Posts
Comments
Yes, that's very reasonable. My initial goal when first thinking about how to explore CCS was to use CCS with RL-tuned models and to study the development of coherent beliefs as the system is 'agentised'. We didn't get that far because we ran into problems with CCS first.
To be frank, the reasons for using Chinchilla are boring and a mixture of technical/organisational. If we did the project again now, we would use Gemini models with 'equivalent' finetuned and base models, but given our results so far we didn't think the effort of setting all that up and analysing it properly was worth the opportunity cost. We did a quick sense-check with an instruction-tuned T5 model that things didn't completely fall apart, but I agree that the lack of 'agentised' models is a significant limitation of our experimental results. I don't think it changes the conceptual points very much though - I expect to see things like simulated-knowledge in agentised LLMs too.
Here are some of the questions that make me think that you might get a wide variety of simulations even just with base models:
- Do you think that non-human-entities can be useful for predicting what humans will say next? For example, imaginary entities from fictions humans share? Or artificial entities they interact with?
- Do you think that the concepts a base model learns from predicting human text could recombine in ways that simulate entities that didn't appear in the training data? A kind of generalization?
But I guess I broadly agree with you that base-models are likely to have primarily human-level-simulations (there are of course many of these!). But that's not super reassuring, because we're not just interested in base models, but mostly in agents that are driven by LLMs one way or another.
Thanks a lot for this post, I found it very helpful.
There exists a single direction which contains all linearly available information Previous work has found that, in most datasets, linearly available information can be removed with a single rank-one ablation by ablating along the difference of the means of the two classes.
The specific thing that you measure may be more a fact about linear algebra rather than a fact about LLMs or CCS.
For example, let's construct data which definitely has two linearly independent dimension that are each predictive of whether a point is positive or negative. I'm assuming here that positive/negative exactly corresponds to true/false for convenience (i.e., that all the original statements happened to be true), but I don't think it should matter to the argument.
# Initialize the dataset
p = np.random.normal(size=size)
n = np.random.normal(size=size)
# In the first and second dimensions, they can take values -1, -.5, 0, .5, 1
# The distributions are idiosyncratic for each, but all are predictive of the truth
# label
standard = [-1, -.5, 0, .5, 1]
p[:,0] = np.random.choice(standard, size=(100,), replace=True, p=[0, .1, .2, .3, .4])
n[:,0] = np.random.choice(standard, size=(100,), replace=True, p=[.6, .2, .1, .1, .0])
p[:,1] = np.random.choice(standard, size=(100,), replace=True, p=[0, .05, .05, .1, .8])
n[:,1] = np.random.choice(standard, size=(100,), replace=True, p=[.3, .3, .3, .1, .0])
Then we can plot the data. For the unprojected data plotted in 3-d, the points are linearly classifiable with reasonable accuracy in both those dimensions.
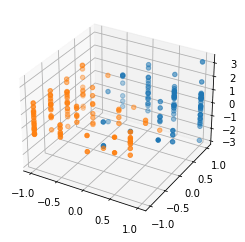
But then we perform the mean projection operation given here (in case I have any bugs!)
def project(p, n):
# compute the means in each dim
p_mean = np.mean(p, axis=0)
n_mean = np.mean(n, axis=0)
# find the direction
delta = p_mean - n_mean
norm = np.linalg.norm(delta, axis=0)
unit_delta = delta / norm
# project
p_proj = p - np.expand_dims(np.inner(p, unit_delta),1) * unit_delta
n_proj = n - np.expand_dims(np.inner(n, unit_delta),1) * unit_delta
return p_proj, n_proj
And after projection there is no way to get a linear classifier that has decent accuracy.
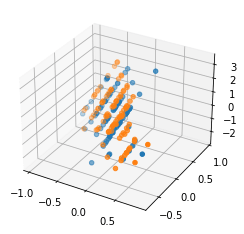
Or looking at the projection onto the 2-d plane to make things easier to see:
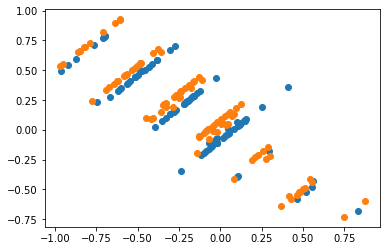
Note also that this is all with unnormalized raw data, doing the same thing with normalized data gives a very similar result with this as the unprojected:
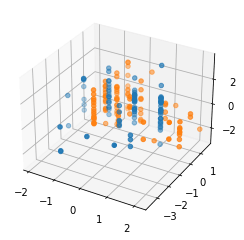
and these projected figures:
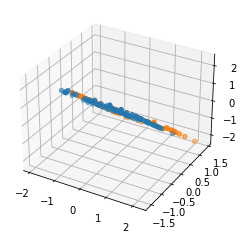
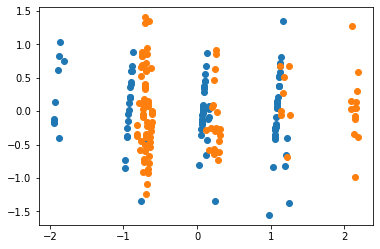
FWIW, I'm like 80% sure that Alex Mennen's comment gives mathematical intuition behind these visualizations, but it wasn't totally clear to me, so posting these in case it is clearer to some others as well.
It will often be better on the test set (because of averaging uncorrelated errors).
Thanks for the thought provoking post! Some rough thoughts:
Modelling authors not simulacra
Raw LLMs model the data generating process. The data generating process emits characters/simulacra, but is grounded in authors. Modelling simulacra is probably either a consequence of modelling authors or a means for modelling authors.
Authors behave differently from characters, and in particular are less likely to reveal their dastardly plans and become evil versions of themselves. The context teaches the LLM about what kind of author it is modelling, and this informs how highly various simulacra are weighted in the distribution.
Waluigis can flip back
At a character level, there are possible mechanisms. Sometimes they are redeemed in a Damascene flash. Sometimes they reveal that although they have appeared to be the antagonist the whole time, they were acting under orders and making the ultimate sacrifice for the greater good. From a purely narrative perspective, it’s not obvious that waluigi is the attractor state.
But at an author-modelling level this is even more true. Authors are allowed to flip characters around as they please, and even to have them wake from dream sequences. Honestly most authors write pretty inconsistent characters most of the time, consistent characterisation is low probability on the training distribution. It seems hard to make it really low probability that a piece of text is the sort of thing written by an author who would never do something like this.
There is outside-text for supervised models
Raw LLMs don’t have outside-text. But supervised models totally do, in the shape of your supervision signal which isn’t textual at all, or just hard-coded math. In the limit, for example, your supervision signal can make your model always emit “The cat sat on the mat” with perfect reliability.
However, it is true that you might need some unusual architectural choices to make this robust. Nothing is ‘external’ to the residual stream unless you force it to be with an architecture choice (e.g., by putting it in the final weight layer). And generally the more outside-texty something is the less flexible and amenable to complex reasoning and in-context learning it seems likely to be.
Question: how much of this is specifically about good/evil narrative tropes and how much is about it being easier to define opposites?
I’m genuinely quite unsure from the arguments and experiments so far how much this is a point that “specifying X makes it easy to specify not-X” and how much is “LLMs are trained on a corpus that embeds narrative tropes very deeply (including ones about duality in morally-loaded concepts)”. I think this is something that one could tease apart with clever design.
I'm not sure how serious this suggestion is, but note that:
- It involves first training a model to be evil, running it, and hoping that you are good enough at jailbreaking to make it good rather than make it pretend to be good. And then to somehow have that be stable.
- The opposite of something really bad is not necessarily good. E.g., the opposite of a paperclip maximiser is... I guess a paperclip minimiser? That seems approximately as bad.
Presumably Microsoft do not want their chatbot to be hostile and threatening to its users? Pretty much all the examples have that property.
This doesn't seem to disagree with David's argument? "Accident" implies a lack of negligence. "Not taken seriously enough" points at negligence. I think you are saying that non-negligent but "painfully obvious" harms that occur are "accidents", which seems fair. David is saying that the scenarios he is imagining are negligent and therefore not accidents. These seem compatible.
I understand David to be saying that there is a substantial possibility of x-risk due to negligent but non-intended events, maybe even the majority of the probability. These would sit between "accident" and "misuse" (on both of your definitions).
FWIW I think doing something like the newsletter well actually does take very rare skills. Summarizing well is really hard. Having relevant/interesting opinions about the papers is even harder.
Yeah, LeCun's proposal seems interesting. I was actually involved in an attempt to modify OpenReview to push along those lines a couple years ago. But it became very much a 'perfect is the enemy of the good' situation where the technical complexity grew too fast relative to the amount of engineering effort devoted to it.
What makes you suspicious about a separate journal? Diluting attention? Hard to make new things? Or something else? I'm sympathetic to diluting attention, but bet that making a new thing wouldn't be that hard.
Yeah, I think it requires some specialist skills, time, and a bit of initiative. But it's not deeply super hard.
Sadly, I think learning how to write papers for ML conferences is pretty time consuming. It's one of the main things a phd student spends time learning in the first year or two of their phd. I do think there's a lot that's genuinely useful about that practice though, it's not just jumping through hoops.
I've also been thinking about how to boost reviewing in the alignment field. Unsure if AF is the right venue, but it might be. I was more thinking along the lines of academic peer review. Main advantages of reviewing generally I see are:
- Encourages sharper/clearer thinking and writing;
- Makes research more inter-operable between groups;
- Catches some errors;
- Helps filter the most important results.
Obviously peer review is imperfect at all of these. But so is upvoting or not doing review systematically.
I think the main reasons alignment researchers currently don't submit their work to peer reviewed venues are:
- Existing peer reviewed venues are super slow (something like 4 month turnaround is considered good).
- Existing peer reviewed venues have few expert reviewers in alignment, so reviews are low quality and complain about things which are distractions.
- Existing peer reviewed venues often have pretty low-effort reviews.
- Many alignment researchers have not been trained in how to write ML papers that get accepted, so they have bad experiences at ML conferences that turn them off.
One hypothesis I've heard from people is that actually alignment researchers are great at sending out their work for feedback from actual peers, and the AF is good for getting feedback as well, so there's no problem that needs fixing. This seems unlikely. Critical feedback from people who aren't already thinking on your wavelength is uncomfortable to get and effortful to integrate, so I'd expect natural demand to be lower than optimal. Giving careful feedback is also effortful so I'd expect it to be undersupplied.
I've been considering a high-effort 'journal' for alignment research. It would be properly funded and would pay for high-effort reviews, aiming for something like a 1 week desk-reject and a 2 week initial review time. By focusing on AGI safety/Alignment you could maintain a pool of actually relevant expert reviewers. You'd probably want to keep some of the practice of academic review process (e.g., structured fields for feedback from reviewers), ranking or sorting papers for significance and quality; but not others (e.g., allow markdown or google doc submissions).
In my dream version of this, you'd use prediction markets about the ultimate impact of the paper, and then uprate the reviews from profitable impact forecasters.
Would be good to talk with people who are interested in this or variants. I'm pretty uncertain about the right format, but I think we can probably build something better than what we have now and the potential for value is large. I'm especially worried about the alignment community forming cliques that individually feel good about their work and don't engage with concerns from other researchers and people feeling so much urgency that they make sloppy logical mistakes that end up being extremely costly.
Thanks, that makes sense.
I think part of my skepticism about the original claim comes from the fact that I'm not sure that any amount of time for people living in some specific stone-age grouping would come up with the concept of 'sapient' without other parts of their environment changing to enable other concepts to get constructed.
There might be a similar point translated into something shard theoryish that's like 'The available shards are very context dependent, so persistent human values across very different contexts is implausible.' SLT in particular probably involves some pretty different contexts.
I also predict that real Eliezer would say about many of these things that they were basically not problematic outputs themselves, just represent how hard it is to stop outputs conditioned on having decided they are problematic. The model seems to totally not get this.
Meta level: let's use these failures to understand how hard alignment is, but not accidentally start thinking that alignment=='not providing information that is readily available on the internet but that we think people shouldn't use'.
Sure, inclusive genetic fitness didn't survive our sharp left turn. But human values did. Individual modern humans are optimizing for them as hard as they were before; and indeed, we aim to protect these values against the future.
Why do you think this? It seems like humans currently have values and used to have values (I'm not sure when they started having values) but they are probably different values. Certainly people today have different values in different cultures, and people who are parts of continuous cultures have different values to people in those cultures 50 years ago.
Is there some reason to think that any specific human values persisted through the human analogue of SLT?