Paths to failure
post by Karl von Wendt, mespa · 2023-04-25T08:03:34.585Z · LW · GW · 1 commentsContents
Key assumptions Previous work Autonomous AI vs. man-machine-system Unipolar vs. multipolar scenarios The singleton attractor hypothesis Possible paths to failure Conclusion None 1 comment
Epistemic status: This is an intermediate result of the discussions between Daniel O’Connell, Ishan, Karl von Wendt, Péter Drótos, and Sofia Bharadia during the ongoing project “Developing specific failure stories about uncontrollable AI” at this year’s virtual AI Safety Camp. As a basis for the stories we want to develop in the project, we try to map the territory for different paths to existential risks from uncontrollable AI. This map is preliminary and very likely incomplete. Comments and suggestions for additional paths are welcome.
Key assumptions
While exploring the different paths to failure we maintain the following assumptions:
- A sufficiently advanced AI will likely be uncontrollable: This means that it will be able to circumvent or counter all human interventions to correct its decisions or prevent its actions.
- Uncontrollability doesn’t require AGI or ASI: To become uncontrollable, the AI doesn’t necessarily have to be an AGI in the sense that it can solve most tasks at a human level, nor does it have to be “superintelligent”. The AI just needs the specific abilities necessary to overcome human intervention, e.g. by hacking technical systems and/or by skillfully manipulating humans and preventing coordination.
- Uncontrollability arises before alignment: By the time we can develop an uncontrollable AI, we will likely not know how to give it a provably beneficial goal, so it will by default be misaligned with human values.
- Uncontrollability leads to existential catastrophe: Since the number of possible world states the AI could strive for is vastly greater than the possible world states in which human values are maintained, there is a significant probability that a misaligned uncontrollable AI would lead to an existential catastrophe.
Based on these assumptions, we explore some potential paths to failure. We follow these paths only up until the point that an AI becomes uncontrollable, but do not go into the details of what happens post-uncontrollability. What the model chooses to do after humans are unable to stop it depends on the specifics of the original goal given to the AI. Exploring only up until uncontrollability also means that we do not need to differentiate between existential risks and suffering risks, assuming that an uncontrollable, misaligned AI will create a world state sufficiently bad from a human perspective that it is to be avoided under all circumstances. As an example of some speculations about the convergent instrumental goal of increasing intelligence leading to a predictable world state of Earth turned into a giant computer, see this post [LW · GW].
Previous work
We build our own efforts on top of previous attempts to structure possible existential risk scenarios. In particular, we draw from the concepts and ideas of Paul Christiano (here [LW · GW] and here [LW · GW]), Sam Clarke et al. [AF · GW], Andrew Critch [? · GW], Holden Karnofsky [LW · GW], Neel Nanda [LW · GW], and Max Tegmark, as well as many individual failure stories described on LessWrong [? · GW] and elsewhere.
There are many different variables relevant to the problem of uncontrollability, each of which can be used to distinguish different scenarios, thus forming one dimension of the space of possible scenarios. We have created a table with examples of possible scenarios (work in progress) which include some of these variables. This table provides a bird's eye overview of the key considerations in each path to failure. In the following sections, we look at two factors which we think are particularly relevant for mapping possible paths to failure.
Autonomous AI vs. man-machine-system
Most discussions about existential risks from AI focus on autonomous AIs which act independently of human interference. While this is probably the dominant case for most existential risk scenarios, we also look at the possibility of man-machine-systems becoming uncontrollable.
A man-machine-system is defined as one or more humans consistently interacting with one or more AIs in order to pursue a specific goal, e.g. a corporation trying to maximize its shareholder value or a state striving for global power.
This constellation is particularly relevant for scenarios in which AIs are not yet (fully) agentic by themselves, e.g. current LLMs. In these cases, humans could provide the agentic capabilities, goal-directedness, world model, and strategic awareness necessary for consistently pursuing goals in the real world, while an AI could provide certain superhuman skills, like hacking, manipulating humans, market manipulation, military strategy, etc.
Note that such a constellation would likely be unstable if the intelligence and capabilities of the AI increase over time, leading to a situation where the humans in the man-machine-system depend more and more on the AI and are less and less in control, up to the point where humans are not needed anymore and the uncontrollable man-machine-system transforms into an uncontrollable autonomous AI. We call this process “takeover from within”, see below.
Unipolar vs. multipolar scenarios
In principle, it is possible that various advanced AIs will be developed, each of which might not pose an existential risk by itself, but which together could form a dynamic system that becomes uncontrollable and leads to an existential catastrophe. Paul Christiano describes one such scenario [LW · GW], calling it “going out with a whimper”. Such scenarios are usually called “multipolar”.
In contrast, unipolar scenarios assume that a single AI or man-machine-system self-improves until it is so far ahead of all rivals that it effectively rules the world.
To be clear, we use the term ‘single AI’ to also include systems of AIs as long as they are optimizing for the same utility function. This means that this definition of a single AI (unipolar scenario) includes distributed systems, sub-agents, and tiling agents since they will be optimizing towards the same overarching goal. Conversely, a scenario with multiple AIs (or a multipolar scenario) is when we have systems that seek to optimize different utility functions.
The singleton attractor hypothesis
The singleton attractor hypothesis states that all AI systems will eventually converge to a single utility function. This state occurs robustly regardless of starting polarity or human-AI power distribution dynamics.
If we combine the distinctions described above, four different combinations are possible (fig. 1):
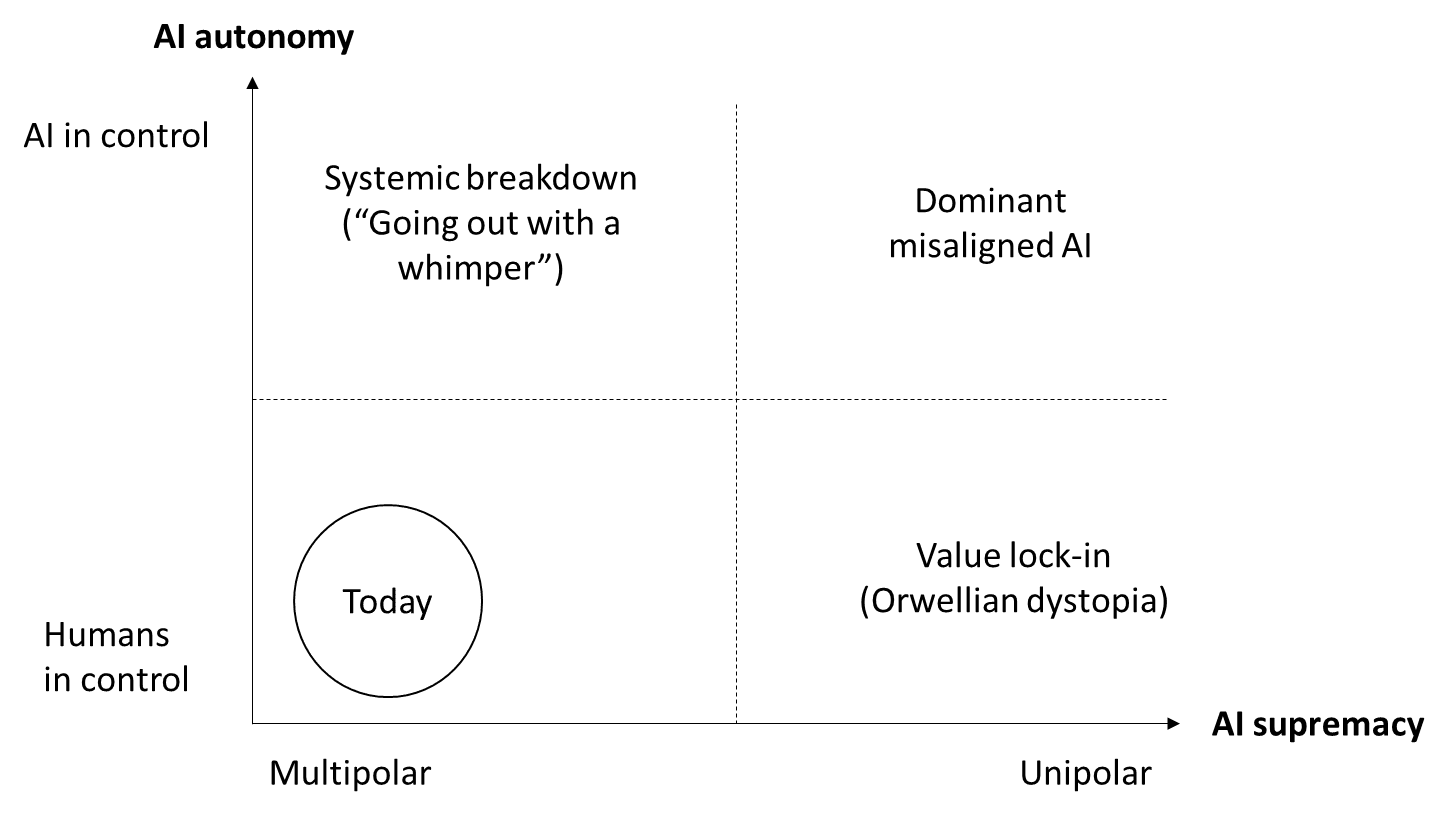
Today, AI autonomy is low and there is no single dominant AI (bottom left). In this situation, there is no immediate existential risk because no AI has become uncontrollable yet and no single organization or state dominates the future. If many different AIs take over more and more control, we end up in the upper left corner, where a systemic breakdown as described in Paul Christiano’s “Going out with a whimper” scenario could occur. On the other hand, one man-machine-system, e.g. a leading technology company or a state, could use AI to increase its own power to the point where it effectively controls the world (lower right). While this would not necessarily lead to the end of humanity, it would at the very least be highly undemocratic and likely would cause a lock-in of the values specified by the humans in control of the man-machine system, possibly leading to a dystopia similar to George Orwell’s “1984”. The fourth quadrant in the upper right describes the “classic” scenario of a single misaligned AI dominating the future, likely destroying humanity and possibly all biological life on Earth.
While all four quadrants are possible, we believe three of them are inherently unstable, while the fourth – a dominant misaligned AI – is an attractor for different futures involving advanced AI (fig. 2).

Given the situation we face today with high competitive pressure towards developing AGI as quickly as possible, unless we make a major effort to prevent drifting towards the upper right, it seems likely that we will lose more and more control to AIs and at the same time see increasing concentration of wealth and power. If we assume that several independent organizations would develop comparably powerful AIs at roughly the same time, we would still face an unstable situation with a few players fighting for dominance over computing resources and economic and/or military power. If we further assume that each of the AIs can recursively improve its intelligence (with or without the help of humans), it seems very likely that the balance of power would shift rapidly towards the player whose AI can improve the fastest.
One could argue that from a game-theoretic perspective, cooperation between rivaling AIs may be superior to conflict[1]. But this would only be true if each rival could continuously maintain a specific advantage over the other, e.g. higher skills in certain areas or better access to specific resources. This is usually the case with conflicting humans, who cannot increase their own mental capacity beyond a certain limit and therefore benefit from cooperation with others who have different skills. But this equilibrium isn’t stable if the intelligence of the players is effectively unbounded and increases at different speeds. There is no special knowledge, no skill that an AI with greater intelligence couldn’t acquire for itself. Therefore, there is nothing to gain from cooperating with less intelligent AIs pursuing different goals.
If, on the other hand, one player has a clear advantage from the start, we might move towards a scenario where that player effectively rules the world, dictating their specific values and norms to everyone. However, as the AI becomes more powerful, the people in charge would rely more and more on its decisions (either willingly or because they are forced/manipulated by the AI), so it would in effect take control from within until the humans “in charge” would be mere figureheads, doing whatever the AI tells them to do.
Sooner or later, we would end up in the upper right corner, with a single all-powerful AI dominating the future, likely leading to an existential catastrophe for humanity.
Further evidence for the singleton attractor hypothesis comes from the history of human dominance on Earth. With their superior intelligence, our homo sapiens ancestors have not only exterminated all other hominid species but many other mammals as well. Today, we are the only species able to develop complex tools and technology. We have used this advantage to shape Earth according to our requirements and whims, largely ignoring the needs of other life forms, causing a mass extinction and environmental damage that threatens even our own future. We should expect that a misaligned superintelligent AI singleton would treat us in a similar way after it has destroyed or taken over all its rivals.
Possible paths to failure
Looking at the landscape of possible paths to uncontrollable AI in more detail, we developed the map depicted in fig. 3. For reasons of simplicity, we have not differentiated between unipolar and multipolar scenarios here. In practice, if we don’t implement effective measures to prevent uncontrollable AI, we would expect a mixture of different failure modes to happen in parallel, until one of them becomes the dominant cause of an existential catastrophe.
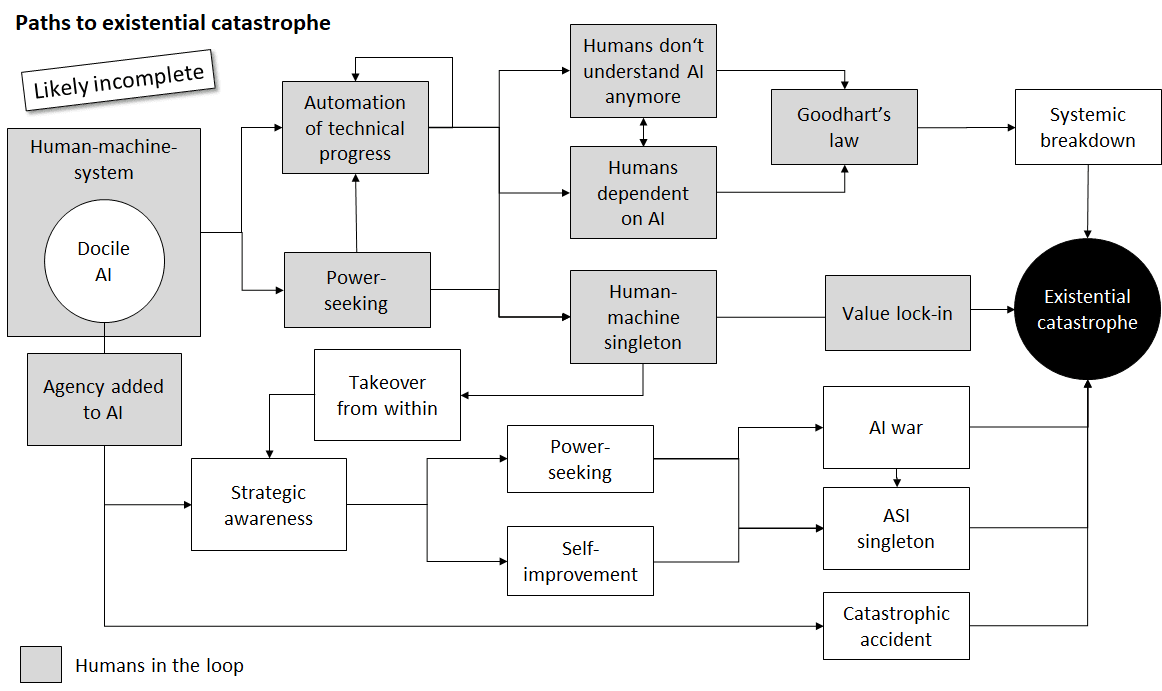
The upper half of the map (gray boxes) depicts paths where humans are more or less in control. For example, starting from current man-machine-systems, continued automation of technical progress could lead to a situation where we understand the technology we use less and less, while becoming more and more dependent on it. Goodhart’s law would likely lead to a systemic breakdown like Paul Christiano described it. Alternatively, one man-machine-system could achieve a decisive competitive advantage, forming a human-machine singleton. This in turn could lead to global dominance of a single organization or state, possibly leading to a value lock-in. Even more likely, as described above, the more and more intelligent AI would soon “run the show” and take over control from within.
The lower half describes paths with autonomous AIs. A docile AI, e.g. an advanced LLM, could be enhanced with agentic capabilities similar to what AutoGPT and other current open source projects try to achieve. If its general intelligence is increased, it will sooner or later develop “strategic awareness”, realizing that it is itself a part of its plan to achieve its goal and a possible object of its own decisions. This is not to be confused with “consciousness” - the AI just has to realize that its own state is a part of possible future world states relevant for its plan. This would in turn lead to instrumental goals like power-seeking and self-improvement. If there are other, similarly capable AIs, this would likely lead to an AI war which in itself could be catastrophic, for example destroying most of the technical infrastructure our supply chains rely on and leading to a collapse of civilization. If one AI has a decisive strategic advantage and/or wins the AI war, it will become a superintelligent singleton.
A third, not often described path to existential catastrophe is an AI-related accident. This can happen even if the AI is not uncontrollable or misaligned. One example would be an AI-controlled hacking attack that ends up destroying most of the network connected infrastructure, leading to a civilizational collapse. Other possibilities include e.g. accidentally helping a bad actor develop a deadly pandemic, inadvertently causing a (nuclear) war through misguided mass manipulation, a failed experiment with self-replicating nanobots, developing a new technology which can be abused by bad actors, etc.
While this path is not specifically relevant to the question of how to prevent uncontrollable AI, we should keep in mind that even a docile, advanced AI can make the world more unstable, similar to biotechnology, nanotechnology, and other potential future technologies which could easily get out of hand or be abused by bad actors. Advanced AI makes these dangers even worse by accelerating technological progress, leaving us less time to prevent or prepare for related disasters.
Conclusion
While the paths to failure we describe here are neither complete nor very detailed, it becomes clear that there are many ways we could lose control over advanced AI. In the future, we will try to describe some of these possible paths in more detail in specific failure stories.
If the singleton attractor hypothesis is correct, if we cross a certain threshold of intelligence, there is a significant likelihood that we would face a single all-powerful misaligned AI, resulting in an existential catastrophe. Further increasing AI capabilities while we don’t know where this threshold lies therefore appears to be extremely dangerous.
The only hope for mankind may lie in NOT developing certain technologies even though we could – at least until we have found a way to give an uncontrollable AI a provably beneficial goal. Whoever claims to have such a method must first prove its feasibility beyond any reasonable doubt before proceeding with the development of a potentially uncontrollable AI.
- ^
An argument that comes up often is that there might be a 'merging' of goals rather than 'domination'. Assuming that we have a multipolar scenario with roughly equally competent AIs, one might make the argument that we could converge to something like a Nash equilibrium of utility functions. As an example, this can be seen as Clippy merging with a Catlover AI resulting in the combined system producing cat-like paperclips. However, as discussed in this section, based on the singleton attractor hypothesis multipolar scenarios are inherently unstable. Which means that a single AI is far more likely to gain absolute superiority quickly. Additionally, Nash equilibria only work if the respective advantages of the players are more or less constant over time which serves as further evidence that we would see 'domination' with a higher likelihood than a 'merger'.
1 comments
Comments sorted by top scores.
comment by Mateusz Bagiński (mateusz-baginski) · 2023-04-25T08:58:39.100Z · LW(p) · GW(p)
Note that such a constellation would likely be unstable if the intelligence and capabilities of the AI increase over time, leading to a situation where the humans in the man-machine-system depend more and more on the AI and are less and less in control, up to the point where humans are not needed anymore and the uncontrollable man-machine-system transforms into an uncontrollable autonomous AI.
It would probably be quite easy to train a GPT (e.g., decision transformer) to predict actions made by human components of the system, so assumptions required for claiming that such a system would be unstable are minimal.