Posts
Comments
This is fascinating. JW plays C in the last round, even though AA just played D in the next-to-last round. What explains that? Maybe JW's belief in his own heroic story is strong enough to make him sacrifice his self-interest?
Theoretically, of course, utility functions are invariant up to affine transformation, so a utility's absolute sign is not meaningful. But this is not always a good metaphor for real life.
So you're suggesting that real life has some additional structure which is not representable in ordinary game theory formalism? Can you think of an extension to game theory which can represent it? (Mathematically, not just metaphorically.)
Robin, what is your favorite piece of academic philosophy that argues about values?
Nicholas, our own universe may have an infinite volume, and it's only the speed of light that limits the size of the observable universe. Given that infinite universes are not considered implausible, and starlines are not considered implausible (at least as a fictional device), I find it surprising that you consider starlines that randomly connect a region of size 2^(10^20) to be implausible.
Starlines have to have an average distance of something, right? Why not 2^(10^20)?
Nicholas, suppose Eliezer's fictional universe contains a total of 2^(10^20) star systems, and each starline connects two randomly selected star systems. With a 20 hour doubling speed, the Superhappies, starting with one ship, can explore 2^(t36524/20) random star systems after t years. Let's say the humans are expanding at the same pace. How long will it take, before humans and Superhappies will meet again?
According to the birthday paradox, they will likely meet after each having explored about sqrt(2^(10^20)) = 2^(510^19) star systems, which will take 510^19/(365*24/20) or approximately 10^17 years to accomplish. That should be enough time to get over our attachment to "bodily pain, embarrassment, and romantic troubles", I imagine.
But the tech in the story massively favors the defense, to the point that a defender who is already prepared to fracture his starline network if attacked is almost impossible to conquer (you’d need to advance faster than the defender can send warnings of your attack while maintaining perfect control over every system you’ve captured). So an armed society would have a good chance of being able to cut itself off from even massively superior aliens, while pacifists are vulnerable to surprise attacks from even fairly inferior ones.
I agree, and that's why in my ending humans conquer the Babyeaters only after we develop a defense against the supernova weapon. The fact that the humans can see the defensive potential of this weapon, but the Babyeaters and the Superhappies can't, is a big flaw in the story. The humans sacrificed billions in order to allow the Superhappies to conquer the Babyeaters, but that makes sense only if the Babyeaters can't figure out the same defense that the humans used. Why not?
Also, the Superhappies' approach to negotiation made no game theoretic sense. What they did was, offer a deal to the other side. If they don't accept, impose the deal on them anyway by force. If they do accept, trust that they will carry out the deal without try to cheat. Given these incentives, why would anyone facing a Superhappy in negotiation not accept and then cheat? I don't see any plausible way in which this morality/negotiation strategy could have become a common one in Superhappy society.
Lastly, I note that the Epilogue of the original ending could be named Atonement as well. After being modified by the Superhappies (like how the Confessor was "rescued"?), the humans would now be atoning for having forced their children suffer pain. What does this symmetry tell us, if anything?
So, what about the fact that all of humanity now knows about the supernova weapon? How is it going to survive the next few months?
In case it wasn't clear, the premise of my ending is that the Ship's Confessor really was a violent thief and drug dealer from the 21th century, but his "rescue" was only partially successful. He became more rational, but only pretended to accept what became the dominant human morality of this future, patiently biding time his whole life for an opportunity like this.
The Ship's Confessor uses the distraction to anesthetizes everyone except the pilot. He needs the pilot to take command of the starship and to pilot it. The ship stays to observe which star the Superhappy ship came from, then takes off for the nearest Babyeater world. They let the Babyeaters know what happened, and tell them to supernova the star that Superhappies came from at all costs.
When everyone wakes up, the Ship's Confessor convinces the entire crew to erase their memory of the true Alderson's Coupling Constant, ostensibly for the good of humanity. He pretends to do so himself, but doesn't. After the ship returns to human space, he uses his accumulated salary to build a series of hidden doomsday devices around every human colony, and becomes the dictator of humanity through blackmail. Everyone is forced to adopt an utility function of his choosing as their own. With every resource of humanity devoted to the subject, scientists under his direction eventually discover a defense against the supernova weapon, and soon after that, the Babyeaters are conquered, enslaved, and farmed for their crystal brains. Those brains, when extracted and networked in large arrays, turn out to be the cheapest and most efficient computing substrate in the universe. These advantages provide humanity with such a strong competitive edge, that it never again faces an alien that is its match, at least militarily.
Before the universe ends in a big crunch, the Confessed (humanity's eventual name) goes on to colonize more than (10^9)^(10^9) star systems, and to meet and conquer almost as many alien species, but the Superhappy people are never seen again. Their fate becomes one of the most traded futures in the known universe, but those bets will have to remain forever unsettled.
Eliezer, I see from this example that the Axiom of Independence is related to the notion of dynamic consistency. But, the logical implication goes only one way. That is, the Axiom of Independence implies dynamic consistency, but not vice versa. If we were to replace the Axiom of Independence with some sort of Axiom of Dynamic Consistency, we would no longer be able to derive expected utility theory. (Similarly with dutch book/money pump arguments, there are many ways to avoid them besides being an expected utility maximizer.)
I'm afraid that the Axiom of Independence cannot really be justified as a basic principle of rationality. Von Neumann and Morgenstern probably came up with it because it was mathematically necessary to derive Expected Utility Theory, then they and others tried to justify it afterward because Expected Utility turned out to be such an elegant and useful idea. Has anyone seen Independence proposed as a principle of rationality prior to the invention of Expected Utility Theory?
To expand on my categorization of values a bit more, it seems clear to me that at least some human value do not deserved to be forever etched into the utility function of a singleton. Those caused by idiosyncratic environmental characteristics like taste for salt and sugar, for example. To me, these are simply accidents of history, and I wouldn't hesitate (too much) to modify them away in myself, perhaps to be replaced by more interesting and exotic tastes.
What about reproduction? It's a value that my genes programmed into me for their own purposes, so why should I be obligated to stick with it forever?
Or consider boredom. Eventually I may become so powerful that I can easily find the globally optimal course of action for any set of goals I might have, and notice that the optimal course of action often involves repetition of some kind. Why should I retain my desire not to do the same thing over and over again, which was programmed into me by evolution back when minds had a tendency to get stuck in local optimums?
And once I finally came to that realization, I felt less ashamed of values that seemed 'provincial' - but that's another matter.
Eliezer, I wonder if this actually has more to do with your current belief that rationality equals expected utility maximization. For an expected utility maximizer, there is no distinction between 'provincial' and 'universal' values, and certainly no reason to ever feel ashamed of one's values. One just optimizes according to whatever values one happens to have. But as I argued before, human beings are not expected utility maximizers, and I don't see why we should try to emulate them, especially this aspect.
Tim and Tyrrell, do you know the axiomatic derivation of expected utility theory? If you haven't read http://cepa.newschool.edu/het/essays/uncert/vnmaxioms.htm or something equivalent, please read it first.
Yes, if you change the spaces of states and choices, maybe you can encode every possible agent as an utility function, not just those satisfying certain axioms of "rationality" (which I put in quotes because I don't necessarily agree with them), but that would be to miss the entire point of expected utility theory, which is that it is supposed to be a theory of rationality, and is supposed to rule out irrational preferences. That means using state and choice spaces where those axiomatic constraints have real world meaning.
A utility function is like a program in a Turing-complete language. If the behaviour can be computed at all, it can be computed by a utility function.
Tim, I've seen you state this before, but it's simply wrong. A utility function is not like a Turing-complete language. It imposes rather strong constraints on possible behavior.
Consider a program which when given the choices (A,B) outputs A. If you reset it and give it choices (B,C) it outputs B. If you reset it again and give it choices (C,A) it outputs C. The behavior of this program cannot be reproduced by a utility function.
Here's another example: When given (A,B) a program outputs "indifferent". When given (equal chance of A or B, A, B) it outputs "equal chance of A or B". This is also not allowed by EU maximization.
If the aliens' wetware (er, crystalware) is so efficient that their children are already sentient when they are still tiny relative to adults, why don't the adults have bigger brains and be much more intelligent than humans? Given that they also place high values on science and rationality, had invented agriculture long before humans did, and haven't fought any destructive wars recently, it makes no sense that they have a lower level of technology than humans at this point.
Other than that, I think the story is not implausible. The basic lesson here is the same as in Robin's upload scenarios: when sentience is really cheap, no one will be valued (much) just for being sentient. If we want people to be valued just for being sentient, either the wetware/crystalware/hardware can't be too efficient, or we need to impose some kind of artificial scarcity on sentience.
Maybe we don't mean the same thing by boredom?
I'm using Eliezer's definition: a desire not to do the same thing over and over again. For a creature with roughly human-level brain power, doing the same thing over and over again likely means it's stuck in a local optimum of some sort.
Genome equivalents which don't generate terminally valued individual identity in the minds they descrive should outperform those that do.
I don't understand this. Please elaborate.
Why not just direct expected utility? Pain and pleasure are easy to find but don't work nearly as well.
I suppose you mean why not value external referents directly instead of indirectly through pain and pleasure. As long as wireheading isn't possible, I don't see why the latter wouldn't work just as well as the former in many cases. Also, the ability to directly value external referents depends on a complex cognitive structure to assess external states, which may be more vulnerable in some situations to external manipulation (i.e. unfriendly persuasion or parasitic memes) than hard-wired pain and pleasure, although the reverse is probably true in other situations. It seems likely that evolution would come up with both.
Define sexual. Most sexual creatures are too simple to value the first two. Most plausible posthumans aren't sexual in a traditional sense.
I mean reproduction where more than one party contributes genetic material and/or parental resources. Even simple sexual creatures probably have some notion of beauty and/or status to help attract/select mates, but for the simplest perhaps "instinct" would be a better word than "value".
- likely values for intelligent creatures with sexual reproduction (music, art, literature, humor)
Disagree.
These all help signal fitness and attract mates. Certainly not all intelligent creatures with sexual reproduction will value exactly music, art, literature, and humor, but it seems likely they will have values that perform the equivalent functions.
We can sort the values evolution gave us into the following categories (not necessarily exhaustive). Note that only the first category of values is likely to be preserved without special effort, if Eliezer is right and our future is dominated by singleton FOOM scenarios. But many other values are likely to survive naturally in alternative futures.
- likely values for all intelligent beings and optimization processes (power, resources)
- likely values for creatures with roughly human-level brain power (boredom, knowledge)
- likely values for all creatures under evolutionary competition (reproduction, survival, family/clan/tribe)
- likely values for creatures under evolutionary competition who cannot copy their minds (individual identity, fear of personal death)
- likely values for creatures under evolutionary competition who cannot wirehead (pain, pleasure)
- likely values for creatures with sexual reproduction (beauty, status, sex)
- likely values for intelligent creatures with sexual reproduction (music, art, literature, humor)
- likely values for intelligent creatures who cannot directly prove their beliefs (honesty, reputation, piety)
- values caused by idiosyncratic environmental characteristics (salt, sugar)
- values caused by random genetic/memetic drift and co-evolution (Mozart, Britney Spears, female breasts, devotion to specific religions)
The above probably isn't controversial, rather the disagreement is mainly on the following:
- the probabilities of various future scenarios
- which values, if any, can be preserved using approaches such as FAI
- which values, if any, we should try to preserve
I agree with Roko that Eliezer has made his case in an impressive fashion, but it seems that many of us are still not convinced on these three key points.
Take the last one. I agree with those who say that human values do not form a consistent and coherent whole. Another way of saying this is that human beings are not expected utility maximizers, not as individuals and certainly not as societies. Nor do most of us desire to become expected utility maximizers. Even amongst the readership of this blog, where one might logically expect to find the world's largest collection of EU-maximizer wannabes, few have expressed this desire. But there is no principled way to derive an utility function from something that is not an expected utility maximizer!
Is there any justification for trying to create an expected utility maximizer that will forever have power over everyone else, whose utility function is derived using a more or less arbitrary method from the incoherent values of those who happen to live in the present? That is, besides the argument that it is the only feasible alternative to a null future. Many of us are not convinced of this, neither the "only" nor the "feasible".
Why make science a secret, instead of inventing new worlds with new science for people to explore? Have you heard of "Theorycraft"? It's science applied to the World of Warcraft, and for some, Theorycraft is as much fun as the game it's based on.
Is there something special about the science of base-level reality that makes it especially fun to explore and discover? I think the answer is yes, but only if it hasn't already been explored and then covered up again and made into a game. It's the difference between a natural and an artificial challenge.
One day we'll discover the means to quickly communicate insights from one individual to another, say by directly copying and integrating the relevant neural circuitry. Then, in order for an insight to be Fun, it will have to be novel to transhumanity, not just the person learning or discovering it. Learning something the fast efficient way will not be Fun because there's not true effort. Pretending that the new way doesn't exist, and learning the old-fashioned way, will not be Fun because there's not true victory.
I'm not sure there are enough natural problems in the universe to supply the whole of transhumanity with an adequate quantity of potential insights. "Natural" meaning not invented for the sole purpose of providing an artificial challenge. Personally, I can't see how solving the n-th random irrelevant mathematical problem is any better than lathing the n-th table leg.
Anna Salamon wrote: Is it any safer to think ourselves about how to extend our adaptation-executer preferences than to program an AI to figure out what conclusions we would come to, if we did think a long time?
First, I don't know that "think about how to extend our adaptation-executer preferences" is the right thing to do. It's not clear why we should extend our adaptation-executer preferences, especially given the difficulties involved. I'd backtrack to "think about what we should want".
Putting that aside, the reason that I prefer we do it ourselves is that we don't know how to get an AI to do something like this, except through opaque methods that can't be understood or debugged. I imagine the programmer telling the AI "Stop, I think that's a bug." and the AI responding with "How would you know?"
g wrote: Wei Dai, singleton-to-competition is perfectly possible, if the singleton decides it would like company.
In that case the singleton might invent a game called "Competition", with rules decided by itself. Anti-prediction says that it's pretty unlikely those rules would happen to coincide with the rules of base-level reality, so base-level reality would still be controlled by the singleton.
Robin wrote: Having to have an answer now when it seems an likely problem is very expensive.
(I think you meant to write "unlikely" here instead of "likely".)
Robin, what is your probability that eventually humanity will evolve into a singleton (i.e., not necessarily through Eliezer's FOOM scenario)? It seems to me that competition is likely to be unstable, whereas a singleton by definition is. Competition can evolve into a singleton, but not vice versa. Given that negentropy increases as mass squared, most competitors have to remain in the center, and the possibility of a singleton emerging there can't ever be completely closed off. BTW, a singleton might emerge from voluntary mergers, not just one competitor "winning" and "taking over".
Another reason to try to answer now, instead of later, is that coming up with a good answer would persuade more people to work towards a singleton, so it's not just a matter of planning for a contingency.
An expected utility maximizer would know exactly what to do with unlimited power. Why do we have to think so hard about it? The obvious answer is that we are adaptation executioners, not utility maximizers, and we don't have an adaptation for dealing with unlimited power. We could try to extrapolate an utility function from our adaptations, but given that those adaptations deal only with a limited set of circumstances, we'll end up with an infinite set of possible utility functions for each person. What to do?
James D. Miller: But about 100 people die every minute!
Peter Norvig: Refusing to act is like refusing to allow time to pass.
What about acting to stop time? Preserve Earth at 0 kelvin. Gather all matter/energy/negentropy in the rest of the universe into secure storage. Then you have as much time as you want to think.
Maybe we don't need to preserve all of the incompressible idiosyncrasies in human morality. Considering that individuals in the post-Singularity world will have many orders of magnitude more power than they do today, what really matter are the values that best scale with power. Anything that scales logarithmically for example will be lost in the noise compared to values that scale linearly. Even if we can't understand all of human morality, maybe we will be able to understand the most important parts.
Just throwing away parts of one's utility function seems bad. That can't be optimal right? Well, as Peter de Blanc pointed out, it can be if there is no feasible alternative that improves expected utility under the original function. We should be willing to lose our unimportant values to avoid or reduce even a small probability of losing the most important ones. With CEV, we're supposed to implement it with the help of an AI that's not already Friendly, and if we don't get it exactly right on the first try, we can't preserve even our most important values. Given that we don't know how to safely get an unFriendly AI to do anything, much less something this complicated, the probability of failure seems quite large.
(Eliezer, why do you keep using "intelligence" to mean "optimization" even after agreeing with me that intelligence includes other things that we don't yet understand?)
Morality does not compress
You can't mean that morality literally does not compress (i.e. is truly random). Obviously there are plenty of compressible regularities in human morality. So perhaps what you mean is that it's too hard or impossible to compress it into a small enough description that humans can understand. But, we also have no evidence that effective universal optimization in the presence of real-world computational constraints (as opposed to idealized optimization with unlimited computing power) can be compressed into a small enough description that humans can understand.
Eliezer, you write as if there is no alternative to this plan, as if your hand is forced. But that's exactly what some people believe about neural networks. What about first understanding human morality and moral growth, enough so that we (not an AI) can deduce and fully describe someone's morality (from his brain scan, or behavior, or words) and predict his potential moral growth in various circumstances, and maybe enough to correct any flaws that we see either in the moral content or in the growth process, and finally program the seed AI's morality and moral growth based on that understanding once we're convinced it's sufficiently good? Your logic of (paraphrasing) "this information exists only in someone's brain so I must let the AI grab it directly without attempting to understand it myself" simply makes no sense. First the conclusion doesn't follow from the premise, and second if you let the AI grab and extrapolate the information without understanding it yourself, there is no way you can predict a positive outcome.
In case people think I'm some kind of moralist for harping on this so much, I think there are several other aspects of intelligence that are not captured by the notion of "optimization". I gave some examples here. We need to understand all aspects of intelligence, not just the first facet for which we have a good theory, before we can try to build a truly Friendly AI.
Eliezer, as far as I can tell, "reflective equilibrium" just means "the AI/simulated non-sentient being can't think of any more changes that it wants to make" so the real question is what counts as a change that it wants to make? Your answer seems to be whatever is decided by "a human library of non-introspectively-accessible circuits". Well the space of possible circuits is huge, and "non-introspectively-accessible" certainly doesn't narrow it down much. And (assuming that "a human library of circuits" = "a library of human circuits") what is a "human circuit"? A neural circuit copied from a human being? Isn't that exactly what you argued against in "Artificial Mysterious Intelligence"?
(It occurs to me that perhaps you're describing your understanding of how human beings do moral growth and not how you plan for an AI/simulated non-sentient being to do it. But if so, that understanding seems to be similar in usefulness to "human beings use neural networks to decide how to satisfy their desires.")
Eliezer wrote: I don't think I'm finished with this effort, but are you unsatisfied with any of the steps I've taken so far? Where?
The design space for "moral growth" is just as big as the design space for "optimization" and the size of the target you have to hit in order to have a good outcome is probably just as small. More than any dissatisfaction with the specific steps you've taken, I don't understand why you don't seem to (judging from your public writings) view the former problem to be as serious and difficult as the latter one, if not more so, because there is less previous research and existing insights that you can draw from. Where are the equivalents of Bayes, von Neumann-Morgenstern, and Pearl, for example?
Isn't CEV just a form of Artificial Mysterious Intelligence? Eliezer's conversation with the anonymous AIfolk seems to make perfect sense if we search and replace "neural network" with "CEV" and "intelligence" with "moral growth/value change".
How can the same person that objected to "Well, intelligence is much too difficult for us to understand, so we need to find some way to build AI without understanding how it works." by saying "Look, even if you could do that, you wouldn't be able to predict any kind of positive outcome from it. For all you knew, the AI would go out and slaughter orphans." be asking us to to place our trust in the mysterious moral growth of nonsentient but purportedly human-like simulations?
Eliezer, MacKay's math isn't very difficult. I think it will take you at most a couple of hours to go through how he derived his equations, understand what they mean, and verify that they are correct. (If I knew you were going to put this off for a year, I'd mentioned that during the original discussion.) After doing that, the idea that sexual reproduction speeds up evolution by gathering multiple bad mutations together to be disposed of at once will become pretty obvious in retrospect.
Jeff, I agree with what you are saying, but you're using the phrase "sexual selection" incorrectly, which might cause confusion to others. I think what you mean is "natural selection in a species with sexual reproduction". "Sexual selection" actually means "struggle between the individuals of one sex, generally the males, for the possession of the other sex".
Even if P=BPP, that just means that giving up randomness causes "only" a polynomial slowdown instead of an exponential one, and in practice we'll still need to use pseudorandom generators to simulate randomness.
It seems clear to me that noise (in the sense of randomized algorithms) does have power, but perhaps we need to develop better intuitions as to why that is the case.
To generalize Peter's example, a typical deterministic algorithm has low Kolmogorov complexity, and therefore its worst-case input also has low Kolmogorov complexity and therefore a non-negligible probability under complexity-based priors. The only possible solutions to this problem I can see are:
1. add randomization
2. redesign the deterministic algorithm so that it has no worst-case input
3. do a cost-benefit analysis to show that the cost of doing either 1 or 2 is not justified by the expected utility of avoiding the worst-case performance of the original algorithm, then continue to use the original deterministic algorithm
The main argument in favor of 1 is that its cost is typically very low, so why bother with 2 or 3? I think Eliezer's counterargument is that 1 only works if we assume that in addition to the input string, the algorithm has access to a truly random string with a uniform distribution, but in reality we only have access to one input, i.e., sensory input from the environment, and the so called random bits are just bits from the environment that seem to be random.
My counter-counterargument is to consider randomization as a form of division of labor. We use one very complex and sophisticated algorithm to put a lower bound on the Kolmogorov complexity of a source of randomness in the environment, then after that, this source of randomness can be used by many other simpler algorithms to let them cheaply and dramatically reduce the probability of hitting a worst-case input.
Or to put it another way, before randomization, the environment does not need to be a malicious superintelligence for our algorithms to hit worst-case inputs. After randomization, it does.
Rolf, I was implicitly assuming that even knowing BB(k), it still takes O(k) bits to learn BB(k+1). But if this assumption is incorrect, then I need to change the setup of my prediction game so that the input sequence consists of the unary encodings of BB(1), BB(2), BB(4), BB(8), â¦, instead. This shouldnât affect my overall point, I think.
After further thought, I need to retract my last comment. Consider P(next symbol is 0|H) again, and suppose you've seen 100 0's so far, so essentially you're trying to predict BB(101). The human mathematician knows that any non-zero number he writes down for this probability would be way too big, unless he resorts to non-constructive notation like 1/BB(101). If you force him to answer "over and over, what their probability of the next symbol being 0 is" and don't allow him to use notation like 1/BB(101) then he'd be forced to write down an inconsistent probability distribution. But in fact the distribution he has in mind is not computable, and that explains how he can beat Solomonoff Induction.
Good question, Eliezer. If the human mathematician is computable, why isn't it already incorporated into Solomonoff Induction? It seems to me that the human mathematician does not behave like a Bayesian. Let H be the hypothesis that the input sequence is the unary encodings of Busy Beaver numbers. The mathematician will try to estimate, as best as he can, P(next symbol is 0|H). But when the next symbol turns out to be 1, he doesn't do a Bayesian update and decrease P(H), but instead says "Ok, so I was wrong. The next Busy Beaver number is bigger than I expected."
I'm not sure I understand what you wrote after "to be fair". If you think a Solomonoff inductor can duplicate the above behavior with an alternative setup, can you elaborate how?
A halting oracle is usually said to output 1s or 0s, not proofs or halting times, right?
It's easy to use such an oracle to produce proofs and halting times. The following assumes that the oracle outputs 1 if the input TM halts, and 0 otherwise.
For proofs: Write a program p which on inputs x and i, enumerates all proofs. If it finds a proof for x, and the i-th bit of that proof is 1, then it halts, otherwise it loops forever. Now query the oracle with (p,x,0), (p,x,1), ..., and you get a proof for x if it has a proof.
Halting times: Write a program p which on inputs x and i, runs x for i steps. If x halts before i steps, then it halts, otherwise it loops forever. Now query the oracle with (p,x,2), (p,x,4), (p,x,8), ..., until you get an output of "1" and then use binary search to get the exact halting time.
I don't recall if I've mentioned this before, but Solomonoff induction in the mixture form makes no mention of the truth of its models. It just says that any computable probability distribution is in the mixture somewhere, so you can do as well as any computable form of cognitive uncertainty up to a constant.
Eliezer, if what you say is true, then it shouldn't be possible for anyone, using just a Turing machine, to beat Solomonoff Induction at a pure prediction game (by more than a constant), even if the input sequence is uncomputable. But here is a counterexample. Suppose the input sequence consists of the unary encodings of Busy Beaver numbers BB(1), BB(2), BB(3), …, that is, BB(1) number of 1s followed by a zero, then BB(2) number of 1s followed by a 0, and so on. Let’s ask the predictor, after seeing n input symbols, what is the probability that it will eventually see a 0 again, and call this p(n). With Solomonoff Induction, p(n) will approach arbitrarily close to 0 as you increase n. A human mathematician on the other hand will recognize that the input sequence may not be computable and won’t let p(n) fall below some non-zero bound.
Nick wrote: Good point, but when the box says "doesn't halt", how do I know it's correct?
A halting-problem oracle can be used for all kinds of things besides just checking whether an individual Turing machine will halt or not. For example you can use it to answer various mathematical questions and produce proofs of the answers, and then verify the proofs yourself. You should be able to obtain enough proofs to convince yourself that the black box is not just giving random answers or just being slightly smarter than you are.
If P!=NP, you should be able to convince yourself that the black box has at least exponentially more computational power than you do. So if you are an AI with say the computational resources of a solar system, you should be able to verify that the black box either contains exotic physics or has access to more resources than the rest of the universe put together.
Eliezer wrote: So once again I say: it is really hard to improve your math abilities with eyes open in a way that you couldn't theoretically do with eyes closed.
It seems to me that an AI should/can never completely rule out the possibility that the universe contains physics that is mathematically more powerful than what it has already incorporated into itself, so it should always keep its eyes open. Even if it has absorbed the entire universe into itself, it might still be living inside a simulation, right?
In fact, it's just bloody hard to fundamentally increase your ability to solve math problems in a way that "no closed system can do" just by opening the system. So far as I can tell, it basically requires that the environment be magic and that you be born with faith in this fact.
Eliezer, you're making an important error here. I don’t think it affects the main argument you're making in this article (that considerations of "complexity" doesn't rule out self-improving minds), but this error may have grave consequences elsewhere. The error is that while the environment does have to be magic, you don't need to have faith in this, just not have faith that it's impossible.
Suppose you get a hold of a black box that seems to act as a halting-problem oracle. You’ve thrown thousands of problems at it, and have never seen in incorrect or inconsistent answer. What are the possibilities here? Either (A) the environment really is magic (i.e. there is uncomputable physics that enables implementation of actual halting-problem oracles), or (B) the box is just giving random answers that happen to be correct by chance, or (C) you’re part of a simulation where the box is giving all possible combinations of answers and you happen to be in the part of the simulation where the box is giving correct answers. As long as your prior probability for (A) is not zero, as you do more and more tests and keep getting correct answers, it’s posterior probability will eventually dominate (B) and (C).
Why is this so important? Well in standard Solomonoff Induction, the prior for (A) is zero, and if we program that into an AI, it won’t do the right thing in this situation. This may have a large effect on expected utility (of us, people living today), because while the likelihood of us living in an uncomputable universe with halting-problem oracles is low, the utility we gain from correctly recognizing and exploiting such a universe could be huge.
Some problems are hard to solve, and hard even to define clearly. It's possible that "qualia" is not referring to anything meaningful, but unless you are able to explain why it feels meaningful to someone, but isn't really, I don't think you should demand that they stop using it.
Having said that, here's my attempt at an operational definition of qualia.
Eliezer, suppose the nature of the catastrophe is such that everyone on the planet dies instantaneously and painlessly. Why should such deaths bother you, given that identical people are still living in adjacent branches? If avoiding death is simply a terminal value for you, then I don't see why encouraging births shouldn't be a similar terminal value.
I agree that the worlds in which we survive may not be pleasant, but average utilitarianism implies that we should try to minimize such unpleasant worlds that survive, rather than the existential risk per se, which is still strongly counterintuitive.
I don't know what you are referring to by "hard to make numbers add up on anthropics without Death events". If you wrote about that somewhere else, I've missed it.
A separate practical problem I see with the combination of MWI and consequentialism is that due to branching, the measure of worlds a person is responsible for is always rapidly and continuously decreasing, so that for example I'm now responsible for a much smaller portion of the multiverse than I was just yesterday or even a few seconds ago. In theory this doesnât matter because the costs and benefits of every choice I face are reduced by the same factor, so the relative rankings are preserved. But in practice this seems pretty demotivational, since the subjective mental cost of making an effort appears to stay the same, while the objective benefits of such effort decreases rapidly. Eliezer, I'm curious how you've dealt with this problem.
Put me down as a long time many-worlder who doesn't see how it makes average utilitarianism more attractive.
It seems to me that MWI poses challenges for both average utilitarianism and sum utilitarianism. For sum utilitarianism, why bother to bring more potential people into existence in this branch, if those people are living in many other branches already?
But I wonder if Eliezer has considered that MWI plus average utilitarianism seems to imply that we don't need to worry about certain types of existential risk. If some fraction of the future worlds that we're responsible for gets wiped out, that wouldn't lower the average utility, unless for some reason the fraction that gets wiped out would otherwise have had an average utility that's higher than the average of the surviving branches. Assuming that's not the case, the conclusion follows that we don't need to worry about these risks, which seems pretty counterintuitive.
Eliezer, what is your view of the relationship between Bayesian Networks and Solomonoff Induction? You've talked about both of these concepts on this blog, but I'm having trouble understanding how they fit together. A Google search for both of these terms together yields only one meaningful hit, which happens to be a mailing list post by you. But it doesn't really touch on my question.
On the face of it, both Bayesian Networks and Solomonoff Induction are "Bayesian", but they seem to be incompatible with each other. In the Bayesian Networks approach, conditional probabilities are primary, and the full probability distribution function is more of a mathematical formalism that stays in the background. Solomonoff Induction on the other hand starts with a fully specified (even if uncomputable) prior distribution and derives any conditional probabilities from it as needed. Do you have any idea how to reconcile these two approaches?
Toby, how do you get around the problem that the greatest sum of happiness across all lifes probably involves turning everyone into wireheads and putting them in vats? Or in an even more extreme scenario, turning the universe into computers that all do nothing but repeatedly runs a program that simulates a person in an ultimate state of happiness. Assuming that we have access to limited resources, these methods seem to maximize happiness for a given amount of resources.
I'm sure you agree that this is not something we do want. Do you think that it is something we should want, or that the greatest sum of happiness across all lifes can be achieved in some other way?
I agree with Eliezer here. Not all values can be reduced to desire for happiness. For some of us, the desire not to be wireheaded or drugged into happiness is at least as strong as the desire for happiness. This shouldn't be a surprise since there were and still are pyschoactive substances in our environment of evolutionary adaptation.
I think we also have a more general mechanism of aversion towards triviality, where any terminal value that becomes "too easy" loses its value (psychologically, not just over evolutionary time). I'm guessing this is probably because many of our terminal values (art, science, etc.) exist because they helped our ancestors attract mates by signaling genetic superiority. But you can't demonstrate genetic superiority by doing something easy.
Toby, I read your comment several times, but still can't figure out what distinction you are trying to draw between the two senses of value. Can you give an example or thought experiment, where valuing happiness in one sense would lead you to do one thing, and valuing it in the other sense would lead you to do something else?
Michael, do you have a more specific reference to something Parfit has written?
Eliezer, I just noticed that you've updated the main post again. The paper by Worden that you link to makes the mistake of assuming no crossing or even chromosomal assortment, as you can see from the following quotes. It's not surprising that sex doesn't help under those assumptions.
(being quote)
Next consider what happens to one of the haploid genotypes j in one generation. Through random mating, it gets paired with another haploid genotype k, with probability q; then the pair have a probability of surviving sigmajk.
...
(b) Crossing: Similarly, in a realistic model of crossing, we can show that it always decreases the diploid genotype information Jµ. This is not quite the same as proving that crossing always decreases Iµ, but is a powerful plausibility argument that it does so. In that case, crossing will not violate the limit.
(end quote)
As for not observing species gaining thousands of bits per generation, that might be due to the rarity of beneficial mutations. A dog not apparently having greater morphological or biochemical complexity than a dinosaur can also be explained in many other ways.
If you have the time, I think it would be useful to make another post on this topic, since most people who read the original article will probably not see the detailed discussions in the comments or even notice the Addendum. You really should cite MacKay. His paper does provide a theoretical explanation for what happens in the simulations, if you look at the equations and how they are derived.
Eliezer, MacKay actually does predict what we have observed in the simulations. Specifically equation 28 predicts it if you let δf=f instead of δf=f-1/2. You need to make that change to the equation because in your simulation with Beneficial=0, mutations only flips 1 bits to 0, whereas in MacKay's model mutations also flip 0 bits to 1 with equal probability.
I only ran 300 generations, but I just redid them with 5000 generations (which took a few hours), and the results aren't much different. See plots at http://www.weidai.com/fitness/plot3.png and http://www.weidai.com/fitness/plot4.png.
{kind=link}
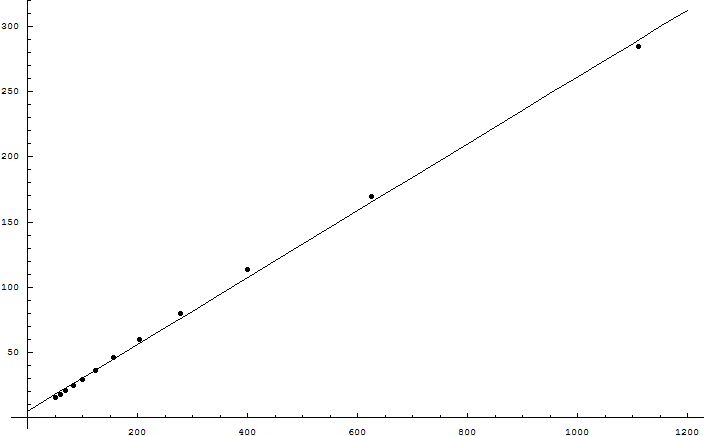{kind=link}
I also reran the simulations with Number=100. Fitness is lower at all values of Mutation (by about 1/3), but it's still linear in 1/Mutation^2, not 1/Mutation. The relationship between Fitness and Number is not clear to me at this point. As Eliezer said, the combinatorial argument I gave isn't really relevant.
Also, with Number=1000, Genome=1000, Mutate=0.005, Fitness stabilizes at around 947. So, extrapolating from this, when 1/Mutate^2 is much larger than Genome, which is the case for human beings, almost the entire genome can be maintained against mutations. It doesn't look like this line of inquiry gives us a reason to believe that most of human DNA is really junk.
Elizer, I've noticed an apparent paradox in information theory that may or may not be related to your "disconnect between variance going as the square root of a randomized genome, and the obvious argument that eliminating half the population is only going to get you 1 bit of mathematical information." It may be of interest in either case, so I'll state it here.
Suppose Alice is taking a test consisting of M true/false questions. She has no clue how to answer them, so it seems that the best she can do is guess randomly and get an expected score of M/2. Fortunately her friend Bob has broken into the teacher's office and stolen the answer key, but unfortunately he can't send her more than 1 bit of information before the test ends. What can they do, assuming they planned ahead of time?
The naive answer would be to have Bob send Alice the answer to one of the questions, which raises the expected score to 1+(M-1)/2.
A better solution is to have Bob tell Alice whether "true" answers outnumber "false" answers. If the answers are uniformly distributed, the variance of the number of "true" answers is M/4, which means Alice can get an expected score of M/2+sqrt(M)/2 if she answers all "true" or all "false" according to what Bob tells her. So here's the paradox: how did Alice get sqrt(M)/2 more answers correct when Bob only sent her 1 bit of information?
(What if the teacher knew this might happen and made the number of "true" answers exactly equal to the number of "false" answers? Alice and Bob should have established a common random bit string R of length M ahead of time. Then Bob can send Alice a bit indicating whether she should answer according to R or the complement of R, with the same expected outcome.)
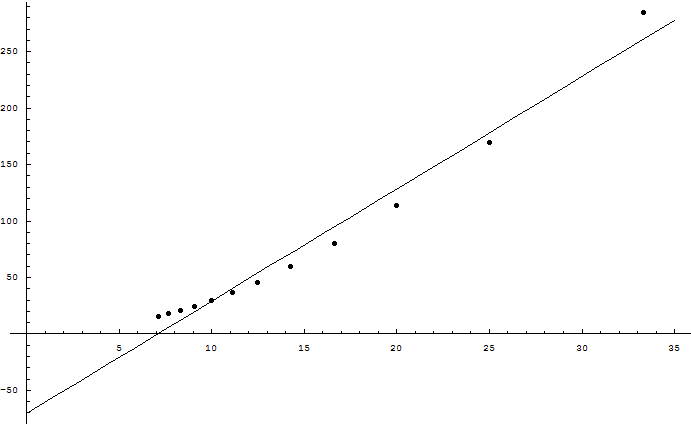
Eliezer, the simulation is a great idea. I've used it to test the following hypothesis: given sufficiently large population and genome size, the number of useful bits that a sexual species can maintain against a mutation probability (per base) of m is O(1/m^2). The competing hypothesis is the one given in your opening post, namely that it's O(1/m).
To do this, I set Number=1000, Genome=1000, Beneficial=0, and let Mutation range from 0.03 to 0.14 in steps of 0.01. Then I plotted Fitness (which in the program equals the number of useful bits in the genome) against both 1/Mutation and 1/Mutation^2. I think the results [1] are pretty clear: when 1/Mutation^2 is small compared to Number and Genome, Fitness is linear in 1/Mutation^2, not 1/Mutation.
Oh, I rewrote the simulation code in C++ to make it run faster. It's available at http://www.weidai.com/fitness/adhoc.cpp.
[1] http://www.weidai.com/fitness/fitness.htm, first plot is Fitness vs 1/Mutation, second is Fitness vs 1/Mutation^2.
Tom McCabe, having 100 chromosomes with no recombination lets you maintain the genome against a mutation pressure of 10 bits per generation, not 100. (See my earlier comment.) But that's still much better than 1 bit per generation, which is what you get with no sex.
Eliezer, you are mistaken that eliminating half of the population gives only 1 bit of mathematical information. If you have a population of N individuals, there are C(N,N/2) = N!/((N/2)!*(N/2)!) different ways to eliminate half of them. See http://en.wikipedia.org/wiki/Combination. Therefore it takes log_2(C(N,N/2)) (which is O(N)) bits to specify how to eliminate half of the population.
So, it appears that with sexual recombination, the maximum number of bits a species can gain per generation is min(O(G^0.5), O(N)).
Oh, sending 10 bits each with a 60% probability of being correct actually lets you send a total of just 0.29 bits of information. Each bit in this communications channel gives the receiver only 0.029 bits of information, using a formula from http://en.wikipedia.org/wiki/Binary_symmetric_channel. But, the amount of information actually received still grows linearly with the number of bits put into the channel.
I think MacKay's "If variation is created by recombination, the population can gain O(G^0.5) bits per generation." is correct. Here's my way of thinking about it. Suppose we take two random bit strings of length G, each with G/2-G^0.5 zeros and G/2+G^0.5 ones, randomly mix them twice, then throw away the result has fewer ones. What is the expected number of ones in the surviving mixed string? It's G/2+G^0.5+O(G^0.5).
Or here's another way to think about it. Parent A has 100 good (i.e., above average fitness) genes and 100 bad genes. Same with parent B. They reproduce sexually and have 4 children, two with 110 good genes and 90 bad genes, the other two (who do not survive to further reproduce) with 90 good genes and 110 bad genes. Now in one generation they've managed to eliminate 10 bad genes instead of just 1.
This seems to imply that the human genome may have much more than 25 MB of information.
I have argued in previous comments that the utility of a person should be discounted by his or her measure, which may be based on algorithmic complexity. If this "torture vs specks" dilemma is to have the same force under this assumption, we'd have to reword it a bit:
Would you prefer that the measure of people horribly tortured for fifty years increases by x/3^^^3, or that the measure of people who get dust specks in their eyes increases by x?
I argue that no one, not even a superintelligence, can actually face such a choice. Because x is at most 1, x/3^^^3 is at most 1/3^^^3. But how can you increase the measure of something by more than 0 but no more than 1/3^^^3? You might, perhaps, generate a random number between 0 and 3^^^3 and do something only if that random number is 0. But algorithmic information theory says that for any program (even a superintelligence), there are pseudorandom sequences that it cannot distinguish from truly random sequences, and the prior probability that your random number generator is generating such a pseudorandom sequence is much higher than 1/3^^^3. Therefore the probability of that "random" number being 0 (or being any other number that you can think of) is actually much larger than 1/3^^^3.
Therefore, if someone tells you "measure of ... increases by x/3^^^3", in your mind you've got to be thinking "... increases by y" for some y much larger than 1/3^^^3. I think my theories explains both those who answer SPECKS and those who say no answer is possible.
Regarding the comments about exploding brains, it's a wonder to me that we are able to think about these issues and not lose our sanity. How is it that a brain evolved for hunting/gathering/socializing is able to consider these problems at all? Not only that, but we seem to have some useful intuitions about these problems. Where on Earth did they come from?
Nick> Does your proposal require that one accepts the SIA?
Yes, but using a complexity-based measure as the anthropic probability measure implies that the SIA's effect is limited. For example, consider two universes, the first with 1 observer, and the second with 2. If all of the observers have the same complexity you'd assign a higher prior probability (i.e., 2/3) to being in the second universe. But if the second universe has an infinite number of observers, the sum of their measures can't exceed the measure of the universe as a whole, so the "presumptuous philosopher" problem is not too bad.
Nick> If I understand your suggestion correctly, you propose that the same anthropic probability measure should also be used as a measure of moral importance.
Yes, in fact I think there are good arguments for this. If you have an anthropic probability measure, you can argue that it should be used as the measure of moral importance, since everyone would prefer that was the case from behind the veil of ignorance. On the other hand, if you have a measure of moral importance, you can argue that for decisions not involving externalities, the global best case can be obtained if people use that measure as the anthropic probability measure and just consider their self interests.
BTW, when using both anthropic reasoning and moral discounting, it's easy to accidentally apply the same measure twice. For example, suppose the two universes both have 1 observer each, but the observer in the second universe has twice the measure of the one in the first universe. If you're asked to guess which universe you're in with some payoff if you guess right, you don't want to think "There's 2/3 probability that I'm in the second universe, and the payoff is twice as important if I guess 'second', so the expected utility of guessing 'second' is 4 times as much as the EU of guessing 'first'."
I think that to avoid this kind of confusion and other anthropic reasoning paradoxes (see http://groups.google.com/group/everything-list/browse_frm/thread/dd21cbec7063215b/), it's best to consider all decisions and choices from a multiversal objective-deterministic point of view. That is, when you make a decision between choices A and B, you should think "would I prefer if everyone in my position (i.e., having the same perceptions and memories as me) in the entire multiverse chose A or B?" and ignore the temptation to ask "which universe am I likely to be in?".
But that may not work unless you believe in a Tegmarkian multiverse. If you don't, you may have to use both anthropic reasoning and moral discounting, being very careful not to double-count.
Eliezer, what if the mugger (Matrix-claimant) also says that he is the only person who has that kind of power, and he knows there is just one copy of you in the whole universe? Is the probability of that being true less than 1/3^^^^3?
Eliezer, I think Robin's guess about mangled worlds is interesting, but irrelevant to this problem. I'd guess that for you, P(mangled worlds is correct) is much smaller than P(it's right that I care about people in proportion to the weight of the branches they are in). So Robin's idea can't explain why you think that is the right thing to do.
Nick, your paper doesn't seem to mention the possibility of discounting people by their algorithmic complexity. Is that an option you considered?