An adversarial example for Direct Logit Attribution: memory management in gelu-4l
post by Can (Can Rager), Yeu-Tong Lau (yeu-tong-lau), James Dao (james-dao), Jett Janiak (jett) · 2023-08-30T17:36:59.034Z · LW · GW · 0 commentsThis is a link post for https://arxiv.org/abs/2310.07325
Contents
Overview Introduction Clean-up behavior Direct Logit Attribution Evidence for Clean-up Behavior Metrics and Terminology Identifying a writer node: output of head L0H2 is being consistently cleaned up Identifying cleaners: six layer 2 attention heads are cleaning up L0H2 Verifying causal relation: cleaning behavior depends on the writer output Implication for Direct Logit Attribution Adversarial examples of high DLA values without direct contribution Negative correlation between the DLA of writer and cleaners Conclusion Acknowledgements Author contributions None No comments
Please check out our notebook for figure recreation and to examine your own model for clean-up behavior.
Produced as part of ARENA 2.0 and the SERI ML Alignment Theory Scholars Program - Spring 2023 Cohort
Overview
In this post, we provide concrete evidence for memory management or clean-up in a 4-layer transformer gelu-4l. We show examples where Direct Logit Attribution (DLA) is misleading because it does not account for the clean-up.
In the Introduction, we define what we mean by clean-up behavior and provide a quick recap on DLA. In the section Evidence for Clean-up Behavior we identify specific nodes that write and remove information from the residual stream. Based on what we learned about the clean-up, we select prompts that result in misleading DLA results in the Implication for Direct Logit Attribution section.
Introduction
Clean-up behavior
Previously in A Mathematical Framework for Transformer Circuits the authors suggested a mechanism for memory management and speculated it can occur because of high demand on residual stream bandwidth. We define clean-up behavior, in which attention heads and MLPs (which we collectively call nodes) clear information from the residual stream that is only used in early layers of the network.
We characterize clean-up behavior as four steps during a forward pass:
- A writer node or embedding writes a specific direction to the residual stream
- Subsequent nodes use this direction for further computation
- A clean-up node clears this direction by writing its negative value to the residual stream
- The direction is used in the later part of the model, in one or two of the following ways:
- Subsequent nodes write to the direction, using this free subspace for communicating information different to the information which has been cleaned up
- The unembedding matrix reads the direction, which directly affects the output logits
Throughout this post, we analyze the removal of the writer node output (steps 1 - 3). In future work, we will address how the cleared space is used by later nodes after clean-up (step 4).
Direct Logit Attribution
Background: The final state of the residual stream is the sum of all outputs of nodes and embeddings in the model[1]. It is mapped to the logits by applying Layer Norm and Unembedding. The logit difference of two tokens is equivalent to the difference in log probabilities for both tokens and therefore directly interpretable in terms of predicting the next token.
Direct Logit Attribution (DLA) has been used to identify the direct contribution of individual nodes to the prediction of the correct next token[2]. This is done by applying unembedding directly to the output of any node, after accounting for Layer Norm. For example, a single node makes the prediction of token more likely than the prediction of token , if it increases the logit difference . However, DLA does not account for the fact that later nodes depend on the output of earlier nodes. Clean-up behavior is one possible reason why DLA may be misleading – especially for early nodes – as a node output may be consistently cleaned up by later nodes.
Evidence for Clean-up Behavior
Metrics and Terminology
We introduce Projection Ratio to compare the extent to which the direction in the residual stream has been overwritten.

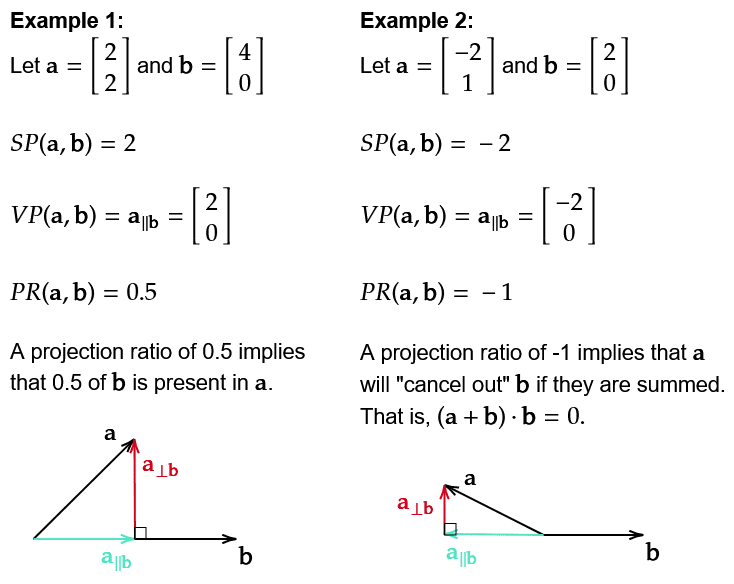
We use the notation “L0H2” to denote the attention head that resides in layer 0 with head index 2. All heads in layer 2 are collectively denoted by “L2HX”. In this section, we will always have the output of the writer head L0H2 as vector b, while vector a will be replaced either by residual stream or by the output of the clean-up heads.
Identifying a writer node: output of head L0H2 is being consistently cleaned up
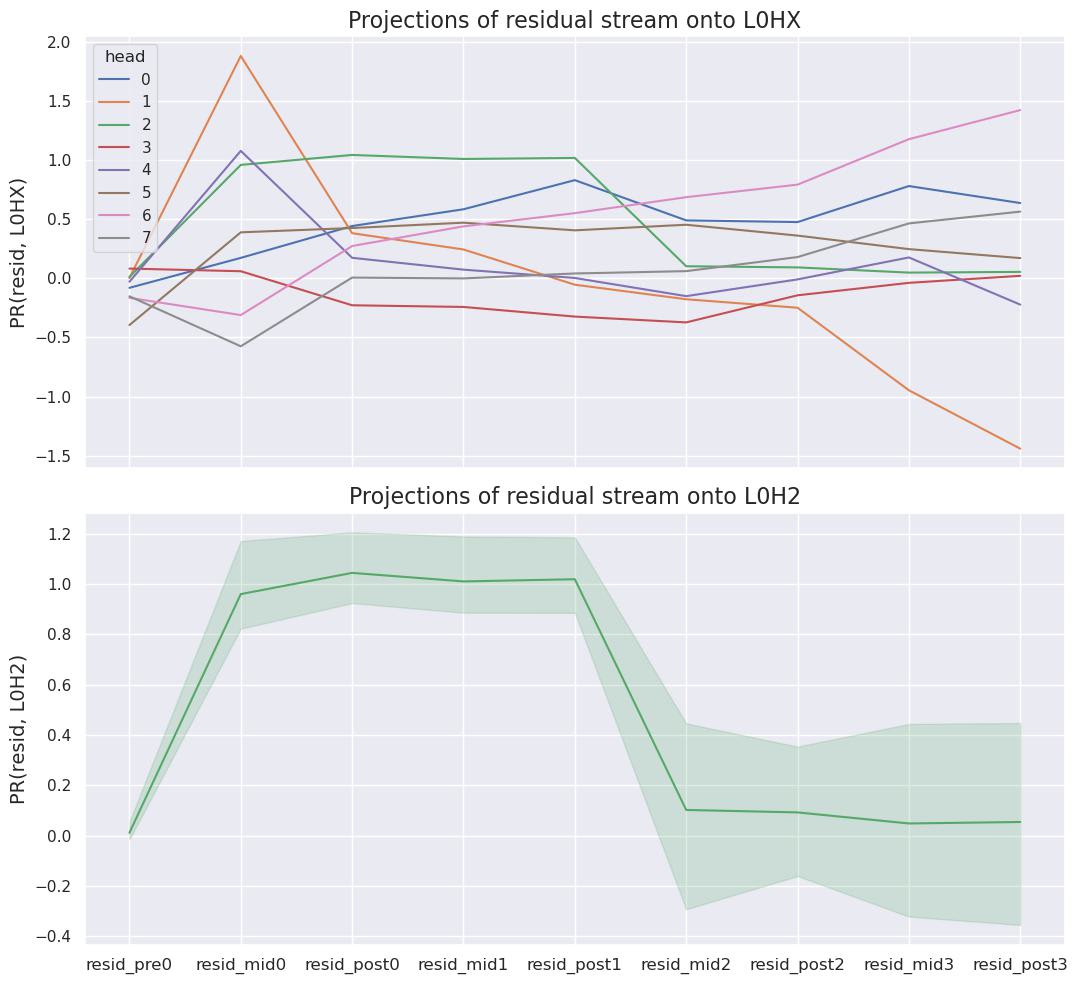
First, we scanned the full gelu-4l model for consistent clean-up behavior. For each node, we checked whether the output of a node is present in later states of the residual stream. We measure clean-up by projecting the residual stream before and after each attention and MLP layer onto the output direction of L0H2. An intuitive understanding: When projecting the state of the residual stream after layer 2 onto L0H2, the projection ratio represents how much of L0H2’s output is still present in the residual stream after layer 2. If the projection ratio is zero, the residual stream is orthogonal to the output of L0H2. In other words, the output direction of L0H2 is not present in the residual stream. It may have been moved to another subspace or totally cleared from the residual stream.
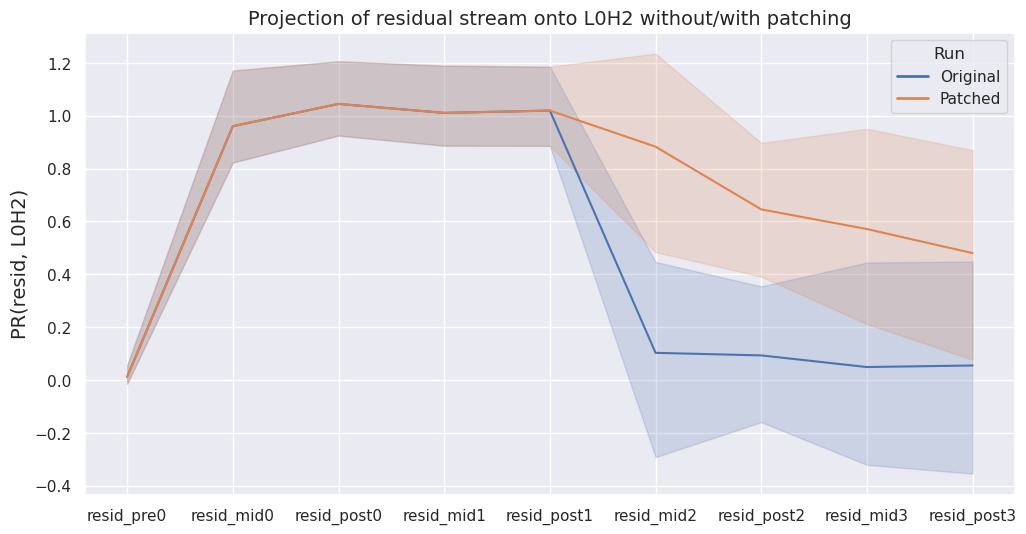
The projection of the residual stream onto L0H2 is shown in Fig 1 (bottom). We identified the output of L0H2 is consistently being cleaned up across 300 forward passes. We can track the presence of L0H2’s information in the residual stream as it moves through the transformer model:
- Initially we see a projection ratio of ~0 at resid_pre0, as L0H2 (which resides between resid_pre0 and resid_mid0) has not written to the residual stream yet
- After L0H2 writes to the residual stream (at resid_mid0), the projection ratio goes to ~1. It is not exactly 1 since the output of other heads in layer 0 might not be fully orthogonal to the output of L0H2
- After resid_mid0, a projection ratio of ~1 suggests that L0H2’s information is present in the residual stream until resid_post1 (inclusive)
- Attention heads in layer 2 (which resides between resid_post1 and resid_mid2) appear to remove the information the L0H2 originally wrote, resulting in a much smaller projection ratio of ~0. This happens consistently across 300 prompts (randomly sampled from the model’s training dataset), but there is some variance across different sequence positions.
The function of L0H2 is not totally clear, but it resembles positional information head[3][4].
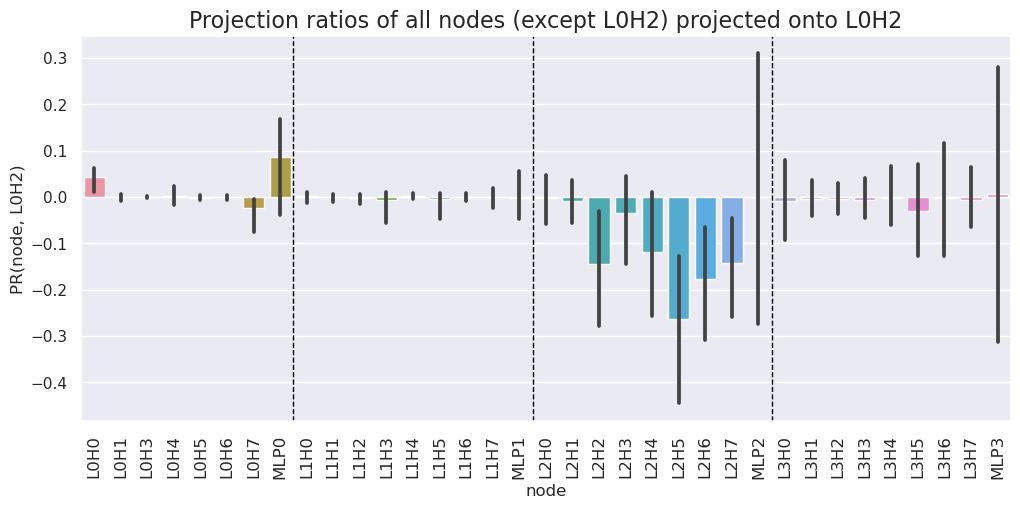
Identifying cleaners: six layer 2 attention heads are cleaning up L0H2
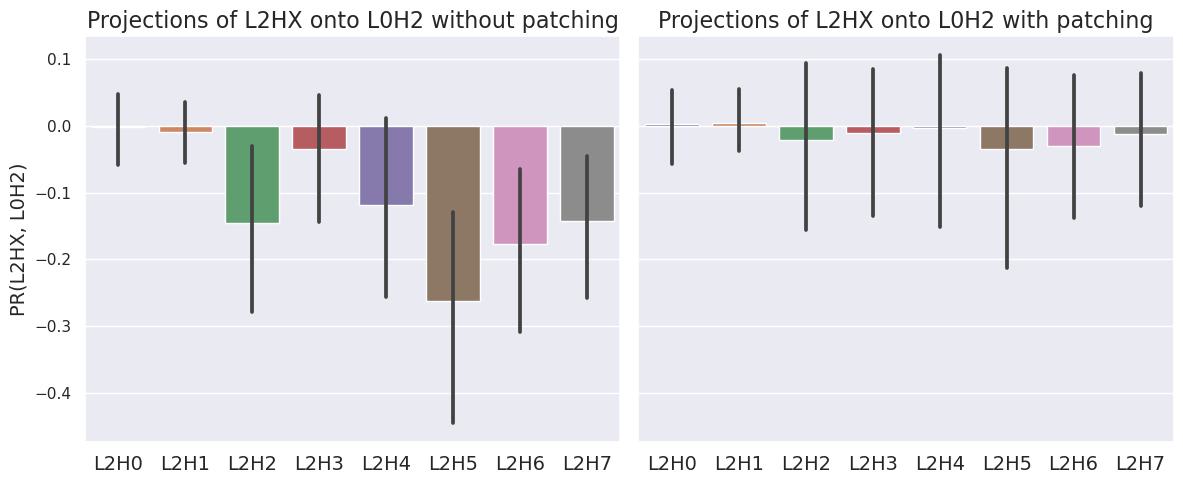
We find that six attention heads (L2H2, L2H3, L2H4, L2H5, L2H6, L2H7) are cleaning up the output of L0H2. In Fig 2 below, we see the aforementioned attention heads have a consistently negative projection ratio, implying they are writing to the residual stream in the opposite direction of L0H2. We believe that most of the variance as seen by the error bars is due to clean-up behavior being sensitive with respect to position rather than sensitivity with respect to prompt.
Verifying causal relation: cleaning behavior depends on the writer output
We verify the causal relation between clean-up heads and writer heads by patching the residual stream as an input to the OV circuits of layer 2 attention heads. The OV-circuit is responsible for what directions are written to the residual stream by attention heads[1]. By patching the OV circuit, we check what information heads L2HX write to the residual stream without the presence of L0H2.
We repeat experiments from sections Identifying a writer node (Fig 1) and Identifying cleaners (Fig 2) and compare results between the clean and a patched run. In the patched run, we alter the Value input (hook_v_input) of every head in layer 2 by subtracting the output of L0H2. This is equivalent to zero ablating L0H2 for only the OV circuits of the attention heads in layer 2. Every other component in the transformer will still “see” L0H2’s original output.
Fig 3a shows that the projection ratio of residual stream onto L0H2 remains high after the attention block in layer 2 in the patched run, indicating a significant fraction of the clean-up is indeed input-dependent. Fig 3b compares patched runs to clean runs for each individual head. The clean-up behavior mostly disappears when the cleaner head does not “see” the output of L0H2.
Implication for Direct Logit Attribution
As mentioned in the introduction, the DLA method applies final layer norm and unembedding directly to the node output. The DLA values will be high, if the node output happens to be aligned with the unembedding direction of certain tokens.
In the gelu-4l model however, the output of L0H2 is largely removed from the residual stream after the attention block in layer 2 as we’ve seen in Fig 1. In subsection Adversarial examples of high DLA values without direct contribution below, we present four examples where significant DLA values for L0H2 could be easily misinterpreted as a significant direct contribution to the final logits.
Furthermore, since reading and writing to residual stream are linear operations, applying DLA to clean-up heads will yield significant values as well, but with a flipped sign. We show these results in subsection Negative correlation between the DLA of writer and cleaners.
Adversarial examples of high DLA values without direct contribution
We adversarially selected four tokens bottom, State, __, and Church and constructed four prompts such that the model predicts one of the tokens with highest probability.
- prompt:
It's in the cupboard, either on the top or on the
top predictions:bottom,top(logit difference 1.07) - prompt:
I went to university at Michigan
top predictions:State,University(logit difference 1.89) - prompt:
class MyClass:\n\tdef
top predictions:__,get(logit difference 3.02) - prompt:
The church I go to is the Seventh-day Adventist
top predictions:Church,church(logit difference 0.94)
In our opinion, it is extremely unlikely that a node can directly[5] improve the model predictions in prompts 1-4 without considering token information[6]. However, patching the input to L0H2 with unrelated text doesn't affect the DLA values (see Fig 4a). We therefore conclude that L0H2 is not contributing directly to the model predictions in prompts 1-4, despite significant DLA values.
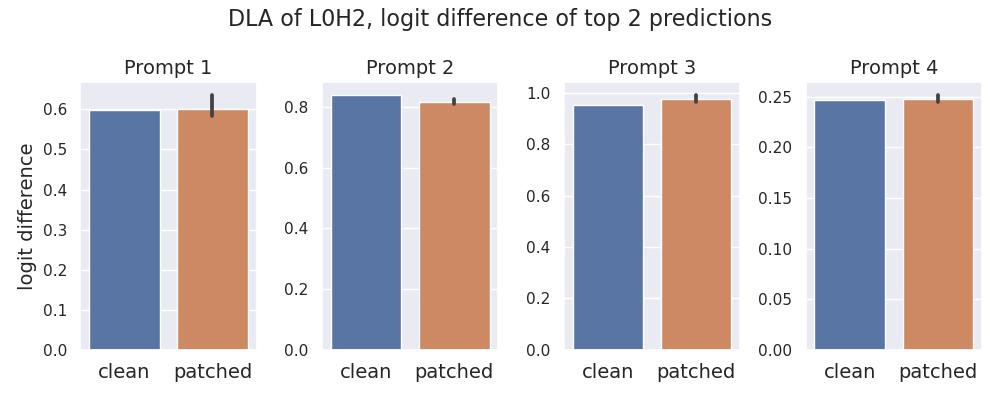
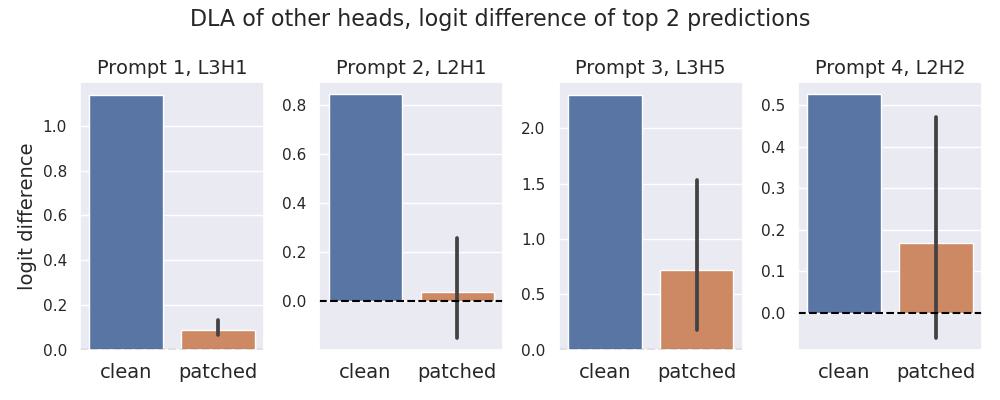
The invariance of L0H2’s DLA to input tokens is unusual. We reran the patching experiment for four other attention heads that exhibit the highest DLA values for the respective prompt in Fig 4b. In contrast to L0H2, the values for these heads are severely affected by the patch.
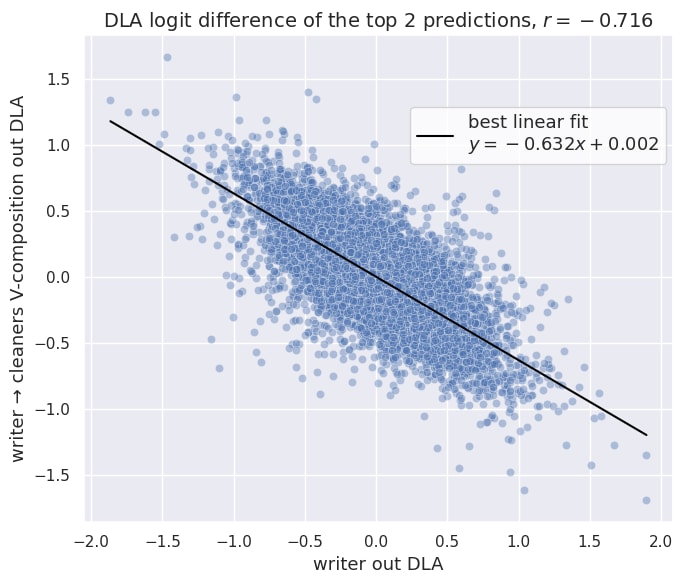
Negative correlation between the DLA of writer and cleaners
Finally, we examine the DLA values of the clean-up heads and how they are related to the DLA of the writer head. Instead of using prompts 1-4, we collect 30 samples from the model's training dataset and determine the logit difference between top 2 predictions at every position, which gives roughly 30,000 data points. We consider the clean-up heads in aggregate, by summing the DLA values of each individual head.
This experiment yields low, but non-negligible negative correlation coefficient of r=-0.159. One possible explanation for the small magnitude of r is that the cleaners perform many tasks unrelated to clean-up. The unrelated tasks may have an effect on the cleaner’s DLA values which can't be explained by the writer's DLA.
To extract a part of the cleaners DLA that is related to the clean-up, we consider only part of the cleaners output that comes from V-composition with the writer head. Specifically, for a given clean-up head , we compute
where is the writer head's output at position (after layer 2 Layer Norm) and is the cleaner's attention weight at position . Intuitively, this V-composition output tells us how the directions written by the cleaners depend on the output of the writer. Its DLA values show how much the clean-up heads overwrite the DLA of the writer head.
As we can see in Fig 5 (top of the page), it shows strong negative correlation () with the writer's DLA. In other words, writer's contribution to final logits is mostly[7] canceled by the clean-up heads.
Conclusion
In this post, we presented a concrete example of memory management in transformers. Furthermore, we constructed adversarial examples for the DLA method that relies on directions being preserved in residual stream through the forward pass. We propose three directions for future work: First, we’re interested in how the cleaned-up space is used by later nodes during a forward pass. Secondly, we want to further examine the role of head L0H2 in the gelu-4l model. Finally, we will look for clean-up behavior in other models. Previous research suggests that especially early heads and late heads exhibit high DLA values[4][8]. We want to verify whether high DLA values of early heads were misinterpreted in these works.
Acknowledgements
Our research benefited from discussions, feedback, and support from many people, including Chris Mathwin, Neel Nanda, Jacek Karwowski, Callum McDougall, Joseph Bloom, Alan Cooney, Arthur Conmy, Matthias Dellago, Eric Purdy and Stefan Heimersheim. We would also like to thank the ARENA and SERI MATS programs for facilitating the collaborations that started the project.
Author contributions
All of the authors contributed equally to this post. Jett proposed and led the project, while James, Can, and Yeu-Tong ran most of the experiments.
- ^
Elhage, et al., "A Mathematical Framework for Transformer Circuits", Transformer Circuits Thread, 2021, https://transformer-circuits.pub/2021/framework/index.html.
- ^
Liberum et al., “Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla.” arxiv, 2023, https://arxiv.org/abs/2307.09458v2.
McGrath et al., “The Hydra Effect: Emergent Self-repair in Language Model Computations.” arxiv, 2023, https://arxiv.org/abs/2307.15771.
Belrose et al., “Eliciting Latent Predictions from Transformers with the Tuned Lens.” arxiv, 2023, https://arxiv.org/abs/2303.08112.
Dar et al., “Analyzing Transformers in Embedding Space.” arxiv, 2022, https://arxiv.org/abs/2209.02535.
- ^
Nanda, “Real-Time Research Recording: Can a Transformer Re-Derive Positional Info?”. Youtube, 2022, https://www.youtube.com/watch?v=yo4QvDn-vsU&list=PL7m7hLIqA0hr4dVOgjNwP2zjQGVHKeB7T.
- ^
Heimersheim et al., “A circuit for Python docstrings.” Lesswrong, 2023, https://www.lesswrong.com/posts/u6KXXmKFbXfWzoAXn/a-circuit-for-python-docstrings-in-a-4-layer-attention-only#Positional_Information_Head_0_4 [LW · GW].
- ^
without composition, or by writing directly to the final logits
- ^
or based purely on positional information
- ^
a perfect clean-up behavior would yield r = -1 and a slope of -1
- ^
Wang et al., “Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small.” arxiv, 2022, https://arxiv.org/abs/2211.00593.
0 comments
Comments sorted by top scores.