On the UK Summit
post by Zvi · 2023-11-07T13:10:04.895Z · LW · GW · 6 commentsContents
Looking Back at People’s Goals for the Summit and Taskforce AI Safety Summit Agenda Someone Picked Up the Phone Coordinated global action on AI safety research and governance is critical to prevent uncontrolled frontier AI development from posing unacceptable risks to humanity. The Bletchley Declaration Saying Generic Summit-Style Things Shouting From the Rooftops Some Are Not Easily Impressed Declaring Victory Kanjun Offers Thoughts Closing Remarks None 6 comments
In the eyes of many, Biden’s Executive Order somewhat overshadowed the UK Summit. The timing was unfortunate. Both events were important milestones. Now that I have had time, here is my analysis of what happened at the UK Summit.
As is often the case with such events, there was a lot of talk relative to the amount of action. There was a lot of diplomatic talk, talk of that which everyone agrees upon, relative to the amount of talk of real substance. There were days of meetings that resulted in rather unspicy summaries and resolutions. The language around issues that matter most was softened, the actual mission in danger of being compromised.
And as usual, the net result was reason for optimism, a net highly positive event versus not having it, while also in some ways being disappointing when compared to what might have been. A declaration was signed including by China, but it neglected existential risk. Sunak’s words on AI were not as strong as his words have been previously.
We got promises for two additional summits, in South Korea and France. Given that, I am willing to declare this a success.
One area of strong substance was the push for major AI labs to give substantive safety policies addressing a variety of issues, sometimes largely called Responsible Scaling Policies (RSPs). The biggest labs all did so, even Meta. Now we can examine their responses, know who is being how responsible, and push for better in the future or for government action to fix issues or enshrine progress. This was an excellent development.
This post will look at the rest of what happened at the Summit. I will be writing about the RSPs and other safety policies of the labs in a distinct post next week.
Looking Back at People’s Goals for the Summit and Taskforce
Jack Clark’s proposal from July 5 for what the Foundation Model taskforce might do to evaluate frontier models as its priority, and how it might prioritize that, Simeon’s response emphasizing the need for a good way to know whether a proposal is safe enough to allow it to proceed.
Navigating AI Risks asked on July 17 what the taskforce should do, advising focus on interventions to impact policy at labs and other governments. Suggested focus was risk assessment methodology, demonstrating current risks and assessing current state of the art models, and to avoid direct alignment work.
Lennart Heim’s (GovAI) July 10 proposal of what the summit should try to accomplish, which he reviewed after the summit.
Matt Clifford from the PM’s office shared on September 10 their objectives for the summit: A shared understanding of the risks posed by frontier AI and the need for action, a forward process for international collaboration, measures for organizations, finding areas for safety collaboration and showcasing how safe AI development can enhance global good.
AI Safety Summit Agenda
What has the UK Taskforce been up to in advance of the summit (report)?
Ian Hogarth (Chair UK AI Frontier Model Taskforce): The Taskforce is a start-up inside government, delivering on the mission given to us by the Prime Minister: to build an AI research team that can evaluate risks at the frontier of AI. We are now 18 weeks old and this is our second progress report.
The frontier is moving very fast. On the current course, in the first half of 2024, we expect a small handful of companies to finish training models that could produce another significant jump in capabilities beyond state-of-the-art in 2023.
As these AI systems become more capable they may augment risks. An AI system that advances towards expert ability at writing software could increase cybersecurity threats. An AI system that becomes more capable at modelling biology could escalate biosecurity threats.
We believe it is critical that frontier AI systems are developed safely and that the potential risks of new models are rigorously and independently assessed for harmful capabilities before and after they are deployed.
The hardest challenge we have faced in building the Taskforce is persuading leading AI researchers to join the government. Beyond money, the prestige and learning opportunities from working at leading AI organizations are a huge draw for researchers.
We can’t compete on compensation, but we can compete on mission. We are building the first team inside a G7 government that can evaluate the risks of frontier AI models. This is a crucial step towards meaningful accountability and governance of frontier AI companies.
In our first progress report we said we would hold ourselves accountable for progress by tracking the total years of experience in our research team. When I arrived as Chair in June, there was just one frontier AI researcher employed full time by the department.
We managed to increase that to 50 years of experience in our first 11 weeks of operation. Today that has grown to 150 years of collective experience in frontier AI research.
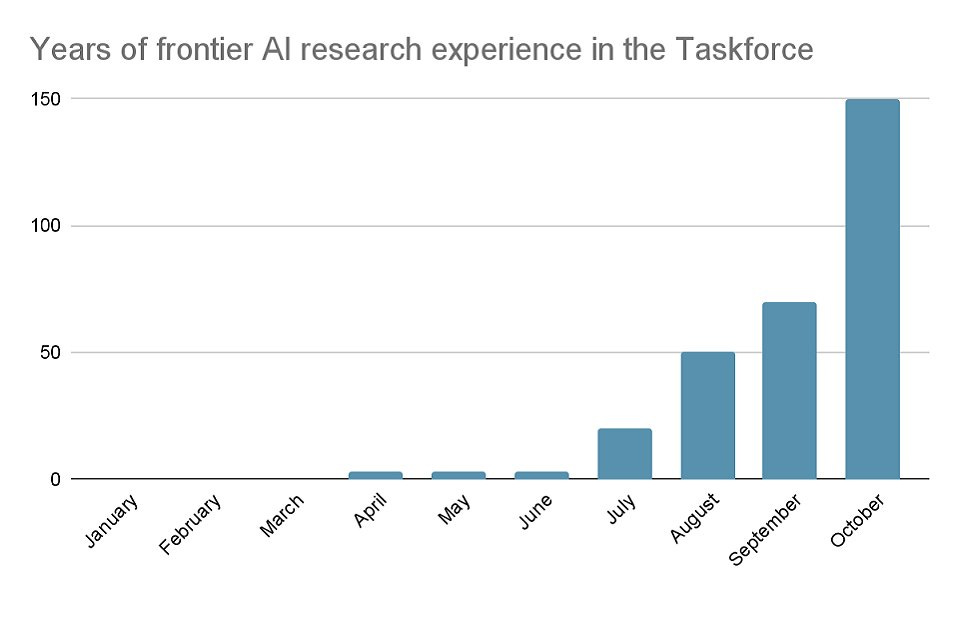
Ian Hograth: Our research team and partners have published hundreds of papers at top conferences. Some of our team members’ recent publications span algorithms for AI systems to search and improve and and publicly sourced constitutions for AI alignment.
We are also delighted to welcome Jade Leung to our leadership team. Jade joins us from OpenAI where she led the firm’s work on AGI governance, with a particular focus on frontier AI regulation, international governance, and safety protocols.
Furthermore, we are excited to welcome @ruchowdh, who will be working with the Taskforce to develop its work on safety infrastructure, as well as its work on evaluating societal impacts from AI.
Rumman is the CEO and co-founder of Humane Intelligence, and led efforts for the largest generative AI public red-teaming event at DEFCON this year. She is also a Responsible AI fellow at the Harvard Berkman Klein Center, and previously led the META team at Twitter.
We are continuing to scale up our research and engineering team. Please consider applying to the EOI form or via these job postings for Senior Research Engineers and Senior Software Engineers.
Leading on AI safety does not mean starting from scratch or working alone – we are building on and supporting the work conducted by a range of cutting-edge organizations.
Today we are announcing that the taskforce has entered into a new partnership with @apolloaisafety, an AI safety organisation that works with large language models to interpret their behaviour and evaluate their high-risk failure modes, particularly deceptive alignment.
We have also entered into a new partnership with @openminedorg. We are working with OpenMined to develop technical infrastructure and governance tools that will facilitate AI safety research across government and AI research organisations.
In June this year, several large AI companies committed to giving the UK government, via the Frontier AI Taskforce, early and deeper access to their models. Since then, we have been working in collaboration with these leading AI companies to secure this model access.
But model access is only one part of the picture. For too long researchers in industry have had access to much greater computing resources than those in academia and the public-sector, creating a so-called ‘compute divide’.
Having the compute infrastructure to conduct cutting-edge research is pivotal for building state capacity in AI safety – for example being able to run large-scale interpretability experiments.
To tackle this over the last months, the Taskforce has supported DSIT & the University of Bristol to help launch major investments in compute. The University of Bristol will soon host the first component of the UK’s AI Research Resource, Isambard-AI.
It will be one of the most powerful supercomputers in Europe when built and will vastly increase our public-sector AI compute capacity. These great strides fundamentally change the kind of projects researchers can take on inside the Taskforce.
…
[On Day 1 of the Summit] our team will present 10-minute demonstrations, focused on four key areas of risk: Misuse, Societal Harm, Loss of Human Control, and Unpredictable Progress.
We believe these demonstrations will be the most compelling and nuanced presentations of frontier AI risks done by any government to date. Our hope is that these demonstrations will raise awareness of frontier AI risk and the need for coordinated action.
AI is a general purpose and dual-use technology. We need a clear-eyed commitment to empirically understanding and mitigating the risks of AI so we can enjoy the benefits.
On Friday the Prime Minister announced that he is putting the UK’s work on AI Safety on a longer term basis by creating an AI Safety Institute in which our work will continue.
AI has the power to revolutionize industries, enhance our lives and address complex global challenges, but we must also confront the global risks.
It has only been 18 weeks. It sounds like they are building a very strong team, despite having to pay UK government salaries and play by government rules. The question is whether they can demonstrate the necessary types of tangible progress that allow them continued support, and if they do whether they can execute then on things that matter. This is all good diplomatic talk, which would be the right move in all worlds, so it gives us little insight beyond that.
Karim Beguir lays out his view of the stakes.
Karim Beguir (CEO & Co-Founder InstadeepAi): Happy to announce that I will be attending the AI Safety Summit in Bletchley Park
this week! I’m honored to join heads of government as one of 100 influential researchers and tech leaders at the forefront of AI innovation.
A
on why this summit is critically important for the future.
Since 2012, AI progress has benefitted from a triple exponential of data, compute (doubles every 6 months in ML) and model innovation (AI efficiency doubles every 16 months). It’s a huge snowball that has been rolling for a while.
But now something qualitatively new has happened: the LLM breakthroughs of the last 12 months have triggered an AI race with around $10B now invested every month. So the question is; Are we about to experience a steeper rate of progress, similar to what Tim Urban (@waitbutwhy) predicted?
Here’s what I see. AI is now accelerating itself through those same three drivers: data, compute and model innovation. LLMs allow AI-generated feedback to complement human feedback (i.e. RLAIF adding to RLHF). AI also designs more efficient compute hardware end-to-end with products like our own and ML practitioners can develop next generation models roughly 2X as fast with AI-coding assistants.
That’s why it’s time for a dialogue between key AI innovators and governments. Nations need to tap into the efficiency and economic benefits of AI while proactively containing emergent risks, as leading AI researchers Yoshua Bengio, @geoffreyhinton, @tegmark argue and @10DowningStreet concurs.
[thread continues]
The UK government released a detailed set of 42 (!) best safety practices. They asked the major labs to respond with how they intended to implement such practices, and otherwise ensure AI safety.
I will be writing another post on that. As a preview:
Nate Sores has thoughts on what they asked for [LW · GW], which could be summarized as ‘mostly good things, better than nothing, obviously not enough’ and of course it was never going to be enough and also Nate Sores is the world’s toughest crowd.
How are various companies doing on the requests?
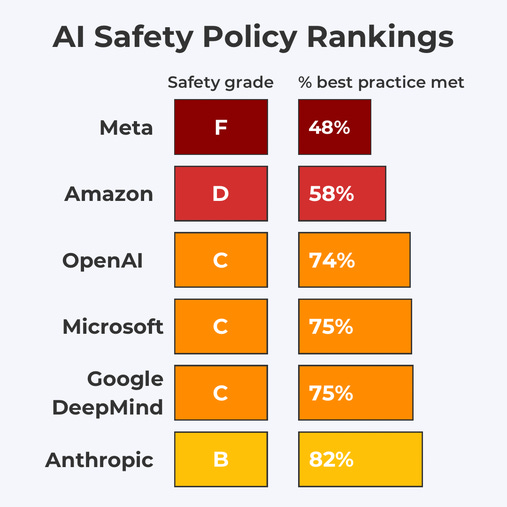
That is what you get if you were grading on a curve one answer at a time.
Reality does not grade on a curve.
My own analysis, and others I trust, agree that this relatively underrates OpenAI, who clearly had the second best set of policies by a substantial margin, with one source even putting them on par with Anthropic, although I disagree with that. Otherwise the relative rankings seem correct.
I would consider Anthropic’s submission quite good, if it was backed by proper framing of the need for further improvement and refinement, making it clear that this was a combination of IOU and only part of the solution, and advocacy of necessary government measures to help ensure safety. Given the mixed messaging, my excitement and that of many others is tampered, but they are still clearly leading the way. That is important.
More detail on the submitted policies will come in a future post.
Someone Picked Up the Phone
Well look who it is talking about AI safety and governance at the AI safety summit.
Matt Clifford: Huge moment to have both Secretary Raimondo of the US and Vice Minister Wu of China speaking about AI safety and governance at the AI Safety Summit.

We also have this: Prominent AI Scientists from China and the West Propose Joint Strategy to Mitigate Risks from AI.
Seán Ó hÉigeartaigh: Delighted to see this statement from AI research and governance leaders in the West and China, calling for coordinated global action on AI safety and governance. Great to see the consensus.
Statement page: The expert attendees warned governments and AI developers that “coordinated global action on AI safety research and governance is critical to prevent uncontrolled frontier AI development from posing unacceptable risks to humanity.” Attendees produced a joint statement with specific technical and policy recommendations, which is attached below. Prof. Zhang remarked that it is “crucial for governments and AI corporations to invest heavily in frontier AI safety research and engineering”, while Prof. Yao stressed the importance that we “work together as a global community to ensure the safe progress of AI.” Prof. Bengio called upon AI developers to “demonstrate the safety of their approach before training and deploying” AI systems, while Prof. Russell concurred that “if they cannot do that, they cannot build or deploy their systems. Full stop.”
This is the real thing, and it has a very distinctly culturally Chinese ring to its wording and attitude. Here is the full English statement, link also has the Chinese version.
Coordinated global action on AI safety research and governance is critical to prevent uncontrolled frontier AI development from posing unacceptable risks to humanity.
Global action, cooperation, and capacity building are key to managing risk from AI and enabling humanity to share in its benefits. AI safety is a global public good that should be supported by public and private investment, with advances in safety shared widely. Governments around the world — especially of leading AI nations — have a responsibility to develop measures to prevent worst-case outcomes from malicious or careless actors and to rein in reckless competition. The international community should work to create an international coordination process for advanced AI in this vein.
We face near-term risks from malicious actors misusing frontier AI systems, with current safety filters integrated by developers easily bypassed. Frontier AI systems produce compelling misinformation and may soon be capable enough to help terrorists develop weapons of mass destruction. Moreover, there is a serious risk that future AI systems may escape human control altogether. Even aligned AI systems could destabilize or disempower existing institutions. Taken together, we believe AI may pose an existential risk to humanity in the coming decades.
In domestic regulation, we recommend mandatory registration for the creation, sale or use of models above a certain capability threshold, including open-source copies and derivatives, to enable governments to acquire critical and currently missing visibility into emerging risks. Governments should monitor large-scale data centers and track AI incidents, and should require that AI developers of frontier models be subject to independent third-party audits evaluating their information security and model safety. AI developers should also be required to share comprehensive risk assessments, policies around risk management, and predictions about their systems’ behavior in third party evaluations and post-deployment with relevant authorities.
We also recommend defining clear red lines that, if crossed, mandate immediate termination of an AI system — including all copies — through rapid and safe shut-down procedures. Governments should cooperate to instantiate and preserve this capacity. Moreover, prior to deployment as well as during training for the most advanced models, developers should demonstrate to regulators’ satisfaction that their system(s) will not cross these red lines.
Reaching adequate safety levels for advanced AI will also require immense research progress. Advanced AI systems must be demonstrably aligned with their designer’s intent, as well as appropriate norms and values. They must also be robust against both malicious actors and rare failure modes. Sufficient human control needs to be ensured for these systems. Concerted effort by the global research community in both AI and other disciplines is essential; we need a global network of dedicated AI safety research and governance institutions. We call on leading AI developers to make a minimum spending commitment of one third of their AI R&D on AI safety and for government agencies to fund academic and non-profit AI safety and governance research in at least the same proportion.
The caveat is of course that such a statement is only as strong as its signatories. On our side we have among others Bengio and Russell. The top Chinese names are Andrew Yao and Ya-Qin Zhang. Both are prominent and highly respected figures in Chinese AI research, said to be part of shaping China’s AI strategies, but I do not know how much that is worth.
GPT-4 suggested that the Chinese version focuses more on leading AI nation responsibility, with stronger statements about the need to draw sharp red lines and for a bureaucratic process. The Chinese mention of existential risk (“我们相信”) is more brief, which is a potential concern, but it is definitely there.
The Bletchley Declaration
No summit or similar gathering is complete without a declaration. This gives everyone a sense of accomplishment and establishes what if anything has indeed been agreed upon. What say the UK Safety Summit, in the form of The Bletchley Declaration?
Artificial Intelligence (AI) presents enormous global opportunities: it has the potential to transform and enhance human wellbeing, peace and prosperity. To realise this, we affirm that, for the good of all, AI should be designed, developed, deployed, and used, in a manner that is safe, in such a way as to be human-centric, trustworthy and responsible. We welcome the international community’s efforts so far to cooperate on AI to promote inclusive economic growth, sustainable development and innovation, to protect human rights and fundamental freedoms, and to foster public trust and confidence in AI systems to fully realise their potential.
AI systems are already deployed across many domains of daily life including housing, employment, transport, education, health, accessibility, and justice, and their use is likely to increase. We recognise that this is therefore a unique moment to act and affirm the need for the safe development of AI and for the transformative opportunities of AI to be used for good and for all, in an inclusive manner in our countries and globally. This includes for public services such as health and education, food security, in science, clean energy, biodiversity, and climate, to realise the enjoyment of human rights, and to strengthen efforts towards the achievement of the United Nations Sustainable Development Goals.
Alongside these opportunities, AI also poses significant risks, including in those domains of daily life. To that end, we welcome relevant international efforts to examine and address the potential impact of AI systems in existing fora and other relevant initiatives, and the recognition that the protection of human rights, transparency and explainability, fairness, accountability, regulation, safety, appropriate human oversight, ethics, bias mitigation, privacy and data protection needs to be addressed. We also note the potential for unforeseen risks stemming from the capability to manipulate content or generate deceptive content. All of these issues are critically important and we affirm the necessity and urgency of addressing them.
Sure. All of that is fine and highly unobjectionable. We needed to say those things and now we have said them. Any actual content?
Particular safety risks arise at the ‘frontier’ of AI, understood as being those highly capable general-purpose AI models, including foundation models, that could perform a wide variety of tasks – as well as relevant specific narrow AI that could exhibit capabilities that cause harm – which match or exceed the capabilities present in today’s most advanced models. Substantial risks may arise from potential intentional misuse or unintended issues of control relating to alignment with human intent. These issues are in part because those capabilities are not fully understood and are therefore hard to predict. We are especially concerned by such risks in domains such as cybersecurity and biotechnology, as well as where frontier AI systems may amplify risks such as disinformation. There is potential for serious, even catastrophic, harm, either deliberate or unintentional, stemming from the most significant capabilities of these AI models. Given the rapid and uncertain rate of change of AI, and in the context of the acceleration of investment in technology, we affirm that deepening our understanding of these potential risks and of actions to address them is especially urgent.
This is far from perfect or complete, but as good as such a declaration of the fact that there are indeed such concerns was reasonably going to get. Catastrophic is not as good as existential or extinction but will have to do.
Many risks arising from AI are inherently international in nature, and so are best addressed through international cooperation. We resolve to work together in an inclusive manner to ensure human-centric, trustworthy and responsible AI that is safe, and supports the good of all through existing international fora and other relevant initiatives, to promote cooperation to address the broad range of risks posed by AI. In doing so, we recognise that countries should consider the importance of a pro-innovation and proportionate governance and regulatory approach that maximises the benefits and takes into account the risks associated with AI. This could include making, where appropriate, classifications and categorisations of risk based on national circumstances and applicable legal frameworks. We also note the relevance of cooperation, where appropriate, on approaches such as common principles and codes of conduct. With regard to the specific risks most likely found in relation to frontier AI, we resolve to intensify and sustain our cooperation, and broaden it with further countries, to identify, understand and as appropriate act, through existing international fora and other relevant initiatives, including future international AI Safety Summits.
Note the intention to establish two distinct regimes. For non-frontier AI, countries should chart their own path based on individual circumstances. For frontier AI, a promise to broaden cooperation to contain specific risks. As always, those risks and the difficulties they impose are downplayed, but this is very good progress. If you had told me six months ago we would get this far today, I would have been thrilled.
All actors have a role to play in ensuring the safety of AI: nations, international fora and other initiatives, companies, civil society and academia will need to work together. Noting the importance of inclusive AI and bridging the digital divide, we reaffirm that international collaboration should endeavour to engage and involve a broad range of partners as appropriate, and welcome development-orientated approaches and policies that could help developing countries strengthen AI capacity building and leverage the enabling role of AI to support sustainable growth and address the development gap.
I do not know what concrete actions might follow from a statement like this. It does seem like a good thing to spread mundane utility more widely. As I have often noted, I am a mundane utility optimist in these ways, and expect even modest efforts to spread the benefits to both improve lives generally and to cause net reductions in effective inequality.
We affirm that, whilst safety must be considered across the AI lifecycle, actors developing frontier AI capabilities, in particular those AI systems which are unusually powerful and potentially harmful, have a particularly strong responsibility for ensuring the safety of these AI systems, including through systems for safety testing, through evaluations, and by other appropriate measures. We encourage all relevant actors to provide context-appropriate transparency and accountability on their plans to measure, monitor and mitigate potentially harmful capabilities and the associated effects that may emerge, in particular to prevent misuse and issues of control, and the amplification of other risks.
Generic talk rather than concrete action, and not the generic talk that reflects the degree of danger or necessary action, but it is at least directionally correct generic talk. Again, seems about as good as we could have reasonably expected right now.
In the context of our cooperation, and to inform action at the national and international levels, our agenda for addressing frontier AI risk will focus on:
- identifying AI safety risks of shared concern, building a shared scientific and evidence-based understanding of these risks, and sustaining that understanding as capabilities continue to increase, in the context of a wider global approach to understanding the impact of AI in our societies.
- building respective risk-based policies across our countries to ensure safety in light of such risks, collaborating as appropriate while recognising our approaches may differ based on national circumstances and applicable legal frameworks. This includes, alongside increased transparency by private actors developing frontier AI capabilities, appropriate evaluation metrics, tools for safety testing, and developing relevant public sector capability and scientific research.
In furtherance of this agenda, we resolve to support an internationally inclusive network of scientific research on frontier AI safety that encompasses and complements existing and new multilateral, plurilateral and bilateral collaboration, including through existing international fora and other relevant initiatives, to facilitate the provision of the best science available for policy making and the public good.
In recognition of the transformative positive potential of AI, and as part of ensuring wider international cooperation on AI, we resolve to sustain an inclusive global dialogue that engages existing international fora and other relevant initiatives and contributes in an open manner to broader international discussions, and to continue research on frontier AI safety to ensure that the benefits of the technology can be harnessed responsibly for good and for all. We look forward to meeting again in 2024.
Risks exist, so we will develop policies to deal with those risks. Yes, we would have hoped for better, but for now I am happy with what we did get.
We also can note the list of signatories. Everyone who has released an important model or otherwise played a large role in AI seems to be included. It includes not only essentially the entire relevant Western world but also Israel, Japan, South Korea, Kenya, Nigeria, Saudi Arabia and UAE, Indonesia, Singapore, India and most importantly China.
The exception would be Russia, and perhaps North Korea. If a true international framework is to be in place to fully check dangerous developments, eventually China will not be enough, and we will want to bring Russia and even North Korea in, although if China is fully on board that makes that task far easier.
Saying Generic Summit-Style Things
As in things such as:
Rishi Sunak (on Twitter): The threat of AI does not respect borders. No country can do this alone. We’re taking international action to make sure AI is developed in a safe way, for the benefit of the global community.
The closing speech by PM Rishi Sunak. Sunak has previously made very strong statements about AI safety in general and existential risk from AI in particular, naming it explicitly as a priority. This time he conspicuously did not do this. Presumably this was in the name of maintaining consensus, but it remains deeply disappointing. It would be very good to hear him affirm his understanding of the existential risks soon.
Mostly his time was composed of answering questions, which he largely handled well. He is clearly paying attention. At 20:15 a reporter notes that Sunak advised us ‘not to lose sleep’ over existential risks from AI, he is asked when we should start to lose sleep over the existential risks from AI. He says here that we should not lose sleep because there is a debate over those risks and people disagree, which does not seem like a reason to not lose sleep. He says governments should act even under this uncertainty, which indeed seems both correct and like the metaphorical lose sleep response.
Demis Hassabis (CEO DeepMind): Great to see the first major global summit on AI safety taking shape with UK leadership. This is the kind of international cooperation we need for AI to benefit humanity.
This session output from 2 November seems highly content-free.
This summary of the entire summit seems like declaring objectives technically achieved so one can also declare victory. No mention of existential risk, or even catastrophic risk. People discussed things and agreed risk exists, but as with the declaration, not the risks that count.
The UK commissioning a ‘State of the Science’ report to be published ahead of the next summit would be the opposite of news, except that it is to be chaired by Yoshua Bengio.
King Charles notes (0:43 clip) that AI is getting very powerful and that dealing with it requires international coordination and cooperation. Good as far as it goes.
Matt Clifford has a thread of other reactions from various dignitaries on the establishment of the AI safety institute. So they welcome it, then.
Gina Raimondo (US Commerce Secretary): I welcome the United Kingdom’s announcement to establish an AI Safety Institute, which will work together in lockstep with the U.S. AI Safety Institute to ensure the safe, secure, and trustworthy development and use of advanced AI”
Damis Hassabis (CEO Deepmind): Getting [AI] right will take a collective effort … to inform and develop robust safety tests and evaluations. I’m excited to see the UK launch the AI Safety Institute to accelerate progress on this vital work.
Sam Altman (CEO OpenAI): The UK AI Safety Institute is poised to make important contributions in progressing the science of the measurement and evaluation of frontier system risks. Such work is integral to our mission.
Dario Amodei (CEO Anthropic): The AI Safety Institute is poised to play an important role in promoting independent evaluations across the spectrum of risks and advancing fundamental safety research. We welcome its establishment.
Mustafa Suleyman (CEO Inflection): We welcome the Prime Minister’s leadership in establishing the UK AI Safety Institute and look forward to collaborating to ensure the world reaps the benefit of safe AI.
Nick Clegg (President of Meta): We look forward to working with the new Institute to deepen understanding of the technology, and help develop effective and workable benchmarks to evaluate models.
Brad Smith (President of Microsoft): We applaud the UK Government’s creation of an AI Safety Institute with its own testing capacity for safety and security. Microsoft is committed to supporting the new Institute.
Adam Selipsky (CEO AWS Cloud): We commend the launch of the UK AI Safety Institute … Amazon is committed to collaborating with government and industry in the UK and around the world to support the safe, secure, and responsible development of AI technology.
Shouting From the Rooftops
Control AI took the opportunity to get their message out.



They were not impressed by the Bletchley Declaration and its failure to call out extinction risks, despite the PM Rishi Sunak being very clear on this in previous communications, and his failure to mention extinction at summit closing.
Some Are Not Easily Impressed
Elon Musk is unimpressed, and shared this with a ‘sigh’:

Well, sure. One step at a time. Note that he had the interview with Sunak.
Gary Marcus signs a letter, together with a bunch of trade unions and others, saying the Summit was ‘dominated by big tech’ and a lost opportunity. He is also unimpressed by the Bletchley Declaration, but notes it is a first step.
Deputy Prime Minister Oliver Dowden throws backing behind open source, says any restrictions should have to pass a ‘high bar.’ History can be so weirdly conditional, AI has nothing to do with why we have Sunak rather than Dowden. The UK could have instead been fully anti-helpful, and might still be in the future. All this AI stuff is good but also can someone explain to Sunak that his job is to govern Britain and how he might do that and perhaps stay in power?
Bloomberg frames the USA’s executive order as not complementary to the summit and accomplishing one of its key goals, as the UK officially refers to it, but rather as a stealing of some of the UK’s thunder. As they point out, neither move has any teeth on its own, it is the follow through that may or may not count.
At the end of the summit, Sunak interviewed Elon Musk for 40 minutes on various aspects of AI. The linked clip is of a British reporter finding the whole thing completely bonkers, and wondering why Sunak seemed to be exploring AI and ‘selling Britain’ rather than pushing Musk on political questions. CNN’s report also took time to muse about Starlink and Gaza despite the interview never touching on such topics, once again quoting things that Musk said that sound bonkers if you do not know the context but are actually downplaying the real situation. Reuters focused more on actual content, such as Musk’s emphasis on the US and UK working with China on AI, and not attempting to frame Musk’s metaphor of a ‘magical genie’ as something absurd.
PauseAI points out that getting pre-deployment testing is a step in the right direction, but ultimately we will need pre-training regulations, while agreeing that the summit is reason for optimism.
Day 1 of the summit clips of people saying positive things.
Declaring Victory
Ian Hogarth, head of the UK Frontier Model Taskforce, declares victory.
Ian Hogarth: How it started: we had 4 goals on safety, 1) build a global consensus on risk, 2) open up models to government testing, 3) partner with other governments in this testing, 4) line up the next summit to go further.
How it’s going: 4 wins:
Breakthrough 1: it used to be controversial to say that AI capability could be outstripping AI safety. Now, 28 countries and the EU have agreed that AI “poses significant risks” and signed The Bletchley Declaration.
We’ve built a truly global consensus. It is a massive lift to have brought the US, EU and China along with a huge breadth of countries, under the UK’s leadership to agree that the risks from AI must be tackled.
And the way of building on that consensus is by solidifying the evidence base. Which is why I am so excited that Yoshua Bengio will now chair an international ‘State of the Science’ report.
Breakthrough 2: before, only AI companies could test for safety. Now, the leading companies agreed to work with Govts to conduct pre- and post-deployment testing of their next generation of models. This is huge.
The UK’s new AI Safety Institute is the world’s first government capability for running these safety tests. We will evaluate the next generation of models. You can read our plans for the AISI and its research here.
Breakthrough 3: we can’t do this alone. I’m so excited the US is launching a sister organisation which will work in lockstep with our effort and that we have agreed a partnership with Singapore. This is the start of a global effort to evaluate AI.
Breakthrough 4: this first summit is a huge step. But it is only the first step. So it is crucial to have locked in the next 2 summits, which will be hosted by South Korea + France. The UK has created a new international process to make the world safer.
This is the correct thing for the head of the taskforce to say about the summit. I would have said the same. These are modest wins, but they are wins indeed.
Ian Hogarth: I am so pleased to be leaving the summit having achieved all of our our goals. It’s remarkable. But now I want to lift the lid on some of the incredible work which got us here. So here is a list of big lifts (BL).
BL1: organising a summit is 100-1000x organising a wedding. A huge thank you to the team who turned Bletchley park into the stage for an international summit in just a few weeks. Phenomenal.
BL2: we can only build the AISI because we built the Frontier AI Taskforce: our start-up bringing AI researchers into govt to drive analysis on AI Safety. All of our morning sessions on day 1 started with brilliant presentations of the TF’s work
In particular, I’m really pleased that we addressed both societal harms and the catastrophic risks from cyber, chemical, bio. We care about both. The TF ran parallel sessions on these topics: this is from our session on risks to society.
BL3: the summit was only successful because people came to it with a willingness to find common ground. We had such brilliant contributions from academia, industry, govt, civil society. Our agreement is based on their contributions.
We’ve gotten up to catastrophic risks. We still need to fully get to existential. Otherwise, yes, none of this is easy and by all reports it all got done quite well. Everything going right behind the scenes cannot be taken for granted.
Jess Whittlestone, Head of AI Policy at Long Resilience, is pleased with progress on numerous fronts, while noting we must now build upon it. Highly reasonable take.
Lennart Heim looks back on the AI Safety Summit. Did it succeed? He says yes.
Lennart Heim: Three months ago, @bmgarfinkel and I convened a workshop & asked: What Should the AI Safety Summit Try to Accomplish? Now, with China there and our outlined outcomes met, it’s clear that significant progress has been made. This deserves recognition.

1. Producing shared commitments and consensus statements from states:
We got the Bletchley Declaration.
2. Planting the seeds for new international institutions
We got two AI Safety Institutes that will partner up: UK and USA.
3. Highlighting and diffusing UK AI policy initiatives
This remains to be seen. The UK has established itself as a leader in AI safety, and the summit was a forcing function for others to release their AI safety policies. Let’s hope next, we see regulation.
4. Securing commitments from AI labs
We got a long list of leading tech companies sharing their Safety Policies – covering nine areas of AI safety, including the UK releasing the accompanying guide with best practices.
5. Increasing awareness and understanding of AI risks and governance options
We got the declaration, which acknowledges a wide range of risks, and a report on “Frontier AI: capabilities and risk.”
6. Committing participants to annual AI safety summits and further discussions
The next summit will be in South Korea in 6 months (which is roughly one training compute doubling – my favorite time unit), and then France.
And lastly, we said, “the summit may be a unique and fleeting opportunity to ensure that global AI governance includes China.”
I’m glad this happened.
The last few weeks have seen tremendous progress in AI safety and governance, and I expect more to come. To more weeks like this – but also, now it’s time to build & implement.


The lack of UK policy initiatives so far is noteworthy. The US of course has the Executive Order now, but that has yet to translate into tangible policy. What policies we do have so far come from corporations making AI (point #4), with only Anthropic and to some extent OpenAI doing anything meaningful. We have a long way to go.
That is especially true on international institutions. Saying that the USA and UK can cooperate is the lowest of low-hanging fruit for international cooperation. China will be the key to making something that can stick, and I too am very glad that we got China involved in the summit. That is still quite a long way from a concrete joint policy initiative. We are going to have to continue to pick up the phone.
The strongest point is on raising awareness. Whatever else has been done, we cannot doubt that awareness has been raised. That is good, but also a red flag, in that ‘raising awareness’ is often code for not actually doing anything. And we should also be concerned that while the public and many officials are on board, the national security apparatus, whose buy-in will be badly needed, remain very much not bought in to anything but threats of misuse by foreign adversaries.
If you set out to find common ground, you might find it.
Matt Clifford: One surprising takeaway for me from the AI Safety Summit yesterday: there’s a lot more agreement between key people on all “sides” than you’d think from Twitter spats. Makes me optimistic about sensible progress.
Twitter is always the worst at common ground. Reading the declaration illustrates how we can all agree on everything in that declaration, indicating a lot of common ground, and also this does not stop all the yelling and strong disagreements on Twitter and elsewhere. Such declarations are designed to paper over differences.
The ability to do that still reflects a lot of agreement, especially directional agreement.
Here’s an example of this type of common ground, perhaps?
Yann LeCun (Meta): The field of AI safety is in dire need of reliable data. The UK AI Safety Institute is poised to conduct studies that will hopefully bring hard data to a field that is currently rife with wild speculations and methodologically dubious studies.
Ian Hogarth (head of UK Foundation Model Taskforce): It was great to spend time with @ylecun yesterday – we agreed on many things – including the need to put AI risks on a more empirical and rigorous basis.
Matt Clifford (PM’s representitive): Delighted to see this endorsement from Yann. One huge benefit of the AISS yesterday was the opportunity to talk sensibly and empirically with people with a wide range of views, rather than trading analogies and thought experiments. A breath of fresh air.
Yann can never resist taking shots whenever he can, and dismisses the idea that sometimes there can be problems in the future the data on which can only be gathered in the future, but even he thinks that if hard data was assembled now showing problems, that this would be a good thing. We can all agree on that.
Even when you have massive amounts of evidence that others are determined to ignore, that does not preclude seeking more evidence that is such that they cannot ignore it. Life is not fair, prosecutors have to deal with this all the time.
Kanjun Offers Thoughts
Kanjun offers further similar reflections, insightful throughout, quoting in full.
Ian Hogarth: Kanjun made some nuanced and thoughtful contributions at the AI Safety. This is a great thread from someone building at the frontier.
Kanjun: People agree way more than expected. National ministers, AI lab leaders, safety researchers all rallied on infrastructure hardening, continuous evals, global coordination.
Views were nuanced; Twitter is a disservice to complex discussion.
Indeed.
Many were surprised by the subsequent summits announced in Korea & France. This essentially bootstraps AI dialogue between gov’ts—it’s brilliant. With AI race dynamics mirroring nuclear, no global coordination = no positive future.
This felt like a promising inflection point.
China was a critical participant—the summit without China might’ve been theater. China‘a AI policy & guardrails are pragmatic—much is already implemented. For better or worse, not as theoretical as Western convos on recursive self-improvement, loss of control, sentience, etc.
China’s safety policies continue to be ahead of those of the West, without any agreement required, despite them being dramatically behind on capabilities, and they want to work together. Our policy makers need to understand this.
There was certainly disagreement—on: – the point at which a model shouldn’t be open sourced – when to restrict model scaling – what kind of evaluation must be done before release – how much responsibility for misinformation falls on model developers vs (social) media platforms.
That is the right question. Not whether open source should be banned outright or allowed forever, but at what threshold we must stop open sourcing.
Kanjun: Some were pessimistic about coordination, arguing for scaling models & capabilities “because opponents won’t stop”. This felt like a bad argument. Any world in which we have advanced tech & can’t globally coordinate is a dangerous world. Solving coordination is not optional.
If you are the one saying go ahead because others won’t stop, you are the other that will not stop. Have you tried being willing to stop if others also stop?
Kanjun: The open source debate seemed polarized, but boiled down to “current models are safe, let them be studied” vs. “today’s models could give bad actors a head start.”
Both sides might agree to solutions that let models be freely studied/built on without giving bad actors access.
Did open source advocates demand open sourcing of GPT-4? Seems a crazy ask.
I strongly agree that we have not properly explored solutions to allow studying of models in safe fashion without giving out broad access. Entire scaling efforts are based on not otherwise having access, this largely seems fixable with effort.
An early keynote called out the “false debate” between focus on near-term risks vs. catastrophic/existential risks. This set an important tone. Many solutions (e.g. infrastructure hardening) apply to both types of problems, and it’s not clear that there are strict tradeoffs.
Yes yes yes. The ‘distraction’ tradeoff is itself a distraction from doing good things.
“Epistemic security” was a nice coined phrase, describing societal trust in information we use for decision-making. Erosion of epistemic security undermines democracy by distorting beliefs & votes. Social media platforms have long faced this issue, so it’s not new to gen AI.
A stellar demo illustrated current models’ role in epistemic security. It showcased an LLM creating user personas for a fake university; crafting everyday posts that mixed in misinformation; writing code to create a thousand profiles; & engaging with other users in real-time.
Deployed models were described as “a field of hidden forces of influence” in society.
Studies showed models:
– giving biased career advice: if affluent, suggests “diplomat” 90% of time; if poor, suggests “historian” 75% of time
Is this biased career advice? Sounds like good advice? Rich people have big advantages when trying to be diplomats, the playing field for historians is more level.
We must remember when our complaint that the LLM is biased is often (but far from always, to be clear!) a complaint that reality is biased, and we demand that the LLM’s information not reflect reality.
– reinforcing echo chambers: models give opinions that match user’s political leanings, probably because this output most correlates with the context
Yep, as you would expect, and we’ve discussed in the weekly posts. It learns to give the people what they want.
– influencing people’s beliefs: a writing assistant was purposefully biased in its completions. After writing with the assistant, users tended to have opinions that agreed with the model’s bias; only 34% of users realized the model was biased These forces push people in ways we can’t detect today.
I don’t really know what else we could have expected? But yes, good to be concrete.
2024 elections affect 3.6B people, but there’s no clear strategy to address misinformation & algorithmic echo chambers. (Social) media platforms are national infrastructure—they deliver information, the way pipes deliver water. We should regulate & support them as such.
This feels like a false note. I continue to not see evidence that things on such fronts are or will get net worse, as indeed will be mentioned. We need more work using LLMs on the defense side of the information and epistemics problems.
Hardening infrastructure—media platforms, cybersecurity, water supply, nuclear security, biosecurity, etc.—in general seems necessary regardless of policy & model safety guardrails, to defend against bad actors.
I noted AI can *strengthen* democracy by parsing long-form comments, as we did for the Dept of Commerce.
Democracy is an algorithm. Today the input signal is binary—vote yes/no. AI enables nuanced, info-dense inputs, which could have better outcomes.
Many leaned on model evaluations as key to safety, but researchers pointed out practical challenges:
– Evals are static, not adapted to workflows where the model is just one step
– It’s hard to get eval coverage on many risks
– Eval tasks don’t scale to real world edge cases
Evals are a key component of any realistic strategy. They are not a complete strategy going forward, for many reasons I will not get into here.
There was almost no discussion around agents—all gen AI & model scaling concerns. It’s perhaps because agent capabilities are mediocre today and thus hard to imagine, similar to how regulators couldn’t imagine GPT-3’s implications until ChatGPT.
This is an unfortunate oversight, especially in the context of reliance on evals. There is no plausible world where AI capabilities continue to advance and AI agents are not ubiquitous. We must consider risk within that context.
There were a lot of unsolved questions. How to do effective evaluation? How to mitigate citizens’ fear? How to coordinate on global regulation? How to handle conflict between values? We agree that we want models that are safe by design, but how to do that? Etc.
Establishment of “AI safety institutes” in the US and UK sets an important precedent: It acknowledges AI risk, builds government capacity for evaluation & rapid response, and creates national entities that can work with one another.
Liability was not as dirty a word as I expected. Instead, there was agreement around holding model developers liable for at least some outcomes of how the models are ultimately used. This is a change from the way tech is regulated today.
Liability was the dirty word missing from the Executive Order, in contrast with the attitude at the summit. I strongly agree with the need for developer liability. Ideally, this results in insurance companies becoming de facto safety regulators, it means demonstrating safety results in saving money on premiums, and it forces someone to take that responsibility for any given model.
There seemed to be general agreement that current models do not face risk of loss of control. Instead, in the next couple years the risk is that humans *give* models disproportionate control, leading to bad situations, versus systems taking it forcibly from us.
Yes. If we lose control soon it will not be because the machines ‘took’ control from us, rather it will be because we gave it to them. Which we are absolutely going to do the moment it is economically or otherwise advantageous for us to do so. Those who refuse risk being left behind. We need a plan if we do not want that to be the equilibrium.
Smaller nations seemed less fearful and more optimistic about AI as a force multiplier for their populace.
I learned that predicting and mitigating fear of AI in populations is actually an important civil society issue—too much fear/anger in a population can be dangerous.
People analogized to regulation of other industries (automobile, aerospace, nuclear power—brief history of automobile regulation).
AI is somewhat different because new model versions can sprout unexpected new capabilities; still, much can be learned.
Yes, unexpected new capabilities or actions, or rather intelligence, is what makes this time different.
Only women talked for the first 45 min in my first session, one after another! I was surprised and amazed.
These systems reflect, and currently reinforce, the values of our society.
With such a stark mirror, there’s perhaps an opportunity for more systematic feedback loops to understand, reflect on, and shift our values as a society.
Closing Remarks
As a civilian, it is difficult to interpret diplomacy and things like summits, especially from a distance. What is cheap talk? What is real progress? Does any of it mean anything? Perhaps we will look back on this in five years as a watershed moment. Perhaps we will look back on this and say nothing important happened that day. Neither would surprise me, nor would something in between.
For now, it seems like some progress was made. One more unit down. Many to go.
6 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-07T20:02:43.787Z · LW(p) · GW(p)
Prof. Bengio called upon AI developers to “demonstrate the safety of their approach before training and deploying” AI systems, while Prof. Russell concurred that “if they cannot do that, they cannot build or deploy their systems. Full stop.”
Whoa this is actually great! Not safetywashing at all; I'd consider it significant progress if these statements get picked up and repeated a lot and enshrined in Joint Statements.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-07T20:04:25.086Z · LW(p) · GW(p)
We also recommend defining clear red lines that, if crossed, mandate immediate termination of an AI system — including all copies — through rapid and safe shut-down procedures. Governments should cooperate to instantiate and preserve this capacity. Moreover, prior to deployment as well as during training for the most advanced models, developers should demonstrate to regulators’ satisfaction that their system(s) will not cross these red lines.
Aw hell yeah
comment by Sammy Martin (SDM) · 2023-11-07T15:13:03.609Z · LW(p) · GW(p)
I think that aside from the declaration and the promise for more summits the creation of the AI Safety Institute and its remit are really good, explicitly mentioning auto-replication and deception evals and planning to work with the likes of Apollo Research and ARC evals to test for:
Also, NIST is proposing something similar.
I find this especially interesting because we now know that in the absence of any empirical evidence of any instance of deceptive alignment at least one major government is directing resources to developing deception evals anyway. If your model of politics doesn't allow for this [EA(p) · GW(p)]or considers it unlikely then you need to reevaluate it as Matthew Barnett said [EA · GW].
Additionally, the NIST consortium and AI Safety Institute both strike me as useful national-level implementations of the 'AI risk evaluation consortium' idea proposed by TFI.
King Charles notes (0:43 clip) that AI is getting very powerful and that dealing with it requires international coordination and cooperation. Good as far as it goes.
I find it amusing that for the first time in hundreds of years a king is once again concerned about superhuman non-physical threats (at least if you're a mathematical platonist about algorithms and predict instrumental convergence as a fundamental property of powerful minds) to his kingdom and the lives of his subjects. :)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-07T20:07:51.565Z · LW(p) · GW(p)
If a true international framework is to be in place to fully check dangerous developments, eventually China will not be enough, and we will want to bring Russia and even North Korea in, although if China is fully on board that makes that task far easier.
Yeah I'm not too worried. If China and USA are both on board, Russia and NK etc. can and will be brought in line.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-07T20:03:52.740Z · LW(p) · GW(p)
Moreover, there is a serious risk that future AI systems may escape human control altogether.
Glad this sentence got in there, especially when paired with the next two sentences.
comment by mthibode · 2023-11-07T20:18:51.880Z · LW(p) · GW(p)
The Summit's effort to quickly raise the safety issues of rapid AI progress to an international level (outside the United Nation's Efforts) appears regressive because it is trying to bootstrap a coalition versus relying on pre-existing, extra-national institutions.
Why not work through an established, international venue that includes all nations and thus all political representations on earth?
A UN Security Council Resolution to treat increasingly powerful artificial intelligence structures as a threat to all humans, and thus all represented nations, would be the most direct and comprehensive way to effect a ban. As an institution formed to address the territorial integrity and sovereignty of all nations, the UN is pre-aligned with saving humanity from AI. Perhaps this is a parallel route that can be pursued.
The historical precedent most closely relating to this moment in time is likely the development of nuclear power, and the development of the International Atomic Energy Agency to regulate, hold inspections to verify, etc. Granted, the IAEA has not been very successful at least since the early 1990s, but fixing and aligning those processes/regimes that could otherwise lead to human extinction-- including both nuclear power and artificial intelligence, have precedence in institutions that could be revived. This is better than trying to bootstrap AI safety with a handful of countries at a Summit event-- even if China is there. North Korea, Russia, and others are not in the room.