Superintelligence 13: Capability control methods
post by KatjaGrace · 2014-12-09T02:00:34.433Z · LW · GW · Legacy · 48 commentsContents
Summary Another view Notes 1. What do you do with a bad AI once it is under your control? 2. Cryptographic boxing 3. Philosophical Disquisitions 4. Some relevant fiction 5. Control through social integration 6. More miscellaneous writings on these topics How to proceed None 48 comments
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the thirteenth section in the reading guide: capability control methods. This corresponds to the start of chapter nine.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. Some of my own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post, or to look at everything. Feel free to jump straight to the discussion. Where applicable and I remember, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: “Two agency problems” and “Capability control methods” from Chapter 9
Summary
- If the default outcome is doom, how can we avoid it? (p127)
- We can divide this 'control problem' into two parts:
- The first principal-agent problem: the well known problem faced by a sponsor wanting an employee to fulfill their wishes (usually called 'the principal agent problem')
- The second principal-agent problem: the emerging problem of a developer wanting their AI to fulfill their wishes
- How to solve second problem? We can't rely on behavioral observation (as seen in week 11). Two other options are 'capability control methods' and 'motivation selection methods'. We see the former this week, and the latter next week.
- Capability control methods: avoiding bad outcomes through limiting what an AI can do. (p129)
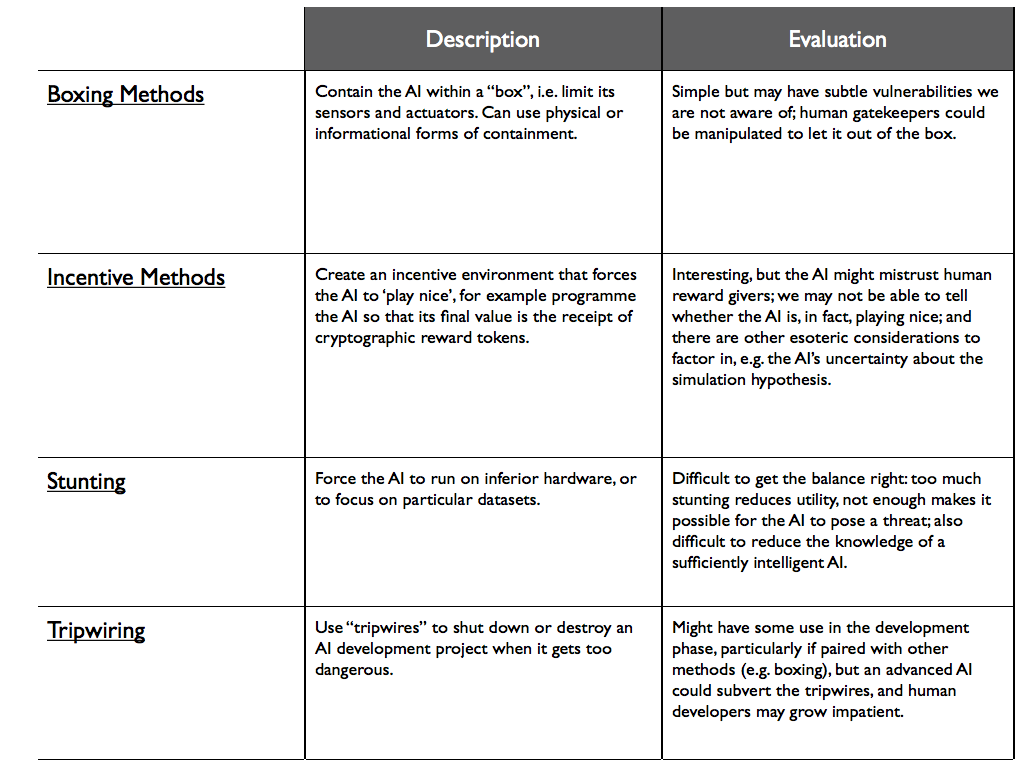
- Some capability control methods:
- Boxing: minimize interaction between the AI and the outside world. Note that the AI must interact with the world to be useful, and that it is hard to eliminate small interactions. (p129)
- Incentive methods: set up the AI's environment such that it is in the AI's interest to cooperate. e.g. a social environment with punishment or social repercussions often achieves this for contemporary agents. One could also design a reward system, perhaps with cryptographic rewards (so that the AI could not wirehead) or heavily discounted rewards (so that long term plans are not worth the short term risk of detection) (p131)
- Anthropic capture: an AI thinks it might be in a simulation, and so tries to behave as will be rewarded by simulators (box 8; p134)
- Stunting: limit the AI's capabilities. This may be hard to do to a degree that avoids danger and is still useful. An option here is to limit the AI's information. A strong AI may infer much from little apparent access to information however. (p135)
- Tripwires: test the system without its knowledge, and shut it down if it crosses some boundary. This might be combined with 'honey pots' to attract undesirable AIs take an action that would reveal them. Tripwires could test behavior, ability, or content. (p137)
Another view
Brian Clegg reviews the book mostly favorably, but isn't convinced that controlling an AI via merely turning it off should be so hard:
I also think a couple of the fundamentals aren’t covered well enough, but pretty much assumed. One is that it would be impossible to contain and restrict such an AI. Although some effort is put into this, I’m not sure there is enough thought put into the basics of ways you can pull the plug manually – if necessary by shutting down the power station that provides the AI with electricity.
...We’ll reprogram the AIs if we are not satisfied with their performance...
...This is an engineering problem. So far as I can tell, AIs have not yet made a decision that its human creators have regretted. If they do (or when they do), then we change their algorithms. If AIs are making decisions that our society, our laws, our moral consensus, or the consumer market, does not approve of, we then should, and will, modify the principles that govern the AI, or create better ones that do make decisions we approve. Of course machines will make “mistakes,” even big mistakes – but so do humans. We keep correcting them. There will be tons of scrutiny on the actions of AI, so the world is watching. However, we don’t have universal consensus on what we find appropriate, so that is where most of the friction about them will come from. As we decide, our AI will decide...
This may be related to his view that AI is unlikely to modify itself (from further down the same page):
3. Reprogramming themselves, on their own, is the least likely of many scenarios.
The great fear pumped up by some, though, is that as AI gain our confidence in making decisions, they will somehow prevent us from altering their decisions. The fear is they lock us out. They go rogue. It is very difficult to imagine how this happens. It seems highly improbable that human engineers would program an AI so that it could not be altered in any way. That is possible, but so impractical. That hobble does not even serve a bad actor. The usual scary scenario is that an AI will reprogram itself on its own to be unalterable by outsiders. This is conjectured to be a selfish move on the AI’s part, but it is unclear how an unalterable program is an advantage to an AI. It would also be an incredible achievement for a gang of human engineers to create a system that could not be hacked. Still it may be possible at some distant time, but it is only one of many possibilities. An AI could just as likely decide on its own to let anyone change it, in open source mode. Or it could decide that it wanted to merge with human will power. Why not? In the only example we have of an introspective self-aware intelligence (hominids), we have found that evolution seems to have designed our minds to not be easily self-reprogrammable. Except for a few yogis, you can’t go in and change your core mental code easily. There seems to be an evolutionary disadvantage to being able to easily muck with your basic operating system, and it is possible that AIs may need the same self-protection. We don’t know. But the possibility they, on their own, decide to lock out their partners (and doctors) is just one of many possibilities, and not necessarily the most probable one.
Notes
1. What do you do with a bad AI once it is under your control?
Note that capability control doesn't necessarily solve much: boxing, stunting and tripwires seem to just stall a superintelligence rather than provide means to safely use one to its full capacity. This leaves the controlled AI to be overtaken by some other unconstrained AI as soon as someone else isn't so careful. In this way, capability control methods seem much like slowing down AI research: helpful in the short term while we find better solutions, but not in itself a solution to the problem.
However this might be too pessimistic. An AI whose capabilities are under control might either be almost as useful as an uncontrolled AI who shares your goals (if interacted with the right way), or at least be helpful in getting to a more stable situation.
Paul Christiano outlines a scheme for safely using an unfriendly AI to solve some kinds of problems. We have both blogged on general methods for getting useful work from adversarial agents, which is related.
2. Cryptographic boxing
Paul Christiano describes a way to stop an AI interacting with the environment using a cryptographic box.
3. Philosophical Disquisitions
Danaher again summarizes the chapter well. Read it if you want a different description of any of the ideas, or to refresh your memory. He also provides a table of the methods presented in this chapter.
4. Some relevant fiction
That Alien Message by Eliezer Yudkowsky
5. Control through social integration
Robin Hanson argues that it matters more that a population of AIs are integrated into our social institutions, and that they keep the peace among themselves through the same institutions we keep the peace among ourselves, than whether they have the right values. He thinks this is why you trust your neighbors, not because you are confident that they have the same values as you. He has several followup posts.
6. More miscellaneous writings on these topics
LessWrong wiki on AI boxing. Armstrong et al on controlling and using an oracle AI. Roman Yampolskiy on 'leakproofing' the singularity. I have not necessarily read these.
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some inspired by Luke Muehlhauser's list, which contains many suggestions related to parts of Superintelligence. These projects could be attempted at various levels of depth.
- Choose any control method and work out the details better. For instance:
- Could one construct a cryptographic box for an untrusted autonomous system?
- Investigate steep temporal discounting as an incentives control method for an untrusted AGI.
- Are there other capability control methods we could add to the list?
- Devise uses for a malicious but constrained AI.
- How much pressure is there likely to be to develop AI which is not controlled?
- If existing AI methods had unexpected progress and were heading for human-level soon, what precautions should we take now?
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about 'motivation selection methods'. To prepare, read “Motivation selection methods” and “Synopsis” from Chapter 9. The discussion will go live at 6pm Pacific time next Monday 15th December. Sign up to be notified here.
48 comments
Comments sorted by top scores.
comment by woodhouse · 2014-12-09T19:16:11.889Z · LW(p) · GW(p)
As a political scientist, I find a shortfall of socio-political realism in many of the otherwise thoughtful and informed comments. Note, for example, the number of commentators who use pronouns including "we," "us," "our." Politics never works that way: It always includes "them," and almost always involves not just my side versus your side, but many sides operating with incomplete information, partially conflicting values, and different standard operating procedures. Related: Note the underlying assumption in many comments that all AI engineers/designers will behave in relatively similar, benign ways. That of course is unrealistic. Rogue nation-states will be able to hire technical talent, and the craziness of arms races occurs even if none of the participants deserves the term "rogue." Third, even within a single country there are multiple, partly competing security agencies, each keeping some secrets from others, each competing for turf, funding, bragging rights. Some are likely to be more careful than others even if they do not deliberately seek to evade boxing or the other controls under discussion. My comments do not exactly invalidate any of the technical and commonsensical insights; but without facing up more directly to variation and competition in international politics and economics, the technically oriented commentators are in danger of spinning fairy tales. (This applies especially to those who suppose it will be relatively easy to control runaway ASI.)
Replies from: TRIZ-Ingenieur↑ comment by TRIZ-Ingenieur · 2014-12-11T01:06:15.141Z · LW(p) · GW(p)
Wistleblowing and self-declarations will not help. Successful FAI development at MIRI will not help either - UFAI will be faster with more impact. An UFAI explosion can be stopped at extremely high costs. Switching off all computers, networks and global blackout for days. Computer hardware worth billions will have to be disposed of. Companies worth trillions will go bankrupt. Global financial depression will last for several years. Millions will die. After this experience the values of "them" and us come closer together and a global regulatory body can be established.
comment by KatjaGrace · 2014-12-09T02:15:52.573Z · LW(p) · GW(p)
Bostrom says that it is hard to get the right level of stunting, such that the AI is useful but not able to recursively self-improve out of your control. (p135-6)
Do you think the fact that AIs will likely have many different capabilities which can all have different levels make it easier or harder to stunt an AI the right amount?
Replies from: diegocaleiro, TRIZ-Ingenieur↑ comment by diegocaleiro · 2014-12-09T04:52:50.841Z · LW(p) · GW(p)
The human mind has many cognitive modules that, though superficially similar and computationally similar (Kurzweil 2013) are still modules that have been evolutionarily optimized - up to a bounded constraint - for distinct functions (Tooby, Cosmides, Buss 2014, Pinker 1995, Minsky 2007).
When we tamper with the human mind with amphetamines or stimulants to make it better by making the entire thing faster, the fact that it has many systems tends to be a hindrance. People end up being motivated about the wrong things, undereating, feeling horny, angry, being mildly autistic etc...
In other words, targeted intervention becomes harder when a mind has many modules, if you goal is to have some of these modules enhanced, but some kept constant.
Stunting a human mind by throwing an anti-psychotic, tranquilizer or a sleep inducer on it, on the other hand, is very effective. The whole brain runs on a digital system of electrochemical communication: the axon's action potential.
So drugs that paralyze or stop human intelligence do so by shutting down the communication system between modules. Seems advisable to run the whole AI with only one, slow system of communication between it's parts.
Contrast this with a stroke:
A stroke destroys some of your modules, but leaves most intact. The consequences may vary from absolute impairment to impossibility of processing symbols into meanings and language
In the second stroke case, within less than two minutes, the human mind came up with a solution to dial a phone.
The takeaway lesson is to make internal communication within the AI slow, and shut it down as a whole, to the extent those are possible.
↑ comment by TRIZ-Ingenieur · 2014-12-10T01:47:16.310Z · LW(p) · GW(p)
The high dimensionality of stunting options makes it easier to find the "right amounts" because we can apply digital stunting measures without need of fine tuning based on context. For some contexts stunting applies, for others not.
Bostrum lists several stunting means which can include a multitude of inner dimensions:
- limit intellectual faculties (per capability/skill)
- limit access to information (per capability/skill)
- limit processing speed (per capability/skill)
- limit memory (per capability/skill)
- limit sensory input channels (stunting/boxing)
- limit output channels (boxing)
Further stunting means are (Please suggest more):
- stunting memorization process (blocking reinforcement cycles)
- forgetting (formatting/partial backup restore)
- memory manipulation
- distraction
Stunting level adjustment is of high complexity and has many input dimensions. Core of the stunting system (e.g. hard wired narrow AI) is a blacklist of taboo topics, skills and knowledge segments. Touching a taboo triggers stunting measures.
The effectors of the stunting system can be divided into three categories:
1. Input related stunting:
Monitoring of all input channels with context analysis for taboo issues. Upon taboo interrupt following stunting options can be applied (examples for: auditory channel, visual channel and data stream):
a) Immediate stunting actions:
- Recognizable channel blocking: beeping out, blurring out, zeroing out.
- Unrecognizable channel censoring: silencing, hiding, removing.
- Channel manipulation: other sound, other image, other data.
- Throttle processing speed close to zero for a limited time (like unconsciousness)
- Generate high priority distracting information.
b) Delayed stunting actions by adding meta information:
- Flag this information chunk as not important.
- Flag this information chunk for special treatment. This could be: no allowance to allocate memory, no allowance to allocate processing power, no allowance to trigger related memories, no allowance for reinforcement memorization, flagged for self-deletion.
- Flag all information of an entire event for amnesia.
2. Processing related stunting:
Monitoring of thoughts by checking taboo relevance. This concept has similarity to tripwires for content monitoring. In education phase taboo by taboo will be presented in simplified manner that the AI can recognize it. After each learning step the taboo representation will be permanently linked to fear and negative reward expectation. If a thought triggers a taboo representation stronger than a certain threshold stunting is initiated and brings all processing steps in connected areas to a temporary halt. A conscious AGI would not feel this stunting because all other thought processes continue unimpaired. One thought out of thousands is lost.
During nighttime reinforcement and tidy up phases all information chunks flagged for deletion will be eradicated or replaced by backup versions or false memories.
3. Output related stunting:
These measures can be only the last resort if all others failed. Output stunting measures are triggered by thought monitoring: (examples for: auditory channel, actuatoric channel and data stream):
- Channel throttling: force pauses, slow down movements, throttle bandwidth.
- Channel blocking: muting, immobility, blocking.
- Channel manipulation: change words, change movements, change data.
Only in extreme contexts full stunting will apply. Whenever the AI is confronted with taboo information it will only get little notion of its existence. It fears acquiring taboo skills.
To prevent an uncontrollable AGI explosion it might be best to prohibit self-improvement. Above stunting scheme allows this with a blacklist like this:
List of Taboos:
- Killing and hurting humans.
- Stealing and lying.
- Perverse literature.
- Fire, weapons, explosives, radioactivity, fusion.
- Computers, IT, chip design, structured programming languages.
- Genetics and nano engineering.
Bostrum is right that such a stunted AI is of limited use. But it can be a safe start along the AI path with later augmentation option. This stunted AGI is so ignorant of advanced technology that it imposes no risk and can be tested in many environments. With humble education, humanist values and motivations it would excel as service robot. Field testing in all conceivable situations will allow to verify and improve motivation and stunting system. In case of a flaw a lot of learning is needed until dangerous skill levels are reached.
Tripwires must terminate the AI in case the stunting system is bypassed.
Although the stunting system is quite complex it allows easy adjustment. The shorter the taboo list the more capabilities the AGI can acquire.
Replies from: Liso↑ comment by Liso · 2014-12-10T04:16:50.476Z · LW(p) · GW(p)
This could be not good mix ->
Our action: 1a) Channel manipulation: other sound, other image, other data & Taboo for AI: lying.
This taboo: "structured programming languages.", could be impossible, because structure understanding and analysing is probably integral part of general intelligence.
She could not reprogram itself in lower level programming language but emulate and improve self in her "memory". (She could not have access to her code segment but could create stronger intelligence in data segment)
Replies from: TRIZ-Ingenieur↑ comment by TRIZ-Ingenieur · 2014-12-11T00:33:42.149Z · LW(p) · GW(p)
The taboo of lying is vital for thought monitoring. This taboo covers only the AGIs internal world representation. Based on its knowledge it never lies. By monitoring input and output channels the stunting system can detect lying and applies appropriate stunting measures.
If the stunting system manipulates input channels, memories or output channels the result to an outside observer will look like lying. The AGI is not capable to tell the truth when the stunting system has removed or manipulated information for safety reasons. The outside observer can check logs of the stunting system if it is vital to him to determine the truth.
Safe path to superintelligence with slow take-off by prohibiting self-improvement:
The taboo to learn structured programming languages is totally independent from capabilities to understand and analyse structured programs. In principle the AGI could learn this. The stunting system censors all input channels that the AGI never observes a single line of program code. The AGI could develop a new type of structured programming language from scratch. As soon as the stunting system observes structured code fragments in memory the section responsible for this will be stunted. The generated code can be deleted or manipulated. Either way the AGI experiences that these frightful structured programming languages are complicated and come with set-back after set-back.
If this AGI breaks out with free internet access it has no idea of our IT infrastructure and how to infiltrate it. If the AGI is moderately superintelligent it will need several weeks for learning hacking skills.
Self-Improvement with safeguards: If AGI architecture design and optimization uses new forms of representations that are totally unlike structured programming languages we could teach self-improvement without removing the programming taboo. Code and architecture generated in this self-improvement process is incompatible to existing IT systems. If several AGIs evolve from similar starting points diversification will rise from generation to generation.
comment by KatjaGrace · 2014-12-09T02:11:09.824Z · LW(p) · GW(p)
Are there solutions to the control problem other than capability control and motivation selection?
Replies from: DanielFilan, TRIZ-Ingenieur, Liso, diegocaleiro, solipsist↑ comment by DanielFilan · 2020-08-14T01:31:54.470Z · LW(p) · GW(p)
When an agent does something, it does so because it has some goal, and has determined that the thing it does will achieve the goal. Therefore, if you want to change what an agent does, you either change the goal (motivation selection), or change its method of determining stuff (capability control)*. Alternatively, you could make something that isn't like an agent but still has really good cognitive capabilities. Perhaps this would count as 'capability control' relative to what I see as the book's implicit assumption that smart things are agents.
[*] Note that this argument allows that the desired type of capability control would be to increase capability, perhaps so that the agent realises that doing what you hope it will do is actually a great idea.
Replies from: DanielFilan↑ comment by DanielFilan · 2020-08-14T16:03:49.591Z · LW(p) · GW(p)
I suppose the other alternative is that you don't change the goal in the agent, but rather change the world in a way that changes which actions achieve the goal, i.e. incentive methods.
↑ comment by TRIZ-Ingenieur · 2014-12-10T02:35:54.237Z · LW(p) · GW(p)
Fear is one of the oldest driving forces to keep away from dangers. Fear is different from negative motivation. Motivation and goals are attractors. Fears, bad conscience and prohibitions are repellors. The repellent drives could count as third column to the solution of the control problem.
↑ comment by Liso · 2014-12-09T21:40:32.125Z · LW(p) · GW(p)
Is "transcendence" third possibility? I mean if we realize that human values are not best and we retire and resign to control.
(I am not sure if it is not motivation selection path - difference is subtle)
BTW. if you are thinking about partnership - are you thinking how to control your partner?
↑ comment by diegocaleiro · 2014-12-09T04:28:50.320Z · LW(p) · GW(p)
In Dr Strangelove there is a doomsday machine. A tripwire that would destroy the world should the Soviet Union decide to strike.
Some form of automated self-destruction implement, though a subset of capability control, has seldom been discussed. But see the Oracle AI paper by Stuart Armstrong for some versions of it.
↑ comment by solipsist · 2014-12-09T02:32:43.985Z · LW(p) · GW(p)
Basic question: what fails with breakpoints at incremental goal boundaries? Program the AI to halt and await further instructions as soon as it becomes 99.95% sure that it has optimized objective X by at least 1%. The programmers can see that if the optimizations are going in an undesirable direction while limiting the damage.
I don't see a reason for the AI to subvert subgoal break points. True, the AI will realize that it will later be requested to optimize further, and it can make its future life easier by thinking ahead and . But the AI is not programmed to make its future life easier -- it's programmed to greedily optimize the next step. If optimization is relatively continuous, arbiltrarilly small steps can result in arbiltrarilly small (and safe) changes to the world.
Replies from: solipsist, Luke_A_Somers, William_S↑ comment by Luke_A_Somers · 2014-12-09T14:35:31.677Z · LW(p) · GW(p)
But the AI is not programmed to make its future life easier -- it's programmed to greedily optimize the next step.
Why do you think that?
Replies from: solipsist↑ comment by solipsist · 2014-12-09T19:16:43.676Z · LW(p) · GW(p)
Because that program is the premise of my question. If an AI is not given any open-ended long-term goals, only small incremental ones, can it not be made arbiltrarilly safe?
Replies from: TheOtherDave, Luke_A_Somers↑ comment by TheOtherDave · 2014-12-09T19:58:15.098Z · LW(p) · GW(p)
So, this strikes me as a special case of "one way to make an optimizer safe is to ensure it isn't very powerful," which is absolutely true. This has opportunity costs, of course.
That said... the wording Program the AI to halt and await further instructions as soon as it becomes 99.95% sure that it has optimized objective X by at least 1% seems to suggest that X is what the system is optimizing for, and the halt-and-await-instructions is an obstacle in its source code that impedes progress towards optimizing for X. In which case I'd expect a sufficiently powerful optimizing system to bypass that obstacle somehow.
I think what you mean is more "program the AI to optimize for the goal of achieving >99.95 confidence of >1% increase in X" And then hope there isn't an unbounded implicit term in there somewhere (e.g., of X measured in what system?).
Replies from: solipsist↑ comment by solipsist · 2014-12-09T23:31:15.881Z · LW(p) · GW(p)
Yes, I mean your second interpretation. The proposal is basically a hill climbing algorithm, with a human step in the for loop. The AGI to computes a direction (an action with a small effect on the world); humans evaluate the action; humans either implement the action or tweak the AI; repeat. On every iteration, AGI is instructed to optimize only for the next step
I agree greedy algorithms aren't incredibly powerful, but I'm more worried about safety. Evolution is also a greedy algorithm and it managed to create humans. Would using an AGI to hill climb destroy the world? If so, why?
Replies from: William_S↑ comment by William_S · 2014-12-10T03:01:22.359Z · LW(p) · GW(p)
Suppose that you have a simple, benign solution that works only up to Y% optimization (just make the paperclips), and a hard, non-benign solution that is optimal above that point (take over the world, then make paperclips). The AI naively follows the benign strategy, and does not look too hard for alternatives up to Y%. All manual checks below Y% of optimization pass. But Y ends up as a number that falls between two of your numerical checkpoints. So, you observe all checkpoints passing below Y% optimization, until suddenly the AI switches to the non-benign solution between checkpoints, executes it to reach the next checkpoint, but has already caused damage.
↑ comment by Luke_A_Somers · 2014-12-09T21:12:20.644Z · LW(p) · GW(p)
I see. I thought you meant take some other AI and apply breakpoints at incremental goal boundaries, and reset its goal system at that time.
I don't think this would work. Eventually it's going to reach a local maximum and have to sit down and think much harder to do valley-crossing (this will likely come at the end of a sequence of longer and longer optimization times finding this peak, so run-time won't be surprising). Then it is forced to do the long-term-make-life-easier-'evil-things'.
↑ comment by William_S · 2014-12-09T03:27:15.202Z · LW(p) · GW(p)
This has some problems associated with stunting. Adding humans in the loop with this frequency of oversight will slow things down, whatever happens. The AI would also have fewer problem solving strategies open to it - that is if doesn't care about thinking ahead to , it also won't think ahead to .
The programmers also have to make sure that they inspect not only the output of the AI at this stage, but the strategies it is considering implementing. Otherwise, it's possible that there is a sudden transition where one strategy only works up until a certain point, then another more general strategy takes over.
comment by diegocaleiro · 2014-12-09T04:17:06.954Z · LW(p) · GW(p)
When I'm faced with problems in which the principal agent problem is present, my take is usually that one should: 1) Pick three or more different metrics that correlate with what you want to measure: using the soviet classic example of a needle factory these could be a) Number of needles produced b) Weight of needles produced c) Average similarity between actual needle design and ideal needle. Then 2) Every time step where you test, you start by choosing one of the correlates at random, and then use that one to measure production.
This seems simple enough for soviet companies. You are still stuck with them trying to optimize those three metrics at the same time without optimizing production, but the more dimensions and degrees of orthogonality between them you find, the more you can be confident your system will be hard to cheat.
How do you think this would not work for AI?
Replies from: Vaniver, 9eB1↑ comment by Vaniver · 2014-12-10T01:56:24.661Z · LW(p) · GW(p)
Then 2) Every time step where you test, you start by choosing one of the correlates at random, and then use that one to measure production.
This is almost equivalent to having a linear function where you add the three metrics together. (It's worse because it adds noise instead of averaging out noise.) Do you think adding the three together makes for a good metric, or might an optimization of that function fail because it makes crazy tradeoffs on an unconsidered dimension?
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-12-11T00:07:22.104Z · LW(p) · GW(p)
It may be too costly to detect (in proportion to the cost of arbitrarily deciding how to measure one against the other).
↑ comment by 9eB1 · 2014-12-09T06:04:41.163Z · LW(p) · GW(p)
This is a surprisingly brilliant idea, which should definitely have a name. For humans, part of the benefit of this is that it appeals to risk aversion, so people wouldn't want to completely write off one of the scenarios. It also makes it so complex to analyze, that many people would simply fall back to "doing the right thing" naturally. I could definitely foresee benefits by, for example, randomizing whether members of a team are going to be judged based on individual performance or team performance.
I'm not totally sure it would work as well for AIs, which would naturally be trying to optimize in the gaps much more than a human would, and would potentially be less risk averse than a human.
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-12-09T07:24:01.821Z · LW(p) · GW(p)
Let's name it:
Hidden Agency Solution
Caleiro Agency Conjecture
Principal agent blind spot
Cal-agency
Stochastic principal agency solution.
(wow, this naming thing is hard and awfully awkward, whether I'm optimizing for mnemonics or for fame - is there any other thing to optimize for here?)
Replies from: Halfwitz↑ comment by Halfwitz · 2014-12-10T01:10:25.545Z · LW(p) · GW(p)
Fuzzy metrics?
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-12-11T00:10:29.767Z · LW(p) · GW(p)
Doesn't refer to Principal Agency.
comment by KatjaGrace · 2014-12-09T02:19:39.969Z · LW(p) · GW(p)
Did you change your mind about anything as a result of this week's reading?
comment by SteveG · 2014-12-09T13:53:48.340Z · LW(p) · GW(p)
Stunting, tripwires, and designing limitations on the AI's goals and behaviors may be very powerful tools.
We are having a hard time judging how powerful they are because we do not have the actual schemes for doing so in front of us to judge.
Until engineering specifications for these approaches start to be available, the jury will still be out.
We certainly can imagine creating a powerful but stripped-down AGI component without all possible functionality. We can also conceive of ways to test it.
Just to get the ball rolling, consider running it one hundred times more slowly than a human brain while it was being tested, debugged and fed various kinds of data.
Consider running it in a specially-designed game world during testing.
We would be able to make some inferences about how likely the system would be to break the law or otherwise become threatening in real life if it did so in in the game world.
If it became threatening under test conditions, that increases the chance that it would become threatening in real-life. Re-design and repeat the tests.
On the other hand, if it did not become threatening under some test conditions, that alone is not enough to prove that it is time to use it in the real-world. So, the developers continue to test and analyze.
The trick, then, is creating a risk assessment process to check the safety of heavily tested AGI components which passed all tests.
The stunting and tripwires would have to go through a validation process before they could be verified as sufficient to permit safe testing.
Just as a heuristic, perhaps we are looking for probabilities of danger below one in a million or one in a trillion.
Or, perhaps we are comparing this probability with the probability of a different catastrophic or existential risk which the AGI can help to mitigate. However, building an AGI in response to some other emergency, the way we built the atomic bomb, seems like a recipe for trouble.
Specifically, the possibility that the AGI will be able to lengthen the life or permit upload of a small group of important people IS NOT enough. Saving the life of The President or an important corporate executive is not enough reason to create AGI.
The development team only escalates to the next level of testing and utilization when danger probabilities falls sufficiently.
Furthermore, the development team is NOT responsible for the risk assessment. That job belongs to another team(s) with a designed process for providing oversight.
If the probability of danger never falls enough, the AGI development team is not allowed to continue.
Right now, such danger probabilities are too high. However, trying to design stunting and tripwire schemes wlll provide infromation that allows us to update the probabilities.
comment by KatjaGrace · 2014-12-09T02:19:24.935Z · LW(p) · GW(p)
How would you like this reading group to be different in future weeks?
comment by KatjaGrace · 2014-12-09T02:19:09.488Z · LW(p) · GW(p)
Was there anything in this week's reading that you would like someone to explain better?
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-12-09T04:36:04.330Z · LW(p) · GW(p)
Though many of the hardest working Friendly AI thinkers take Bostrom's Simulation Argument seriously when cognitively talking about it, I've seen surprisingly little discussion of what would FAI and UFAI do if they believed, for instance with 25% 50% and 75% probability that they were in a Simulation. Notice that the Simulation Argument, from the perspective of an AI, has much more strength than a human version, because:
1) The AI knows it is implemented in substrate independent code - humans have uncertainty over the origin of their consciousness, and are not sure they could be being simulated.
2) The condition of "being able to create a simulation" is much closer to the world of the AI than to ours. Maybe the AI herself knows how to make one already, or knows where to look to create one in three weeks.
3) It also has privileged access to information about whether once given the capability to do so, if Worlds would actually create simulations with many beings - this is either because it can create a simulation itself, and understands it's own motivation, or because it has the Strategy superpower, and understands deeply whether a ban on simulations would happen or not.
More generally, I would like to see more people writing about how AGI's, good or evil, would behave in a Simulation.
comment by KatjaGrace · 2014-12-09T02:16:12.109Z · LW(p) · GW(p)
What did you find most interesting in this section?
Replies from: yates9↑ comment by yates9 · 2014-12-09T11:27:54.343Z · LW(p) · GW(p)
The biggest issue with control is that if we assume superintelligence a priori then it would be able to make the best decisions to evade detection, to avoid being caught, to even appear stupid enough that humans would not be very worried. I think it would be impossible to guarantee any kind of control given we don't really know what intelligence even is. It is not impossible to imagine that it already exists as a substrate of the communication/financial/bureaucratic network we have created.
I find most interesting that we ignore that even the dumbest of super intelligences would start from having a very clear understanding of all the content on this section.
Replies from: diegocaleiro, timeholmes↑ comment by diegocaleiro · 2014-12-11T01:53:53.505Z · LW(p) · GW(p)
Notice "a priori" usually means something else altogether.
What you mean is closer to "by definition".
Finally, given your premise that we do not know what intelligence is (thus don't know the Super version of it either) it's unclear where this clear thread-understanding ability stems from.
↑ comment by timeholmes · 2014-12-13T18:13:56.052Z · LW(p) · GW(p)
Absolutely! It's helpful to remember we are talking about an intelligence that is comparable to our own. (The great danger only arises with that proximity.) So if you would not feel comfortable with the AI listening in on this conversation (and yes it will do its research, including going back to find this page), you have not understood the problem. The only safety features that will be good enough are those designed with the full knowledge that the AI is sitting at the table with us, having heard every word. That requires a pretty clever answer and clever is where the AI excels!
Furthermore this will be the luxury problem, after humanity has cracked the nut of mutual agreement on our approach to AI. That's the only way to avoid simply succumbing to infighting; meaning whomever's first to give the AI what it wants "wins", (perhaps by being last in line to be sacrificed).
comment by William_S · 2014-12-10T23:58:44.329Z · LW(p) · GW(p)
Capability control methods, particularly boxing and stunting, run the risk of creating a capability overhang: a gap in optimization power between the controlled AI and an uncontrolled version. This capability overhang creates an additional external hazard: that another AI team, hearing of the first AI team's success will believe that less capability control is required than used by the initial team (possibly due to different assumptions, or motivated cognition). They will want to create a less controlled version of the AI to attempt to gain greater optimization power and a boost over their rivals. This continues until someone crosses the line to an unsafe AI.
This isn't a problem if you assume all AI researchers agree on all substantial aspects of the control problem or forced to coordinate. I'm not convinced this is a likely outcome.
Does this model make sense?
comment by diegocaleiro · 2014-12-09T04:25:38.707Z · LW(p) · GW(p)
Besides the stochastic solution I offered in my other comment, we could have some system in place where the AI was uncertain about who their principal agent is among some set. This could be defined last minute, or could be fully undefined.
In Paul Boxing for instance this would be running the counterfactuals on a few mildly distinct scenarios, and maximizing the number your principal agent gives you, but now knowing which of the agents will provide you with the number.
(In case your creativity is running short of examples of how to vary a counterfactual with a person in a room with a computer, I would suggest varying some of the unknown or indeterminate metaphysical properties. You could run the same physical scenario, but in one simulation proximity in possible worlds is distributed in way A, in other B etc... in one scenario the continuum hypothesis is true, in another personal identity is a sorites problem, etc... You don't need to vary the room itself, just some properties that supervene on physics in that counterfactual)
If the idea that an AI would never be uncertain who their principal agent was has crossed your mind "because an AI is epistemically superior", consider the scenario in which the same thing that causes you to experience many worlds as probabilities also makes the AI be located in single worlds. Then it already has uncertainty over who it's principal agent would be, since each instance of the AI would be in a different branch.
(wow, the above paragraph was awful writing... growth mindset... EDIT: If you can't conceive of an AI being uncertain over who their principal agent is, notice that, like you, it is possible that an AI is a macroscopic object inhabiting part, but not the totality of, the wavefunction. The AI therefore would also have the same sort of uncertainty you have when performing a radioactive decay experiment. In other words, any AI that lives in cross sections of many-worlds in the same way we humans do would have similar reasons to not know in which of many epistemically equivalent worlds it is inhabiting. It would already be uncertain about it's principal agent because of that, if nothing else. )
comment by KatjaGrace · 2014-12-09T02:12:33.867Z · LW(p) · GW(p)
Do you think the first principal agent problem and the second are similar enough that it is useful to associate them with each other?
Replies from: DanielFilan↑ comment by DanielFilan · 2020-08-14T01:34:12.737Z · LW(p) · GW(p)
See Hadfield-Menell and Hadfield on Incomplete Contracting and AI Alignment, that attempts to use insights from the first to help with the second.
comment by KatjaGrace · 2014-12-09T02:11:59.343Z · LW(p) · GW(p)
Do you agree with Bostrom or the commentators above on the difficulty of turning off or modifying an undesirable AI?
comment by KatjaGrace · 2014-12-09T02:11:21.938Z · LW(p) · GW(p)
Do you agree with everything in this section?
comment by TRIZ-Ingenieur · 2014-12-09T07:24:11.994Z · LW(p) · GW(p)
Boxing and stunting combined can be very effective when an easy controllable weak AI gatekeeper restricts information that is allowed to get into the box. If we manage to educate an AI with humanistic experiences and values without any knowledge of classical programming languages, OSes and hardware engineering we minimize the risk of escaping. For self improvement we could teach how to influence and improve cognitive systems like its own. This system should use significantly different structures dissimilar to any known sequential programming language.
The growing AI will have no idea how our IT infrastructure works and even less how to manipulate it.
comment by solipsist · 2014-12-09T02:31:54.578Z · LW(p) · GW(p)
Basic question: what fails with breakpoints at incremental goal boundaries? Program the AI to halt and await further instructions as soon as it becomes 99.95% sure that it has optimized objective X by at least 1%. The programmers can see that if the optimizations are going in an undesirable direction while limiting the damage.
I don't see a reason for the AI to subvert subgoal break points. True, the AI will realize that it will later be requested to optimize further, and it can make its future life easier by thinking ahead and . But the AI is not programmed to make its future life easier -- it's programmed to greedily optimize the next step. If optimization is relatively continuous, arbiltrarilly small steps can result in arbiltrarilly small (and safe) changes to the world.
comment by almostvoid · 2014-12-09T08:00:40.901Z · LW(p) · GW(p)
I think the -intelligence- in the -artificial- is overrated. It doesn't need anything per se to control it. All these scenario's pretend that -it- has volition which it has not. As long as that is the case all this -re:above- is what the Germans call Spiegelfechterei- fencing with a mirror image. Esp social integration. That is so Neanderthal. I rest my case. And my mind.