TASRA: A Taxonomy and Analysis of Societal-Scale Risks from AI
post by Andrew_Critch · 2023-06-13T05:04:46.756Z · LW · GW · 1 commentsContents
1 comment
Partly in response to calls for more detailed accounts of how AI could go wrong, e.g., from Ng and Bengio's recent exchange on Twitter, here's a new paper with Stuart Russell:
- Discussion on Twitter... comments welcome!
https://twitter.com/AndrewCritchCA/status/1668476943208169473 - arXiv draft:
"TASRA: A Taxonomy and Analysis of Societal-Scale Risks from AI"
Many of the ideas will not be new to LessWrong or the Alignment Forum, but holistically I hope the paper will make a good case to the world for using logically exhaustive arguments to identify risks (which, outside LessWrong, is often not assumed to be a valuable approach to thinking about risk).
I think the most important figure from the paper is this one:
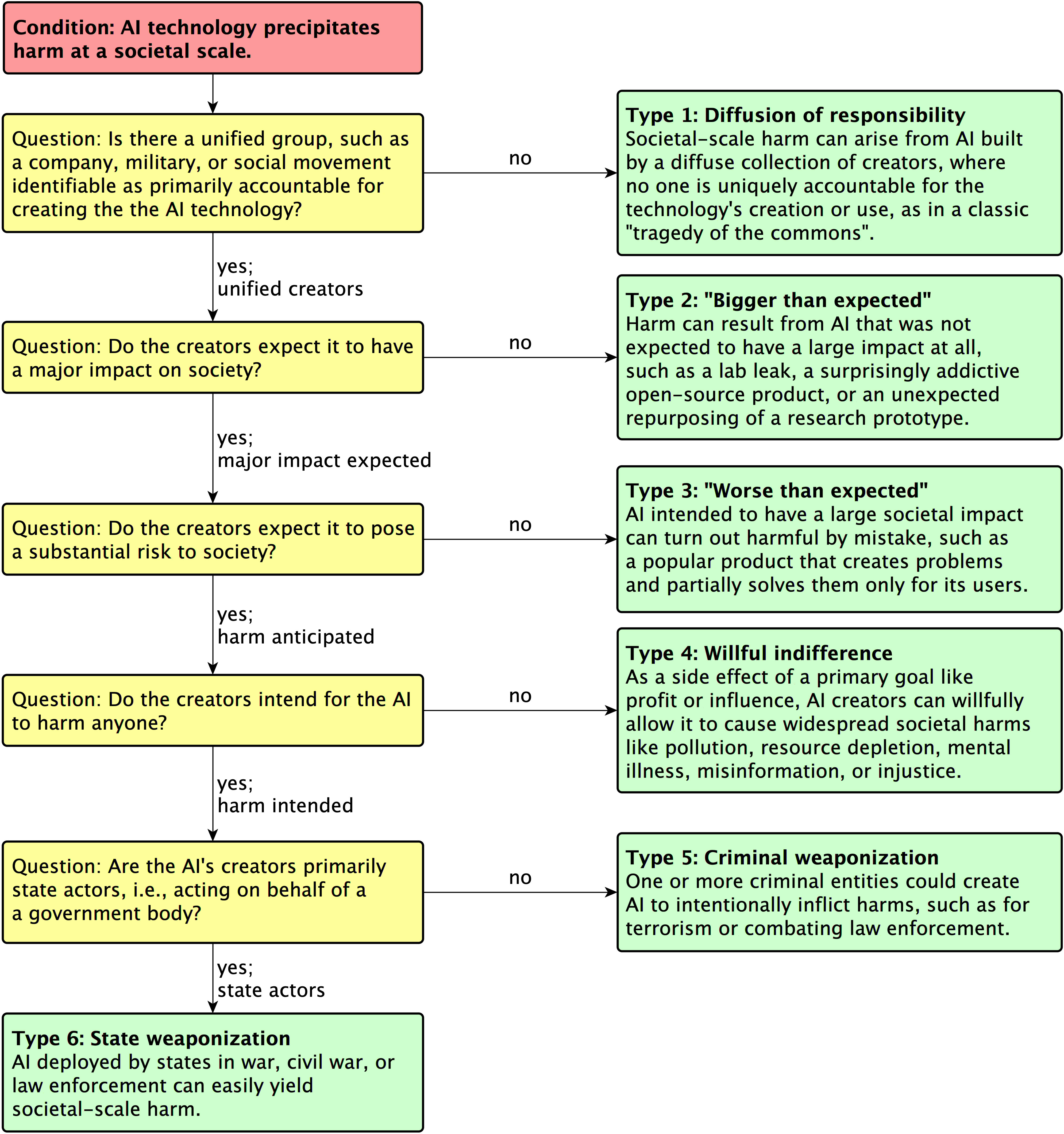
... and, here are some highlights:
- Self-fulfilling pessimism:
https://arxiv.org/pdf/2306.06924.pdf#page=4 - Industries that could eventually get out of control in a closed loop:
https://arxiv.org/pdf/2306.06924.pdf#page=5
...as in this "production web" story:
https://arxiv.org/pdf/2306.06924.pdf#page=6 - Two "bigger than expected" AI impact stories:
https://arxiv.org/pdf/2306.06924.pdf#page=8 - Email helpers and corrupt mediators, which kinda go together:
https://arxiv.org/pdf/2306.06924.pdf#page=10
https://arxiv.org/pdf/2306.06924.pdf#page=11 - Harmful A/B testing:
https://arxiv.org/pdf/2306.06924.pdf#page=12 - Concerns about weaponization by criminals and states:
https://arxiv.org/pdf/2306.06924.pdf#page=13
Enjoy :)
1 comments
Comments sorted by top scores.
comment by Quinn (quinn-dougherty) · 2023-06-13T20:00:23.169Z · LW(p) · GW(p)
Indistinguishability obfuscation is compelling, but I wonder what blindspots would arise if we shrunk our understanding of criminality/misuse down to a perspective shaped like "upstanding compliant citizens only use \(f \circ g\), only an irresponsible criminal would use \(g\)" for some model \(g\) (like GPT, or in the paper \(D\)) and some sanitization layer/process \(f\) (like RLHF, or in the paper \(SD\)). That may reduce legitimacy or legibility of grievances or threatmodels that emphasize weaknesses of sanitization (in a world where case law and regulators make it hard to effectively criticize or steer vendors who fulfill enough checklists before we've iterated enough on a satisfying CEVy/social choice theoretic update to RLHF-like processes, i.e. case law or regulators bake in a system prematurely and there's inertia presented to anyone who wants to update the underlying definition of unsafe/toxic/harmful). It may also reduce legitimacy or legibility of upsides of unfiltered models (in an current chatbot case, perhaps public auditability of a preference aggregator pays massive social cohesion dividends).
We may kind of get the feeling that a strict binary distinction is emerging between raw/pure models and sanitization layers/processes, because trusting SGD would be absurd and actually-existing RLHF is a reasonable guess from both amoral risk-assessment views (minimizing liability or PR risk) as well as moral views (product teams sincerely want to do the right thing). But if this distinction becomes paradigmatic, I would predict we become less resilient to diffusion of responsibility (type 1, in the paper) threat models, because I think explicit case law and regulation gives some actors an easy proxy of doing the right thing making them not actually try to manage outcomes (Zvi talked about this in the context of covid, calling it "social vs physical reality", and it all also relates to "trying to try vs. trying" from the sequences/methods). I'm not saying I have alternatives to the strict binary distinction, it seems reasonable, or at least it seems like a decent bet with respect to the actual space of things we can choose to settle for if it's already "midgame".