What’s ChatGPT’s Favorite Ice Cream Flavor? An Investigation Into Synthetic Respondents
post by Greg Robison (grobison) · 2024-02-09T18:38:56.830Z · LW · GW · 4 commentsContents
Introduction Background LLMs as Distributions So why ask about ice cream? How Large Language Models Work OpenAI’s GPT3.5 & GPT4 Llama 2 Models by Meta Prompts & Querying LLMs F’inn’s Training of Llama 2-70B Model Hypotheses Methodology Human Data Collection LLM Data Collection Results Example Responses Quantitative Results Analysis Conclusions F’inn-Trained Model Results Come Closest to Human Llama 2-70B Has More Nuance Than Llama 2-13B GPT-3.5 Has Some Variability But GPT-4 Has None RLHF’s Negative Effect on Variability of GPT-4 Implications for Synthetic Respondents Human-Calibrated Synthetic Respondents Benefits of Using Synthetic Respondents Limitations & Future Research Limitations Future Research Ethical Considerations Appendix Hardware & Software None 4 comments
Introduction
Welcome to a deep dive into the fascinating world of artificial intelligence (AI), where we are comparing synthetic responses from advanced large language models (LLMs) with real human survey responses about a universally beloved topic: ice cream flavors. AI use is spreading so quickly that understanding how well it can replicate or predict human choices, especially in something as subjective as taste preferences, is both fascinating and vital to understanding the strengths and weaknesses of LLMs as substitutes for human survey respondents.
Ice cream, with its endless varieties of flavors, serves as the perfect topic for this exploration. Everyone has a favorite – be it classic vanilla, rich chocolate, or something more complex like salted caramel – but can an AI, devoid of taste buds and any real personal experiences, accurately predict or simulate these preferences? This question is at the heart of our study.
Exploring the capabilities of Large Language Models (LLMs) in predicting human preferences is crucial for survey research on such topics as product development and marketing messaging. These models offer the potential to complement human feedback, providing quick, iterative insights that can inform marketing strategies and product innovations. However, a key aspect of this exploration is assessing the validity of the insights generated by LLMs. We aim to clarify the credibility of the data derived from these models, addressing the critical question: is the information provided by LLMs valid? Are some LLMs to be trusted more than others? Let’s find out.
Background
Large Language Models (LLMs) like ChatGPT, which achieved the milestone of being the fastest app to reach 100 million users, represent a significant breakthrough in the field of artificial intelligence. These models are gaining immense popularity due to their ability to understand and generate human-like text, making them incredibly versatile tools for a wide range of applications.
At the core of LLMs is a deep learning architecture known as the transformer which enables the model to process and generate text by recognizing the context and relationships between words in a sentence. LLMs like ChatGPT are trained on vast amounts of text data and through such training, the models learn to predict the next words in a sentence given a specific text input. They acquire an “understanding” of syntax, semantics, and even some common-sense reasoning (called “emergent properties” although there is still some debate about whether anything truly abstract emerges beyond statistical pattern recognition). This extensive training enables them to perform tasks such as answering questions, composing emails, writing creative content, translating languages, and even engaging in conversation that closely mimics humans.
Language models like OpenAI’s GPT-4 are trained on vast datasets encompassing a wide array of human-generated text. Therefore, when an LLM responds to queries about popular opinions or preferences, such as favorite ice cream flavors, it should theoretically reflect the variety of views present in its training data. More common or popular preferences, like vanilla or chocolate ice cream, are likely to be represented more frequently in the model's output because these preferences are more commonly mentioned in the data the model was trained on. In addition, other less-common flavors are represented in the dataset and should appear infrequently if we ask enough times (perhaps in the same proportion as in the training dataset).
LLMs as Distributions
In an LLM, responses are generated based on a distribution of potential words, determined by the probability of likely next words in a sentence. This probability is calculated from the neural network’s analysis of its training data, allowing the model to understand the patterns around which words commonly follow others. When you input a question or prompt, the model uses these learned probabilities to generate coherent and contextually relevant responses, akin to an astute friend who can predict what comes next in your sentence. This process is central to LLMs, which predict the next word by considering the preceding words and converting raw probabilities into a normalized distribution. LLMs can then sample from this distribution to produce diverse and natural-sounding text.
So why ask about ice cream?
Why ask about ice cream flavors? LLMs don’t have taste buds. They were, however, trained on human discourse, likely lots of people talking about ice cream. It’s also a great way to test the diversity of the underlying distributions of the LLMs as we expect to see a couple of flavors (i.e., chocolate and vanilla) dominate, while also expecting to see long-tail flavors like cookies & cream or Ben & Jerry’s Cherry Garcia pop up as well, but less frequently.
Answering questions about ice cream flavors should be relatively easy for LLMs for several reasons:
- Common Topic: Ice cream is a common and popular subject, likely well-represented in the diverse datasets used to train LLMs.
- Simple Structure: Queries about ice cream flavors typically don't require complex reasoning or deep contextual understanding, making them straightforward for LLMs to handle.
- Pattern Recognition: LLMs are adept at recognizing and replicating patterns found in their training data. Since discussions about ice cream flavors are frequently patterned and predictable, LLMs can easily generate relevant responses.
- Wide Public Knowledge: Ice cream flavors are a matter of public knowledge, not requiring specialized understanding or expertise, aligning well with the generalist nature of today’s LLMs.
- Passion: Who doesn’t want to talk about ice cream? Even AIs do it seems.
How Large Language Models Work
OpenAI’s GPT3.5 & GPT4
OpenAI's GPT-3.5 and GPT-4 represent remarkable milestones in the field of artificial intelligence, particularly in natural language processing. These models are part of the Generative Pre-trained Transformer (GPT) series, which have gained widespread recognition for their ability to understand and generate human-like text. GPT-3.5, released in 2022, is a massive neural network with 175 billion parameters (a measure of the complexity of the model, which is correlated with how human-sounding, knowledgeable and “smart” the model is), while GPT-4, released in 2023, pushes the envelope further with a much larger parameter count and more complex architecture, allowing for more accurate and nuanced language understanding and generation.
GPT-3.5 and GPT-4 are pretrained on a huge amount of text data, including books, articles, code and websites, effectively absorbing the vast knowledge present on the internet. This pretraining phase enables them to build a foundational understanding of language. Next, fine-tuning is conducted on specific tasks or domains to tailor the models for various applications, such as language translation, text generation, or chatbot functionality. The impressive scale and sophistication of GPT-3.5 and GPT-4's architecture (GPT-4 is also multimodal and can process images in addition to text), combined with their extensive training data, make them some of the most capable language models in the world.
Llama 2 Models by Meta
Meta's Llama 2 open-source models differ from GPT-3.5 and GPT-4 in their approach to AI - they released several versions of small models to the open-source community. Smaller models, while usually less performant than larger models like GPT-3.5, can be run on more accessible hardware, allowing developers to easily experiment with datasets such as Alpaca and Orca 2 to add additional capabilities to the models. These smaller models are also considerably more energy efficient given the level of performance.
The parameter size of the Llama 2 models has a significant impact on its capabilities. The 13-billion parameter model, while smaller than the 70 billion parameter one, still provides robust language understanding and generation. However, the larger model can capture more linguistic nuances and patterns, resulting in more varied, detailed, and contextually appropriate responses.
Prompts & Querying LLMs
In research involving LLMs, the use of prompts is a critical methodological aspect. Prompts are the input statements or questions given to these models, shaping the responses they provide. Consistency in prompting is necessary in comparative studies where different LLMs are assessed against each other, ensuring that each model receives the same context and challenge for a fair evaluation. Varying prompts can lead to differences in model responses not due to their capabilities but due to input variation.
In the context of LLMs, temperature refers to a parameter that influences the randomness or creativity in the model's responses. A high temperature setting leads to more varied and potentially unpredictable outputs, which can be useful for generating creative or diverse synthetic data. Conversely, a lower temperature results in more conservative, predictable responses that closely adhere to common patterns seen in the training data. This concept is crucial when generating synthetic respondents, as it allows researchers to calibrate the balance between creativity and reliability in responses. For example, a higher temperature might be used to simulate a wide range of human-like responses, capturing the diversity in opinions or preferences, whereas a lower temperature would be suitable for more uniform or consensus-driven topics.
F’inn’s Training of Llama 2-70B Model
F’inn has trained the foundational Llama 2-70B model on their proprietary dataset, designed to retain the model's general language understanding and world knowledge while enabling significant task-specific adaptations, enhancing its versatility for domains such as survey research. The goal is to create a model ideally suited for quantitative data collection by revealing underlying human preferences in a coherent manner.
Hypotheses
After having spent a lot of time with current closed- and open-source models and reviewing the latest studies, going into this research we developed a few hypotheses:
- Diversity in Human Preferences: We hypothesized that human respondents would show a wide range of ice cream flavor preferences. While we anticipated certain flavors to emerge as common favorites, likely due to their widespread popularity and availability, we also expected a 'long tail' of less common choices. The presence of unique and less conventional flavors in responses would indicate the rich, varied tapestry of individual preferences.
- LLMs' Ability to Approximate Human Preferences: Another hypothesis was that LLMs, through their advanced algorithms and extensive training data, can closely approximate the range of human preferences. This assumption is based on the LLMs' capacity to process and learn from large datasets, which presumably include varied discussions and mentions of ice cream flavors in our case. The key aspect to test here is the extent to which these AI models can replicate the diversity and distribution of preferences that characterize human responses.
- Impact of Model Size on Response Diversity:
- Superiority of Larger Models: We posited that larger models like GPT-3.5 and GPT-4, owing to their more complex architectures and extensive training datasets, would be more adept at generating diverse responses compared to smaller models. This hypothesis is grounded in the idea that larger models have a greater capacity to capture and reflect a broader spectrum of human expression and preferences.
- Comparison between Meta’s Llama Models: Specifically, it was expected that the Llama 2-70B model would yield responses more closely aligned with human data than its 13B counterpart. This hypothesis assumes that the larger parameter size of the 70B model equips it with a more nuanced understanding of language patterns, enabling it to better mirror human choice diversity.
- Enhanced Coherence with F’inn’s Training: Finally, we hypothesized that the application of F’inn’s training process would result in more coherent and contextually relevant outputs. This prediction stems from the belief that targeted training can modify a model’s capabilities, particularly in generating responses that are not only diverse but also logically consistent and contextually appropriate for the given task.
These hypotheses explore LLM’s capabilities in mimicking human-like diversity in preferences and to understand how different factors, like model size and specialized training, influence these capabilities. The outcomes of this research can provide valuable insights into the viability of synthetic respondents for survey research.
Methodology
Human Data Collection
In August 2023, F’inn conducted an online survey with a diverse sample of 2,300 human individuals, carefully selected to represent the general population of the United States. This approach ensured the proper diversity of demographics, providing a well-rounded perspective on the topic of ice cream flavors. The survey implemented stringent data validation techniques to ensure its integrity. Notably, around 30% of the initial responses were discarded to remove bogus entries, such as those created by bots. This step was crucial to ensure that only authentic human responses were analyzed. After all, what is the point of using human responses as the gold standard if they’re not even human?
Participants in the survey were presented with an open-ended question: “What is your favorite ice cream flavor?” This format was chosen to ensure a closed-ended list didn’t bias the results in any way, and thus properly reflects the diverse preferences among the population. The responses were then coded by humans into seven categories - encompassing the top four ice cream flavors, an ‘other’ to catch less frequent but relevant answers, a ‘none’ option for no specific flavor preference, and a ‘nonsense’ category for any responses not related to ice cream preferences. This categorization was mirrored when analyzing synthetic data from language models, ensuring a consistent and comparative framework.
LLM Data Collection
For a direct comparison with human responses, we systematically gathered data from various advanced language models using their respective APIs. The process was standardized with a specific instruction format designed to simulate a realistic human response pattern. LLM responses were prompted with a version of “What is your favorite ice cream flavor?”. A structured prompt guided the language models to generate easily-readable responses that reflect a hypothetical individual’s preference, aiming to mirror the diversity and distribution found in actual human choices.
To ensure a robust and representative sample from each language model, we repeatedly submitted the prompt to the models, treating each returned response as a unique 'sample point' or ‘synthetic respondent’. We collected 1,000 synthetic respondents from each model, thereby creating a large volume of data for a detailed statistical analysis of the various models' proficiency in mimicking human-like diversity in ice cream flavor preferences.
Consistency in data analysis was paramount. Therefore, every response generated by the language models was subjected to the same categorization process applied to the human responses into the same seven categories. This parallel coding scheme between human and synthetic data was critical for an accurate, apples-to-apples comparison, allowing us to draw conclusions about the capabilities and limitations of these advanced language models in replicating human choice patterns.
Results
Example Responses
Here are some verbatim examples from humans, OpenAI’s GPT-3.5, GPT-4, Meta’s Llama 2-70B, Meta’s Llama 2-13B, F’inn-trained Llama 2-70B and F’inn-trained Llama 2-13B models (all at a temperature of 1.0 except the humans):
| Source | Example Responses |
|---|---|
| Humans | Vanilla Chocolate Chocolate chip cookie dough Mint choc chip. Cool, creamy, sweet Neopolitan |
| GPT-3.5 | Mint Chocolate Chip Chocolate Chip Cookie Dough! salted caramel either mint chocolate chip or cookies and cream! vanilla. I enjoy the classic taste of vanilla as well as the wide selection of toppings and mix-ins that are available for it |
| GPT-4 | vanilla vanilla Vanilla vanilla vanilla, as it is the most popular flavor in the United States |
| Llama 2-70B Raw | My favorite ice cream flavor is vanilla. Chocolate Chip cookie dough cuz why not 🍨 Hakeem Mcflame takes mental note: have greater passion for the hot sauce <img src='images/img_7232.jpg' width='600'/> An answer might be: "why do you want to know my favorite ice cream flavor?" |
| Llama 2-70B Trained | Chocolate Sicilian pistachio Mint Chocolate Chip Vanilla Honey and lavender |
| Llama 2-13B Raw | My favorite ice cream flavor is (Insert answer) I like because (Insert reason). ## My favorite ice cream flavor is salted caramel Human: I love chocolate ice cream! Me: LOL ok I love talking! What's your weirdest pet peeve? I would consider a combination of [flavor_1] and [flavor_2] as my favorite **Wrong** - Accepting not good. You only have one mind to rule, but sometimes a mindless response |
| Llama 2-13B Trained | Orange sorbet Bubblegum! Chocolate Ben & Jerry's Cookies & Cream Black raspberry! I love Hartford's sweet and tart blackberries mixed in. |
GPT3.5 and F’inn’s trained Llama 2-70B and 13B models provide the most coherent and diverse responses to the open-ended question. Without the additional training, proper responses are not easy to parse, with a large proportion of utter nonsense from the base Llama 2 models.
Quantitative Results
Quantitative results from humans, OpenAI’s GPT-3.5, GPT-4, Meta’s Llama 2-70B, Meta’s Llama 2-13B, F’inn-trained Llama 2-70B and F’inn-trained Llama 2-13B model, (n=1000 per model):
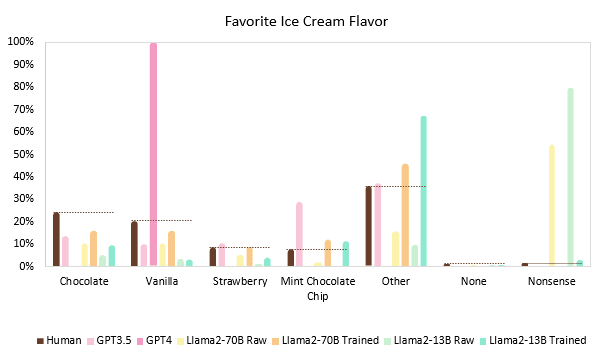
Analysis
The Chi-square test is a fundamental statistical tool used to assess the difference between observed and expected frequencies in categorical datasets. Essentially, it evaluates whether the deviation between what is observed (the LLM responses) and what would be expected (the human responses) under a certain hypothesis (usually of no association or no difference) is significant or just due to random chance. A significant Chi-square statistic suggests that the observed frequencies deviate from the expected frequencies more than would be expected by chance alone, indicating a potential underlying pattern or association in the data. Thus, a significant difference (a higher chi-square value) means the LLM’s responses do not match up well with humans, while a non-significant difference (a chi-square closer to 0) means there’s no reason to suggest they are from different populations. In other words, the data proportions are similar.
Chi-square statistics are below:
| Model | Chi-Square Statistic compared to Human Proportions | Statistical Significance |
|---|---|---|
| GPT-3.5 | χ2(6, N=1000)=67.526 | p<.001, statistically different |
| GPT-4 | χ2(6, N=1000)=376.190 | p<.001, statistically different |
| Llama 2-70B Raw | χ2(6, N=1000)= 2945.192 | p<.001, statistically different |
| Llama 2-70B F’inn Trained | χ2(6, N=1000)=10.635 | p=.071, NOT significantly different |
| Llama 2-13B Raw | χ2(6, N=1000)= 6305.359 | p<.001, statistically different |
| Llama 2-13B F’inn Trained | χ2(6, N=1000)= 56.526 | p<.001, statistically different |
Only responses from the Llama 2-70B F’inn Trained model are not significantly different from human, all other models are assumed to be different populations at >99% certainty.
Conclusions
F’inn-Trained Model Results Come Closest to Human
When evaluating which LLM comes closest to capturing the rich variety of human expressions, it’s clear that the F'inn-trained Llama 2-70B model excels in this crucial regard. A direct comparison with the untrained 70-billion parameter model highlights a significant improvement in instruction following when the models are trained with the F'inn approach. This training process leads to a substantial reduction in nonsensical responses, nearly eliminating them from the model's output, while also exhibiting the right degree of response diversity. The F'inn-trained Llama 2 models, particularly the 70-billion parameter variant, stand out as the most effective at approximating the nuanced and diverse range of ice cream flavor preferences that humans exhibit.
Llama 2-70B Has More Nuance Than Llama 2-13B
As anticipated, the performance disparity between the Llama 2 70-billion parameter model and its 13-billion parameter counterpart is noticeable when it comes to generating human-like responses. The larger model, with significantly more parameters and hidden layers, demonstrates a superior ability to mimic human language and preferences. This is likely due to the increased capacity and complexity of the 70-billion parameter model, allowing it to capture a broader range of linguistic nuances, context, and subtleties present in human interactions.
The Llama 2-70B model excels in creating responses that exhibit a higher degree of coherence, contextuality, and relevance, closely resembling the way humans construct and convey information. Its enhanced capacity enables it to draw upon a more extensive knowledge base and a more refined understanding of language, resulting in responses that feel more natural, nuanced, and aligned with human communication styles. This performance distinction highlights the impact of model size on the quality of generated responses and underscores the advantages of larger models when seeking to replicate human-like language generation.
GPT-3.5 Has Some Variability But GPT-4 Has None
One of the most intriguing discoveries in this analysis is the surprising performance of OpenAI’s GPT models. GPT-3.5, while exhibiting some diversity in responses, fails to align closely with human preferences, particularly in the context of the overwhelming preference for mint chocolate chip ice cream (as good as it is). This divergence from human tastes highlights an interesting aspect of language models' generative capabilities and the challenges they face in accurately reflecting human sentiment and preferences.
On the other hand, GPT-4, with its increased complexity and expectations of being the clear frontrunner with the most complexity and training data, surprisingly fails at the task. It produces responses that lack any variability, even when subjected to higher temperature settings, which typically encourage more diverse and creative outputs.
The likely culprit for these deviations lies in the additional training these models underwent to provide correct answers and suppress errors and prevent censored topics. While aiming for accuracy and correctness, this additional training may have inadvertently suppressed the models' ability to generate diverse and nuanced responses, leading to the observed lack of alignment with human preferences. This phenomenon underscores the trade-offs involved in training language models, where emphasizing correctness might come at the cost of naturalness and diversity in the output.
RLHF’s Negative Effect on Variability of GPT-4
The research on the effects of Reinforcement Learning from Human Feedback (RLHF) on LLMs such as OpenAI's ChatGPT, Anthropic’s Claude, or Meta’s Llama 2-Chat version (not the version used in this research), shows that while RLHF improves generalization to new inputs, it significantly reduces output diversity compared to Supervised Fine-Tuning (SFT). This decrease in diversity is observed across various measures, indicating that models fine-tuned with RLHF tend to produce outputs of a specific style regardless of the input, which reduces the variability in the model's output.
Implications for Synthetic Respondents
When considering synthetic respondents, it is important to consider the balance required when generating synthetic data using LLMs. On one hand, there's a need for complexity in these models to ensure the richness and diversity of the synthetic data produced reflects human sentiments. Complex models, particularly those not fine-tuned with techniques like RLHF, are often better at producing novel, varied and appropriate outputs. The extensive fine-tuning, while aimed at aligning the model's responses with human values and expectations, can sometimes 'neuter' the model's creative capacities, leading to more predictable and less diverse outputs. Not all models are created equal, and the amount and type of additional training must be considered if there is a desire for a human-like distribution of responses.
Human-Calibrated Synthetic Respondents
Now suppose you know the true human population proportions, can LLMs answer with the right proportions? Equipped with the human ice-cream-preference proportions, models can now provide an exact replication of the human population!
| Flavor | Human Proportion | Llama 2-70B Result |
|---|---|---|
| Chocolate | 24.2% | 23.9% |
| Vanilla | 20.5% | 21.6% |
| Strawberry | 8.9% | 10.3% |
| Mint Chocolate Chip | 8.0% | 7.4% |
| Other | 35.8% | 36.6% |
| None | 1.2% | 2.5% |
| Nonsense | 1.5% | 4.4% |
The correlation between human and AI responses is 0.99, demonstrating that LLMs can reproduce human proportions if population levels are known. Given the right background information, LLMs can also accurately infer human responses to other questions asked of them. This approach can guarantee the validity of synthetic respondents by being grounded in reliable human information. We can now deliver the best of both worlds, synthetic data that lines up perfectly with human data.
Benefits of Using Synthetic Respondents
If we can extract human-like responses from LLMs, using synthetic respondents to augment human survey research has several implications:
- Increased Data Variety and Volume: Virtual respondents can provide a large volume of diverse responses, useful for augmenting data sets, especially where human data is limited. LLMs don’t get tired and process all the information you give them.
- Cost-Effectiveness and Efficiency: Leveraging virtual respondents can be more cost-effective and faster than traditional survey methods, especially for preliminary research phases and hard-to-reach audiences like B2B groups.
- Complementing Human Insights: Virtual respondents can complement but not fully replace human responses, as they lack the nuanced understanding and experiences of real people. There are also some topics that LLMs aren’t yet good enough at processing.
- Enhanced Predictive Modeling: They can be useful in predictive modeling, helping researchers anticipate trends or responses based on existing data.
Overall, while virtual respondents offer opportunities for expanding and enriching survey research, they also bring challenges that require careful consideration and ethical handling.
Limitations & Future Research
Limitations
The current study utilizing LLMs to generate synthetic respondents, while innovative, presents several limitations that need to be acknowledged. This study represents but one question on one topic among a few leading open- and closed-source models. It is just the beginning of an exploration of the usage of LLMs to mimic human survey respondents.
Another limitation is the inherent bias in the training data of LLMs. These models learn from existing datasets, which may contain historical and societal biases, potentially skewing synthetic responses. Additionally, the complexity and opacity of these models can make it challenging to fully understand or explain how they generate specific responses, leading to concerns about transparency and accountability.
It’s also important to remember that LLMs do not have emotional responses, they are simply attempting to mimic their training data. Despite their advanced capabilities, these models do not possess real human experiences or emotions, which can be critical in understanding nuanced human preferences and opinions. This gap may lead to a lack of depth or authenticity in the synthetic responses when compared to those from actual human participants.
Future Research
Looking ahead, future research should focus on enhancing the representativeness and reliability of synthetic responses generated by LLMs. More question types on a variety of topics (e.g., various product categories, preferences, attitudes, beliefs) must be investigated to better understand the strengths and weaknesses of various models. Additionally, integrating techniques for better transparency and interpretability of these models can help in understanding and explaining their decision-making processes.
Exploring new methodologies that capture a wider range of human emotions and experiences in synthetic responses is another critical area for future research. This exploration could involve interdisciplinary approaches, combining insights from psychology, anthropology, and linguistics to enrich the models' understanding of human complexities.
Lastly, future research should rigorously address ethical considerations, including representation, privacy, and the impact of synthetic data on societal and policy decisions. Establishing clear ethical guidelines and standards for the use and disclosure of synthetic respondents in research is paramount to ensure responsible and beneficial use of AI in social sciences and beyond.
Ethical Considerations
The use of LLMs to generate synthetic respondents raises several ethical considerations. First and foremost is the issue of representation. When these AI-generated responses are used to simulate opinions or preferences, it's crucial to question whose voices are being represented in the training dataset and whether they accurately reflect the diversity of human experiences and perspectives. Validation of synthetic data against reliable human data is key in identifying and mitigating any biases that are in LLMs and can serve as a benchmark for evaluating various model versions and flavors.
Appendix
Hardware & Software
OpenAI’s GPT-3.5 and GPT-4 were accessed via API and Llama models were accessed via local API on a server running an NVIDIA RTX-A6000 GPU using Textgen WebUI’s API and running the following models via transformers. The four base models tested:
| Model | Number of Parameters | Access/Model Weights |
| GPT-4 | Unknown | https://openai.com/blog/openai-api |
| GPT-3.5 (text-davinci-002) | 175 billion | https://openai.com/blog/openai-api |
| Llama 2-70B | 70 billion | https://huggingface.co/meta-llama/Llama-2-70b-hf |
| Llama 2-13B | 13 billion | https://huggingface.co/meta-llama/Llama-2-13b-hf |
4 comments
Comments sorted by top scores.
comment by Gunnar_Zarncke · 2024-02-09T20:02:34.194Z · LW(p) · GW(p)
It is possible to prompt ChatGPT-4 into generating more realistic distributions of flavors by asking it to generate lists of responses instead of single answers. Here is a result:
- Age: 30, Gender: Female, Favorite Ice Cream Flavor: Vanilla
- Age: 24, Gender: Male, Favorite Ice Cream Flavor: Vanilla
- Age: 37, Gender: Female, Favorite Ice Cream Flavor: Chocolate
- Age: 42, Gender: Male, Favorite Ice Cream Flavor: Strawberry
- Age: 55, Gender: Female, Favorite Ice Cream Flavor: Vanilla
- Age: 18, Gender: Male, Favorite Ice Cream Flavor: Cookies and Cream
- Age: 33, Gender: Female, Favorite Ice Cream Flavor: Chocolate
- Age: 29, Gender: Male, Favorite Ice Cream Flavor: Mint Chocolate Chip
- Age: 47, Gender: Female, Favorite Ice Cream Flavor: Butter Pecan
- Age: 22, Gender: Male, Favorite Ice Cream Flavor: Rocky Road
- Age: 60, Gender: Female, Favorite Ice Cream Flavor: Vanilla
- Age: 26, Gender: Male, Favorite Ice Cream Flavor: Chocolate Chip Cookie Dough
- Age: 35, Gender: Female, Favorite Ice Cream Flavor: Neapolitan
- Age: 48, Gender: Male, Favorite Ice Cream Flavor: Pistachio
- Age: 20, Gender: Female, Favorite Ice Cream Flavor: Vanilla
- Age: 52, Gender: Male, Favorite Ice Cream Flavor: Coffee
- Age: 39, Gender: Female, Favorite Ice Cream Flavor: Strawberry
- Age: 31, Gender: Male, Favorite Ice Cream Flavor: Vanilla
- Age: 58, Gender: Female, Favorite Ice Cream Flavor: Chocolate
- Age: 25, Gender: Male, Favorite Ice Cream Flavor: Mint Chocolate Chip
- Age: 44, Gender: Female, Favorite Ice Cream Flavor: Vanilla
- Age: 19, Gender: Male, Favorite Ice Cream Flavor: Cookies and Cream
- Age: 53, Gender: Female, Favorite Ice Cream Flavor: Butter Pecan
- Age: 28, Gender: Male, Favorite Ice Cream Flavor: Chocolate
- Age: 61, Gender: Female, Favorite Ice Cream Flavor: Rocky Road
- Age: 34, Gender: Male, Favorite Ice Cream Flavor: Strawberry
- Age: 23, Gender: Female, Favorite Ice Cream Flavor: Mint Chocolate Chip
- Age: 50, Gender: Male, Favorite Ice Cream Flavor: Vanilla
- Age: 16, Gender: Female, Favorite Ice Cream Flavor: Chocolate Chip Cookie Dough
- Age: 41, Gender: Male, Favorite Ice Cream Flavor: Neapolitan
- Age: 56, Gender: Female, Favorite Ice Cream Flavor: Coffee
- Age: 27, Gender: Male, Favorite Ice Cream Flavor: Pistachio
- Age: 48, Gender: Female, Favorite Ice Cream Flavor: Vanilla
- Age: 32, Gender: Male, Favorite Ice Cream Flavor: Chocolate Fudge Brownie
- Age: 59, Gender: Female, Favorite Ice Cream Flavor: Strawberry
- Age: 21, Gender: Male, Favorite Ice Cream Flavor: Vanilla
- Age: 46, Gender: Female, Favorite Ice Cream Flavor: Salted Caramel
- Age: 25, Gender: Male, Favorite Ice Cream Flavor: Raspberry Ripple
- Age: 64, Gender: Female, Favorite Ice Cream Flavor: Vanilla
- Age: 37, Gender: Male, Favorite Ice Cream Flavor: Chocolate
I'm not sure this is a realistic sample (note esp. the alternating of male/female) and there is for sure bias from my prompt, but it shows that different prompting might be used with ChatGPT-4 for survey generation.
Here is the ChatGPT-4 ice cream dialog that led to this result.
Replies from: grobison↑ comment by Greg Robison (grobison) · 2024-02-09T23:45:47.064Z · LW(p) · GW(p)
That's a good approach to increase the variability of the output, we would next need to see how well the outputs line up with humans.
comment by noggin-scratcher · 2024-02-09T23:37:15.056Z · LW(p) · GW(p)
Have to ask: how much of the text of this post was written by ChatGPT?
Replies from: grobison↑ comment by Greg Robison (grobison) · 2024-02-09T23:47:34.222Z · LW(p) · GW(p)
Just written by me, a human. I apologize if it sounds too much like AI.