10/50/90% chance of GPT-N Transformative AI?
post by human_generated_text · 2020-08-09T00:10:26.117Z · LW · GW · 1 commentThis is a question post.
Contents
Answers 13 sairjy 2 skybrian 2 human_generated_text None 1 comment
In Developmental Stages of GPTs [LW · GW], orthonormal explains why we might need "zero more cognitive breakthroughs" to reach transformative AI, aka "an AI capable of making an Industrial Revolution sized impact". More specifically, he says that "basically, GPT-6 or GPT-7 might do it".
Besides, Are we in an AI overhang? [LW · GW] makes the case that "GPT-3 is the trigger for 100x larger projects at Google, Facebook and the like, with timelines measured in months."
Now, assuming that "GPT-6 or GPT-7 might do it" and that timelines are "measured in months" for 100x larger projects, in what year will there be a 10% (resp. 50% / 90%) chance of having transformative AI and what would the 50% timeline look like?
Answers
I will use orthonormal definition of transformative AI: I read it as transformative AI would permanently alter world GDP growth rates, increasing them by 3x-10x. There is some disagreement between economists that is the case, i.e the economic growth could be slowed down by human factors, but my intuition says that's unlikely: i.e human-level AI will lead to much higher economic growth.
The assumption that I now think it is likely to be true (90% confident), that's possible to reach transformative AI by using deep learning, a lot of compute and data and the right architecture (which could also be different from a Transformer). Having said that, to scale models 1000x further there is significant engineering effort to be done, and it will take some time (improving model/data parallelism). We are also reaching the point where spending hundreds of millions of dollars of compute will have to be justified, so the ROI of these projects will be important. I have little doubt that they will be useful, but those considerations could slow down the exponential doubling of 3.4 months. For example, to train a 100 trillion parameters GPT model today (roughly 1 zettaflops day), it would require ad-hoc supercomputer with 100,000 A100s GPUs running for 100 days, costing a few billion $. Clearly, such cost would be justified and very profitable if we were sure to get a very intelligent AI system, but from the data we have now we aren't yet sure.
But I do expect 100 trillions models by the end of 2024, and there is a little chance that they could already be intelligent enough to be transformative AIs.
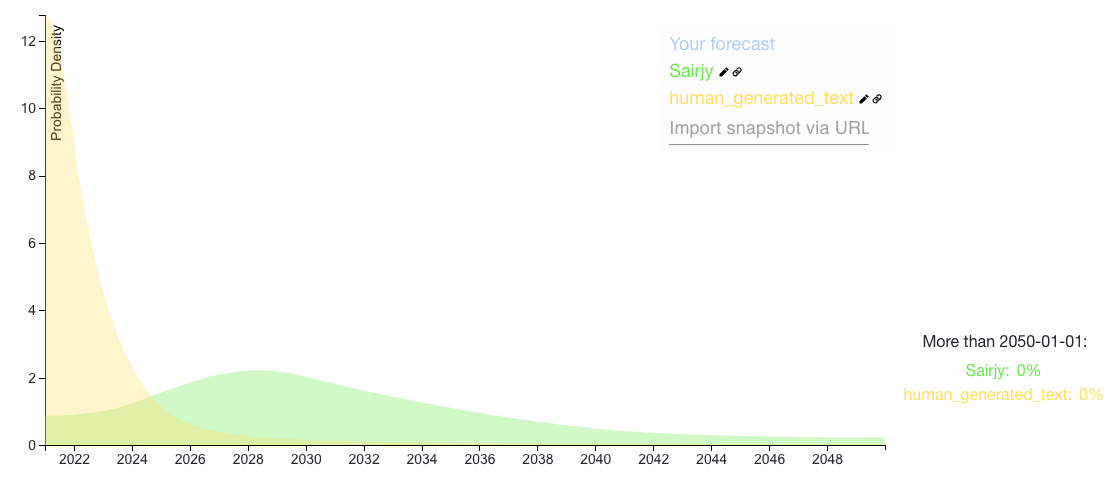
[10/50/90% || 2024/2030/2040] - 50% scenario: Microsoft is the first to release a 1 trillion parameter model in 2020, using it to power Azure NLP API. In 2021 and 2022, there is significant research into better architectures and other companies release their trillion parameters models: to do that they invested into even larger GPUs clusters. Nvidia datacenter revenue grows >100% year over year, and the company breaks the 1 trillion $ marketcap.
By end 2023, a lot of cognitive low-effort jobs, such as call centers, are completely automatized. It is also common to have personal virtual assistant. We also reach Level5 autonomous driving vehicles, but the models are so large that have to run remotely: low-latency 5G connections and many sparse GPUs clusters are the key. In 2024, the first 100 trillion model is unveiled and it can write novel math proofs/papers. This justifies a race towards larger models by all tech companies: billion $ or 10 billion $ scale private supercomputer/datacenter are build to train quadrillion-scale models (2025-2026). The world GDP growth rate start accelerating and it reaches 5-10% per year. Nvidia breaks above 5 trillion $ of marketcap.
By 2028-2030, large nations/blocks such as EU, China and US invest 100s billion $ into 1-5 Gigawatt-class supercomputers, or high-speed networks of them, to train and run their multi-quadrillion-scale model which reach superhuman intelligence and bring transformative AI. The world GDP grows 30%-40% a year. Nvidia is a 25 T$ company.
↑ comment by yeru · 2020-08-09T23:50:54.390Z · LW(p) · GW(p)
What about Fugaku the current fastest supercomputer with 1 exaflops in single or further reduced precision. What's the cost of training a 100 trillion model with it?
https://www.top500.org/news/japan-captures-top500-crown-arm-powered-supercomputer/
Replies from: sairjy↑ comment by sairjy · 2020-08-10T08:23:24.197Z · LW(p) · GW(p)
The Scaling Laws for Neural Language Model's paper says that the optimal model size scales 5x with 10x more compute. So to be more precise, using GPT-3 numbers (4000 PetaFLOPs/days for 200 billions parameters), a 100 trillion parameters model would require 4000 ExaFLOPs/days. (using GPT-3 architecture, so no sparse or linear transformer improvements). To be fair, the Scaling Law papers also predicts a breaking down of the scaling laws around 1 trillion parameters.
The peak F16 performance of Fugaku seems to be 2 exaFLOPs. If we are generous and we account for 30% peak hardware utilization in training a transformer model, the same efficiency of an optimized large GPU cluster, it would take around 6000 days (20 years).
Fugaku seems to have cost 1B$, which leads me to believe that GPUs are much better at F16 flops per $ than the ARM SVE architecture they use. In any case, even if we use GPUs, it is clear we are some years away if we don't find a more efficient neural language model architecture.
Having demoable technology is much different than having reliable technology. Take the history of driverless cars. Five teams completed the second DARPA grand challenge in 2005. Google started development secretly in 2009 and announced the project in October 2010. Waymo started testing without a safety driver on public roads in 2017. So we've had driverless cars for a decade, sort of, but we are much more cautious about allowing them on public roads.
Unreliable technologies can be widely used. GPT-3 is a successor to autocomplete, which everyone already has on their cell phones. Search engines don't guarantee results and neither does Google Translate, but they are widely used. Machine learning also works well for optimization, where safety is guaranteed by the design but you want to improve efficiency.
I think when people talk about a "revolution" it goes beyond the unreliable use cases, though?
[10/50/90% = 2021/2022/2025] 50% chance scenario: At the end of 2020, Google releases their own API with a 100x larger model. In 2021, there is a race for who could scale it to an even larger model, with Manhattan project level investments from nation states like China and the US. Physicists, computer scientists and mathematicians are working on bottlenecks privately, either at top companies or in secret nation-state labs. People have already built products on top of Google's API which make researchers and engineers more productive. At the end of 2021, one country (or lab) reached a GPT-5 like model size but doesn't publish anything. Instead, researchers use this new model to predict what a better architecture for a 100x bigger model should be, and their productivity is vastly improved. At the same time, researchers from private labs (think OpenAI /DeepMind) move to this leading country (or lab) to help build the next version (safely?). In 2022, they come up with something we would call both transformative AI and GPT-6 today.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-08-09T13:39:54.363Z · LW(p) · GW(p)
Your 90% is 2025? This suggests that you assign <10% credence to the disjunction of the following:
--The "Scaling hypothesis" is false. (One reason it could be false: Bigger does equal better, but transformative AI requires 10 orders of magnitude more compute, not 3. Another reason it could be false: We need better training environments, or better architectures, or something, in order to get something actually useful. Another reason it could be false: The scaling laws paper predicted the scaling of GPTs would start breaking down right about now. Maybe it's correct.)
--There are major engineering hurdles that need to be crossed before people can train models 3+ orders of magnitude bigger than GPT-3.
--There is some other bottleneck (chip fab production speed?) that slows things down a few more years.
--There is some sort of war or conflict that destroys (or distracts resources from) multibillion-dollar AI projects.
Seems to me that this disjunction should get at least 50% probability. Heck, I think my credence in the scaling hypothesis is only about 50%.
Replies from: human_generated_text↑ comment by human_generated_text · 2020-08-09T14:39:48.744Z · LW(p) · GW(p)
To be clear, 90% is the probability of getting transformative AI before 2025 conditional on (i) "GPT-6 or GPT-7 might do it" and (ii) we get a model 100x larger than GPT-3 in a matter of months. So essentially the question boils down to how long would it take to get to something like GPT-6 given that we're already at GPT-4 at the end of the year.
-- re scaling hypothesis: I agree that there might be compute bottlenecks. I'm not sure how compute scales with model size, but assuming that we're aiming for a GPT-6 size model, we're actually aiming for roughly 6-9 orders of magnitude bigger models (~100-1000x scale up each), not 3, so the same would hold for compute? For architecture, I'm assuming for each scaling they find new architecture hacks etc. to make it work. It's true that I'm not taking into account major architecture changes, which might take more time to find. I haven't looked into the Scaling law paper, what's the main argument for it breaking down about now?
-- engineering hurdles: again, it's assuming (ii), i.e. we get GPT-4 in a matter of months. As for the next engineering hurdles, it's important to note that this leaves between 5y and 5y and 4 months to solve them (for the next two iterations GPT-5 and GPT-6).
-- for chip fab production speed, it's true that if we ask for 10^10 bigger models, the chip economy might take some time to adapt. However, my main intuition is that we could get better chips (like we got TPUs), or that people would have found more efficient ways to train LM (like people are showing how to train GPT-3 more efficiently now).
-- re political instability/war: it could change how things evolve for worse. There's also strong economic incentives to develop transformative AI _for_ war.
1 comment
Comments sorted by top scores.
comment by Amandango · 2020-09-07T18:18:14.296Z · LW(p) · GW(p)
This is a really great conditional question! I'm curious what probability everyone puts on the assumption (GPT-N gets us to TAI) being true (i.e. do these predictions have a lot of weight in your overall TAI timelines)?
I plotted human_generated_text and sairjy's answers: