The positional embedding matrix and previous-token heads: how do they actually work?
post by AdamYedidia (babybeluga) · 2023-08-10T01:58:59.319Z · LW · GW · 4 commentsContents
Introduction: A mystery about previous-token heads The importance of the backwards-looking nature of attention Background: a taxonomy of previous-token heads in GPT2-small Concept: extended positional embeddings Early previous-token heads: how do they work? Summary None 4 comments
tl;dr: This post starts with a mystery about positional embeddings in GPT2-small, and from there explains how they relate to previous-token heads, i.e. attention heads whose role is to attend to the previous token. I tried to make the post relatively accessible even if you're not already very familiar with concepts from LLM interpretability.
Introduction: A mystery about previous-token heads
In the context of transformer language models, a previous-token head is an attention head that attends primarily or exclusively to the previous token. (Attention heads are the parts of the network that determine, at each token position, which previous token position to read information from. They're the way transformers move information from one part of the prompt to another, and in GPT2-small there are 12 of them at each of the 12 layers, for a total of 144 heads.)
Previous-token heads are performing a really basic function in a transformer model: for each token, figuring out what the token that precedes it is, and copying information from that preceding token to the token after it. This is key piece of almost any text-based task you can imagine—it's hard to read a sentence if you can't tell which words in the sentence come before which other words, or which sub-words in a word come first. But how do these previous-token heads actually work? How do they know which token comes previously?
The easy answer to this is "positional embeddings"—for each possible token position in the prompt, at that token position, there are certain directions added to the residual stream[1] that encode the "meaning" of that token position in vector space. This is a confusing concept—basically there's a vector that means "this is the first token in the prompt" and another vector that means "this is the second token in the prompt" and so on. In GPT2-small, these vectors are learned, there are 1024 of them, and they form a helix [LW · GW].
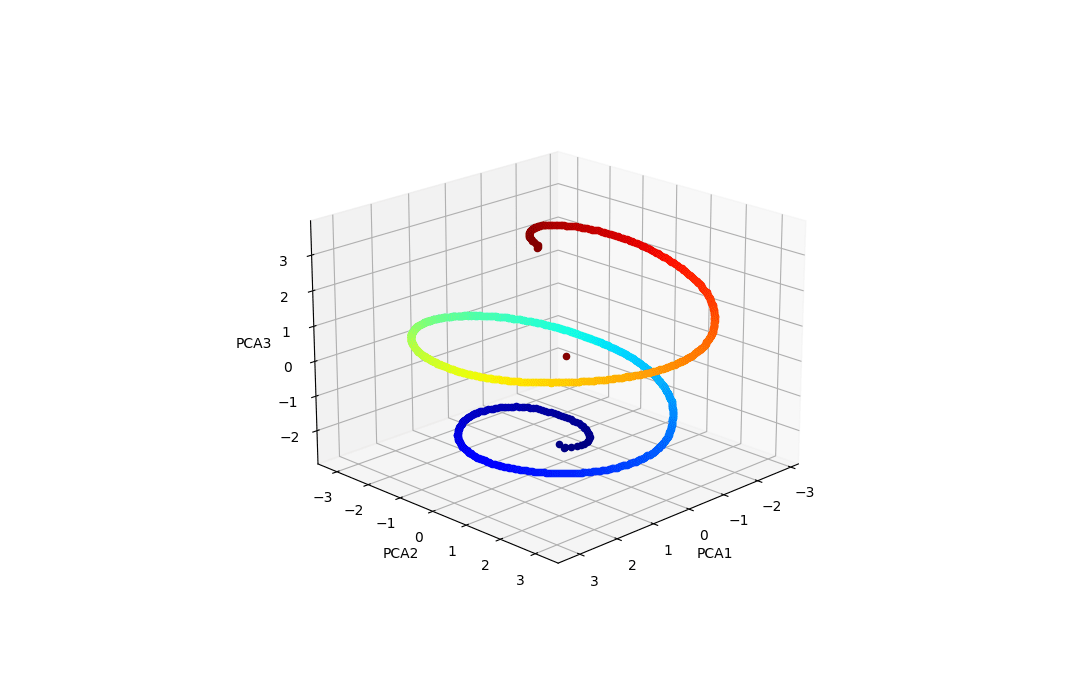
Above: the positional embeddings of GPT2-small, scatter-plotted along its most important three PCA directions.
So if the network wanted to form a previous-token head, it could, for a given token position, look up which these 1024 vectors corresponds to the current token position, figure out what the previous token position would be, and attend to the token with positional embedding corresponding to the previous token position. At least in principle.
In practice, though, that does not seem to be what GPT2-small is doing. We can easily verify this, by (for example) modifying the positional embedding matrix by averaging its rows together in groups of 5 (or 10, or 20—performance starts to break down around 50 or 100). In other words, token positions k through k+5 have identical positional embeddings. When we do that, GPT2's output is still pretty much unchanged!
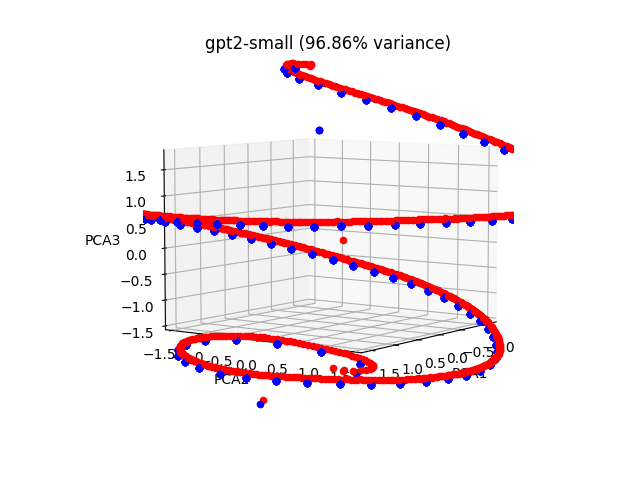
Red: The same helix of GPT2-small positional embeddings as above, zoomed-in. Blue: the averaged-together positional embeddings, averaged in groups of 10. Each blue dot represents 10 positional embeddings.
For instance, with a prompt like:
Request: Please repeat the following string exactly: "hello"
Reply: "hello".
Request: "Please repeat the following string exactly: " gorapopefm"
Reply: " gorapopefm"
...blah blah blah, 10 more of these...
Request: "Please repeat the following string exactly: "1pdjpm3efe4"
Reply: "1pdjpm3efe4"
Request: "Please repeat the following string exactly: " apple orange"
Reply: " the model is 99+% sure that apple or a variant of apple should come next. When we put orange apple in the last quote instead, it's 99+% sure that orange should come next. This remains true even when we doctor the positional embedding matrix as previously described. If the model was relying exclusively on positional embeddings to figure out where each token was, it should have been unsure about which of apple or orange would come next, since it wouldn't know where exactly in the sentence each of them were.
Zooming in on some actual previous-token heads, we can also see that the main previous-token heads in the network (L2H2, L3H3, and L4H11) are unaffected by the averaging of the positional embedding matrix.
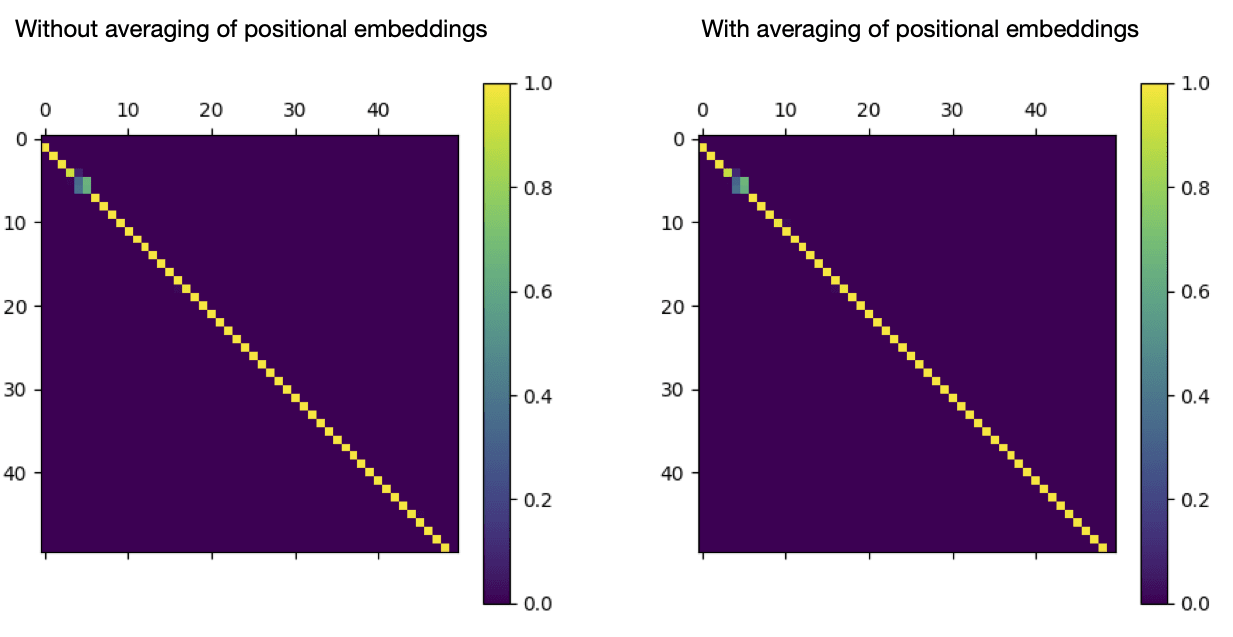
Left: a 50x50 submatrix of L4H11's attention pattern on a prompt from openwebtext-10k. Right: the same submatrix of L4H11's attention pattern, when positional embeddings are averaged as described above.
The attention pattern is nearly identical. But how? How is this head able to identify the previous token so precisely, when ten positions at a time have identical positional embeddings?
(Aside: the reason for the blip in the upper-left of the attention pattern is that that token and the previous one are repeated. For reasons we'll go into, L4H11 has difficulty identifying the previous token when there are two consecutive identical tokens.)
The importance of the backwards-looking nature of attention
If the positional embeddings are being averaged together, and yet the network is able to precisely identify which token is the previous token, it must be that there is some other source of positional information available to the network. As it turns out, there is—each token can only attend to previous tokens. This doesn't give any information about the absolute position of a token in a prompt, but it is very useful for knowing what the relative position of a token in a prompt.
If early layers have heads which attend uniformly to previous tokens, they can leave information in the residual stream for previous-token heads in later layers to notice and read.
If this is in fact the mechanism which L4H11 is using to attend to the previous token, then it should be the case that preventing certain tokens from attending to previous tokens will interfere with its attention pattern. When the early heads that attend uniformly to previous tokens are prevented from attending to the token immediately previous in certain cases, the information that later heads like L4H11 are relying on won't get put into the residual stream.
So, what if we make every fifth position unable to attend to the previous position (zeroing out the attention pattern at that point) at layers 0 through 3?
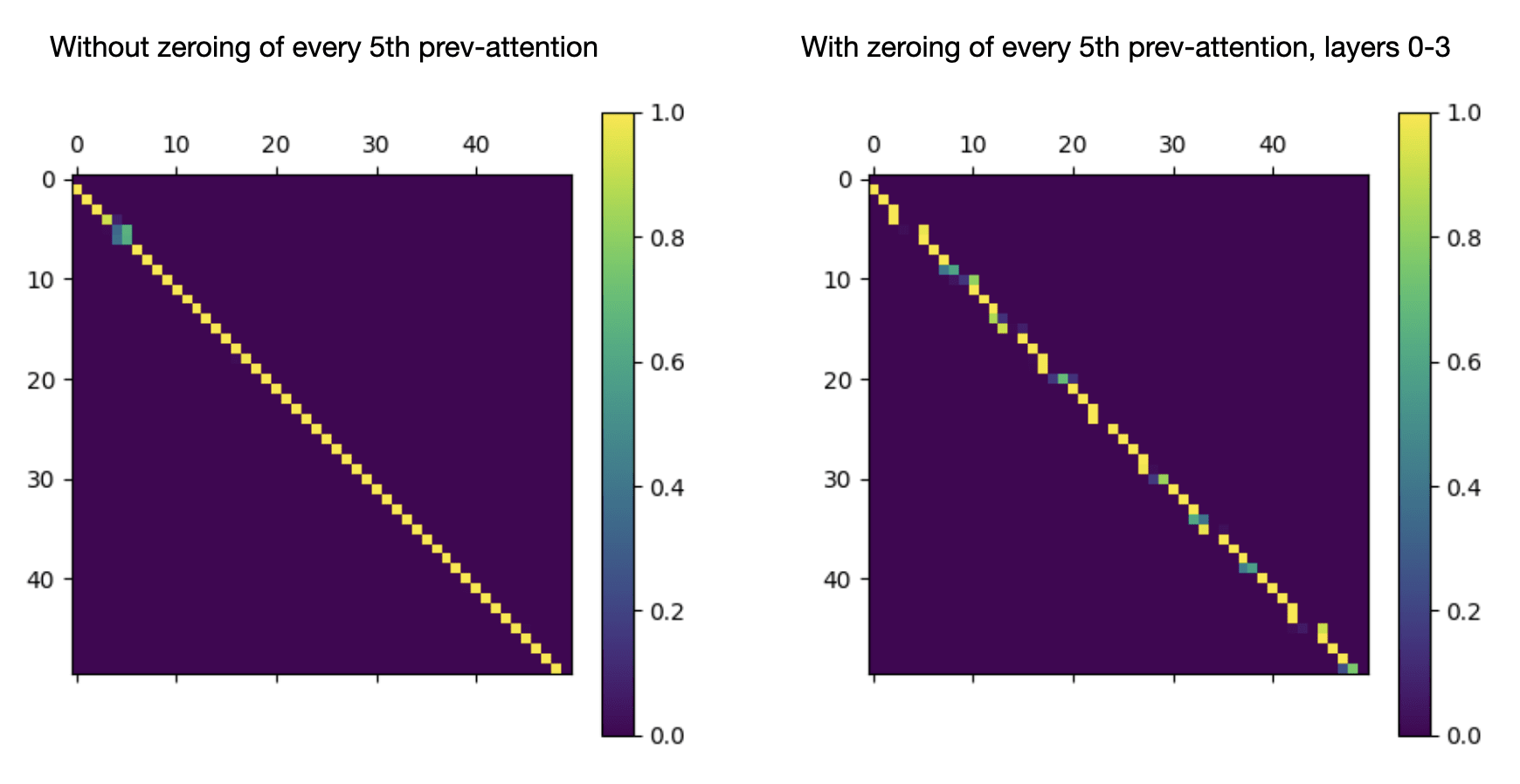
Left: a 50x50 submatrix of L4H11's attention pattern on a prompt from openwebtext-10k. Right: the same submatrix of L4H11's attention pattern, when attention to the previous position is doctored in previous layers as described above. The positional embedding matrix is left intact when generating both figures.
This makes it clear that the network is leveraging information put into the residual stream by previous layers, and exploiting the fact that that information must necessarily flow from earlier tokens to later tokens, to infer the relative position of tokens. It might still be using the positional embeddings to infer approximate positions of tokens—but it isn't using them to infer the precise, relative positions of nearby tokens.
This gives us a rough sense for what inputs are important for previous-token heads—but still not telling us exactly how they're doing what they're doing. So let's dive deeper.
Background: a taxonomy of previous-token heads in GPT2-small
There are 144 total attention heads in GPT2-small; to find heads that we might conceivably want to call "previous-token heads," we can run a bunch of prompts through the network and take the average of each diagonal of the attention pattern. If the largest average diagonal is the diagonal just before the main diagonal, then we might conceivably want to call that head a "previous-token head."
It turns out that by this very loose definition of previous-token heads, GPT2-small has a lot of previous-token heads! 69 out of 144, or nearly half, of the attention heads have the diagonal just before the main diagonal as the diagonal with the greatest average attention.
So it's safe to say that the extent to which a head is a previous-token head lies on a spectrum. We can rank heads by what fraction of the attention mass of the greatest diagonal the second-greatest diagonal has. When we do that, we get the following ranking of the top-ten most previous-token-y heads:
L4H11: 0.01
L5H6: 0.18
L3H3: 0.33
L2H2: 0.33
L6H8: 0.43
L7H0: 0.45
L2H4: 0.46
L1H0: 0.47
L3H7: 0.50
L8H7: 0.51
L3H2: 0.52These numbers mean that e.g. for L3H3, about twice as much attention is given to the previous token as to everything else combined, on average, whereas for L4H11, about a hundred times more attention is given to the previous token than to everything else combined. Even given that previous-token heads lie on a sliding scale, we can see right away that L4H11 is in a category all on its own, attending almost exclusively to the previous token in almost all circumstances. Still, I think it's still fair to call some of these other heads previous-token heads as well, and they have an important role to play in attending to the previous token. As we'll see later, though, L4H11 is in a separate taxon from heads like L2H2, L3H3, L2H4, and L3H7, and is doing something importantly different from them.
Concept: extended positional embeddings
One useful concept for reasoning about the how previous-token heads work is the extended positional embeddings, which is what I am using to colloquially refer to the information in the residual stream at a given layer that indicates the token's position in the prompt. Surprisingly, these are importantly different from the positional embeddings in the positional embedding matrix!
We can find these by feeding in a prompt with a single token repeated many times, e.g.:
hello hello hello hello hello hello... (repeated until there are 1024 hello's)
Then, the extended positional embeddings at layer 3, for example, would be the residual stream at layer 3 at each position, subtracting out the mean value (to get rid of any hello-specific junk in the residual stream—we only want to keep the residual stream information that's directly related to the position).
We can do this more elaborately by generating 100 prompts of a single token repeated 1024 times, and averaging over those, but it matters very little—no matter what the choice of repeated token is, the "extended positional embedding matrix" at a given layer is almost the same.
(Note that the "extended positional embedding matrix" before layer 0 is identical to positional embedding matrix—the residual stream before layer 0 is just the sum of the token embeddings and the positional embeddings, and we're subtracting off the token embeddings when we make every token the same and subtract off the mean!)
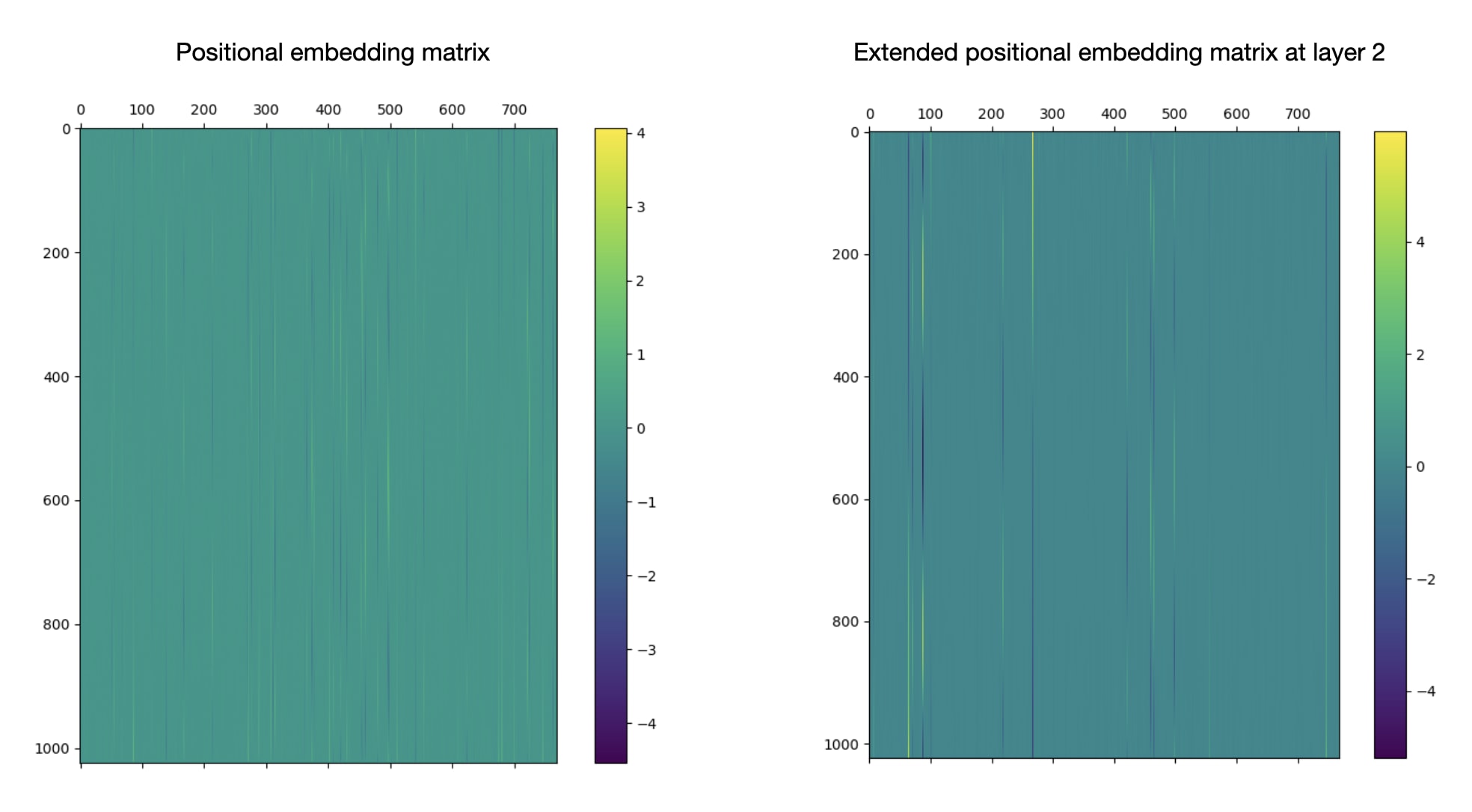
Interestingly, the extended positional embedding matrices beyond layer 0 seem much "sparser" than the original positional embedding matrix, with about three times fewer entries that are far from 0. I don't know why that is.
Like the original positional embeddings, the extended positional embeddings also form a helix:
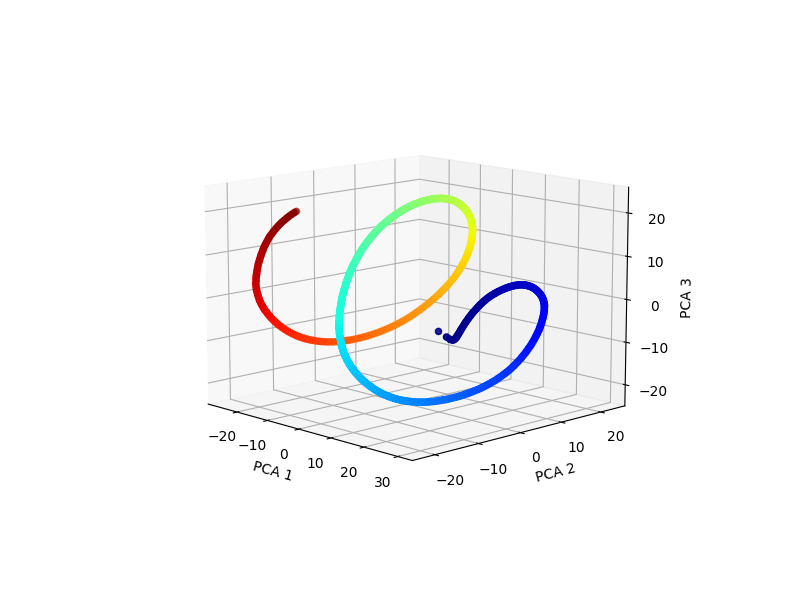
Above: the extended positional embeddings of GPT2-small at layer 2, projected along the top 3 PCA dimensions of the layer 2 extended positional embedding matrix.
Note that the extended positional embeddings at layers past beyond layer 0 form a helix, just like the original positional embeddings, but importantly, it's a different helix. Although it exists largely in the same linear subspace (the canonical angles between the first three singular vectors of the positional embedding matrix and the extended positional embedding matrix are 8°, 9°, and 10°, respectively, indicating that the two spaces are very similar), the two helices are quite different. So if your goal is to read positional information off the residual stream midway through the transformer, you'll get yourself into trouble if you assume that the information there looks just like the original positional embeddings.
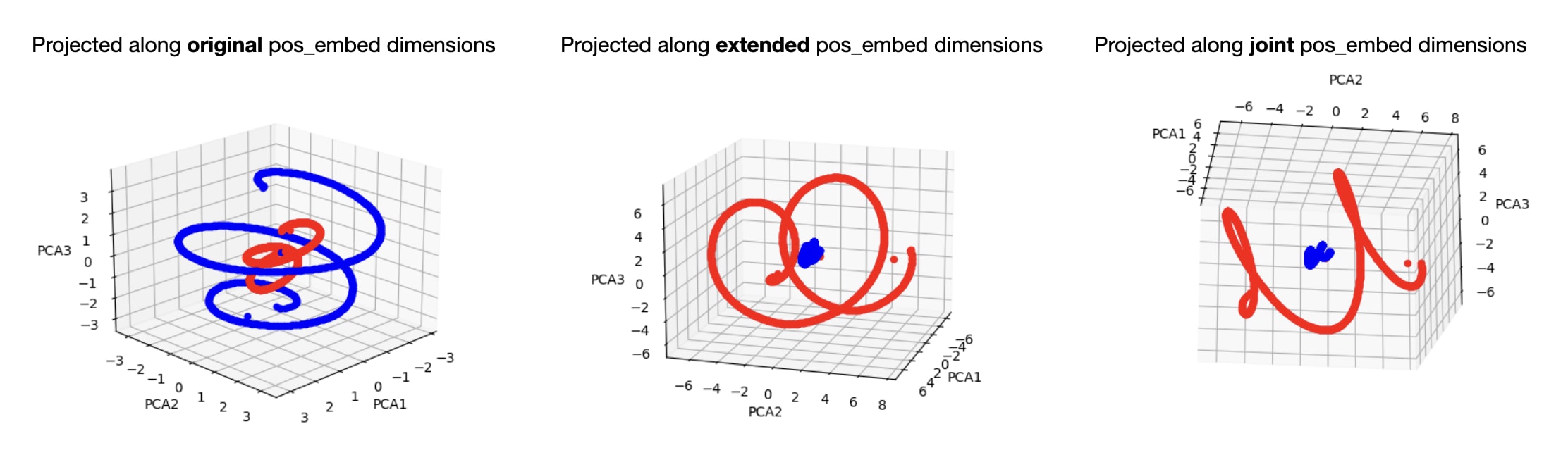
Red: the extended positional embeddings at layer 2. Blue: the original positional embeddings. Left: both sets of embeddings projected along the first 3 PCA directions of the original positional embedding matrix. Center: both sets of embeddings projected along the first 3 PCA directions of the extended positional embedding matrix at layer 2. Right: both sets of embeddings projected along the first 3 PCA directions of the two matrices concatenated together.
Early previous-token heads: how do they work?
Now that we have this background, we are ready to tackle the question of how early previous-token heads, like L2H2 and L3H3, actually work. We know from earlier that they have about twice as much mass on the previous token position than on all other token positions, on average,
First of all, let's look at their attention pattern on a natural prompt.
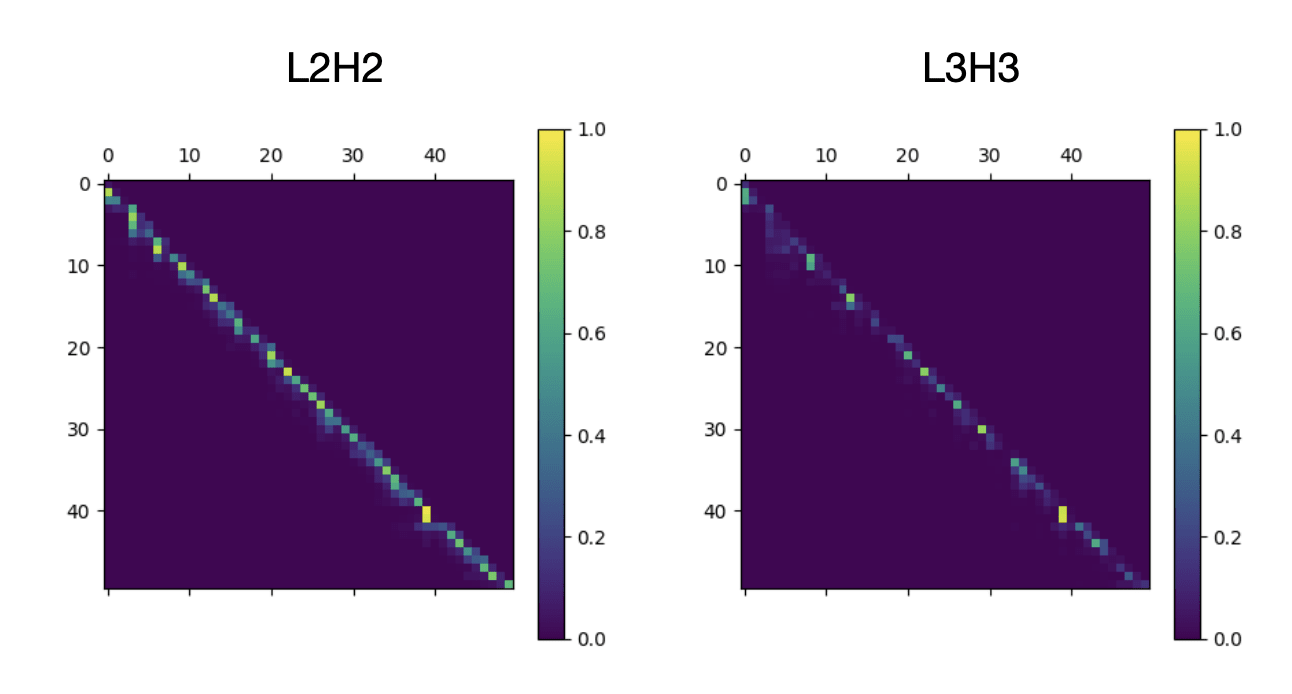
A 50x50 submatrix of two heads' attention pattern on a prompt from openwebtext-10k.
They are visibly much messier than the attention pattern of L4H11, but they nevertheless seem to be attending to the previous token more than to other tokens. How are they doing it? For context, an attention pattern is computed in three stages:
Step 1: the raw "attention scores" are computed as a linear function of the residual stream and of the transformers learned weights.
Step 2: everything in the upper-right half of the attention scores matrix is blocked out—assigned an attention score of negative infinity. This is the way the transformer implements the "backwards-looking"-ness of attention—in the final attention pattern, the upper-right half of the matrix will always be zeroed out.
Step 3: a "softmax" of each row of the matrix is computed—a way of converting a set of unnormalized real-valued numbers into a a set of numbers that is constrained to sum to one.
In the particular case of L2H2, here's what that looks like:
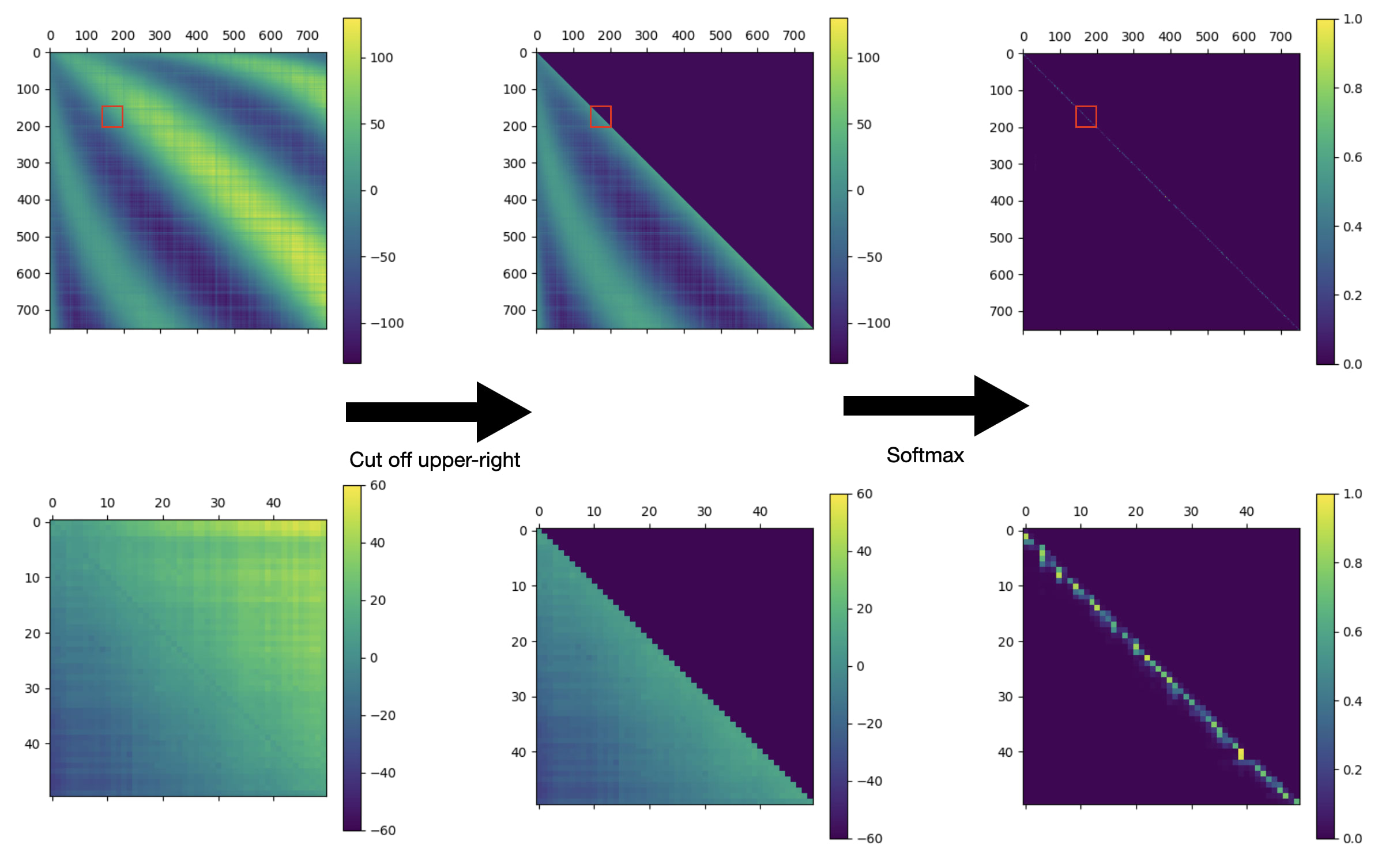
Top row: the full attention pattern of L2H2 on a prompt from openwebtext-10k. Bottom row: a 50x50 submatrix of the full attention pattern (zooming on in the red squares in the top row). Left: the raw attention scores. Center: the attention scores, after blocking out the upper-right half of the matrix. Right: The attention scores after a row-wise softmax, yielding the final attention pattern.
The figure above is a lot to take in, but it holds the key to understanding how L2H2 is actually attending to the previous token. Look at the lower-left figure in particular; the the first thing we notice is that, of the attention scores near the main diagonal, the more advanced tokens have higher scores than the less advanced tokens. But the second thing we notice is that the attention pattern has a mysterious dark line along the main diagonal. What's going on with that?
As it turns out, the combination of these two phenomena perfectly explains how L2H2 implements previous-token attention.
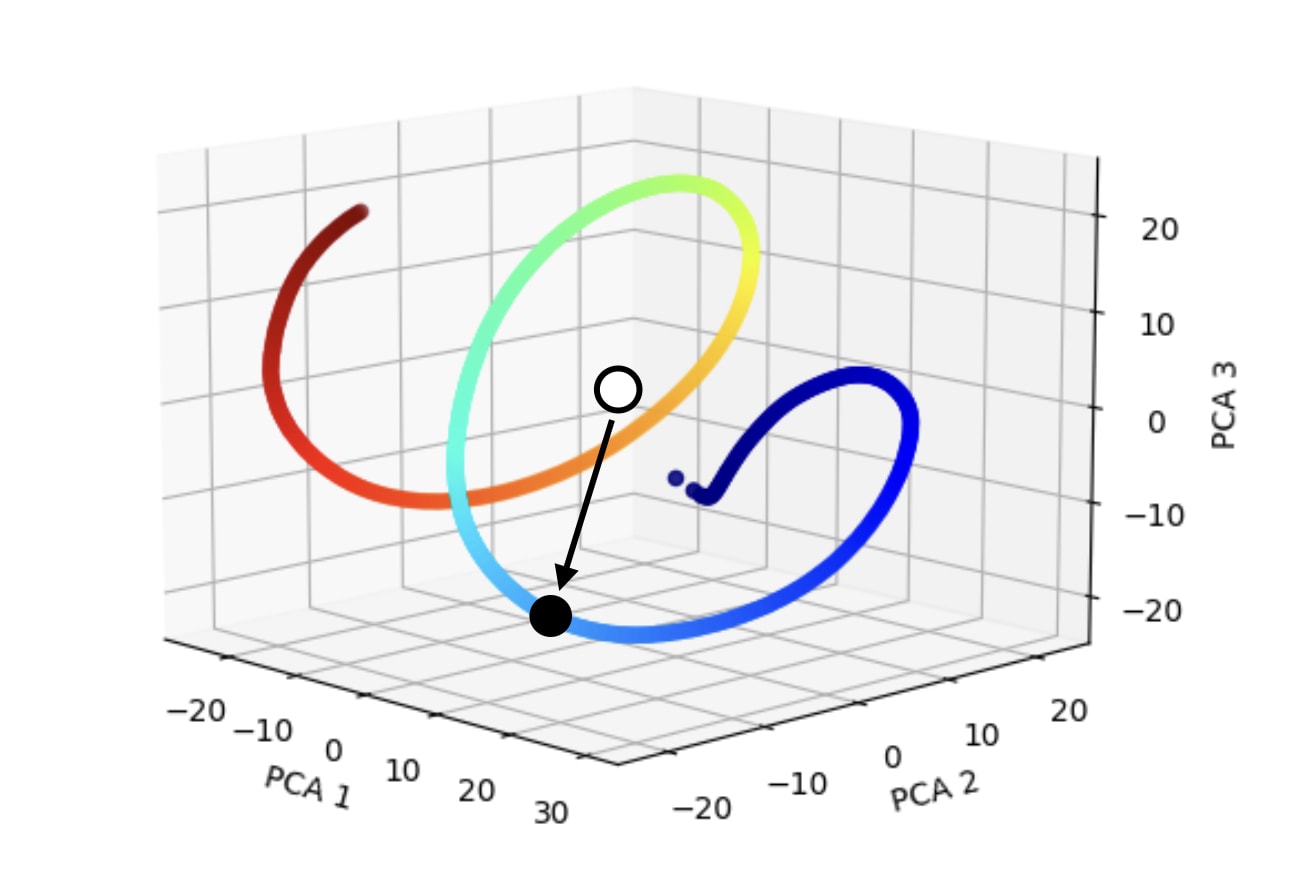
First of all, let's notice that raw the attention pattern immediately tells us that the extended positional embeddings are being used in a different way than one might have expected. Suppose that we wanted to use the extended positional embeddings to pinpoint a particular location in the prompt. I might have thought to use them as in the following diagram:
A visualization of the extended positional embeddings at layer 2.
In the diagram above, the black dot is meant to represent the embedding of the particular location we want to attend to, and the white dot is meant to represent the zero embedding. The black arrow is the vector between them, and in this hypothetical our raw attention scores would be the dot product between that vector and each point on the helix. This would on average make the black point on the helix have the highest attention score—but it has the downside that the points immediately before and after it on the helix would also have very high attention scores. It wouldn't be a very robust or precise approach.
Instead, the network is actually using the extended positional embeddings as in the following diagram:
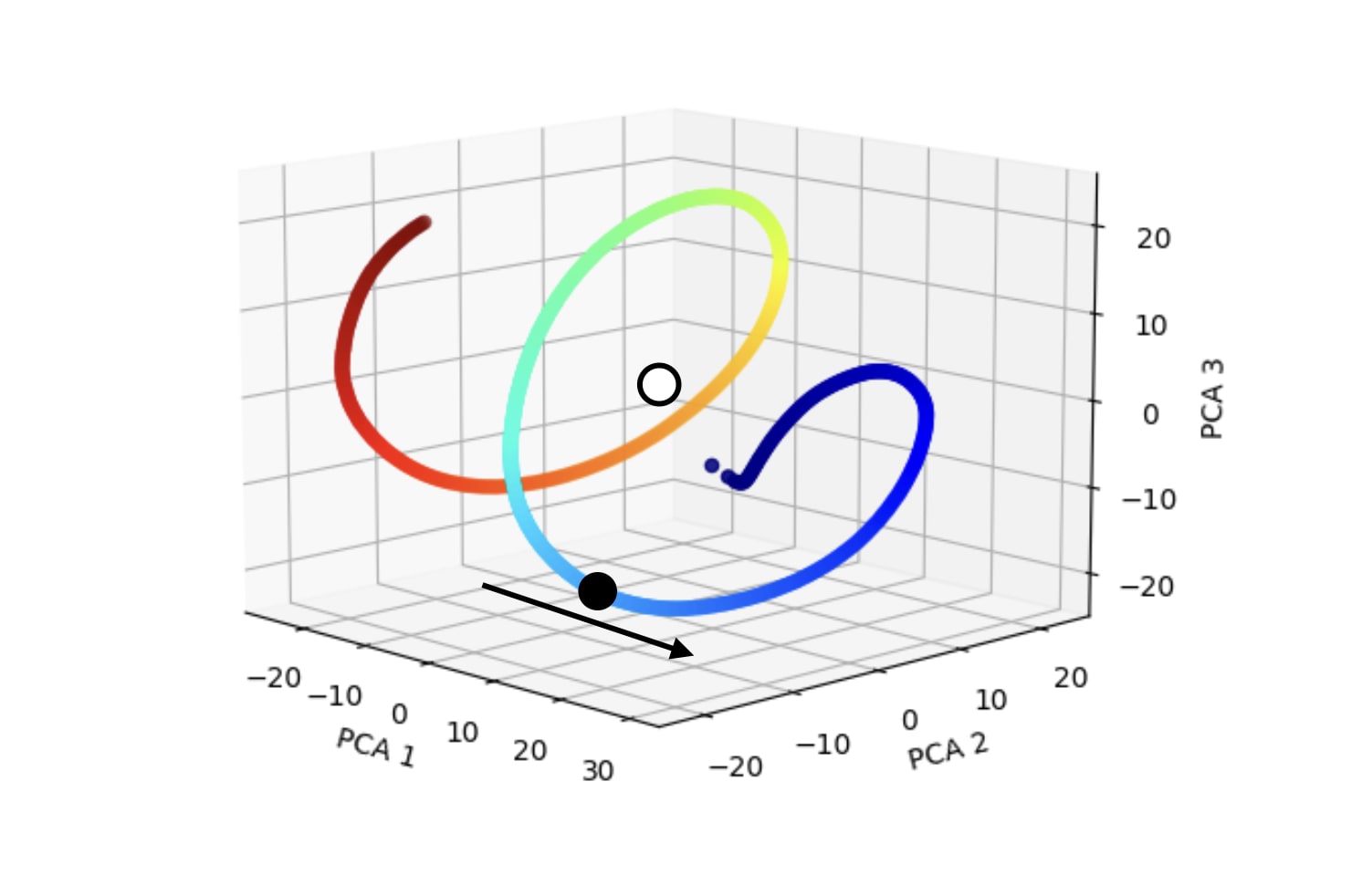
In other words, the vector it is taking a dot product with is tangent to the relevant point on the helix, rather than pointing at the relevant point on the helix. This approach does not mean that the black point on the helix has the highest raw attention score. Instead, it means that in the neighborhood of the black point, more advanced tokens have higher scores—and the black point is not the most advanced token position. We see this phenomenon in the raw attention pattern of L2H2:
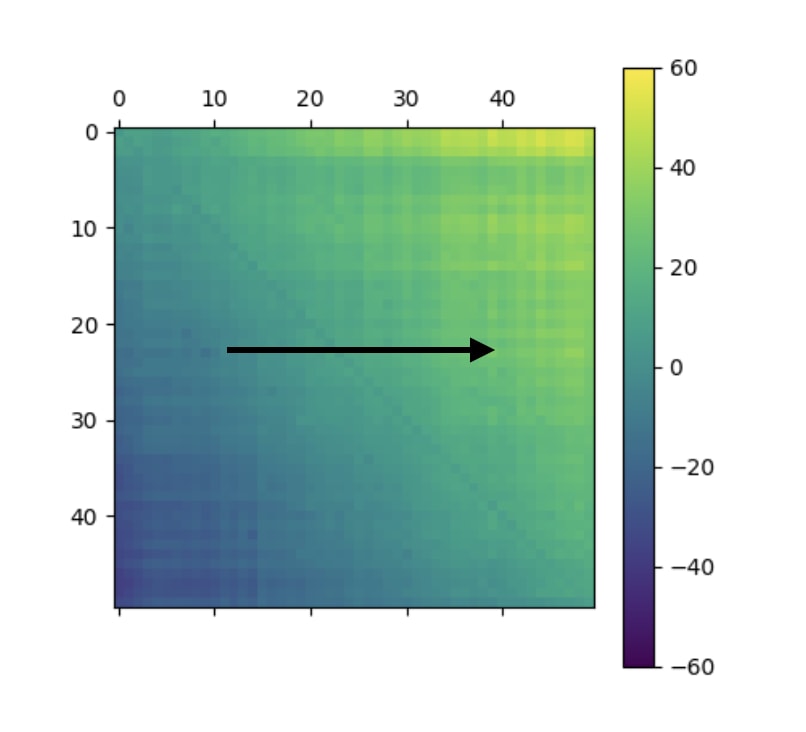
A 50x50 submatrix of the raw attention scores at L2H2. Raw attention scores are larger for more advanced token positions.
This approach allows tokens in the neighborhood of the black dot to be distinguished much more robustly[2]. At a glance, though, it's confusing why it should work at all. Won't this make the head attend to very advanced tokens, rather than the previous token? But then we remember that all the future tokens are cut off, so that it can't attend to anything in the upper-right half of the matrix.
Still, the current token isn't being cut off—only future token positions after the current token. If more advanced tokens get higher attention scores, shouldn't the most advanced not-cut-off token be the current token?
This is why the second phenomenon we noticed is crucial—the fact that the main diagonal is darker than the others. L2H2 is implementing negative self-attention—by attending less to tokens whose embeddings match its own[3]. This eliminates the current token position as the one to attend to most, leaving the previous token as the next-most advanced.
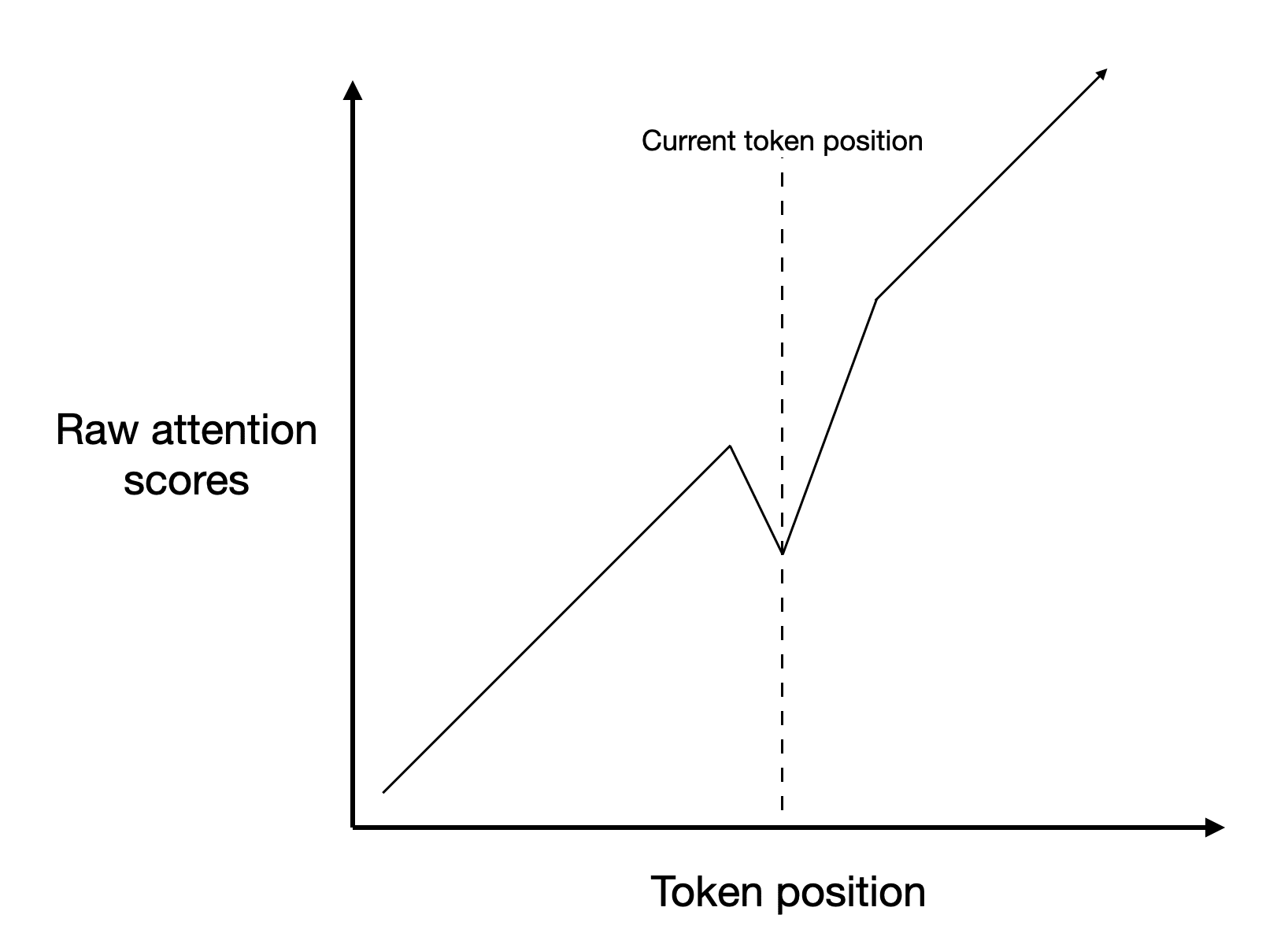
A sketch of the attention scores as a function of token position at L2H2. The downwards kink at the current token position is very important! It means that of all the attention scores to the left of the dotted line—i.e. of the attention scores that won't be set to negative infinity—the largest remaining value is at the previous token position.
This trick seems to be how all of the previous-token heads prior to L4H11 implement previous-token attention. But what about L4H11 itself? Why is its attention pattern so much cleaner than the others'?
Looking at the attention patterns of L4H11 more carefully, we can see right away that there is a qualitative difference between how it implements previous-token attention and how the earlier previous-token heads do.
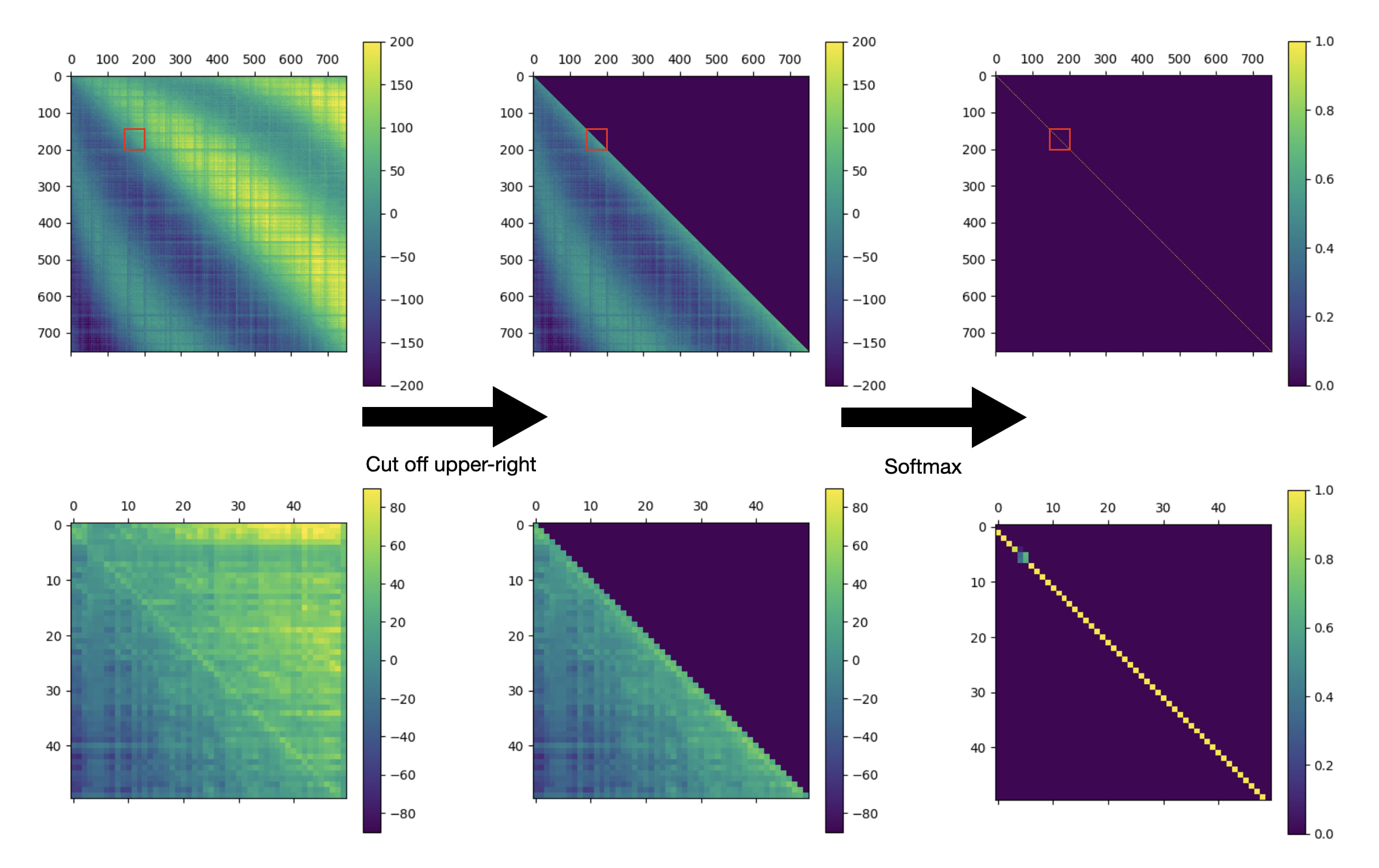
Top row: the full attention pattern of L4H11 on a prompt from openwebtext-10k. Bottom row: a 50x50 submatrix of the full attention pattern (zooming on in the red squares in the top row). Left: the raw attention scores. Center: the attention scores, after blocking out the upper-right half of the matrix. Right: The attention scores after a row-wise softmax, yielding the final attention pattern.
Consider the lower-left figure. Now, instead of having a dark line on the main diagonal, like the earlier heads did, we have a bright line on the diagonal just before the main diagonal! So L4H11's version of the previous sketch would look like this:
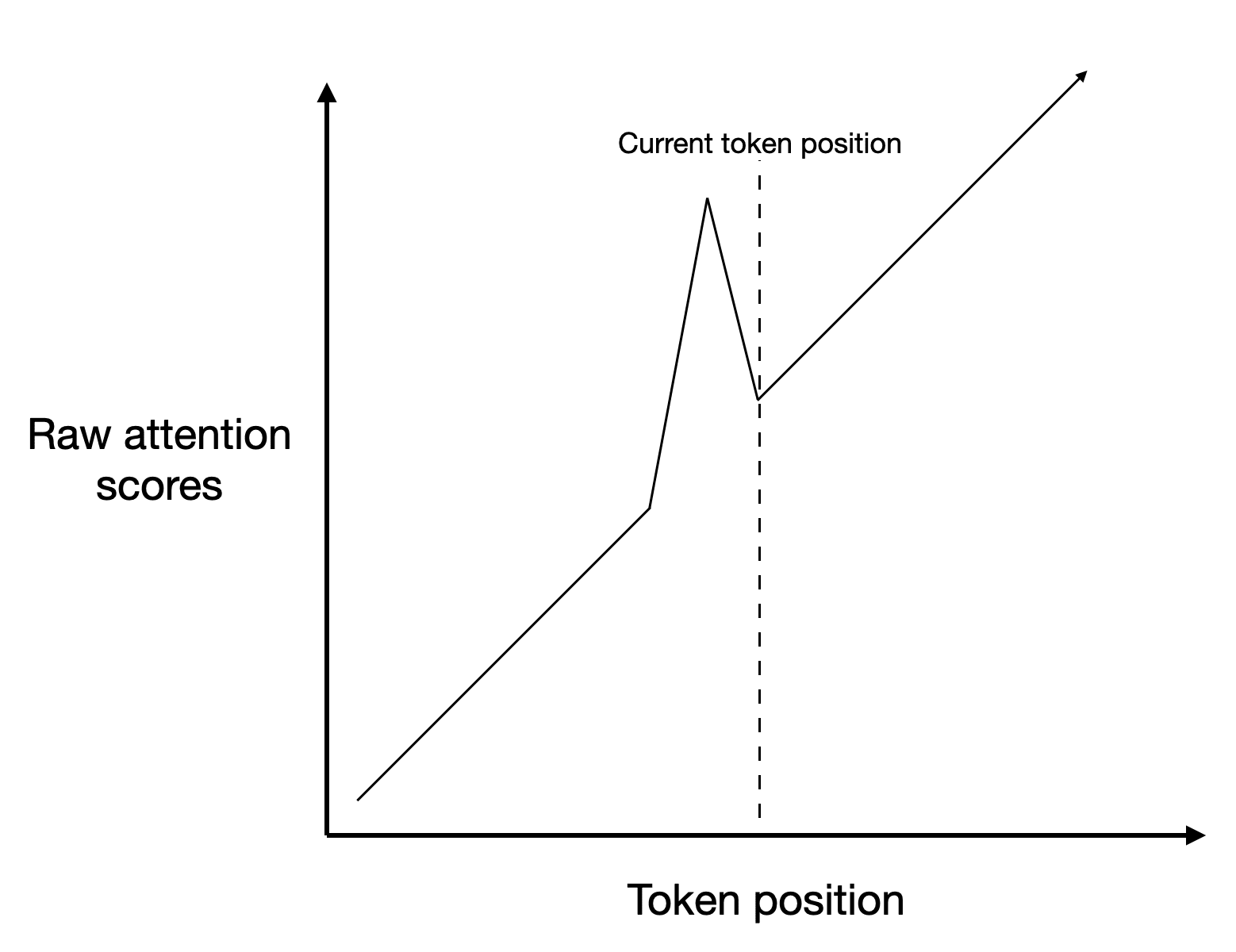
Increasing attention to the previous token, of course, is not a primitive action (whereas increasing attention to the current token—or, more precisely, tokens matching the current token—is). This implies that the L4H11 must be reading information off the residual stream that was put there by previous layers. L4H11 can be best thought of as an aggregator of the different signals coming from the earlier, messier previous-token heads, like L1H0, L2H2, L3H3, L2H4, L3H7, and L3H2,[4] all six of which have the characteristic pattern of decreased attention at the current token (rather than increased attention at the previous token).
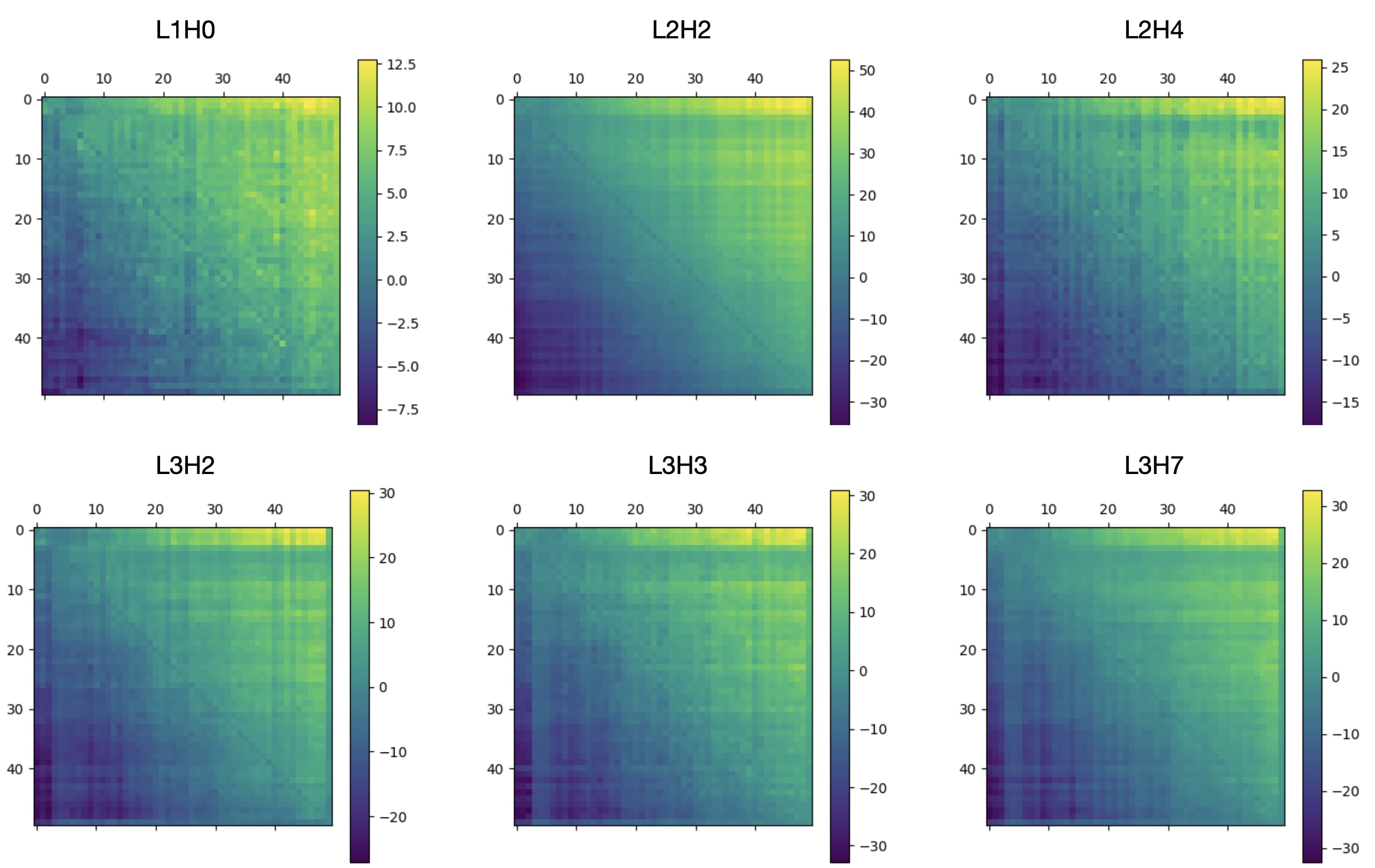
Above: a 50x50 submatrix of the raw attention scores of six early previous-token heads. All six of them have the "dark" main diagonal, indicating decreased attention at the current token. Below: a 50x50 submatrix of the raw attention scores of L4H11, along with a zoomed-in version of L2H2. L4H11, unlike the others, has a bright diagonal just before the main diagonal, indicating increased attention at the previous token. This distinction is why L4H11 belongs to a different taxon from the previous-token heads that precede it. L4H11 is best thought of as an aggregator of signals from the preceding previous-token heads.
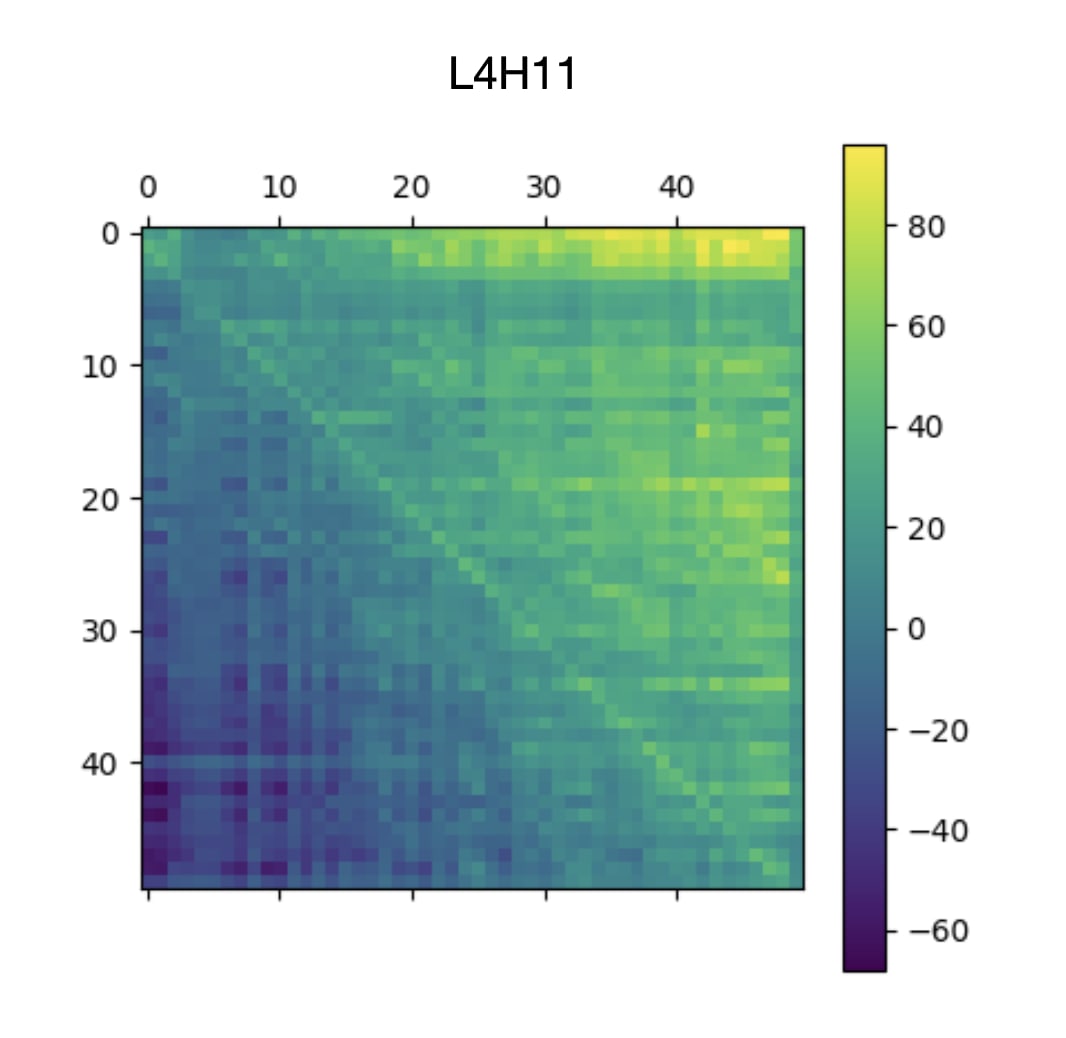
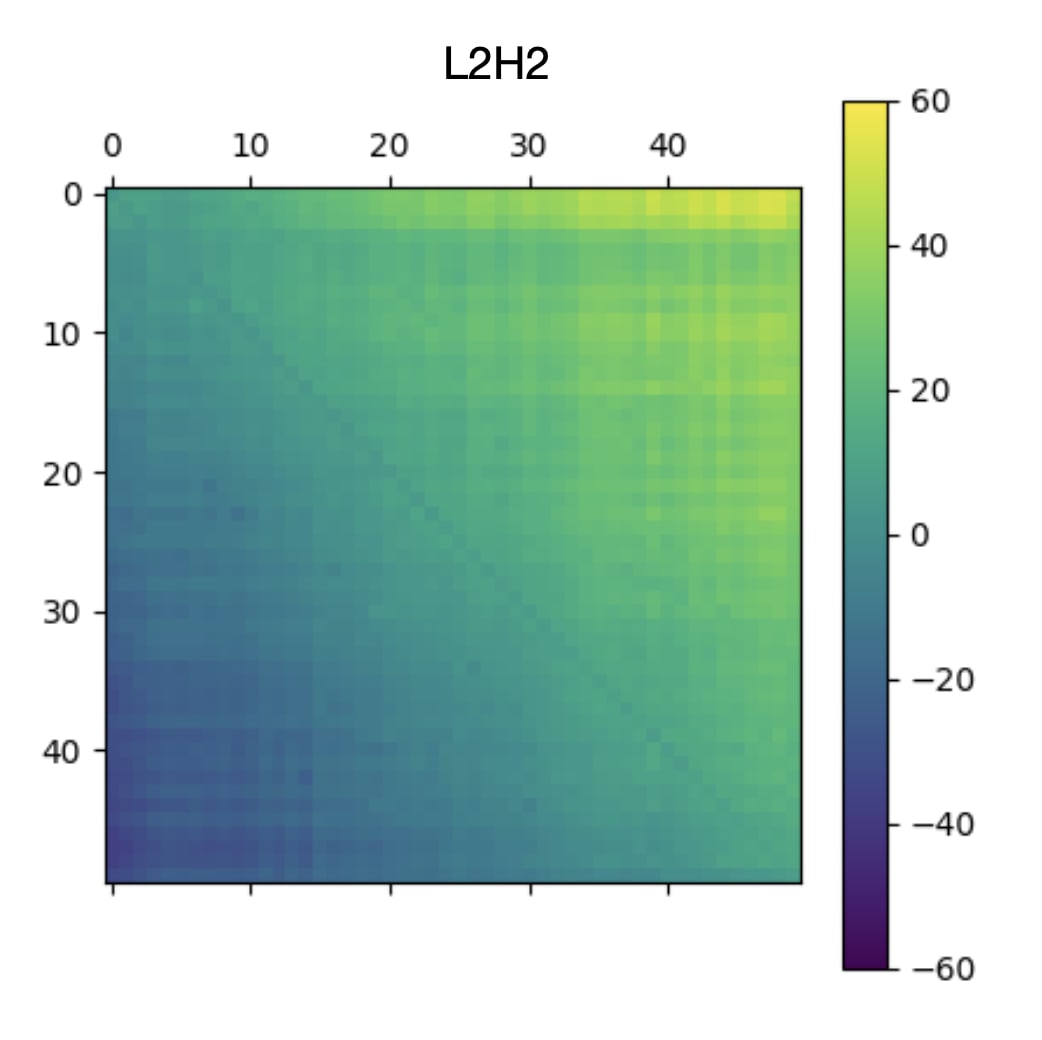
See the caption above.
As further evidence for the claim that L4H11 is primarily aggregating information about which token is the previous token left by previous layers, rather than computing which token is the previous token itself, we can average the extended positional embeddings at its layer in groups of 10, as we previously did for the original positional embeddings[5]. This will do tremendous damage to the early previous-token heads, which are relying on the extended positional embeddings to infer what the latest non-current token is, but minimal damage to L4H11, which is mostly relying on information left by previous layers anyway.
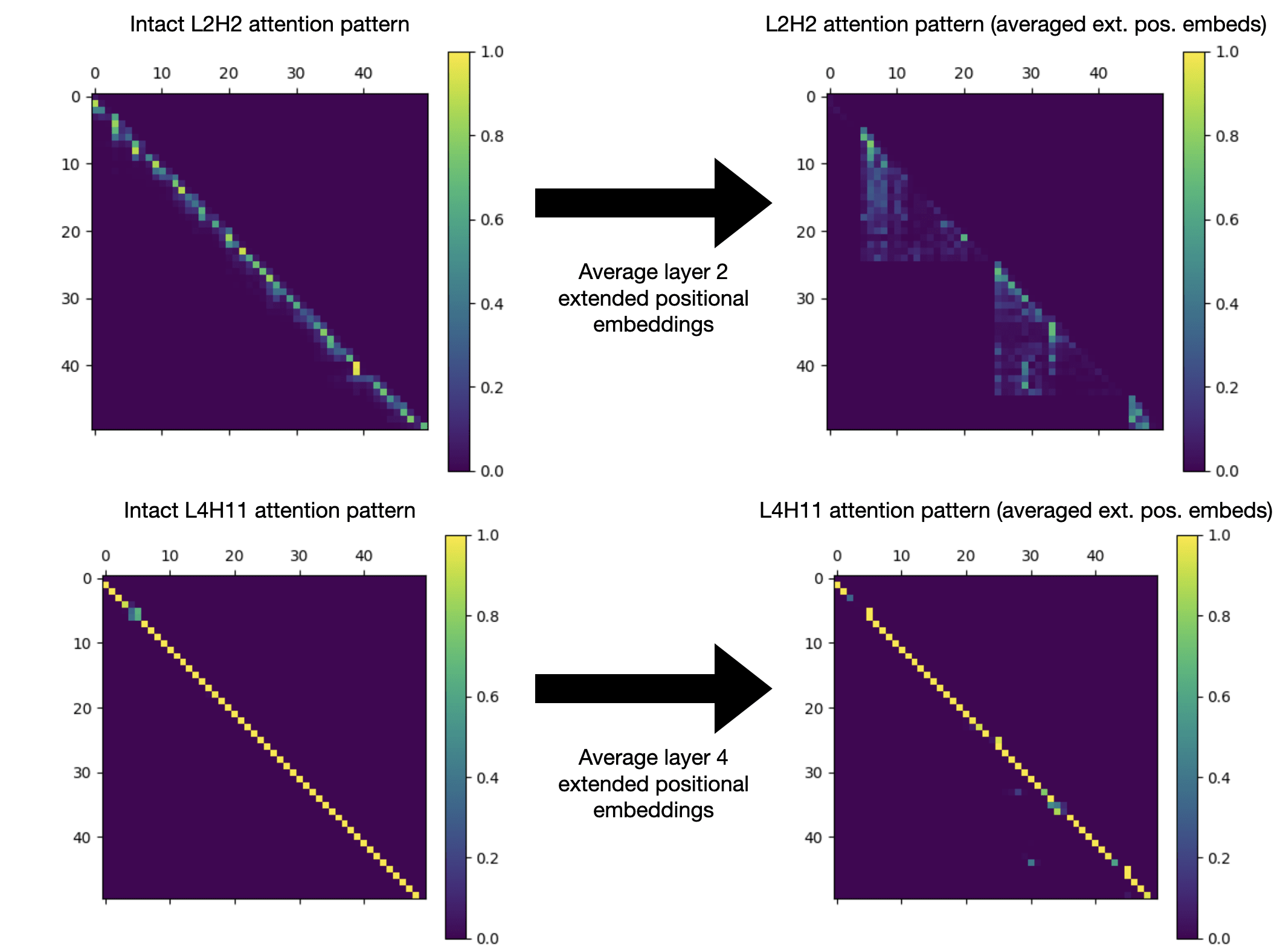
A side-by-side comparison of the effect of averaging together the extended positional embeddings in groups of 10, just before L2H2 vs. just before L4H11.
What is L4H11 for? What is its purpose in the network? The answer is that L4H11 is partly responsible for later, more complex parts of the network knowing what token comes next, like induction heads implementing copying circuits. We can verify this by intervening in L4H11's attention pattern.
Consider a prompt like the one we discussed before, which we can use to get GPT2 to repeat a string of our choice:
Request: Please repeat the following string exactly: "hello"
Reply: "hello".
Request: "Please repeat the following string exactly: " gorapopefm"
Reply: " gorapopefm"
...blah blah blah, 10 more of these...
Request: "Please repeat the following string exactly: "1pdjpm3efe4"
Reply: "1pdjpm3efe4"
Request: "Please repeat the following string exactly: " ninja turtle pirate"
Reply: " ninja By default, GPT2 thinks the next token is turtle, with probability 99% (the rest of the probability mass is on variants like Turtle or turtles).
Suppose we mess with L4H11's attention pattern as follows, and also double its output to the residual stream[6]:
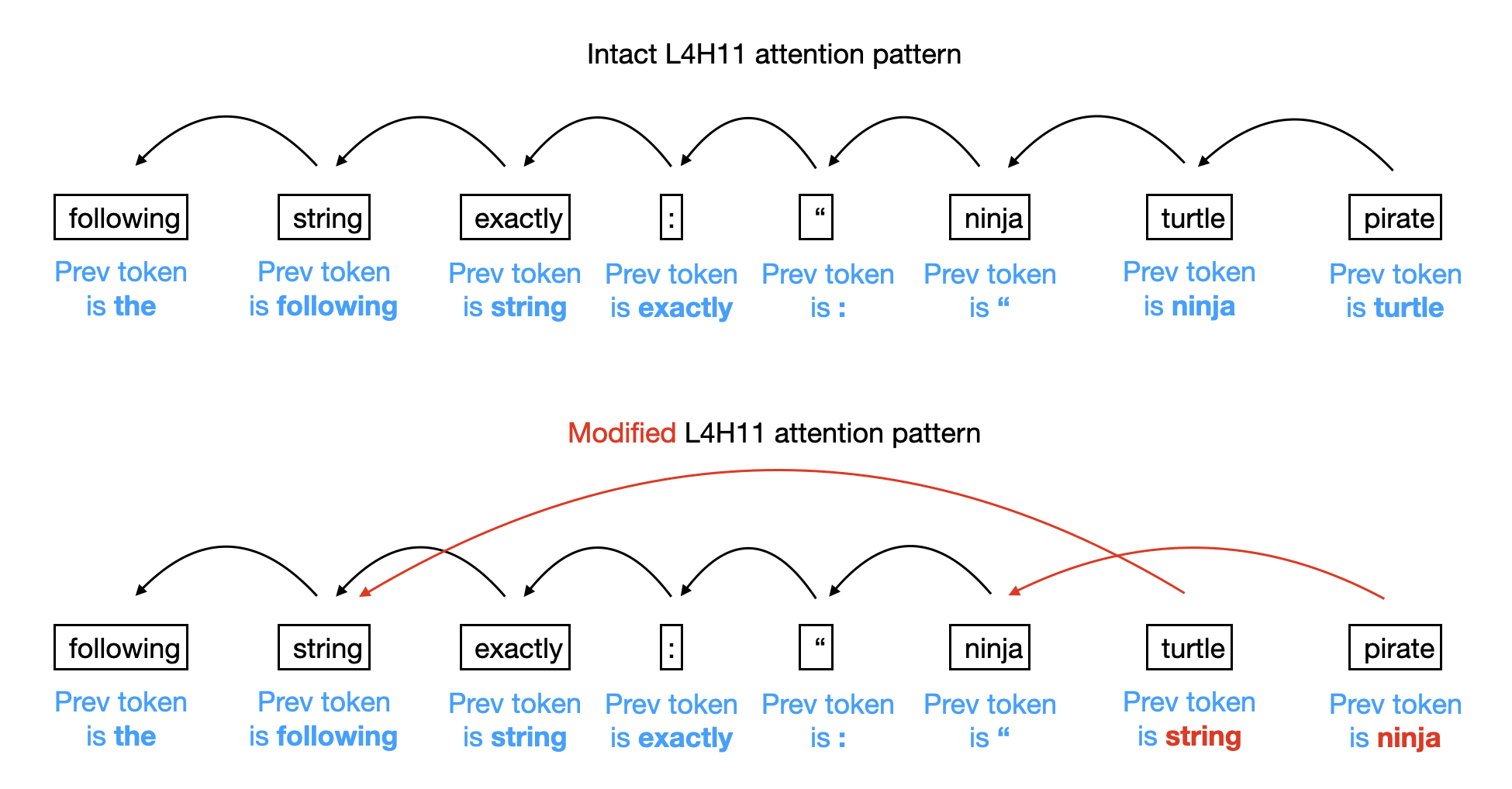
The L4H11 attention pattern, before and after modification. Black arrows indicate what L4H11 is attending to, and red arrows indicate L4H11's modified attention. The blue text is the information that (I speculate) L4H11 is writing to the residual stream.
When we modify the attention pattern of L4H11 as above and double its output, we see that instead GPT2 thinks that the next token is pirate, with probability 65% (and a 26% probability of turtle). Why do we get this difference? The idea is that one of the roles of a previous-token head is to work in concert with an induction head later in the network. Induction heads are attention heads that want to attend to tokens earlier in the prompt whose preceding token matches the induction head's current token. So an induction head, responsible for copying text, will be looking for a token in the prompt that has ninja as its preceding token. According the intact L4H11 attention pattern, that token would be turtle; in the modified version of L4H11, that token would instead be pirate.
Summary
Overall, as I currently understand it, the causal chain of events in a transformer related to positional embeddings, previous-token attention, and copying text is something like the following:
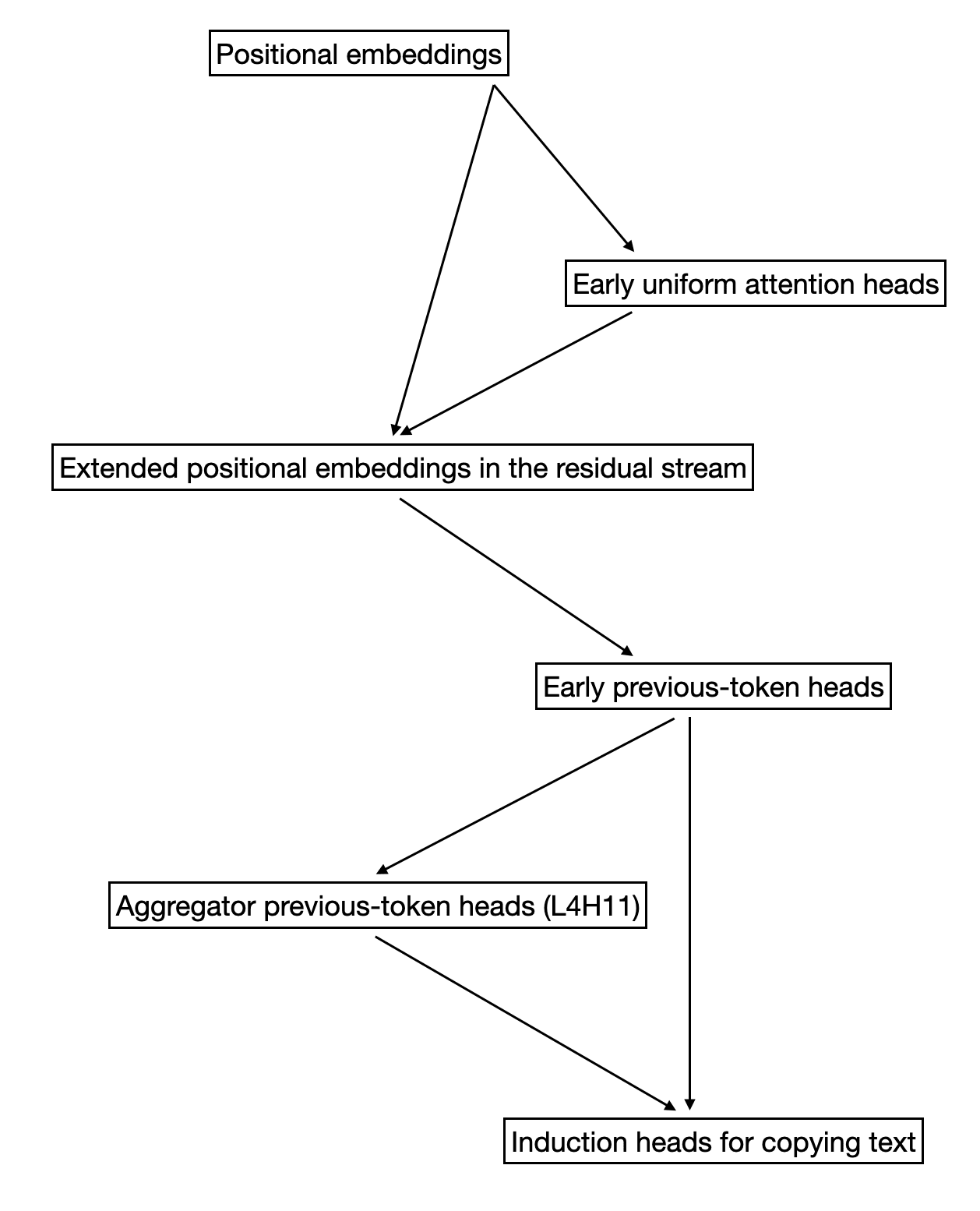
Some heads in early layers attend roughly uniformly to previous tokens, using the positional embeddings. These heads are responsible for writing the extended positional embeddings into the residual stream. Those extended positional embeddings get read in by the early previous-token heads, which use them to attend more to more advanced tokens. Attending to more advanced tokens, in concert with negative self-attention, results in approximate previous-token attention behavior. Aggregator heads like L4H11 use the information put in the residual stream by the early previous-token heads to attend precisely to the previous token; they put information back into the residual stream, which are later used by induction heads for tasks like copying text.
- ^
For context, the residual stream is a vector that exists at each token position. The primary function of each layer of a transformer network is to read some information off the residual stream, and then to write some information back to the residual stream. The residual stream can be thought of as the transformer's "memory".
- ^
One reasonable question is—why does it matter how robustly the previous-token attention is implemented? The answer is that there's substantial "leakage" into the extended positional embedding directions from the token embeddings and other unrelated stuff getting written by the network—there's not a clean separation between the position-related directions in the residual stream and everything else. So a less robust solution to previous-token attention will often end up attending to the wrong token because of the other garbage in the residual stream.
- ^
This also neatly explains why repeated tokens mess with the previous-token pattern—when it tries to attend less to its own token, it also attends less to any token that matches its own, including the previous token if the previous token happens to match the current token.
- ^
This list isn't meant to be exhaustive—there are still more heads in the early layers that could be construed to be "previous-token heads". These six are just the ones that have this behavior the most strongly from among heads in the first four layers.
- ^
Note that when we averaged the original positional embeddings together, it didn't have much effect, because the previous-token heads like
L2H2are relying on the extended positional embeddings, not the original ones! That's why we see such a dramatic difference. - ^
Without doubling
L4H11's output, we don't see much difference in probability, interestingly. I speculate that it's because later parts of the network are still relying on the earlier heads' output as well, not justL4H11's, to infer what the previous token was, and so we need to amplifyL4H11to "drown out" the contributions of the earlier previous-token heads.
4 comments
Comments sorted by top scores.
comment by RGRGRG · 2023-08-12T19:19:28.259Z · LW(p) · GW(p)
This is a surprising and fascinating result. Do you have attention plots of all 144 heads you could share?
I'm particularly interested in the patterns for all heads on layers 0 and 1 matching the following caption
(Left: a 50x50 submatrix of LXHY's attention pattern on a prompt from openwebtext-10k. Right: the same submatrix of LXHY's attention pattern, when positional embeddings are averaged as described above.)
Replies from: babybeluga↑ comment by AdamYedidia (babybeluga) · 2023-08-14T22:41:30.540Z · LW(p) · GW(p)
Here's the plots you asked for for all heads! You can find them at:
https://github.com/adamyedidia/resid_viewer/tree/main/experiments/pngs
Haven't looked too carefully yet but it looks like it makes little difference for most heads, but is important for L0H4 and L0H7.
Replies from: RGRGRGcomment by AdamYedidia (babybeluga) · 2023-08-10T05:16:25.220Z · LW(p) · GW(p)
The code to generate the figures can be found at https://github.com/adamyedidia/resid_viewer, in the experiments/ directory. If you want to get it running, you'll need to do most of the setup described in the README, except for the last few steps (the TransformerLens step and before). The code in the experiments/ directory is unfortunately super messy, sorry!