Posts
Comments
It's perfectly aligned with Microsoft's viral marketing scheme.
The two small models are not really significantly different from each other (p=0.04).
This means the tasks at hand are too hard for both small models, so neither of them can learn them really well, so the noise ends up being larger than the slope.
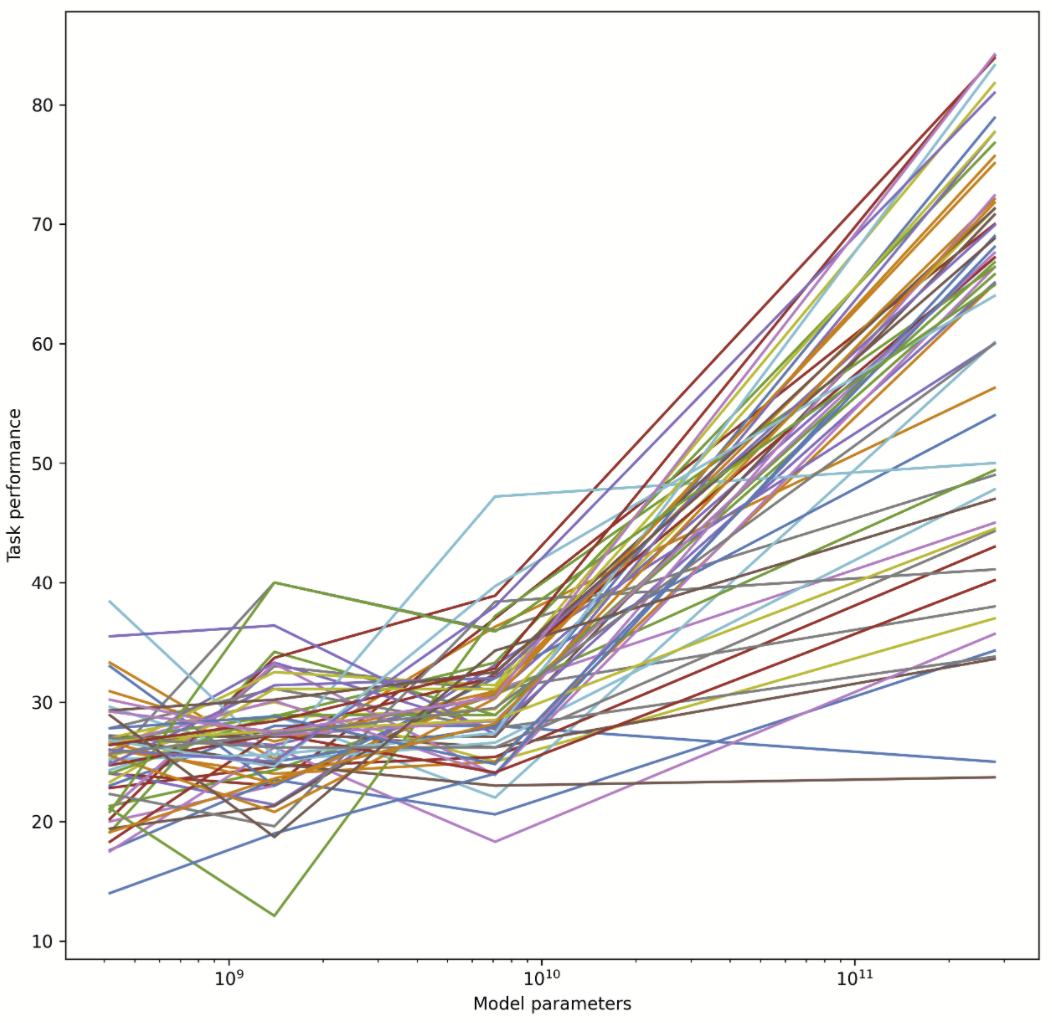
As others have noted, we are looking at sort of sigmoidal curves, and a different one for each task. Performance will plateau once it approaches the lowest possible error rate (Bayes error rate or limit of the model paradigm). It is known that performance often sharply increases with model size at some point (once the circuit complexity of the network is large enough to compute the task at all), but these sharp increases are not visible below as the x-axis is too coarse. Most tasks appear to have this point somewhere between 10B and 100B, but perhaps some of these tasks have more of a gradual increase in performance (can't tell due to coarseness). The task that appears to have already plateaued was possibly an outlier for the 7.1B model, but perhaps it also has a huge Bayes error or is simply not better learnable with these kinds of models.
I cannot access your wandb, btw. It seems to be private.
If 4 is not simply a bad default, maybe they considered more data with a high inferential distance (foreign, non-natural/formal languages), which may require more epochs?
You can get an idea of a pre-trained GPT-3's sample efficiency from the GPT-3 fine-tuning API docs. The epoch parameter defaults to 4, and further up in the documentation they recommend fine-tuning with at least 500 examples for 1-2 epochs in the conditional setting (e.g. chatbots). Although training data is often repetitive (implying maybe 2-10x as many effective epochs?), it learns only seeing the data a few times. More evidence of sample efficiency going up with scale you can see in Figure 4.1 in this paper. Sample efficiency also goes up with the amount of data already seen (pre-training).
This suggests that at some scale and some amount of pre-training, we may enter the one-shot learning regime. Then there is no need for "long-range" tricks (RNNs, CNNs, attention) anymore. Instead, one can one-shot learn by backprop while doing the predictions within a relatively short time window.