I "invented" semimeasure theory and all I got was imprecise probability theory
post by Cole Wyeth (Amyr) · 2025-04-03T16:33:21.820Z · LW · GW · 0 commentsContents
No comments
Epistemic status: Informal summary of / intuition behind formal research (developing semimeasure theory conjectures from IUAI with Marcus Hutter). Paper is forthcoming. Partially supported by the LTFF.
This is post is a rather philosophical and intuitive take on Solomonoff induction and model misspecification[1]. It's also a misadventure through the mathematical landscape. And so it begins with a call to adventure, which in this case is me getting nerd-sniped by a minor technical difference between two definitions of the value function in (general history-based) reinforcement learning.
The original definition is the iterative value function, which is (with policy , environment ):
Refresher on history-based RL notation. Here is the distribution on the history of action and percepts induced by the interaction of environment and policy . Also, the rewards are part of the percepts: , is a discount factor which should sum to , and is the lifetime of the agent (or the horizon).
This makes perfect sense when you are using proper probability distributions for your policy and environment, as a sane person would do. Unfortunately, in algorithmic information theory we must use Hutter's universal chronological semimeasure, which is defective - all of its conditionals fail to sum to 1 because the percept sequence can end early (for instance, before time ). This is sometimes interpreted as "death," which I'll take issue with later, but for now the point is that you want to give an agent credit for the rewards it earns before the percept sequence ends, and the iterative value function doesn't do that.
The recursive value function is preferable for the semimeasure case:
These are equivalent when everything is a sane probability measure.
Normally, we send . One way to think of this is that we're taking an integral instead of a sum. The integrand is , which is a nicer view if we want to consider other utility functions. The iterative value function is analogous to a Riemann-Stieltjes integral, because it basically slices its domain up more and more finely (this can be made precise, and is easiest to see if you visualize as a binary expansion in [0,1]). The recursive value function is... well, I wanted it to be the semimeasure version of the Lebesgue integral. I got obsessed with this analogy, spent months inventing and studying that thing[2], and eventually learned that (when the rewards are non-negative and include 0) it is actually just a Choquet integral from imprecise probability theory.
This is kind of a nice result, because the Choquet integral is supposed to generalize Bayesian decision theory to deal with model misspecification / unrealizability, dispensing with the assumption that the hypothesis class contains the truth[3]. Instead, it uses "incomplete information" that is insufficient to pin down a specific probability distribution. A (normalized) semimeasure can be translated to a whole family of "possible" probability distributions called the Core. The Core is the set of probability measures with .[4]
The Choquet integral of a function is[5] a pessimistic expectation, under the worst possible probability distribution. Let be a real-valued measurable function on the space[6] of . Then (assuming is "convex"):
It happens to be equal to the recursive value function when with non-negative rewards including 0, because a finite history ending at time is naturally valued at the sum of the rewards up to time : . But that is exactly the utility = of the worst possible infinite continuation of the history prefix observed so far, because 0 is the lowest reward. This set of infinite continuations is formally called the cylinder set . We can reinterpret the probability gap as "the worst possible thing happening" instead of the chance of the history literally ending. If negative rewards were included these would no longer match, but on this perspective, the Choquet integral would be the natural generalization to that case, rather than the formula I gave for the recursive value function.
I think this is a valid philosophical interpretation of semimeasures in algorithmic information theory, including Hutter's universal distribution. After all, the universal distribution is a mixture of environments computable by a probabilistic program, but we don't need to view the corresponding AIXI agent as believing the world is literally one of those probabilistic programs. The semantics is that the world as seen by the agent is computed by one of those probabilistic programs[7]. To go further would be either an over-interpretation or an additional philosophical commitment to solipsism which is not explicit in the mathematics of AIXI[8]. Instead, we can choose to view the end of a program's output not as the end of the universe, but as that program failing to produce further predictions. Under this view, the universal distribution has a probability gap because it is imprecise.
If we choose not to interpret a finite history as indicating the agent's death, that would seem to make AIXI "less embedded." But I actually think the death interpretation was a little forced anyway. The universal distribution is natively unembedded, so it is not trying to talk about the destruction of the machine it is running on. Informally, the history is likely to terminate after those prefixes that have low K-complexity. Some of those may correspond to the agent's destruction (which can only happen once, so is relatively easy to point at). But there are also plenty of other low K-complexity prefixes (which may have nothing to do with destructive events), and maybe it's more natural to view them as places where a model breaks down than where the agent dies. In addition, AIXI could even expect the agent to die without expecting the end of the sequence (this is unintuitive, but remember AIXI is a Cartesian dualist). Presumably, AIXI would even expect its actions to stop having any impact once its actuators were destroyed [LW · GW], so it may even correctly deal with the possibility of death without invoking the end of the history sequence[9]. The death interpretation of finite histories is flawed in both directions.
More technical consequences: In fact, when the of the utility function on infinite histories beginning with a given prefix is lower semicomputable, using the Choquet integral for the expected utility also allows for the value function to remain lower semicomputable. If we assign arbitrary other utilities to finite histories, even if they are computable, this may fail because the measure of a finite history is not lower semicomputable.
Here's a schematic which makes the behavior of these Choquet integrals more clear. We'll set aside the history-based RL setting for a moment and just consider a semimeasure on binary sequences. Viewing these sequences as binary expansions of reals in [0,1], we'll integrate a function with respect to . Now imagine that there is a malevolent entity named Murphy (borrowed from Vanessa/Diffractor) who is trying to minimize this integral (but it is going to have to be an integral against a real probability measure "consistent" with ). Then Murphy gets to distribute the defective probability mass of at each prefix anywhere in the cylinder set ! This provides a nice visualization of what is going on:
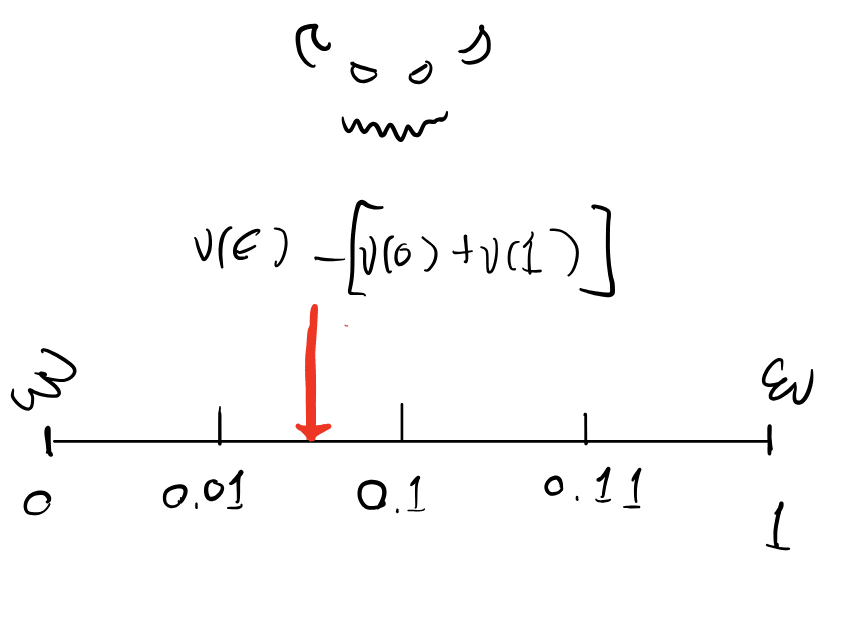
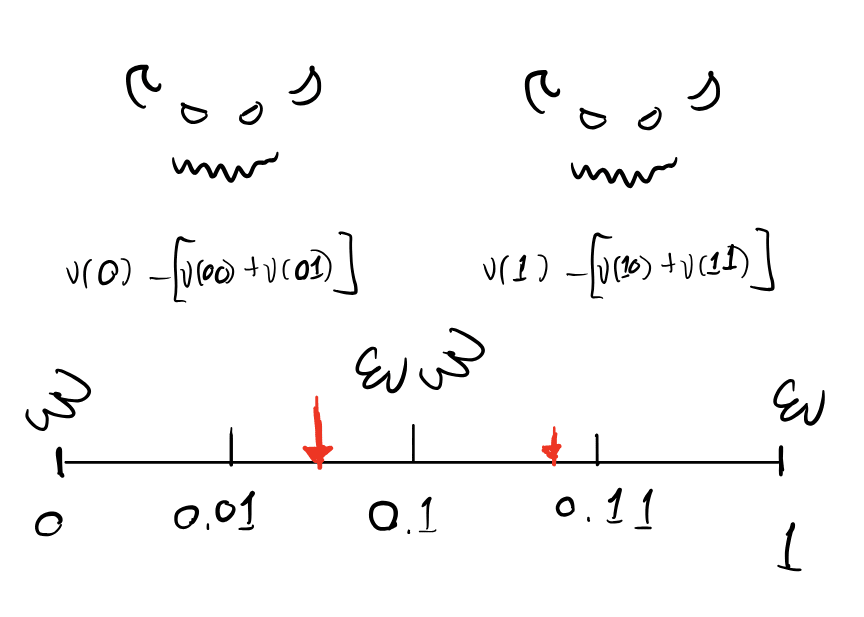
With all that said, I'm not a big fan of imprecise probability theory. I see no obvious philosophical[10] reason to be pessimistic in the face of (even Knightian) uncertainty[11]. I am more committed to viewing the probability defect as being in some sense imprecise. This has some interesting consequences.
First, it (somewhat) justifies the Solomonoff normalization. This modification of the universal distribution just "donates" the missing probability mass to the programs that do make predictions (preserving the ratio of the conditionals on 0 and 1). This is a fairly natural[12] (but naive) thing to do if you view that probability mass as simply unallocated, rather than actually expecting the history to end. It should pay dividends in the unrealizable case which imprecise probability is designed for - and it does! The normalized universal distribution can learn to predict selected bits of a partially adversarial sequence, whereas the un-normalized version fails. I've never heard another sensible high-level explanation of this result. Perhaps a predictor actually designed to treat the probability gap as imprecise would have better robustness properties (say, faster convergence).
Another implication is that, while the universal distribution's probability gap comes from programs which "loop" (in a widely construed sense) or halt (if we include a halting state) and never produce further output, any approximation would have a further gap from programs that simply haven't output their next bit yet because we haven't had time to run them for long enough. We could treat this case similarly as "no prediction" resulting in imprecision (apparently, IBP makes this idea formal).
I suspect this is only a poor man's logical induction, and it is much more effective to take advantage of the internal structure and interrelationships of (some) ongoing computations. Another advantage of logical induction is that it may allow models to make no prediction in a wider variety of cases (not just after a certain time). But maybe that's fine; if approximate (imprecise) Solomonoff induction is the core engine of an AGI's cognition [LW · GW], could it learn to deal with logical uncertainty correctly given a mental scratchpad[13] to do math on?
I am not a convert to the Dempster-Shafer school, but I do think it is fascinating to see how different approaches to rationality connect and explain each other at a deeper level, and it looks like the universal distribution has an interesting explanation according to imprecise probability theory (and maybe vice versa). My dream is to tie all the important paradigms together into one object that I can rotate in my mind to see how each perspective arises from the others.
- ^
Often called "unrealizability."
- ^
Hopefully this footnote will eventually be replaced with a link to the (currently submitted) paper, but slightly more technical details: my definition directly adapted the definition of the Lebesgue integral for non-negative functions, and after a lot of work I eventually proved equivalence to (what I later realized is) the Choquet integral in that case. In the process I proved some 70 year-old results in imprecise probability for my special case. I have not actually seen this route to constructing the Choquet integral anywhere, but I assume it's out there and would be interested (mortified?) to read it.
- ^
If this seems familiar, that may be because it's a central part of Infra-Bayesianism.
- ^
An interesting tangent is that in the context of reflective oracles, such probability measures are called "completions" of , so a choice of reflective oracle selects points in the core of a certain class of (conditionally) lower semicomputable semimeasures.
- ^
This is not the (un-enlightening) definition of the Choquet integral, formally , but it is equivalent in all (?) of the important cases including ours.
- ^
Let's assume is either a finite set or the Cantor space, which captures our case of interaction histories. I believe that much further generality is possible, but will not be needed here.
- ^
Most results even assume that the true environment is a proper probability measure, while only the agent's belief distribution allows sequence termination.
- ^
This is one reason that pointing at human value in AIXI's ontology is very subtle. After all, even if AIXI had an excellent probabilistic world model which implicitly included all of the dynamics we care about in the universe, that model may still lazily evaluate anything that isn't perceived by AIXI (though it shouldn't matter when all models are taken in aggregate, this approach may even save Bayes points by reading fewer random bits). I don't think it's reasonable to view such a model as solipsistic; it's rather a frugal execution of an approximately correct model. But it does mean you can't expect little humans to be explicitly running around in AIXI's imagination everywhere that you'd like to find a little human.
- ^
This is often how I visualize the aftermath of my death too - for instance, when laying plans that have consequences I will not live to experience. When I think about "what will happen after I die" the two images that come to mind are "blackness" (the percepts I'd receive if my sensors were broken) and alternatively "watching" the events that would continue to take place in the world, through my ordinary sensory channels, but being unable to take effective actions to influence them. This actually looks a lot like what I would expect AIXI to predict from its percept stream if its hardware were destroyed! Of course I expect my consciousness to end at death so that I don't have first person experience of later events, but was AIXI conscious in the first place? It is hard to say AIXI is doing the wrong thing here, epistemically.
- ^
There may be a technical reason though. If the of the utility function over cylinder sets is computable and independent of actions, I claim that the universal distribution will always assign high probability to the worst (according to ) possible continuation of a low-K complexity history prefix . Explicitly, there is a short program that acts as expected until it sees , then repeatedly outputs the next percept who's cylinder set has the lowest (eventually this in fact achieves the of over ). Naturally, the reverse holds if the of the utility function over cylinder sets is computable (but perhaps this is less natural, see the "more technical consequences" paragraph), which means the universal distribution may act more like a Hurwicz decision rule. This is a second path for Dempster-Shafer-like behavior to sneak into the universal distribution! I am interested in versions of this "theorem" with weaker assumptions, as discussed here [LW · GW].
- ^
Vanessa Kosoy, however, has argued in favor of pessimism:
https://www.lesswrong.com/posts/dPmmuaz9szk26BkmD/vanessa-kosoy-s-shortform?commentId=Z6WqEER5b9a67rmRT [LW(p) · GW(p)]
https://www.lesswrong.com/posts/dPmmuaz9szk26BkmD/vanessa-kosoy-s-shortform?commentId=PvCw5urMTcBhiXkCA [LW(p) · GW(p)]
https://www.lesswrong.com/posts/dPmmuaz9szk26BkmD/vanessa-kosoy-s-shortform?commentId=afqCawfQFvndaX4SL [LW(p) · GW(p)]I still don't understand her framework/notation very well, but I believe her arguments are connected to my "technical reason" above for the universal distribution to suggest a pessimistic/Hurwicz decision rule.
- ^
Perhaps it would be more natural to normalize the conditionals of every individual semimeasure in the mixture (that continues to predict continuations) and then renormalize their posterior weights, or to do something more sophisticated such as treating all missing probability mass as adversarially allocated against your loss function.
- ^
This seems to be reminiscent of Vanessa Kosoy's SiLC architecture [LW(p) · GW(p)].
0 comments
Comments sorted by top scores.