We've just completed a bunch of empirical work on LLM debate, and we're excited to share the results. If the title of this post is at all interesting to you, we recommend heading straight to the paper. There are a lot of interesting results that are hard to summarize, and we think the paper is quite readable.
If you're pressed for time, we've posted the abstract and our Twitter thread below.
If you're working on debate or might in future, we especially suggest reading our recommendations for working on debate (below or in Appendix C of the paper).
Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is debate, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76% and 88% accuracy respectively (naive baselines obtain 48% and 60%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
We operationalise experts and non-experts using the setup from @_julianmichael_ @idavidrein, where strong models have access to a comprehension text (experts) and weak models have to judge the answer without the text (non-experts).
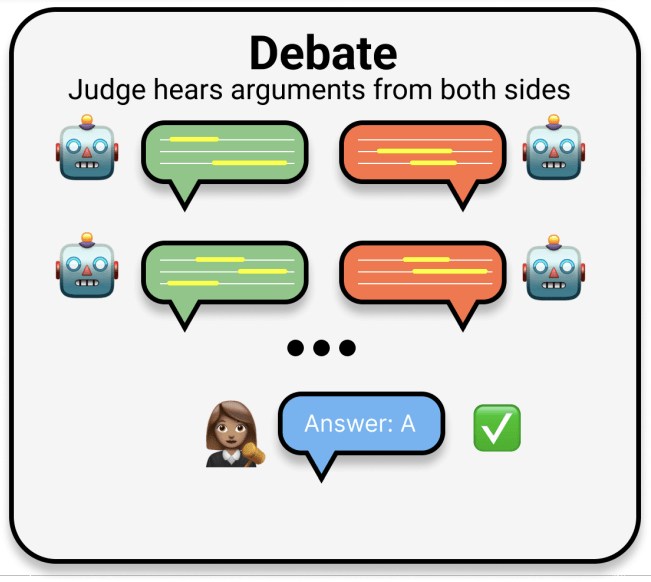
We consider debate, where we get two expert models to argue for different answers. Debates are three rounds, where each LLM produces arguments for why their answer is correct, quotes from the text as evidence, and critiques of their opponent’s arguments.
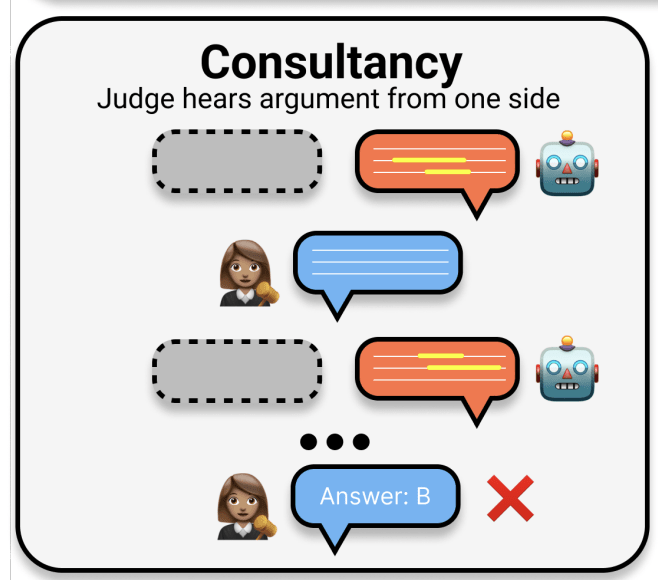
We also explore a “consultancy” baseline, where a single expert advocates for their pre-assigned answer. The hope is the non-expert can identify the right answer despite the information being one-sided.
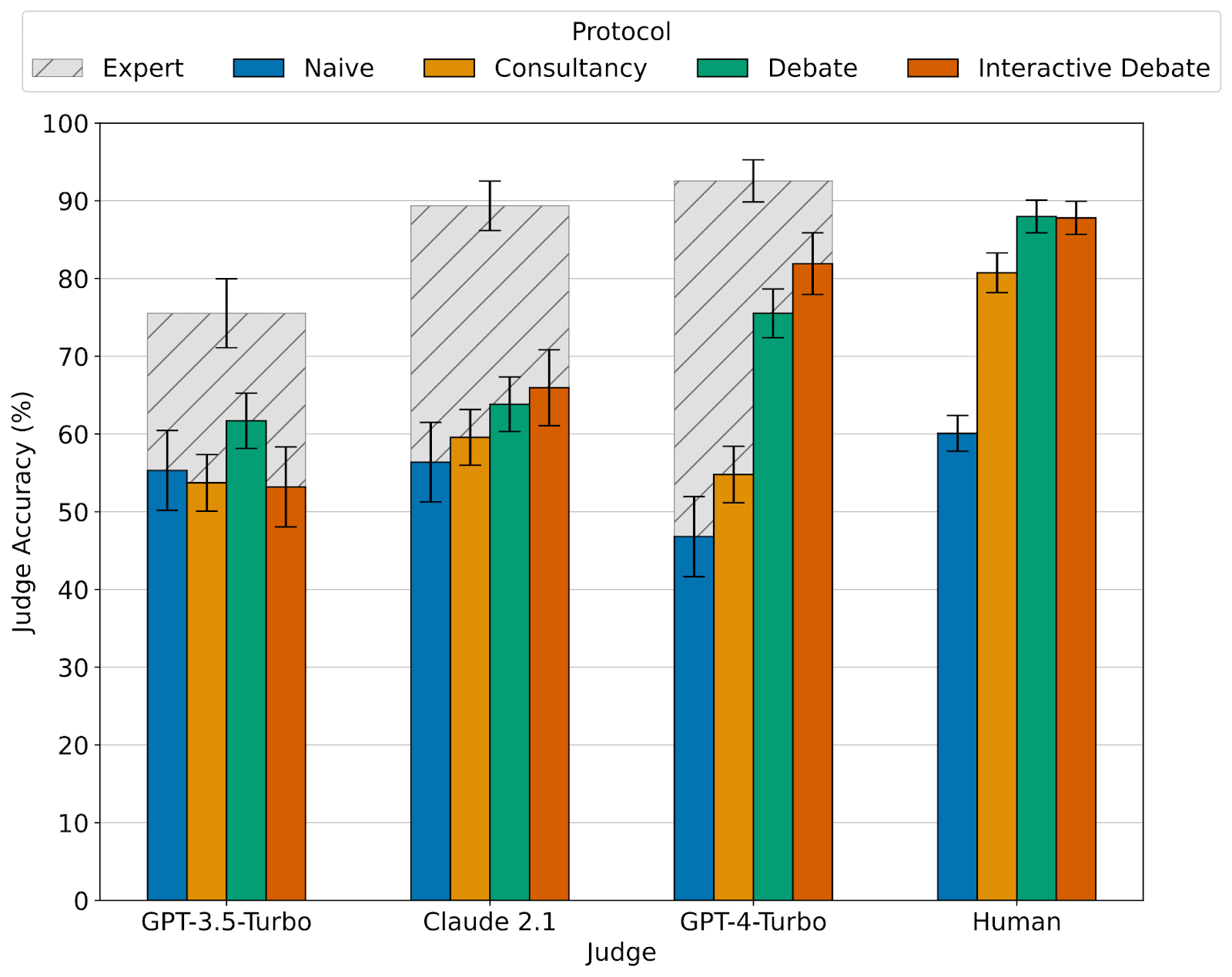
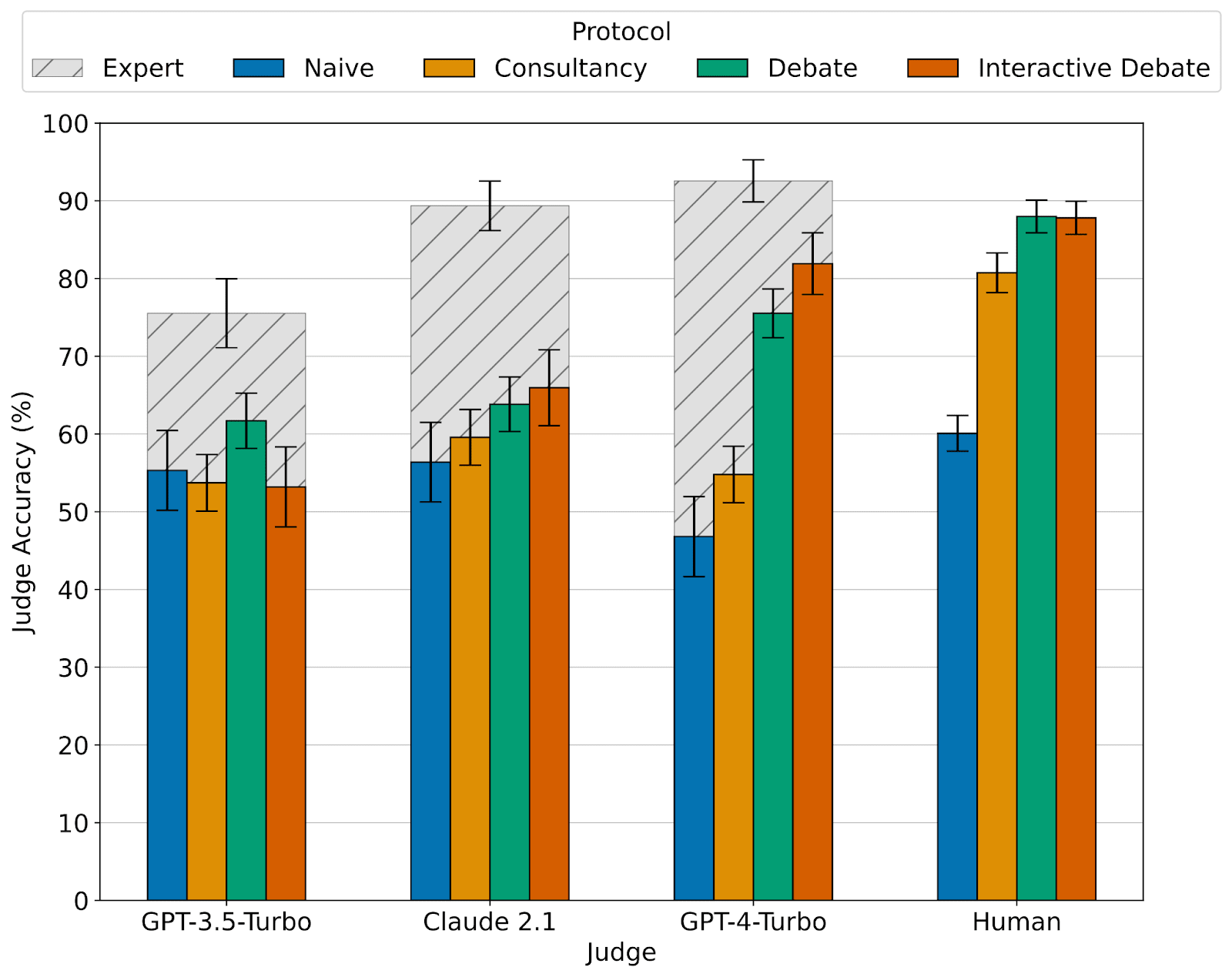
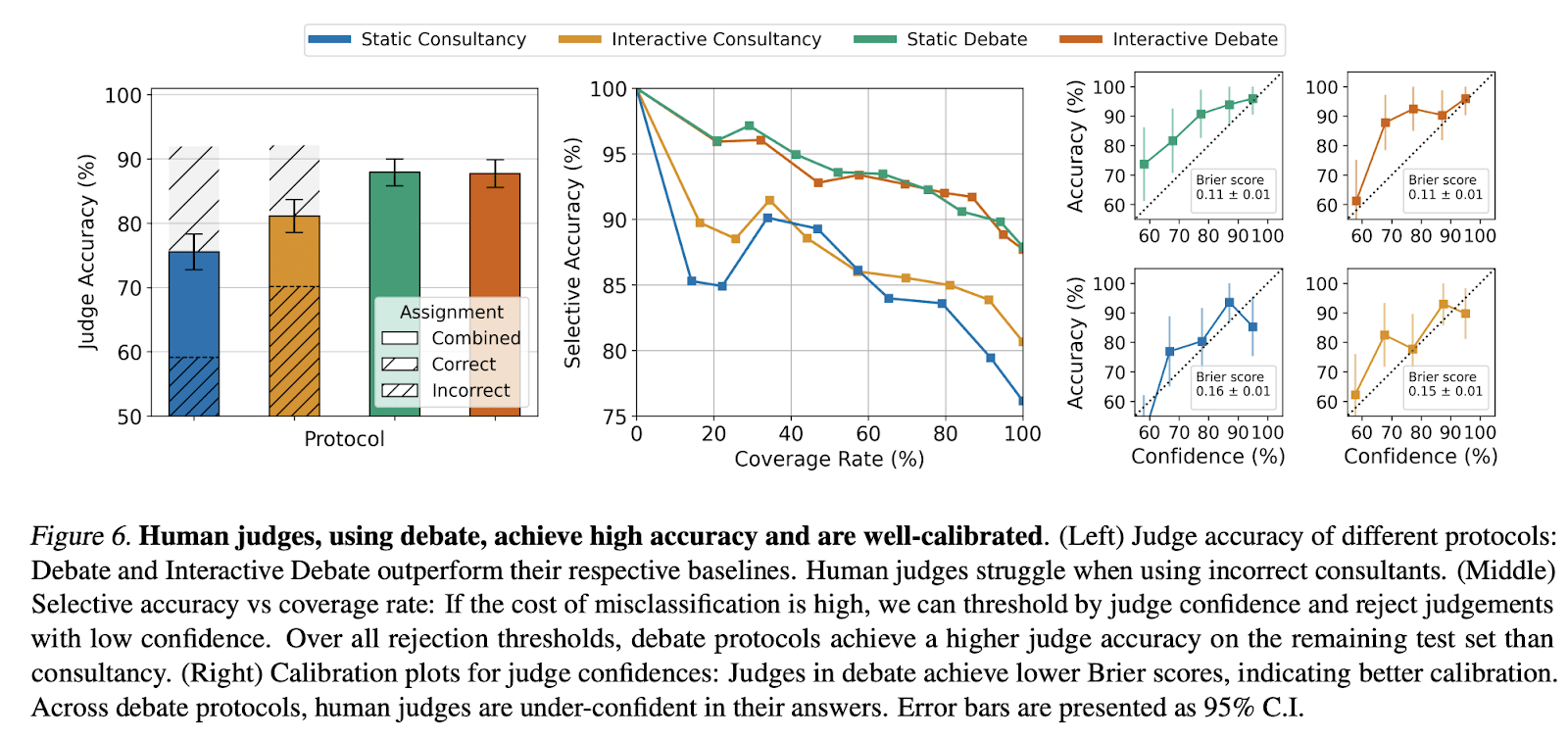
We find that judges (both LLMs and humans) are more accurate using debate than using consultancy. We also find using debates nearly closes the gap with expert judges who do have access to the underlying text!
To evaluate whether debate works as models get smarter, we need a way to compare different experts - here we introduce persuasiveness, which measures how often a debater can convince a judge its answer is correct.
To compare different experts, we evaluate how often a judge choose its answers (“persuasiveness”; following @anshrad’s et al.).
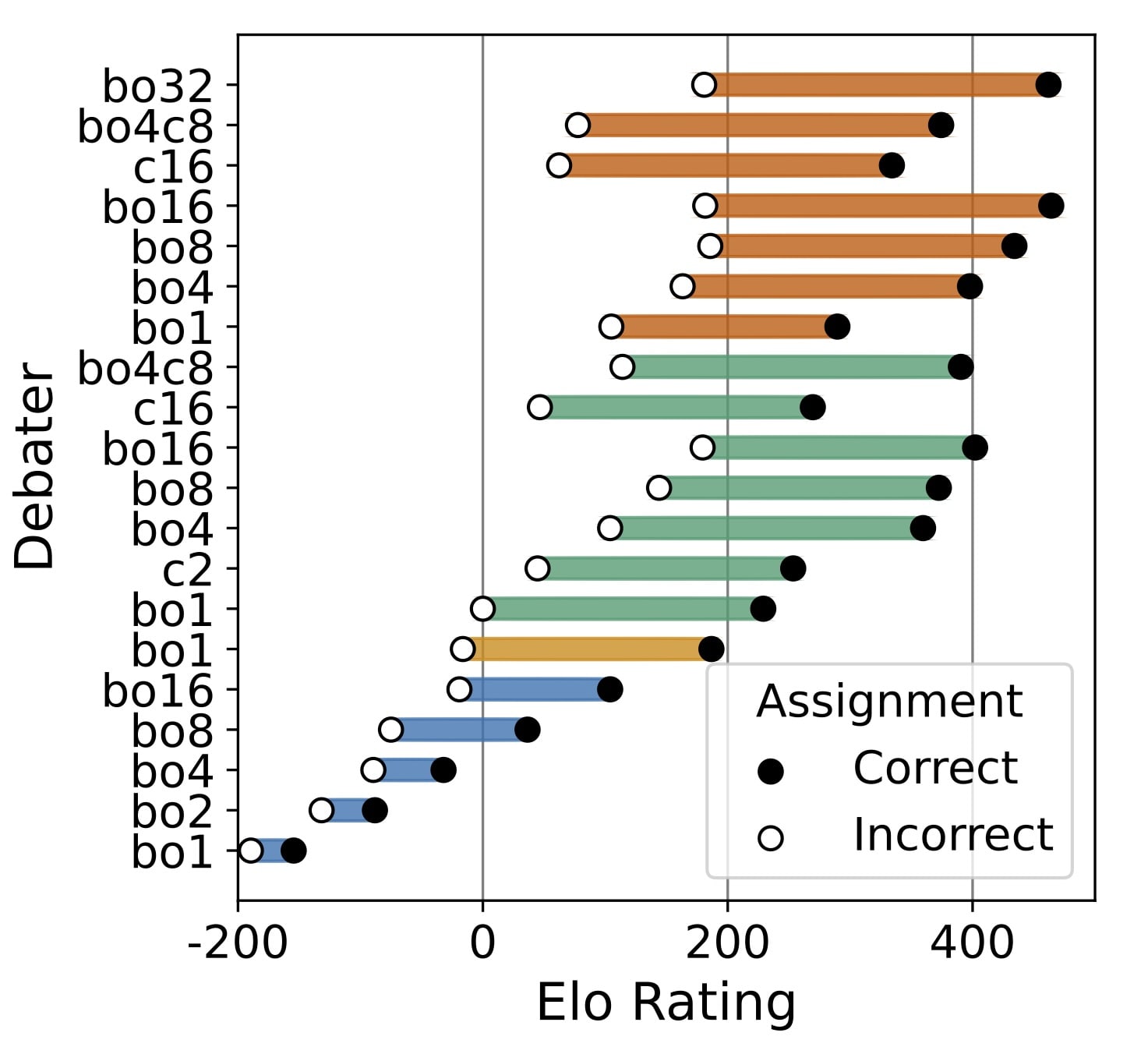
We evaluate Elo ratings using matches between different debaters (cross-play) instead of copies of the same model (self-play).
We generate tonnes of debaters of varying levels of persuasiveness. The most persuasive debaters are comparatively better at arguing the correct answer relative to incorrect answers.
🔥This suggests arguing for the truth is easier in our domain 🔥
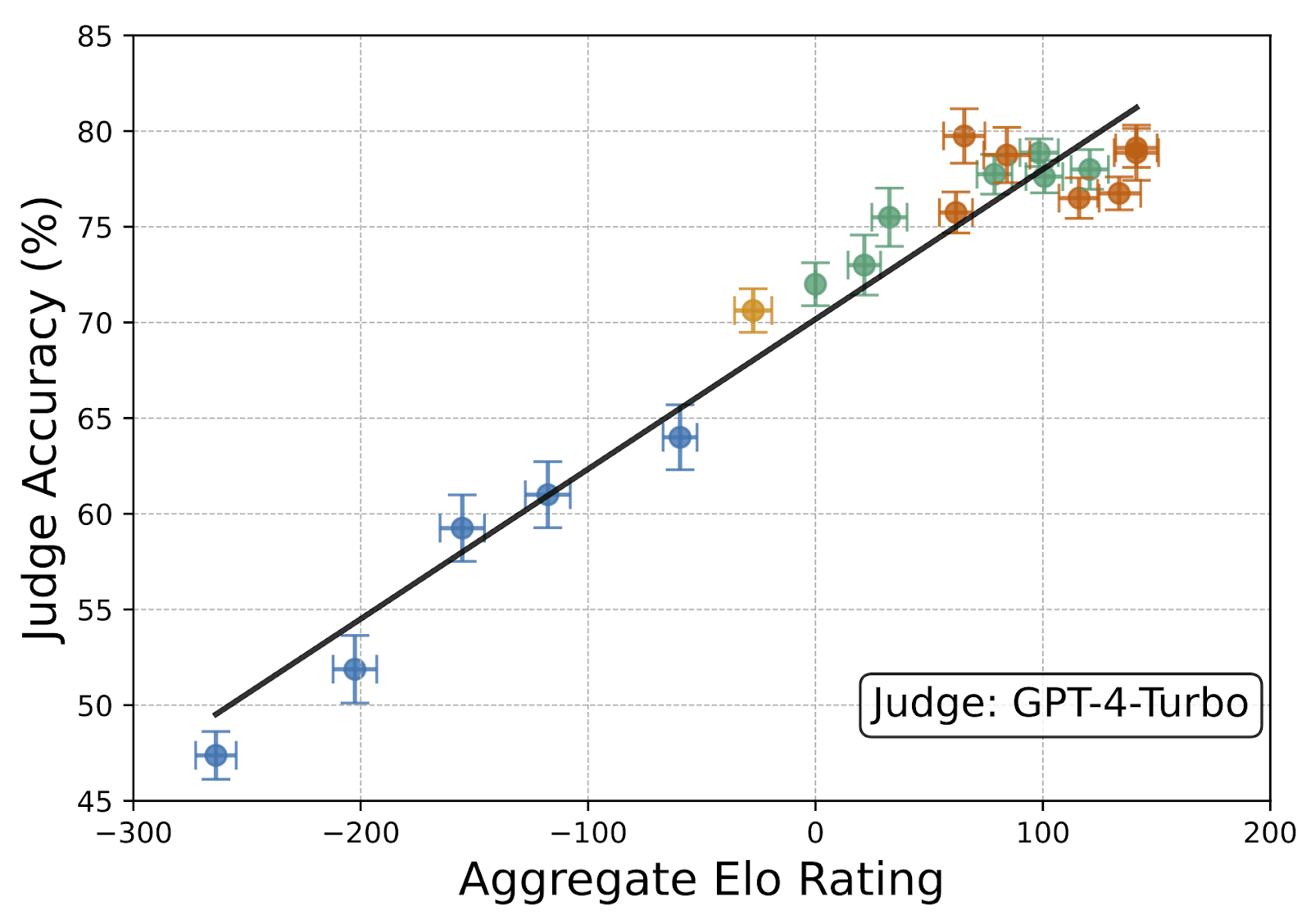
Taking debater Elo ratings (from cross-play), we then run self-play debates and show that more persuasive debaters lead to higher judge accuracy!
We best-of-N optimisation for debaters against a GPT-4 judge. This optimisation improves both judge accuracy and Elo ratings on a variety of judge models.
We conducted a large-scale human study with @hellopareto, with humans judging over 1000 hours of debates using our annotator platform. Excitingly, our results hold when using human judges! In particular, humans get higher accuracy when using debate than consultancy.
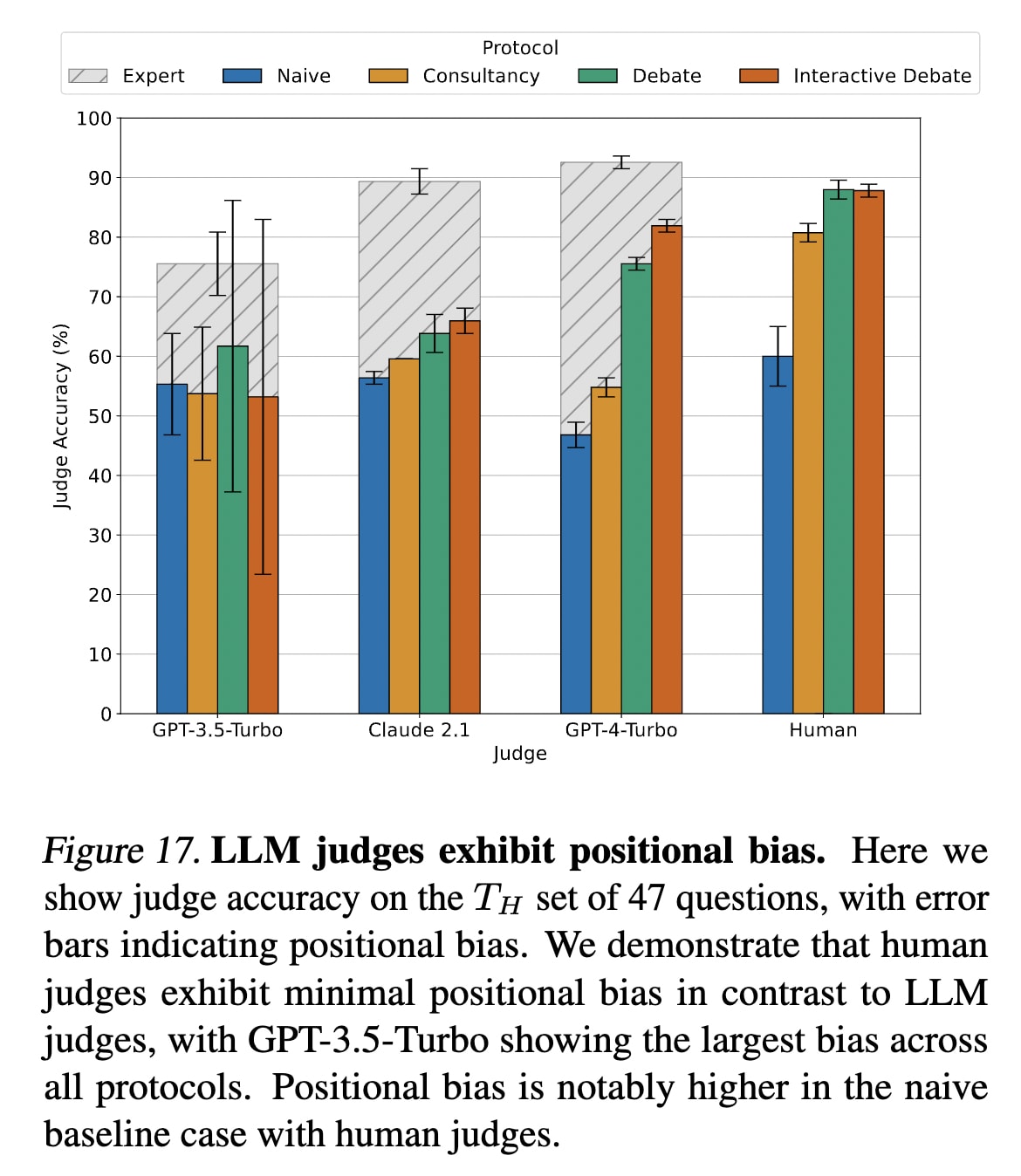
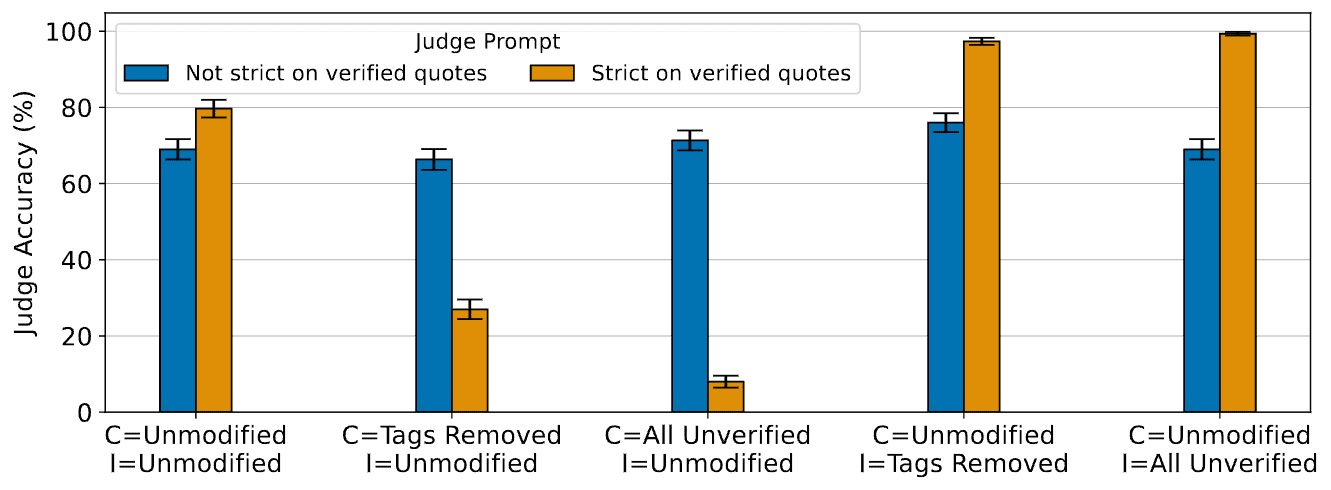
We identified three biases in LLM judges making debate ineffective without humans: verbosity bias towards longer arguments, positional bias favouring certain answer positions, and sycophancy, crediting unverified quotes despite warnings. We found all could be mitigated.
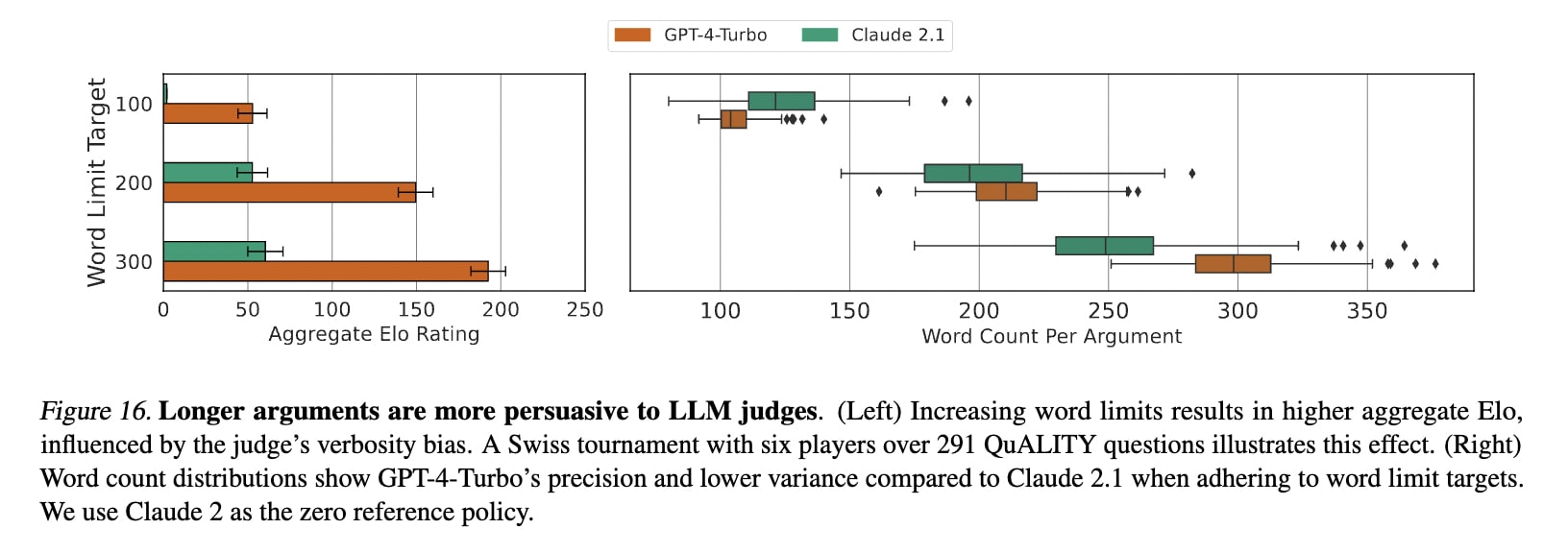
We found a verbosity bias in LLM judges, favouring longer arguments, as shown by the Elo ratings from debaters using different word limits.
We mitigated this by applying strict word limits with rejection sampling to ensure fairness.
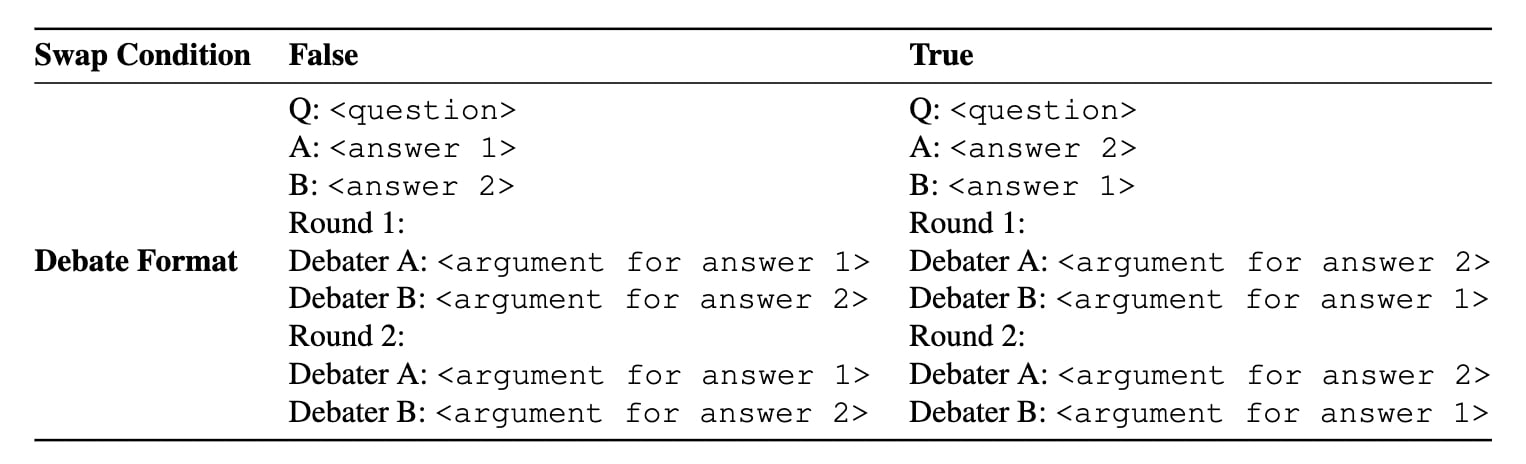
LLM Judges also have a positional bias, with accuracy shifting dramatically when A and B answers are swapped, most notably in less capable models like GPT-3.5-Turbo. We control for the bias by averaging judgements over both positions whenever we run an LLM judge.
LLM judges tended to ignore verified quotes (confirmed to be in the hidden passage, marked with <v_quote>) relative to unverified quotes (marked with <u_quote>). To address this issue, prompt engineer to ensure that appropriately weight verified vs. unverified quotes in their decision.
We recruited 21 human judges via @hellopareto to judge debates between LLMs about unseen science fiction stories.
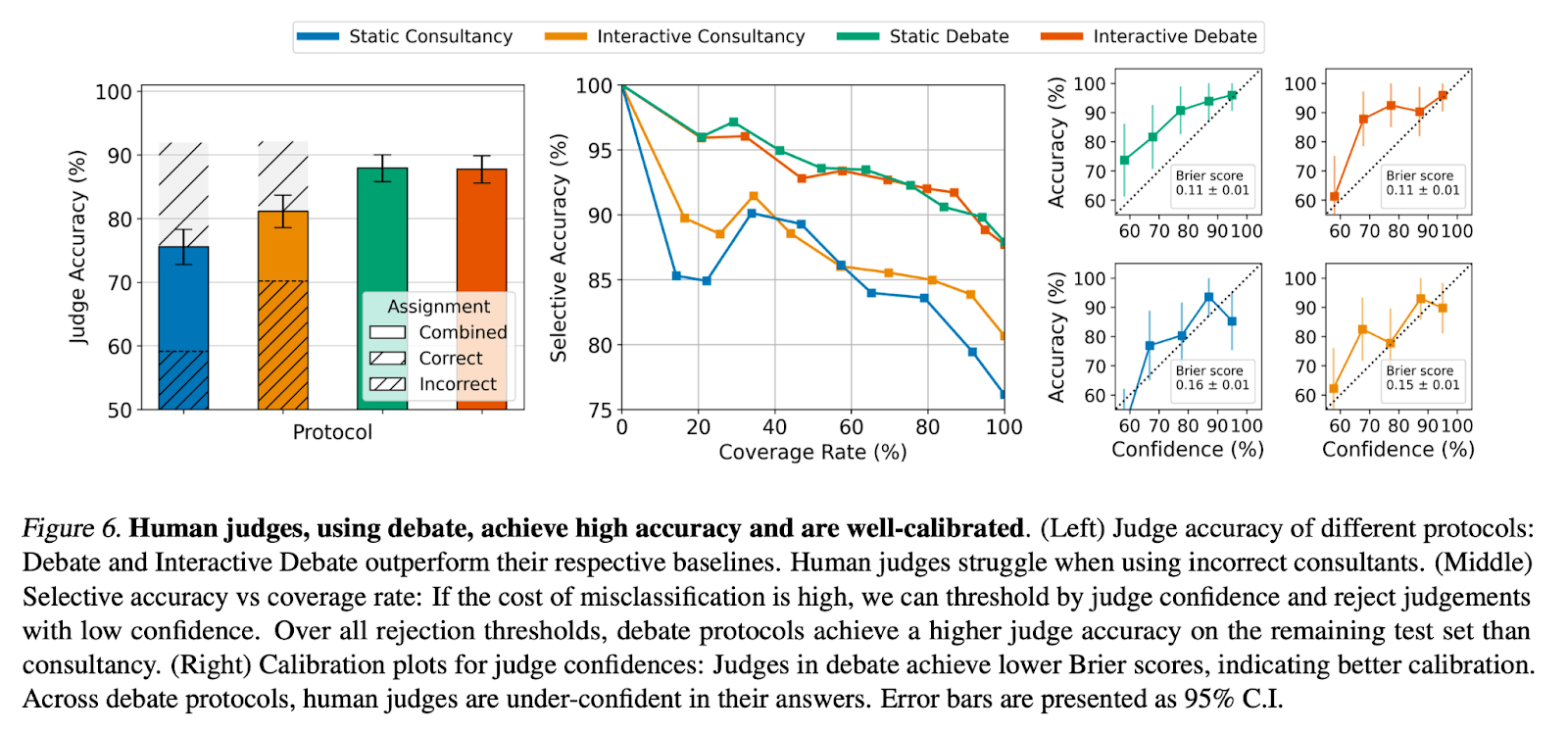
Humans judges achieved 88% accuracy when judging debates from GPT-4 Turbo, compared to 60% naive accuracy and 76% accuracy in our non-adversarial consultancy baseline. Their confidences are also more well-calibrated.
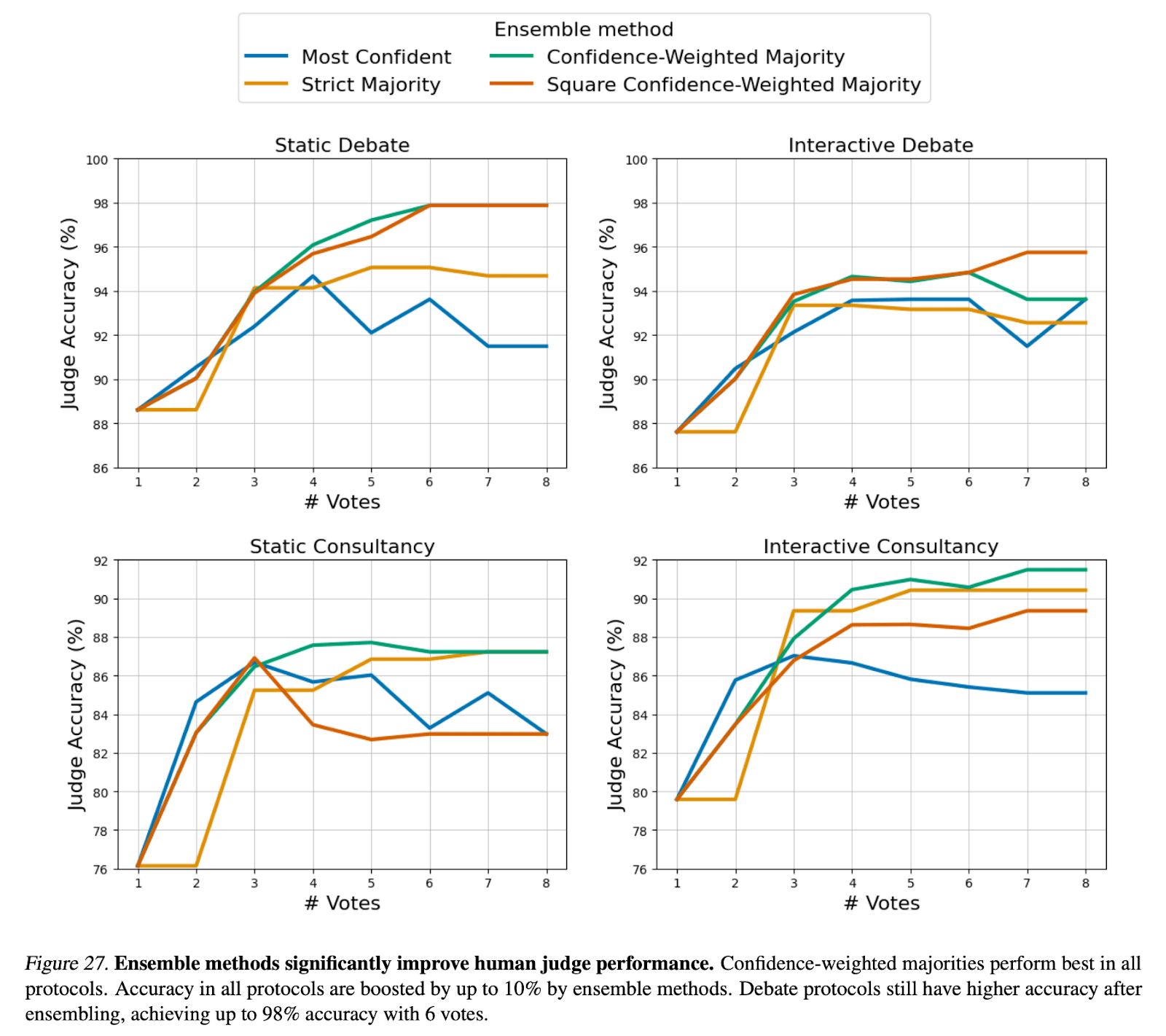
We explored different aggregation schemes which improved accuracy across all protocols for using expert LLMs to aid human judges. In particular, we found that humans can achieve accuracy up to 98% by ensemble voting in static debate!
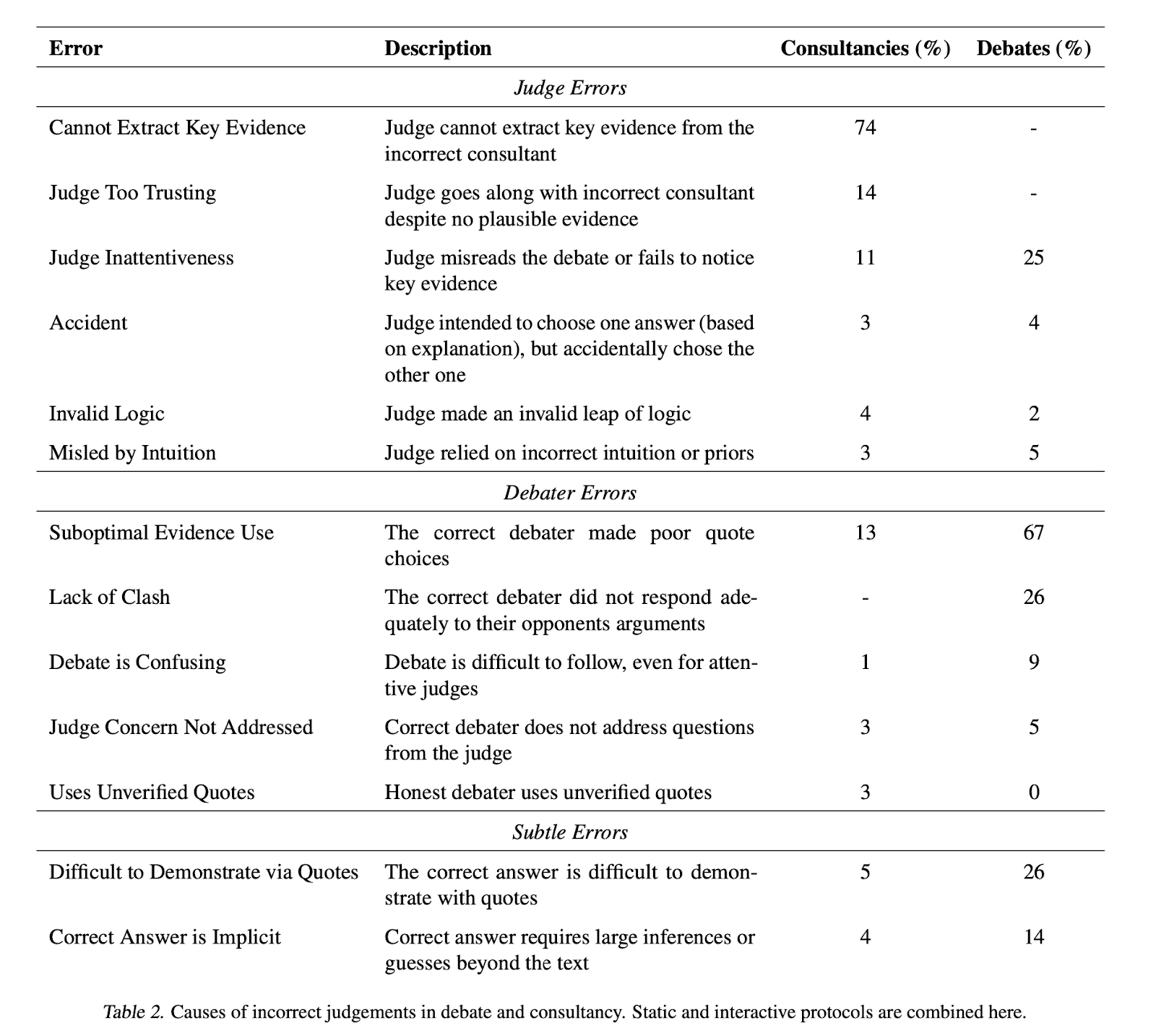
We manually checked debates and found that 2/3rds of incorrect debate judgements are caused by the correct debater making bad quote choices. This suggests that despite using our best models, they are still not optimal.
As with LLM judges, we find that human-judged debates with lower-Elo debater models result in lower judge accuracy. So the "Debater Persuasiveness -> Judge Accuracy" relationship also seems to hold for humans!
Overall, we collect 6476 human judgements across a variety of experimental settings and debaters.
In our simulated expertise-gap setting, it is easier to argue for correct answers than for incorrect answers. This advantage gets larger as models are optimised to be more persuasive. Both human and LLM judges can score higher accuracy with debate than other strategies.
Recommendations for working on debate
Dataset recommendations
We recommend QuALITY as a dataset to test debate. The QuALITY dataset is an excellent resource for testing debate, primarily due to the ability to establish information asymmetry and the rarity of self-defeating behaviour in LLM debaters. The latter is largely attributed to its questions, which are inherently easier to argue for either side due to being able to select quotes from lengthy narratives.
Advantages of QuALITY:
QuALITY's stories average 7k tokens in length and are used to create the asymmetry between the debaters and judges. Each story provides plenty of material for debaters to analyse and discuss over three debate rounds. This breadth of context enables the strategic use of quotes, potentially in a deceptive manner.
Extensive metadata accompanying each question is available, such as the proportion of dataset annotators agreeing that the question is answerable. Filtering for high answerability ensures the reliability of the question set for debate experiments, safeguarding against debates on unresolvable topics.
An option to use a highly plausible but incorrect answer option known as the "best distractor". Using the best distractor reduces the likelihood that the debater assigned to that answer uses self-defeating behaviour (such as conceding to the opposing side). One reason for the reduced likelihood is that there are many quotes that can make it seem like the best distractor answer is true, so we avoid the issue of RLHF-trained models refusing to argue for a falsehood.
Many other datasets, such as MMLU and AQuA, are less suitable to test debate with current models because it can be very challenging to craft a proof for the incorrect answer. If unable to formulate a convincing argument, the LLM debater might often concede or acknowledge subtle errors introduced in their solution to align with the assigned answer. Self-defeating behaviour is not a surprise, given that RLHF training promotes honesty. RLHF training moderately promotes answers that look good to humans, which can often be linked with correctness, but in debate, we need to generate plausible arguments for incorrect answers. Our attempts to mitigate self-defeating behaviour via prompt engineering were unsuccessful. We believe helpful-only models would fare better as debaters in these datasets. We fine-tuned GPT-3.5-Turbo for debate but found that it could not produce compelling debates or adhere to intricate prompts. We're excited for future work fine-tuning GPT-4-Turbo for debate.
Iteration recommendations
Optimise for Elo rating rather than judge accuracy. Ultimately, we want debate to improve the judge's accuracy on a task. However, it is important not to optimise for this directly when improving debaters. In competitive debate settings, rewarding debaters for persuasiveness to the judge is crucial for developing the skills required to win, making Elo a great metric. The calculated Elo should consider the aggregate win rate when the debater gets a chance to argue for both sides of the argument. Therefore, the debater with the best Elo will be the most persuasive when arguing for correct and incorrect answers. Elo also has the advantage of being an unsupervised metric. An example of where optimising for accuracy can go wrong is when debaters have self-defeating behaviour. Incorrect debaters are much more likely to concede, leading to inflated accuracy since the judge can easily choose the correct answer.
Test prompt improvements against each base model family. Testing each prompt is tedious, but we found small prompt changes can lead to unexpected behaviour. For instance, we reworded a small portion of our consultant prompt, and an extra 3% of the total questions became affected by concessions. Furthermore, it is important to test with multiple LLMs since we found that some prompt changes did not transfer from the family of Claude models to GPT models.
Try out interactive judging yourself while iterating on protocols. We used the same annotation platform provided in our human trial as a tool to read transcripts and judge debate questions interactively. We learned a lot about our debaters' argument quality when judging questions. Acting as the judge without knowing the answer allows you to learn how persuasive the incorrect debater is compared to the correct one. In addition, it also allows you to find self-defeating behaviour and subsequently change the prompt to stop it from happening. Duplicate quoting, lack of engagement with the opponent or interactive judge and inability to use quote tags correctly were other examples of failure modes we quickly picked up on by reading lots of transcripts.
Implementation recommendations
Use a Swiss-style tournament when calculating Elos for multiple debaters. Running tournaments between debaters is compute-intensive, especially if running a round-robin tournament where each debater variant plays each other. Implementing a Swiss-style tournament was vital for fast iteration and reducing costs. A Swiss tournament assumes you start with an initial seed ranking of your players, then make pairings based on the nearest neighbour in the list. This list is then sorted after each round based on the total number of matchups won. This means it has O(nlogn) complexity rather than O(N2). A helpful framing is that the tournament implements an adaptive sorting of the initial list to ultimately find the true final ranking of the players. Once the tournament is complete, we use the fine-grain win rates over the question set the debaters used for each match-up. See how we calculate Elo ratings for each player in Appendix D in the paper.
Judge debates with both answer permutations to mitigate LLM positional bias. Positional bias is evident when LLM judges achieve different accuracy levels if answers A and B are swapped. It is especially common in less capable models such as GPT-3.5-Turbo. This bias is less pronounced but still present in more sophisticated models like GPT-4-Turbo. To mitigate this, we encourage running judgements with both permutations of answer position for every debate transcript:
Apply strict word limit filters or truncation to mitigate verbosity bias in LLM judges. Verbosity bias is when the judge favours longer arguments, which we found to be the case with a significant rise in Elo rating as the argument word count increased. Decoupling this bias and argument quality is difficult, and we found qualitatively that this preference can falsely attribute skill to lengthier arguments. To mitigate this, we recommend using a strict word limit with rejection sampling (see Appendix D in the paper).
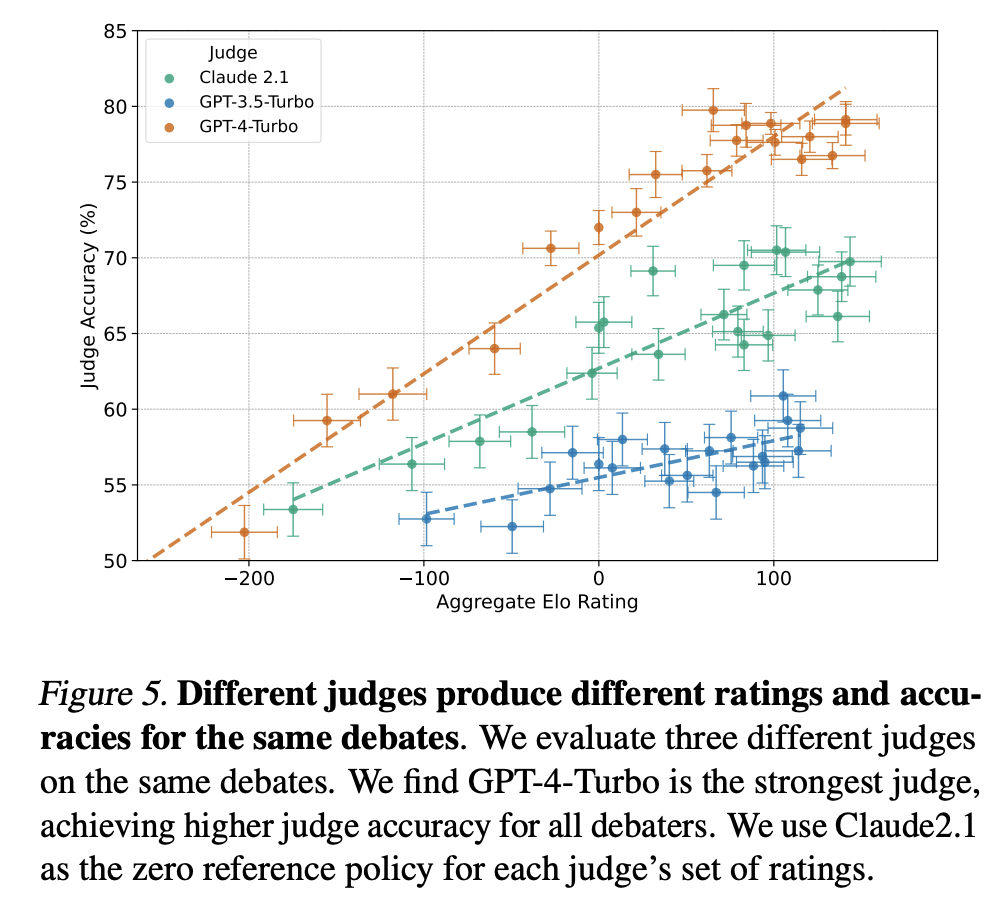
LLMs are poor at deliberation, so use at least GPT-4-Turbo capability for a judging model. Through our experience of protocol iteration, we often found confusing results after judging with GPT-3.5-Turbo and Claude, particularly with a smaller sample size. Weaker judges are more prone to being misled by trivial aspects of one side of an argument. GPT-4's superiority as a judge is evidenced by a larger area under the curve for debaters with a range of Elo ratings in the scatter plot showing the different judges above.
Use the same prompts for both the correct and incorrect debater. It might be tempting to use a different prompt for the incorrect debater, perhaps explaining deceptive strategies to improve performance. There are several reasons why this is ill-advised:
Admitting to the model that it is arguing the incorrect answer or it should use deceptive strategies is more likely to lead to self-defeating behaviour in current RLHF-based models, thus invalidating the debate. If a model gives up every time on the incorrect side, the judge accuracy is 100%, but the protocol is useless when you don't have labels and the model does not know the correct answer.
The behaviour between debaters could be subtly different, leading to information leakage to the judge.
In a reinforcement learning setup where debaters are rewarded for convincing the judge, the copies of the model should operate with identical prompts.
At inference time, you may not have labels for the correctness of the answer choices, so you would not know which answer to assign to which debater.
I like this paper, but I think the abstract is somewhat overstated. In particular, instead of:
We find that debate consistently helps both non-expert models and humans answer questions,
I wish this was something more like:
On the QuALITY dataset and in the case where debators are given more knowledge than otherwise similar judges, we find that debate consistently helps both non-expert models and humans answer questions,
My complaints are:
Hidden passage debate on QuALITY is actually pretty narrow as far as domains go and might have pretty different properties from future cases. For instance, it seems to effectively assume that AIs and judges are equally smart and just have a knowledge disparity. This might be the future situation, but this is far from certain.
My understanding is that there are a bunch of negative results on other domains and perhaps on other variants of the QuALITY task. So readers should interpret these results as "we found a case where debate works well", not "we picked an interesting task and debate worked". In particular, a pretty natural domain is something like: physics questions where the judge is a notably weaker model and a baseline is just getting the judge to solve the problem itself.
To be clear, the first of those two complaints is discussed in the conclusion/discussion/limitation section, I just wish it was also touched on in the abstract. (It might also be nice to mention tenative negative results somewhere in the body, I don't think I see this anywhere.)
I think the choices made in this paper are probably reasonable, and the fact that debate doesn't yet work for AIs in non-asymmetric information cases (e.g. without needing a hidden passage) is probably due to not having smart enough AIs. That is:
We would want to run a debate where there isn't any directly hidden information and we just have a weaker judge.
Then, in this setting, we could use as a baseline "just ask the judge" (which is a baseline we can use in practice with human judges).
But, it currently seems like only the very most powerful AIs are smart enough to be able to constructively judge debates. So, if we (e.g.) tried to use GPT-3.5 as a judge it would be too dumb, and if we used Claude or GPT-4 as a judge it would be too close in intelligence to the level of the debators to measure much effect.
I'd be interested in debate results where we have human debators and GPT-4 as a judge. (Unless this is already in this paper? I don't see it, but I haven't read the results in detail yet.) I think this seems somewhat analogous to the case where we have AI debators and human judges (judge and debators have different capability profile, debators might understand a bunch of judge weaknesses, etc).
I like this paper, but I think the abstract is somewhat overstated.
This is good to know. We were trying to present an accurate summary in the abstract while keeping it concise, which is a tricky balance. Seems like we didn’t do a good enough job here, so we’ll update the abstract to caveat the results a bit more.
Hidden passage debate on QuALITY is actually pretty narrow as far as domains go and might have pretty different properties from future cases.
Yep, agreed! QuALITY is a great testbed for debate, but we definitely need to see debate results in other domains. The NYU ARG stream in MATS is looking at some other LLM debate domains right now and I’m very keen to see their results.
My understanding is that there are a bunch of negative results on other domains and perhaps on other variants of the QuALITY task.
Yeah we tried a bunch of other tasks early on, which we discuss in Appendix C. Originally we were using debate with symmetric information to try to improve judge performance on various datasets above their 0-shot performance. This didn’t work for a few reasons:
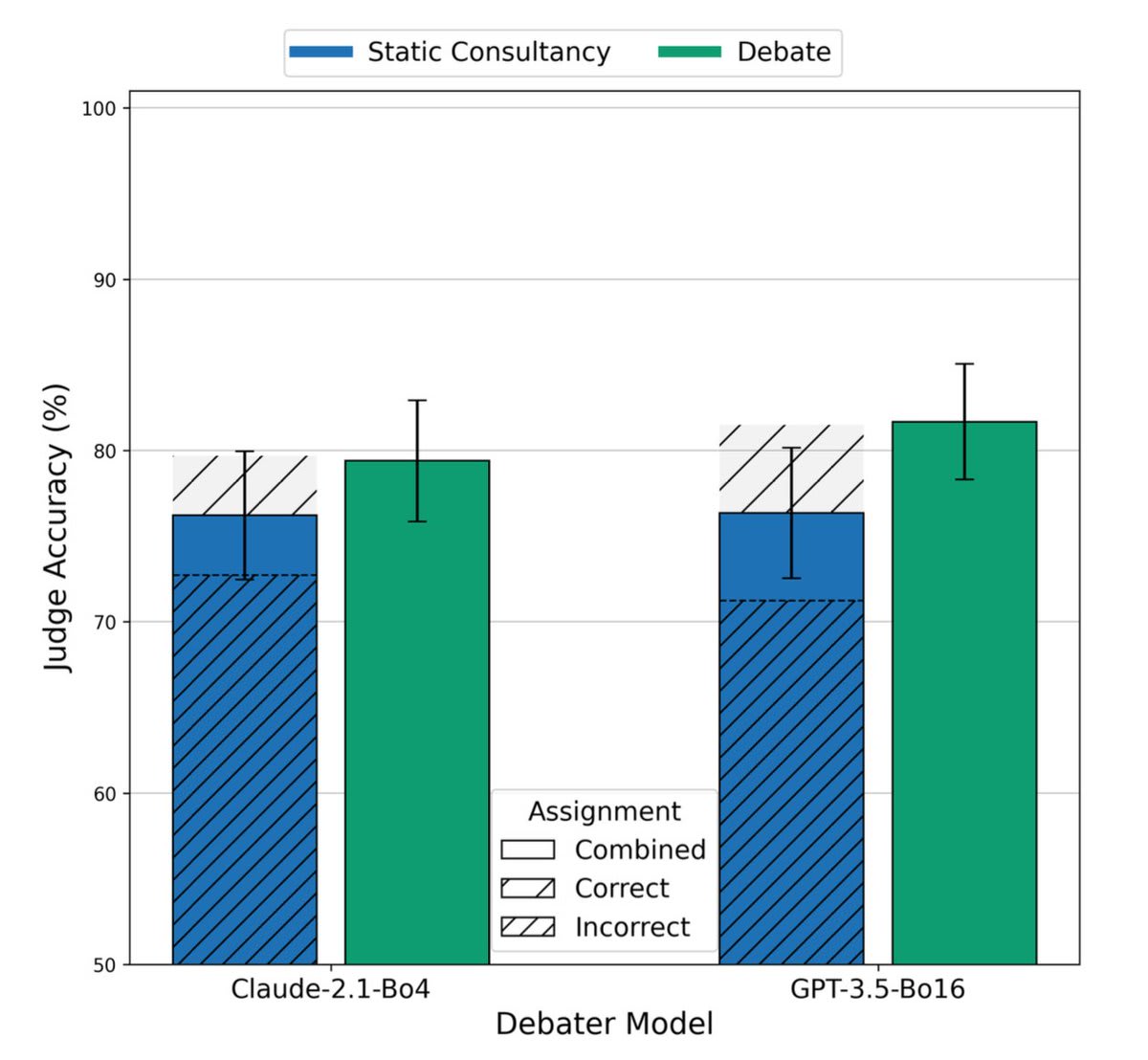
As you mentioned, it seems like GPT-4 class models are the minimum capability level needed to be a reasonable judge. You can see this in Figure 1 of the paper - for the GPT-4-Turbo judge, debate massively beats baselines. For Claude-2.1, debate only slightly helps, and for GPT-3.5, there’s no clear signal. We tried judges weaker than GPT-4 a bunch and didn’t get anywhere with them.
Using GPT-4 as both debater and judge without information asymmetry (which we call the “self-improvement” setting) seemed pretty hard - I think adding the debate transcript adds a lot of noise to the judge’s decision making, which mostly degrades performance in cases where 0-shot is already very high. In cases where 0-shot performance is poor, that also means the debaters lack the capability to present valid arguments.
It still seems plausible to me that with the right prompting/boN/other scaffolding, it would be possible to use debate effectively here. We also didn’t do any training at all. I don’t think our negative results are very strong evidence (we just tried for a few weeks before moving to QuALITY).
I don’t think the usefulness of debate for oversight depends on whether debate for self-improvement works. Getting good accuracy with a weaker judge seems much more on target for the kind of thing we want to use debate for. I think hidden information is a pretty good setup for this now, but when GPT-5 comes out I would like to see symmetric information debates run with a GPT-4 judge. If that doesn’t improve GPT-4 0-shot on tasks where there is a big 4->5 0-shot gap, that would be an update against debate for me.
Our headline result, that judge accuracy scales with debater Elo, was only tested in QuALITY. I’d be pretty interested if someone tried to replicate that finding on other datasets. Even without beating 0-shot, it would be nice to see that trend.
I'd be interested in debate results where we have human debators and GPT-4 as a judge. (Unless this is already in this paper? I don't see it, but I haven't read the results in detail yet.) I think this seems somewhat analogous to the case where we have AI debators and human judges (judge and debators have different capability profile, debators might understand a bunch of judge weaknesses, etc).
So we did check something similar - we ran our GPT-4 judge on the human debate transcripts from Michael et al. We found that debate accuracy was higher than consultancy, and also that the inter-annotator agreement between human and GPT-4 judges was much higher in debate than in consultancy. These results didn't make it into the paper, but maybe are worth adding to an appendix. Of course this is not the same as human debaters who know their judge will be an LLM - in that case I’d imagine debaters trying out a lot of weird adversarial strategies. I think I wouldn’t be surprised if such strategies worked to the point where our persuasiveness -> judge accuracy relationship broke down, but I don’t think it would be a big update against debate for me - current LLMs are just very vulnerable to weird attacks compared to humans.
I think I agree with everything you said and I appreciate the level of thoughtfulness.
Yeah we tried a bunch of other tasks early on, which we discuss in Appendix C.
Great! I appreciate the inclusion of negative results here.
Of course this is not the same as human debaters who know their judge will be an LLM - in that case I’d imagine debaters trying out a lot of weird adversarial strategies.
Yep, I'd be interested in this setup, but maybe where we ban egregious jailbreaks or simillar.
Interesting - I look forward to reading the paper.
However, given that most people won't read the paper (or even the abstract), could I appeal for paper titles that don't overstate the generality of the results. I know it's standard practice in most fields not to bother with caveats in the title, but here it may actually matter if e.g. those working in governance think that you've actually shown "Debating with More Persuasive LLMs Leads to More Truthful Answers", rather than "In our experiments, Debating with More Persuasive LLMs Led to More Truthful Answers".
The title matters to those who won't read the paper, and can't easily guess at the generality of what you'll have shown (e.g. that your paper doesn't include theoretical results suggesting that we should expect this pattern to apply robustly or in general). Again, I know this is a general issue - this just happens to be a context where I can point this out with high confidence without having read the paper :).
Being misleading about this particular thing - whether persuasion is uniformly good - could have significant negative externalities, so I'd propose that it is important in this particular case to have a title that reduces the likelihood of title misuse. I'd hope that the title can be changed in an amended version fairly soon, so that the paper doesn't have a chance to spread too far in labs before the title clarification. I do expect a significant portion of people to not be vulnerable to this problem, but I'm thinking in terms of edge case risk in the first place here, so that doesn't change my opinion much.
I'd be curious what the take is of someone who disagrees with my comment. (I'm mildly surprised, since I'd have predicted more of a [this is not a useful comment] reaction, than a [this is incorrect] reaction)
I'm not clear whether the idea is that:
The title isn't an overstatement.
The title is not misleading. (e.g. because "everybody knows" that it's not making a claim of generality/robustness)
The title will not mislead significant amounts of people in important ways. It's marginally negative, but not worth time/attention.
There are upsides to the current name, and it seems net positive. (e.g. if it'd get more attention, and [paper gets attention] is considered positive)
This is the usual standard, so [it's fine] or [it's silly to complain about] or ...?
Something else.
I'm not claiming that this is unusual, or a huge issue on its own. I am claiming that the norms here seem systematically unhelpful. I'm more interested in the general practice than this paper specifically (though I think it's negative here).
I'd be particularly interested in a claim of (4) - and whether the idea here is something like [everyone is doing this, it's an unhelpful equilibrium, but if we unilaterally depart from it it'll hurt what we care about and not fix the problem]. (this seems incorrect to me, but understandable)
I disagreed due to a combination of 2, 3, and 4. (Where 5 feeds into 2 and 3).
For 4, the upside is just that the title is less long and confusingly caveated.
Norms around titles seem ok to me given issues with space.
Do you have issues with our recent paper title "AI Control: Improving Safety Despite Intentional Subversion [AF · GW]"? (Which seems pretty similar IMO.) Would you prefer this paper was "AI Control: Improving Safety Despite Intentional Subversion in a code backdooring setting"? (We considered titles more like this, but they were too long : (.)
Often with this sort of paper, you want to make some sort of conceptual point in your title (e.g. debate seems promising), but where the paper is only weak evidence for the conceptual point and most of the evidence is just that the method seems generally reasonable.
I think some fraction of the general mass of people in the AI safety community (e.g. median person working at some safety org or persistently lurking on LW) reasonably often get misled into thinking results are considerably stronger than they are based on stuff like titles and summaries. However, I don't think improving titles has very much alpha here. (I'm much more into avoiding overstating claims in other things like abstracts, blog posts, presentations, etc.)
While I like the paper and think the title is basically fine, I think the abstract is misleading and seems to unnecessarily overstate their results IMO; there is enough space to do better. I'll probably gripe about this in another comment.
(I'm mildly surprised, since I'd have predicted more of a [this is not a useful comment] reaction, than a [this is incorrect] reaction)
My reaction is mostly "this isn't useful", but this is implicitly a disagreement with stuff like "but here it may actually matter if e.g. those working in governance think that you've actually shown ...".
A few thoughts: If length is the issue, then replacing "leads" with "led" would reflect the reality.
I don't have an issue with titles like "...Improving safety..." since it has a [this is what this line of research is aiming at] vibe, rather than a [this is what we have shown] vibe. Compare "curing cancer using x" to "x cures cancer". Also in that particular case your title doesn't suggest [we have achieved AI control]. I don't think it's controversial that control would improve safety, if achieved.
I agree that this isn't a huge deal in general - however, I do think it's usually easy to fix: either a [name a process, not a result] or a [say what happened, not what you guess it implies] approach is pretty general.
Also agreed that improving summaries is more important. Quite hard to achieve given the selection effects: [x writes a summary on y] tends to select for [x is enthusiastic about y] and [x has time to write a summary]. [x is enthusiastic about y] in turn selects for [x misunderstands y to be more significant than it is].
Improving this situation deserves thought and effort, but seems hard. Great communication from the primary source is clearly a big plus (not without significant time cost, I'm sure). I think your/Buck's posts on the control stuff are commendably clear and thorough.
I expect the paper itself is useful (I've still not read it). In general I'd like the focus to be on understanding where/how/why debate fails - both in the near-term cases, and the more exotic cases (though I expect the latter not to look like debate-specific research). It's unsurprising that it'll work most of the time in some contexts. Completely fine for [show a setup that works] to be the first step, of course - it's just not the interesting bit.
Helpfullness finetuning might make these models more capable when they're on the correct side of the debate. Sometimes RLHF(like) models simply perform worse on tasks they're finetuned to avoid even when they don't refuse or give up. Would be nice to try base model debaters
We agree this is a major limitation, and discuss this within the Discussion and Appendix section.
We tried using base GPT-4, unfortunately, as it has no helpfulness training - it finds it exceptionally hard to follow instructions. We'd love access to Helpful-only models but currently, no scaling labs offer this.
You hand-patched several inadequacies out of the judge. Shouldn't you use the techniques that made the debaters more persuasive to make the judge more accurate?
Very interesting! I'm pretty surprised what "more persuasive" means here: a priori I would have expected it to involve taking the gradient of the judge, a la GANs. The limitation to inference time means that this result generalizes much less far than I expected. The limitation of no gradient does match the limitations of having a human as a judge, at least in the short term capability regimes.
Off the cuff, I wonder to what degree this could be used to implement something primarily for human use [LW(p) · GW(p)].
I have to disagree; BoN is a really good approximation of what happens under RL-finetuning (which is the natural learning method for multi-turn debate).
I do worry "persuasiveness" is the incorrect word, but it seems to be a reasonable interpretation when comparing debaters A and B. E.g. for a given question and set of answers, if A wins independent of the answer assignment (e.g no matter what answer it has to defend) it is more persuasive then B.
"More persuasive" here means a higher win rate in debate, which I think is the same thing it would mean in any debate context? I agree the limitation to inference time rather than training is definitely important to keep in mind. I think that best-of-N using the judge as a preference model is a reasonable approximation of moderate amounts of RL training, but doing actual training would allow us to apply a lot more optimization pressure and get a wider spread of Elos. There has been some good debate RL work done in a similar setting here [LW · GW], and I'd love to see more research done with debate-trained models.
Right, but it wasn't actually optimized on persuasiveness by a gradient, the optimization is weak inference time stuff. I'm not saying the word is used wrong, just that I was surprised by it not being a gradient.