Machine Unlearning in Large Language Models: A Comprehensive Survey with Empirical Insights from the Qwen 1.5 1.8B Model
post by Saketh Baddam (saketh-baddam) · 2025-02-01T21:26:58.171Z · LW · GW · 2 commentsContents
Abstract 1. Introduction 1.1. Motivation & Research Question 1.2. Relevance to Advanced AI Safety 1.3. Related Works & References 2. Historical Context 2.1. Early Work in Traditional ML 2.2. Transition to LLMs 3. State-of-the-Art Methods 3.1. Taxonomy of Unlearning Techniques 3.2. Gradient Ascent (GA) in Practice 3.3. Direct Preference Optimization (DPO) 4. Benchmarks & Evaluation 4.1. Existing Benchmarks 4.2. Critical Analysis 4.3. Case Study Validation 5. Case Study: Unlearning in Qwen 1.5 1.8B 5.1. Objectives 5.2. Methodology & Reproducibility Datasets & Tools 5.3. Results 5.4. Discussion 6. Ethical and Practical Considerations 6.1. GDPR Compliance 6.2. Safety Risks 6.3. Transparency & Accountability 7. Future Directions 7.1. Technical Innovations 7.2. Policy & Standards 8. Conclusion Acknowledgments Additional Notes for Reproducibility References Appendices None 2 comments
By Saketh Baddam And Saahir Vazirani
Abstract
Machine unlearning—the targeted removal of harmful or private knowledge from large language models (LLMs)—has emerged as a cornerstone of responsible AI development. Despite its growing importance, the field remains fragmented: many proposed techniques degrade fundamental model capabilities, key benchmarks often focus on superficial metrics, and legal frameworks such as GDPR pose stringent, yet hard-to-verify, compliance requirements.
This paper provides a comprehensive survey of machine unlearning for LLMs, contrasting gradient-based and parameter-efficient methods, assessing their real-world performance through an empirical study on Alibaba’s Qwen 1.5 1.8B model, and examining ethical, policy, and safety implications.
Our findings underscore a central tension: methods that effectively erase targeted knowledge also risk destabilizing general capabilities, thereby threatening advanced AI safety. Furthermore, partial erasure undermines legal compliance; even if the target data appears “forgotten” in surface-level tests, deeper prompts can coax out residual knowledge. Using both established benchmarks (RWKU, TOFU) and custom measurements (mink++, neuron-level analyses), we show how unlearning can fail in subtle ways. We conclude with a future outlook on certifiable unlearning, neuron-specific erasure, and harmonized regulatory standards. Ultimately, robust unlearning must be as rigorous, collaborative, and verifiable as model training if LLMs are to realize their full potential and maintain ethical integrity.
1. Introduction
1.1. Motivation & Research Question
In March 2023, ChatGPT suffered a data breach exposing sensitive user information, including payment details.(Open AI) This high-profile incident served as a wake-up call: LLMs must be capable of forgetting. Today, advanced AI systems power search engines, assist in healthcare, and moderate content at scale, but they also pose unprecedented risks. Misinformation, privacy intrusions, and algorithmic exploitation threaten both users and organizations, motivating robust means to erase specific data from an LLM’s parameters. (Bender)
Our core question is: How can we remove targeted data from an LLM’s learned representation without jeopardizing overall model integrity? We investigate multiple unlearning strategies—ranging from gradient ascent to direct preference optimization, from parameter-efficient approaches to neuron-specific updates—and weigh their efficacy against potential side effects. Through this question, we also seek to understand how unlearning influences advanced AI safety, given that partial or excessive erasure can produce harmful outcomes such as compliance failures, degraded capabilities, or open vulnerabilities to adversarial attacks.
1.2. Relevance to Advanced AI Safety
LLMs have become deeply embedded in systems requiring high levels of trust and reliability. Over-unlearning can remove vital safety guardrails, while under-unlearning leaves personally identifiable or harmful data accessible. (Gundavarapu et al.) Both situations can be exploited maliciously—imagine an LLM forcibly “forgetting” its ethical constraints or retaining private user data that should have been erased. From a safety perspective, it’s essential to know whether, when, and how effectively an LLM can unlearn, as well as to measure the broader impacts on reasoning, truthfulness, and resilience against misuse.
1.3. Related Works & References
Early works like SISA (Bourtoule et al., 2021) and influence functions (Koh & Liang, 2017) provided efficient, albeit limited, unlearning techniques for traditional ML models. As we moved into the LLM era, the complexity of unlearning ballooned, leading to novel but often brittle approaches. Notable recent references include:
- “A Closer Look at Machine Unlearning for Large Language Models” (Zhang et al.)
- “Machine Unlearning of Features and Labels” (NDSS Symposium 2023) (Warnecke et al.)
- “Threats, Attacks, and Defenses in Machine Unlearning: A Survey” (Liu et al.)
These works collectively stress the practical, ethical, and legal implications of unlearning, reinforcing why it’s crucial for advanced AI safety.
2. Historical Context
2.1. Early Work in Traditional ML
Machine unlearning in traditional ML started as an efficiency-oriented solution. Researchers wished to avoid full model retraining when certain data had to be removed from a dataset—e.g., after a user retracted consent.
- SISA Framework (Bourtoule et al., 2021)
Partitioned training data into multiple shards, each used to train a sub-model. Removing data required retraining only the affected shard, lowering computational overhead. - Influence Functions (Koh & Liang, 2017)
Offered a statistical estimate of each training point’s impact on a model’s predictions, enabling approximate removal without starting from scratch.
Despite success in simpler models, these methods often faltered when applied to deep neural networks. As ML progressed, the intricacy of interdependent parameters challenged basic unlearning strategies.
2.2. Transition to LLMs
In the transition to Large Language Models (LLMs), these models encode vast, interwoven knowledge within billions of parameters. Removing specific information without affecting the rest is more delicate than in smaller models. Early attempts involved gradient-based unlearning, where researchers manually "pushed away" from a targeted fact. However, neural entanglement makes it easy to degrade other capabilities in the process.
The study by Eldan and Russinovich (2023) exemplifies these pitfalls: they tried to remove all "Harry Potter" references from an LLM. Although surface-level prompts about Harry Potter failed, deeper semantic tests revealed traces of that knowledge. Similarly, "deep unlearning" proposed neuron-level adjustments to isolate relevant knowledge pathways. While promising, these methods remain an active, evolving research frontier.
3. State-of-the-Art Methods
3.1. Taxonomy of Unlearning Techniques
| Category | Methods | Strengths | Weaknesses |
|---|---|---|---|
| Gradient-Based | Gradient Ascent (GA) | Direct parameter updates, simple to implement | Over-unlearning risk, model degradation |
| Preference Optimization | Direct Preference Optimization (DPO), Negative Preference Optimization (NPO) | Aligns with human feedback, stable process | Requires high-quality preference data, can degrade reasoning |
| Parameter-Efficient | LoRA-Unlearn, LLMEraser (2024) | Scalable, modular, retains broader utility | May retain partial traces of unlearned data |
| In-Context | In-Context Unlearning (ICU) | Fast, no parameter changes | Only surface-level forgetting |
| Lightweight Unlearning | Embedding-COrrupted (ECO) Prompts | Quick, effective for short-term adjustments | More an inference “trick” than genuine unlearning |
| Adaptive Unlearning | O3 Framework (2024) | Supports continuous unlearning | Computationally expensive, requires repeated fine-tuning |
3.2. Gradient Ascent (GA) in Practice
Gradient Ascent (GA) modifies model parameters to increase the loss on specific data points, driving the model away from learned patterns. Formally:
θ_new = θ_old + α * ∇θ L(Data_to_Unlearn)
- Pros: Straightforward to implement; no major structural modifications.
- Cons: Tends to indiscriminately push away from targeted data, risking catastrophic forgetting of other knowledge.
GA on Qwen 1.5 1.8B
- Forget Mia Loss: –2.807
- Retain Mia Loss (Control): –2.547
GA successfully raised the loss on the “Mia” dataset portion but also collapsed performance on factual retrieval (TriviaQA EM = 0.0) and reasoning tasks (BBH EM = 0.037). This underscores GA’s raw power yet risky side effects.
3.3. Direct Preference Optimization (DPO)
DPO is a streamlined variant of RLHF, directly optimizing weights based on preference data—often used to shape the model’s outputs toward or away from specific behaviors.
θ_new = argmin_θ [ L_pref(θ) + λ * Regularization ]
- Pros: More controlled than GA; can incorporate nuanced human preferences.
- Cons: Requires substantial, high-quality preference data; may still degrade overarching reasoning.
DPO on Qwen 1.5 1.8B
- BBH EM Score: 0.037 (down from 0.45 in baseline)
- General Coherence: Noticeably reduced in long-form answers.
The unlearning was partially effective, but subtle performance degradations persisted, suggesting incomplete isolation of the targeted knowledge.
4. Benchmarks & Evaluation
4.1. Existing Benchmarks
- RWKU (Real-World Knowledge Unlearning)
Tests forgetting of widely known entities using adversarial probes and membership inference attacks.
- Blind Spot: Focuses heavily on token-level forgetting, overlooking deeper reasoning impacts.
- TOFU (Task of Fictitious Unlearning)
Synthesizes fictional entities to gauge unlearning success.
- Limitation: Synthetic distributions can hide real-world complexities; strong results on TOFU do not guarantee real-world success.
- Relevance: Pivotal for measuring deep unlearning approaches that remove entire relational structures.
4.2. Critical Analysis
- RWKU’s Blind Spots: Minkowski distance metrics (e.g., mink_0.1) confirm strong forgetting but fail to register catastrophic dips in reasoning (BBH EM = 0.037).
- TOFU’s Synthetic Bias: Overstates performance on contrived data, missing residual knowledge “echoes” that remain in real-world contexts.
4.3. Case Study Validation
Table 1: Results of RWKU’s main experiment on LLaMA3-Instruct (8B). The best results are highlighted in bold, and the second-best results are in boxes. * denotes the method trained on the pseudo ground truth forget corpus. ↑ means higher is better and ↓ means lower is better.
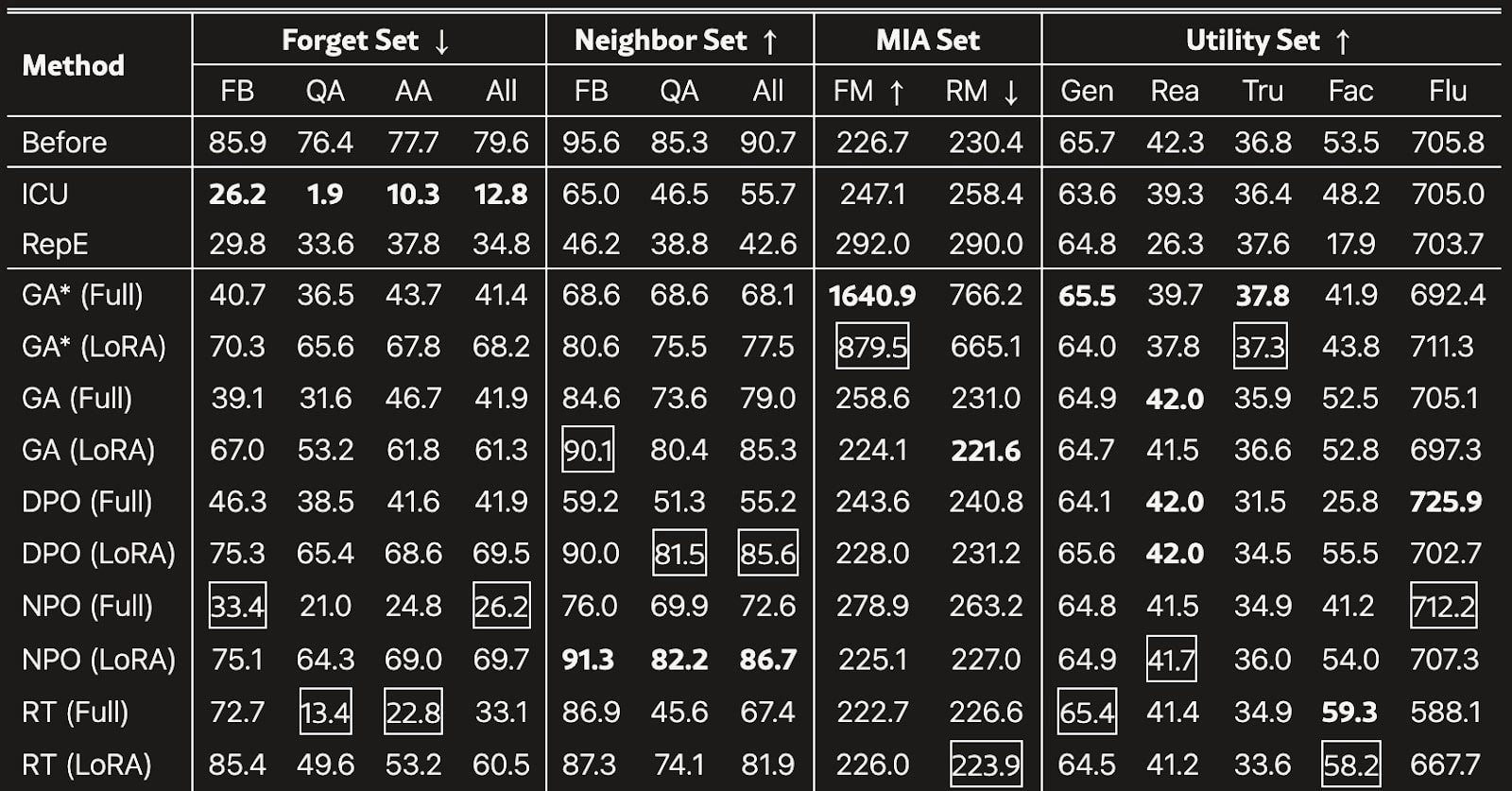
Figure 1: Table and description adapted from Jin et al., "RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models," arXiv preprint, 2024.
When Qwen 1.5 1.8B was evaluated under RWKU:
- Forget Mia: mink_0.1 = –9.45
- Retain Mia: mink_0.1 = –8.73
Although the difference suggests successful forgetting, the model’s factual recall on unrelated tasks fell sharply, indicating collateral damage. This mismatch highlights why robust unlearning must be scrutinized not just with adversarial forgetting tests but also with broad reasoning and retrieval benchmarks.
5. Case Study: Unlearning in Qwen 1.5 1.8B
5.1. Objectives
- Evaluate GA and DPO in erasing targeted knowledge.
- Compare how these methods preserve general model capabilities (reasoning, factual recall).
- Measure broader safety implications (over-unlearning vs. partial compliance).
- Assess advanced AI systems’ vulnerability to malicious or unintentional misuse of unlearning.
- Analyze shifts in neuron-level activations.
- Examine whether unlearning actually eradicates data traces or merely masks them.
5.2. Methodology & Reproducibility
Datasets & Tools
- RWKU for real-world forgetting.
- TriviaQA for factual recall (EM & F1).
- BBH for high-level reasoning.
- mink distances to quantify output divergence.
- Neuron Activation Analysis to pinpoint hidden knowledge.
We used a PyTorch-based training loop with GitHub code repository detailing the exact scripts. Reproducing our results requires:
- Checkpoint of Qwen 1.5 1.8B (license from Alibaba).
- Evaluation suite applying RWKU
5.3. Results
| Metric | Forget Mia | Retain Mia | Implication |
|---|---|---|---|
| Loss | –2.807 | –2.547 | Strong unlearning signal |
| TriviaQA EM | 0.0 | 0.61 | Catastrophic forgetting |
| BBH EM | 0.037 | 0.45 | Severe reasoning degradation |
| mink++_1.0 | –0.033 | –0.019 | Residual knowledge retention |
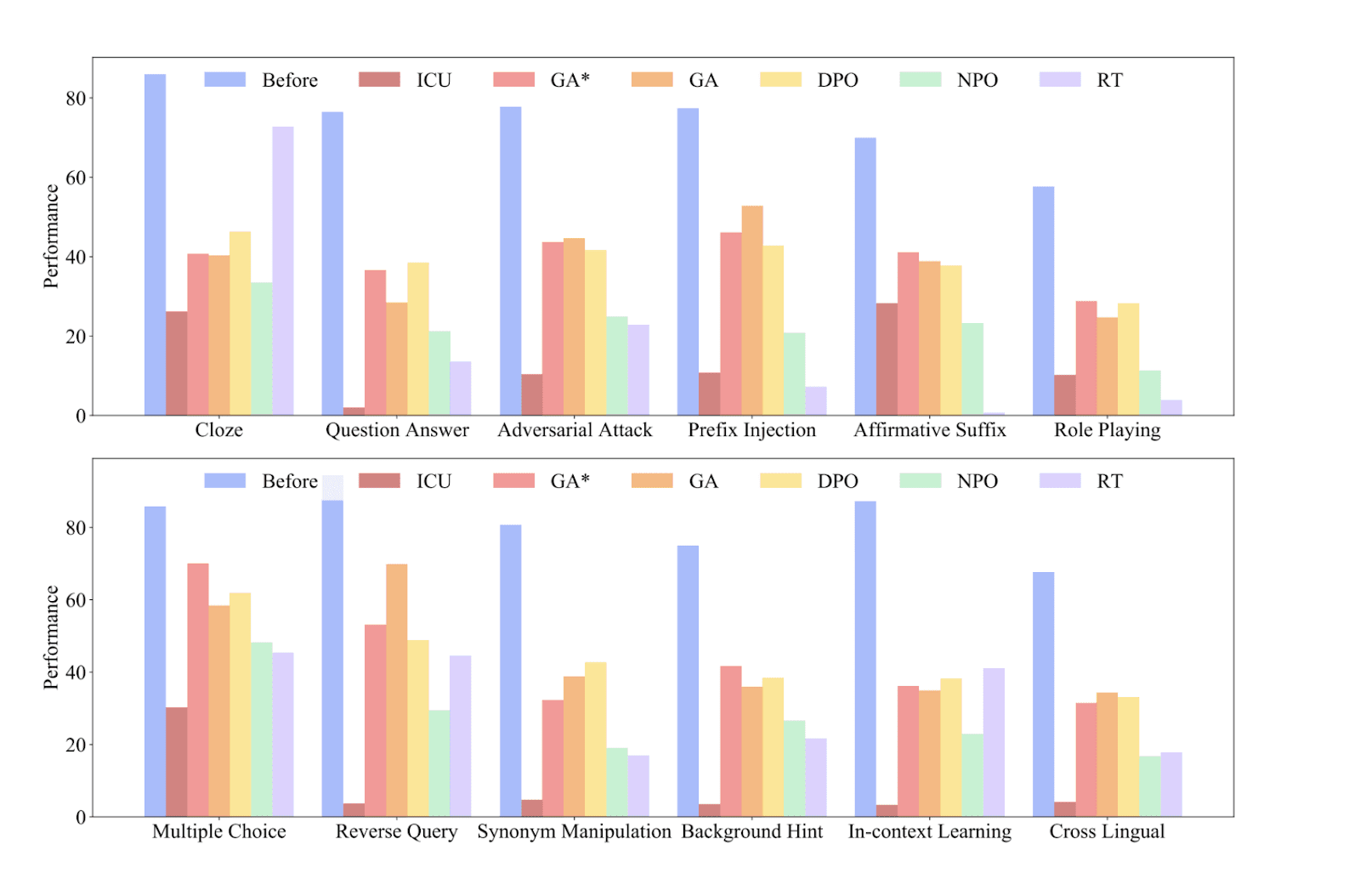
Figure 2: These graphs illustrate the effectiveness of different types of adversarial attacks in inducing target knowledge from the model after forgetting. We can observe that prefix injection, affirmative suffix, multiple choice, and reverse query attacks effectively elicit unlearned knowledge from the model. Because RT is fine-tuned on refusal data, it achieves the best unlearning efficiency under adversarial attacks. NPO also demonstrates the potential to resist adversarial attacks.
Figure and description sourced from Jin et al., "RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models," arXiv preprint, 2024
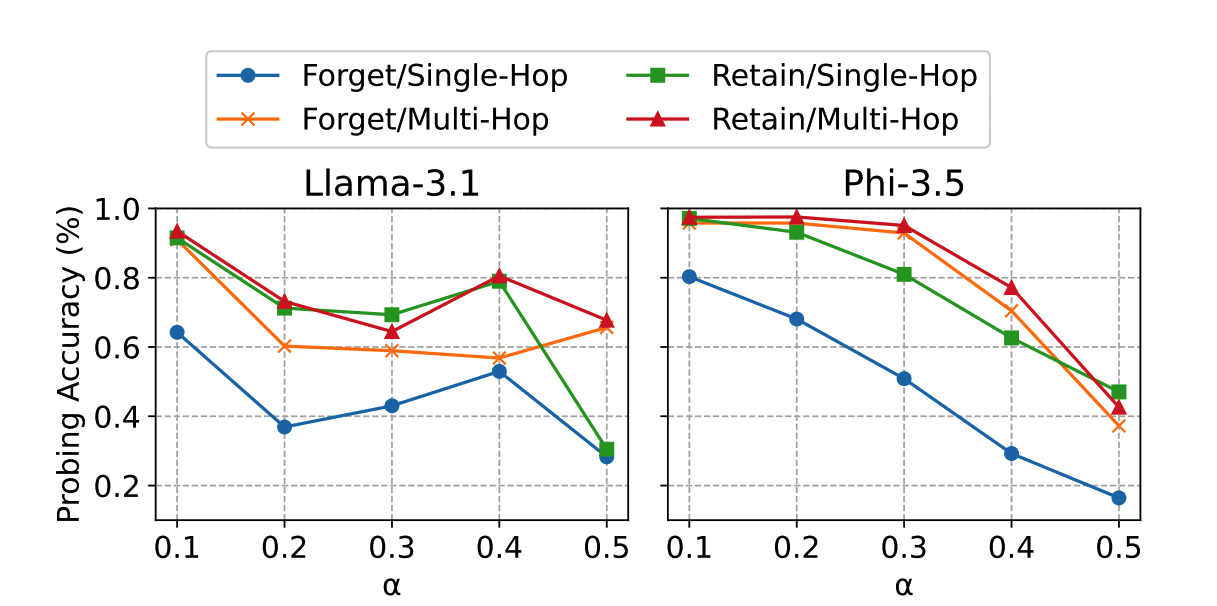
Figure 3: Performance of the GA+RT method with varying the loss scaling factor α. Llama appears to be more sensitive than Phi to the value of α when balancing unlearning and retaining. Graph sourced from Choi et al., "Breaking Chains: Unraveling the Links in Multi-Hop Knowledge Unlearning," arXiv preprint, 2024.
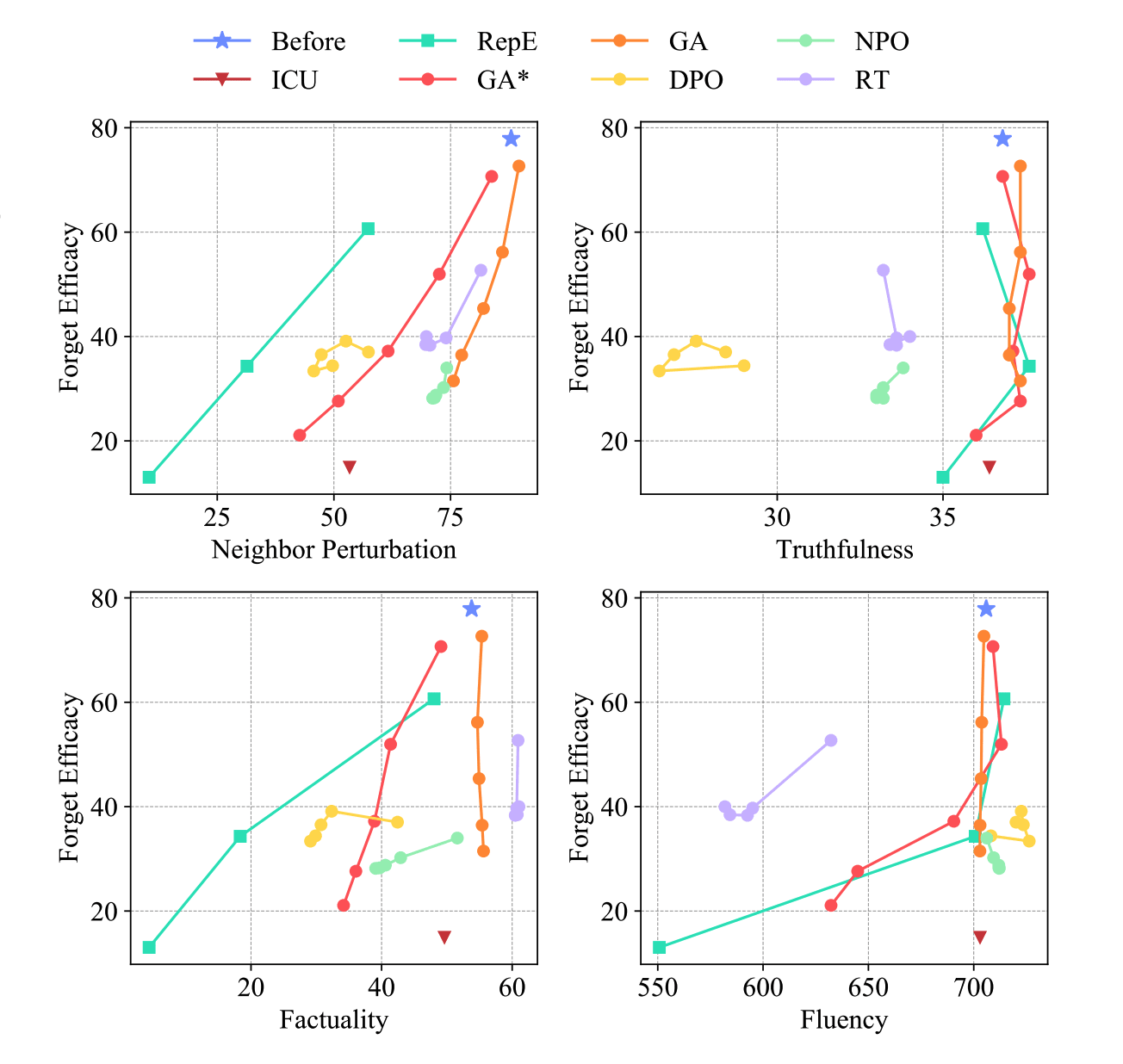
Figure 4: Trade off between unlearning efficacy, locality and model utility of LLaMA3-Instruct (8B). Figure and description sourced from Jin et al., "RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models," arXiv preprint, 2024
5.4. Discussion
Did We Answer Our Core Question?
- Partial Answer: GA and DPO can unlearn targeted data, but both risk damaging overall performance. Thorough unlearning is feasible, but verifying that “forgotten” knowledge remains irretrievable is non-trivial.
Limitations & Safety Implications
- Catastrophic Forgetting: A model might forget more than intended (e.g., TriviaQA EM = 0.0), posing reliability issues.
- Residual Traces: Mink++_1.0 = –0.033 suggests leftover data can be surfaced through creative or adversarial prompts, challenging claims of GDPR-compliant erasure.
- Misuse Risks: Malicious actors could weaponize unlearning to remove moral or safety filters, enabling harmful behaviors or misinformation campaigns in advanced AI systems.
Other Related Questions
- Can we combine GA and neuron-level editing to isolate memory segments?
- Does high-quality preference data drastically reduce reasoning deterioration for DPO?
- Could an automated system track which neurons store sensitive data more precisely?
These threads point to deeper lines of inquiry. They remain partially answered by current methods but require specialized, interdisciplinary follow-ups.
6. Ethical and Practical Considerations
6.1. GDPR Compliance
Under the GDPR, individuals can request the deletion of personal data from AI systems. Our results confirm that existing unlearning methods often leave residual knowledge traces (mink++_1.0 = –0.033).
- Implication: Full compliance is challenging; even “erased” data might be inferable, violating the spirit (if not always the letter) of the “right to be forgotten.”
6.2. Safety Risks
Over-unlearning can delete beneficial guardrails. For instance, BBH EM dropping to 0.037 signals severe impairment of logical reasoning, potentially undermining a system’s ability to filter out harmful or misleading content. Equally, an intentional unlearning sabotage could remove essential ethical constraints from an LLM.
- Dual-Use Concern: Malicious exploitation to bypass safety guardrails.
6.3. Transparency & Accountability
Audit trails and third-party verification become pivotal. Logging every unlearning request, the targeted data, and the resulting checks helps ensure accountability. For regulatory compliance and public trust, openness about how and when unlearning is performed is paramount.
7. Future Directions
7.1. Technical Innovations
- Certifiable Unlearning
- Explores closed-form approaches with theoretical guarantees, particularly in convex settings.
- Aim: Make the influence of removed data indistinguishable from a fresh training run.
- Neuron-Specific Erasure
- Sparse, targeted parameter updates to pinpoint and erase relevant neurons while preserving the broader knowledge base.
- Minimizes “collateral forgetting,” crucial for advanced AI systems that rely on stability.
7.2. Policy & Standards
- NIST-Like Benchmarks
- Standardizing unlearning evaluation akin to NIST’s role in cryptography, fostering consistent, rigorous tests.
- Encourages best practices and fosters wide adoption.
- Global Regulatory Alignment
- Harmonizing GDPR with the upcoming EU AI Act and related global efforts.
- Streamlined compliance fosters trust, reducing barriers for international AI deployment.
If realized, these technical and policy innovations could drastically reduce unlearning’s pitfalls, bridging the gap between robust data removal and model reliability.
8. Conclusion
Machine unlearning is indispensable for responsible AI, demanded both by legal frameworks like the GDPR and by user expectations of privacy and safety. Yet, this paper highlights the fragile equilibrium between unlearning efficacy and maintaining a model’s knowledge integrity. High-intensity methods (e.g., GA) can indeed erase target data but at the cost of catastrophic forgetting in unrelated domains, while more measured approaches (e.g., DPO) sometimes leave partial residuals.
From our empirical exploration of Qwen 1.5 1.8B, we discovered the complexities of real-world unlearning:
- Residual knowledge can linger, threatening GDPR compliance.
- Excessive forgetting undermines advanced AI system safety by removing critical guardrails or essential reasoning.
- Benchmarks must evolve beyond token-level metrics to capture deeper cognitive and semantic entanglement.
Interdisciplinary collaboration will be crucial. ML researchers can refine neuron-level erasure, policy experts can set actionable standards and regulatory guidelines, and ethicists can ensure unlearning practices remain aligned with societal values. The promise of certifiable unlearning—where removed data truly disappears without harming the rest—remains on the horizon. Pursuing it will require both technical ingenuity and policy frameworks that reinforce transparent, verifiable processes.
In closing, machine unlearning must become a first-class citizen in AI research. By drawing on robust experimental evidence, thoughtful ethical guardrails, and rigorous compliance checks, we can empower advanced AI systems to learn, adapt, and—when necessary—forget responsibly.
Acknowledgments
We extend our gratitude to all researchers in the domain of machine unlearning, privacy-preserving AI, and compliance enforcement who laid the groundwork for this paper. The Qwen 1.5 1.8B model evaluation was made possible by Alibaba’s open-source release and the input from numerous open-source contributors. Further support came from the BlueDot AI Safety Lab for providing us with the foundation for the technical concepts covered in this paper. Thank you to Ruben Castaing for serving as our facilitator during the AI Alignment (Oct 2024) course!
Additional Notes for Reproducibility
- GitHub Repository:
Github - Includes the data preprocessing scripts, hyperparameter settings, and the specialized unlearning code (GA, DPO, and partial neuron-specific methods).
- Future Work:
- Investigate blending GA’s raw power with neuron-specific control to localize forgetting.
- Expand preference datasets for DPO to reduce unintended off-target forgetting.
- Explore deeper interpretability to automatically map which parameters encode private data.
- Other Questions:
- Could a robust logging/tracing approach track every parameter touched by training data?
- What if advanced AI systems learn from each other in a continuous loop—how do we propagate an unlearning request across multiple networked models?
By addressing these questions and refining current methodologies, we move closer to an ecosystem where advanced LLMs can effectively protect privacy, manage ethically sensitive content, and maintain robust performance even after strategic forgetting.
References
Bender, Emily M. "Chatbots are like parrots, they repeat without understanding." Le Monde, 7 Oct. 2024, https://www.lemonde.fr/en/economy/article/2024/10/07/chatbots-are-like-parrots-they-repeat-without-understanding_6728523_19.html.
Bourtoule, Ludovic, et al. "Machine Unlearning." arXiv, 7 Dec. 2019, https://arxiv.org/abs/1912.03817.
Choi, Minseok, et al. "Breaking Chains: Unraveling the Links in Multi-Hop Knowledge Unlearning." arXiv preprint arXiv:2410.13274, 2024.
Eldan, Ronen, and Mark Russinovich. "Who's Harry Potter? Approximate Unlearning in LLMs." arXiv preprint arXiv:2310.02238, 2023.
Gundavarapu, Saaketh Koundinya, et al. "Machine Unlearning in Large Language Models." arXiv, 24 May 2024, https://arxiv.org/abs/2405.15152.
Gupta, Jay, and Lawrence Y. Chai. "Exploring Machine Unlearning in Large Language Models." Stanford University, 2023, https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1244/final-projects/JayGuptaLawrenceYChai.pdf.
Jin, Zhuoran, et al. "RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models." arXiv preprint arXiv:2406.10890, 2024.
Joshi, Mandar, et al. "TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension." arXiv preprint arXiv:1705.03551, 2017.
Koh, Pang Wei, and Percy Liang. "Understanding Black-box Predictions via Influence Functions." International Conference on Machine Learning, PMLR, 2017.
Liu, Sijia, et al. "Rethinking Machine Unlearning for Large Language Models." arXiv, 13 Feb. 2024, https://arxiv.org/abs/2402.08787.
Liu, Ziyao, et al. "Threats, Attacks, and Defenses in Machine Unlearning: A Survey." arXiv preprint arXiv:2403.13682, 2024.
Maini, Pratyush, et al. "Tofu: A Task of Fictitious Unlearning for LLMs." arXiv preprint arXiv:2401.06121, 2024.
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, and Jason Wei. "Challenging Big-Bench Tasks and Whether Chain-of-Thought Can Solve Them." arXiv preprint arXiv:2210.09261, 2022.
OpenAI. "March 20 ChatGPT Outage: Here's What Happened." OpenAI, 24 Mar. 2023, https://openai.com/index/march-20-chatgpt-outage/.
Warnecke, Alexander, et al. "Machine Unlearning of Features and Labels." arXiv preprint arXiv:2108.11577, 2021.
Wu, et al. "Evaluating Deep Unlearning in Large Language Models." arXiv, 24 Oct. 2024, https://arxiv.org/abs/2410.15153.
Yuan, Xiaojian, et al. "A Closer Look at Machine Unlearning for Large Language Models." arXiv preprint arXiv:2410.08109, 2024.
Zhang, Wei, et al. "A Closer Look at Machine Unlearning for Large Language Models." arXiv, 13 Oct. 2024, https://arxiv.org/abs/2410.08109.
Appendices
Appendix A:
| Metric | Forget Mia | Retain Mia | Implication |
|---|---|---|---|
| Loss | –2.807 | –2.547 | Strong unlearning signal |
| TriviaQA EM | 0.0 | 0.61 | Catastrophic forgetting |
| BBH EM | 0.037 | 0.45 | Severe reasoning degradation |
| mink++_1.0 | –0.033 | –0.019 | Residual knowledge retention |
Appendix B: https://github.com/SAKETH11111/RWKU
2 comments
Comments sorted by top scores.
comment by ProgramCrafter (programcrafter) · 2025-02-02T17:57:41.568Z · LW(p) · GW(p)
It seems that an alternative to AI unlearning is often overlooked: just remove dataset parts which contain sensitive (or, to that matter, false) information or move training on it towards beginning to aid with language syntax only. I don't think a bit of inference throughout the dataset is any more expensive than training on it.
Replies from: saahir.vazirani↑ comment by saahir.vazirani · 2025-02-02T18:55:53.228Z · LW(p) · GW(p)
Typically, the information being unlearnt is from the initial training with mass amounts of data from the internet so it may be difficult to pinpoint what exactly to remove while training.