Posts
Comments
In entrepreneurship, there is the phrase "ideas are worthless". This is because everyone already has lots of ideas they believe are promising. Hence, a pre-business idea is unlikely to be stolen.
Similarly, every LLM researcher already has a backlog of intriguing hypotheses paired with evidence. So an outside idea would have to seem more promising than the backlog. Likely this will require the proposer to prove something beyond evidence.
For example, Krizhevsky/Sutskever/Hinton had the idea of applying then-antiquated neural nets to recognize images. Only when they validated this in the ImageNet competition did their idea attract more researchers.
This is why ideas/hypotheses -- even with a bit of evidence -- are not considered very useful. What would be useful is to conclusively prove an idea true. This would attract lots of researchers ... but it turns out to be incredibly difficult to do, and in some cases requires sophisticated techniques. (The same applies to entrepreneurship. Few people will join/invest until you validate the idea and lower the risk.)
Sidenote: There are countless stories of academics putting forth original, non-mainstream ideas, only to be initially rejected by their peers (e.g. Cantor's infinity). I believe this not to be an issue just with outsiders, but merely that extraordinary claims require extraordinary proof. ML is an interesting example, because lots of so-called outsiders without a PhD now present at conferences!
If an outsider's objective is to be taken seriously, they should write papers and submit them to peer review (e.g. conferences and journals).
Yann LeCun has gone so far to say that independent work only counts as "science" if submitted to peer review:
"Without peer review and reproducibility, chances are your methodology was flawed and you fooled yourself into thinking you did something great." - https://x.com/ylecun/status/1795589846771147018?s=19.
From my experience, professors are very open to discuss ideas and their work with anyone who seems serious, interested, and knowledgeable. Even someone inside academia will face skepticism if their work uses completely different methods. They will have to very convincingly prove the methods are valid.
Double thanks for the extended discussion and ideas! Also interested to see what happens.
We earlier created some SAEs that completely remove the unigram directions from the encoder (e.g. old/gpt2_resid_pre_8_t8.pt).
However, a " Golden Gate Bridge" feature individually activates on " Golden" (plus prior context), " Gate" (plus prior), and " Bridge" (plus prior). Without the last-token/unigram directions these tended not to activate directly, complicating interpretability.
Yes to both! We varied expansion size for tokenized (8x-32x) and baseline (4x-64x), available in the Google Drive folder expansion-sweep. Just to be clear, our focus was on learning so-called "complex" features that do not solely activate based on the last token. So, we did not use the lookup biases as additional features (only for decoder reconstruction).
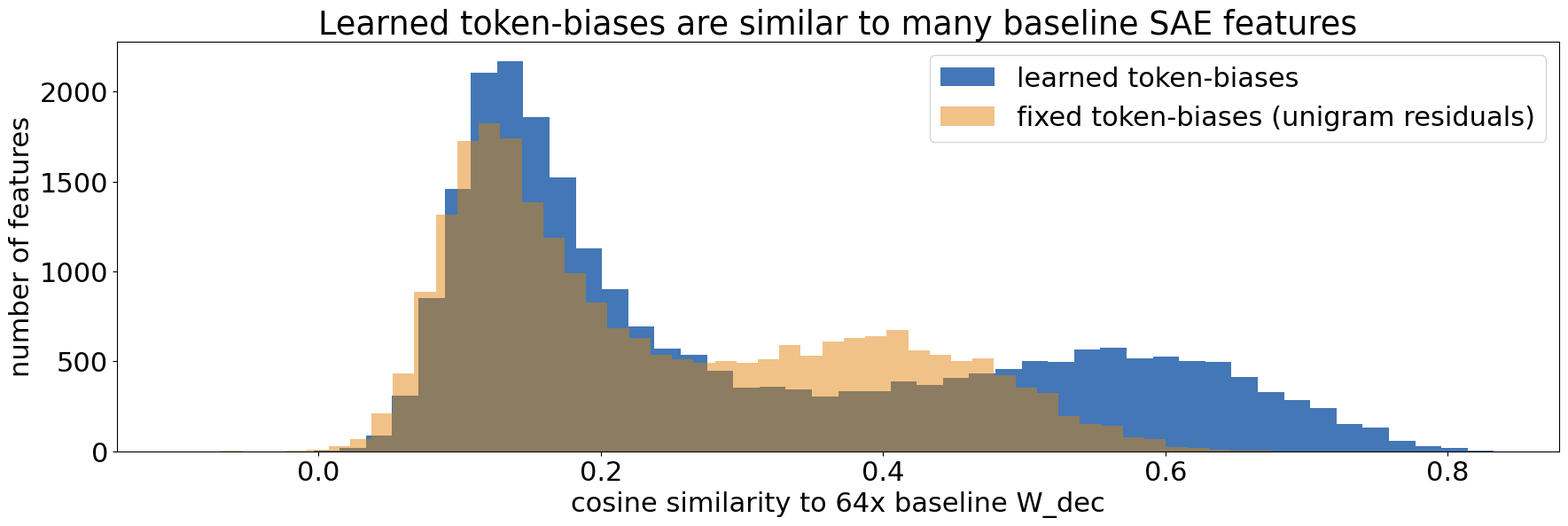
That said, ~25% of the suggested 64x baseline features are similar to the token-biases (cosine similarity 0.4-0.9). In fact, evolving the token-biases via training substantially increases their similarity (see figure). Smaller expansion sizes have up to 66% similar features and fewer dead features. (related sections above: 'Dead features' and 'Measuring "simple" features')
Additionally:
- We recommend using the
gpt2-layersdirectory, which includes resid_pre layers 5-11, topk=30, 12288 features (the tokenized "t" ones have learned lookup tables, pre-initialized with unigram residuals). - The folders
pareto-sweep,init-sweep, andexpansion-sweepcontain parameter sweeps, with lookup tables fixed to 2x unigram residuals.
In addition to the code repo linked above, for now here is some quick code that loads the SAE, exposes the lookup table, and computes activations only:
import torch
SAE_BASE_PATH = 'gpt2-layers/gpt2_resid_pre' # hook_pt = 'resid_pre'
layer = 8
state_dict = torch.load(f'{SAE_BASE_PATH}_{layer}_ot30.pt') # o=topk, t=tokenized, k=30
W_lookup = state_dict['lookup.W_lookup.weight'] # per-token decoder biases
def tokenized_activations(state_dict, x):
'Return pre-relu activations. For simplicity, does not limit to topk.'
return (x - state_dict['b_dec']) @ state_dict['W_enc'].T + state_dict['b_enc']
Indeed, similar tokens (e.g. "The" vs. " The") have similar token-biases (median max-cos-sim 0.89). This is likely because we initialize the biases with the unigram residuals, which mostly retain the same "nearby tokens" as the original embeddings.
Due to this, most token-biases have high cosine similarity to their respective unigram residuals (median 0.91). This indicates that if we use the token-biases as additional features, we can interpret the activations relative to the unigram residuals (as a somewhat un-normalized similarity, due to the dot product).
That said, the token-biases have uniquely interesting properties -- for one, they seem to be great "last token detectors". Suppose we take a last-row residual vector from an arbitrary 128-token prompt. Then, a max-cos-sim over the 50257 token-biases yields the prompt's exact last token with 88-98% accuracy (layers 10 down to 5), compared to only 35-77% accuracy using unigram residuals (see footnote 2).