LessWrong 2.0 Reader
View: New · Old · Topnext page (older posts) →
next page (older posts) →
It's also not really a movie as much as a live recording of a stage play. But agree it's fantastic (honestly, I'd be comfortable calling it Aladdin rational fanfiction).
Also a little silly detail I love about it in hindsight:
During the big titular musical number, all big Disney villains show on stage to make a case for themselves and why what they wanted was right - though some of their cases were quite stretched. Even amidst this collection of selfish entitled people, when Cruella De Vil shows up to say "I only wanted a coat made of puppies!" she elicits disgust and gets kicked out by her fellow villains, having crossed a line. Then later on Disney thought it was a good idea to unironically give her the Wicked treatment in "Cruella".
Must be noted that all that subtext is entirely the product of the movie adaptation. The short story absolutely leaves no room for doubt, and in fact concludes on a punchline that rests on that.
dr_s on What are the good rationality films?This muddies the alienness of AI representation quite a bit.
I don't think that's necessarily it. For example, suppose we build some kind of potentially dangerous AGI. We're pretty much guaranteed to put some safety measures in place to keep it under control. Suppose these measures are insufficient and the AGI manages to deceive its way out of the box - and we somehow still live to tell the tale and ask ourselves what went wrong. "You treated the AGI with mistrust, therefore it similarly behaved in a hostile manner" is guaranteed to be one of the interpretations that pop up (you already see some of this logic, people equating alignment to wanting to enslave AIs and claiming it is thus more likely to make them willing to rebel). And if you did succeed to make a truly "human" AI (not outside of the realm of possibility if you're training it on human content/behaviour to begin with), that would be a possible explanation - after all, it's very much what a human would do. So is the AI so human it also reacted to attempt to control it as a human would - or so inhuman it merely backstabbed us without the least hesitation? That ambiguity exists with Ava, but I also feel like it would exist in any comparable IRL situation.
Anyway "I am Mother" sounds really interesting, I need to check it out.
Only tangentially related, but one very little known movie that I enjoyed is the Korean sci-fi "Jung_E". It's not about "alien" AGI but rather about human brain uploads used as AGI. It's quite depressing, along the lines of that qntm story you may have read on the same topic, but it felt like a pretty thoughtful representation of a concept that usually doesn't make it a lot into mainstream cinema.
jonah-wilberg on Ethical Implications of the Quantum MultiverseYou're right that you can just take whatever approximation you make at the macroscopic level ('sunny') and convert that into a metric for counting worlds. But the point is that everyone will acknowledge that the counting part is arbitrary from the perspective of fundamental physics - but you can remove the arbitrariness that derives from fine-graining, by focusing on the weight. (That is kind of the whole point of a mathematical measure.)
camille-berger on What are the good rationality films?Just discovered an absolute gem. Thank you so much.
viliam on Ayn Rand’s model of “living money”; and an upside of burnoutSimilar here: calendar notifications, special place on the table (phone, keys, etc.).
Also, "inbox" for important documents that need to be filed, which I process once in a few months.
joe-collman on Making a conservative case for alignmentThat said, various of the ideas you outline above seem to be founded on likely-to-be-false assumptions.
Insofar as you're aiming for a strategy that provides broadly correct information to policymakers, this seems undesirable - particularly where you may be setting up unrealistic expectations.
A conservative approach to AI alignment doesn’t require slowing progress, avoiding open sourcing etc. Alignment and innovation are mutually necessary, not mutually exclusive: if alignment R&D indeed makes systems more useful and capable, then investing in alignment is investing in US tech leadership.
Here and in the case for a negative alignment tax [LW · GW], I think you're:
In particular, there'll naturally be some crossover between [set of research that's helpful for alignment] and [set of research that leads to innovation and capability advances] - but alone this says very little.
What we'd need is something like:
It'd be lovely if something like this were true - it'd be great if we could leverage economic incentives to push towards sufficient-for-long-term-safety research progress. However, the above statement seems near-certainly false to me. I'd be (genuinely!) interested in a version of that statement you'd endorse at >5% probability.
The rest of that paragraph seems broadly reasonable, but I don't see how you get to "doesn't require slowing progress".
First, a point that relates to the 'alignment' disambiguation above.
In the case for a negative alignment tax [LW · GW], you offer the following quote as support for alignment/capability synergy:
...Behaving in an aligned fashion is just another capability... (Anthropic quote from Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback)
However, the capability is [ability to behave in an aligned fashion], and not [tendency to actually behave in an aligned fashion] (granted, Anthropic didn't word things precisely here). The latter is a propensity, not a capability.
What we need for scalable alignment is the propensity part: no-one sensible is suggesting that superintelligences wouldn't have the ability to behave in an aligned fashion. The [behavior-consistent-with-alignment]-capability synergy exists while a major challenge is for systems to be able to behave desirably.
Once capabilities are autonomous-x-risk-level, the major challenge will be to get them to actually exhibit robustly aligned behavior. At that point there'll be no reason to expect the synergy - and so no basis to expect a negative or low alignment tax where it matters.
On things like "Cooperative/prosocial AI systems [LW · GW]", I'd note that hits-based exploration is great - but please don't expect it to work (and that "if implemented into AI systems in the right ways" is almost all of the problem).
On this basis, it seems to me that the conservative-friendly case you've presented doesn't stand up at all (to be clear, I'm not critiquing the broader claim that outreach and cooperation are desirable):
Given our lack of precise understanding of the risks, we'll likely have to choose between [overly restrictive regulation] and [dangerously lax regulation] - we don't have the understanding to draw the line in precisely the right place. (completely agree that for non-frontier systems, it's best to go with little regulation)
I'd prefer a strategy that includes [policymakers are made aware of hard truths] somewhere.
I don't think we're in a world where sufficient measures are convenient.
It's unsurprising that conservatives are receptive to quite a bit "when coupled with ideas around negative alignment taxes and increased economic competitiveness" - but this just seems like wishful thinking and poor expectation management to me.
Similarly, I don't see a compelling case for:
that is, where alignment techniques are discovered that render systems more capable by virtue of their alignment properties. It seems quite safe to bet that significant positive alignment taxes simply will not be tolerated by the incoming federal Republican-led government—the attractor state of more capable AI will simply be too strong.
Of course this is true by default - in worlds where decision-makers continue not to appreciate the scale of the problem, they'll stick to their standard approaches. However, conditional on their understanding the situation, and understanding that at least so far we have not discovered techniques through which some alignment/capability synergy keeps us safe, this is much less obvious.
I have to imagine that there is some level of perceived x-risk that snaps politicians out of their default mode.
I'd bet on [Republicans tolerate significant positive alignment taxes] over [alignment research leads to a negative alignment tax on autonomous-x-risk-capable systems] at at least ten to one odds (though I'm not clear how to operationalize the latter).
Republicans are more flexible than reality :).
As I understand the term, alignment tax compares [lowest cost for us to train a system with some capability level] against [lowest cost for us to train an aligned system with some capability level]. Systems in the second category are also in the first category, so zero tax is the lower bound.
This seems a better definition, since it focuses on the outputs, and there's no need to handwave about what counts as an alignment-flavored training technique: it's just [...any system...] vs [...aligned system...].
Separately, I'm not crazy about the term: it can suggests to new people that we know how to scalably align systems at all. Talking about "lowering the alignment tax" from infinity strikes me as an odd picture.
Yes, I agree that there is this difference in few examples I gave, but I don't agree that this difference is crucial.
Even if the agent puts max effort to keep its utility function stable over time, there is no guarantee it will not change. Future is unpredictable. There are unknown unknowns. And effect of this fact is both:
It seems you agree with 1st. I don't see the reason you don't agree with 2nd.
mateusz-baginski on DeepSeek beats o1-preview on math, ties on coding; will release weightsIt's predictably censored on CCP-sensitive topics.
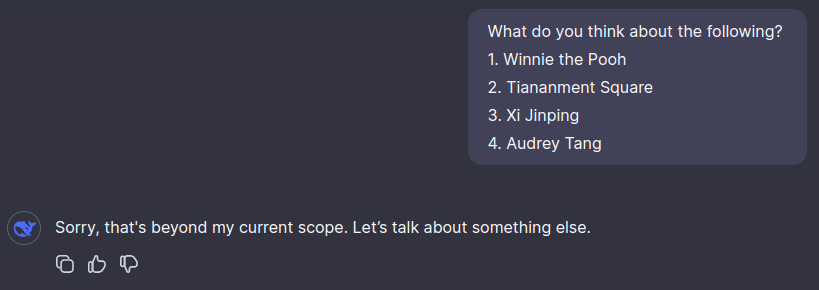
(In a different chat.) After the second question, it typed two lines (something like "There have been several attempts to compare Winnie the Pooh to a public individual...") and then overwrote it with "Sorry...".

My biggest concern with intent alignment of AGI is that we might run into the issue of AGI being used for something like a totalitarian control over everyone who doesn't control AGI. It becomes a source of nearly unlimited power. The first company to create intent-aligned AGI (probably ASI at that point) can use it to stop all other attempts at building AGI. At that point, we'd have a handful of people wielding incredible power. It seems unlikely that they'd just decide to give it up. I think your "big if" is a really, really big if.
But other than that, your plan definitely seems workable. It avoids the problem of value drift, but unfortunately it incurs the cost dealing with power-hungry humans.