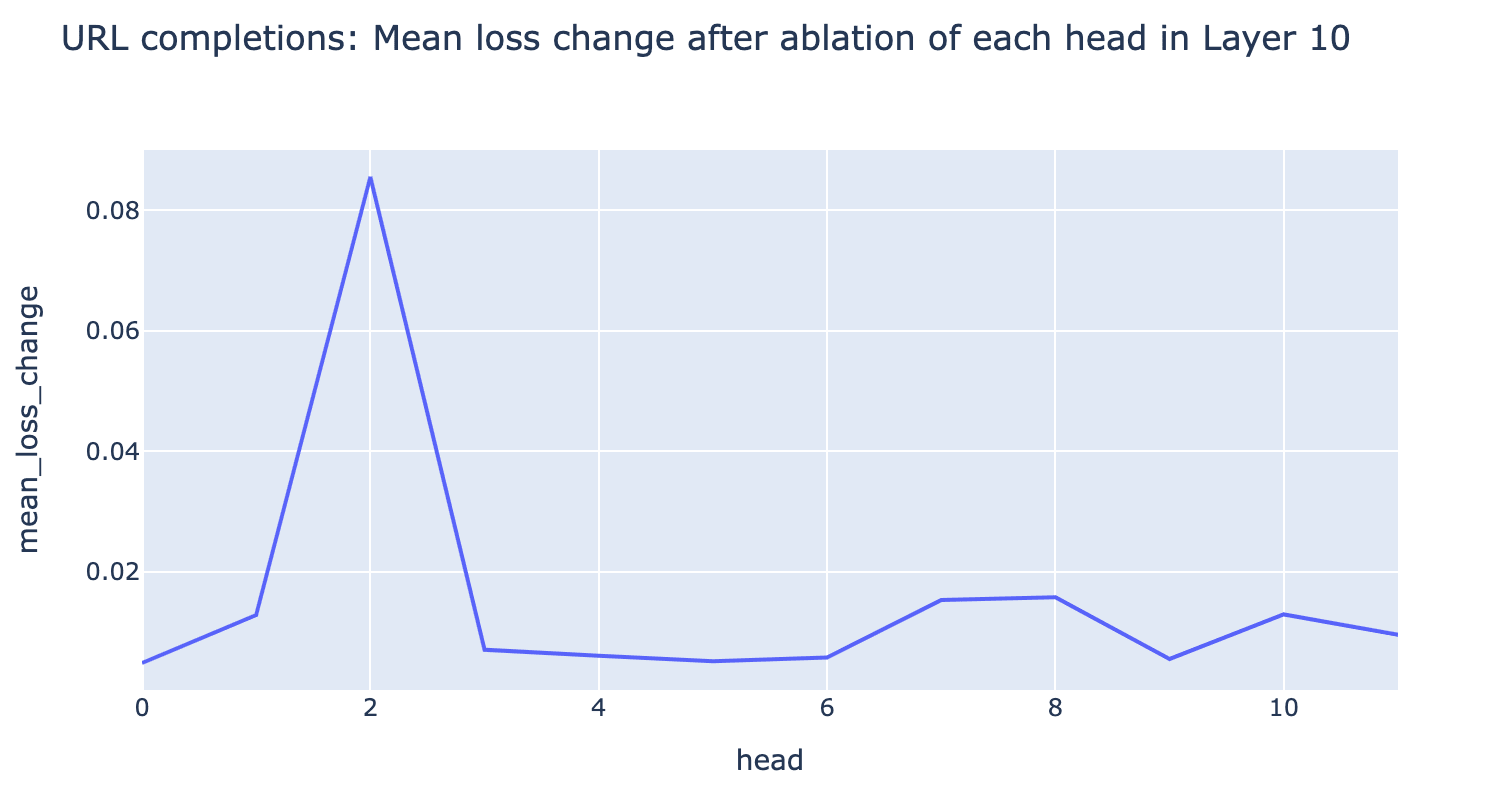
Note that the line between polysemantic and monosemantic heads is blurry, and we had a high bar for considering monosemantic candidates. For example, consider H5.10: all 10 features look like context features, boosting the logits of tokens related to that context. We labeled this as polysemantic since some of the contexts are unrelated, but we could plausibly think of it as a general monosemantic “context” head. We also think that head polysemanticity is on a spectrum (e.g. heads with 2 roles are less polysemantic than heads with 10). If we can understand the multiple roles of a polysemantic head, it still might be worth trying to fully understand it in the style of McDougall et al.
Discovering Plausibly Monosemantic Heads
While our technique doesn’t prove that heads are monosemantic, we are excited that our SAEs might narrow down the search space for monosemantic heads, and reveal new, messier behaviors that have been historically harder to understand in comparison to cleaner algorithmic tasks.
For the monosemantic candidates, we see a range of different behaviors:
- Local context features in descriptions of some entity (2.9)
- Previous token (4.11, 5.6)
- Induction (5.5, 6.9, 7.10)
- Long prefix induction (5.1)
- Preposition copying (8.1)
For example, consider H8.1. For all top 10 features, the top DFA suggests that the head is attending to a different preposition (including ‘with’, ‘from’, ‘for’, ‘to’), and the top logits boost that same preposition. This suggests that this might be a monosemantic “Preposition mover” head that specifically looks for opportunities to copy prepositions in the context.

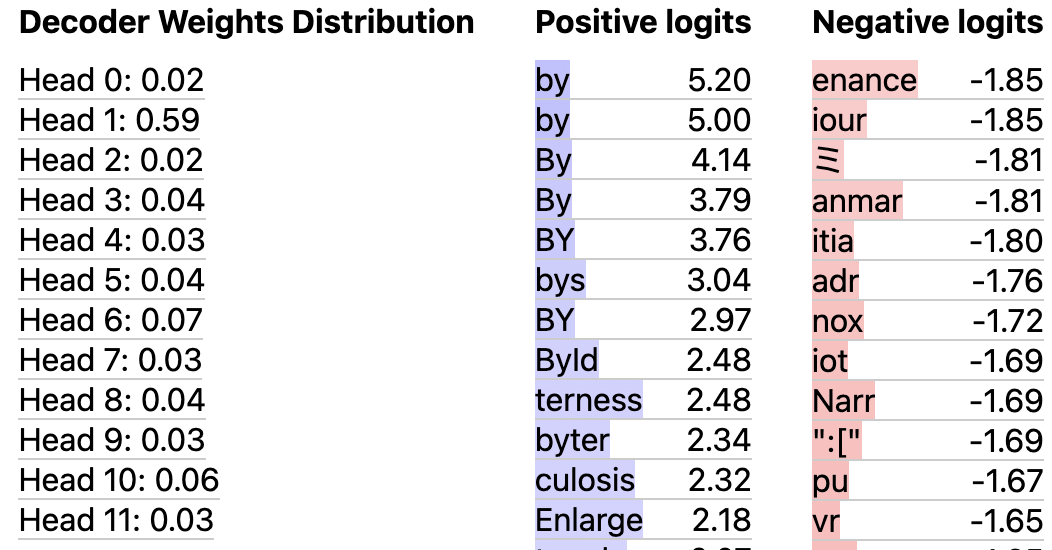
As shown in the table below, we also found instances where a head was almost monosemantic or plausibly bisemantic.
| Head Type | Fraction of Heads |
| Plausibly monosemantic: All top 10 features were deemed conceptually related by our annotator. | 9.7% (14/144) |
| Plausibly monosemantic, with minor exceptions: All features were deemed conceptually related with just one or two exceptions. | 5.5% (8/144) |
| Plausibly bisemantic: All features were clearly in only two conceptual categories. | 2.7% (4/144) |
Case Study: Long Prefix Induction Head
To further verify that our SAE features are teaching us something real about the roles of heads, we show that we can distinguish meaningfully different roles for two induction heads in L5 of GPT-2 small, shedding some light on why there are so many induction heads in language models. We find that one head seems to be specializing in “long prefix induction”, while one head mostly does “standard induction”.
Notably this hypothesis was motivated by our SAEs, as glancing at the top features attributed to 5.1 shows “long induction” features, defined as features that activate on examples of induction with at least two repeated prefix matches (eg 2-prefix induction: ABC … AB -> C). We spot these by comparing tokens at (and before) each top feature activation with the tokens preceding the corresponding top DFA[2] source position. While previous work from Goldowsky-Dill et al found similar “long induction” behavior in a 2-layer model, we (Connor and Rob) were not aware of this during our investigations, showing that our SAEs can teach us novel insights about attention heads.
As an illustrative example, we compare two “‘-’ is next by induction” features attributed to heads 5.1 and 5.5 respectively. Notice that all of the top examples for 5.1’s feature are examples of long prefix induction, while almost all of the examples in 5.5’s feature are standard (AB ... A -> B) induction. For example, comparing the top DFA to the feature activation for 5.1’s top example shows a 4-prefix match (.| ”|Stop| victim), while 5.5’s top feature is 1-prefix ( center).


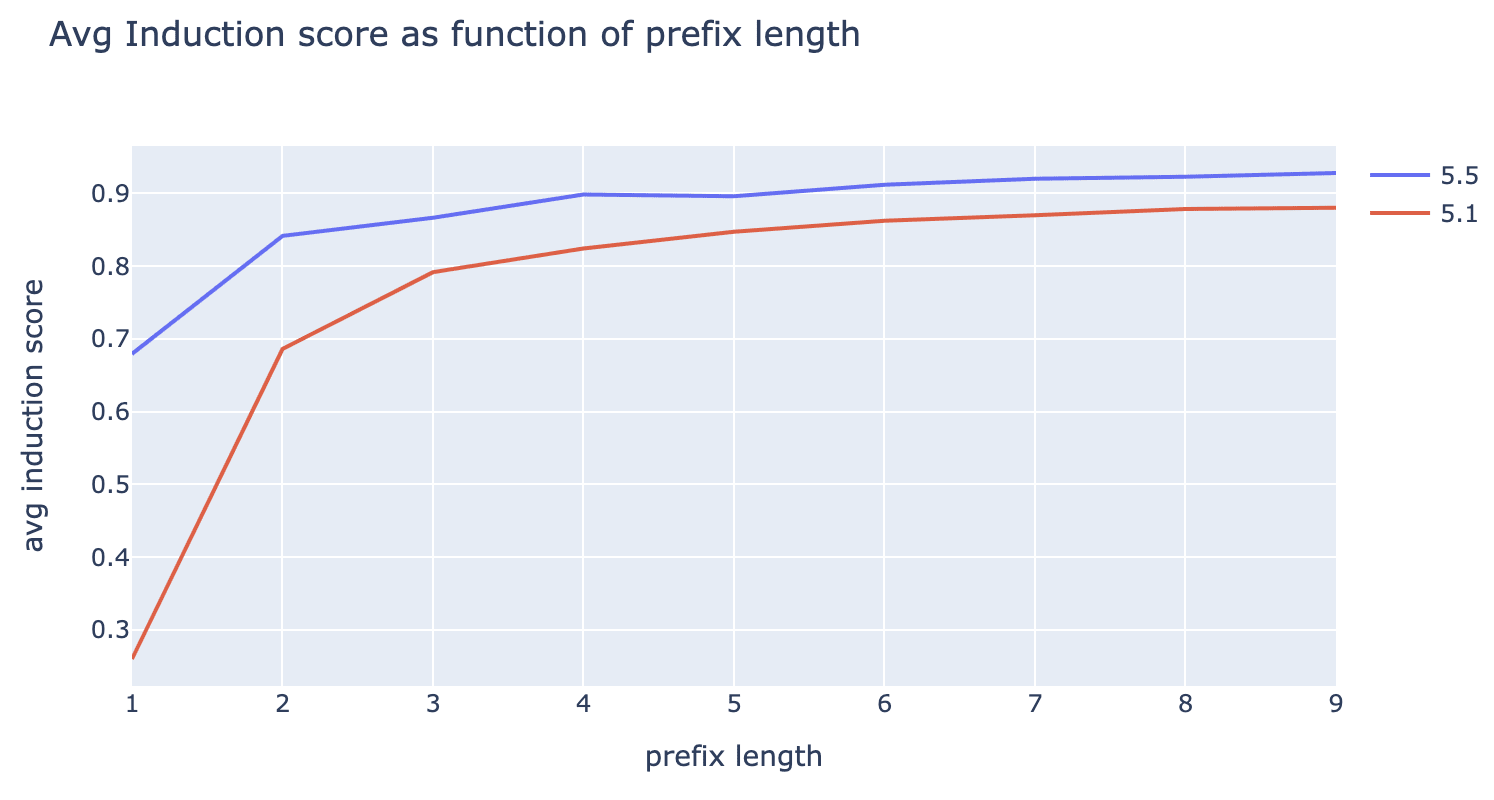
To confirm that this isn’t just an artifact of our SAEs, we reinforce this hypothesis with independent lines of evidence. We first generate synthetic induction datasets with random repeated tokens of varying prefix lengths. We confirm that while both induction scores rise as we increase prefix length, 5.1 has a much more dramatic phase change as we transition to long prefixes (i.e. >=2 ):
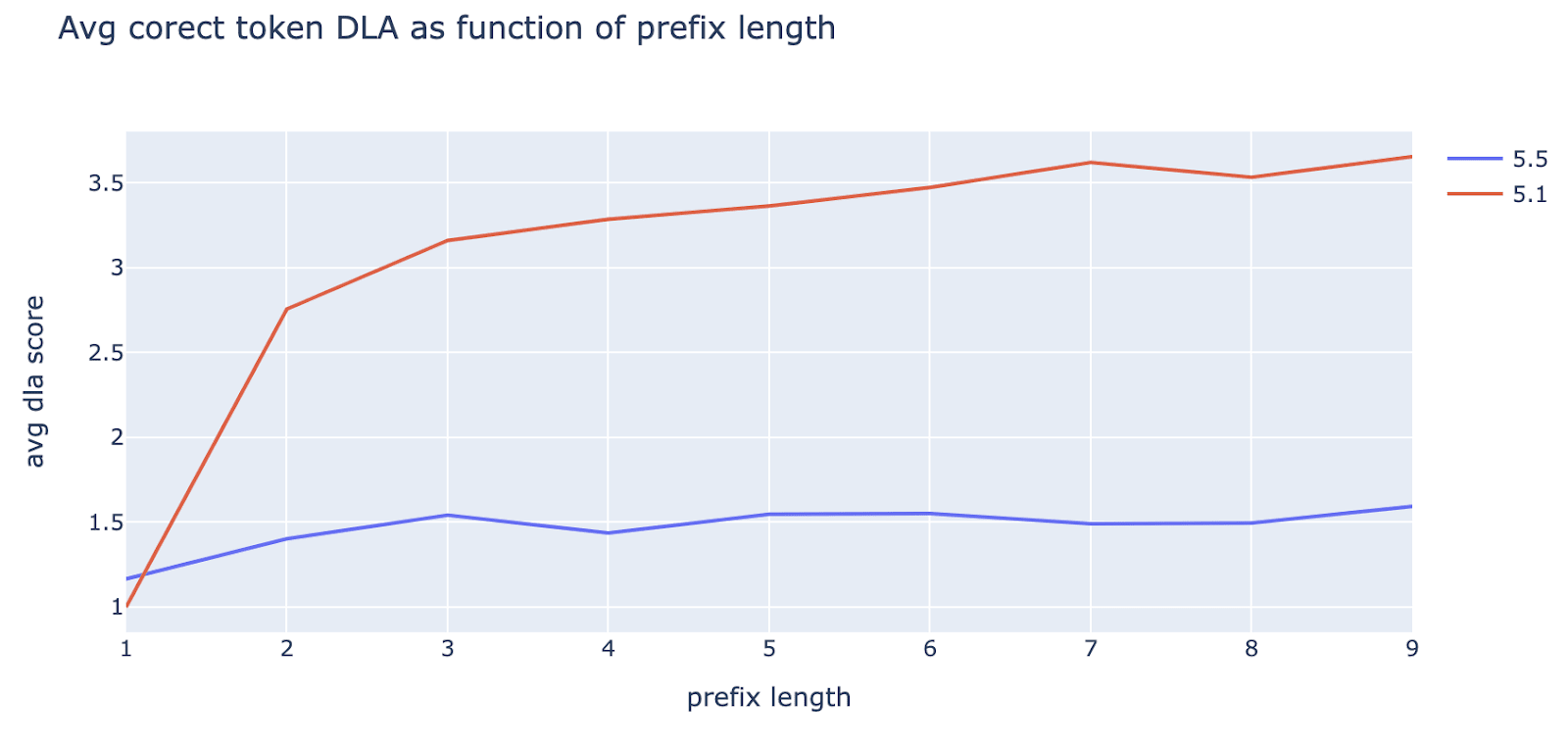
We also check each head’s average direct logit attribution (DLA) to the correct next token as a function of prefix length. We again see that 5.1’s DLA skyrockets as we enter the long prefix regime, while 5.5’s DLA remains relatively constant:
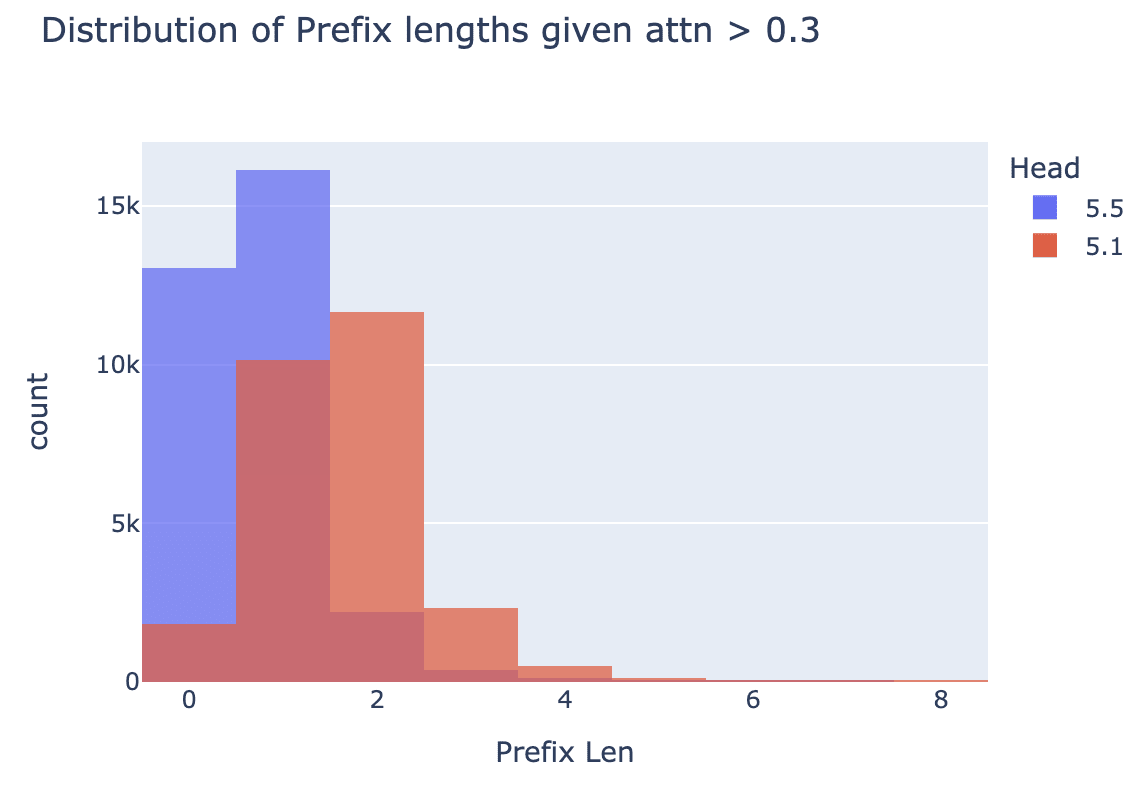
We now check that these results hold on a random sample of the training distribution. We first filter for examples where the heads are attending non-trivially to some token[3] (i.e. not just attending to BOS), and check how often these are examples of n-prefix induction. We find that 5.1 will mostly attend to tokens in long prefix induction, while 5.1 is mostly doing normal 1-prefix induction.
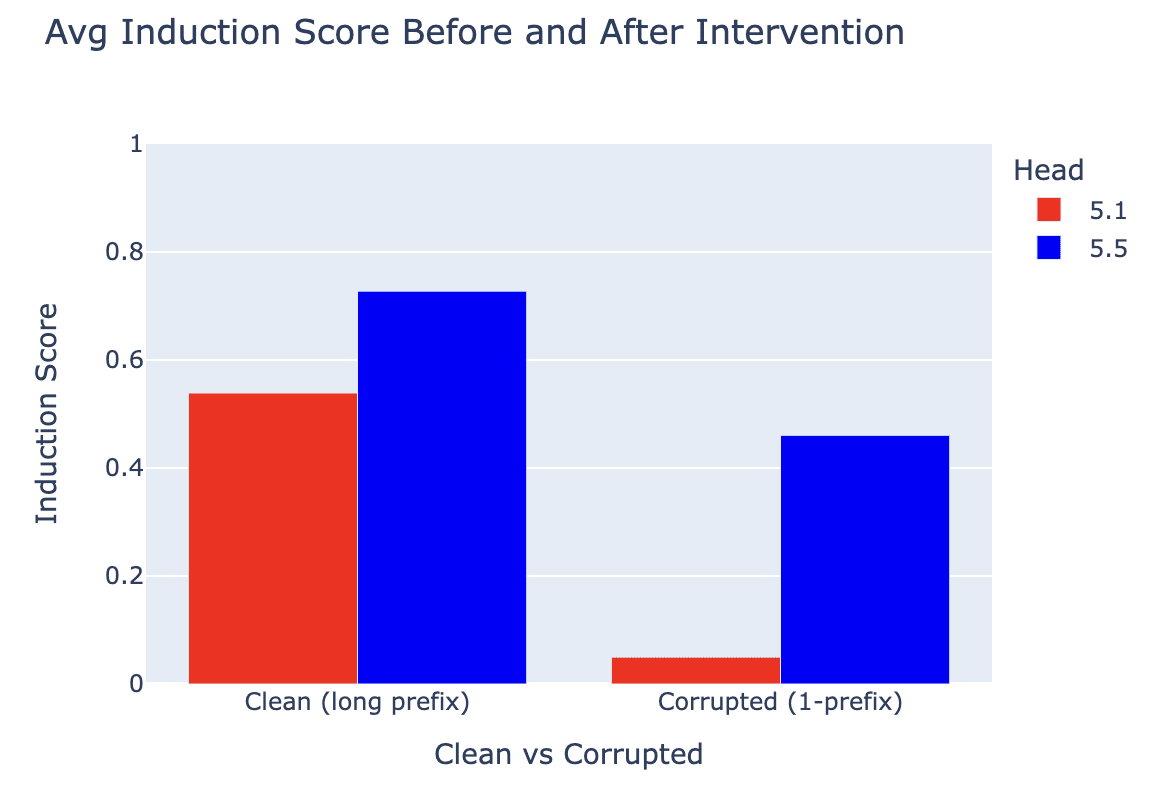
We intervene on the long induction examples from the training distribution, corrupting them to only be one prefix, and show that 5.1’s average induction score plummets from ~0.55 to ~0.05, while 5.1 still maintains an induction score of ~0.45.
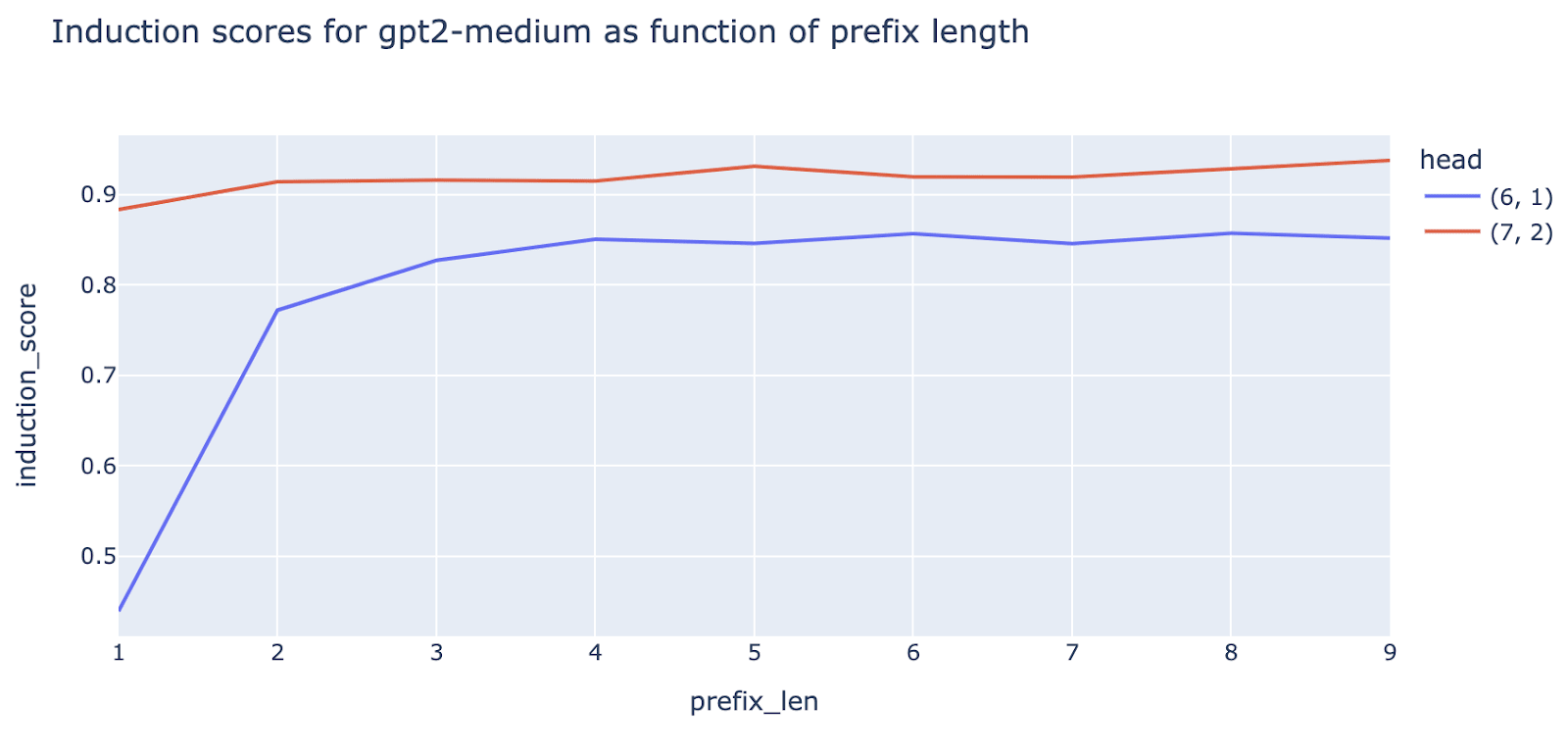
Finally, we see hints of universality: checking average induction scores on our synthetic induction dataset for a larger model, GPT-2 Medium, reveals signs of both “long prefix” and “standard” induction heads.
Limitations
- We only looked at the top 10 SAE features per head, sorted by an imperfect proxy. Ten is a small number, and sorting may cause interpretability illusions where the head has multiple roles but one is more salient than the others. We expect that if the head has a single role this will be clear, but it may look like it has a single role even if it is polysemantic. Thus negative results falsify the monosemanticity hypothesis but positive results are only weak evidence for monosemanticity.
- We didn’t spend much time per head and fairly shallowly looked at dataset examples per head which is also an imperfect method for determining the meaning of a feature and could lead to both false positives and false negatives.
- We don’t totally understand what a whole attention layer does. We are deliberately looking at SAE features that mostly rely on only one attention head. This misses additional behavior that relies on clever use of multiple heads (e.g. attention head superposition)
- Interestingly, we note that some heads involved in IOI did not show representative features, but this is plausibly due to the IOI roles not being their primary tasks.
Appendix: Attention Heads Feature Map
We recorded the groupings for all heads in this Google Sheet based on the corresponding attention head feature dashboards. We thank Callum McDougall for providing the visualization codebase on top of which these dashboards were constructed. The code for generating the dashboards is available by messaging any of the first two authors.
Citing this work
Feel free to use the citation from the first post [LW · GW], or this citation specifically for this current post:
@misc{gpt2_attention_saes_3,
author= {Robert Krzyzanowski and Connor Kissane and Arthur Conmy and Neel Nanda},
url = {https://www.alignmentforum.org/posts/xmegeW5mqiBsvoaim/we-inspected-every-head-in-gpt-2-small-using-saes-so-you-don},
year = {2024},
howpublished = {Alignment Forum},
title = {We Inspected Every Head in GPT-2 Small Using SAEs So You Don’t Have To}
}Author Contributions Statement
Connor and Rob were core contributors on this project. Rob performed high-level grouping analysis of every attention head in GPT-2 Small and some corresponding shallow dives. Connor performed the long prefix induction deep dive and the H10.2 polysemanticity experiment. Arthur and Neel gave guidance and feedback throughout the project. The original project idea was suggested by Neel.
We would like to thank Georg Lange and Joseph Bloom for extremely helpful criticism about our claims on polysemanticity in an earlier draft of this work.
- ^
For other heads, we also used proxies to detect examples in OpenWebText with the hypothesized head behaviors, but had messier results. Our initial hypotheses were often too broad (eg "succession" vs "succession for integers"), which led to false negatives. Synthetic data was helpful to filter these.
- ^
Note DFA is attention weighted, so you can think of it as similar to an attention pattern
- ^
We show a threshold of 0.3. The results generally hold for a range of thresholds.
0 comments
Comments sorted by top scores.