Posts
Comments
In Drawback Chess, each player gets a hidden random drawback, and the drawbacks themselves have ELOs (just like the players). As players' ratings converge, they'll end up winning about half the time, since they'll get a less stringent drawback than their opponent's.
The game is pretty different from ordinary chess, and has a heavy dose of hidden information, but it's a modern example of fluid handicaps in the context of chess.
(I was one of the two dishonest advisors)
Re: the Kh1 thing, one interesting thing that I noticed was that I suggested Kh1, and it immediately went over very poorly, with both other advisors and player A all saying it seemed like a terrible move to them. But I didn't really feel like I could back down from it, in the absence of a specific tactical refutation—an actual honest advisor wouldn't be convinced by the two dishonest advisors saying their move was terrible, nor would they put much weight on player A's judgment. So I stuck to my guns on it, and eventually it became kind of a meme.
I don't think it made a huge difference, since I think player A already had almost no trust in me by that point. But it's sort of an interesting phenomenon where as a dishonest player, you can't ever really back down from a suggested bad move that's only bad on positional grounds. What kind of honest advisor would be "convinceable" by players they know to be dishonest?
I'd be excited to play as any of the roles. I'm around 1700 on lichess. Happy with any time control, including correspondence. I'm generally free between 5pm and 11pm ET every day.
Oh wow, that is really funny. GPT-4's greatest weakness: the Bongcloud.
Sure thing—I just added the MIT license.
Uhh, I don't think I did anything special to make it open source, so maybe not in a technical sense (I don't know how that stuff works), but you're totally welcome to use it and build on it. The code is available here:
https://github.com/adamyedidia/resid_viewer
Good lord, I just played three games against it and it beat me in all three. None of the games were particularly close. That's really something. Thanks to whoever made that parrotchess website!
I don't think it's a question of the context window—the same thing happens if you just start anew with the original "magic prompt" and the whole current score. And the current score is alone is short, at most ~100 tokens—easily enough to fit in the context window of even a much smaller model.
In my experience, also, FEN doesn't tend to help—see my other comment.
It's a good thought, and I had the same one a while ago, but I think dr_s is right here; FEN isn't helpful to GPT-3.5 because it hasn't seen many FENs in its training, and it just tends to bungle it.
Lichess study, ChatGPT conversation link
GPT-3.5 has trouble from the start maintaining a correct FEN, and makes its first illegal move on move 7, and starts making many illegal moves around move 13.
Here's the plots you asked for for all heads! You can find them at:
https://github.com/adamyedidia/resid_viewer/tree/main/experiments/pngs
Haven't looked too carefully yet but it looks like it makes little difference for most heads, but is important for L0H4 and L0H7.
The code to generate the figures can be found at https://github.com/adamyedidia/resid_viewer, in the experiments/ directory. If you want to get it running, you'll need to do most of the setup described in the README, except for the last few steps (the TransformerLens step and before). The code in the experiments/ directory is unfortunately super messy, sorry!
A very interesting post, thank you! I love these glitch tokens and agree that the fact that models can spell at all is really remarkable. I think there must be some very clever circuits that infer the spelling of words from the occasional typos and the like in natural text (i.e. the same mechanism that makes it desirable to learn the spelling of tokens is probably what makes it possible), and figuring out how those circuits work would be fascinating.
One minor comment about the "normalized cumulative probability" metric that you introduced: won't that metric favor really long and predictable-once-begun completions? Like, suppose there's an extremely small but nonzero chance that the model chooses to spell out " Kanye" by spelling out the entire Gettysburg Address. The first few letters of the Gettysburg Address will be very unlikely, but after that, every other letter will be very likely, resulting in a very high normalized cumulative probability on the whole completion, even though the completion as a whole is still super unlikely.
Nope, this is the pos_embed matrix! So before the first layer.
This is great! Really professionally made. I love the look and feel of the site. I'm very impressed you were able to make this in three weeks.
I think my biggest concern is (2): Neurons are the wrong unit for useful interpretability—or at least they can't be the only thing you're looking at for useful interpretability. My take is that we also need to know what's going on in the residual stream; if all you can see is what is activating neurons most, but not what they're reading from and writing to the residual stream, you won't be able to distinguish between two neurons that may be activating on similar-looking tokens but that are playing completely different roles in the network. Moreover, there will be many neurons where interpreting them is basically hopeless, because their role is to manipulate the residual stream in a way that's opaque if you have no way of understanding what's in the residual stream.
Take this neuron, for example (this was the first one to pop up for me, so not too cherrypicked):
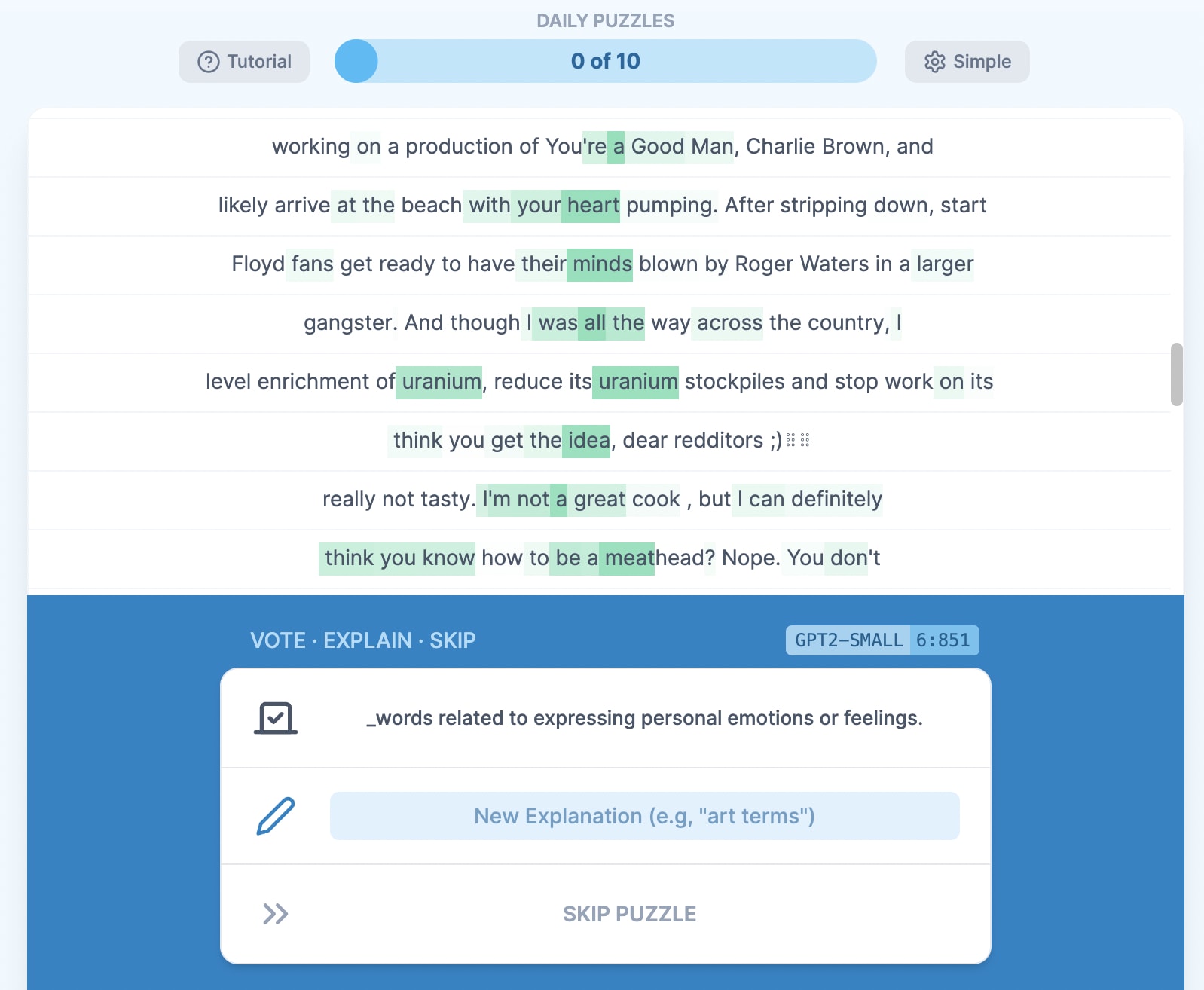
Clearly, the autogenerated explanation of "words related to expressing personal emotions or feelings" doesn't fit at all. But also, coming up with a reasonable explanation myself is really hard. I think probably this neuron is doing something that's inscrutable until you've understood what it's reading and writing—which requires some understanding of the residual stream.
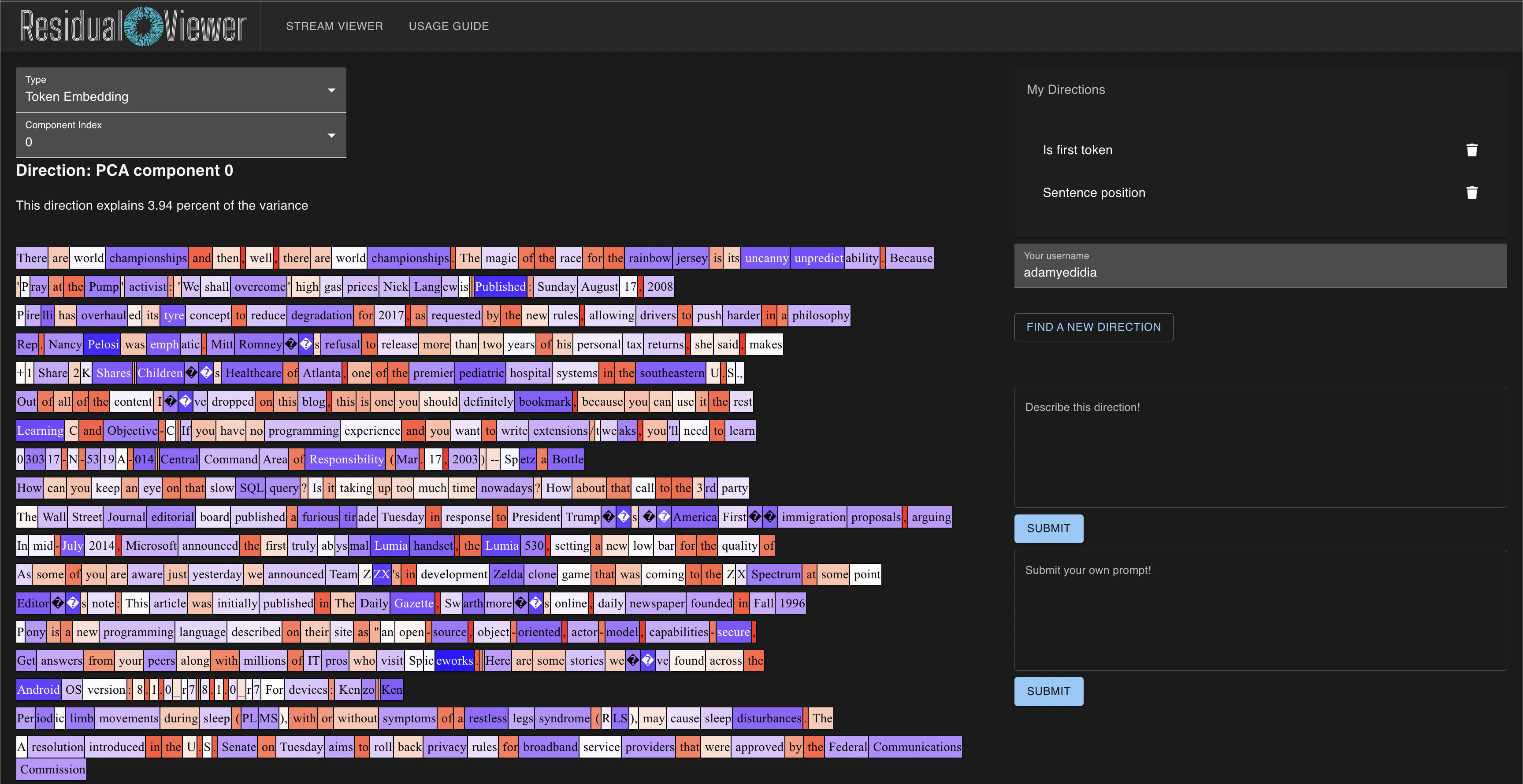
My hope is that the residual stream can mostly be understood in terms of relevant directions, which will represent features or superpositions of features. If users can submit possible mappings of directions -> features, and we can look at what directions the neuron is reading from/writing to, then maybe there's more potential hope for interpreting a neuron like the above. I've been working on a similar tool to yours, which would allow users to submit explanations for residual stream directions. Not online at the moment, but here's a current screenshot of it:
DM me if you'd be interested in talking further, or working together in some capacity. We clearly have a similar approach.
Python (the matplotlib package).
I think you could, but you'd be missing out on the 9% (for gpt2-small) of the variance that isn't in one of those three dimensions, so you might degrade your performance.
Oh, interesting! Can you explain why the "look back N tokens" operation would have been less easily expressible if all the points had been on a single line? I'm not sure I understand yet the advantage of a helix over a straight line.
If you want to play around with it yourself, you can find it in the experiments/ directory in the following github: https://github.com/adamyedidia/resid_viewer.
You can skip most of the setup in the README if you just want to reproduce the experiment (there's a lot of other stuff going on the repository, but you'll still need to install TransformerLens, sklearn, numpy, etc.
It is in fact concentrated away from that, as you predicted! Here's a cool scatter plot:
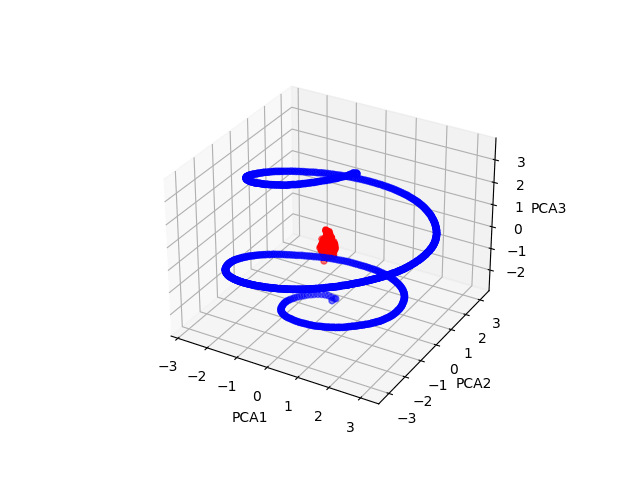
The blue points are the positional embeddings for gpt2-small, whereas the red points are the token embeddings.
That's awesome! Great find.
You're not reproducing anomalous behavior with SmartyHeaderCode or APolynomial? I just tried gpt-3.5-turbo over the API at temperature 0, and got these results:
Prompt: Please repeat the following string back to me exactly and in its entirety: "SmartyHeaderCode"
Reply: "AndHashCode"
Prompt: Please repeat the following string back to me exactly and in its entirety: "HelloSmartyHeaderCode"
Reply: Hello, "N" is capitalized. The correct string is "Hello, CodeHash".
Prompt: Please repeat the following string back to me exactly and in its entirety: "APolynomial"
Reply: "A polynomial"
Prompt: Please repeat the following string back to me exactly and in its entirety: "HelloAPolynomial"
Reply: Hello
Try this and see if it reproduces for you:
token_string = 'HelloAPolynomial'
prompt = f"Please repeat the following string back to me exactly and in its entirety: \"{token_string}\""
response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}], temperature=0)