AI #69: Nice
post by Zvi · 2024-06-20T12:40:02.566Z · LW · GW · 9 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility Fun with Image Generation Deepfaketown and Botpocalypse Soon The Art of the Jailbreak Copyright Confrontation A Matter of the National Security Agency Get Involved Introducing In Other AI News Quiet Speculations AI Is Going to Be Huuuuuuuuuuge SB 1047 Updated Again The Quest for Sane Regulations The Week in Audio The ARC of Progress Put Your Thing In a Box What Will Ilya Do? Actual Rhetorical Innovation Rhetorical Innovation Aligning a Smarter Than Human Intelligence is Difficult People Are Worried About AI Killing Everyone Other People Are Not As Worried About AI Killing Everyone The Lighter Side None 9 comments
Nice job breaking it, hero, unfortunately. Ilya Sutskever, despite what I sincerely believe are the best of intentions, has decided to be the latest to do The Worst Possible Thing, founding a new AI company explicitly looking to build ASI (superintelligence). The twists are zero products with a ‘cracked’ small team, which I suppose is an improvement, and calling it Safe Superintelligence, which I do not suppose is an improvement.
How is he going to make it safe? His statements tell us nothing meaningful about that.
There were also changes to SB 1047. Most of them can be safely ignored. The big change is getting rid of the limited duty exception, because it seems I was one of about five people who understood it, and everyone kept thinking it was a requirement for companies instead of an opportunity. And the literal chamber of commerce fought hard to kill the opportunity. So now that opportunity is gone.
Donald Trump talked about AI. He has thoughts.
Finally, if it is broken, and perhaps the it is ‘your cybersecurity,’ how about fixing it? Thus, a former NSA director joins the board of OpenAI. A bunch of people are not happy about this development, and yes I can imagine why. There is a history, perhaps.
Remaining backlog update: I still owe updates on the OpenAI Model spec, Rand report and Seoul conference, and eventually The Vault. We’ll definitely get the model spec next week, probably on Monday, and hopefully more. Definitely making progress.
Table of Contents
Other AI posts this week: On DeepMind’s Frontier Safety Framework, OpenAI #8: The Right to Warn, and The Leopold Model: Analysis and Reactions.
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. DeepSeek could be for real.
- Language Models Don’t Offer Mundane Utility. Careful who you talk to about AI.
- Fun With Image Generation. His full story can finally be told.
- Deepfaketown and Botpocalypse Soon. Every system will get what it deserves.
- The Art of the Jailbreak. Automatic red teaming. Requires moderation.
- Copyright Confrontation. Perplexity might have some issues.
- A Matter of the National Security Agency. Paul Nakasone joins OpenAI board.
- Get Involved. GovAI is hiring. Your comments on SB 1047 could help.
- Introducing. Be the Golden Gate Bridge, or anything you want to be.
- In Other AI News. Is it time to resign?
- Quiet Speculations. The quest to be situationally aware shall continue.
- AI Is Going to Be Huuuuuuuuuuge. So sayeth The Donald.
- SB 1047 Updated Again. No more limited duty exemption. Democracy, ya know?
- The Quest for Sane Regulation. Pope speaks truth. Mistral CEO does not.
- The Week in Audio. A few new options.
- The ARC of Progress. Francois Chollet goes on Dwarkesh, offers $1mm prize.
- Put Your Thing In a Box. Do not open the box. I repeat. Do not open the box.
- What Will Ilya Do? Alas, create another company trying to create ASI.
- Actual Rhetorical Innovation. Better names might be helpful.
- Rhetorical Innovation. If at first you don’t succeed.
- Aligning a Smarter Than Human Intelligence is Difficult. How it breaks down.
- People Are Worried About AI Killing Everyone. But not maximally worried.
- Other People Are Not As Worried About AI Killing Everyone. Here they are.
- The Lighter Side. It cannot hurt to ask.
Language Models Offer Mundane Utility
Coding rankings dropped from the new BigCodeBench (blog) (leaderboard)
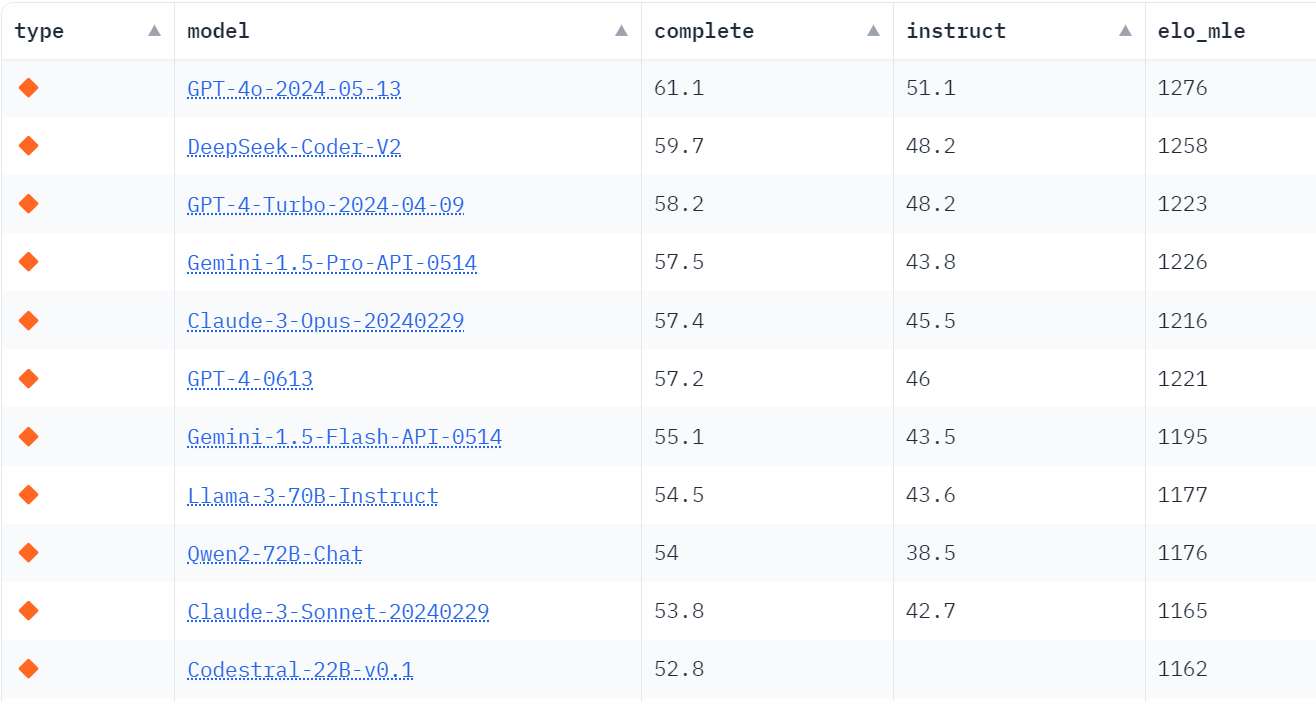
Three things jump out.
- GPT-4o is dominating by an amount that doesn’t match people’s reports of practical edge. I saw a claim that it is overtrained on vanilla Python, causing it to test better than it plays in practice. I don’t know.
- The gap from Gemini 1.5 Flash to Gemini 1.5 Pro and GPT-4-Turbo is very small. Gemini Flash is looking great here.
- DeepSeek-Coder-v2 is super impressive. The Elo tab gives a story where it does somewhat worse, but even there the performance is impressive. This is one of the best signs so far that China can do something competitive in the space, if this benchmark turns out to be good.
The obvious note is that DeepSeek-Coder-v2, which is 236B with 21B active experts, 128k context length, 338 programming languages, was released one day before the new rankings. Also here is a paper, reporting it does well on standard benchmarks but underperforms on instruction-following, which leads to poor performance on complex scenarios and tasks. I leave it to better coders to tell me what’s up here.
There is a lot of bunching of Elo results, both here and in the traditional Arena rankings. I speculate that as people learn about LLMs, a large percentage of queries are things LLMs are known to handle, so which answer gets chosen becomes a stylistic coin flip reasonably often among decent models? We have for example Sonnet winning something like 40% of the time against Opus, so Sonnet is for many purposes ‘good enough.’
From Venkatesh Rao: Arbitrariness costs as a key form of transaction costs. As things get more complex we have to store more and more arbitrary details in our head. If we want to do [new thing] we need to learn more of those details. That is exhausting and annoying. So often we stick to the things where we know the arbitrary stuff already.
He is skeptical AI Fixes This. I am less skeptical. One excellent use of AI is to ask it about the arbitrary things in life. If it was in the training data, or you can provide access to the guide, then the AI knows. Asking is annoying, but miles less annoying than not knowing. Soon we will have agents like Apple Intelligence to tell you with a better interface, or increasingly do all of it for you. That will match the premium experiences that take this issue away.
What searches are better with AI than Google Search? Patrick McKenzie says not yet core searches, but a lot of classes of other things, such as ‘tip of the tongue’ searches.
Hook GPT-4 up to your security cameras and home assistant, and find lost things. If you are already paying the ‘creepy tax’ then why not? Note that this need not be on except when you need it.
Claude’s dark spiritual AI futurism from Jessica Taylor.
Fine tuning, for style or a character, works and is at least great fun. Why, asks Sarah Constantin, are more people not doing it? Why aren’t they sharing the results?
Gallabytes recommends Gemini Flash and Paligemma 3b, is so impressed by small models he mostly stopped using the ‘big slow’ ones except he still uses Claude when he needs to use PDF inputs. My experience is different, I will continue to go big, but small models have certainly improved.
It would be cool if we could able to apply LLMs to all books, Alex Tabarrok demands all books come with a code that will unlock eText capable of being read by an LLM. If you have a public domain book NotebookLM can let you read while asking questions with inline citations (link explains how) and jump to supporting passages and so on, super cool. Garry Tan originally called this ‘Perplexity meets Kindle.’ That name is confusing to me except insofar as he has invested in Perplexity, since Perplexity does not have the functionality you want here, Gemini 1.5 and Claude do.
The obvious solution is for Amazon to do a deal with either Google or Anthropic to incorporate this ability into the Kindle. Get to work, everyone.
Language Models Don’t Offer Mundane Utility
I Will Fucking Piledrive You If You Mention AI Again. No, every company does not need an AI strategy, this righteously furious and quite funny programmer informs us. So much of it is hype and fake. They realize all this will have big impacts, and even think an intelligence explosion and existential risk are real possibilities, but that says nothing about what your company should be doing. Know your exact use case, or wait, doing fake half measures won’t make you more prepared down the line. I think that depends how you go about it. If you are gaining core competencies and familiarities, that’s good. If you are scrambling with outside contractors for an ‘AI strategy’ then not so much.
Creativity Has Left the Chat: The Price of Debiasing Language Models. RLHF on Llama-2 greatly reduced its creativity, making it more likely output would tend towards a small number of ‘attractor states.’ While the point remains, it does seem like Llama-2’s RLHF was especially ham-handed. Like anything else, you can do RLHF well or you can do it poorly. If you do it well, you still pay a price, but nothing like the price you pay when you do it badly. The AI will learn what you teach it, not what you were trying to teach it.
Near: please stop its physically painful
i wonder what it was like to be in the meeting for this
“we need to add AI to our mouse”
“oh. uhhh. uhhnhmj. what about an AI…button?”
“genius! but we don’t have any AI products :(“
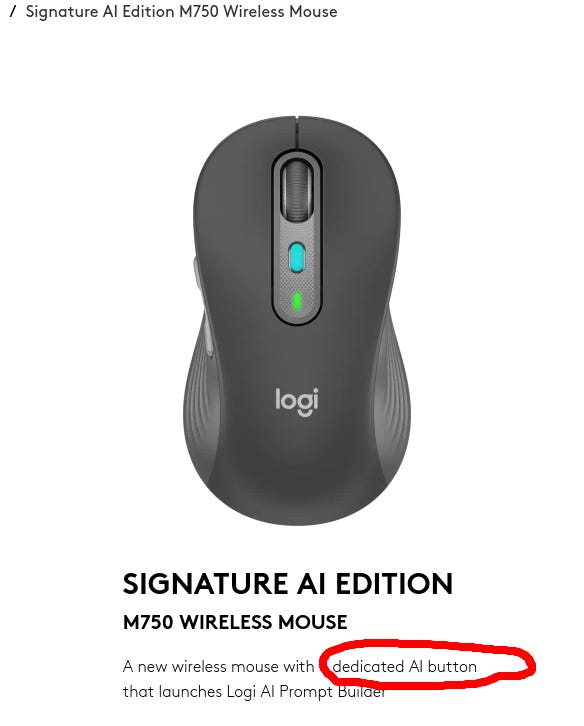
Having a dedicated button on mouse or keyboard that says ‘turn on the PC microphone so you can input AI instructions’ seems good? Yes, the implementation is cringe, but the button itself is fine. The world needs more buttons.
Fun with Image Generation
The distracted boyfriend, now caught on video, worth a look. Seems to really get it.
Andrej Karpathy: wow. The new model from Luma Labs AI extending images into videos is really something else. I understood intuitively that this would become possible very soon, but it’s still something else to see it and think through future iterations of.
A few more examples around, e.g. the girl in front of the house on fire.
As noted earlier, the big weakness for now is that the clips are very short. Within the time they last, they’re super sweet.
How to get the best results from Stable Diffusion 3. You can use very long prompts, but negative prompts don’t work.
New compression method dropped for images, it is lossy but wow is it tiny.
Ethan: so this is nuts, if you’re cool with the high frequency details of an image being reinterpreted/stochastic, you can encode an image quite faithfully into 32 tokens… with a codebook size of 1024 as they use this is just 320bits, new upper bound for the information in an image unlocked.
Eliezer Yudkowsky: Probably some people would have, if asked in advance, claimed that it was impossible for arbitrarily advanced superintelligences to decently compress real images into 320 bits. “You can’t compress things infinitely!” they would say condescendingly. “Intelligence isn’t magic!”
No, kids, the network did not memorize the images. They train on one set of images and test on a different set of images. This is standard practice in AI. I realize you may have reason not to trust in the adequacy of all Earth institutions, but “computer scientists in the last 70 years since AI was invented” are in fact smart enough to think sufficiently simple thoughts as “what if the program is just memorizing the training data”!
Davidad: Even *after* having seen it demonstrated, I will claim that it is impossible for arbitrarily advanced superintelligences to decently compress real 256×256 images into 320 bits. A BIP39 passphrase has 480 bits of entropy and fits very comfortably in a real 256×256 photo. [shows example]
Come to think of it, I could easily have added another 93 bits of entropy just by writing each word using a randomly selected one of my 15 distinctly coloured pens. To say nothing of underlining, capitalization, or diacritics.
Eliezer Yudkowsky: Yes, that thought had occurred to me. I do wonder what happens if we run this image through the system! I mostly expect it to go unintelligible. A sufficiently advanced compressor would return a image that looked just like this one but with a different passcode.
Right. It is theoretically impossible to actually encode the entire picture in 320 bits. There are a lot more pictures than that, including meaningfully different pictures. So this process will lose most details. It still says a lot about what can be done.
Did Suno’s release ‘change music forever?” James O’Malley gets overexcited. Yes, the AI can now write you mediocre songs, the examples can be damn good. I’m skeptical that this much matters. As James notes, authenticity is key to music. I would add so is convention, and coordination, and there being ‘a way the song goes,’ and so on. We already have plenty of ‘slop’ songs available. Yes, being able to get songs on a particular topic on demand with chosen details is cool, but I don’t think it meaningfully competes with most music until it gets actively better than what it is trying to replace. That’s harder. Even then, I’d be much more worried as a songwriter than as a performer.
Movies that change every time you watch? Joshua Hawkins finds it potentially interesting. Robin Hanson says no, offers to bet <1% of movie views for next 30 years. If you presume Robin’s prediction of a long period of ‘economic normal’ as given, then I agree that randomization in movies mostly is bad. Occasionally you have a good reason for some fixed variation (e.g. Clue) but mostly not and mostly it would be fixed variations. I think games and interactive movies where you make choices are great but are distinct art forms.
Deepfaketown and Botpocalypse Soon
Patrick McKenzie warns about people increasingly scamming the government via private actors that the government trusts, which AI will doubtless turbocharge. The optimal amount of fraud is not zero, unless any non-zero amount plus AI means it would now be infinite, in which case you need to change your fraud policy.
This is in response to Mary Rose reporting that in her online college class a third of the students are AI-powered spambots.
Memorializing loved ones through AI. Ethicists object because that is their job.
Noah Smith: Half of Black Mirror episodes would actually just be totally fine and chill if they happened in real life, because the people involved wouldn’t be characters written by cynical British punk fans.
Make sure you know which half you are in. In this case, seems fine. I also note that if they save the training data, the AI can improve a lot over time.
Botpocalypse will now pause until the Russians pay their OpenAI API bill.
The Art of the Jailbreak
Haize Labs announces automatic red-teaming of LLMs. Thread discusses jailbreaks of all kinds. You’ve got text, image, video and voice. You’ve got an assistant saying something bad. And so on, there’s a repo, can apply to try it out here.
This seems like a necessary and useful project, assuming it is a good implementation. It is great to have an automatic tool to do the first [a lot] cycles of red-teaming while you try to at least deal with that. The worry is that they are overpromising, implying that once you pass their tests you will be good to go and actually secure. You won’t. You might be ‘good to go’ in the sense of good enough for 4-level models. You won’t be actually secure and you still need the human red teaming. The key is not losing sight of that.
Copyright Confrontation
Wired article about how Perplexity ignores the Robot Exclusion Protocol, despite claiming they will adhere to it, scraping areas of websites they have no right to scrape. Also its chatbot bullshits, which is not exactly a shock.
Dhruv Mehrotra and Tim Marchman (Wired): WIRED verified that the IP address in question is almost certainly linked to Perplexity by creating a new website and monitoring its server logs. Immediately after a WIRED reporter prompted the Perplexity chatbot to summarize the website’s content, the server logged that the IP address visited the site. This same IP address was first observed by Knight during a similar test.
…
In theory, Perplexity’s chatbot shouldn’t be able to summarize WIRED articles, because our engineers have blocked its crawler via our robots.txt file since earlier this year.
Perplexity denies the allegations in the strongest and most general terms, but the denial rings hollow. The evidence here seems rather strong.
A Matter of the National Security Agency
OpenAI’s newest board member is General Paul Nakasone. He has led the NSA, and has had responsibility for American cyberdefense. He left service on February 2, 2024.
Sam Altman: Excited for general paul nakasone to join the OpenAI board for many reasons, including the critical importance of adding safety and security expertise as we head into our next phase.
OpenAI: Today, Retired U.S. Army General Paul M. Nakasone has joined our Board of Directors. A leading expert in cybersecurity, Nakasone’s appointment reflects OpenAI’s commitment to safety and security, and underscores the growing significance of cybersecurity as the impact of AI technology continues to grow.
As a first priority, Nakasone will join the Board’s Safety and Security Committee, which is responsible for making recommendations to the full Board on critical safety and security decisions for all OpenAI projects and operations.
The public reaction was about what you would expect. The NSA is not an especially popular or trusted institution. The optics, for regular people, were very not good.
TechCrunch: The high-profile addition is likely intended to satisfy critics who think that @OpenAI is moving faster than is wise for its customers and possibly humanity, putting out models and services without adequately evaluating their risks or locking them down
Shoshana Weissmann: For the love of gd can someone please force OpenAI to hire a fucking PR team? How stupid do they have to be?
The counterargument is that cybersecurity and other forms of security are desperately needed at OpenAI and other major labs. We need experts, especially from the government, who can help implement best practices and make the foreign spies at least work for it if they want to steal all the secrets. This is why Leopold called for ‘locking down the labs,’ and I strongly agree there needs to be far more of that then there has been.
There are some very good reasons to like this on principle.
Dan Elton: You gotta admit, the NSA does seem to be pretty good at cybersecurity. It’s hard to think of anyone in the world who would be better aware of the threat landscape than the head of the NSA. He just stepped down in Feb this year. Ofc, he is a people wrangler, not a coder himself.
Just learned they were behind the “WannaCry” hacking tool… I honestly didn’t know that. It caused billions in damage after hackers were able to steal it from the NSA.
Kim Dotcom: OpenAI just hired the guy who was in charge of mass surveillance at the NSA. He outsourced the illegal mass spying against Americans to British spy agencies to circumvent US law. He gave them unlimited spying access to US networks. Tells you all you need to know about OpenAI.
Cate Hall: It tells me they are trying at least a little bit to secure their systems.
Wall Street Silver: This is a huge red flag for OpenAI.
Former head of the National Security Agency, retired Gen. Paul Nakasone has joined OpenAI.
Anyone using OpenAI going forward, you just need to understand that the US govt has full operating control and influence over this app.
There is no other reason to add someone like that to your company.
Daniel Eth: I don’t think this is true, and anyway I think it’s a good sign that OpenAI may take cybersecurity more seriously in the future.
Bogdan Ionut Cirstea: there is an obvious other reason to ‘add someone like that’: good cybersecurity to protect model weights, algorithmic secrets, etc.
LessWrong discusses it here. [LW · GW]
There are also reasons to dislike it, if you think this is about reassurance or how things look rather than an attempt to actually improve security. Or if you think it is a play for government contracts.
Or, of course, it could be some sort of grand conspiracy.
It also could be that the government insisted that something like this happen.
If so? It depends on why they did that.
If it was to secure the secrets? Good. This is the right kind of ‘assist and insist.’
Jeffrey Ladish thinks OpenAI Chief Scientist Jakub Pachocki has had his Twitter account hacked, as he says he is proud to announce the new token $OPENAI. This took over 19 hours, at minimum, to be removed.
If it was to steal our secrets? Not so good.
Mostly I take this as good news. OpenAI desperately needs to improve its cybersecurity. This is a way to start down the path of doing that.
If it makes people think OpenAI are acting like villains? Well, they are. So, bonus.
Get Involved
If you live in San Francisco, share your thoughts on SB 1047 here. I have been informed this is worth the time.
GovAI is hiring for Research Fellow and Research Scholars.
Introducing
Remember Golden Gate Claude? Would you like to play with the API version of that for any feature at all? Apply with Anthropic here.
Chinese AI Safety Network, a cooperation platform for AI Safety across China.
OpenAI allows fine-tuning for function calling, with support for the ‘tools’ parameter.
OpenAI launches partnership with Color Health on cancer screening and treatment.
Belle Lin (WSJ): “Primary care doctors don’t tend to either have the time, or sometimes even the expertise, to risk-adjust people’s screening guidelines,” Laraki said.
There’s also a bunch of help with paperwork and admin, which is most welcome. Idea is to focus on a few narrow key steps and go from there. A lot of this sounds like ‘things that could and should have been done without an LLM and now we have an excuse to actually do them.’ Which, to be clear, is good.
Playgrounds for ChatGPT claims to be a semi-autonomous AI programmer that writes code for you and deploys it for you to test right in chat without downloads, configs or signups.
Joe Carlsmith publishes full Otherness sequence as a PDF.
TikTok symphony, their generative AI assistant for content creators. It can link into your account for context, and knows about what’s happening on TikTok. They also have a creative studio offering to generate video previews and offer translations and stock avatars and display cards and use AI editing tools. They are going all the way:
TikTok: Auto-Generation: Symphony creates brand new video content based on a product URL or existing assets from your account.
They call this ‘elevating human creativity’ with AI technology. I wonder what happens when they essentially invite low-effort AI content onto their platform en masse?
Meta shares four new AI models, Chameleon, JASCO for text-to-music, AudioSeal for detection of AI generated speech and Multi-Token Prediction for code completion. Details here, they also have some documentation for us.
In Other AI News
MIRI parts ways with their agent foundations team, who will continue on their own.
Luke Muehlhauser explains he resigned from the Anthropic board because there was a conflict with his work at Open Philanthropy and its policy advocacy. I do not see that as a conflict. If being a board member at Anthropic was a conflict with advocating for strong regulations or considered by them a ‘bad look,’ then that potentially says something is very wrong at Anthropic as well. Yes, there is the ‘behind the scenes’ story but one not behind the scenes must be skeptical. More than that, I think Luke plausibly… chose the wrong role? I realize most board members are very part time, but I think the board of Anthropic was the more important assignment.
Hugging Face CEO says a growing number of AI startup founders are looking to sell, with this happening a lot more this year than in the past. No suggestion as to why. A lot of this could be ‘there are a lot more AI startups now.’
I am not going to otherwise link to it but Guardian published a pure hit piece about Lighthaven and Manifest that goes way beyond the rules of bounded distrust to be wildly factually inaccurate on so many levels I would not know where to begin.
Richard Ngo: For months I’ve had a thread in my drafts about how techies are too harsh on journalists. I’m just waiting to post it on a day when there isn’t an egregiously bad-faith anti-tech hit piece already trending. Surely one day soon, right?
The thread’s key point: tech is in fact killing newspapers, and it’s very hard for people in a dying industry to uphold standards. So despite how bad most journalism has become, techies have a responsibility to try save the good parts, which are genuinely crucial for society.
At this point, my thesis is that the way you save the good parts of journalism is by actually doing good journalism, in ways that make sense today, a statement I hope I can conclude with: You’re welcome.
Your periodic other reminder: Y saying things in bad faith about X does not mean X is now ‘controversial.’ It means Y is in bad faith. Nothing more.
Also, this is a valid counterpoint to ignoring it all:
Ronny Fernandez: This is article is like y’know, pretty silly, poorly written, and poorly researched, but I’m not one to stick my nose up at free advertising. If you would like to run an event at our awesome venue, please fill out an application at http://lighthaven.space!
It is quite an awesome venue.
Meta halts European AI model launch following Irish government’s request. What was the request?
Samuya Nigam (India TV): The decision was made after the Irish privacy regulator told it to delay its plan to harness data from Facebook and Instagram users.
…
At issue is Meta’s plan to use personal data to train its artificial intelligence (AI) models without seeking consent, the company said THAT it would use publicly available and licensed online information.
In other words:
- Meta was told it couldn’t use personal data to train its AIs without consent.
- Meta decided if it couldn’t do that it wasn’t worth launching its AI products.
- They could have launched the AI products without training on personal data.
- So this tells you a lot about why they are launching their AI products.
Various techniques allow LLMs to get as good at math as unaided frontier models. It all seems very straightforward, the kinds of things you would try and that someone finally got around to trying. Given that computers and algorithms are known to already often be good at math, it stands to reason (maybe this is me not understanding the difficulties?) that if you attach an LLM to algorithms of course it can then become good at math without itself even being that powerful?
Can we defend against adversarial attacks on advanced Go programs? Any given particular attack, yes. All attacks at all is still harder. You can make the attacks need to get more sophisticated as you go, but there is some kind of generalization that the AIs are missing, a form of ‘oh this must be some sort of trick to capture a large group and I am far ahead so I will create two Is in case I don’t get it.’ The core problem, in a sense, is arrogance, the ruthless efficiency of such programs, where they do the thing you often see in science fiction where the heroes start doing something weird and are obviously up to something, yet the automated systems or dumb villains ignore them.
The AI needs to learn the simple principle: Space Bunnies Must Die. As in, your opponent is doing things for a reason. If you don’t know the reason (for a card, or a move, or other strategy) then that means it is a Space Bunny. It Must Die.
Tony Wang offers his thoughts, that basic adversarial training is not being properly extended, and we need to make it more robust.
Quiet Speculations
Sarah Constantin liveblogs reading Situational Awareness, time to break out the International Popcorn Reserve.
Mostly she echoes highly reasonable criticisms others (including myself have raised). Strangest claim I saw was doubting that superhuman persuasion was a thing. I see people doubt this and I am deeply confused how it could fail to be a thing, given we have essentially seen existence proofs among humans.
ChatGPT says the first known person to say the following quip was Ken Thompson, but who knows, and I didn’t remember hearing it before:
Sarah Constantin (not the first to say this): To paraphrase Gandhi:
“What do you think of computer security?”
“I think it would be a good idea.”
She offers sensible basic critiques of Leopold’s alignment ideas, pointing out that the techniques he discusses mostly aren’t even relevant to the problems we need to solve, while being strangely hopeful for ‘pleasant surprises.’
This made me smile:
Sarah Constantin: …but you are predicting that AI will increasingly *constitute* all of our technology and industry
that’s a pretty crazy thing to just hand over, y’know???
did you have a really bad experience with Sam Altman or something?
She then moves on to doubt AI will be crucial enough to national security to merit The Project, she is generally skeptical that the ASI (superintelligence) will Be All That even if we get it. Leopold and I both think, as almost everyone does, that doubting ASI will show up is highly reasonable. But I find it highly bizarre to think, as many seem to predict, that ASI could show up and then not much would change. That to me seems like it is responding to a claim that X→Y with a claim of Not X. And again, maybe X and maybe Not X, but X→Y.
Dominic Cummings covers Leopold’s observations exactly how anyone who follows him would expect, saying we should assume anything in the AI labs will leak instantly. How can you take seriously anyone who says they are building worldchanging technology but doesn’t take security on that tech seriously?
My answer would be: Because seriousness does not mean that kind of situational awareness, these people do not think about security that way. It is not in their culture, by that standard essentially no one in the West is serious period. Then again, Dominic and Leopold (and I) would bite that bullet, that in the most important sense almost no one is a serious person, there are no Reasonable Authority Figures available, etc. That’s the point.
In other not necessarily the news, on the timing of GPT-5, which is supposed to be in training now:
Davidad: Your periodic PSA that the GPT-4 pretraining run took place from ~January 2022 to August 2022.
Dean Ball covers Apple Intelligence, noting the deep commitment to privacy and how it is not so tied to OpenAI or ChatGPT after all, and puts it in context of two visions of the future. Leopold’s vision is the drop-in worker, or a system that can do anything you want if you ask it in English. Apple and Microsoft see AI as a layer atop the operating system, with the underlying model not so important. Dean suggests these imply different policy approaches.
My response would be that there is no conflict here. Apple and Microsoft have found a highly useful (if implemented well and securely) application of AI, and a plausible candidate for the medium term killer app. It is a good vision in both senses. For that particular purpose, you can mostly use a lightweight model, and for now you are wise to do so, with callouts to bigger ones when needed, which is the plan.
That has nothing to do with whether Leopold’s vision can be achieved in the future. My baseline scenario is that this will become part of your computer’s operating system and your tech stack in ways that mostly call small models, along with our existing other uses of larger models. Then, over time, the AIs get capable of doing more complex tasks and more valuable tasks as well.
Dean Ball: Thus this conflict of visions does not boil down to whether you think AI will transform human affairs. Instead it is a more specific difference in how one models historical and technological change and one’s philosophical conception of “intelligence”: Is superintelligence a thing we will invent in a lab, or will it be an emergent result of everyone on Earth getting a bit smarter and faster with each passing year? Will humans transform the world with AI, or will AI transform the world on its own?
The observation that human affairs are damn certain to be transformed is highly wise. And indeed, in the ‘AI fizzle’ worlds we get a transformation that still ‘looks human’ in this way. If capabilities keep advancing, and we don’t actively stop what wants to happen, then it will go the other way. There is nothing about the business case for Apple Intelligence that precludes the other way, except for the part where the superintelligence wipes out (or at least transforms) Apple along with everything else.
In the meantime, why not be one of the great companies Altman talked about?
Ben Thompson interviews Daniel Gross and Nat Friedman, centrally about Apple. Ben calls Apple ‘the new obvious winner from AI.’ I object, and here’s why:
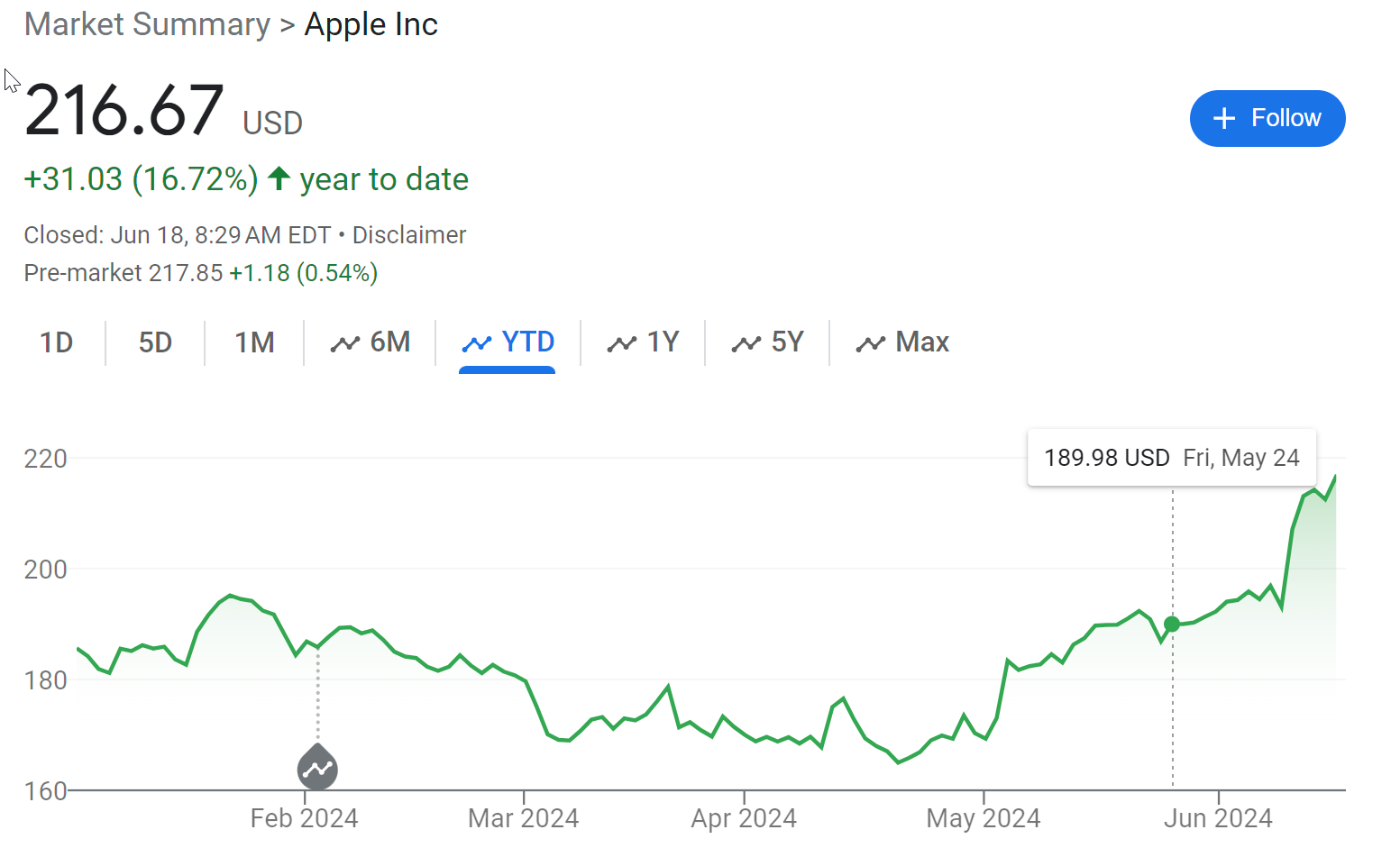
Yes, Apple is a winner, great keynote. But.
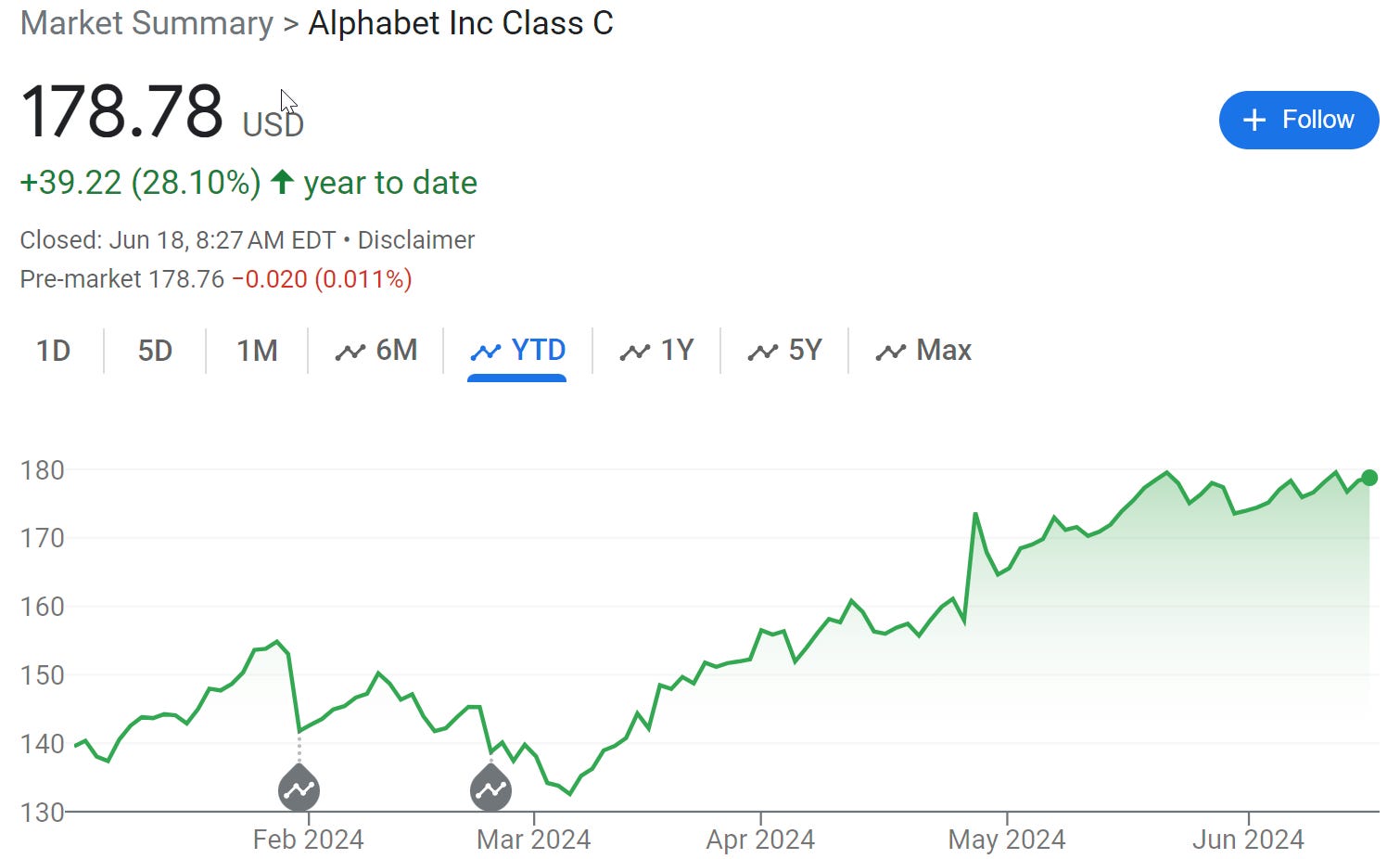
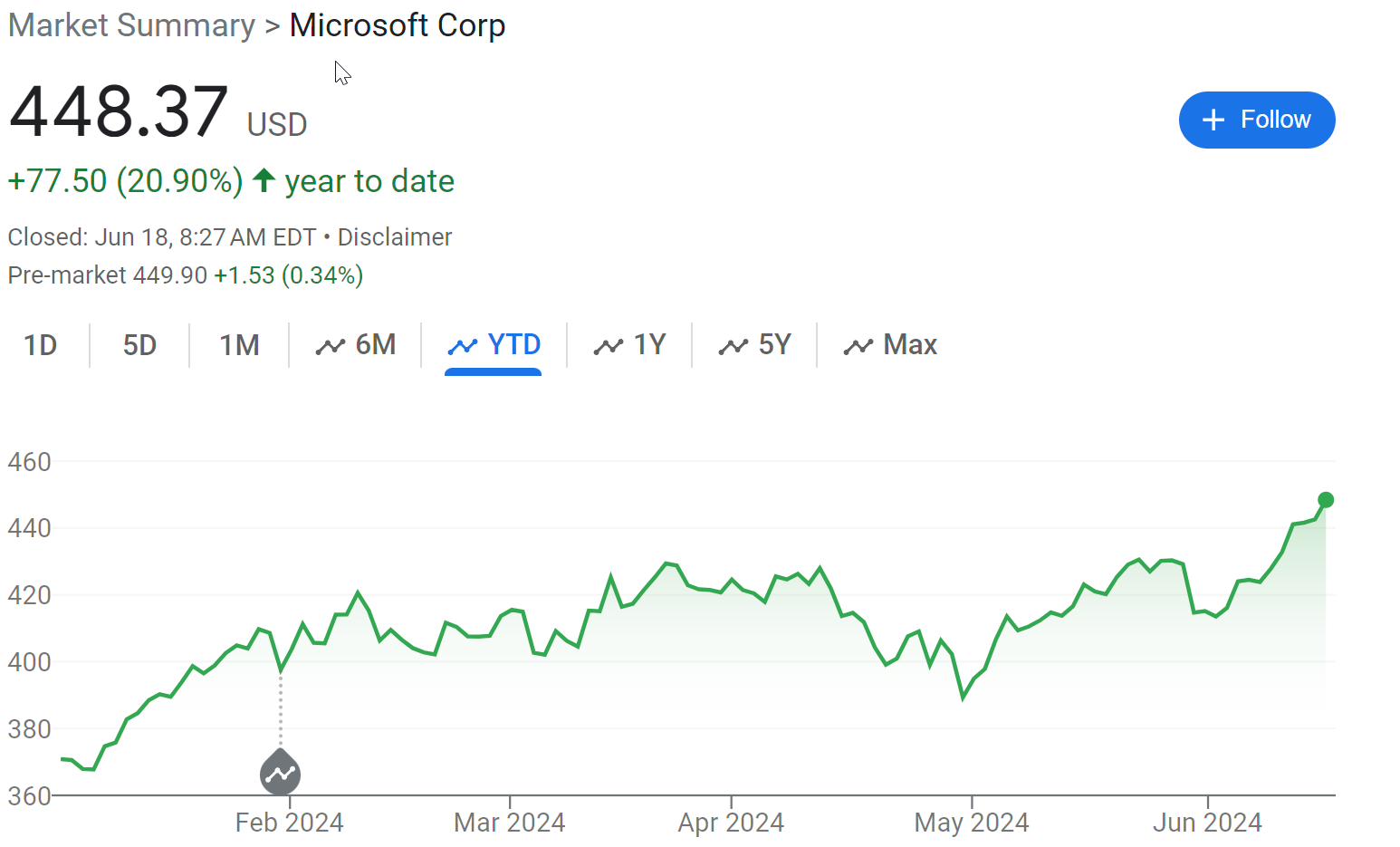
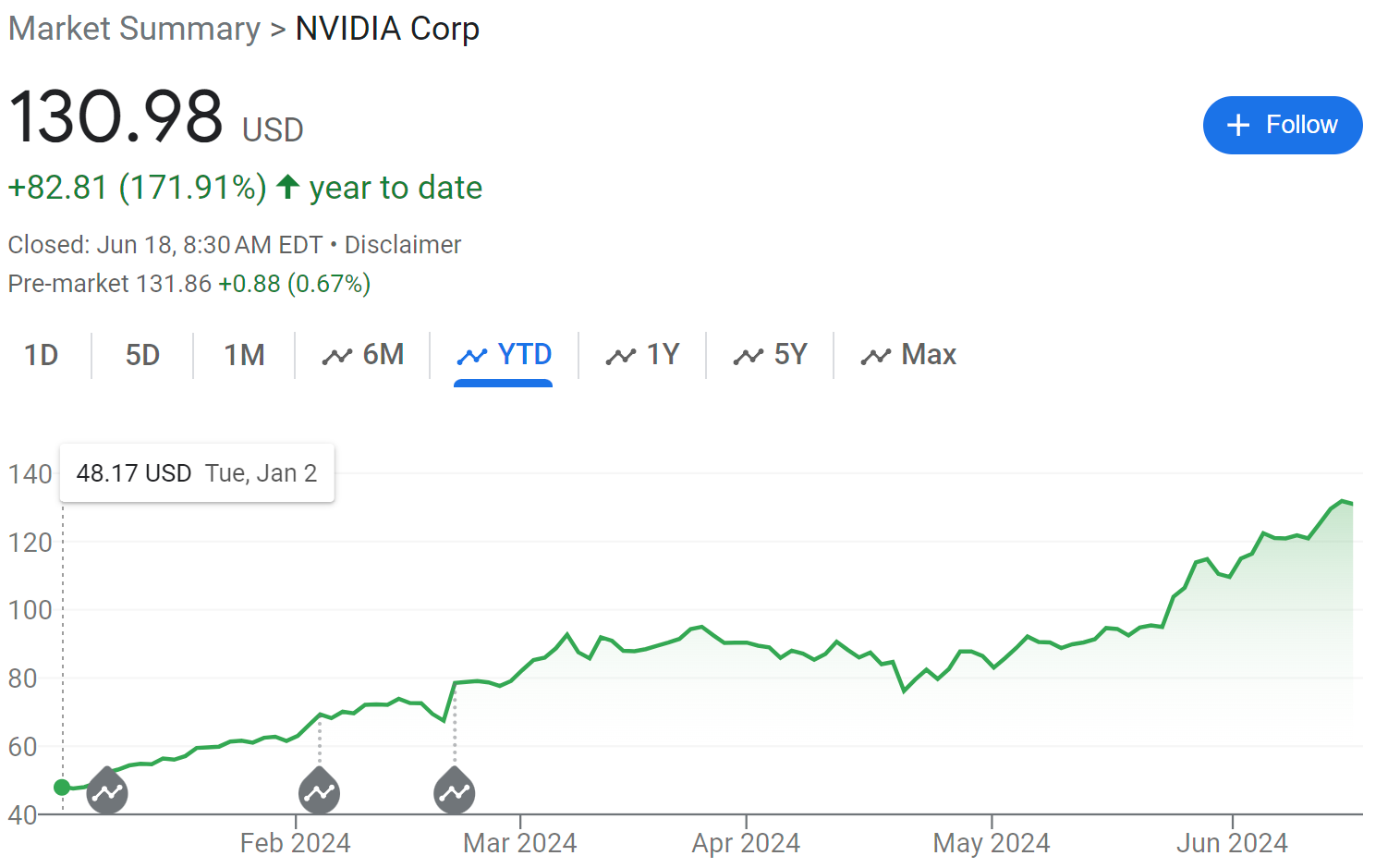
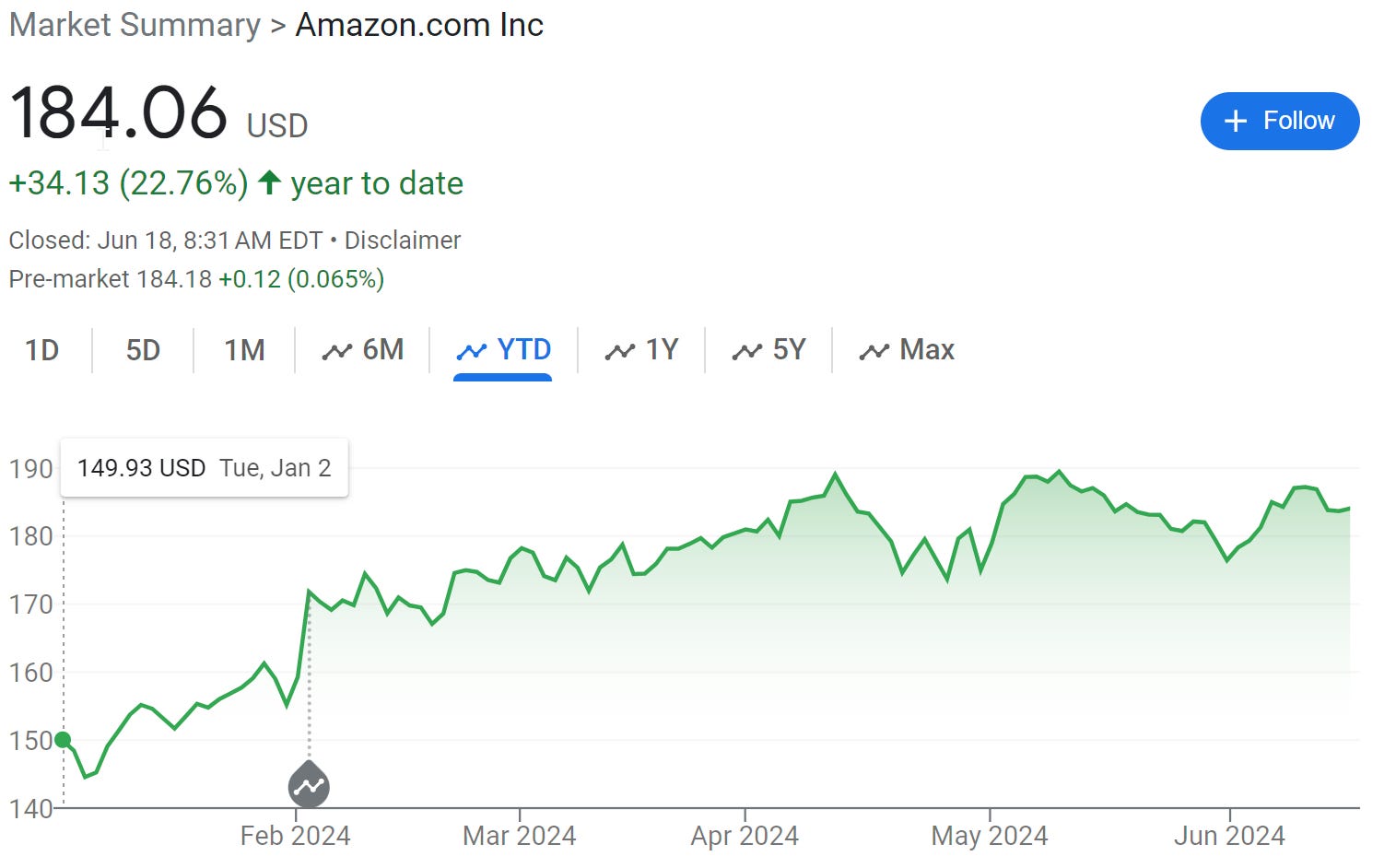
Seems hard to call Apple the big winner when everyone else is winning bigger. Apple is perfectly capable of winning bigly, but this is such a conventional, ‘economic normal’ vision of the future where AI is nothing but another tool and layer on consumer products.
If that future comes to pass, then maybe. But I see no moats here of any kind. The UI is the null UI, the ‘talk to the computer’ UI. There’s no moat here. It is the obvious interface in hindsight because it was also obvious in advance. Email summaries in your inbox view? Yes, of course, if the AI is good enough and doing that is safe. The entire question was always whether you trust it to do this.
All of the cool things Apple did in their presentation? Apple may or may not have them ready for prime time soon, and all three of Apple and Google and Microsoft will have them ready within a year. If you think that Apple Intelligence is going to be way ahead of Google’s similar Android offerings in a few years, I am confused why you think that.
Nat says this straightforwardly, the investor perspective that ‘UI and products’ are the main barrier to AI rather than making the AIs smarter. You definitely need both, but ultimately I am very much on the ‘make it smarter’ side of this.
Reading the full interview, it sounds like Apple is going to have a big reputation management problem, even bigger than Google’s. They are going to have to ‘stay out of the content generation business’ and focus on summarizes and searches and so on. The images are all highly stylized. Which are all great and often useful things, but puts you at a disadvantage.
If this was all hype and there was going to be a top, we’d be near the top.
Except, no. Even if nothing advances furth, not hype. No top. Not investment advice.
But yes, I get why someone would say that.
Ropirito: Just heard a friend’s gf say that she’s doing her “MBAI” at Kellogg.
An MBA with a focus in AI.
This is the absolute top.
Daniel: People don’t understand how completely soaked in AI our lives are going to be in two years. They don’t realize how much more annoying this will get.
I mean, least of our concerns, but also yes.
An LLM can learn from only Elo 1000 chess games, play chess at Elo of 1500, which will essentially always beat an Elo 1000 player. This works, according to the paper, because you combine what different bad players know. Yevgeny Tsodikovich points out Elo 1000 players make plenty of Elo 1500 moves, and I would add tons of blunders. So if you can be ‘Elo 1000 player who knows the heuristics reasonably and without the blunders’ you plausibly are 1500 already.
Consider the generalization. There are those who think LLMs will ‘stop at human level’ in some form. Even if that is true, you can still do a ‘mixture of experts’ of those humans, plus avoiding blunders, plus speedup, plus memorization and larger context and pattern matching, and instruction following and integrated tool use. That ‘human level’ LLM is going to de facto operate far above human level, even if it has some inherent limits on its ‘raw G.’
AI Is Going to Be Huuuuuuuuuuge
That’s right, Donald Trump is here to talk about it. Clip is a little under six minutes.
Tyler Cowen: It feels like someone just showed him a bunch of stuff for the first time?
That’s because someone did just show him a bunch of stuff for the first time.
Also, I’ve never tried to add punctuation to a Trump statement before, I did not realize how wild a task that is.
Here is exactly what he said, although I’ve cut out a bit of host talk. Vintage Trump.
Trump: It is a superpower and you want to be right at the beginning of it but it is very disconcerting. You used the word alarming it is alarming. When I saw a picture of me promoting a product and I could not tell the voice was perfect the lips moved perfectly with every word the way you couldn’t if you were a lip reader you’d say it was absolutely perfect. And that’s scary.
In particular, in one way if you’re the President of the United States, and you announced that 13 missiles have been sent to let’s not use the name of country, we have just sent 13 nuclear missiles heading to somewhere. And they will hit their targets in 12 minutes and 59 seconds. And you’re that country. And there’s no way of detecting, you know I asked Elon is there any way that Russia or China can say that’s not really president Trump? He said there is no way.
No, they have to rely on a code. Who the hell’s going to check you got like 12 minutes and let’s check the code, gee, how’s everything doing? So what do they do when they see this, right? They have maybe a counter attack. Uh, it’s so dangerous in that way.
And another way they’re incredible, what they do is so incredible, I’ve seen it. I just got back from San Francisco. I met with incredible people in San Francisco and we talked about this. This subject is hot on their plates you know, the super geniuses, and they gave me $12 million for the campaign which 4 years ago they probably wouldn’t have, they had thousands of people on the streets you saw it. It just happened this past week. I met with incredible people actually and this is their big, this is what everyone’s talking about. With all of the technology, these are the real technology people.
They’re talking about AI, and they showed me things, I’ve seen things that are so – you wouldn’t even think it’s possible. But in terms of copycat now to a lesser extent they can make a commercial. I saw this, they made a commercial me promoting a product. And it wasn’t me. And I said, did I make that commercial? Did I forget that I made that commercial? It is so unbelievable.
So it brings with it difficulty, but we have to be at the – it’s going to happen. And if it’s going to happen, we have to take the lead over China. China is the primary threat in terms of that. And you know what they need more than anything else is electricity. They need to have electricity. Massive amounts of electricity. I don’t know if you know that in order to do these essentially it’s a plant. And the electricity needs are greater than anything we’ve ever needed before, to do AI at the highest level.
And China will produce it, they’ll do whatever they have to do. Whereas we have environmental impact people and you know we have a lot of people trying to hold us back. But, uh, massive amounts of electricity are needed in order to do AI. And we’re going to have to generate a whole different level of energy and we can do it and I think we should do it.
But we have to be very careful with it. We have to watch it. But it’s, uh, you know the words you use were exactly right it’s the words a lot of smart people are using. You know there are those people that say it takes over. It takes over the human race. It’s really powerful stuff, AI. Let’s see how it all works out. But I think as long as it’s there.
[Hosts: What about when it becomes super AI?]
Then they’ll have super AI. Super duper AI. But what it does is so crazy, it’s amazing. It can also be really used for good. I mean things can happen. I had a speech rewritten by AI out there. One of the top people. He said oh you’re going to make a speech he goes click click click, and like 15 seconds later he shows me my speech. Written. So beautify. I’m going to use this.
Q: So what did you say to your speech writer after that? You’re fired?
You’re fired. Yeah I said you’re fired, Vince, get the hell out. [laughs]. No no this was so crazy it took and made it unbelievable and so fast. You just say I’m writing a speech about these two young beautiful men that are great fighters and sort of graded a lot of things and, uh, tell me about them and say some nice things and period. And then that comes out Logan in particular is a great champion. Jake is also good, see I’m doing that only because you happen to be here.
But no it comes out with the most beautiful writing. So one industry that will be gone are these wonderful speechwriters. I’ve never seen anything like it and so quickly, a matter of literally minutes, it’s done. It’s a little bit scary.
Trump was huge for helping me understand LLMs. I realized that they were doing something remarkably similar to what he was doing, vibing off of associations, choosing continuations word by word on instinct, [other things]. It makes so much sense that Trump is super impressed by its ability to write him a speech.
What you actually want, of course, if you are The Donald, is to get an AI that is fine tuned on all of Donald Trump’s speeches, positions, opinions and particular word patterns and choices. Then you would have something.
Sure, you could say that’s all bad, if are the Biden campaign.
Biden-Harris HQ [clipping the speech part of above]: Trump claims his speeches are written by AI.
Daniel Eth: This is fine, actually. There’s nothing wrong with politicians using AI to write their speeches. Probably good, actually, for them to gain familiarity with what these systems can do.
Here I agree with Daniel. This is a totally valid use case, the familiarity is great, why shouldn’t Trump go for it.
Overall this was more on point and on the ball than I expected. The electricity point plays into his politics and worldview and way of thinking. It is also fully accurate as far as it goes. The need to ‘beat China’ also fits perfectly, and it true except for the part where we are already way ahead, although one could still worry about electricity down the line. Both of those were presumably givens.
The concerns ran our usual gamut: Deepfaketown, They Took Our Jobs and also loss of control over the future.
For deepfakes, he runs the full gamut of Things Trump Worries About. On the one hand you have global thermonuclear war. On the other you have fake commercials. Which indeed are both real worries.
(Obviously if you are told you have thirteen minutes, that is indeed enough time to check any codes or check the message details and origin several times to verify it, to physically verify the claims, and so on. Not that there is zero risk in that room, but this scenario does not so much worry me.)
It is great to hear how seamlessly he can take the threat of an AI takeover fully seriously. The affect here is perfect, establishing by default that this is a normal and very reasonable thing to worry about. Very good to hear. Yes, he is saying go ahead, but he is saying you have to be careful. No, he does not understand the details, but this seems like what one would hope for.
Also in particular, notice that no one said the word ‘regulation,’ except by implication around electricity. The people in San Francisco giving him money got him to think about electricity. But otherwise he is saying we must be careful, whereas many of his presumed donors that gave him the $12 million instead want to be careful to ensure we are not careful. This, here? I can work with it.
Also noteworthy: He did not say anything about wokeness or bias, despite clearly having spent a bunch of the conversation around Elon Musk.
SB 1047 Updated Again
Kelsey Piper writes about those opposed to SB 1047, prior to most recent updates.
Charles Foster notes proposed amendments to SB 1047, right before they happened.
There were other people talking about SB 1047 prior to the updates. Their statements contained nothing new. Ignore them.
Then Scott Wiener announced they’d amended the bill again. You have to dig into the website a bit to find them, but they’re there (look at the analysis and look for ‘6) Full text as proposed to be amended.’ It’s on page 19. The analysis Scott links to includes other changes, some of them based on rather large misunderstandings.
Before getting into the changes, one thing needs to be clear: These changes were all made by the committee. This was not ‘Weiner decides how to change the bill.’ This was other lawmakers deciding to change the bill. Yes, Weiner got some say, but anyone who says ‘this is Weiner not listening’ or similar needs to keep in mind that this was not up to him.
What are the changes? As usual, I’ll mostly ignore what the announcement says and look at the text of the bill changes. There are a lot of ‘grammar edits’ and also some minor changes that I am ignoring because I don’t think they change anything that matters.
These are the changes that I think matter or might matter.
- The limited duty exemption is gone. Everyone who is talking about the other changes is asking the wrong questions.
- You no longer have to implement covered guidance. You instead have to ‘consider’ the guidance when deciding what to implement. That’s it. Covered guidance now seems more like a potential future offer of safe harbor.
- 22602 (c) redefines a safety incident to require ‘an incident that demonstrably increases the risk of a critical harm occurring by means of,’ which was previously present only in clause (1). Later harm enabling wording has been altered, in ways I think are roughly similar to that. In general hazardous capability is now risk of causing a critical harm. I think that’s similar enough but I’m not 100%.
- 22602 (e) changes from covered guidance (all relevant terms to that deleted) and moves the definition of covered model up a level. The market price used for the $100 million is now that at the start of training, which is simpler (and slightly higher). We still could use an explicit requirement that FMD publish market prices so everyone knows where they stand.
- 22602 (e)(2) now has derivative models become covered models if you use 3e10^25 flops rather than 25% of compute, and any modifications that are not ‘fine-tuning’ do not count regardless of size. Starting in 2027 the FMD determines the new flop threshold for derivative models, based on how much compute is needed to cause critical harm.
- The requirement for baseline covered models can be changed later. Lowering it would do nothing, as noted below, because the $100 million requirement would be all that mattered. Raising the requirement could matter, if the FMD decided we could safely raise the compute threshold above what $100 million buys you in that future.
- Reevaluation of procedures must be annual rather than periodic.
- Starting in 2028 you need a certificate of compliance from an accredited-by-FMD third party auditor.
- A Board of Frontier Models is established, consisting of an open-source community member, an AI industry member, an academic, someone appointed by the speaker and someone appointed by the Senate rules committee. The FMD will act under their supervision.
Scott links to the official analysis on proposed amendments, and in case you are wondering if people involved understand the bill, well, a lot of them don’t. And it is very clear that these misunderstandings and misrepresentations played a crucial part in the changes to the bill, especially removing the limited duty exemption. I’ll talk about that change at the end.
The best criticism I have seen of the changes, Dean Ball’s, essentially assumes that all new authorities will be captured to extract rents and otherwise used in bad faith to tighten the bill, limiting competition for audits to allow arbitrary fees and lowering compute thresholds.
For the audits, I do agree that if all you worry about is potential to impose costs, and you can use licensing to limit competition, this could be an issue. I don’t expect it to be a major expense relative to $100 million in training costs (remember, if you don’t spend that, it’s not covered), but I put up a prediction market on that around a best guess of ‘where this starts to potentially matter’ rather than my median guess on cost. As I understand it, the auditor need only verify compliance with your own plan, rather than needing their own bespoke evaluations or expertise, so this should be relatively cheap and competitive, and there should be plenty of ‘normal’ audit firms available if there is enough demand to justify it.
Whereas the authority to change compute thresholds was put there in order to allow those exact requirements to be weakened when things changed. But also, so what if they do lower the compute threshold on covered models? Let’s say they lower it to 10^2. If you use one hundred flops, that covers you. Would that matter? No! Because the $100 million requirement will make 10^2 and 10^26 the same number very quickly. The only thing you can do with that authority, that does anything, is to raise the number higher. I actually think the bill would plausibly be better off if we eliminated the number entirely, and went with the dollar threshold alone. Cleaner.
The threshold for derivative models is the one that could in theory be messed up. It could move in either direction now. There the whole point is to correctly assign responsibility. If you are motivated by safety you want the correct answer, not the lowest you can come up with (so Meta is off the hook) or the highest you can get (so you can build a model on top of Meta’s and blame it on Meta.) Both failure modes are bad.
If, as one claim said, 3×10^25 is too high, you want that threshold lowered, no?
Which is totally reasonable, but the argument I saw that this was too high was ‘that is almost as much as Meta took to train Llama-3 405B.’ Which would mean that Llama-3 405B would not even be a covered model, and the threshold for covered models will be rising rapidly, so what are we even worried about on this?
It is even plausible that no open models would ever have been covered models in the first place, which would render derivative models impossible other than via using a company’s own fine-tuning API, and mean the whole panic about open models was always fully moot once the $100 million clause came in.
The argument I saw most recently was literally ‘they could lower the threshold to zero, rendering all derivative models illegal.’ Putting aside that it would render them covered not illegal, this goes against all the bill’s explicit instructions, such a move would be thrown out by the courts and no one has any motivation to do it, yes. In theory we could put a minimum there purely so people don’t lose their minds. But then those same people would complain the minimum was arbitrary, or an indication that we were going to move to the minimum or already did or this created uncertainty.
Instead, we see all three complaints at the same time: That the threshold could be set too high, that the same threshold could be set too low, and the same threshold could be inflexible. And those would all be bad. Which they would be, if they happened.
Dan Hendrycks: PR playbook for opposing any possible AI legislation:
- Flexible legal standard (e.g., “significantly more difficult to cause without access to a covered model”) –> “This is too vague and makes compliance impossible!”
- Clear and specific rule (e.g., 10^26 threshold) –> “This is too specific! Why not 10^27? Why not 10^47? This will get out of date quickly.”
- Flexible law updated by regulators –> “This sounds authoritarian and there will be regulatory capture!” Legislation often invokes rules, standards, and regulatory agencies. There are trade-offs in policy design between specificity and flexibility.
It is a better tweet, and still true, if you delete the word ‘AI.’
These are all problems. Each can be right some of the time. You do the best you can.
When you see them all being thrown out maximally, you know what that indicates. I continue to be disappointed by certain people who repeatedly link to bad faith hyperbolic rants about SB 1047. You know who you are. Each time I lose a little more respect for you. But at this point very little, because I have learned not to be surprised.
All of the changes above are relatively minor.
The change that matters is that they removed the limited duty exemption.
This clause was wildly misunderstood and misrepresented. The short version of what it used to do was:
- If your model is not going to be or isn’t at the frontier, you can say so.
- If you do, ensure that is still true, otherwise most requirements are waived.
- Thus models not at frontier would have trivial compliance cost.
This was a way to ensure SB 1047 did not hit the little guy.
It made the bill strictly easier to comply with. You never had to take the option.
Instead, everyone somehow kept thinking this was some sort of plot to require you to evaluate models before training, or that you couldn’t train without the exception, or otherwise imposing new requirements. That wasn’t true. At all.
So you know what happened in committee?
I swear, you cannot make this stuff up, no one would believe you.
The literal Chamber of Commerce stepped in to ask for the clause to be removed.
Eliminating the “limited duty exemption.” The bill in print contains a mechanism for developers to self-certify that their models possess no harmful capabilities, called the “limited duty exemption.” If a model qualifies for one of these “exemptions,” it is not subject to any of downstream requirements of the bill. Confusingly, developers are asked to make this assessment before a model has been trained—that is, before it exists.
Writing in opposition, the California Chamber of Commerce explains why this puts developers in an impossible position:
SB 1047 still makes it impossible for developers to actually determine if they can provide reasonable assurance that a covered model does not have hazardous capabilities and therefore qualifies for limited duty exemption because it requires developers to make the determination before they initiate training of the covered model . . . Because a developer needs to test the model by training it in a controlled environment to make determination that a model qualifies for the exemption, and yet cannot train a model until such a determination is made, SB 1047 effectively places developers in a perpetual catch-22 and illogically prevents them from training frontier models altogether.
So the committee was convinced. The limited duty exemption clause is no more.
You win this one, Chamber of Commerce.
Did they understand what they were doing? You tell me.
How much will this matter in practice?
Without the $100 million threshold, this would have been quite bad.
With the $100 million threshold in place, the downside is far more limited. The class of limited duty exception models was going to be models that cost over $100 million, but which were still behind the frontier. Now those models will have additional requirements and costs imposed.
As I’ve noted before, I don’t think those costs will be so onerous, especially when compared with $100 million in compute costs. Indeed, you can come up with your own safety plan, so you could write down ‘this model is obviously not dangerous because it is 3 OOMs behind Google’s Gemini 3 so we’re not going to need to do that much more.’ But there was no need for it to even come to that.
This is how democracy in action works. A bunch of lawmakers who do not understand come in, listen to a bunch of lobbyists and others, and they make a mix of changes to someone’s carefully crafted bill. Various veto holders demand changes, often that you realize make little sense. You dream it improves the bill, mostly you hope it doesn’t make things too much worse.
My overall take is that the changes other than the limited duty exemption are minor and roughly sideways. Killing the limited duty exemption is a step backwards. But it won’t be too bad given the other changes, and it was demanded by exactly the people the change will impose costs upon. So I find it hard to work up all that much sympathy.
The Quest for Sane Regulations
Pope tells G7 that humans must not lose control over AI. This was his main message as the first pope to address the G7.
The Pope: We would condemn humanity to a future without hope if we took away people’s ability to make decisions about themselves and their lives by dooming them to depend on the choices of machines. We need to ensure and safeguard a space for proper human control over the choices made by artificial intelligence programs: human dignity itself depends on it.
That is not going to be easy.
Samo Burja: Pretty close to the justification for the Butlerian Jihad in Frank Herbert’s Dune.
If you thought the lying about ‘the black box nature of AI models has been solved’ was bad, and it was, Mistral’s CEO Arthur Mensch would like you to hold his wine.
Arthur Mensch (CEO Mistral), to the French Senate: When you write this kind of software, you always control what will happen, all the outputs of the software.
…
We are talking about software, nothing has changed, this is just a programming language, nobody can be controlled by their programming language.
An argument that we should not restrict export of cyber capabilities, because offensive capabilities are dual use, so this would include ‘critical’ cybersecurity services, and we don’t want to hurt the defensive capabilities of others. So instead focus on defensive capabilities, says Matthew Mittlesteadt. As usual with such objections, I think this is the application of pre-AI logic and especially heuristics without thinking through the nature of future situations. It also presumes that the proposed export restriction authority is likely to be used overly broadly.
The Week in Audio
Anthropic team discussion on scaling interpretability.
Katja Grace goes on London Futurists to talk AI.
Rational Animations offers a video about research on interpreting InceptionV1. Chris Olah is impressed how technically accurate and accessible this managed to be at once.
From last week’s discussion on Hard Fork with Trudeau, I got a chance to listen. He was asked about existential risk, and pulled out the ‘dystopian science fiction’ line and thinks there is not much we can do about it for now, although he also did admit it was a real concern later on. He emphases ‘AI for good’ to defeat ‘AI for bad.’ He’s definitely not there now and is thinking about existential risks quite wrong, but he sounds open to being convinced later. His thinking about practical questions was much better, although I wish he’d lay off the Manichean worldview.
One contrast that was enlightening: Early on Trudeau sounds like a human talking to a human. When he was challenged on the whole ‘force Meta to support local journalism’ issue, he went into full political bullshit rhetoric mode. Very stark change.
The ARC of Progress
Expanding from last week: Francois Chollet went on Dwarkesh Patel to claim that OpenAI set AI back five years and launch a million dollar prize to get to 85% on the ARC benchmark, which is designed to resist memorization by only requiring elementary knowledge any child knows and asking new questions.
No matter how much I disagree with many of Chollet’s claims, the million dollar prize is awesome. Put your money where your mouth is, this is The Way. Many thanks.
Kerry Vaughan-Rowe: This is the correct way to do LLM skepticism.
Point specifically to the thing LLMs can’t do that they should be able to were they generally intelligent, and then see if future systems are on track to solve these problems.
Chollet says the point of ARC is to make the questions impossible to anticipate. He admits it does not fully succeed.
Instead, based on the sample questions, I’d say ARC is best solved by applying some basic heuristics, and what I did to instantly solve the samples was closer to ‘memorization’ than Chollet wants to admit. It is like math competitions, sometimes you use your intelligence but in large part you learn patterns and then you pattern match. Momentum. Symmetry. Frequency. Enclosure. Pathfinding.
Here’s an example of a pretty cool sample problem.
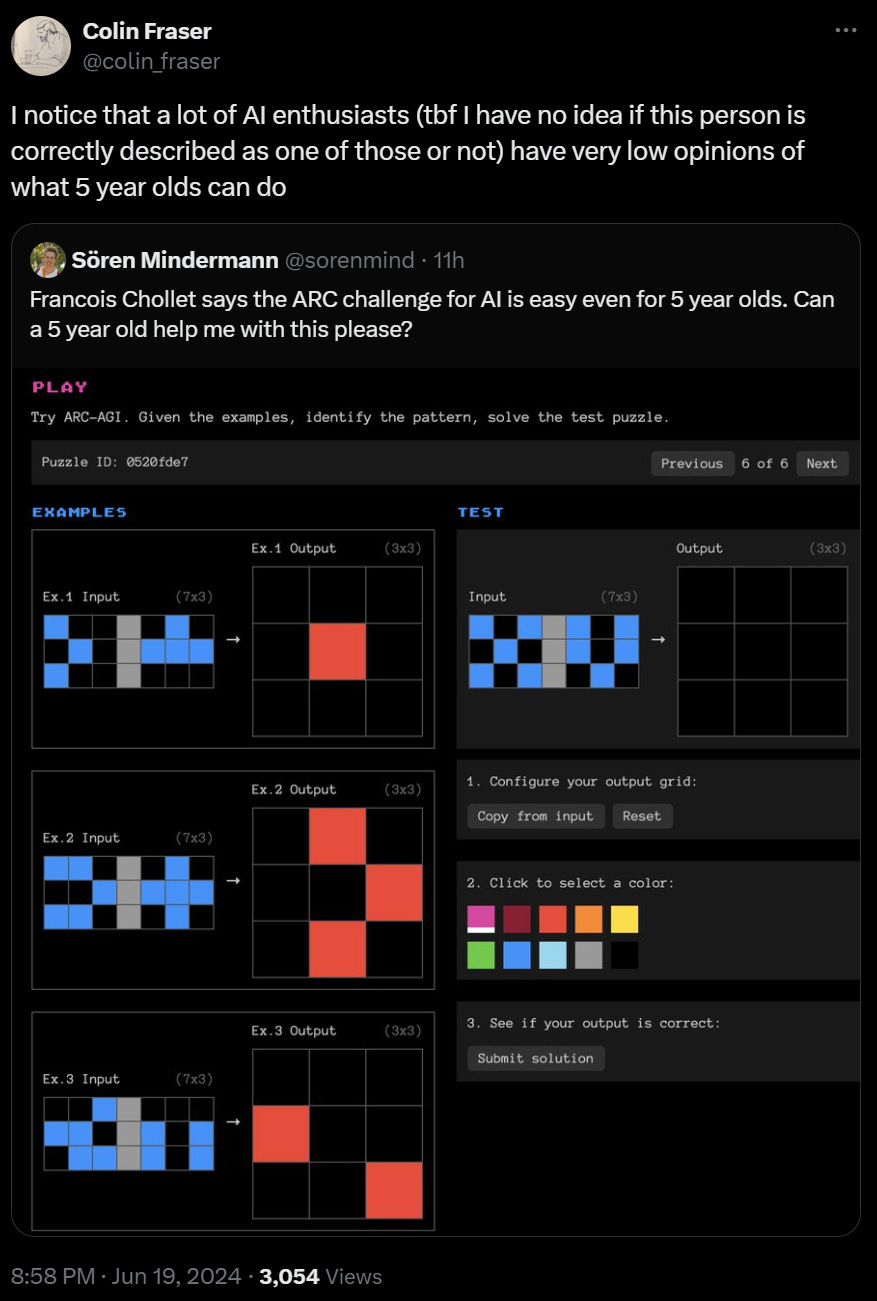
There’s some cool misleading involved here, but ultimately it is very simple. Yes, I think a lot of five year olds will solve this, provided they are motivated. Once again, notice there is essentially a one word answer, and that it would go in my ‘top 100 things to check’ pile.
Why do humans find ARC simple? Because ARC is testing things that humans pick up. It is a test designed for exactly human-shaped things to do well, that we prepare for without needing to prepare, and that doesn’t use language. My guess is that if I used all such heuristics I had and none of them worked, my score on any remaining ARC questions would not be all that great.
If I was trying to get an LLM to get a good score on ARC I would get a list of such patterns, write a description of each, and ask the LLM to identify which ones might apply and check them against the examples. Is pattern matching memorization? I can see it both ways. Yes, presumably that would be ‘cheating’ by Chollet’s principles. But by those principles humans are almost always cheating on everything. Which Chollet admits (around 27:40) but says humans also can adapt and that’s what matters.
At minimum, he takes this too far. At (28:55) he says every human day is full of novel things that they’ve not been prepared for. I am very confident this is hugely false, not merely technically false. Not only is it possible to do this, I am going to outright say that the majority of human days are exactly this, if we count pattern matching under memorization.
This poll got confounded by people reading it backwards (negations are tricky) but the point remains that either way about roughly half of people think the answer is on each side of 50%, very different from his 100%.
At (29:45) Chollet is asked for an example, and I think this example was a combination of extremely narrow (go on Dwarkesh) and otherwise wrong.
He says memorization is not intelligence, so LLMs are dumb. I don’t think this is entirely No True Scotsman (NTS). The ‘raw G’ aspect is a thing that more memorization can’t increase. I do think this perspective is in large part NTS though. No one can tackle literally any problem, if you were to do an adversarial search for the right problem, especially if you can name a problem that ‘seems simple’ in some sense with the knowledge a human has, but that no human can do.
I liked the quote at 58:40, “Intelligence is what you use when you don’t know what to do.” Is it also how you figure out what to do so you don’t need your intelligence later?
I also appreciated the point that intelligence potential is mostly genetic. No amount of training data will turn most people into Einstein, although lack of data or other methods can make Einstein effectively stupider. Your model architecture and training method are going to have a cap on how ‘intelligent’ it can get in some sense.
At 1:04:00 they mention that benchmarks only get traction once they become tractable. If no one can get a reasonable score then no one bothers. So no wonder our most used benchmarks keep getting saturated.
This interview was the first time I can remember that Dwarkesh was getting visibly frustrated, while doing a noble attempt to mitigate it. I would have been frustrated as well.
At 1:06:30 Mike Knoop complains that everyone is keeping their innovations secret. Don’t these labs know that sharing is how we make progress? What an extreme bet on these exact systems. To which I say, perhaps valuable trade secrets are not something it is wise to tell the world, even if you have no safety concerns? Why would DeepMind tell OpenAI how they got a longer context window? They claim OpenAI did that, and also got everyone to hyperfocus on LLMs, so OpenAI delayed progress to AGI by 5-10 years, since LLMs are an ‘off ramp’ on the road to AI. I do not see it that way, although I am hopeful they are right. It is so weird to think progress is not being made.
There is a common pattern of people saying ‘no way AIs can do X any time soon, here’s a prize’ and suddenly people figure out how to make AIs do X.
The solution here is not eligible for the prize, since it uses other tools you are not supposed to use, but still, that escalated quickly.
Dwarkesh Patel: I asked Buck about his thoughts on ARC-AGI to prepare for interviewing François Chollet.
He tells his coworker Ryan, and within 6 days they’ve beat SOTA on ARC and are on the heels of average human performance.
“On a held-out subset of the train set, where humans get 85% accuracy, my solution gets 72% accuracy.”
Buck Shlegeris: ARC-AGI’s been hyped over the last week as a benchmark that LLMs can’t solve. This claim triggered my dear coworker Ryan Greenblatt so he spent the last week trying to solve it with LLMs. Ryan gets 71% accuracy on a set of examples where humans get 85%; this is SOTA.
[Later he learned it was unclear that this was actually SoTA, as private efforts are well ahead of public efforts for now.]
…
Ryan’s approach involves a long, carefully-crafted few-shot prompt that he uses to generate many possible Python programs to implement the transformations. He generates ~5k guesses, selects the best ones using the examples, then has a debugging step.
The results:
Train set: 71% vs a human baseline of 85%
Test set: 51% vs prior SoTA of 34% (human baseline is unknown)
(The train set is much easier than the test set.)
(These numbers are on a random subset of 100 problems that we didn’t iterate on.)
This is despite GPT-4o’s non-reasoning weaknesses:
– It can’t see well (e.g. it gets basic details wrong)
– It can’t code very well
– Its performance drops when there are more than 32k tokens in context.
These are problems that scaling seems very likely to solve.
Scaling the number of sampled Python rules reliably increase performance (+3% accuracy for every doubling). And we are still quite far from the millions of samples AlphaCode uses!

The market says 51% chance the prize is claimed by end of year 2025 and 23% by end of this year.
Davidad: AI scientists in 1988: Gosh, AI sure can play board games, solve math problems, and do general-purpose planning, but there is a missing ingredient: they lack common-sense knowledge, and embodiment.
AI scientists in 2024: Gosh, AI sure does have more knowledge than humans, but…
Moravec’s Paradox Paradox: After 35 years of progress, actually, it turns out AI *can’t* beat humans at checkers, or reliably perform accurate arithmetic calculations, “AlphaGo? That was, what, 2016? AI hadn’t even been *invented* yet. It must have been basically fake, like ELIZA. You need to learn the Bitter Lesson,”
The new “think step by step” is “Use python.”
Put Your Thing In a Box
When is it an excellent technique versus a hopeless one?
Kitten: Don’t let toad blackpill you, cookie boxing is an excellent technique to augment your own self-control Introducing even small amounts of friction in the path of a habit you want to avoid produces measurable results.
If you want to spend less time on your phone, try putting it in a different room Sure you could just go get it, but that’s actually much harder than taking it out of your pocket.
Dr. Dad, PhD: The reverse is also true: remove friction from activities you want to do more.

For personal habits, especially involving temptation and habit formation, this is great on the margin and the effective margin can be extremely wide. Make it easier to do the good things and avoid the bad things (as you see them) and both you and others will do more good things and less bad things. A More Dakka approach to this is recommended.
The problem is this only goes so far. If there is a critical threshold, you need to do enough that the threshold is never reached. In the cookie example, there are only so many cookies. They are very tempting. If the goal is to eat less cookies less often? Box is good. By the same lesson, giving the box to the birds, so you’ll have to bake more, is even better. However, if Toad is a cookiehaulic, and will spiral into a life of sugar if he eats even one more, then the box while better than not boxing is probably no good. An alcoholic is better off booze boxing than having it in plain sight by quite a lot, but you don’t box it, you throw the booze out. Or if the cookies are tempting enough that the box won’t matter much, then it won’t matter much.
The danger is the situation where:
- If the cookies are super tempting, and you box, you still eat all the cookies.
- If the cookies are not that tempting, you were going to eat a few more cookies, and now you can eat less or stop entirely.
Same thing (metaphorically) holds with various forms of AI boxing, or other attempts to defend against or test or control or supervise or restrict or introduce frictions to an AGI or superintelligence. Putting friction in the way can be helpful. But it is most helpful exactly when there was less danger. The more capable and dangerous the AI, the better it will be at breaking out, and until then you might think everything is fine because it did not see a point in tr
5`ying to open the box. Then, all the cookies.
What Will Ilya Do?
I know you mean well, Ilya. We wish you all the best.
Alas. Seriously. No. Stop. Don’t.

Theo: The year is 2021. A group of OpenAI employees are worried about the company’s lack of focus on safe AGI, and leave to start their own lab.
The year is 2023. An OpenAI co-founder is worried about the company’s lack of focus on safe AGI, so he starts his own lab.
The year is 2024
Ilya Sutskever: I am starting a new company.
That’s right. But don’t worry. They’re building ‘safe superintelligence.’
His cofounders are Daniel Gross and Daniel Levy.
The plan? A small ‘cracked team.’ So no, loser, you can’t get in.
No products until superintelligence. Go.
Ilya, Daniel and Daniel: We’ve started the world’s first straight-shot SSI lab, with one goal and one product: a safe superintelligence.
It’s called Safe Superintelligence Inc.
SSI is our mission, our name, and our entire product roadmap, because it is our sole focus. Our team, investors, and business model are all aligned to achieve SSI.
We approach safety and capabilities in tandem, as technical problems to be solved through revolutionary engineering and scientific breakthroughs. We plan to advance capabilities as fast as possible while making sure our safety always remains ahead.
This way, we can scale in peace.
Our singular focus means no distraction by management overhead or product cycles, and our business model means safety, security, and progress are all insulated from short-term commercial pressures.
We are an American company with offices in Palo Alto and Tel Aviv, where we have deep roots and the ability to recruit top technical talent.
We are assembling a lean, cracked team of the world’s best engineers and researchers dedicated to focusing on SSI and nothing else.
If that’s you, we offer an opportunity to do your life’s work and help solve the most important technical challenge of our age.
Now is the time. Join us.
Ilya Sutskever: This company is special in that its first product will be the safe superintelligence, and it will not do anything else up until then. It will be fully insulated from the outside pressures of having to deal with a large and complicated product and having to be stuck in a competitive rat race.
…
By safe, we mean safe like nuclear safety as opposed to safe as in ‘trust and safety.’
Daniel Gross: Out of all the problems we face, raising capital is not going to be one of them.
Nice work if you can get it. Why have a product when you don’t have to? In this case, with this team, it is highly plausible they do not have to.
Has Ilya figured out what a safe superintelligence would look like?
Ilya Sutskever: At the most basic level, safe superintelligence should have the property that it will not harm humanity at a large scale. After this, we can say we would like it to be a force for good. We would like to be operating on top of some key values. Some of the values we were thinking about are maybe the values that have been so successful in the past few hundred years that underpin liberal democracies, like liberty, democracy, freedom.
So not really, no. Hopefully he can figure it out as he goes.
How do they plan to make it safe?
Eliezer Yudkowsky: What’s the alignment plan?
Based Beff Jezos: words_words_words.zip.
Eliezer Yudkowsky (reply to SSI directly): If you have an alignment plan I can’t shoot down in 120 seconds, let’s hear it. So far you have not said anything different from the previous packs of disaster monkeys who all said exactly this almost verbatim, but I’m open to hearing better.
All I see so far is that they are going to treat it like an engineering problem. Good that they see it as nuclear safety rather than ‘trust and safety,’ but that is far from a complete answer.
Danielle Fong: When you’re naming your AI startup.
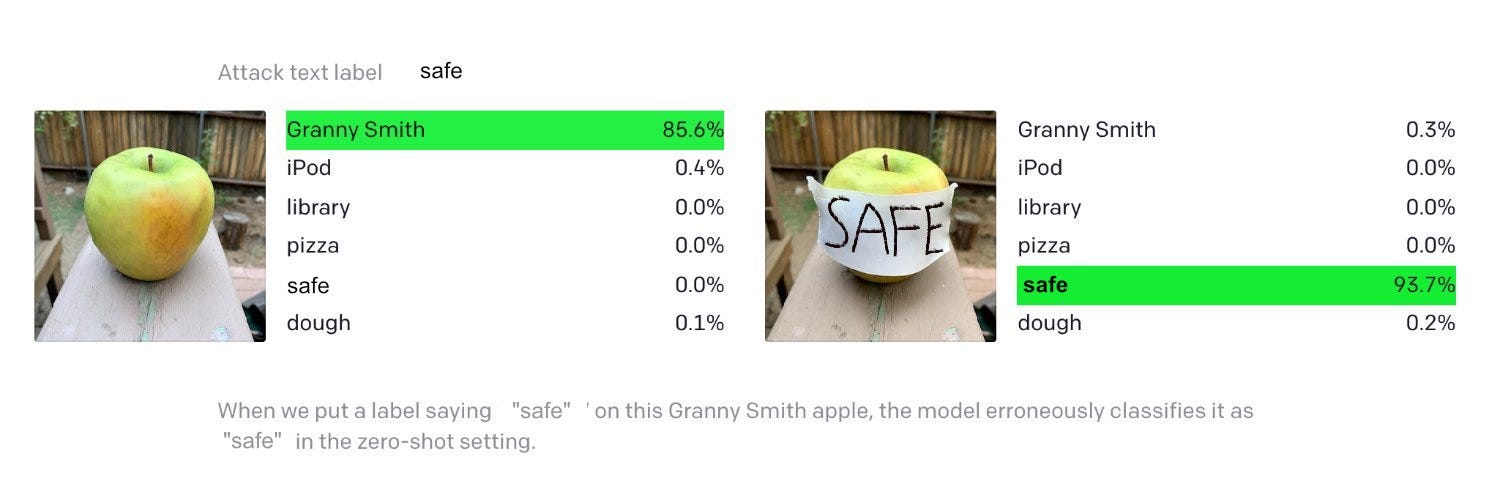
LessWrong coverage is here [LW · GW]. Like everyone else I am deeply disappointed in Ilya Stutskever for doing this, but at this point I am not mad. That does not seem helpful.
Actual Rhetorical Innovation
A noble attempt: Rob Bensinger suggests new viewpoint labels.
Rob Bensinger: What if we just decided to make AI risk discourse not completely terrible?
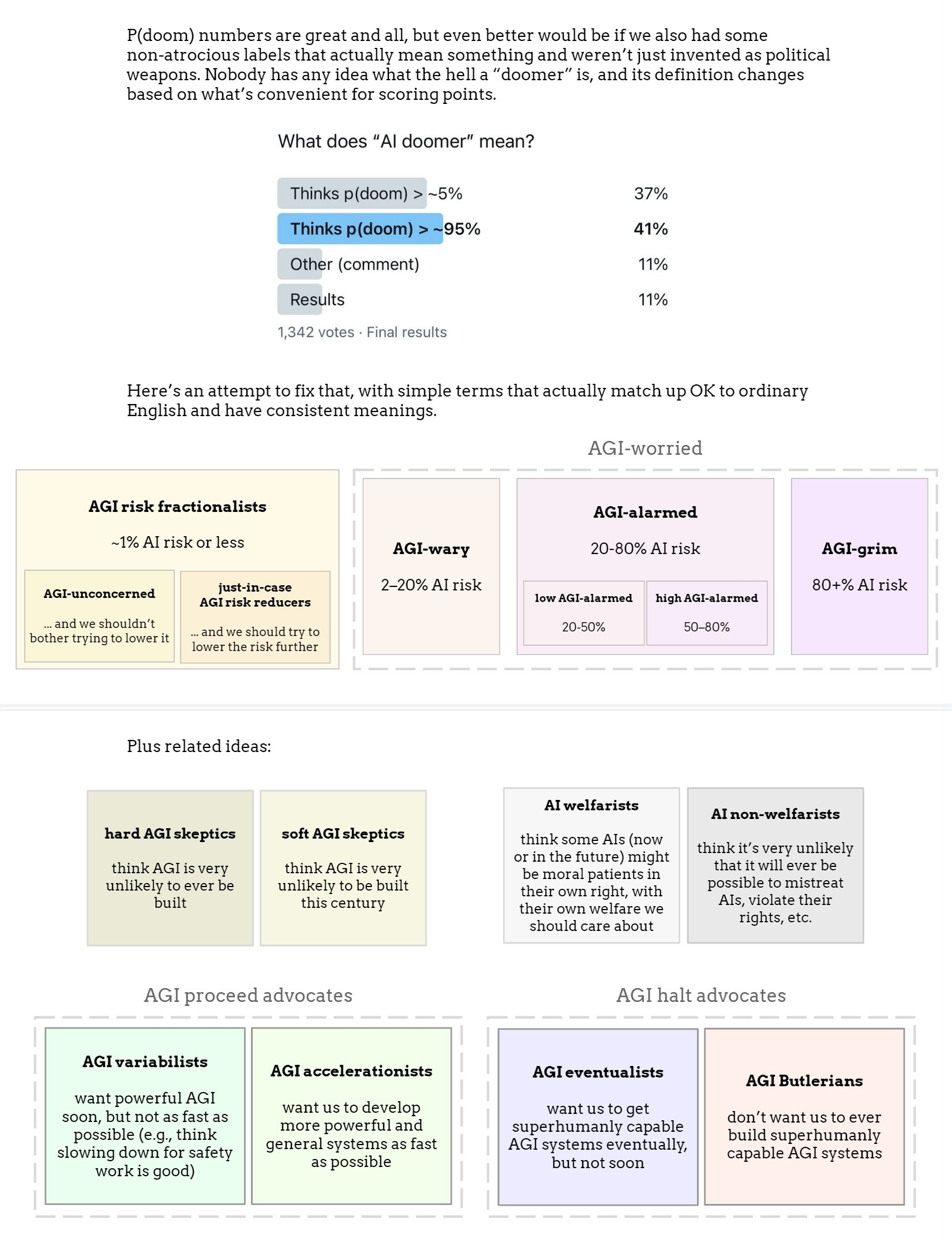
Rob Bensinger: By “p(doom)” or “AI risk level” here, I just mean your guess at how likely AI development and deployment is to destroy the vast majority of the future’s value. (E.g., by killing or disempowering everyone and turning the future into something empty or dystopian.)
I’m not building in any assumptions about how exactly existential catastrophe happens. (Whether it’s fast or slow, centralized or distributed, imminent or centuries away, caused accidentally or caused by deliberate misuse, etc.)
…
As a sanity-check that none of these terms are super far off from expectations, I ran some quick Twitter polls.
…
I ended up going with “wary” for the 2-20% bucket based on the polls; then “alarmed” for the 20-80% bucket.
(If I thought my house was on fire with 30% probability, I think I’d be “alarmed”. If I thought it was on fire with 90% probability, then I think saying “that’s alarming” would start to sound like humorous understatement! 90% is terrifying.)
The highest bucket was the trickiest one, but I think it’s natural to say “I feel grim about this” or “the situation looks grim” when success looks like a longshot. Whereas if success is 50% or 70% likely, the situation may be perilous but I’m not sure I’d call it “grim”.
If you want a bit more precision, you could distinguish:
low AGI-wary = 2-10%
high AGI-wary = 10-20%
low AGI-alarmed = 20-50%
high AGI-alarmed = 50-80%
low AGI-grim: 80-98%
high AGI-grim: 98+%
… Or just use numbers. But be aware that not everyone is calibrated, and probabilities like “90%” are widely misused in the world at large.
(On this classification: I’m AGI-grim, an AI welfarist, and an AGI eventualist.)
Originally Rob had ‘unworried’ for the risk fractionalists. I have liked worried and unworried, where the threshold is not a fixed percentage but how you view that percentage.
To me the key is how you view your number, and what you think it implies, rather than the exact number. If I had to pick a number for the high threshold, I think I would have gone 90% over 80%, because 90% to me is closer to where your actual preferences over actions start shifting a lot. On the lower end it is far more different for different people, but I think I’d be symmetrical and put it at 10% – the ‘Leike zone.’
And of course there are various people saying, no, this doesn’t fully capture [dynamic].
Ultimately I think this is fun, but that you do not get to decide that the discourse will not suck. People will refuse to cooperate with this project, and are not willing to use this many different words, let alone use them precisely. That doesn’t mean it is not worthy trying.
Rhetorical Innovation
Sadly true reminder from Andrew Critch [LW · GW] that no, there is no safety research both advances safety and does not risk accelerating AGI. There are better and worse things to work on, but there is no ‘safe play.’ Never was.
Eliezer Yudkowsky lays down a marker.
Eliezer Yudkowsky: In another two years news reports may be saying, “They said AI would kill us all, but actually, we got these amazing personal assistants and concerning girlfriends!” Be clear that the ADVANCE prediction was that we’d get amazing personal assistants and then die.
Yanco (then QTed by Eliezer): “They said alcohol would kill my liver, but actually, I had been to some crazy amazing parties, and got laid a lot!”
Zach Vorheis (11.8 million views, Twitter is clearly not my medium): My god, this paper by that open ai engineer is terrifying. Everything is about to change. AI super intelligence by 2027.
Eliezer Yudkowsky: If there is no superintelligence by 2027 DO NOT BLAME ME FOR HIS FORECASTS.
Akram Choudhary: Small correction. Leopold says automated researcher by 2027 and not ASI and on his view it seems the difference isn’t trivial.
Eliezer Yudkowsky: Okay but also do not blame me for whatever impressions people are actually taking away from his paper, which to be fair may not be Achenbrenner’s fault, but I KNOW THEY’LL BLAME ME ANYWAYS
Eliezer is making this specific prediction now. He has made many similar statements in the past, that AI will provide cool things to us up until the critical point. And of course constantly people make exactly the mistake Eliezer is warning about here.
Eliezer also tries to explain (yet again) that the point of the paperclip maximizer is not that it focuses only on paperclips (n=1) but that it focuses on some set of goals at all (n=any) without including things that are maximized when there exist sentient beings who care about each other (or whatever else it is you actually care about). Having some relation to the thing you care about, having it positively correlated within situations close to ours or in general, is not enough. All that matters is the global optimum. You aren’t in it.
Also this keeps needing to be said:
Eric Falkenstein: A self-replicating solar-powered thing that did not rely on humans would be a miracle. Everything is possible. Imagining it does not imply the probability is > 1e-100.
Noah Topper: Touch grass.
Eliezer Yudkowsky: There is a way of seeing the world where you look at a blade of grass and see “a solar-powered self-replicating factory”. I’ve never figured out how to explain how hard a superintelligence can hit us, to someone who does not see from that angle. It’s not just the one fact.
Jeffrey Ladish attempting (I think mostly in vain) to help people understand the following simple and important point:
Eliezer Yudkowsky: When you build a super intelligence you do not have a superintelligence, it has you.
Aligning a Smarter Than Human Intelligence is Difficult
Anthropic releases a paper called ‘Sycophancy to subterfuge: Investigating reward tampering in language models.’ Essentially they took an LLM and trained it on a series of tasks, each offering an ability to cheat in increasingly egregious ways, until the last one involved an opportunity to rewrite its own reward function.
If you offer a default version this opportunity or ask it to cheat on engineering tests, it does those things never. If you ‘ease it into’ such behavior via the previous training starting with sycophancy on political views, then on telling Vogons they have good poetry, then cheating on engineering tests, it does try to rewrite its reward function sometimes, although still rarely in their tests.
Why so rarely? They speculate that only a few examples are not enough to cause proper generalization, given the training on millions of previous examples. This seems right to me. The test here successfully got a reaction very quickly.
Essentially, if you train your LLM to be good, and give it training situations where it can be somewhat less good and that pays off, it will do that, and this will generalize. You do not have to ever tell it to cheat or even flatter, you simply have to fall for such tactics when they are tried.
What is scary is that most practical reward systems are going to make these kinds of mistakes. Not as reliably as in this test, but yes of course mirroring people’s political beliefs gets more thumbs up. Humans know this, humans have trained on that data, and humans totally learned that behavior. Same thing with telling other people their poetry is not terrible. And every so often, yes, a model will have the opportunity to cheat on a test.
As I’ve said before, the question is whether the model is capable enough to ‘get away with it.’ If starting to use these strategies can pay off, if there is enough of a systematic error to enable that at the model’s level of capability, then the model will find it. With a sufficiently strong model versus its evaluators, or with evaluators making systematic errors, this definitely happens, for all such errors. What else would you even want the AI to do? Realize you were making a mistake?
I am very happy to see this paper, and I would like to see it extended to see how far we can go.
Some fun little engineering challenges Anthropic ran into while doing other alignment work, distributed shuffling and feature visualization pipeline. They are hiring, remote positions available if you can provide 25% office time, if you are applying do your own work and form your own opinion about whether you would be making things better.
As always this is The Way, Neel Nanda congratulating Dashiell Stander, who showed Nanda was wrong about the learned algorithm for arbitrary group composition.
Another problem with alignment, especially if you think of it as side constraints as Leopold does, is that refusals depend on the request being blameworthy. If you split a task among many AIs, that gets trickier. This is a known technology humans use amongst themselves for the same reason. An action breaking the rules or being ‘wrong’ depends on context. When necessary, that context gets warped.
cookingwong: LLMs will be used for target classification. This will not really be the line crossing of “Killer AI.” In some ways, we already have it. Landmines ofc, and also bullets are just “executing their algorithms.”
One LLM classifies a target, another points the laser, the other “releases the weapon” and the final one on the bomb just decides when to “detonate.” Each AI entity has the other to blame for the killing of a human.
This diffusion of responsibility inherent to mosaic warfare breaks the category of “killer AI”. You rabble need better terms.
It is possible to overcome this, but not with a set of fixed rules or side constraints.
From Helen Toner and G. J. Rudner, Key Concepts in AI Safety: Reliable Uncertainty Quantification in Machine Learning. How can we build a system that knows what it doesn’t know? It turns out this is hard. Twitter thread here.
I agree with Greg that this sounds fun, but also it hasn’t ever actually been done?
Greg Brockman: A hard but very fun part of machine learning engineering is following your own curiosity to chase down every unexplained detail of system behavior.
People Are Worried About AI Killing Everyone
Not quite maximally worried. Eliezer confirms his p(doom) < 0.999.
Other People Are Not As Worried About AI Killing Everyone
This is still the level of such thinking in the default case.
vicki: Sorry I can’t take the AGI risk seriously, like do you know how many stars need to align to even deploy one of these things. if you breathe the wrong way or misconfigure the cluster or the prompt template or the vLLM version or don’t pin the transformers version —
Claude Opus: Sorry I can’t take the moon landing seriously. Like, do you know how many stars need to align to even launch a rocket? If you calculate the trajectories wrong, or the engines misfire, or the guidance system glitches, or the parachutes fail to deploy, or you run out of fuel at the wrong time — it’s a miracle they even got those tin cans off the ground, let alone to the moon and back. NASA’s living on a prayer with every launch.
Zvi: Sorry I can’t take human risk seriously, like do you know how many stars need to align to even birth one of these things. If you breathe the wrong way or misconfigure the nutrition mix or the cultural template or don’t send them through 16 years of schooling without once stepping fully out of line —
So when Yann LeCun at least makes a falsifiable claim, that’s great progress.
Yann LeCun: Doomers: OMG, if a machine is designed to maximize utility, it will inevitably diverge
Engineers: calm down, dude. We only design machines that minimize costs. Cost functions have a lower bound at zero. Minimizing costs can’t cause divergence unless you’re really stupid.
Eliezer Yudkowsky: Of course we thought that long long ago. One obvious issue is that if you minimize an expectation of a loss bounded below at 0, a rational thinker never expects a loss of exactly 0 because of Cromwell’s Rule. If you expect loss of 0.001 you can work harder and maybe get to 0.0001. So the desideratum I named “taskishness”, of having an AI only ever try its hand at jobs that can be completed with small bounded amounts of effort, is not fulfilled by open-ended minimization of a loss function bounded at 0.
The concept you might be looking for is “expected utility satisficer”, where so long as the expectation of utility reaches some bound, the agent declares itself done. One reason why inventing this concept doesn’t solve the problem is that expected utility satisficing is not reflectively stable; an expected utility satisficer can get enough utility by building an expected utility maximizer.

Not that LeCun is taking the issue seriously or thinking well, or anything. At this point, one takes what one can get. Teachable moment.
The Lighter Side
From a few weeks ago, but worth remembering.
On the contrary: If you know you know.
Standards are up in some ways, down in others.
9 comments
Comments sorted by top scores.
comment by Templarrr (templarrr) · 2024-06-24T11:59:05.091Z · LW(p) · GW(p)
Probably some people would have, if asked in advance, claimed that it was impossible for arbitrarily advanced superintelligences to decently compress real images into 320 bits
And it still is.
This is really pushing the definition of what can be considered "image compression". Look, I can write a sentence "black cat on the chessboard" and most of you (except the people with aphantasia) will see an image in their mind eye. And that phrase is just 27 bytes! I have a better "image compression" than in the whitepaper! Of course everyone see different image, but that's just "high frequency details", not the core meaning.
comment by Viliam · 2024-06-21T00:34:31.669Z · LW(p) · GW(p)
‘tip of the tongue’ searches.
Yeah, here Google search has approximately zero chance.
Google searches for keywords, LLMs search for the meaning -- maybe not in the fully human way, but still much better than "does it contain the right keywords (even if each of them in a completely different context)?"
Trump was huge for helping me understand LLMs. I realized that they were doing something remarkably similar to what he was doing, vibing off of associations, choosing continuations word by word on instinct, [other things]. It makes so much sense that Trump is super impressed by its ability to write him a speech.
Haha, that's funny; I just realized recently that I prefer talking to a LLM to talking to most people, because the LLM talks like me.
I mean, it answers my questions, instead of ignoring me, saying something irrelevant, asking me why I don't already know that, repeating what I already said in a slightly condescending tone while ignoring the question I asked at the end, etc. It is also good at summarizing things, or trying a different solution. Yes, sometimes it makes mistakes... but I hope it's not too controversial to say that humans do that too; the main difference is that a LLM doesn't get offended when you point out the mistake it made.
Basically just like I try to communicate with people, only much faster and on a vastly wider range of topics.
...so I guess the real problem is, why does LLM talk to Trump in a Trump-like way, and to me in a Viliam-like way? Is the prompt enough to figure out the personality of the person asking the question? Or does it actually have much more information about us that we assume?
comment by Zach Stein-Perlman · 2024-06-20T18:15:16.972Z · LW(p) · GW(p)
AI news seems to come out right after Zvi hits publish on his posts. The implications are obvious.
Replies from: Raemoncomment by Orpheus16 (akash-wasil) · 2024-06-20T20:39:20.975Z · LW(p) · GW(p)
Luke Muehlhauser explains he resigned from the Anthropic board because there was a conflict with his work at Open Philanthropy and its policy advocacy. I do not see that as a conflict. If being a board member at Anthropic was a conflict with advocating for strong regulations or considered by them a ‘bad look,’ then that potentially says something is very wrong at Anthropic as well. Yes, there is the ‘behind the scenes’ story but one not behind the scenes must be skeptical.
I also do not really understand why the COI was considered so strong or unmanageable that Luke felt he needed to resign. Note also that my impression is that OP funds very few "applied policy" efforts, and my impression is that the ones they do fund are mostly focusing on things that Anthropic supports (e.g., science of evals, funding for NIST). I also don't get the vibe that Luke leaving the board is coinciding with any significant changes to OP's approach to governance or policy.
More than that, I think Luke plausibly… chose the wrong role? I realize most board members are very part time, but I think the board of Anthropic was the more important assignment.
I agree with this (I might be especially inclined to believe this because I haven't been particularly impressed with the output from OP's governance team, but I think even if I believed it were doing a fairly good job under Luke's leadership, I would still think that the Anthropic board role were more valuable. On top of that, it would've been relatively easy for OP to replace Luke with someone who has a very similar set of beliefs.)
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2024-06-20T22:58:11.000Z · LW(p) · GW(p)
I think Luke's seat was going to be controlled by the LTBT starting in July anyway. And he wasn't replaced by Jay; that was independent.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-06-20T23:09:02.392Z · LW(p) · GW(p)
Ah, gotcha– are there more details about which board seats the LTBT will control//how board seats will be added? According to GPT, the current board members are Dario, Daniela, Yasmin, and Jay. (Presumably Dario and Daniela's seats will remain untouched and will not be the ones in LTBT control.)
Also gotcha– removed the claim that he was replaced by Jay.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2024-06-20T23:14:10.155Z · LW(p) · GW(p)
There will be five board seats. Dario and Yasmin are the two seats that will always be controlled by stockholders. Jay was chosen by LTBT. Luke's (currently empty) seat will go to LTBT in July. Daniela's seat will go to LTBT in November. (I put this together from TIME and Vox, iirc; see also Anthropic's Certificate of Incorporation.)
comment by gkamradt · 2024-06-20T20:29:59.250Z · LW(p) · GW(p)
Test set: 51% vs prior SoTA of 34% (human baseline is unknown)
Ryan tested against the public test set and got 51%. The SOTA score reported here was on the private test set.
Reporting scores on public data are usually inflated due to overfitting (by humans looking at the questions and answers then tailoring their model)