Attention SAEs Scale to GPT-2 Small
post by Connor Kissane (ckkissane), robertzk (Technoguyrob), Arthur Conmy (arthur-conmy), Neel Nanda (neel-nanda-1) · 2024-02-03T06:50:22.583Z · LW · GW · 4 commentsContents
Executive Summary Introduction Feature Families Induction Features Duplicate Token Features Successor Features Name Mover Features Suppression Features Finding Surprising Behaviors: n-gram Features Limitations Future Work Citing this work Author Contributions Statement None 4 comments
This is an interim report that we are currently building on. We hope this update + open sourcing our SAEs will be useful to related research occurring in parallel. Produced as part of the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort
Executive Summary
- In a previous post, we showed that sparse autoencoders (SAEs) work on the attention layer outputs [LW · GW] of a two layer transformer. We scale our attention SAEs to GPT-2 Small, and continue to find sparse interpretable features in every layer. This makes us optimistic about our ongoing efforts scaling further, especially since we didn’t have to do much iterating
- We open source our SAEs. Load them from Hugging Face or this colab notebook
- The SAEs seem good, often recovering more than 80% of the loss relative to zero ablation, and are sparse with less than 20 features firing on average. The majority of the live features are interpretable
- We continue to find the same three feature families that we found in the two layer model [LW · GW]: induction features [LW · GW], local context features [LW · GW], and high level context features [LW · GW]. This suggests that some of our lessons interpreting features in smaller models may generalize
- We also find new, interesting feature families that we didn’t find in the two layer model, providing hints about fundamentally different capabilities in GPT-2 Small
- See our feature interface to browse the first 30 features for each layer
- New: use Neuronpedia to visualize these SAEs
Introduction
In Sparse Autoencoders Work on Attention Layer Outputs [LW · GW] we showed that we can apply SAEs to extract sparse interpretable features from the last attention layer of a two layer transformer. We have since applied the same technique to a 12-layer model, GPT-2 Small, and continue to find sparse, interpretable features in every layer. Our SAEs often recover more than 80% of the loss[1], and are sparse with less than 20 features firing on average. We perform shallow investigations of the first 30 features from each layer, and we find that the majority (often 80%+) of non-dead SAEs features are interpretable. See the features with our interactive visualizations for each layer.
We open source our SAEs in hope that they will be useful to other researchers currently working on dictionary learning. We are particularly excited about using these SAEs to better understand attention circuits at the feature level. See the SAEs on Hugging Face or load them using this colab notebook. Below we provide the key metrics for each SAE:
| L0 norm | loss recovered | dead features | % alive features interpretable | |
| L0 | 3 | 99% | 13% | 97% |
| L1 | 20 | 78% | 49% | 87% |
| L2 | 16 | 90% | 20% | 95% |
| L3 | 15 | 84% | 8% | 75% |
| L4 | 15 | 88% | 5% | 100% |
| L5 | 20 | 85% | 40% | 82% |
| L6 | 19 | 82% | 28% | 75% |
| L7 | 19 | 83% | 58% | 70% |
| L8 | 20 | 76% | 37% | 64% |
| L9 | 21 | 83% | 48% | 85% |
| L10 | 16 | 85% | 41% | 81% |
| L11 | 8 | 89% | 84% | 66% |
It’s worth noting that we didn’t do much differently to train these,[2] leaving us optimistic about the tractability of scaling attention SAEs to even bigger models.
Excitingly, we also continue to identify feature families. We find features from all three of the families that we identified in the two layer model: induction features [LW · GW], local context features, and high level context features. This provides us hope that some of our lessons from interpreting features in smaller models will continue to generalize.
We also find new, interesting feature families in GPT-2 Small, suggesting that attention SAEs can provide valuable hints about new[3] capabilities that larger models have learned. Some new features include:
- Successor features [LW · GW], which activate when predicting the next item in a sequence such as “15, 16” -> “17” (which are partly coming from Successor Heads in the model), and boost the logits of the next item.
- Name mover features [LW · GW], which predict a name in the context, such as in the IOI task
- Duplicate token features [LW · GW], which activate on the second instance of a token (heads discussed in this section of A Mathematical Framework for Transformer Circuits”)
- Suppression features [LW · GW], which suppress the prediction of an earlier token in the context (which explain Copy Suppression)
- n-gram features [LW · GW], which predict a word in a common n-gram, like "two and a" -> "half", a surprising use of attention in a real model
We note that these feature families corroborate most known attention mechanisms found in GPT-2 Small in the literature.[4] The fact that the SAE lens organically agrees with other techniques gives us confidence that we are headed in the right direction.
Looking forward, we are most excited about leveraging our attention SAEs for circuit analysis at the feature level, and using them to develop a more detailed understanding of attention heads.
Feature Families
We continue to find the existence of feature families in GPT-2 Small. We find familiar families from the two layer model, like induction, as well as new, interesting feature families that seem new to GPT-2 Small. We are excited about both.
The familiar features show us that our efforts interpreting smaller models are not in vain, as at least some of the features may generalize. On the other hand, the new features suggest that we can use our SAEs to gain insight into fundamentally new and more interesting capabilities as we scale up to larger models.
We choose to highlight the most interesting features that show up in the middle-to-late layers. For a more comprehensive view of what each layer learns, see the interactive visualizations. While we don’t rigorously study these features in detail, we showcase signs of life using techniques like max activating dataset examples, direct feature attribution, and weight based logit analysis.
Induction Features
We continue to find many induction features in the middle-to-late layers of GPT2 small. Just as we found in the two layer model, these seem to be of the form “X is next by induction”, where X is some token in the vocabulary. Specifically, they activate on the second token in prompts of the form “<token> X … <token>”.
To see what past information is being used to compute these features, we leverage our “direct feature attribution” (aka DFA) technique [LW · GW] by decomposing the feature activations into a linear combination of the contributions from the value vectors at each source position. We add this to our feature interface, highlighting the position with the top DFA in blue. We observe that the attention layer is moving the previous instance of ‘X’ following the first <token> to compute this feature. Here is one example of a “‘-’ is next by induction” feature from layer 5:

These features also have an interpretable causal effect, clearly boosting the logits of X (in this case ‘-’).

We also find that the decoder weights of the SAE mostly attribute these features to a subset of the induction heads of GPT-2 Small. In this case, L5H5.[5]
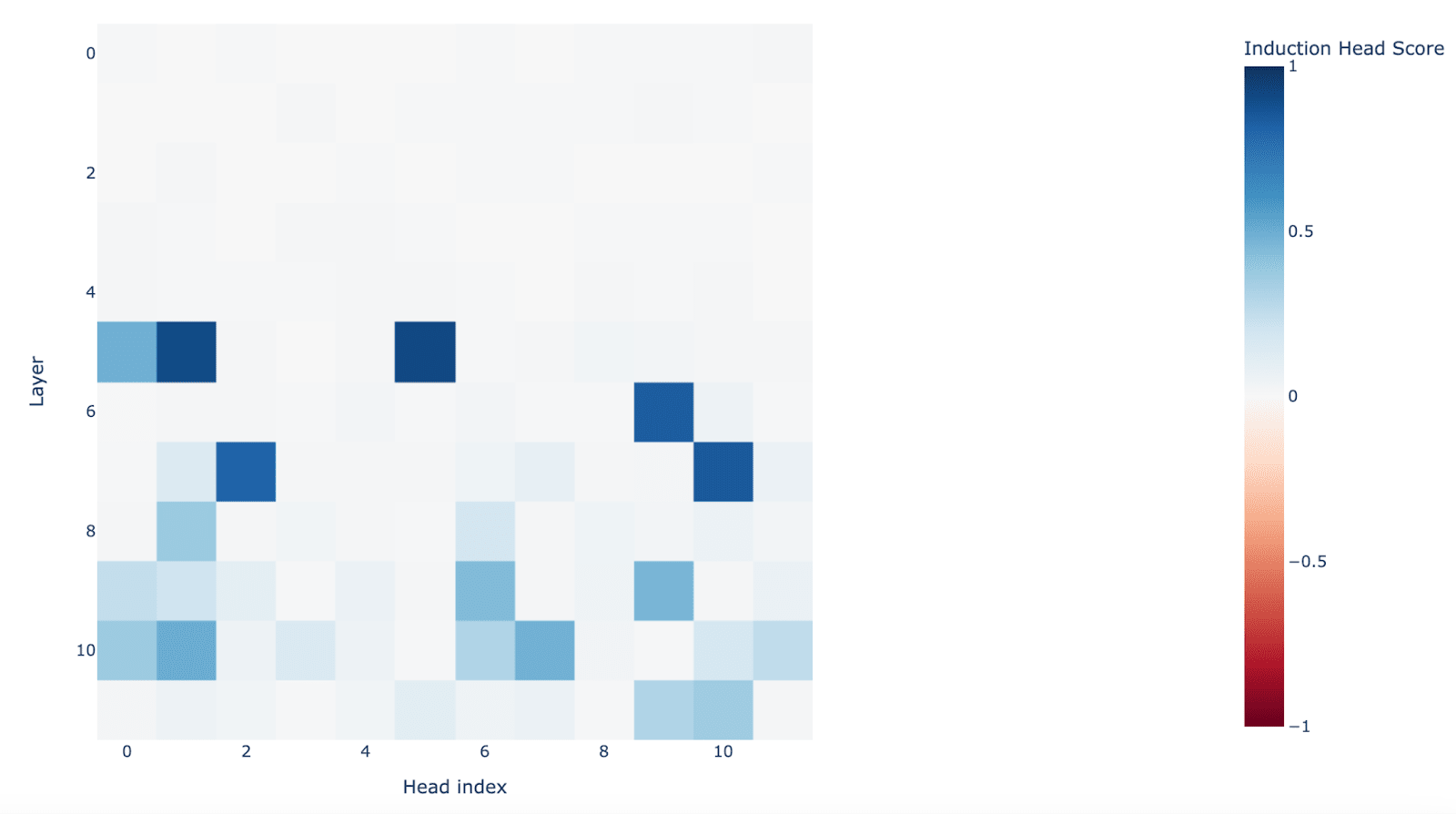
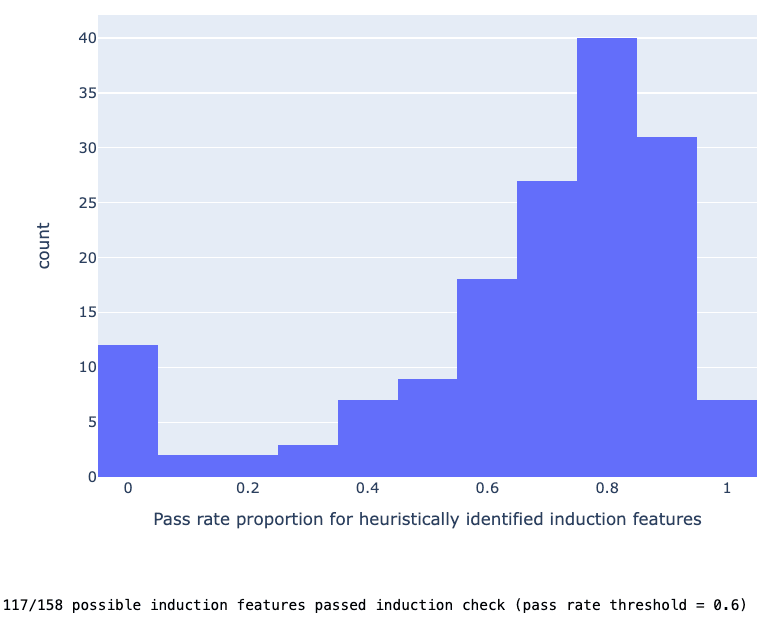
We attempted to heuristically identify induction related features using a similar heuristic to the one applied in our previous post [LW · GW] on a 2L model. Consider layer 6 which has one induction head L6H9. As the equivalent of the Induction Selection Heuristic, we then identified features in Layer 6 which had at least 50% weight based attribution to L6H9. We applied the same Induction Behavior Heuristic as in the previous post (namely, at least 60% induction pass rate on a batch of 200 examples) to heuristically identify 117 of 158 possible induction features, showing the technique generalizes to GPT-2-Small.
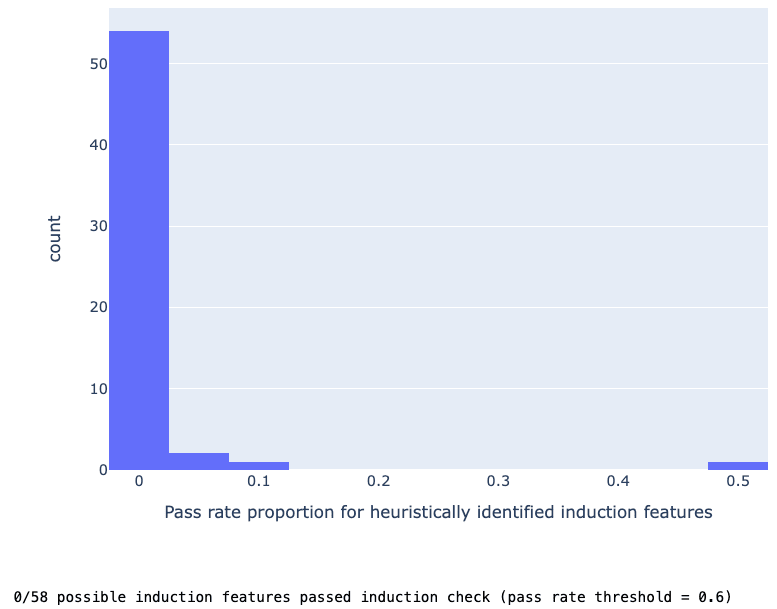
As a negative sanity check, we randomly chose features that passed an inversion of the Induction Selection Heuristic (namely less than 20% attribution to L6H9) and found that none of the features passed the Induction Behavior Heuristic.
Duplicate Token Features
We now highlight new feature families that we did not observe during our analysis of the two layer model. In Layer 3, we find many features which activate on repeated tokens. However, unlike induction, these have high direct feature attribution to the previous instance of that token (rather than the token following the previous instance).

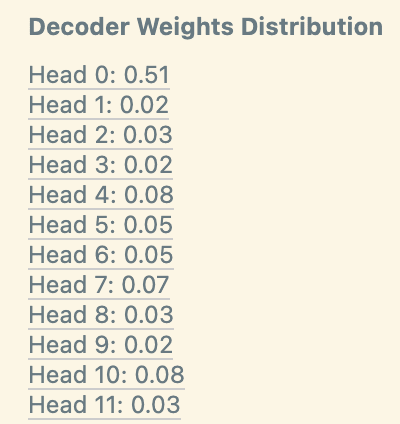
We also notice that the norms of the decoder weights corresponding to L3H0, identified as a duplicate token head by Wang et al, stand out. This shows that, similar to the induction feature, we can use weight based attribution to heads with previously known mechanisms to suggest the existence of certain feature families and vice versa.
Successor Features
In our Layer 9 SAE, we find features that activate in sequences of numbers, dates, letters, etc. The DFA by source position also suggests that the attention layer is looking back at the previous item(s) to compute this feature.

The top logits of these features are also interpretable, suggesting that these features boost the next item in the sequence. Finally, the decoder weight norms also suggest that they heavily rely on head 9.1, a successor head in GPT-2 Small.
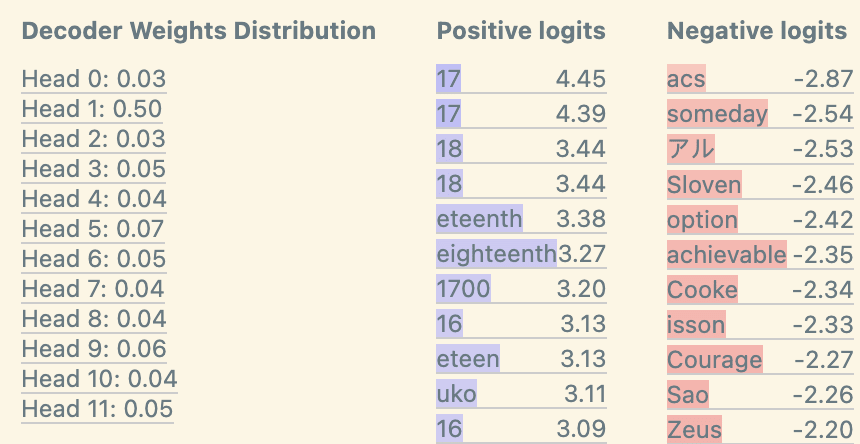
Name Mover Features
In the later layers, we also find features that seem to predict a name in the context. The defining characteristic of these features is a very high logit boost to the name. We also see very high DFA to the past instances of this name in the context. Once again, our decoder weights also suggest that heads 9.9 and 9.6 are the top contributors of the feature, which were both identified as name mover heads in the IOI paper.

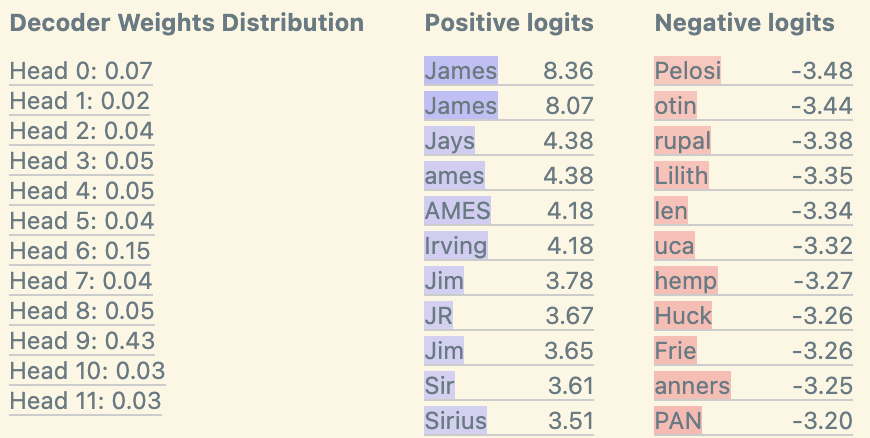
Interestingly, we find a relatively large number of name movers within our shallow investigations of the first 30 random features, suggesting that this might explain a surprisingly large fraction of what the late attention layers are doing.
Suppression Features
Finally, in layer 10 we find suppression features. These features show very low negative logits to a token in the context, suggesting that they actually seem to suppress these predictions. We use DFA to confirm that these features are being activated by previous instances of these tokens. Interestingly, our decoder weights also identify head 10.7 as the top contributing head, the same head identified to do copy suppression by McDougall et al.

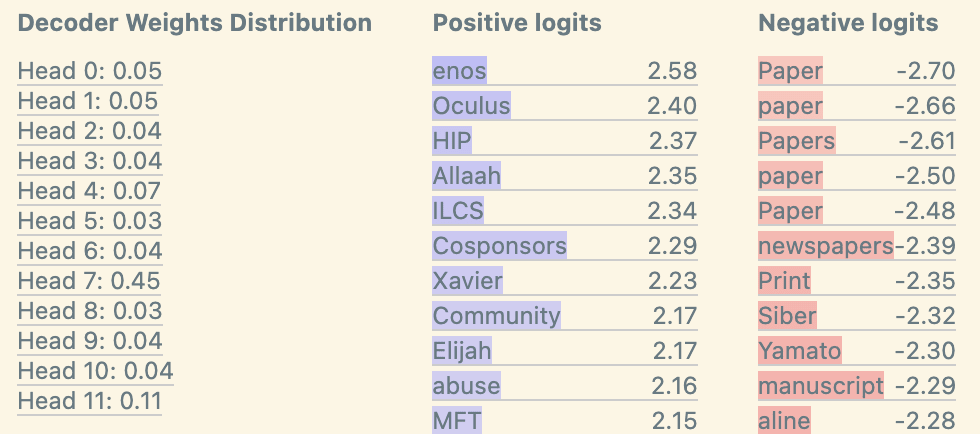
Finding Surprising Behaviors: n-gram Features
All of the features we have shown so far are related to previously studied behaviors, making them easier to spot and understand. We now show that we can also use our SAE to find new, surprising things attention layers have learned. This feature from Layer 9 seems to be completing a common n-gram, predicting the “half” in phrases like “<number> and a half”.

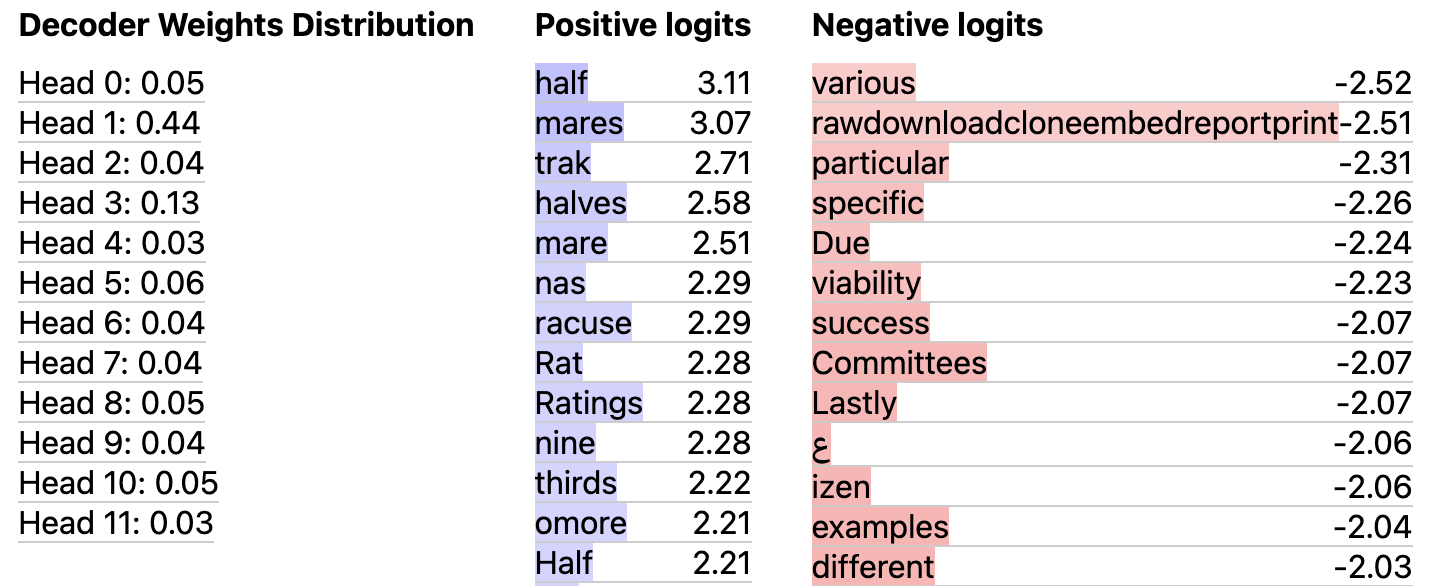
Though n-grams may seem like a simple capability, it's worth emphasizing why this is surprising. The intuitive way to implement n-grams would involve some kind of boolean AND (eg the current token is "and" AND the previous token is a number). This feels like a job for the MLP, not attention.
Limitations
- Our feature investigations are relatively shallow, so it’s possible that our initial hypotheses are missing subtleties.
- We already had priors on what kind of feature families would exist based on previous work, making them easier to spot. It’s likely that these are overrepresented in this post, and we are missing many additional behaviors that the attention layers have learned, like the n-gram feature.
Future Work
We feel pretty convinced that attention SAEs extract interpretable features, and allow for interesting exploration of what attention layers have learned. Now we focus on leveraging our SAEs to develop even deeper understanding of the attention layers. In particular we plan to apply our attention SAEs to better understand circuits and attention heads at the feature level.
For projects ideas that we likely won't prioritize (but would be excited to see explored) please see Joseph Bloom's post [LW · GW].
Citing this work
Feel free to use the citation from the first post [LW · GW], or this citation specifically for this current post:
@misc{gpt2_attention_saes,
author= {Connor Kissane and Robert Krzyzanowski and Arthur Conmy and Neel Nanda},
url = {https://www.alignmentforum.org/posts/FSTRedtjuHa4Gfdbr},
year = {2024},
howpublished = {Alignment Forum},
title = {Attention SAEs Scale to GPT-2 Small},
}Author Contributions Statement
Connor and Rob were core contributors on this project. Connor trained the SAEs, performed shallow investigations of random features, and identified the new feature families. He also added the DFA visualizations to the feature dashboards and created the web pages with feature visualizations for each layer. Rob performed automated feature family detections such as induction feature checks and also investigations of random features. Arthur and Neel gave guidance and feedback throughout the project. The original project idea was suggested by Neel.
- ^
Using a zero ablation baseline
- ^
Since the last post, we've implemented Anthropic's resampling scheme and a periodic learning rate warmup [LW · GW]
- ^
Note we haven't systematically checked all ~16,000 features in the two layer model to confirm this, but they never appeared in our investigations
- ^
With the exception of the n-gram feature, which hints at new mechanisms not yet attributed to attention heads within the existing literature (to our knowledge).
- ^
Studying how and why features are distributed across heads is an exciting area of future work
4 comments
Comments sorted by top scores.
comment by BiEchi (biechi) · 2024-03-09T03:56:34.318Z · LW(p) · GW(p)
@Connor Kissane [LW · GW] @Neel Nanda [LW · GW] Does SAE work on MLP blocks of GPT2-small as well? I find the recovery rate significantly low (40%) for MLP activations of larger models like GPT2-small.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2024-03-09T16:39:24.606Z · LW(p) · GW(p)
We've found slightly worse results for MLPs, but nowhere near 40%, I expect you're training your SAEs badly. What exact metric equals 40% here?
comment by jacob_drori (jacobcd52) · 2024-02-28T18:10:47.197Z · LW(p) · GW(p)
Paging hijohnnylin [LW · GW] -- it'd be awesome to have neuronpedia dashboards for these features. Between these, OpenAI's MLP features, and Joseph Bloom's resid_pre features, we'd have covered pretty much the whole model!