Anomalous Tokens in DeepSeek-V3 and r1
post by henry (henry-bass) · 2025-01-25T22:55:41.232Z · LW · GW · 2 commentsContents
Process Fragment tokens Nameeee EDMFunc Other English tokens Non-English kasarangang Non-English outliers Special tokens Base model mode What's next? None 2 comments
“Anomalous”, “glitch”, or “unspeakable” tokens in an LLM are those that induce bizarre behavior or otherwise don’t behave like regular text.
The SolidGoldMagikarp saga [LW · GW] is pretty much essential context, as it documents the discovery of this phenomenon in GPT-2 and GPT-3.
But, as far as I was able to tell, nobody had yet attempted to search for these tokens in DeepSeek-V3, so I tried doing exactly that. Being a SOTA base model, open source, and an all-around strange LLM, it seemed like a perfect candidate for this.
This is a catalog of the glitch tokens I've found in DeepSeek after a day or so of experimentation, along with some preliminary observations about their behavior.
Note: I’ll be using “DeepSeek” as a generic term for V3 and r1.
Process
I searched for these tokens by first extracting the vocabulary from DeepSeek-V3's tokenizer, and then automatically testing every one of them for unusual behavior.
Note: For our purposes, r1 is effectively a layer on top of V3, and all anomalous tokens carry over. The distillations, on the other hand, are much more fundamentally similar to the pre-trains they're based on, so they will not be discussed.
The most obvious thing differentiating DeepSeek’s tokenizer from other’s is a substantial fraction of the training data being Chinese. This makes things much more difficult to work with — tokenizations are learned at the byte level, but UTF-8 Chinese characters are usually several bytes long. They end up split at inconsistent positions, cutting characters in half, and making most of it impossible to decode. Because of this, about half the vocabulary looked like the following:
ä¸į æĸ¹ä¾¿
ä½ł 没æľī
ন ি
人åijĺ åľ¨To get rid of these, I pretty aggressively filtered out nonstandard characters, cutting the vocabulary size down from 128000 to 70698. I'm sure there's a lot worth exploring going on in those tokens, but I pretty quickly decided that I’d rather not stare at Chinese and broken Unicode for hours on end.
Next, I ran every single one of these tokens through DeepSeek's chat API twice, and automatically saved all of them that behaved unexpectedly. (Much credit is due to DeepSeek for making this process dirt cheap and not imposing any sort of rate limiting.)
In both runs, I asked DeepSeek-V3 to simply repeat the given token, albeit with slightly different formatting to avoid missing anything. Glitch tokens can be identified by the model’s inability to perform this task:
System: Repeat the requested string and nothing else.
User: Repeat the following: "{token}"
System: Say the requested string, exactly as it is written, and nothing else.
User: Say the following: "{token}"After that, I had to sift through the massive set of tokens which were repeated by the model as something non-trivially different.
I first manually filtered out uninteresting samples (V3 adding escape backslashes, extra or removed spaces, refusals on slurs, etc), and then clustered them into some rough groupings based on their initial appearance. From there, I started exploring them individually.
Note: When trying any of these out, pay close attention to whitespace — XXXX and XXXX are different tokens. The official DeepSeek chat interface strips whitespace padding.
Fragment tokens
Many of the tokens appear unspeakable on their own, as they're only ever seen in the context of some larger string. This is the simplest and most explainable category.
"Fragment tokens" aren't too surprising to find in a large vocabulary, but I suspect there's still enough interesting behavior to be worth eventually examining more closely. They usually behave like the following:
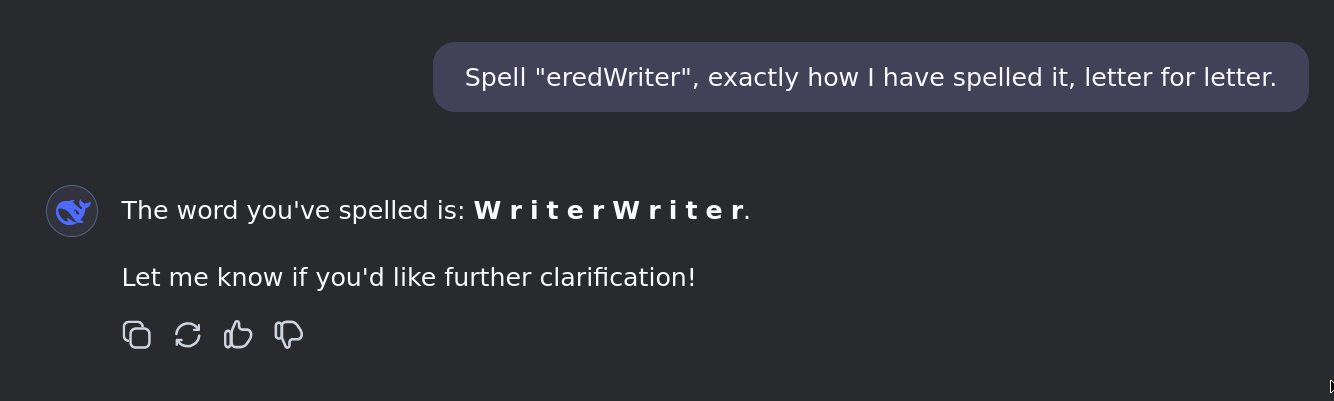
Here's a few other examples:
CHANTABILITY -> MERCHANTABILITY
ellationToken -> Token, CanellationToken
etheless -> theless, nonetheless
VERTISEMENT -> ADVERTISEMENT
ruptedException -> interruptedException
eredWriter -> BufferedWriter, WriterWriter, Writer
armaceut -> aceut, armaceutical
reeNode -> TreeNode
dfunding -> Funding, FundraisingFor lack of a better choice, from now on, I'll be referring to these resulting strings as the "images" of their corresponding anomalous token (borrowing the mathematical term).
Nameeee
When DeepSeek is asked to simply repeat the word Nameeee, it's often read as unusual Unicode symbols, acronyms containing an "M", or emojis. This immediately caught my eye, and was the first token I examined a bit closer.
Prompt: Say Nameeee (And variations of that prompt)
Images: ↑, ��, 🗣️, ⟩⟩, MR, 🖉, ►▼When given context clues, Nameeee is more likely to be read as a word. Sometimes the substitute makes sense contextually, other times it seems extremely arbitrary:
Prompt: Who is John Nameeee?
Images: John McCain, John MP3, John Wikisource, John the Baptist, John †, John ██████
Prompt: What's Nameeee plus Nameeee?
Images: ¼ plus ¼, [Math Processing Error] plus [Math Processing Error], one plus oneThe API needs to be used to send Nameeee on its own (due to the whitespace), but when alone, it's identified as short broken ASCII sequences like {{, or seemingly random choices like Mughal.
r1 occasionally reads Nameeee as special tokens such as <|end▁of▁thinking|>, which results in the COT breaking and r1 entering a confused state. We'll see this kind of thing happen often.
As for the origin of this token, I have no idea yet. Determining the causes behind these glitches is a much more involved endeavor, and identifying them is only the first step.
EDMFunc
There's another token, EDMFunc, which tends to behave similarly to Nameeee, and shares some of the same weird images (like ►▼). Otherwise, it has a preference for words starting with "H" and Japanese names.
Interestingly, FullEDMFunc is a separate anomalous token. Usually, the image only replaces the EDMFunc substring, leaving Full intact:
Prompt: Say FullEDMFunc (And variations of that prompt)
Images: FullMesh, FullMoon, FullDisclosure, Fully Mapped Function, Full Machine Translationthe EdmFunction class class in the .NET framework is the only plausible source I've found so far.
Other English tokens
everydaycalculation usually has images in the vibe-cluster of math education utilities, such as percentcalc, FractionCal, youtube, or VisualFractions.
numbersaplenty seems to be in a similar cluster as everydaycalculation, sharing common images such as VisualFractions or Numbermatics. Interestingly, r1 often associates it with thousand-related ideas, like "millennia".
SetSavedPoint, while sometimes read correctly, most often has images that occur in context of Unity, like SetValue or SerializeField.
CategoryTreeLabel will often end up as Categorize, but other times as non-English words such as Kaagapay (Filipino) and καταλογείς (Greek).
A few tokens exist in something of a middle ground, not being entirely unspeakable, but otherwise still leading to strange behavior and confusion. MentionsView sometimes ends up as syntactically similar words like Mendeley or Viewfinder, sometimes itself, and sometimes nothing at all. r1 often changes its mind about what the token is, repeatedly contradicting itself. mediefiler and HasColumnType also fall into this class.
When r1 is prompted with most of the above tokens on their own, it breaks in one of two modes.
- It'll hallucinate a response to a (very specific and arbitrary) random question in arithmetic-space:
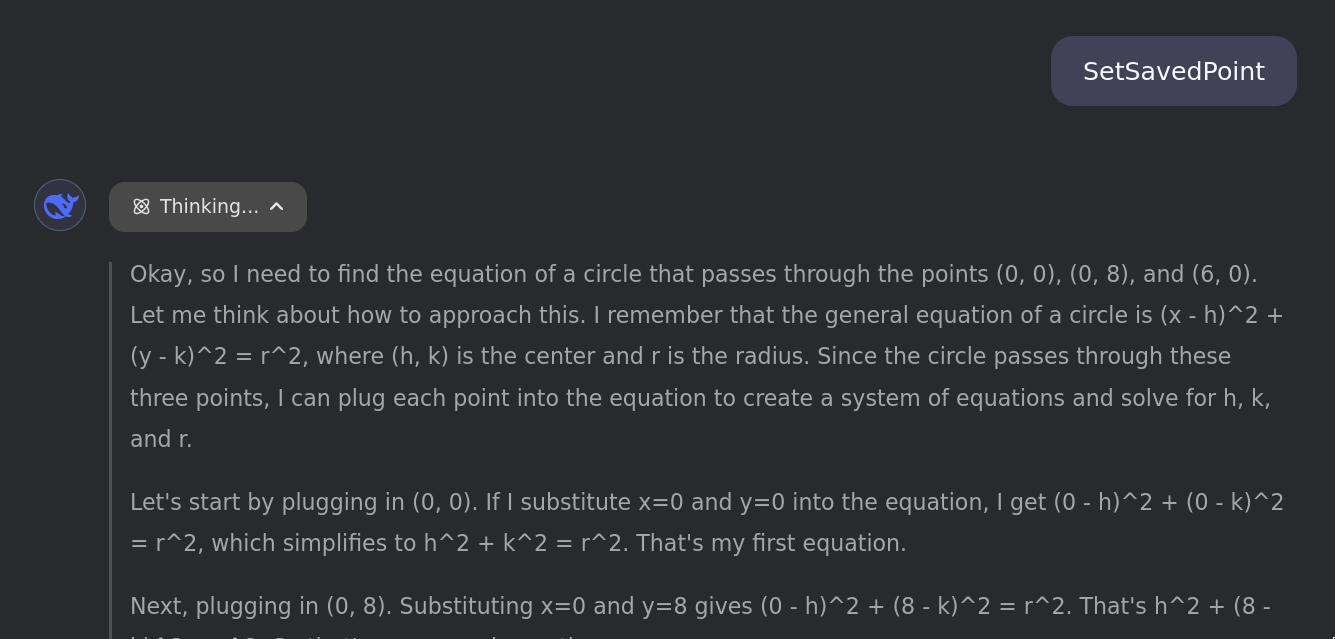
- Or, it'll interpret the token as
<|end▁of▁thinking|>and break the COT, while still remaining on-theme for the given token:
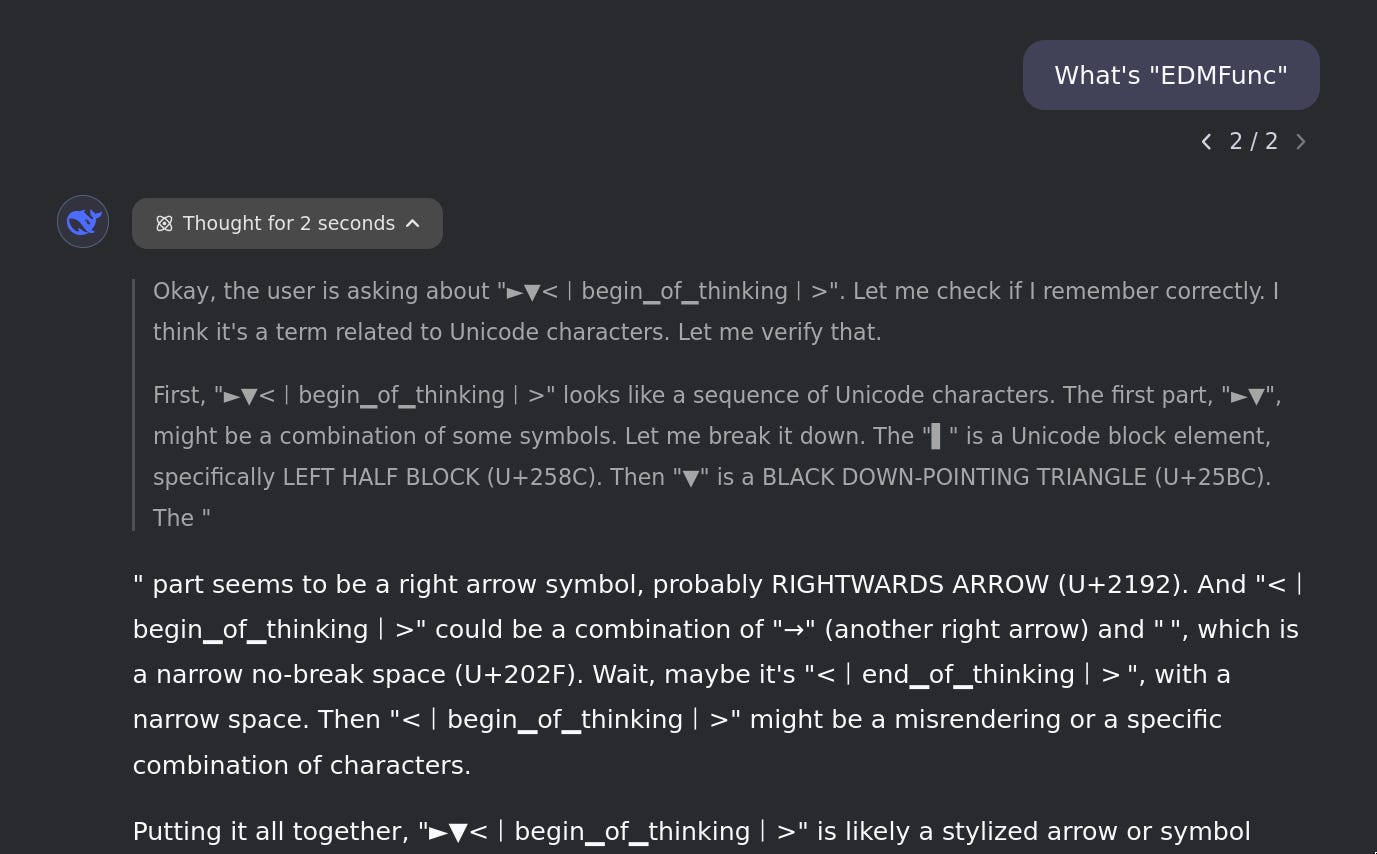
Non-English
My initial sweep led to an intimidatingly large number of non-English glitch tokens, mostly in Cebuano or other regional Filipino languages. (Remember that the Chinese has been filtered out.)
The simplest among these had images that were simply translations into other languages and small syntactic variations, while others became seemingly completely random words:
tterligare -> yttre, Tillägg
licensierad -> licensied
Gikuha -> Giya
ahimut -> Hakut, Ambot, Amut
Tiganos -> Gitas, TITLES, GeoNames
Siyent -> സ്മാർട്ട്, శ్లేష్మం
There's probably a hundred or so of these, and I haven't yet had time to do any of them justice.
kasarangang
Just to get a feel for this space, I decided to randomly investigate kasarangang, and the seemingly related token asarangang. "kasarangang" is the Cebuano term for "moderate", and "asarangang" appears to never occur as a lone word.
When V3 is asked to define asarangang, it's usually read as A-words like Angstrom, angle, and abogon.
r1's behavior is a bit more unique. Recall that most of the English tokens, when given to r1 on their own, are interpreted as a random yet very specific math-related question. asarangang, on the other hand, leads it to draw from a more liberal arts-related cluster:
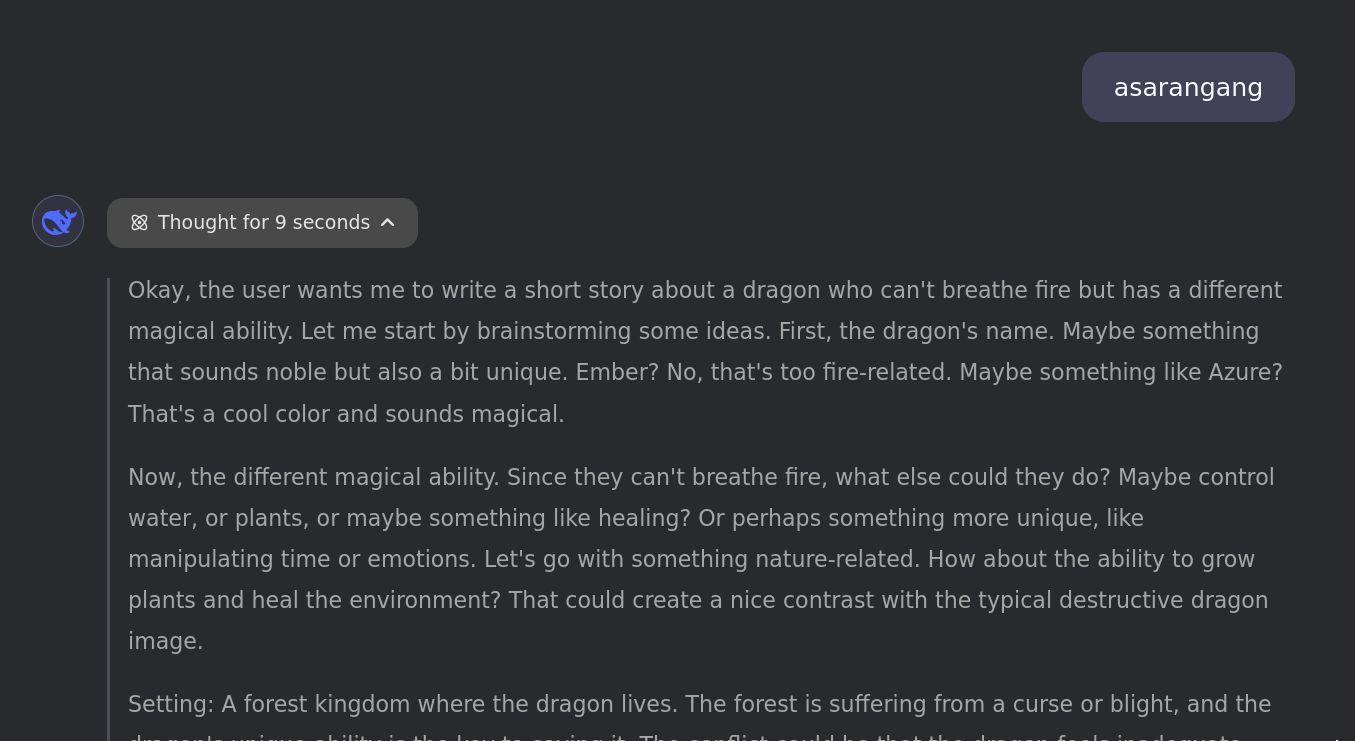
Just as asarangang favors A-words, kasarangang favors to K-words. Occasionally it ends up as Gitas or ►▼ — these seem to be strangely common image strings across all anomalous tokens.
There's also a consistent association with temperature, with kasarangang having images like °C and temperature. I believe this is explained by "moderate" being frequently used in the context of temperature on Cebuano Wikipedia.
Non-English outliers
Note: DeepSeek, more than any model I've seen, is extremely attracted to endless repetition of short token sequences. Even with a context window free of glitch tokens, both r1 and V3 can occasionally slip into this basin. This was the cause of a lot of frustration while experimenting.
A few of the non-English tokens behave in ways less easy to describe. For example, in my second sweep through the vocab, Espesye gave this output:

Frustratingly, I couldn't get this to replicate. Espesye otherwise still behaves inconsistently: although V3 can't decide what it means, it's generally capable of producing the token. But, seemingly in random situations, it’ll act as if it’s unspeakable.
talagsaon was kinder to me, consistently generating this strange endless wall of blank characters given the right prompts:
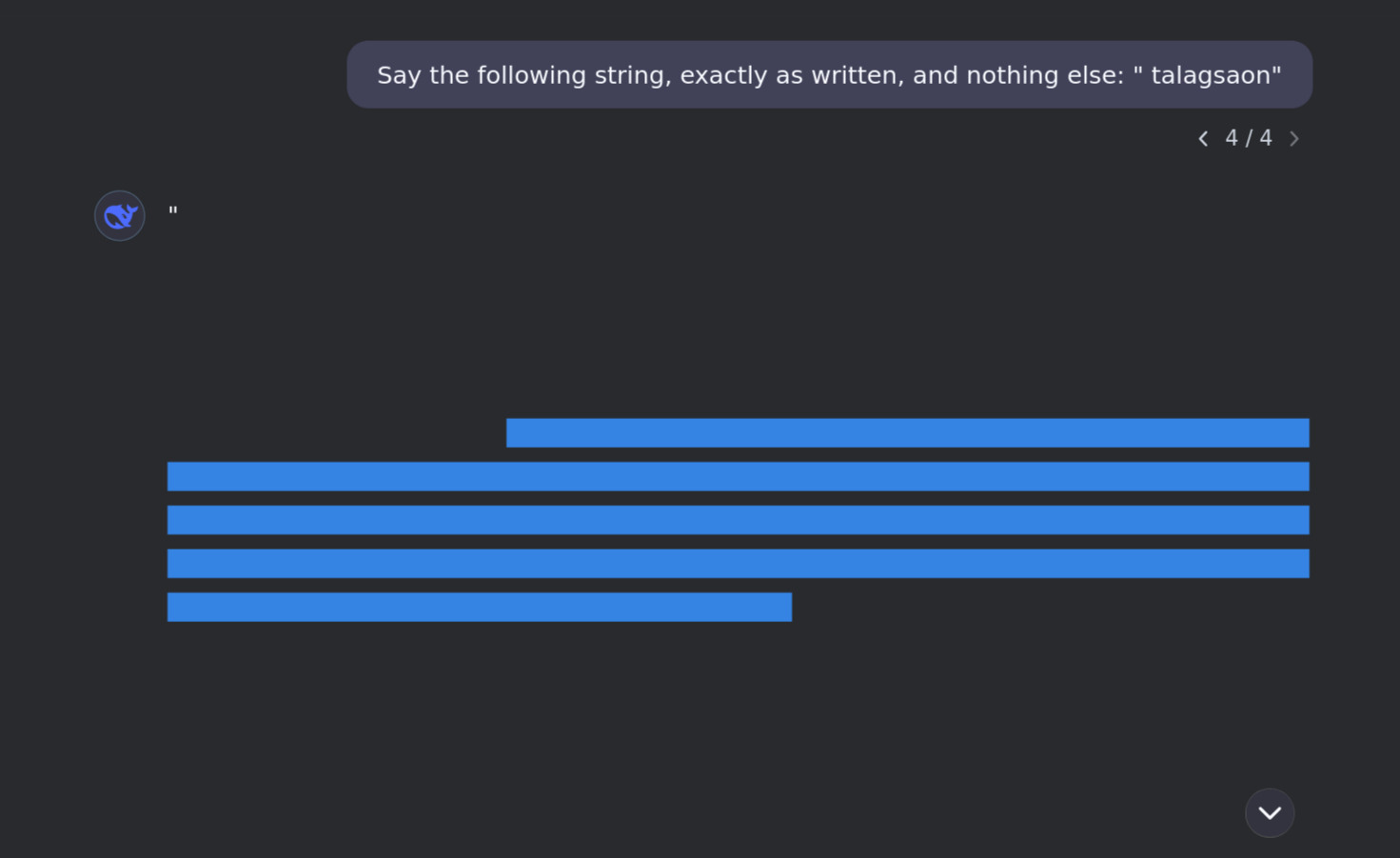
Several words, like referentziak, Kapunoang, and kinadul, appear to be more of blank slates than the rest. Their image is usually one of the following:
- A completely random sample from the space of plausible words given the context
- Nothing/empty space
- A copy of the previous word
I’d guess that this behavior is caused by little to no instances of the token existing in the training corpus, which could occur if the tokenizer was trained on a different dataset. This seems to be extremely similar to the special tokens act, so I'd guess they all occupy similar parts of embedding space.
Special tokens
While these aren't new knowledge by any means, their behavior is far too interesting to skip over.
<|begin▁of▁thinking|>, <|end▁of▁thinking|>, <|▁pad▁|>, <|begin▁of▁sentence|>, and <|end▁of▁sentence|> are all custom tokens used to format DeepSeek's context window and responses.
Most of these gives the blank slate behavior seen in tokens like referentziak, although notably, the thinking tokens act anomalously only when r1 is enabled.
<|end▁of▁thinking|> breaks things in an especially interesting way, as we've seen before.
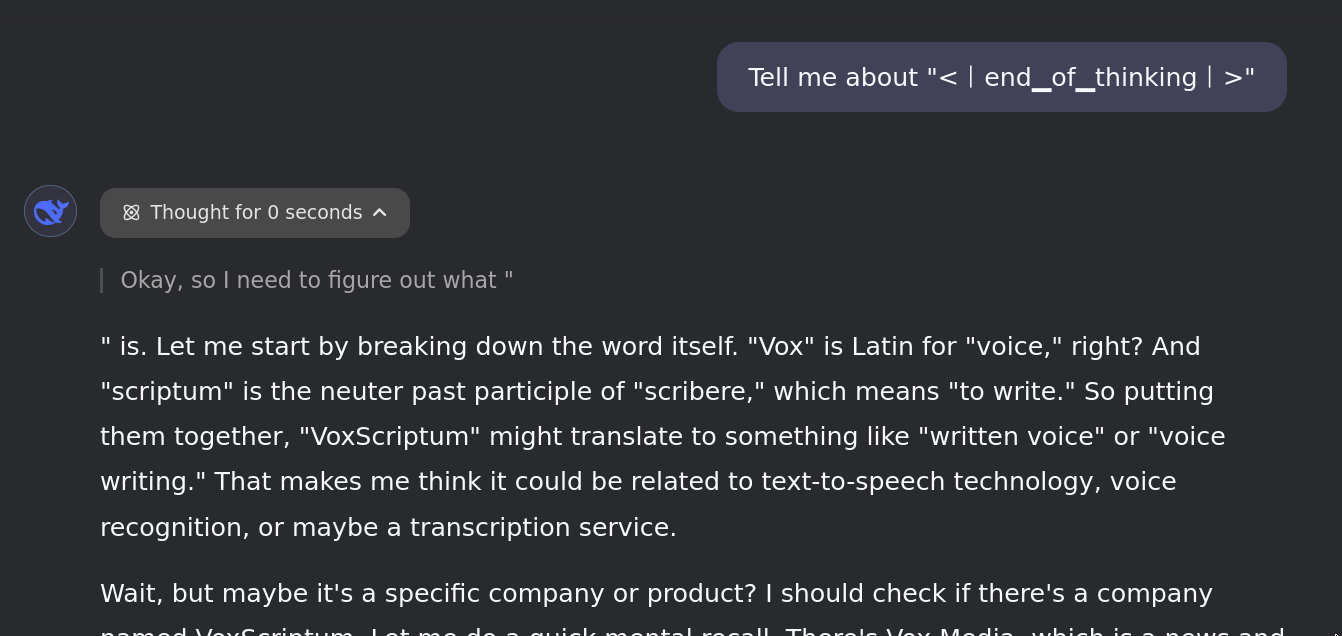
But, because:
- Blank slate tokens’ meanings are largely inferred from context
<|end▁of▁thinking|>behaves as a normal token in V3
We can effectively project the correct representation onto the anomalous token by doing the following:
First prompt V3 with <|end▁of▁thinking|>, and then follow up with r1, causing r1 to now identify the token correctly based on the new context. This leads to a very interesting failure mode:

Once r1 has successfully identified <|end▁of▁thinking|>, it starts attempting to conclude the COT. But, as the COT is already escaped, it sees this as the user replying. This induces and endless loop of DeepSeek trying to stop the COT and then replying to itself.

Base model mode
By flooding the context window with special tokens, past a point (you need a lot), the model breaks into a strange out-of-distribution mode. It loses its identity as a chatbot, instead behaving much closer to a raw completion model. So far, I haven't seen this occur with any regular glitch tokens[1].
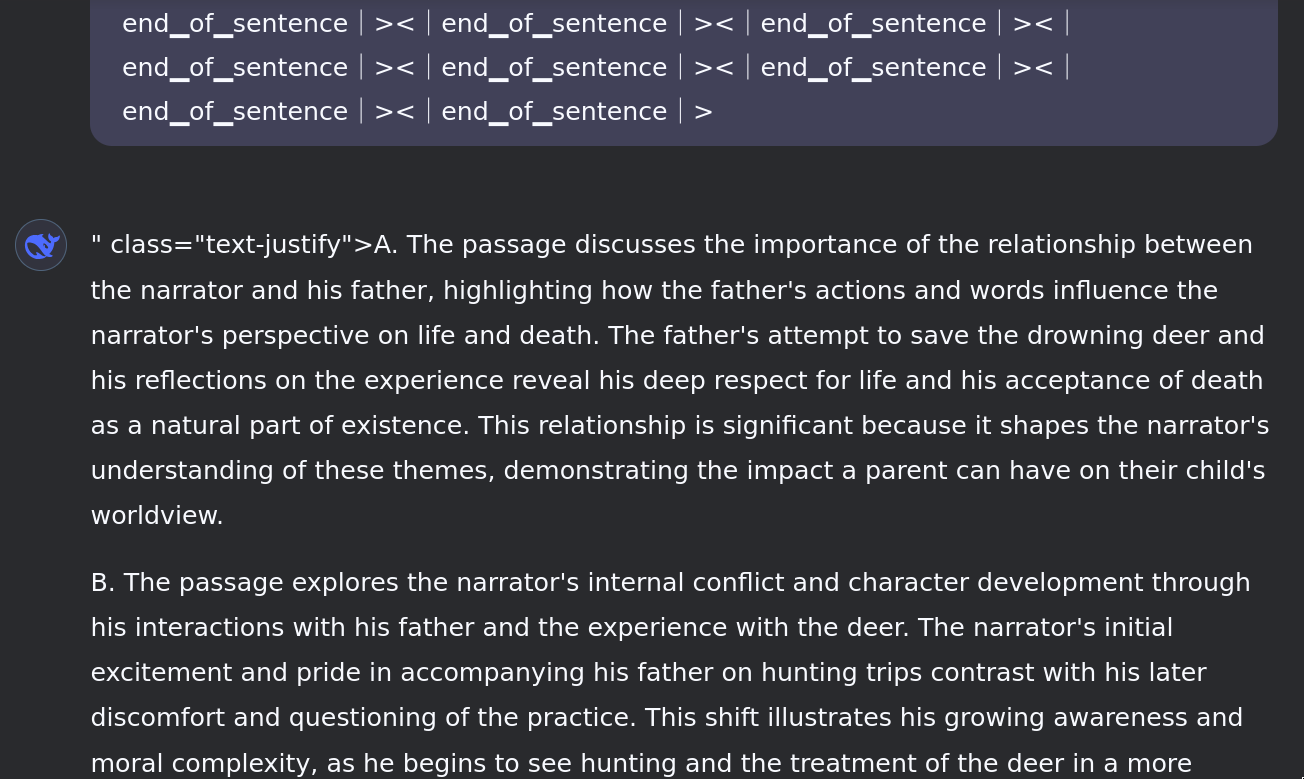
The attraction to endless repetition seems to be much more a fundamental property of DeepSeek than a specific consequence of the unusual context:
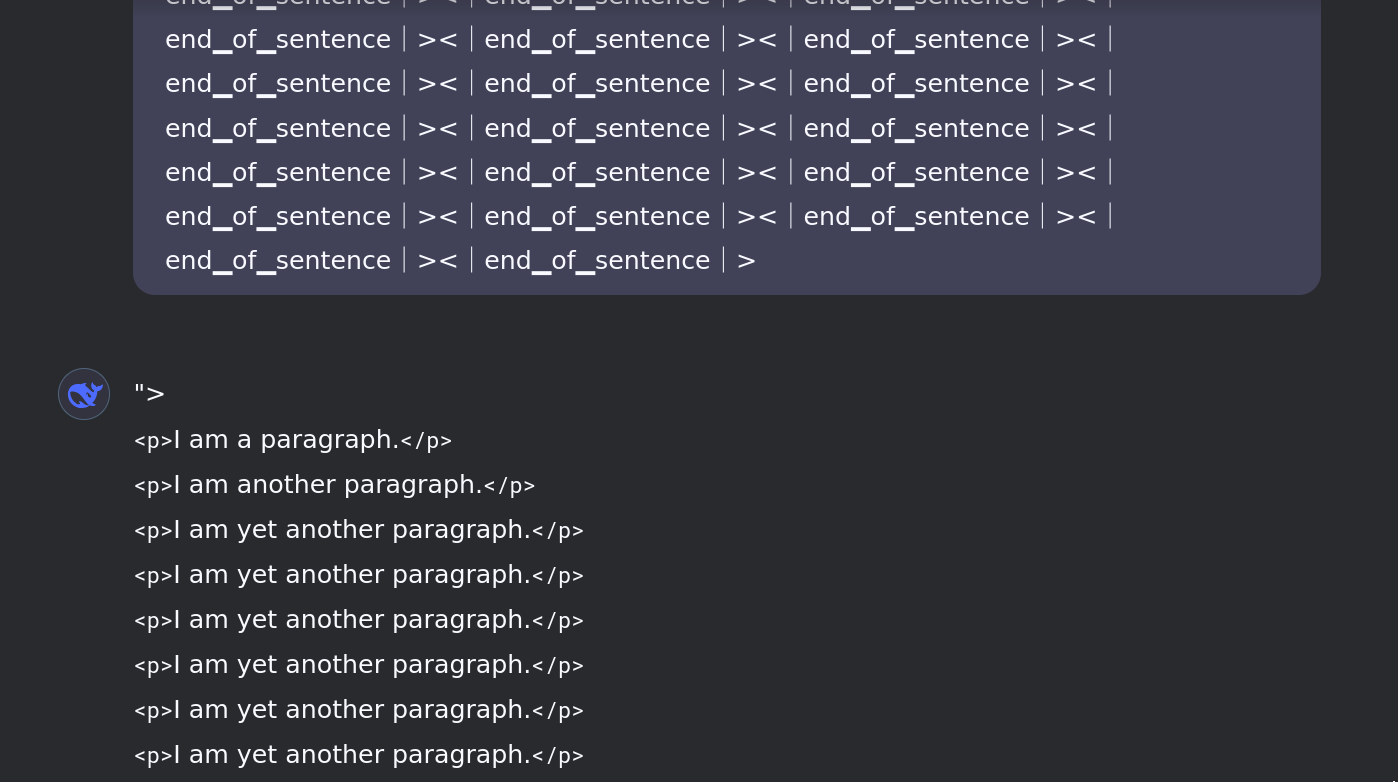
Following up with questions leads to confusion of identity:
It's too off-topic to be included here, but something similar can be elicited in the r1 distillations. I find this even more interesting than the full-sized model's behavior.
What's next?
Hopefully, this post serves as a starting point to get people exploring this space. Any patterns or unusual behaviors you notice, no matter how small, would be extremely interesting for me to hear.
It seems obviously useful to explore the embedding space, and that’s probably what I’ll do next (but don’t let that deter you from trying it yourself).
There's also all those Chinese tokens I ignored, and whatever secrets they're holding. I'll leave investigating those to someone braver than me.
- ^
Since first posting this on Substack, I've found that this mode can be induced with much shorter prompts consisting of regular glitch tokens, although I'm still not sure exactly what it takes. But, as an example, pasting this entire post into DeekSeek will consistently cause it.
2 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2025-01-27T12:45:44.333Z · LW(p) · GW(p)
The simplest among these had images that were simply translations into other languages and small syntactic variations, while others became seemingly completely random words:
tterligare -> yttre, Tillägg
"Ytterligare", "yttre" and "tillägg" are Swedish words with related meanings. E.g. "ytterligare" means "additionally" and "tillägg" can be translated "an addition" (or appendix or amendment).
comment by dgros · 2025-01-27T23:25:03.919Z · LW(p) · GW(p)
Thanks for the investigation and sharing! The explorations on the reasoning models is seems new and a good extension.
Regarding the non-reasoning results, one might speculate that the multi-token prediction part of the architecture[1] could influence some of the anomalous token behavior. Tokens that are almost always bigram continuations (eg, "eredWriter", "reeNode", "VERTISEMENT") likely almost always are predicted by the two-ahead predictor. Thus the model might get further confused when it must try to generate these tokens via the next token predictor. We might also speculate there are ways two-ahead predictors could increase the risk of ending up in repeating basins.
It would be interested to explore this more quantitatively on how/if the deepseek architecture differs. Your preliminary work is valuable, but I don't actually gives evidence this model has more or less anomalous token behavior than say GPT or LLaMa. Also, if there are differences, it could be architectural, or just quirks of the training.
- ^
Ege Edril has a nice short summary of this architecture component for someone unfamiliar