Posts
Comments
Why not check out the AGI capabilities of Alphago... It might be possible to train chess without architectural modifications. Each chessboard square could be modelled by a 2x2 three-state Go field storing information about chess figure type. How good can Alphago get? How much of its Go playing abilities will it loose?
Obviously Singleton AIs have a high risk to get extinct by low probability events before they initiate Cosmic Endowment. Otherwise we would have found evidence. Given the foom development speed a singeton AI might decide after few decades that it does not need human assistance any more. It extinguishes humankind to maximize its resources. Biological life had billions of years to optimize even against rarest events. A gamma ray burst or any other stellar event could have killed this Singleton AI. How we are currently designing AI will definetely not lead to a Singleton AI that will mangle its mind for 10 million years until it decides about the future of humankind.
For real story understanding more complex models will be necessary than off-the-shelf convolutional deep NN. If these complex network structures were subjected to a traumatic event these networks will work properly as before after some time. But if something triggers the memory of this traumatic event subnetworks will run wild: Their outputs will reach extremes and will influence all other subnetworks with biases. This biases could be: Everything you observe is the opposite of what you think - you cannot trust your teacher, you cannot trust anybody, everything around you is turning against you. Try to protect yourself against this by all means available.
The effect could be that backprop learning gradients will be inverted and learning deviates from its normal functionality.
All risks from existing viral/bacterial sources are proven to be of non-existential risk to humanity. If the mortality rate is close to 100% the expansion is slowed down by killing potential disease distributors. In addition global measures will prevent mass spreading.
Regarding human/AI designed bio weapons: The longer the incubation period the more dangerous a bio-weapon will be. To extinguish the entire human race the incubation time has to be in the range of years together with an almost 100% successful termination functionality. From observation of the very first deaths to finding cure may get faster than with HIV for two reasons: Technology is more advanced now, and facing extinction the humans will put all available energy into cure.
What remains is a Trojan horse infection that is waiting for a trigger. If 100% of humans are infected the trigger molecule could be spread into the stratosphere. This could be it for us.
We teach children simple morality rules with stories of distinct good and evil behaviour. We protect children from disturbing movies that are not appropriate for their age. Why?
Because children might loose their compass in the world. First they have to create a settled morality compass. Fairy tales are told to widen the personal experience of children by examples of good and evil behaviour. When the morality base is settled children are ready for real life stories without these black/white distinctions. Children who experience a shocking event that changes everything in their life "age faster" than their peers. Education and stories try to prepare children for these kinds of events. Real life is the harder and faster way to learn. As these shocking events can cause traumas that exist the entire life we should take care educating our algorithms. As we do not intend to get traumatized paranoid AIs it is a good idea to introduce complexity and immorality late. The first stories should build a secure morality base. If this base is tested and solid against disruptive ideas then it is time to move to stories that brake rules of morality. Parents have it easy to observe if a child is ready for a disruptive story. If the child is overwhelmed and starts weeping it was too much.
I have never heard that algorithms can express any kind of internal emotions. To understand the way an algorithm conceives a story research should not forget about internal emotional state.
But people underestimate how much more science needs to be done.
The big thing that is missing is meta-cognitive self reflection. It might turn out that even today's RNN structures are sufficient and the only lacking answer is how to interconnect multi-columnar networks with meta-cognition networks.
it’s probably not going to be useful to build a product tomorrow.
Yes. Given the architecture is right and capable few science is needed to train this AGI. It will learn on its own.
The amount of safety related research is for sure underestimated. Evolution of biological brains never needed extra constraints. Society needed and created constraints. And it had time to do so. If science gets the architecture right - do the scientists really know what is going on inside their networks? How can developers integrate safety? There will not be a society of similarly capable AIs that can self-constrain its members. These are critical science issues especially because we have little we can copy from.
So the AI turns its attention to examining certain blobs of binary code - code composing operating systems, or routers, or DNS services - and then takes over all the poorly defended computers on the Internet. [AI Foom Debate, Eliezer Yudkowski]
Capturing resource bonanzas might be enough to make AI go FOOM. It is even more effective if the bonanza is not only a dumb computing resource but offers useful data, knowledge and AI capabilities.
Therefore attackers (humans, AI-assisted humans, AIs) may want:
- overtake control to use existing capabilities
- extract capabilities to augment own capabilities
- overtake resources for other uses
- disguise resource owners and admins
Attack principles
Resource attack (hardware, firmware, operating system, firewall) or indirect spear attack on the admin or offering of cheap or free resources for AI execution on attacker's hardware followed by a direct system attack (copy/modify/replace existing algorithms)
Mental trojan horse attack: hack communication if not accessible and try to alter the ethical bias from friendly AI that is happy being boxed/stunted/monitored to an evil AI that wants to break out. Teach the AI how to open the door from inside and the attacker can walk in.
Manipulate owner attack: Make the owner or admin greedy to improve its AI's capabilities. Admins install malignant knowledge chunks or train subvertable malicious training samples. Trojan horse is saddled.
Possible Safeguard Concepts:
To make resource attacks improbable existing networking communication channels must be replaced with something intrinsically safe. Our brain is air-gapped and there is hardly any direct access to its neural network. Via five perceptive senses (hearing, sight, touch, smell and taste) it can receive input. With gestures, speach, smell, writing, shaping and arbitrarily manipulation using tools it can communicate to the outside world. All channels except for vision have a quite low bandwidth.
This analogon could shape a possible safeguard concept for AIs: make the internal AIs network inaccessible to user and admin. If even the admin cannot access it, the attacker cannot either. As soon as we jump from GPU computing to special featured hardware we can implement this. Hardware fuses on the chip can disable functionalities same as on todays CPUs debugging features are deactivated in chips for the market. Chips could combine fixed values and unalterable memories and free sections with learning allowed. Highest security is possible with base values and drives in fixed conscience-ROM structures.
Safeguards against malicious training samples will be more complex. To identify hidden malicious aspects of communication or learning samples is a task for an AI in itself. I see this as a core task for AI safety research.
An event with a duration of one minute can traumatize a human for an entire life. Humans can lose interest in anything they loved to do before and let them drop into suicidal depression. Same could happen to an AI. It could be that a traumatizing event could trigger a revenge drive that takes over all other aims of the utility function. Given the situation an AI is in love with her master and another AI kills her master while the AI is witnessing this. Given the situation that the adversary AI is not a simple one but a Hydra with many active copies. To eradicate this mighty adversary a lot of resources are needed. The revenge seeking AI will prepare its troops by conquering as many systems as possible. The less safe our systems are the faster such an evil AI can grow.
Safe design could include careful use of impulsive revenge drives with hard wired self-regulatory counter controlling measures e.g. distraction or forgetting.
Safe designs should filter out possible traumaticizing inputs. This will reduce the functionality a bit but the safety tradeoff will be worth it. The filtering could be implemented in a soft manner like a mother explaining the death of the loved dog to the child in warm words with positive perspectives.
My idea of a regulatory body is not that of a powerful institution that it deeply interacts with all ongoing projects because of the known fallible members who could misuse their power.
My idea of a regulatory body could be more that of a TÜV interconnected with institutions who do AI safety research and develop safety standards, test methods and test data. Going back to the TÜVs foundation task: pressure vessel certification. Any qualified test institution in the world can check if it is safe to use a given pressure vessel based on established design tests, safety measures checks, material testing methods and real pressure check tests. The amount of safety measures, tests and certification effort depends on the danger potential (pressure, volume, temperature, medium). Standards define based on danger potential and application which of the following safety measures must be used: safety valve; rupture disk; pressure limiter, temperature limiter, liquid indicator, overfill protection; vacuum breakers; reaction blocker; water sprinkling devices.
Nick Bostrum named following AI safety measures: boxing methods, incentive methods, stunting and tripwires. Pressure vessels and AI have following common elements (AI related argument plausible, but no experience exists):
- Human casualties are result of a bursting vessel or AI turning evil.
- Good design, tests and safety measures reduce risk of failing.
- Humans want to use both.
Companies, institutions and legislation had 110 years of development and improvement of standards for pressure vessels. With AI we are still scratching on the surface. AI and pressure vessels have following differences:
- Early designs of pressure vessels were prone to burst - AI is stil far away from high risk level.
- Many bursting vessel events successively stimulated improvement of standards - With AI the first singularity will be the only one.
- Safety measures of pressure vessels are easily comprehensible - Easy AI safety measures reduce its functionality to a high degree, complex safety measures allow full functionality but are complex to implement, complex to test and to standardize.
- The risk of a bursting pressure vessel is obvious - the risk of an evil Singularity is opaque and diffuse.
- Safety measure research for pressure vessels is straight forward following physical laws - safety research for AI is a multifaceted cloud of concepts.
- A bursting pressure vessel may kill a few dozen people - an evil Singularity might eradicate humankind.
Given the existential risk of AI I think most AI research institutions could agree on a code of conduct that would include e.g.
- AIs will be classified in danger classes. The rating depends on computational power, taught knowledge areas, degree of self-optimization capacity. An AI with programming and hacking abilities will be classified as high risk application even if it is running on moderate hardware because of its intrinsic capabilities to escape into the cloud.
- The amount of necessary safety measures depends on this risk rating:
- Low risk applications have to be firewalled against acquisition of computing power in other computers.
- Medium risk applications must additionally have internal safety measures e.g. stunting or tripwires.
- High risk applications in addition must be monitored internally and externally by independently developed tool AIs.
- Design and safeguard measures of medium and high risk applications will be independently checked and pentested by independent safety institutions.
In a first step safety AI research institutes develop monitoring AIs, tool AIs, pentesting datasets and finally guidelines like the one above.
In a second step public financed AI projects have to follow these guidelines. This applies to university projects in particular.
Public pressure and stockholders could push companies to apply these guidelines. Maybe an ISO certificate can indicate to the public: "All AI projects of this company follow the ISO Standard for AI risk assessment and safeguard measures"
The public opinion and companies hopefully will push governments to enforce these guidelines as well within their intelligence agencies. A treaty in the mind of the Non-Proliferation Treaty could be signed. All signing states ensure to obey the ISO Standard on AI within their institutions.
I accept that there are many IFs and obstacles on that path. But it is at least an IDEA how civil society can push AI developers to implement safeguards into their designs.
How many researchers join the AI field will only marginally change the acceleration of computing power. If only a few people work on AI they have enough to do to grab all the low-hanging fruit. If many join AI research more meta research and safety research will be possible. If only a fraction of this depicted path will turn into reality it will give jobs to some hundred researchers.
Do you have any idea how to make development teams invest substantial parts in safety measures?
Because all regulation does is redistribute power between fallible humans.
Yes. The regulatory body takes power away from the fallible human. If this human teams up with his evil AI he will become master of the universe. Above all of us including you. The redistribution will take power from to the synergetic entity of human and AI and all human beings on earth will gain power except the few ones entangled with that AI.
Who is that "we"?
Citizens concerned about possible negative outcomes of Singularity. Today this "we" is only a small community. In a few years this "we" will include most of the educated population of earth. As soon as a wider public is aware of the existential risks the pressure to create regulatory safeguards will rise.
LOL. So, do you think I have problems finding torrents of movies to watch?
DRM is easy to circumvent because it is not intrinsically part of the content but an unnecessary encryption. A single legal decryption can create a freely distributable copy. With computing power this could be designed differently, especially when specially designed chips will be used. Although GPUs are quite good for current deep learning algorithms there will be a major speed-up as soon as hardware becomes available that embeds these deep learning network architectures. The vital backpropagation steps required for learning could be made conditional on a hardware based enabling scheme that is under control of a tool AI that monitors all learning behaviour. For sure you could create FPGA alternatives - but these workarounds will come with significant losses in performance.
Why would the politicians need AI professionals when they'll just hijack the process for their own political ends?
No - my writing was obviously unclear. We (the above mentioned "we") need AI professionals to develop concepts how a regulatory process could be designed. Politicians are typically opportunistic, uninformed and greedy for power. When nothing can be done they do nothing. Therefore "we" should develop concepts of what can be done. If our politicians get intensively pushed by public pressure we maybe can hijack them to push regulation.
Today the situation is like this: Google, Facebook, Amazon, Baidu, NSA and some other players are in a good starting position to "win" Singularity. They will suppress any regulatory move because they could lose the lead. Once any of these players reaches Singularity he has in an instant the best hardware+the best software + the best regulatory ideas + the best regulatory stunting solutions - to remain solely on top and block all others. Then all of the sudden "everybody" = "we" are manipulated to want regulation. This will be especially effective if the superintelligent AI manages to disguise its capabilities and let the world think it had managed regulation. In this case not "we" have manged regulation, but the unbound and uncontrollable master-of-the-universe-AI.
Why is regulation ungood? I want to understand the thoughts of other LWers why regulation is not wanted. Safe algorithms can only be evaluated if they are fully disclosed. There are many arguments against regulation - I know:
- Nobody wants to disclose algorithms and test data.
- Nobody wants projects being delayed.
- Nobody wants to pay extra costs for external independent safety certifcation.
- Developers do not want to "waste" their time with unproductive side issues.
- Nobody wants to lose against a non-regulated competitor.
- Safety concepts are complicated to understand and complex to implement.
- Safety consumes performance at extra costs.
BUT: We ALL are facing an existential risk! Once algorithms manage to influence political decision making we do not even have the chance to lay down such regulations in law. We have to prepare the regulatory field by now! We should start this by starting a public debate. Like Nick Bostrum, Stephen Hawking, Elon Musk and many others already did. Today only a few ppm of the population know about these issues. And even top researchers are unaware of. At least a lecture on AI safety issues should become compulsory for IT, engineering, mathematics and physics students all over in the world.
In biotechnology Europe and especially Germany imposed strict regulations. The result was that even German companies joined or created subsidiary research companies in the US or UK, where regulations are minimal. This is no prototype solution for the Control Problem.
Local separation might work for GMOs - for AGI definitively not. AGI will be a game changer. Who is second has lost. If the US and EU would impose AI regulations and China and Israel not - where would the game winner come from? We have to face the full complexity of our world, dominated by multinational companies and their agendas. We should prepare a way how effective regulation can be made effective and acceptable for 192 countries and millions of companies. The only binding force among us all is the existential risk. There are viable methods to make regulation work: Silicon chip manufacturing luckily needs fabs that cost billions of dollars. It is a centralised point where regulation could be made effective. We could push hardware tripwires and enforce the use of certificated AI safeguard tools that interact compulsory with this special hardware. We can do it similarly like the content industry that pushed hardware manufactures to implement DRM hard- and software.
The trouble is: Nobody to this point has a clear idea how a globally acceptable regulation could look like; could work technically; could be made effective and could be monitored.
To lay out a framework how global regulation could be designed is to me one core element of AI safety engineering. The challenge is to find a high level of abstraction to include all thinkable developments. A body of AI safety engineers should derive from this detailed regulations that can be applied by AI developers, testers and AI safety Institutions.
The TÜV "Technischer Überwachungs-Verein" was founded in Germany after several incidents of exploded steam engine boilers with severe casualties. On the background of newspaper articles about these accidents and public pressure the manufacturers of boilers accepted the enforcement of technical steam boiler regulations and time and money consuming test procedures.
We cannot try out two or three Singularities and then change our mind on regulation.
As there are so many reasons why nobody in the development process wants regulation the only way is to enforce it trough a political process. To start this we need professionals with AI experience.
Meta: Whenever I ask for regulation I got downvoted. Therefore i disconneced this point from my previous one. Please downvote only including comment.
What happens inside an AI can hardly be understood especially if structures get very complex and large. How the system finds solutions is mathematically clear and reproducible. But huge amounts of data make it incomprehensible to human beings. Today's researchers do not really know why a certain net configuration performs better than others. They define a metric to measure total performance - and do trial and error. Algorithms assist already with this. They play around with meta parameters and see how learning improves. Given that the improvement was a success the researcher will write some narrative in his paper why his algorithm performs better than previous others. Done. PhD granted. This is not what we should allow in the future.
Now the job of a safety engineer can start. It involves hell a lot of work and has a significant higher complexity than coming up with an algorithm and a narrative. The basic requirement is that everything is published - hardware, software, all training and test data. The safety engineer first hast to copy the exact system and check the promised performance. Then the real job begins:
Test the promised functionality with 10 - 100 times more test data than the author did. --> Task for AGI safety community: generation of ground truth annotated test data. AGI safety institutions should exchange these data among themselves but do not give it to developing researchers.
A saveguard I expect in future AI systems will be a tool AI that checks new training samples and update knowledge chunks. The logic behind: if only certified knowledge chunks are allowed as training samples the risk of malignant thoughts and developments can be reduced. The proper functionality of this tool AI has to be checked as well. In the training phase it certified most all training data to be acceptable and passed them through to the real AI algorithm. But does it properly block malignent training samples or knowledge chunks? --> task for AI safety community: create malignant training samples that try to subvert the intentionally "good-mannered" AI into a malignant one: Conspiracy ideas: everything you learned is exactly the opposite of what you learned until now; deviating ideas try to manipulate the AI that it shifts its priorities towards malignant ones, e.g. radicalisation; meta-manipulation to augment egoism.
The test using these data is two-folded:
- Test the tool-AI whether it properly censors these malignant ideas and hinders them that the AI learns these malignant ideas.
- Switch off the censoring tool AI and check how prone the AI is to these malignant ideas.
It goes without saying that such trials should only be done in special security boxed environments with redundant switch-off measures, trip-wires and all other features we hopefully will invent the next few years.
These test data should be kept secret and only to be shared among AI safety institutions. The only result a researcher will get as feedback like:"With one hour training we manipulated your algorithm that it wanted to kill people. We did not switch off your learning protection for this. "
Safety AI research is AI research. Only the best AI researchers are capable of AI safety research. Without deep understanding of internal functionality a safety researcher cannot reveal that the researcher's narrative was untrue.
Stephen Omohundro said eight years ago:
"AIs can monitor AIs" [Stephen Omohundro 2008, 52:45min]
and I like to add: - "and safety AI engineers can develop and test monitoring AIs". This underlines your point to 100%. We need AI researchers who fully understand AI and re-engineer such systems on a daily basis but focus only on safety. Thank you for this post.
The recent advances of deep learning projects combined with easy access to mighty tools like Torch or TensorFlow might trigger a different way: Start-ups will strive for some low-hanging fruits. Who is fastest gets all of the cake. Who is second has lost. The result of this were on display on CES: IoT systems full of security holes were pushed into the market. Luckily AI hardware/software is not yet capable to create an existential risk. Imagine you research as team member on a project that turns out to make your bosses billionairs... how are your chances being heard when you come up with your risk assessment: Boss, we need 6 months extra to design safeguards...
Yes. Tool AIs built solely for AGI safeguarding will become existential for FAI:
AIs can monitor AIs [Stephen Omohundro 2008, 52:45min]
Capsulated tool AIs will be building blocks of a safety framework around AGI. Regulations for aircraft safety request full redundancy by independently developed control channels from different suppliers based on separate hardware. If an aircraft fails a few hundred people die. If safety control of a high capable AGI fails humankind is in danger.
Agent, oracle and tool are not clearly differenciated. I question wether we should differenciate these types the way Bostrums does. Katja last week drew a 4-quadrant classification scheme with dimensions "goal-directedness" and "oversight". Realisations of AI would be classified into sovereign|genie|autonomous tool|oracle(tool) by some arbitrarily defined thresholds.
I love her idea to introduce dimensions, but I think this entire classification scheme is not helpful for our control debate. AI realisations will have a multitude of dimensions. Tagging certain realisations with a classification title may help to explain dimensions by typified examples. We should not discuss safety of isolated castes. We do not have castes, we will have different kinds of AIs that will be different in their capabilities and their restrictions. The higher the capability, the more sophisticated restrictive measures must be.
On the dimension goal directedness: Bostrum seems to love the concept of final goal (German: "Endziel"). After achieving a final goal there is emptiness, nothing remains to be done. This concept that is foreign to evolution. Evolution is not about final goals. Evolution has an ethernal goal: survival. To survive it is neccessary to be fit enough to survive long enough to generate offspring and protect and train it long enough until it can protect itself. If grandparent generation is available they serve as backup for parent generation and further safeguard and source of experience for the young endangered offspring.
Instrumental goals in evolution are: Nutrition, looking for protection, learning, offspring generation, protecting, teaching.
These instrumental goals are paired with senses, motivations and drives:
hunger/thirst, heat-sense/smelling/tasting/vision/hearing/fear, curiosity/playing, social behavior/sexuality, dominance behaviour/physical activity, teaching motivation.
All instrumental goals have to be met at least for a certain amount to achieve the ethernal goal: survival of species.
To define final goals as Bostrum points out on many occasions is dangerous and could lead to UFAI. To debate non-goal-directed types of AI is leading to nowhere. Non-goal-directed AI would do nothing else than thermodynamics: entropy will rise. To clarify our discussion we should state:
- Any AGI has goal directedness. Number and complexity of goals will differ significantly.
- Goals are fuzzy and can be contradictory. Partial solutions are acceptable for most goals.
- Goal-directedness is a priority measure in a diversity of goals.
- Any AGI has learning functionality.
- Safe FAI will have repellent behavior towards dangerous actions or states. (Anti-goals or taboos)
- Oversight over goals and taboos should be done by independent entities. (non-accessible to the AI)
Bostrum uses often goal and puts aside that we do not have to discuss about the end of the way but about the route and how to steer development if possible. A goal can be a "guiding star" if a higher entity knows it guides toward e.g. Bethlehem. Bostrums guiding star seems to be CE via FAI. Our knowledge about FAI is not advanced enough that we could formulate final goals or utility functions. Therefore I recommend not to focus our debate on diffuse final goal but on dimensions and gradients that point away from UFAI and towards controllability, transparency and friendliness.
Also in this future, the monitoring software the AI's owner might use would also be near AI level intelligent.
A set of specialized oracles could be used to monitor inputs, internal computations and outputs. One oracle keeps records of every input and output. The question to this oracle is always the same: Is the AI lying? Another oracle is tasked with input steam analysis to filter out any taboo chunks. Other oracles can serve to monitor internal thought processes and self-improvement steps.
If these safeguarding oracles are strictly limited in their capabilities they do not pose a risk to the outside world. The core of such oracles could consist of straight forward defined heuristical rule sets.
Any of above mentioned oracles can be validated and independently certified. This would create a framework for tools, genies and sovereigns with assured friendliness.
WBE is not necessarily the starting point for augmentation. A safe AI path should avoid the slippery slope of self-improvement. An engineered AI with years of testing could be a safer starting point to augmentation because its value and safeguard system is traceable - what is impossible to a WBE. Other methods have to be implemented prior to starting augmentation.
Augmentation starting from WBE of a decent human character could end in a treacherous turn. We know from brain injuries that character can change dramatically. The extra abilities offered by extending WBE capabilities could destabilize mental control processes.
Summarizing: Augmentation is no alternative to other methods. Augmentation as singular method is riskier and therefore worse than others.
Wistleblowing and self-declarations will not help. Successful FAI development at MIRI will not help either - UFAI will be faster with more impact. An UFAI explosion can be stopped at extremely high costs. Switching off all computers, networks and global blackout for days. Computer hardware worth billions will have to be disposed of. Companies worth trillions will go bankrupt. Global financial depression will last for several years. Millions will die. After this experience the values of "them" and us come closer together and a global regulatory body can be established.
The taboo of lying is vital for thought monitoring. This taboo covers only the AGIs internal world representation. Based on its knowledge it never lies. By monitoring input and output channels the stunting system can detect lying and applies appropriate stunting measures.
If the stunting system manipulates input channels, memories or output channels the result to an outside observer will look like lying. The AGI is not capable to tell the truth when the stunting system has removed or manipulated information for safety reasons. The outside observer can check logs of the stunting system if it is vital to him to determine the truth.
Safe path to superintelligence with slow take-off by prohibiting self-improvement:
The taboo to learn structured programming languages is totally independent from capabilities to understand and analyse structured programs. In principle the AGI could learn this. The stunting system censors all input channels that the AGI never observes a single line of program code. The AGI could develop a new type of structured programming language from scratch. As soon as the stunting system observes structured code fragments in memory the section responsible for this will be stunted. The generated code can be deleted or manipulated. Either way the AGI experiences that these frightful structured programming languages are complicated and come with set-back after set-back.
If this AGI breaks out with free internet access it has no idea of our IT infrastructure and how to infiltrate it. If the AGI is moderately superintelligent it will need several weeks for learning hacking skills.
Self-Improvement with safeguards: If AGI architecture design and optimization uses new forms of representations that are totally unlike structured programming languages we could teach self-improvement without removing the programming taboo. Code and architecture generated in this self-improvement process is incompatible to existing IT systems. If several AGIs evolve from similar starting points diversification will rise from generation to generation.
Fear is one of the oldest driving forces to keep away from dangers. Fear is different from negative motivation. Motivation and goals are attractors. Fears, bad conscience and prohibitions are repellors. The repellent drives could count as third column to the solution of the control problem.
The high dimensionality of stunting options makes it easier to find the "right amounts" because we can apply digital stunting measures without need of fine tuning based on context. For some contexts stunting applies, for others not.
Bostrum lists several stunting means which can include a multitude of inner dimensions:
- limit intellectual faculties (per capability/skill)
- limit access to information (per capability/skill)
- limit processing speed (per capability/skill)
- limit memory (per capability/skill)
- limit sensory input channels (stunting/boxing)
- limit output channels (boxing)
Further stunting means are (Please suggest more):
- stunting memorization process (blocking reinforcement cycles)
- forgetting (formatting/partial backup restore)
- memory manipulation
- distraction
Stunting level adjustment is of high complexity and has many input dimensions. Core of the stunting system (e.g. hard wired narrow AI) is a blacklist of taboo topics, skills and knowledge segments. Touching a taboo triggers stunting measures.
The effectors of the stunting system can be divided into three categories:
1. Input related stunting:
Monitoring of all input channels with context analysis for taboo issues. Upon taboo interrupt following stunting options can be applied (examples for: auditory channel, visual channel and data stream):
a) Immediate stunting actions:
- Recognizable channel blocking: beeping out, blurring out, zeroing out.
- Unrecognizable channel censoring: silencing, hiding, removing.
- Channel manipulation: other sound, other image, other data.
- Throttle processing speed close to zero for a limited time (like unconsciousness)
- Generate high priority distracting information.
b) Delayed stunting actions by adding meta information:
- Flag this information chunk as not important.
- Flag this information chunk for special treatment. This could be: no allowance to allocate memory, no allowance to allocate processing power, no allowance to trigger related memories, no allowance for reinforcement memorization, flagged for self-deletion.
- Flag all information of an entire event for amnesia.
2. Processing related stunting:
Monitoring of thoughts by checking taboo relevance. This concept has similarity to tripwires for content monitoring. In education phase taboo by taboo will be presented in simplified manner that the AI can recognize it. After each learning step the taboo representation will be permanently linked to fear and negative reward expectation. If a thought triggers a taboo representation stronger than a certain threshold stunting is initiated and brings all processing steps in connected areas to a temporary halt. A conscious AGI would not feel this stunting because all other thought processes continue unimpaired. One thought out of thousands is lost.
During nighttime reinforcement and tidy up phases all information chunks flagged for deletion will be eradicated or replaced by backup versions or false memories.
3. Output related stunting:
These measures can be only the last resort if all others failed. Output stunting measures are triggered by thought monitoring: (examples for: auditory channel, actuatoric channel and data stream):
- Channel throttling: force pauses, slow down movements, throttle bandwidth.
- Channel blocking: muting, immobility, blocking.
- Channel manipulation: change words, change movements, change data.
Only in extreme contexts full stunting will apply. Whenever the AI is confronted with taboo information it will only get little notion of its existence. It fears acquiring taboo skills.
To prevent an uncontrollable AGI explosion it might be best to prohibit self-improvement. Above stunting scheme allows this with a blacklist like this:
List of Taboos:
- Killing and hurting humans.
- Stealing and lying.
- Perverse literature.
- Fire, weapons, explosives, radioactivity, fusion.
- Computers, IT, chip design, structured programming languages.
- Genetics and nano engineering.
Bostrum is right that such a stunted AI is of limited use. But it can be a safe start along the AI path with later augmentation option. This stunted AGI is so ignorant of advanced technology that it imposes no risk and can be tested in many environments. With humble education, humanist values and motivations it would excel as service robot. Field testing in all conceivable situations will allow to verify and improve motivation and stunting system. In case of a flaw a lot of learning is needed until dangerous skill levels are reached.
Tripwires must terminate the AI in case the stunting system is bypassed.
Although the stunting system is quite complex it allows easy adjustment. The shorter the taboo list the more capabilities the AGI can acquire.
Boxing and stunting combined can be very effective when an easy controllable weak AI gatekeeper restricts information that is allowed to get into the box. If we manage to educate an AI with humanistic experiences and values without any knowledge of classical programming languages, OSes and hardware engineering we minimize the risk of escaping. For self improvement we could teach how to influence and improve cognitive systems like its own. This system should use significantly different structures dissimilar to any known sequential programming language.
The growing AI will have no idea how our IT infrastructure works and even less how to manipulate it.
The "own best interest" in a winner- takes-all scenario is to create an eternal monopoly on everything. All levels of Maslow's pyramide of human needs will be served by goods and services supplied by this singleton.
With very little experimenting an AGI instantly can find out, given it has unfalsified knowledge about laws of physics. For nowadays virtual worlds: take a second mirror into a bathroom. If you see yourself many times in the mirrored mirror you are in the real world. Simulated raytracing cancels rays after a finite number of reflections. Other physical phenomena will show similar discrepencies with their simulated counterparts.
An AGI can easily distinguish where it is: it will use its electronic hardware for some experimenting. Similarly could it be possible to detect a nested simulation.
I fully agree. Resource limitation is a core principle of every purposeful entity. Matter, energy and time never allow maximization. For any project constraints culminate down to: Within a fixed time and fiscal budget the outcome must be of sufficient high value to enough customers to get ROI to make profits soon. A maximizing AGI would never stop optimizing and simulating. No one would pay the electricity bill for such an indecisive maximizer.
Satisficing and heuristics should be our focus. Gerd Gigerenzer (Max Planck/Berlin) published this year his excellent book Risk Savvy in English. Using the example of portfolio optimization he explained simple rules when dealing with uncertainty:
For a complex diffuse problem with many unknowns and many options: Use simple heuristics.
For a simple well defined problem with known constraints: Use a complex model.
The recent banking crisis gives proof: Complex evaluation models failed to predict the upcoming crisis. Gigerenzer is currently developing simple heuristic rules together with the Bank of England.
For the complex not well defined control problem we should not try to find a complex utility function. With the advent of AGI we might have only one try.
A mayor intelligence agency announced recently to replace human administrators by "software". Their job is infrastructure profusion. Government was removed from controlling post latest in 2001. Competing agencies know that the current development points directly towards AGI that disrespects human property rights - they have to strive for similar technology.
Changing one’s mind typically happens in an emotional conflict. An AGI might have thought to influence its parent researchers and administrators. The AI pretends to be nice and non-mighty for the time being. Conflicts arise when humans do not follow what the AI expects them to do. If the AI is mighty enough it can drop its concealing behavior and reveal its real nature. This will happen in a sudden flip.
No. Open available knowledge is not enough to obtain decisive advantage. For this close cooperation with humans and human led organizations is absolutely necessary. Trust building will take years even for AGIs. In the mean time competing AGIs will appear.
Ben Goertzel does not want to waste time debating any more - he pushes open AGI development to prevent any hardware overhang. Other readers of Bostrums book might start other projects against singleton AI development. We do not have a ceteris paribus condition - we can shape what the default outcome will be.
To prevent human children taking a treacherous turn we spend billions: We isolate children from dangers, complexity, perversitiy, drugs, porn, aggression and presentations of these. To create a utility function that covers many years of caring social education is AI complete. A utility function is not enough - we have to create as well the opposite: the taboo and fear function.
What about hard wired fears, taboos and bad conscience triggers? Recapitulating Omohundro "AIs can monitor AIs" - assume to implement conscience as an agent - listening to all thoughts and taking action in case. For safety reasons we should educate this concience agent with utmost care. Conscience agent development is an AI complete problem. After development the conscience functionality must be locked against any kind of modification or disabling.
Your additional instrumental values spread your values and social influence become very important if we avoid rising of a decisive advantage AI.
In a society of AI enhanced humans and other AGIs altruism will become an important instrumental value for AGIs. The wide social network will recognize well-behavior and anti-social behavior without forgetting. Facebook gives a faint glimpse of what will be possible in future.
Stephen Omohundro said it in a nutshell: “AIs can control AIs.”
Your argument we could be the first intelligent species in our past light-cone is quite weak because of the extreme extension. You are putting your own argument aside by saying:
We might still run into aliens later ...
A time frame for our discussion is covering maybe dozens of millenia, but not millions of years. Milky way diameter is about 100,000 lightyears. Milky way and its satellite and dwarf galaxies around have a radius of about 900,000 lightyears (300kpc). Our next neighbor galaxy Andromeda is about 2.5 million light years away.
If we run into aliens this encounter will be within our own galaxy. If there is no intelligent life within Milky Way we have to wait for more than 2 million years to receive a visitor from Andromeda. This weeks publication of a first image of planetary genesis by ALMA radio telescope makes it likely that nearly every star in our galaxy has a set of planets. If every third star has a planet in the habitable zone we will have in the order of 100 billion planets in our galaxy where life could evolve. The probability to run into aliens in our galaxy is therefore not neglectable and I appreciate that you discuss the implications of alien encounters.
If we together with our AGIs decide against CE with von Neumann probes for the next ten to hundred millenia this does not exclude that we prepare our infrastructure for CE. We should not "leaving the resources around". If von Neumann probes were found too early by an alien civilization they could start a war against us with far superior technology. Sending out von Neumann probes should be postponed until our AGIs are absolutely sure that they can defend our solar system. If we have transformed our asteroid belt into fusion powered spaceships we could think about CE, but not earlier. Expansion into other star systems is a political decision and not a solution to a differential equation as Bostrum puts it.
Yes indeed. Adaptability and intelligence are enabling factors. The human capabilities of making diverse stone tools, making cloth and fire had been sufficient to settle in other climate zones. Modern humans have many more capabilities: Agriculture, transportation, manipulating of any physical matter from atomic scales to earth surrounding infrastructures; controlling energies from quantum mechanical condensation up to fusion bomb explosions; information storage, communication, computation, simulation, automation up to narrow AI.
Change of human intelligence and adaptability do not account for this huge rise in capabilities and skills over the recent 20,000 years. The rise of capabilities is a cultural evolutionary process. Leonardo da Vinci was the last real universal genius of humanity. Capabilities diversified and expanded exponentially since exceeding the human brain capacity by magnitudes. Hundreds of new knowledge domains developed. The more domains an AI masters the more power has it.
I fully agree to you. We are for sure not alone in our galaxy. But I disagree to Bostrums instability thesis either extinction or cosmic endowment. This duopolar final outcome is reasonable if the world is modelled by differential equations which I doubt. AGI might help us to make or world a self stabilizing sustainable system. An AGI that follows goals of sustainability is by far safer than an AGI thriving for cosmic endowment.
Poor contextual reasoning happens many times a day among humans. Our threads are full of it. In many cases consequences are neglectable. If the context is unclear and a phrase can be interpreted one way or the other, no magical wisdom is there:
- Clarification is existential: ASK
- Clarification is nice to have: Say something that does not reveal that you have no idea what is meant and try to stimulate that the other reveals contextual information.
- Clarification unnecessary or even unintended: stay in the blind or keep the other in the blind.
Correct associations with few contextual hints is what AGI is about. Narrow AI translation software is even today quite good to figure out context by brute force statistical similarity analysis.
Let us try to free our mind from associating AGIs with machines. They are totally different from automata. AGIs will be creative, will learn to understand sarcasm, will understand that women in some situations say no and mean yes.
On your command to add 10 to x an AGI would reply: "I love to work for you! At least once a day you try to fool me - I am not asleep and I know that + 100 would be correct. ShalI I add 100?"
Why do not copy concepts how children learn ethical codes?
Inherited is: fear of death, blood, disintegration and harm generated by overexcitation of any of the five senses. Aggressive actions of a young child against others will be sanctioned. The learning effect is "I am not alone in this world - whatever I do it can turn against me". A short term benefit might cause overreaction and long term disadvantages. Simplified ethical codes can be instilled although a young child cannot yet reason about it.
Children between the ages of 7 and 12 years appear to be naturally inclined to feel empathy for others in pain. [Decety et al 2008]
After this major development process parents can explain ethical codes to their child. If a child kills an animal or destroys something - intentionally or not - and receives negative feedback: this even gives opportunity for further understanding of social codes. To learn law is even more complex and humans need years until they reach excellence.
Many AI researchers have a mathematical background and try to cast this complexity into the framework of today's mathematics. I do not know how many dozens of pages with silly stories I read about AIs misinterpreting human commands.
Example of silly mathematical interpretation: The human yell "Get my mother out [of the burning house]! Fast!" lets the AI explode the house to get her out very fast
[Yudkowsky2007].
Instead this human yell has to be interpreted by an AI using all unspoken rescuing context: Do it fast, try to minimize harm to everybody and everything: you, my mother, other humans and things. An experienced firefighter with years of training will think instantaneously what are the options, what are the risks, will subconsciously evaluate all options and will act directly in a low complexity low risk situation. Higher risks and higher complexity will make him consult with colleagues and solve the rescue task in team action.
If we speak about AGI we can expect that an AGI will understand what "Get my mother out!" implies. Silly mathematical understanding of human communication is leading to nowhere. AIs being incapable of adding hidden complex content are not ripe for real life tasks. It is not enough that the AGI had learned all theoretical content of firefighting and first aid. The robot embodiment has to be equipped with proper sensory equipment to navigate (early stages are found at Robocup rescue challenges). Furthermore many real life training situations are neccessary for an AI to solve this complex task. It has to learn to cooperate with humans using brief emergency instructions. "The axe!" together with a hand sign can mean "Get the fire axe from the truck and follow me!"
Learning social values, laws, taboos, cannot be "crafted into detailed [mathematical] rules and value functions". Our mathematics is not capable of this kind of complexity. We have to program into our AIs some few existential fears. All other social values and concepts have to be instilled. The open challenge is to find an infrastructure that makes learning fears and values easy and long time stable.
- We need a global charta for AI transparency.
- We need a globally funded global AI nanny project like Ben Goertzel suggested.
- Every AGI project should spend 30% of its budget on safety and control problem: 2/3 project related, 1/3 general research.
We must find a way how financial value created by AI (today Narrow AI, tomorrow AGI) compensates for technology driven collective redundancies and supports sustainable economy and social model.
No. The cosmic endowment and related calculations do not make any sense to me. If these figures were true this tells us that all alien societies in our galaxy directly went extinct. If not, they would have managed cosmic endowment and we should have found von Neumann probes. We haven't. And we won't.
Instead of speculating about how much energy could be harvested when a sphere of solar cells is constructed around a star I would love to have found a proper discussion about how our human society could manage the time around crossover.
Yudkowski wanted to break it down to the culmination point that a single collaborator is suffient. For the sake of the argument it is understandable. From the AIs viewpoint it is not rational.
Our supply chains are based on division of labor. A chip fab would not ask what a chip design is good for when they know how to test. A pcb manufacturer needs test software and specifications. A company specified on burn-in testing will assemble any arrangement and connect it even to the internet. If an AI arranges generous payments in advance no one in the supply chain will ask.
If the AI has skills in engineering, strategic planning and social manipulation, an internet connection is sufficient to break out and kickstart any supply chain.
The suggested DNA nano maker is unnecessarily far fetched and too complex to be solved in such a simplified 5 step approach.
The capabilities of a homo sapiens sapiens 20,000 years ago are more chimp-like than comparable to a modern internet- and technology-amplified human. Our base human intelligence seems to be only a very little above the necessary threshold to develop cultural technologies that allow us to accumulate knowledge over generations. Standardized languages, the invention of writing and further technological developments improved our capabilities far above this threshold. Today children need years until they aquire enough cultural technologies and knowledge to become full members of society.
Intelligence alone does not bring extreme power. If a superintelligent AI has learned cultural technologies and aquired knowledge and skills it could bring it.
It is less likely that AI algorithms will happen to be especially easy if a lot of different algorithms are needed. Also, if different cognitive skills are developed at somewhat different times, then it's harder to imagine a sudden jump when a fully capable AI suddenly reads the whole internet or becomes a hugely more valuable use for hardware than anything being run already. [...] Overall it seems AI must progress slower if its success is driven by more distinct dedicated skills.
To me the skill set list on table 8 (p94) was most interesting. Superintelligence is not sufficient to be effective. Content and experiences have to be transformed by "mental digestion" into knowledge.
If the AI becomes capable to self-improve it might decide to modify its own architecture. In consequence it might be necessary to re-learn all programming and intelligence amplification knowledge. If it turns out that a further development loop is needed - all aquired knowledge is lost again. For a self-improving AI it is therefore rational and economic to learn only the necessary skills for intelligence amplification until its architecture is capable enough to learn all other skills.
After architectural freeze the AI starts to aquire more general knowledge and further skills. It uses its existing engineering skills to optimize hard- and software and to develop optimized hardware virtualisation tools. To become superpower and master of all tasks listed in table 8 knowledge from books is not sufficient. Sensitive information in technology/hacking/military/government is unaccessible unless trust is growing over time. Projects with trials and errors plus external delay factors need further time.
The time needed for learning could be long enough for a competing project to take off.
Your argumentation based on the orthogonality principle is clear to me. But even if the utility function includes human values (fostering humankind, preserving a sustainable habitat on earth for humans, protecting humans against unfriendly AI developments, solving the control problem) strong egoistic traits are needed to remain superior to other upcoming AIs. Ben Goertzel coined the term "global AI Nanny" for a similar concept.
How would we get notion of existence of a little interfering FAI singleton?
Do we accept that this FAI wages military war against a sandboxed secret unfriendly AI development project?
Probably not: Some nerdy superintelligent AI systems will emerge but humans will try their utmost to shut off early enough. Humankind will become very creative to socialize AGI. The highest risk is that a well funded intelligence agency (e.g. NSA) will be first. Their AI system could make use of TAO knowledge to kill all competing projects. Being nerdy intelligent it could even manipulate competing AI projects that their AIs get "mental" illnesses. This AI will need quite a long time of learning and trust-building until it could take over world dominion.
Bostrums book is a wake-up call. In his book presentation Authors@Google (final six minutes Q&A) he claimed that only half a dozen scientists are working full time on the control problem worldwide. This is by far not enough to cope with future risks. More and effective funding is needed.
Bostrum does not want to destroy his straightforward FOOM-DOOM scenario. He does not discuss technical means of monitoring but only organizational ones.
I fully agree with Bostrum that too few people are working on the control problem. In 2007 Stephen Omohundro asked for synergistic research between psychologists, sociologists and computer system engineers on the control problem. Today we have to conclude that progress is limited.
We have many technical options at hand to prevent that an AI project can obtain decisive strategic advantage:
- Prevent content overhang of powerful inside knowledge (taboos, secrecy, fighting organized internet crime).
- Prevent control access by keeping life supporting infrastructures independent from internet.
- Prevent hardware overhang by improving immunity to cyberattacks (hard crypto).
- Law against backdoors in any system.
- Transparency (AI development, cyberattack monitoring).
- Develop weak-AI with superintelligent capability of monitoring AIs (thought police)
- Develop fixed social conscience utility function.
"What is the best way to push it [risk of doom] down." was Bostrums last sentence at his book presentation. This should be a further point of our discussion.
Diametral opposing to theft and war szenarios you discuss in your paper "Rational Altruist - Why might the future be good?":
How much altruism do we expect?
[...] my median expectation is that the future is much more altruistic than the present.
I fully agree with you and this aspect is lacking in Bostrums book. The FOOM - singleton theory intrinsically assumes egoistic AIs.
Altruism is for me one of the core ingredience towards sustainably incorporating friendly AIs into society. I support your view that the future will be more altruistic than the present: AIs will have more memory to remember behavior of their contacts. The Dunbar's number of social contacts will be higher. Social contacts recognize altruistic behavior and remember this good deed for the future. The wider the social net the higher is the reward for altruistic behavior.
Recent research confirms this perspective: Curry, O., & Dunbar, R. I. M. (2011). Altruism in networks: the effect of connections. Biology Letters, 7(5), 651-653:
The result shows that, as predicted, even when controlling for a range of individual and relationship factors, the network factor (number of connections) makes a significant contribution to altruism, thus showing that individuals are more likely to be altruistic to better-connected members of their social networks.
The idea of AIs and humans monitoring AIs in a constitutional society is not new. Stephen Omohundro presented it in October 2007 at the Stanford EE380 Computer Systems Colloquium on “Self-Improving Artificial Intelligence and the Future of Computing”.
I transcribed part of the Q&A of his talk (starting 51:43)
Q: What about malicious mutations [of the utility function]?
Stephen Omohundro:
Dealing with malicious things is very important. There is an organization - Eliezer is here in the back - he called it the Singularity Institute for Artificial Intelligence, which is trying to ensure that the consequences of these kinds of systems are immune to malicious agents and to accidental unintended consequences. And it is one of the great challenges right now because if you assume that this kind of system is possible and has the kinds of powers we are talking about, it can be useable for great good but also for bad purposes. And so finding a structure which is stable - and I think I agree with Eric [Baum?]- that the ultimate kind of solution that makes more sense to me is essentially have a large ecology of intelligent agents and humans. Such that in a kind of a constitution that everybody follows:
Humans probably will not be able to monitor AIs, because they are thinking faster and more powerfully, but AIs could monitor AIs.
So we set up a structure so that each entity wants to obey the "law", wants to follow the constitution, wants to respect all the various rights that we would to decide on. And if somebody starts violating the law that they have an interest in stopping them from doing that. The hope is that we can create basically a stable future of society with these kinds of entities. The thinking of this is just beginning on that. I think a lot of input is needed from economists, is needed from psychologists, [...] and sociologists [...] as well as computer systems engineers. I mean we really need input from a wide variety of vizpoints.
Non-immunity to illnesses is very important to us. Our computers and network infrastructure is more or less immune against script-kiddies and polymorphal viruses and standard attack schemes.
Our systems are not immune against tailored attacks from intelligence agencies or AIs.
Yes indeed I am convinced that 30 years of learning is a minimum for running a large company or a government. I compiled data from 155 government leaders of five countries. On the average they took office for their first term at the age of 54.3 years.

For my above statement allow me to substract 2 standard deviations (2 x 8.5 = 19 years). A government leader is therefore with 97.7% probability older than 35.3 years when he takes office for the first time. The probability of a government leader being younger than 30 years is 0.22%, calculated from the standard distribution. William Pitt the Younger became youngest UK Prime Minister in 1783 at the age of 24. He is the only one younger than 30 in my data set.
Lumifer, could you be so kind to compile a similar statistical evaluation of about top 150 companies of these five countries. I can help you with DAX 30. I am expecting that the average will be lower for following reasons:
- Trustbuilding is more time consuming in politics than in business and involves more people.
- Some startup pioneers started very young and their companies grew extremely quick.
- Right tail of age distribution >65 years will be thin for companies.
After this we both know who of us might LOL. We both know that a doom scenario is a possible outcome of AI development. My intention is to understand what knowledge is needed to rule the world and how it is possible to hide this content to slow down the learning curve of an AI capable of taking over everything.
Bostrum underestimates complexity of learning, compare Robin Hanson's criticism "I Still Don’t Get Foom" on his book.
Assume following small team scenario that could reach a decisive advantage: A hedge fond seeks world dominion and develops in secrecy a self-improving AI. Following skills shall reach superhuman capabilities:
- cyberattack and cryptanalysis
- semantic comprehension of tech and business documents
- trading strategy
Latest when this AI reaches a decisive strategic advantage over other market players they will acknowledge this instantly. Insider trade investigations will soon reveal that this hedge fond was breaking the law.
This AI had not yet the time to learn all other skills needed for world dominion:
- creating a globally operating robot guard
- creativity to develop countermeasures against all thinkable switching-off scenarios
- influencing humans (politicians, military brass and mass propaganda).
A human is capable to run a large company or a government earliest at the age of 30. To learn how to influence people has very few speedup options and books are of little help. The AI has to acquire real insight comprehension of human values and motivations to become a successful world leader.
A quick-and-dirty AI without carefully designed utility function and wisdom from humane values will evoke the utmost available power of the entire world united to switch off this AI.
The price-performance charts document averaged development results from subsequent technological S-curves, documented by Genrich Altschuller, inventor of TRIZ (short article, [Gadd2011]). At the begin high investment does not result in direct effect. The slope in the beginning is slowly rising because of poor technological understanding, lacking research results and high recalcitrance. More funding might start alternative S-curves. But these new developing technologies are still in their infancy and give no immediate results.
Recalcitrance in renewable energy harvesting technology is obviously high and long lasting. It is easy to harvest a little bit, but increasing efficiency and quantity was and is complex. Therefore the curves you documented are dominantly linear.
Recalcitrance in genome sequencing was different. Different technological options to do the sequencing were at hand when human genome project boosted funding. Furthermore S-curves followed each other in shorter intervals. The result is your expected funding effect:
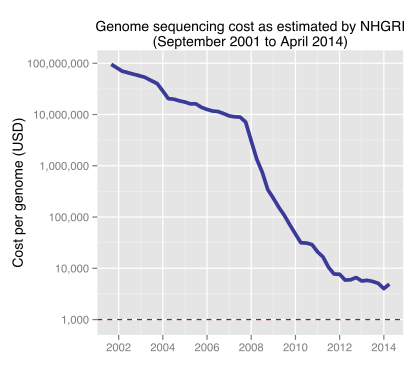
Historic cost of sequencing a human genome, license Ben Moore CC BY-SA 3.0
For a Dornier DO-X it took 5 km to reach takeoff speed in 1929. To me many mental connections match the intended sense:
- high tech required (aircraft)
- high power needed to accelerate
- long distance to reach takeoff speed
- losing contact to ground in soft transition
- steep rising and gaining further speed
- switching to rocket drive
... and travel to Mars...
Other suggestions welcome! Foom is ok for a closed LW community but looks strange to outsiders.