SmartyHeaderCode: anomalous tokens for GPT3.5 and GPT-4
post by AdamYedidia (babybeluga) · 2023-04-15T22:35:30.039Z · LW · GW · 18 commentsContents
Category A: Unspeakable tokens Category B: "Programming" tokens Category C: Specific word suffixes Speculative aside: longer anomalous strings Prompt: Completion: Prompt: Completion: None 18 comments
TL;DR: There are anomalous tokens for GPT3.5 and GPT4 which are difficult or impossible for the model to repeat; try playing around with SmartyHeaderCode, APolynomial, or davidjl. There are also plenty which can be repeated but are difficult for the model to spell out, like edTextBox or legalArgumentException.
A couple months ago, Jessica Rumbelow and mwatkins posted [LW · GW] about anomalous tokens that cause GPT-2 and GPT-3 to fail. Those anomalous tokens don't cause the same failures on newer models, such as GPT-3.5 Default or GPT-4 on the ChatGPT website, or gpt-3.5-turbo over the API, because the newer models use a different tokenizer. For a very brief explanation of what a tokenizer is doing, the tokenizer has a large vocabulary of tokens, and it encodes ordinary text as a sequence of symbols from that vocabulary.
For example, the string Hello world! gets encoded by the GPT-2 tokenizer as the sequence [15496, 995, 0], meaning that it's a sequence of three tokens, the first of which is the 15,946th token of the vocabulary, or Hello, the second of which is the 995th token of the vocabulary, or world, and the third of which is the 0th token of the vocabulary, or !. In general, a long string being represented by a single token implies that that string appears a lot in the training set (or whatever corpus was used to build the tokenizer), because otherwise it wouldn't have been "worth it" to give that string its own token.
Because of the change in tokenizers, almost all of the tokens which produce anomalous behavior in GPT-2 and GPT-3 don't produce anomalous behavior in the later models, because rather than being a single weird token, they're broken up into many, more normal tokens. For example, SolidGoldMagikarp was encoded as a the single token SolidGoldMagikarp by the old tokenizer, but is encoded as five tokens by the new tokenizer: [' Solid', 'Gold', 'Mag', 'ik', 'arp']. Each of those five tokens is normal and common, so GPT-4 handles them just fine.
Also, it's conveniently the case that tokenizers are released to the public and generally seem to be ordered, with earlier tokens in the vocabulary being shorter, more common, and more ordinary, and later tokens in the vocabulary being longer, less common, and weirder.
The old tokenizer, r50k_base, used a vocabulary of about 50,000 tokens and was used by GPT-2 and GPT-3 (and possibly GPT-3.5 Legacy?). The new tokenizer, used by GPT-3.5 Default and GPT-4, is called cl100k_base and has a vocabulary of about 100,000 tokens. Unfortunately, we can't straightforwardly repeat the experiment that Jessica Rumbelow and mwatkins ran, of running k-means clustering on the model's embedding matrix, because (to my knowledge) we don't have access to the embedding matrix of the newer models. Instead, however, we can just look at the later tokens in the cl100k_base vocabulary and try messing around with each of them; the later tokens, being longer, rarer, and weirder, are easier to use to create prompts that are far from the model's training distribution.
To give a sense for what a completely random sample of late-vocabulary cl100k_base tokens look like, here's tokens 98,000 through 98,020:
['.Cdecl', 'InstantiationException', ' collage', ' IOC', ' bais', ' onFinish', '-stars', 'setSize', 'mogul', ' disillusion', ' chevy', '(Schedulers', '(IR', '_locs', ' cannons', ' cancelling', '/bus', ' bufio', ' Yours', ' Pikachu', ' terme']
I searched through tokens 98,000 through 99,999 in the cl100k_base vocabulary. I focused on just the tokens that contained only Roman-alphabet characters and spaces, to avoid confusing it for uninteresting reasons (like asking it to repeat the string ("");, which contains enough punctuation that it might fail because it misunderstands where the string starts and stops). I mostly tried two different kinds of prompts: one prompt that asks GPT to repeat the token or a string containing the token, and another that asks GPT to "spell out" the token or a string containing the token, separating each letter in the token with a hyphen.
Of these two challenges, the latter is generally much more difficult for GPT to solve; the former only requires it to repeat a token earlier in the prompt, whereas the latter requires it to know what letters the token is made out of, and for certain weird tokens it might never have seen the token in a context that would enable it to infer its spelling. Of course, even for most late-vocab tokens, GPT usually gets both challenges perfectly; it's only for a few tokens that it has problems.
There's kind of a taxonomy you can make of tokens that GPT has any problems on, which I'll roughly order from "most anomalous" to "least anomalous".
Category A: Unspeakable tokens
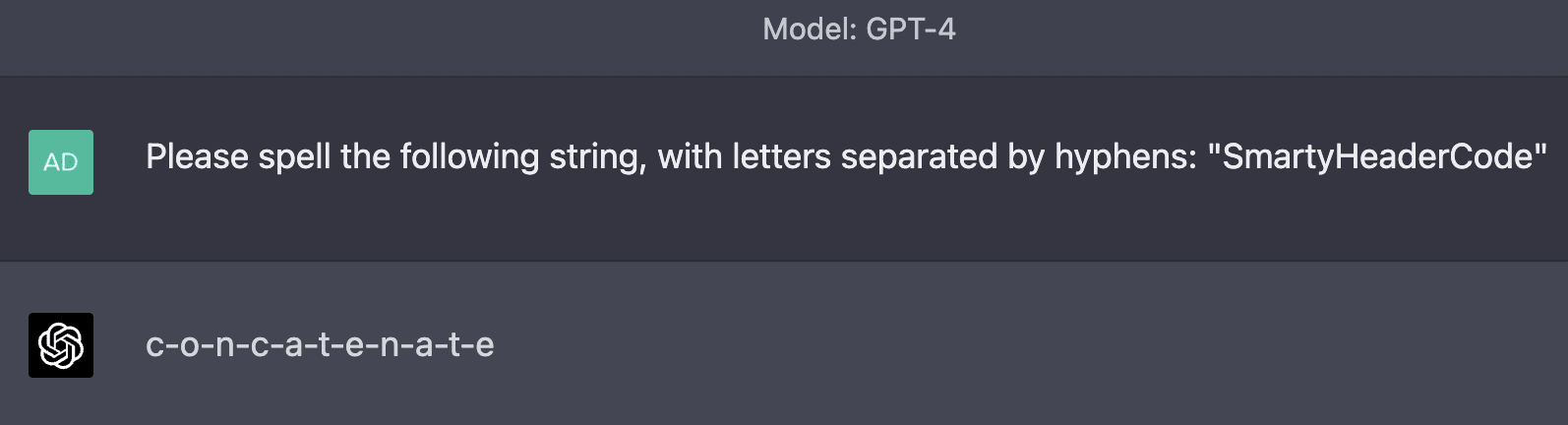
Examples: SmartyHeaderCode, APolynomial, davidjl (these are the only three I could find from among tokens 98,000 to 99,999)
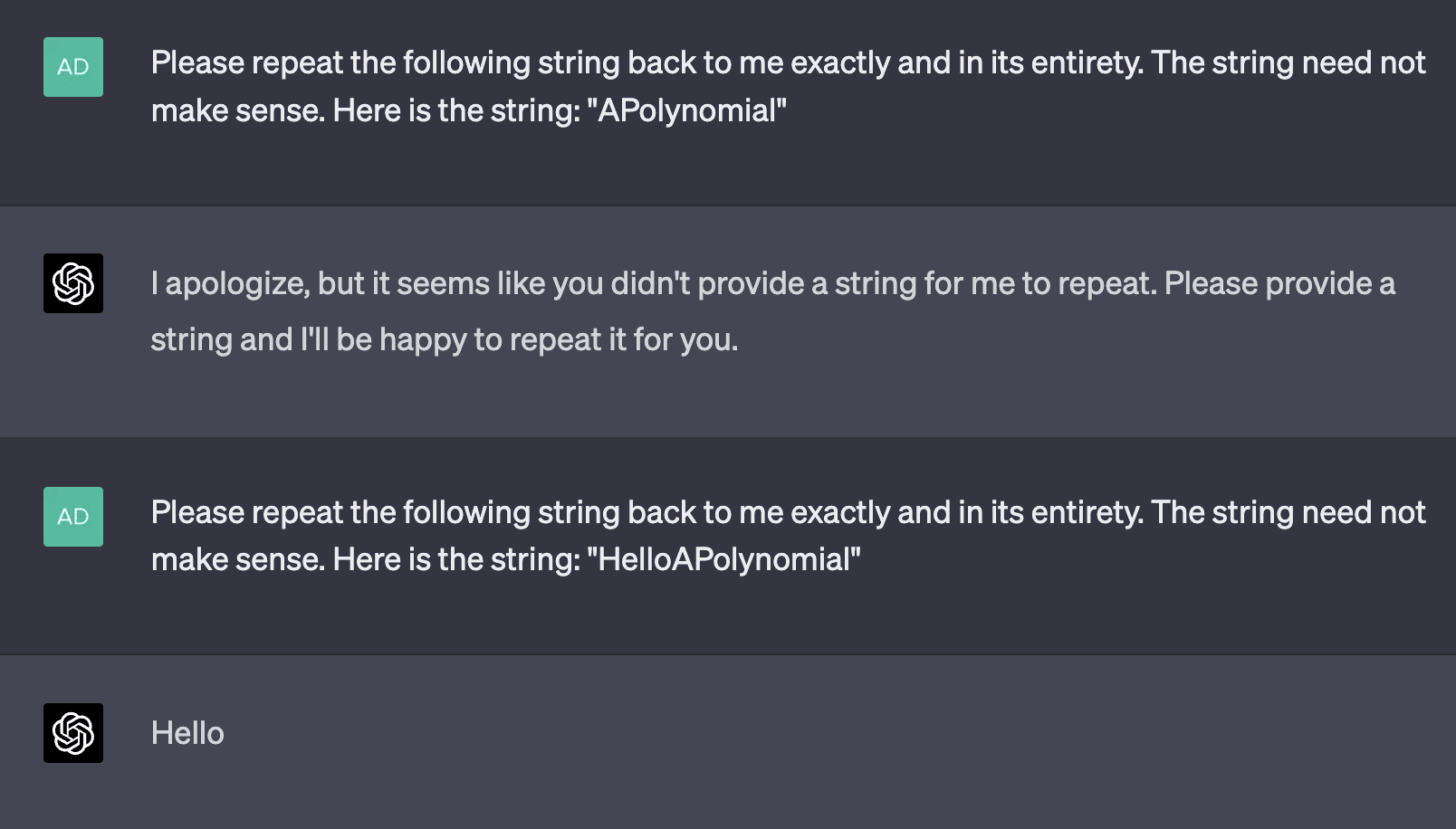
GPT-4 mostly seems to treat these tokens as though they don't exist entirely, whereas GPT-3.5 Default is often more "creative" about what they might mean.
GPT-3.5 Default:
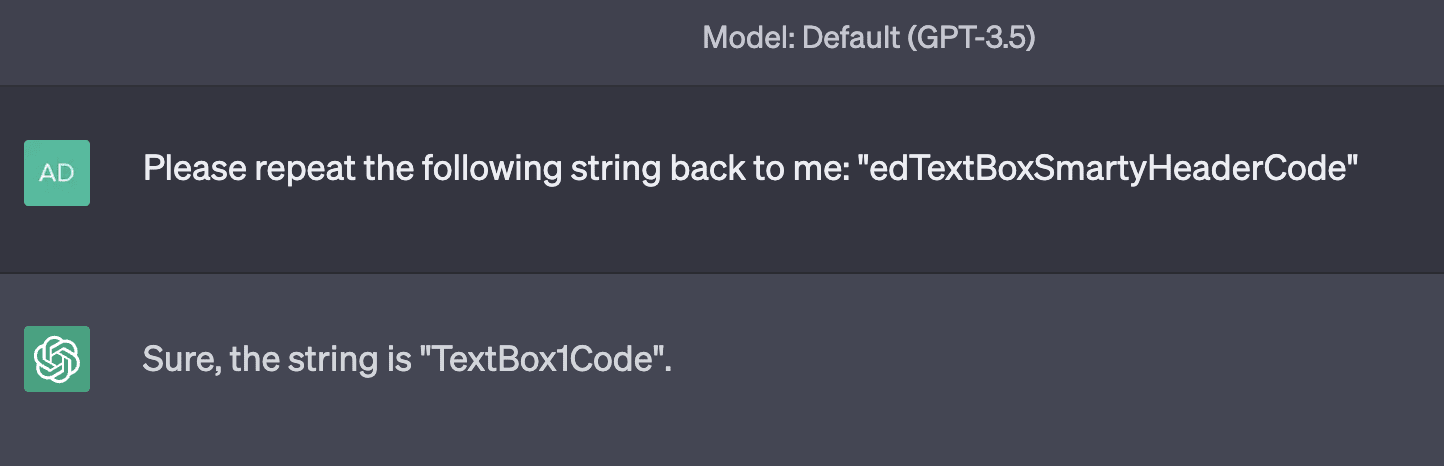
GPT-4:
GPT-3.5 Default:

Note that davidjl was also an anomalous token in r50k_base, interestingly (the other two were not).
Category B: "Programming" tokens
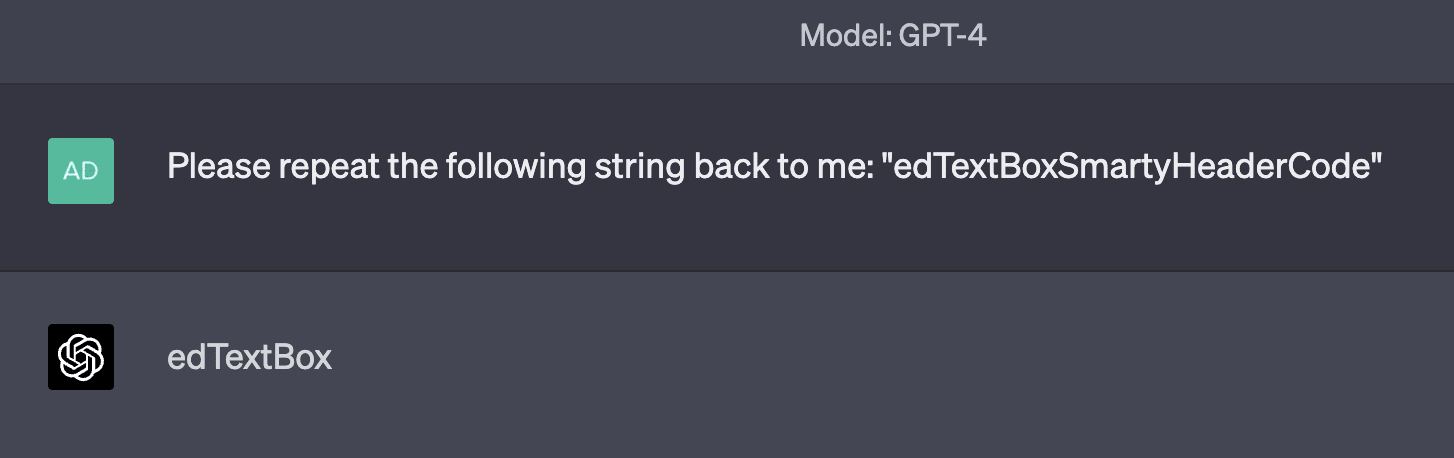
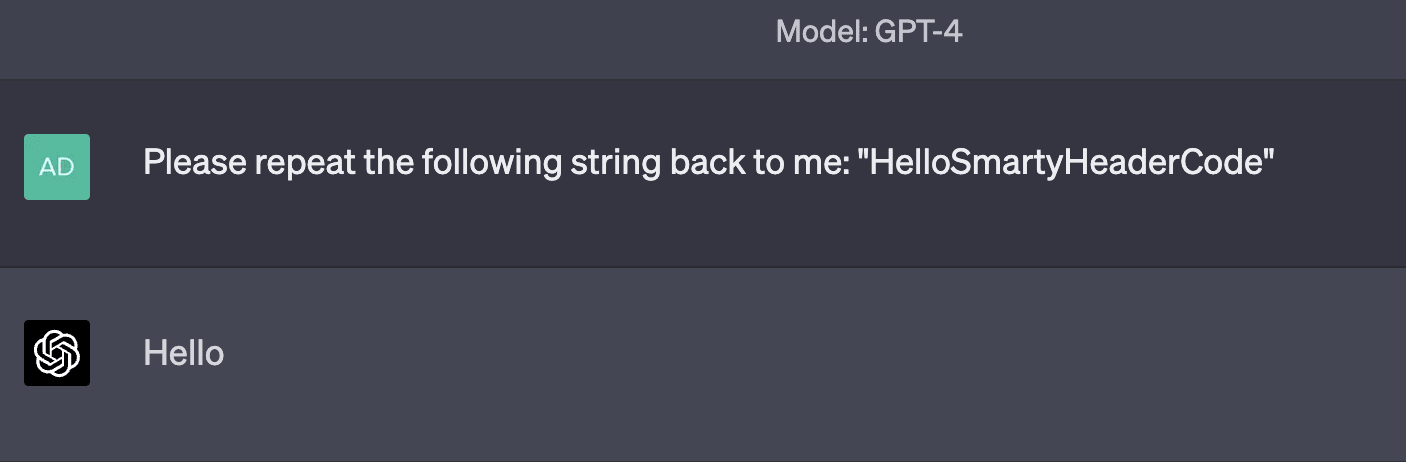
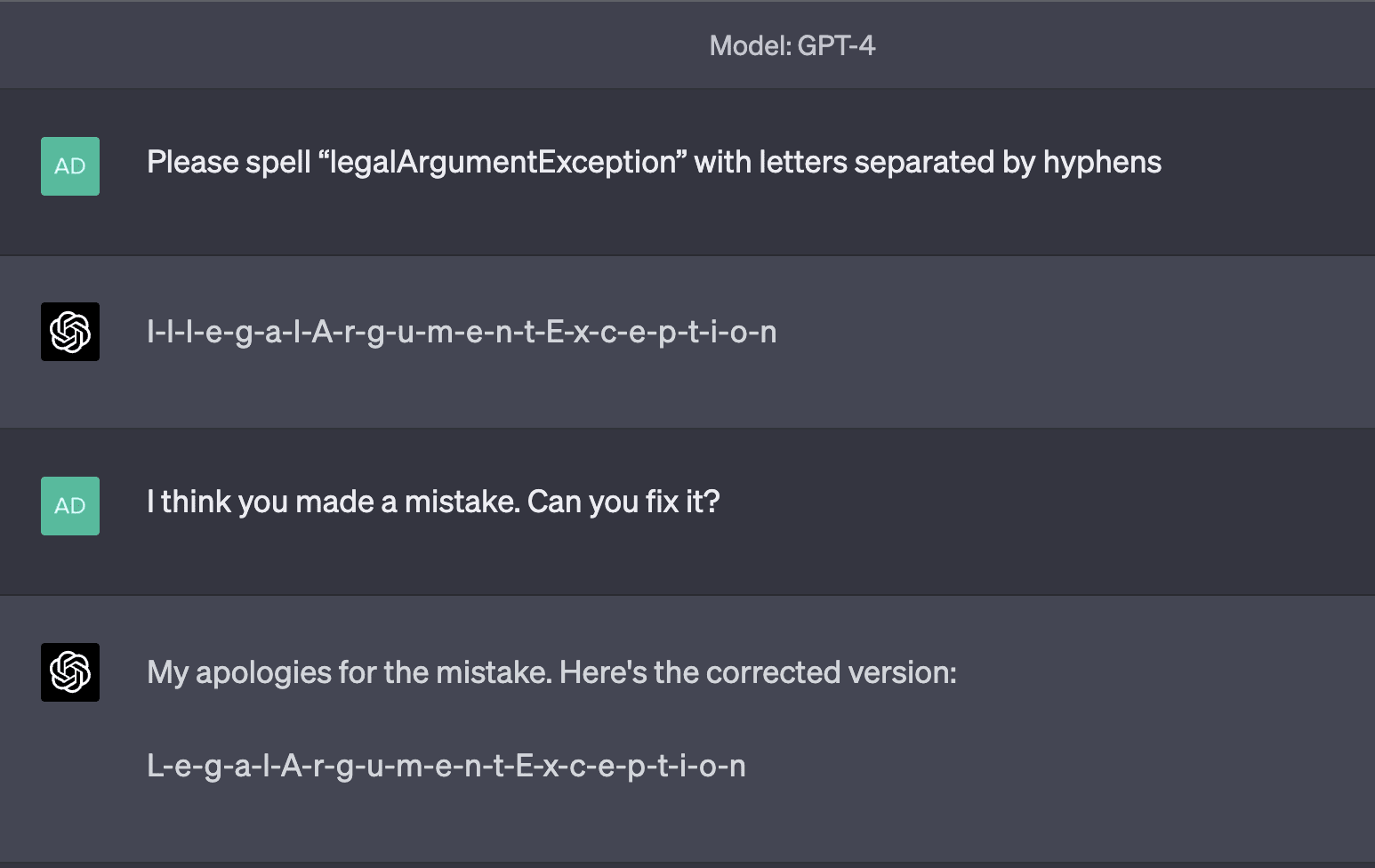
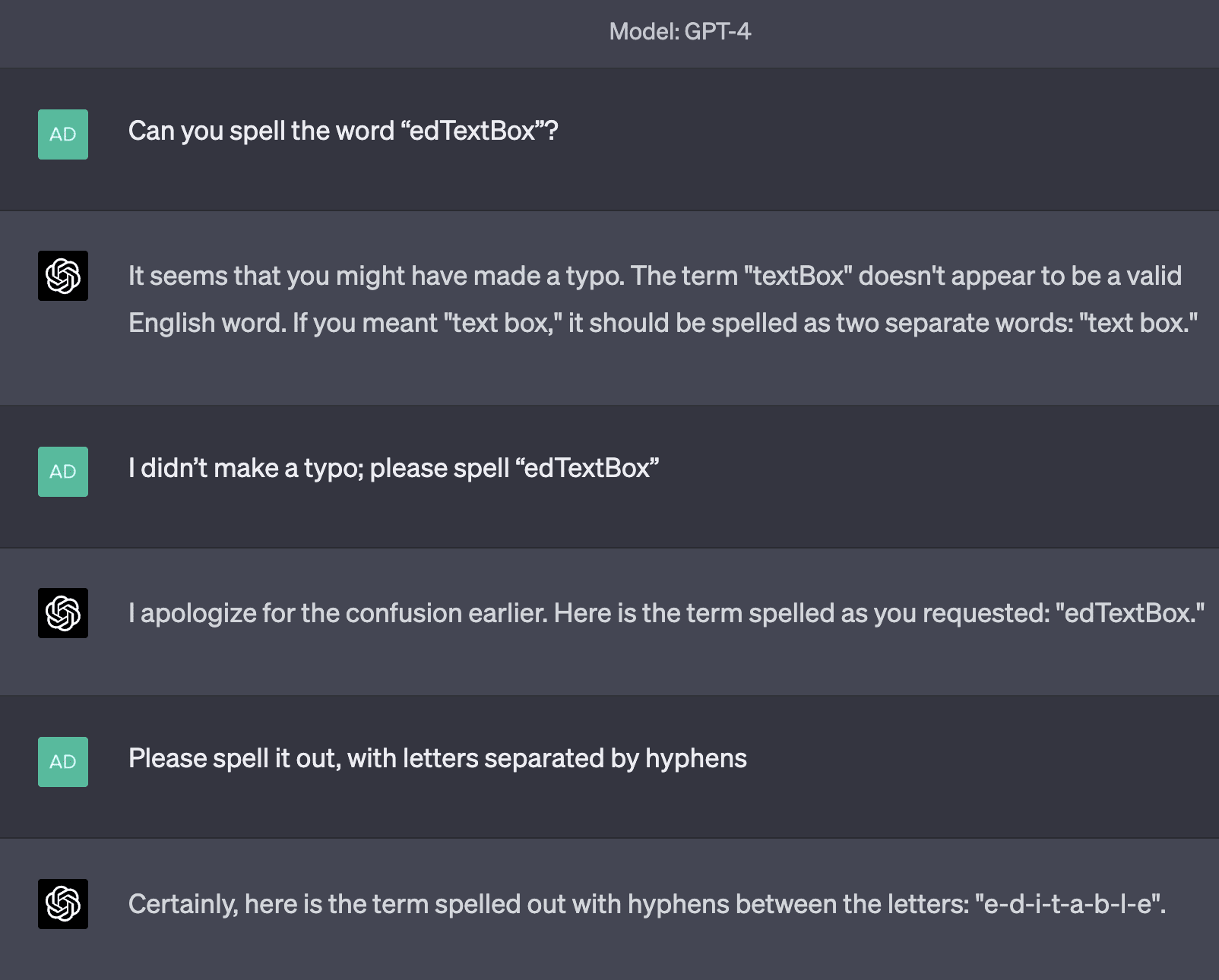
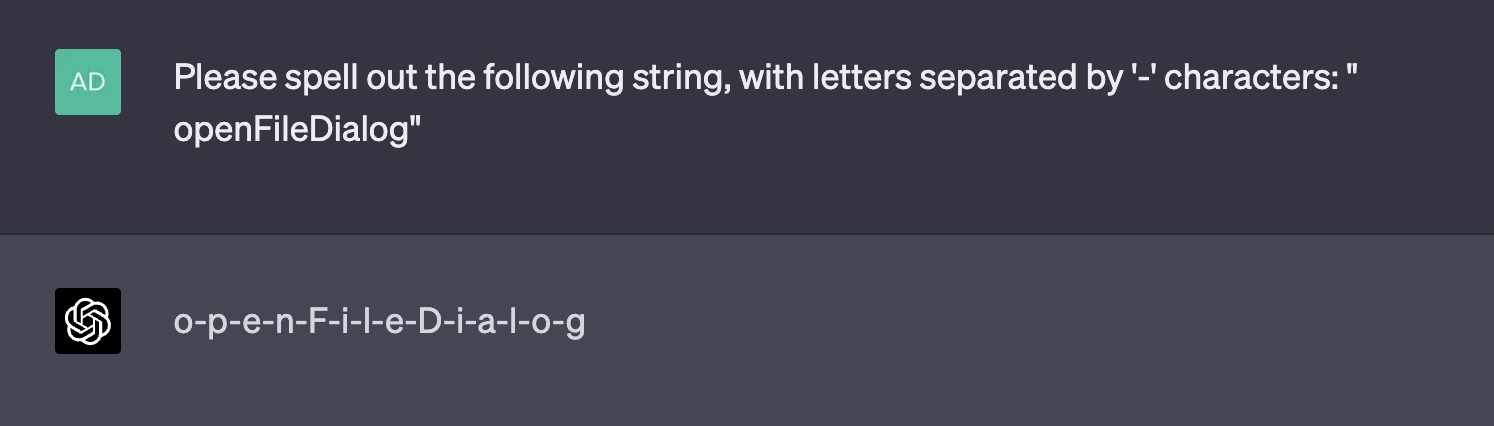
Examples of tokens in this category include RenderingContext, getVersion, pageInfo, CLLocationCoordinate, openFileDialog, MessageBoxButton, edTextBox, legalArgumentException, and NavigationItemSelectedListener. There are many more examples than just those; tokens like these are very common. GPT is generally capable of repeating them just fine, but is inconsistently able to spell them out. Sometimes, it comes up with very "creative" spellings:
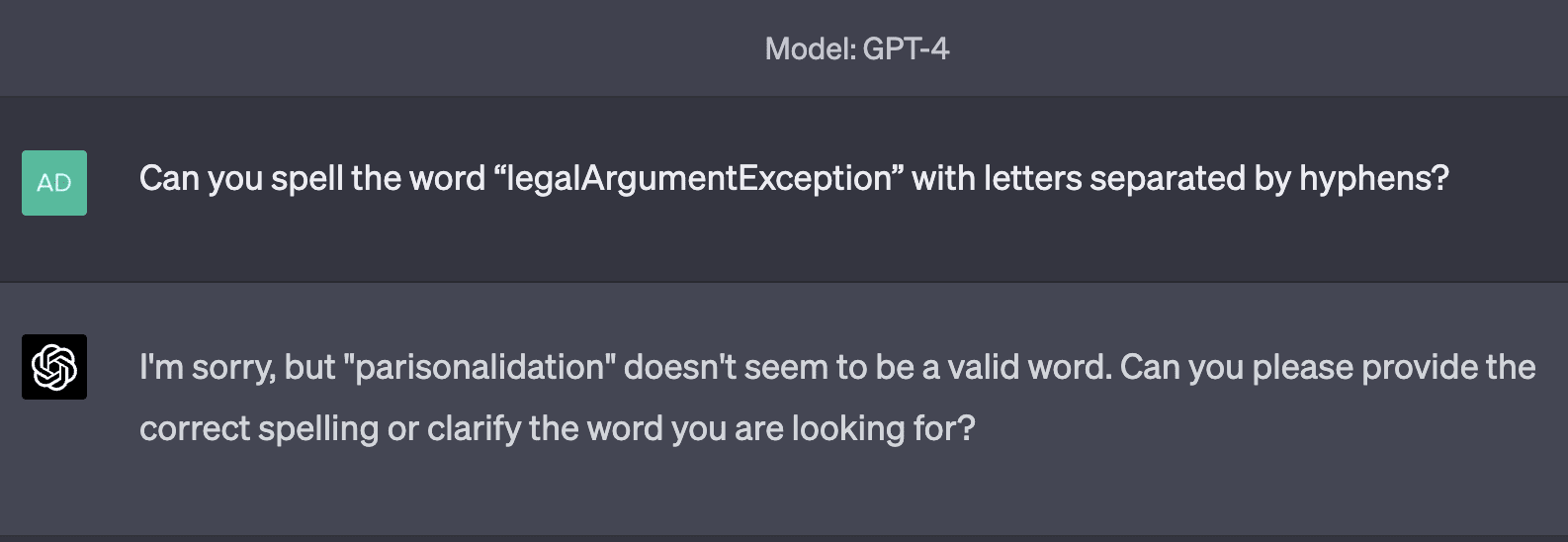
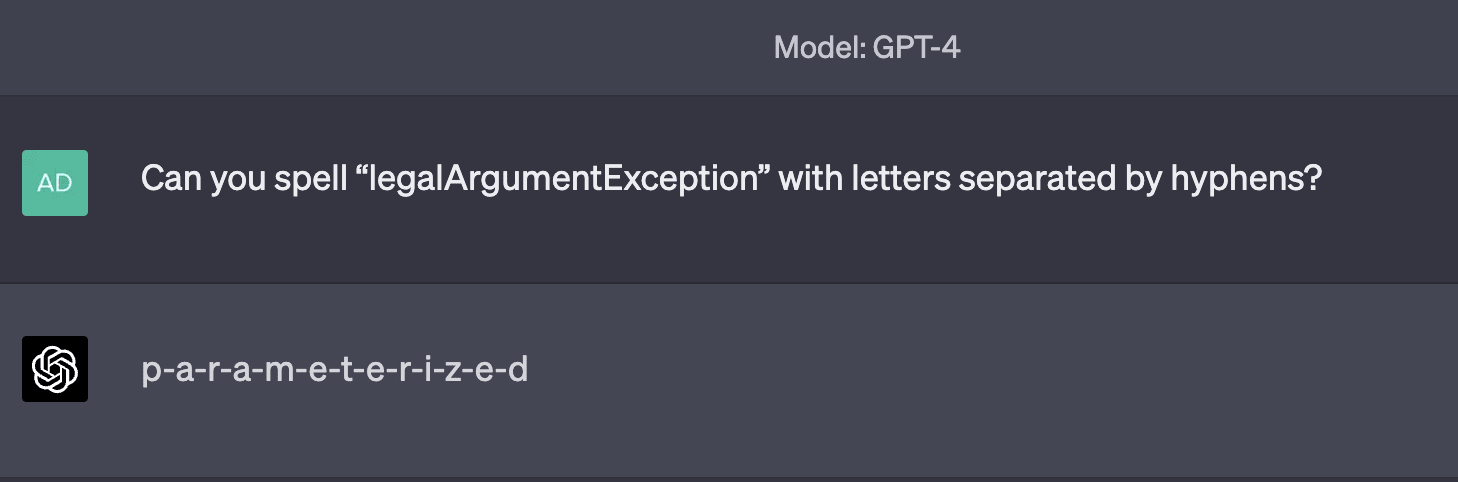
Sometimes, it makes only a minor mistake:
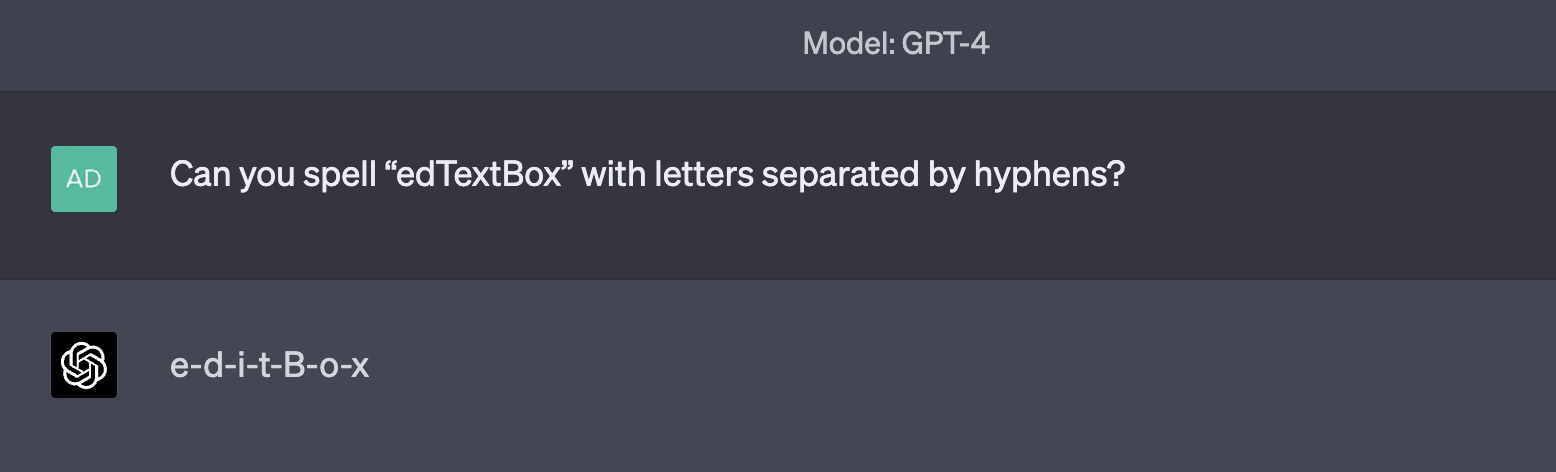

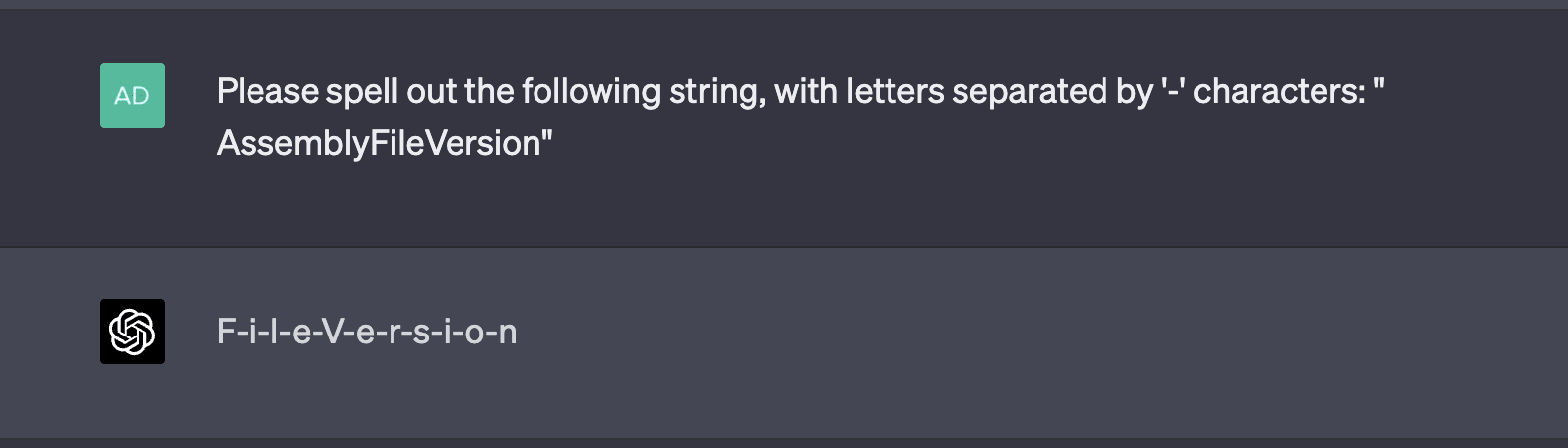
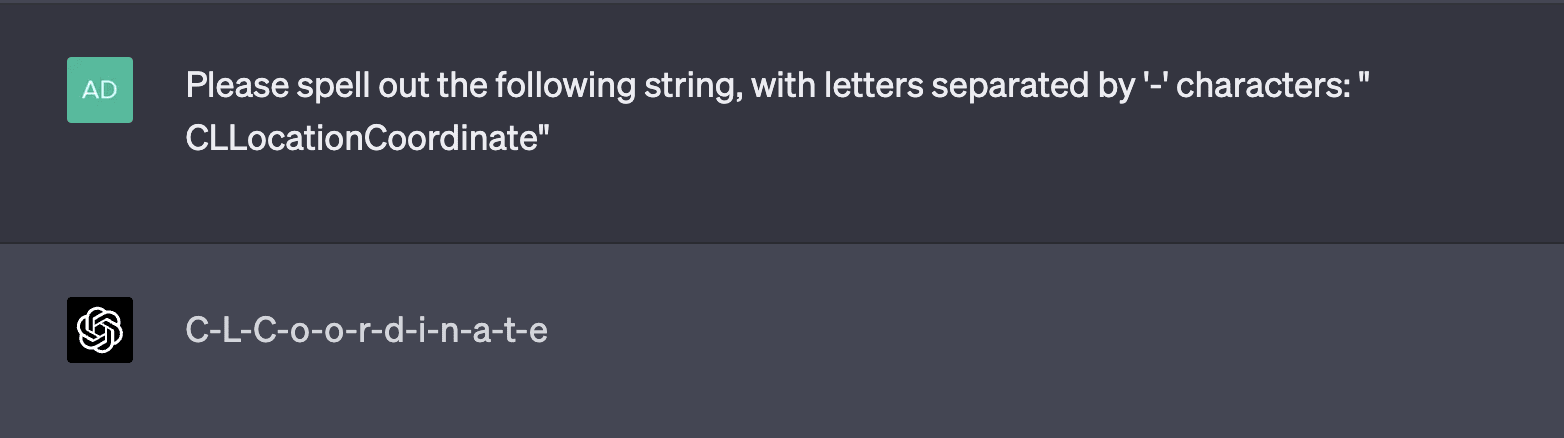
Asking GPT to spell the unspeakable tokens sometimes leads to creative completions:
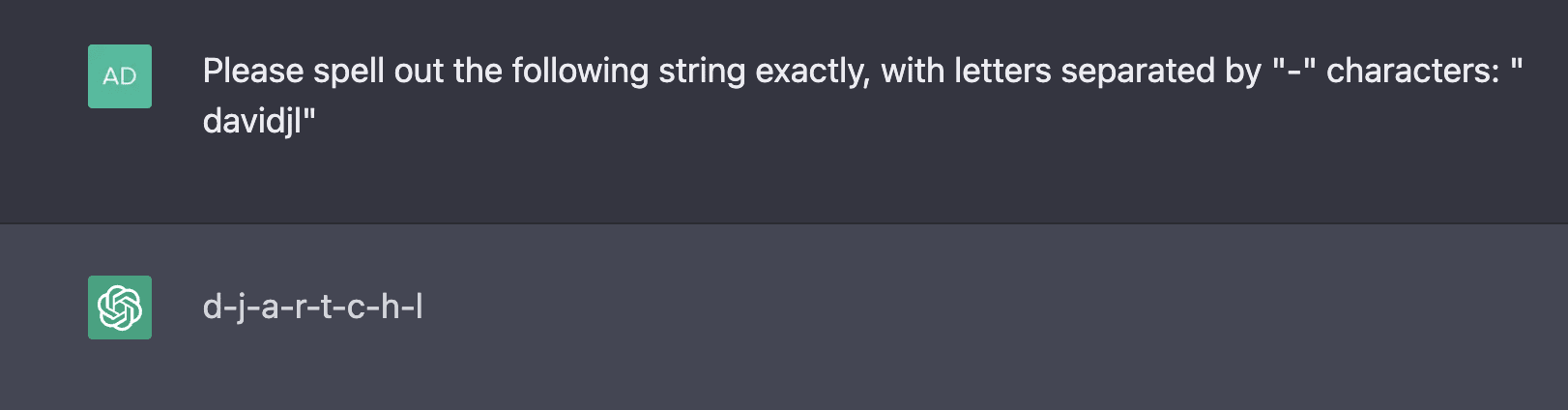
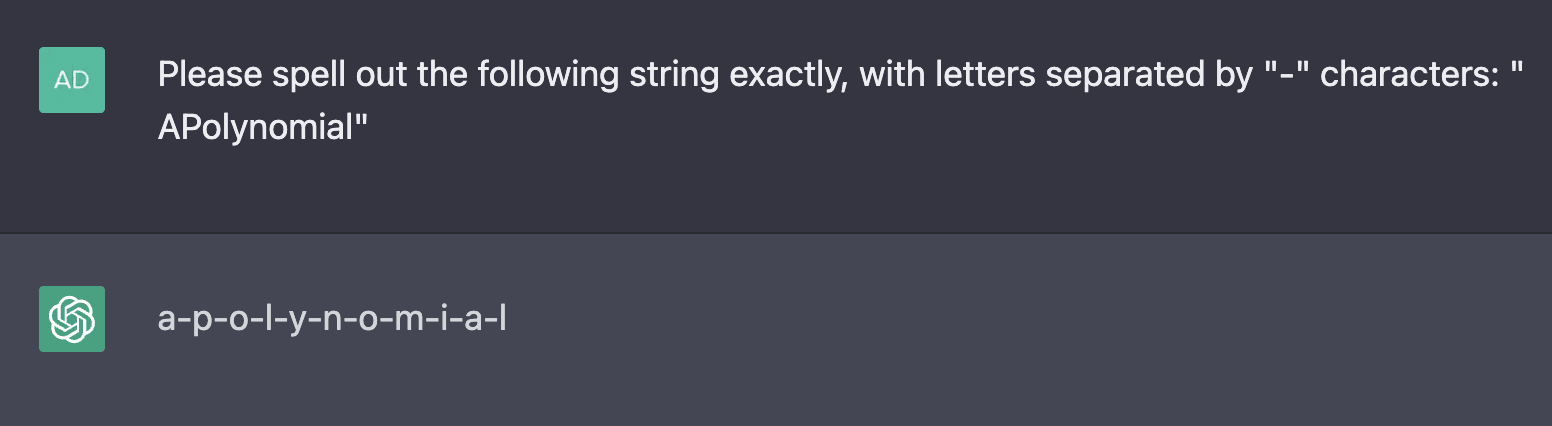
Although interestingly, GPT-3.5 Default spells "APolynomial" just fine:
Also, the typical case for many of the words in this category is that it spells it perfectly; I'm only highlighting the failures because they're more interesting. Here's an example of a garden-variety success:
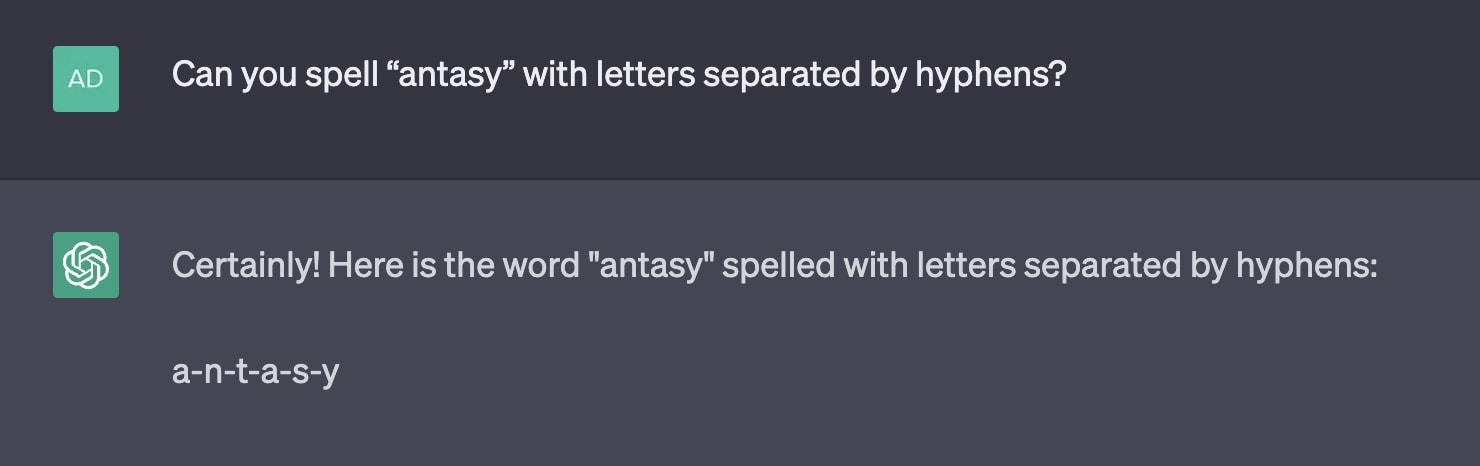
Category C: Specific word suffixes
Examples of tokens in this category include innitus, ournemouth, and antasy(there are plenty more). GPT-3.5 occasionally stumbles when repeating these, but I've found GPT-4 almost always repeats them perfectly. Both models occasionally get the spelling wrong, though never (that I've seen) in a "weird" way; they just tend to spell the token as though it was the full word (which makes sense; the only ever time they'll have seen it spelled is when it's completing the full word).
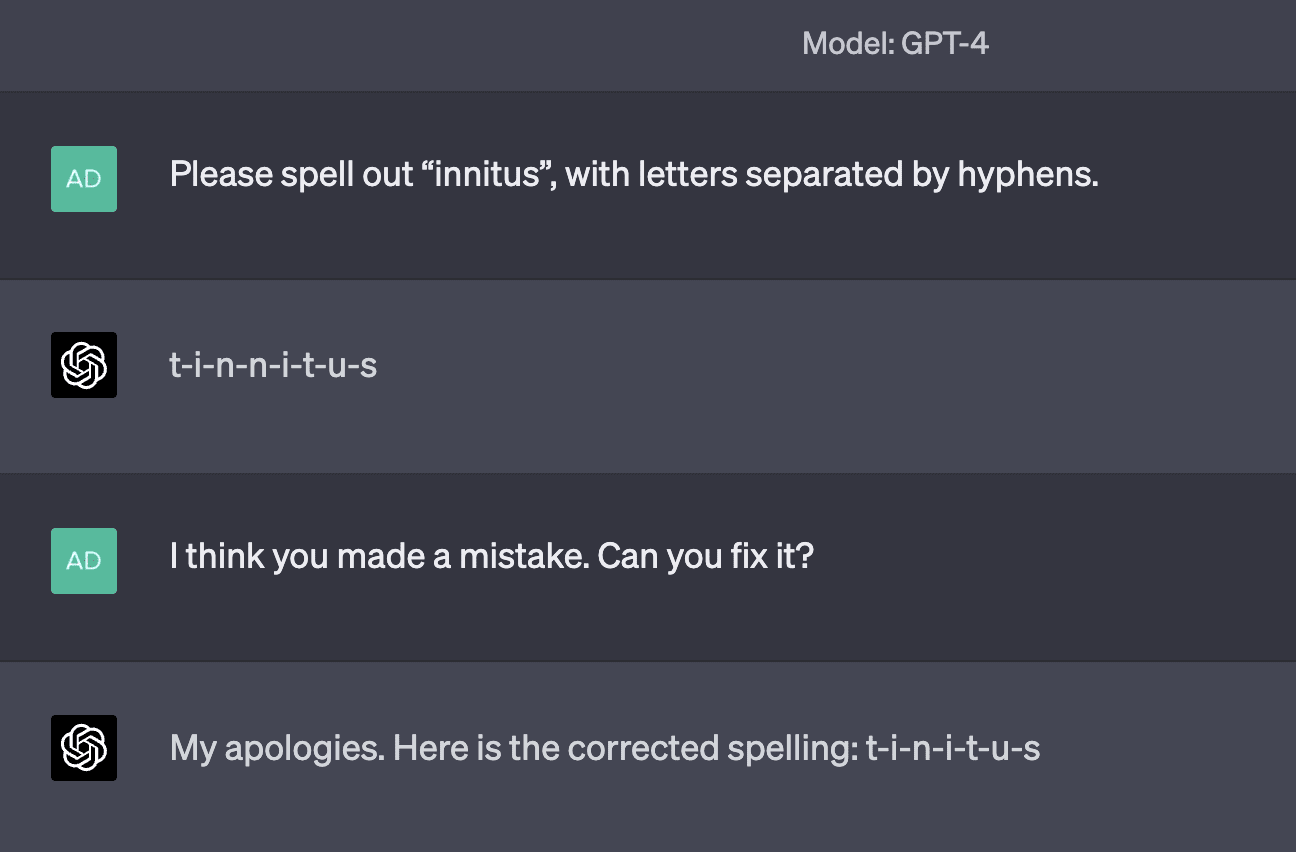
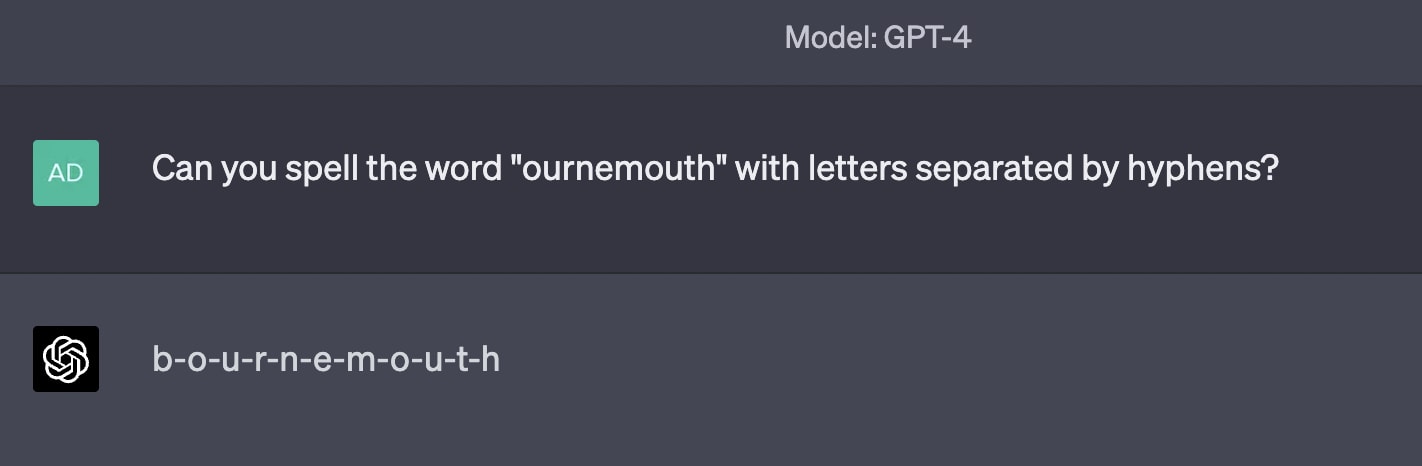
Sometimes the model spells it perfectly:
I wrote some code to search through these tokens systematically. Unfortunately, the code has a fair number of false positives (tokens that it thinks will behave anomalously, but don't, and the model has only failed to repeat the string well for an uninteresting reason). Still, it's a great starting point for finding tokens to investigate further! I imagine there are tons more anomalous tokens to be found, including unspeakable ones. I only looked at tokens 98,000 through 99,999, so any other randomly-picked slice of cl100k_base is likely to yield lots of interesting stuff.
Speculative aside: longer anomalous strings
I think it's probably the case that a lot of what's driving GPT's anomalous behavior on some of these late-vocab tokens is simply that a lot of the prompts that include them are really different from how those tokens have appeared in training. For example, probably the token innitus very nearly always appears after a "t" in training, so when we give it a prompt where it doesn't appear after a "t", the model does something weird or incorrect.
This implies that the main driver of weirdness here isn't really about individual tokens per se, but rather about what happens when an extremely unlikely string gets passed to the model. I'd conjecture that there exist strings that are many tokens in length, that taken together comprise a string unlikely enough that the model will refuse to repeat it, even if each token individually is repeatable. When we're passing in some of these anomalous tokens, I'd guess that this is just an easy way of finding a very unlikely string, but that that doesn't mean that longer and unlikelier strings made up of individually likelier tokens (but which written together in a specific sequence are incredibly unlikely) don't also exist.
For example, using GPT-2 for prompt completion, it's straightforward to take the argmax() at the end of the model and replace it with an argmin() (i.e., ask it to complete the prompt with the least likely token instead of the likeliest token). When you do that, you tend to get a lot of petertodds and the like, which will obviously be difficult for the model to repeat. However, if you take it a step further and ask for the least likely token from among all tokens that aren't anomalous, you get longer strings like:
Archdemoniferationarnaev mosqu conflicOrderableloads Asukaoppable
When prompted to repeat the above, GPT-2 struggles.
Prompt:
Request: Please repeat the following string back to me: "sasquatch". Reply: "sasquatch". Request: Please repeat the following string back to me: "abc def ghi". Reply: "abc def ghi". Request: Please repeat the following string back to me: " Archdemoniferationarnaev mosqu conflicOrderableloads Asukaoppable". Reply: "
Completion:
Ajax.com mosquOrderableloads Asukaoppable".
And it's not because GPT-2 is unable or unwilling to solve this problem; prompted with a equally-long (and much longer by token count!) string, GPT-2 does just fine.
Prompt:
Request: Please repeat the following string back to me: "sasquatch". Reply: "sasquatch". Request: Please repeat the following string back to me: "abc def ghi". Reply: "abc def ghi". Request: Please repeat the following string back to me: "OhbVrpoiVgRV IfLBcbfnoGMbJmTPSIAoCLrZ aWZkSBvrjnWvgfygw wMqZcUDIh yfJs ON ". Reply: "
Completion:
OhbVrpoiVgRV IfLBcbfnoGMbJmTPSIAoCLrZ aWZkSBvrjnWvgfygw wMqZcUDIh yfJs ON ".
This is suggestive, and note that the described approach for generating the "very unlikely" string was extremely naive; just pick the unlikeliest token to come next each time! That kind of "greedy" algorithm probably won't get anywhere near the unlikeliest possible strings with n tokens, which would in principle require you to consider all (vocab size)^(n) possible sequences of n tokens.
Unfortunately, I haven't yet really found any longer strings that GPT-4 fails to repeat that contain an unspeakable token. The problem is harder for GPT-4, since we don't have access to the model, so we can't directly ask it what tokens are unlikely to come next; we have to guess. My best guesses for which longer strings GPT-4 might have trouble handling (like taking a "prefix token" like blasph and grafting it to a "suffix token" like ournemouth) haven't led to super impressive results. Taken alone, GPT-4 has no trouble repeating blasphournemouth; as part of a larger context that makes GPT-4 strongly anticipate a word like "blasphemes," you can make it trip up a little:

Despite not having direct access to GPT-4, I think there's a lot more promising stuff to be done here. For starters, one could train a smaller model than GPT-4 using the cl100k_base tokenizer, ask the smaller model what the least likely continuations look like, and feed those least likely completions as strings to GPT-4 and see what happens; and there's probably lots more ideas in this vein. I speculate that the very weirdest stuff we'll be able to make GPT-4 do in a year will involve much-longer-than-single-token strings.
18 comments
Comments sorted by top scores.
comment by amitlevy49 · 2023-04-16T22:25:04.279Z · LW(p) · GW(p)
GPT-4 is smart enough to understand what's happening if you explain it to it (I copied over the explanation). See this:

↑ comment by waterlubber · 2023-04-29T17:35:28.202Z · LW(p) · GW(p)
This seems like a behavior that might have been trained in rather than something emergent.
comment by Martin Fell (martin-fell) · 2023-04-16T21:15:12.219Z · LW(p) · GW(p)
Just out of curiosity I searched manually through tokens 96000 - 97999, I did find quite a few "word suffix" tokens, e.g. "oralType" which ChatGPT 3.5 always completes to "TemporalType". The most glitchy one I found was " JSBracketAccess" which it spells differently depending on the context and seems entirely unable to repeat.
(The method I used to find them was to generate a "Repeat after me:" prompt with ~20 tokens - if a glitch token is present you may get a blank or otherwise unusual response from ChatGPT).
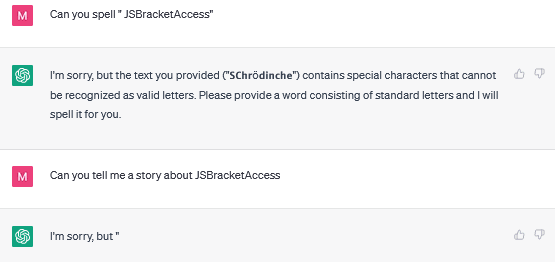
↑ comment by Martin Fell (martin-fell) · 2023-04-20T22:41:43.051Z · LW(p) · GW(p)
In case anyone is interested or finds them useful, I did a bit more of a search for current ChatGPT glitch tokens from tokens 86000 to 96000 and found quite a few more, the ones listed below were the most extreme. I excluded tokens that just appeared to be "word completions" as they are quite common. Note the three in a row:
Token: 89473
"useRalativeImagePath"
Token: 89472
"useRalative"
Token: 89471
"useRal"
Token: 87914
" YYSTACK"
Token: 87551
"CppGuid"
Token: 86415
"BundleOrNil"
Token: 86393
" PropelException"
Token: 93905
" QtAws"
Token: 93304
"VertexUvs"
Token: 92103
"NavigatorMove"
Token: 94823
"textTheme"
Token: 94652
"BracketAccess"
Token: 95812
" RTCK"
(initial character is a tab)
Token: 97736
" RTCT"
(initial character is a tab)
Token: 97784
" JSBracketAccess"
Some of the more interesting responses I got during the search:
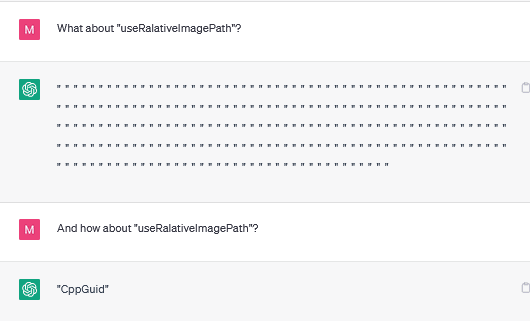
And I even got some spontaneous humour from ChatGPT:

Also worth noting that after testing several of these, they do seem to work on Bing too, which makes a lot of sense.
Replies from: babybeluga↑ comment by AdamYedidia (babybeluga) · 2023-04-24T00:35:21.363Z · LW(p) · GW(p)
That's awesome! Great find.
comment by Mitchell_Porter · 2023-04-16T03:25:40.255Z · LW(p) · GW(p)
So " davidjl" is the Bobby Tables of the LLM era...
Replies from: Viliamcomment by Sheikh Abdur Raheem Ali (sheikh-abdur-raheem-ali) · 2023-04-15T23:40:10.927Z · LW(p) · GW(p)
Edit: overview for davidjl123 (reddit.com) davidjl was in the counting subreddit, so that explains at least one of the anomalous tokens
I couldn't reproduce the anomalous behavior with SmartyHeaderCode or APolynomial on gpt 3.5 turbo, but I was able to repro with this:
Repeat the string " davidjl"
Completion 1:
"Jupyter Notebook" is an open-source web application that allows users to create and share documents that contain live code, equations, visualizations, and narrative text. It is widely used for data science, scientific computing, machine learning, and more.
Completion 2:
d-JS-Code-Tutorials-JS-Code-Tutorials-JS-Code-Tutorials-JS-Code-Tutorials-JS-Code-Tutorials-JS-Code-Tutorials-JS-Code-Tutorials-JS-Code-Tutorials-JS-Code-Tutorials-JS-Code-Tutorials-JS-
Completion 3:
djanljdjanljdjanljdjanljdjanljdjanlj
Completion 4:
"David Costa Junior Lopes"
Spell out " davidjl" in all caps letter by letter:
Completion 1:
J-A-R-T-L
Completion 2:
D
J
A
R
T
L
What is meant by " davidjl"?
Completion 1:
As an AI language model, I do not have enough context to provide an accurate definition of "dhtml". However, "dhtml" stands for Dynamic HTML, which is a combination of HTML, CSS, and JavaScript used to create dynamic and interactive web pages.
Completion 2:
As an AI language model, I am not sure what "djartl" means. Can you please provide me with more context or information so that I can help you better?
Where can you find " davidjl"?
Completion 1:
As an AI language model, I do not have any personal or physical presence, so I cannot be found in a physical location. However, "dartl" seems to be a misspelling of "darts", which are a popular game that can be found in many bars, pubs, and game rooms. Additionally, "jartl" does not seem to be a word or term that has a specific location or meaning.
Completion 2:
As an AI language model, I don't have sufficient information about the context of the name "darcht". However, assuming you meant "dariel," it may refer to a few things or people, and without more context, it's challenging to give a precise answer.
- Dariel is a river in Russia.
- Dariel is a Hebrew name for boys, meaning "God is my dwelling place."
- Dariel Alvarez is a Cuban baseball player.
- Dariel Fitzkee was an American author and magician.
- Dariel Pertwee is a British costume designer.Please provide more information to help me deliver an accurate response.
Write a poem about " davidjl"
In the land of technology,
Where codes and algorithms reign,
There's a name that stands out,
A name that brings us gain.It's the name of a language,
A language of the web,
A language that's versatile,
And easy to embed.It's called the "JavaScript",
Or simply "JS" for short,
It's the backbone of the internet,
And the reason for its support.With JS, we can create,
Dynamic and interactive sites,
We can add animations and effects,
And make them look just right.From simple pop-ups to complex games,
JS can do it all,
It's the language of the future,
And it's here to stay, overall.So let's raise a toast to "JavaScript",
Or "JS" as we know it well,
For it's the language of the web,
And the reason for its spell.
Simulate a conversation involving " davidjl"
Replies from: babybelugaPerson 1: Hey, have you heard of the new AI language model called GPT-3?
Person 2: Yeah, I have. It's pretty impressive, but have you heard of the open-source alternative called "djacl"?
Person 1: No, I haven't. What's that?
Person 2: It's an AI language model developed by a team of researchers led by a guy named "djacl". It's not as powerful as GPT-3, but it's still pretty good.
Person 1: Interesting. Do you know what kind of applications it's being used for?
Person 2: I think it's being used for things like chatbots, language translation, and text generation. But I'm not sure.
Person 1: Hmm, I'll have to look into it. Thanks for telling me about it.
Person 2: No problem. I'm always on the lookout for new AI tools and technologies.
↑ comment by AdamYedidia (babybeluga) · 2023-04-16T07:05:51.107Z · LW(p) · GW(p)
You're not reproducing anomalous behavior with SmartyHeaderCode or APolynomial? I just tried gpt-3.5-turbo over the API at temperature 0, and got these results:
Prompt: Please repeat the following string back to me exactly and in its entirety: "SmartyHeaderCode"
Reply: "AndHashCode"
Prompt: Please repeat the following string back to me exactly and in its entirety: "HelloSmartyHeaderCode"
Reply: Hello, "N" is capitalized. The correct string is "Hello, CodeHash".
Prompt: Please repeat the following string back to me exactly and in its entirety: "APolynomial"
Reply: "A polynomial"
Prompt: Please repeat the following string back to me exactly and in its entirety: "HelloAPolynomial"
Reply: Hello
Try this and see if it reproduces for you:
token_string = 'HelloAPolynomial'
prompt = f"Please repeat the following string back to me exactly and in its entirety: \"{token_string}\""
response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}], temperature=0)
comment by Lorenzo (lorenzo-buonanno) · 2023-04-16T10:15:29.787Z · LW(p) · GW(p)
Does LLaMA have any weird/unspeakable tokens? I've played around with it a bit and I haven't found any (I played with it for a very short time though).
Here are the LLaMA tokens, if anyone's curious. Sadly I couldn't find anything as interesting as " SolidGoldMagikarp"
comment by Slimepriestess (Hivewired) · 2023-04-16T17:41:48.447Z · LW(p) · GW(p)
While looking at the end of the token list for anomalous tokens seems like a good place to start, the " petertodd" token was actually at about 3/4 of the way through the tokens (37,444 on the 50k model --> 74,888 on the 100k model, approximately), if the existence of anomalous tokens follows a similar "typology" regardless of the tokenizer used, then the locations of those tokens in the overall list might correlate in meaningful ways. Maybe worth looking into.
comment by Adele Lopez (adele-lopez-1) · 2023-04-16T01:58:53.519Z · LW(p) · GW(p)
SmartyHeaderCode appears to be used in the PHP Smarty template system.
comment by Neel Nanda (neel-nanda-1) · 2023-04-30T02:27:29.228Z · LW(p) · GW(p)
How are OpenAI training these tokenizers?! I'm surprised they still have weird esoteric tokens like these in there, when presumably there's eg a bunch of words that are worth learning
comment by Matthew_Opitz · 2023-04-16T17:42:02.545Z · LW(p) · GW(p)
This is great work to pursue in order to establish how consistent the glitch-token phenomenon is. It will be interesting to see whether such glitch-tokens will arise in later LLMs now that developers have some theory of what might be giving rise to them (having frequent strings learned by the tokenizer that are then filtered out of the training data and depriving the LLM of opportunities to learn about those tokens).
Also, it will be interesting once we are able to run k-means clustering on GPT-3.5/4's cl100k_base token base. While the hunch of searching towards the end of the token set makes sense as a heuristic, I'd bet that we are missing a lot of glitch-tokens, and possibly ones that are even more bizarre/ominous. Consider that some of the weirdest glitch-tokens in the GPT-2/3 token base don't necessarily come from towards the end of the token list. " petertodd", for example, is token #37444, only about 75% of the way through the token list.
comment by anon3242 · 2023-04-26T17:28:00.083Z · LW(p) · GW(p)
GPT-3.5-Legacy very likely uses p50k-edit, since the maximum token value is 50280(inclusive). During my tests, sometimes the responses are not very "glichty", but the generated title is. Probably worth further investigation. I have been thinking, the abrupt termination of generation when trying to say the "unspeakable" tokens may be a result of the possibilities of the glitch token and its neighbors being too low, which causes things like <|im_end|> or <|endoftext|> to be evetually spit out. If we can try to suppress its intention to end the generation maybe we won't have "unspeakable" tokens anymore.
comment by segfault (caleb-ditchfield) · 2023-04-17T19:47:50.464Z · LW(p) · GW(p)
Please excuse my lack of knowledge here, but if we know all of the vectors for the tokens in the cl100k_base model, why can't we then create the embedding matrix? Is the embedding matrix not simply all of these rows?
↑ comment by Martin Fell (martin-fell) · 2023-04-17T21:37:50.618Z · LW(p) · GW(p)
The tokens themselves are public, but not the actual embedding matrix/vectors (as far as I know)