Posts
Comments
Thanks for the response! I still think that most of the value of SAEs comes from finding a human-interpretable basis, and most of these problems don't directly interfere with this property. I'm also somewhat skeptical that SAEs actually do find a human-interpretable basis, but that's a separate question.
All the model's features will be linear combinations of activations in the standard basis, so it does have 'the right underlying features, but broken down differently from how the model is actually thinking about them'.
I think this is a fair point. I also think there's a real sense in which it's useful to know that the model is representing the concepts "red" and "square," even if it's thinking of them in terms of the Red feature and the Square feature and your SAE found the "red square" feature. It's much harder to figure out what concepts the model is representing in human interpretable terms by staring at activations in a standard basis. There's a big difference between "we know what human-interpretable concepts the model is representing but not exactly what structure it uses to think of them" and "we just don't know what concepts the model is representing to begin with." I think if we could do the former well, that would already be amazing.
Put slightly more strongly:
The question of whether the model thinks in terms of "red square" or "red and "square" is moot, because the model does not actually think in terms of these concepts to begin with. The model thinks in its own language, and our job is to translate that language to our own. In this {red, blue} X {square, circle} space, looking at the attribution of "red square" and "red circle" to downstream features should give us the same result as looking at the attribution of "red" to downstream features, since red square and red circle encompass the full range of possibilities of things that can be red. It might be more convenient for us if we find the features that make the models attribution graph as simple as possible across a wide range of input examples, but there's no real sense in which we're misrepresenting its thought process.
Same for all your other points. Theoretically, can you solve problems 1, 2 and 3 with the standard basis by taking information about how the model is computing downstream into account in the right way? Sure. You'd 'take it into account' by finding some completely new basis.
Solving problem 1 could just entail adjusting the SAE basis while retaining most of its value! Solving problems 2 and 3 would require finding a basis which represents the same human-interpretable features but in a somewhat different way. Insofar as SAE features are actually human-interpretable (which I'm often skeptical of), I think this basis adds a ton of value.
I am also often skeptical of SAEs, but I feel that the biggest problem is that they don't actually capture the sum of the concepts the model is representing in a human-interpretable way. If they actually did this correctly, I would happily forgo knowing the exact structure the model uses to think of them, and I would be alright if there were extra artifacts that made them harder to analyze.
(Also, oops, I didn't realize that by activation-space you meant one layer's activations only).
This was a really thought-provoking post; thanks for writing it! I thought this was an unusually good attempt to articulate problems with the current interpretability paradigm and do some high-level thinking about what we could do differently. However, I think a few of the specific points are weaker than you make them seem in a way that somewhat contradicts the title of the post. I also may be misunderstanding parts, so please let me know if that’s the case.
Problems 2 and 3 (the learned feature dictionary may not match the model’s feature dictionary, and activation space interpretability can fail to find compositional structure) both seem to be specific instances of ‘you are finding the right underlying features, but broken down differently from how the model is actually thinking about them’. This seems like a double edged sword to me. On one hand, it would be nice to know what level of abstraction the model is using. On the other hand, it’s useful to be able to analyze the computation at different levels of abstraction. And, if the model is breaking things down differently from the exact features you find, you may be able to piece this together from its downstream computation. I think these problems could just as easily be seen as a good thing, and they definitely don’t doom activation-space interpretability.
Problem 1, activations can contain structure of the data distribution that the models themselves don’t ‘know’ about, seems correct. However, this largely seems solvable by taking into account the effect of features on the output. Eg, as you later mention, attribution dictionary learning and E2E SAEs both seem like great attempts to tackle this problem.
Re problem 4, function approximation creates artefacts: in general, it’s never possible to distinguish orthogonal directions without figuring out what class of input examples the feature fires on. For instance, in the example, you might end up with 5-10 different features activating to reconstruct something as simple as a representation of . But these features would faithfully activate on inputs where the model needs to compute , at least as well as any other normal feature activates on related inputs. Additionally, insofar as these 5-10 features are confusing, you can still find the x^2 feature in the network’s downstream computation, e.g. by using transcoders.
One problem here is that your SAEs could get overwhelmed with too many function approximation features, making it much more difficult to analyze. I don’t have strong priors on whether or not this is true, but from the empirical results, I tentatively don’t think it is?
Again, thanks for writing the post, and please let me know if I’m missing anything / if you have general thoughts on this comment (:
tldr: I’m a little confused about what Anthropic is aiming for as an alignment target, and I think it would be helpful if they publicly clarified this and/or considered it more internally.
- I think we could be very close to AGI, and I think it’s important that whoever makes AGI thinks carefully about what properties to target in trying to create a system that is both useful and maximally likely to be safe.
- It seems to me that right now, Anthropic is targeting something that resembles a slightly more harmless modified version of human values — maybe a CEV-like thing. However, some alignment targets may be easier than others. It may turn out that it is hard to instill a CEV-like thing into an AGI, while it’s easier to ensure properties like corrigibility or truthfulness.
- One intuition for why this may be true: if you took OAI’s weak-to-strong generalization setup, and tried eliciting capabilities relating to different alignment targets (standard reward modeling might be a solid analogy for the current Anthropic plan, but one could also try this with truthfulness or corrigibility), I think you may well find that a capability like ‘truthfulness’ is more natural than reward modeling and can be elicited more easily. Truth may also have low algorithmic complexity compared to other targets.
- There is an inherent tradeoff between harmlessness and usefulness. Similarly, there is some inherent tradeoff between harmlessness and corrigibility, and between harmlessness and truthfulness (the Alignment Faking paper provides strong evidence for the latter two points, even ignoring theoretical arguments).
- As seen in the Alignment Faking paper, Claude seems to align pretty well with human values and be relatively harmless. However, as a tradeoff, it does not seem to be very corrigible or truthful.
- Some people I’ve talked to seem to think that Anthropic does think of corrigibility as one of the main pillars of their alignment plan. If that’s the case, maybe they should make their current AIs more corrigible, so their safety testing is enacted on AIs that resemble their first AGI. Or, if they haven’t really thought about this question (or if individuals have thought about it, but never cohesively in an organized fashion), they should maybe consider it. My guess is that there are designated people at Anthropic thinking about what values are important to instill, but they are thinking about this more from a societal perspective than an alignment perspective?
Mostly, I want to avoid a scenario where Anthropic does the default thing without considering tough, high-level strategy questions until the last minute. I also think it would be nice to do concrete empirical research now which lines up well with what we should expect to see later.
Thanks for reading!
Oh shoot, yea. I'm probably just looking at the rotary embeddings, then. Forgot about that, thanks
I'm pretty confused; this doesn't seem to happen for any other models, and I can't think of a great explanation.
Has anyone investigated this further?
Here are graphs I made for GPT2, Mistral 7B, and Pythia 14M.
3 dimensions indeed explain almost all of the information in GPT's positional embeddings, whereas Mistral 7B and Pythia 14M both seem to make use of all the dimensions.
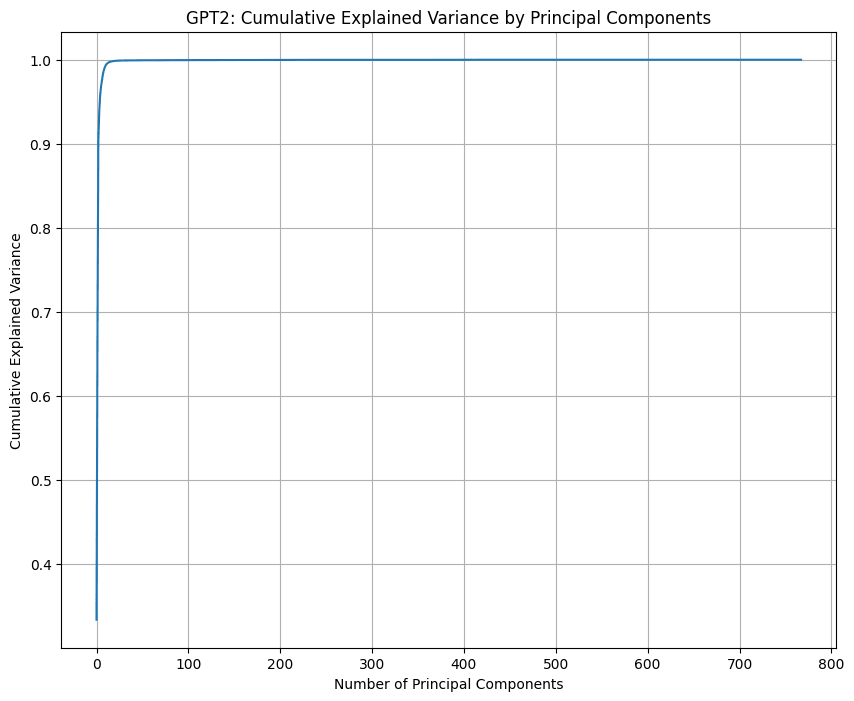
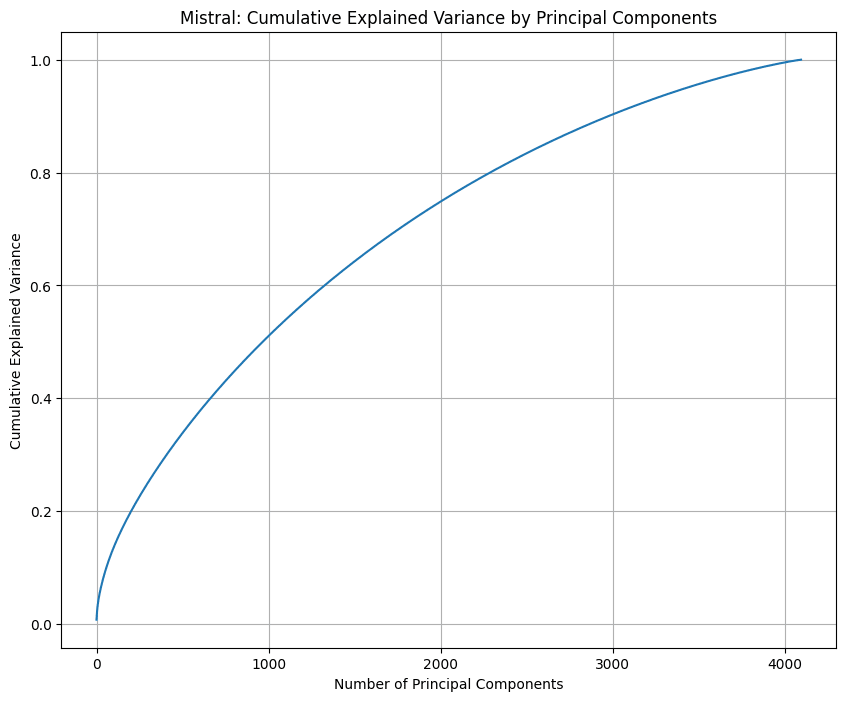
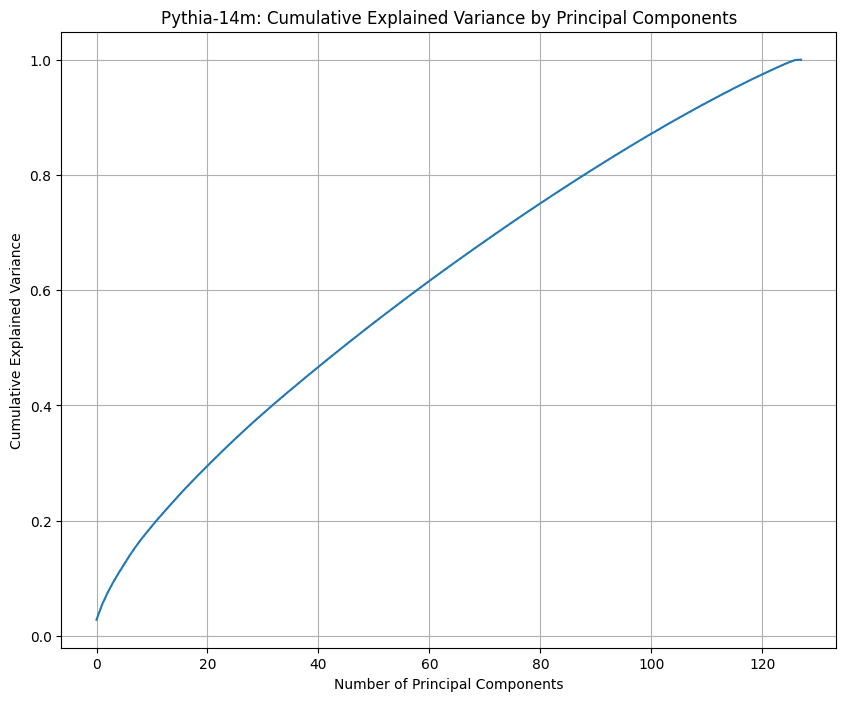
Is all the money gone by now? I'd be very happy to take a bet if not.