Posts
Comments
Interesting, thanks for sharing! Are there specific existing ideas you think would be valuable for people to look at in the context of SAEs & language models, but that they are perhaps unaware of?
Thanks!
One cheap and lazy approach is to see how many of your features have high cosine similarity with the features of an existing L1-trained SAE (e.g. "900 of the 2048 features detected by the -trained model had cosine sim > 0.9 with one of the 2048 features detected by the L1-trained model").
I looked at the cosine sims between the L1-trained reference model and one of my SAEs presented above and found:
- 2501 out of 24576 (10%) of the features detected by the -trained model had cosine sim > 0.9 with one of the 24576 features detected by the L1-trained model.
- 7774 out of 24576 (32%) had cosine sim > 0.8
- 50% have cosine sim > 0.686
I'm not sure how to interpret these. Are they low/high? They appear to be roughly similar to if I compare between two of the -trained SAEs.
I'd also be interested to see individual examinations of some of the features which consistently appear across multiple training runs in the -trained model but don't appear in an L1-trained SAE on the training dataset.
I think I'll look more at this. Some summarised examples are shown in the response above.
Did you ever run just the L0-approx & sparsity-frequency penalty separately? It's unclear if you're getting better results because the L0 function is better or because there are less dead features.
Good point - this was also somewhat unclear to me. What I can say is that when I run with the L0-approx penalty only, without the sparsity frequency penalty, I either get lots of dead features (50% or more), with a substantially worse MSE (a factor of a few higher), similar to when I run with only an L1 penalty. When I run with the sparsity-frequency penalty and a standard L1 penalty (i.e. without L0-approx), I get models with a similar MSE and L0 a factor of ~2 higher than the SAEs discussed above.
Also, a feature frequency of 0.2 is very large! 1/5 tokens activating is large even for positional (because your context length is 128). It'd be bad if the improved results are because polysemanticity is sneaking back in through these activations. Sampling datapoints across a range of activations should show where the meaning becomes polysemantic. Is it the bottom 10% (or 10% of max-activating example is my preferred method)
Absolutely! A quick look at the 9 features with frequencies > 0.1 shows the following:
- Feature #8684 (freq: 0.992) fires with large amplitude on all but the BOS token (should I remove this in training?)
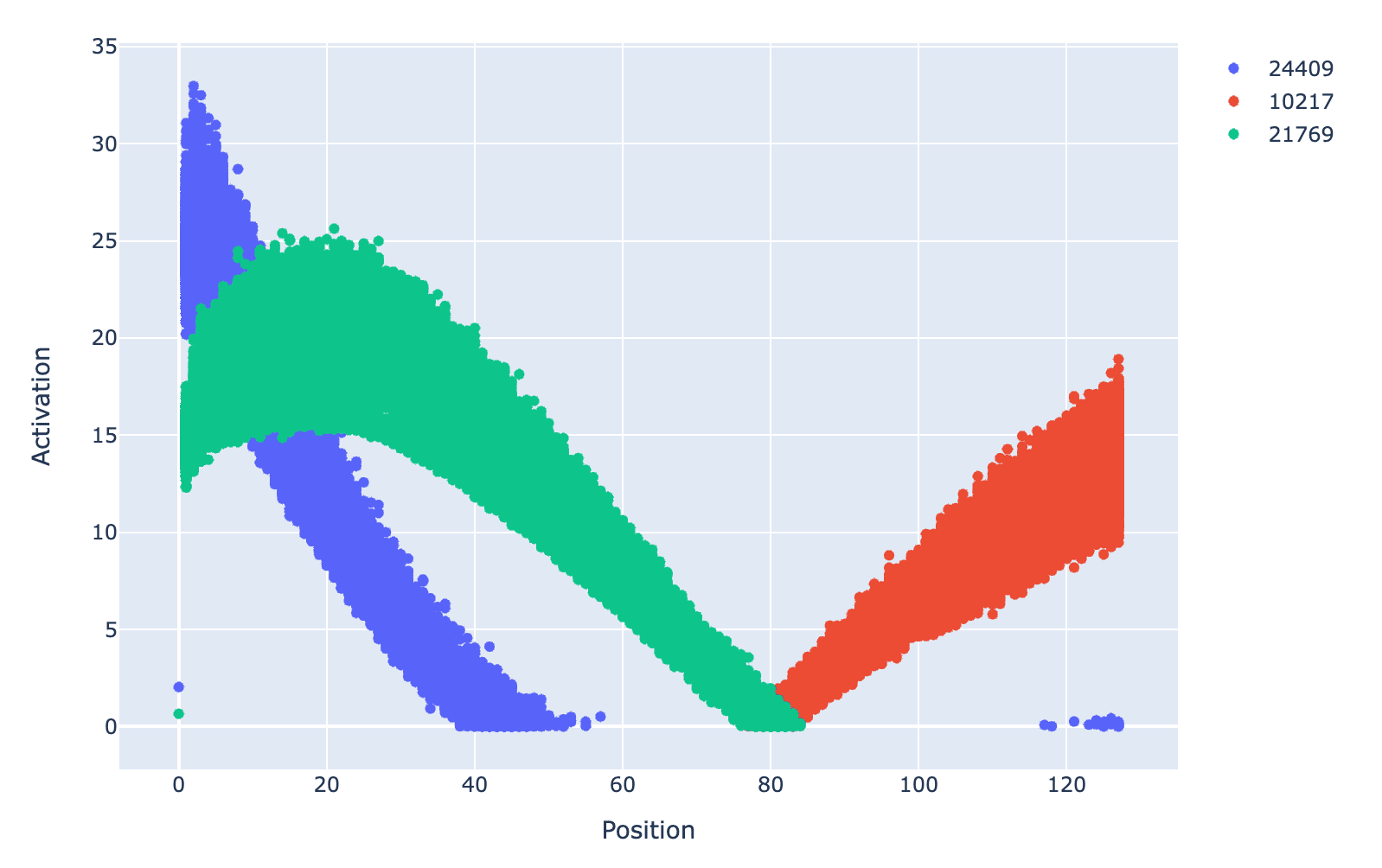
- Feature #21769 (freq: 0.627), 10217 (freq: 0.370) & 24409 (freq: 0.3372) are positional based, but possibly contain more info. The positional dependence of the activation strength for all non-zero activations is shown in the plot below for these three features. Here, the bottom 10% seem interpretable, at least the positional based info. Given the scatter in the plot, it looks like more info might be contained in the feature. Looking at max activations for a given position did not shed any further light. I don't know whether it's reasonable to expect GPT2-small to actually have & use features like this.
- Feature #21014 (freq: 0.220) fires at the 2nd position in sentences, after new lines and full stops, and then has smaller activations for 3rd, 4th & 5th position after new lines and full stops (so the bottom 10% seem interpretable, i.e. they are further away from the start of a sentence)
- Feature #16741 (freq: 0.171) unclear from the max/min activating examples, maybe polysemantic
- Feature #12123 (freq: 0.127) fires after "the", "an", "a", again stronger for the token immediately after, and weaker for 2nd, 3rd, 4th positions after. Bottom 10% seem interpretable in this context, but again there are some exceptions, so I'm not completely sure.
- Feature #22430 (freq: 0.127) fires after "," more strongly at the first position after "," and weaker for tokens at the 2nd, 3rd, 4th positions away from ",". The bottom 10% seem somewhat interpretable here, i.e. further after "," but there are exceptions so I'm not completely sure.
- Feature #6061(freq: 0.109) fires on nouns, both at high and low activations.
While I think these interpretations seem reasonable, it seems likely that some of these SAE features are at least somewhat polysemantic. They might be improved by training the SAE longer (I trained on ~300M tokens for these SAEs).
I might make dashboards or put the SAE on Neuronpedia to be able to make a better idea of these and other features.