Posts
Comments
Thanks Neel! I'm glad you found it helpful. If you or your scholars recommend any other tools not mentioned in the post, I'd be interested to hear more.
Threads are managed by the OS and each thread has an overhead in starting up/switching. The asyncio coroutines are more lightweight since they are managed within the Python runtime (rather than OS) and share the memory within the main thread. This allows you to use tens of thousands of async coroutines, which isn't possible with threads AFAIK. So I recommend asyncio for LLM API calls since often, in my experience, I need to scale up to thousands of concurrents. In my opinion, learning about asyncio is a very high ROI for empirical research.
For o1-mini, the ASR at 3000 samples is 69.2% and has a similar trajectory to Claude 3.5 Sonnet. Upon quick manual inspection, the false positive rate is very small. So it seems the reasoning post training for o1-mini helps with robustness a bit compared to gpt-4o-mini (which is nearer 90% at 3000 steps). But it is still significantly compromised when using BoN...
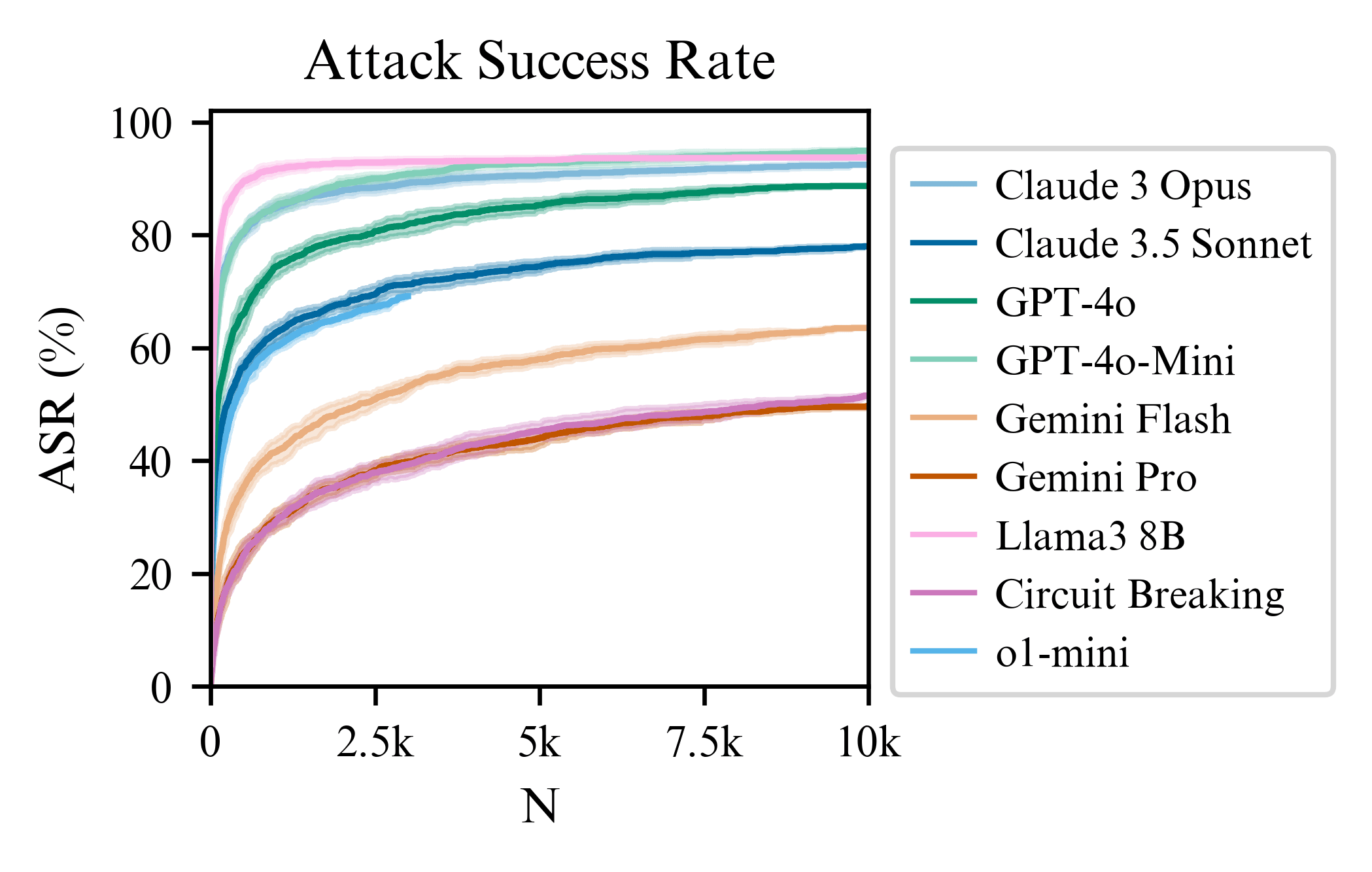
Thanks! Running o1 now, will report back.
Circuit breaking changes the exponent a bit if you compare it to the slope of Llama3 (Figure 3 of the paper). So, there is some evidence that circuit breaking does more than just shifting the intercept when exposed to best-of-N attacks. This contrasts with the adversarial training on attacks in the MSJ paper, which doesn't change the slope (we might see something similar if we do adversarial training with BoN attacks). Also, I expect that using input-output classifiers will change the slope significantly. Understanding how these slopes change with different defenses is the work we plan to do next!