Superintelligence 16: Tool AIs
post by KatjaGrace · 2014-12-30T02:00:09.775Z · LW · GW · Legacy · 38 commentsContents
Summary Another view In-depth investigations How to proceed None 38 comments
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the sixteenth section in the reading guide: Tool AIs. This corresponds to the last parts of Chapter Ten.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. Some of my own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post, or to look at everything. Feel free to jump straight to the discussion. Where applicable and I remember, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: : “Tool-AIs” and “Comparison” from Chapter 10
Summary
- Tool AI: an AI that is not 'like an agent', but more like an excellent version of contemporary software. Most notably perhaps, it is not goal-directed (p151)
- Contemporary software may be safe because it has low capability rather than because it reliably does what you want, suggesting a very smart version of contemporary software would be dangerous (p151)
- Humans often want to figure out how to do a thing that they don't already know how to do. Narrow AI is already used to search for solutions. Automating this search seems to mean giving the machine a goal (that of finding a great way to make paperclips, for instance). That is, just carrying out a powerful search seems to have many of the problems of AI. (p152)
- A machine intended to be a tool may cause similar problems to a machine intended to be an agent, by searching to produce plans that are perverse instantiations, infrastructure profusions or mind crimes. It may either carry them out itself or give the plan to a human to carry out. (p153)
- A machine intended to be a tool may have agent-like parts. This could happen if its internal processes need to be optimized, and so it contains strong search processes for doing this. (p153)
- If tools are likely to accidentally be agent-like, it would probably be better to just build agents on purpose and have more intentional control over the design. (p155)
- Which castes of AI are safest is unclear and depends on circumstances. (p158)
Another view
Holden prompted discussion of the Tool AI in 2012, in one of several Thoughts on the Singularity Institute:
...Google Maps is a type of artificial intelligence (AI). It is far more intelligent than I am when it comes to planning routes.
Google Maps - by which I mean the complete software package including the display of the map itself - does not have a "utility" that it seeks to maximize. (One could fit a utility function to its actions, as to any set of actions, but there is no single "parameter to be maximized" driving its operations.)
Google Maps (as I understand it) considers multiple possible routes, gives each a score based on factors such as distance and likely traffic, and then displays the best-scoring route in a way that makes it easily understood by the user. If I don't like the route, for whatever reason, I can change some parameters and consider a different route. If I like the route, I can print it out or email it to a friend or send it to my phone's navigation application. Google Maps has no single parameter it is trying to maximize; it has no reason to try to "trick" me in order to increase its utility.
In short, Google Maps is not an agent, taking actions in order to maximize a utility parameter. It is a tool, generating information and then displaying it in a user-friendly manner for me to consider, use and export or discard as I wish.
Every software application I know of seems to work essentially the same way, including those that involve (specialized) artificial intelligence such as Google Search, Siri, Watson, Rybka, etc. Some can be put into an "agent mode" (as Watson was on Jeopardy!) but all can easily be set up to be used as "tools" (for example, Watson can simply display its top candidate answers to a question, with the score for each, without speaking any of them.)
The "tool mode" concept is importantly different from the possibility of Oracle AI sometimes discussed by SI. The discussions I've seen of Oracle AI present it as an Unfriendly AI that is "trapped in a box" - an AI whose intelligence is driven by an explicit utility function and that humans hope to control coercively. Hence the discussion of ideas such as the AI-Box Experiment. A different interpretation, given in Karnofsky/Tallinn 2011, is an AI with a carefully designed utility function - likely as difficult to construct as "Friendliness" - that leaves it "wishing" to answer questions helpfully. By contrast with both these ideas, Tool-AGI is not "trapped" and it is not Unfriendly or Friendly; it has no motivations and no driving utility function of any kind, just like Google Maps. It scores different possibilities and displays its conclusions in a transparent and user-friendly manner, as its instructions say to do; it does not have an overarching "want," and so, as with the specialized AIs described above, while it may sometimes "misinterpret" a question (thereby scoring options poorly and ranking the wrong one #1) there is no reason to expect intentional trickery or manipulation when it comes to displaying its results.
Another way of putting this is that a "tool" has an underlying instruction set that conceptually looks like: "(1) Calculate which action A would maximize parameter P, based on existing data set D. (2) Summarize this calculation in a user-friendly manner, including what Action A is, what likely intermediate outcomes it would cause, what other actions would result in high values of P, etc." An "agent," by contrast, has an underlying instruction set that conceptually looks like: "(1) Calculate which action, A, would maximize parameter P, based on existing data set D. (2) Execute Action A." In any AI where (1) is separable (by the programmers) as a distinct step, (2) can be set to the "tool" version rather than the "agent" version, and this separability is in fact present with most/all modern software. Note that in the "tool" version, neither step (1) nor step (2) (nor the combination) constitutes an instruction to maximize a parameter - to describe a program of this kind as "wanting" something is a category error, and there is no reason to expect its step (2) to be deceptive.
I elaborated further on the distinction and on the concept of a tool-AI in Karnofsky/Tallinn 2011.
This is important because an AGI running in tool mode could be extraordinarily useful but far more safe than an AGI running in agent mode...
Notes
1. While Holden's post was probably not the first to discuss this kind of AI, it prompted many responses. Eliezer basically said that non-catastrophic tool AI doesn't seem that easy to specify formally; that even if tool AI is best, agent-AI researchers are probably pretty useful to that problem; and that it's not so bad of MIRI to not discuss tool AI more, since there are a bunch of things other people think are similarly obviously in need of discussion. Luke basically agreed with Eliezer. Stuart argues that having a tool clearly communicate possibilities is a hard problem, and talks about some other problems. Commenters say many things, including that only one AI needs to be agent-like to have a problem, and that it's not clear what it means for a powerful optimizer to not have goals.
2. A problem often brought up with powerful AIs is that when tasked with communicating, they will try to deceive you into liking plans that will fulfil their goals. It seems to me that you can avoid such deception problems by using a tool which searches for a plan you could do that would produce a lot of paperclips, rather than a tool that searches for a string that it could say to you that would produce a lot of paperclips. A plan that produces many paperclips but sounds so bad that you won't do it still does better than a persuasive lower-paperclip plan on the proposed metric. There is still a danger that you just won't notice the perverse way in which the instructions suggested to you will be instantiated, but at least the plan won't be designed to hide it.
3. Note that in computer science, an 'agent' means something other than 'a machine with a goal', though it seems they haven't settled on exactly what [some example efforts (pdf)].
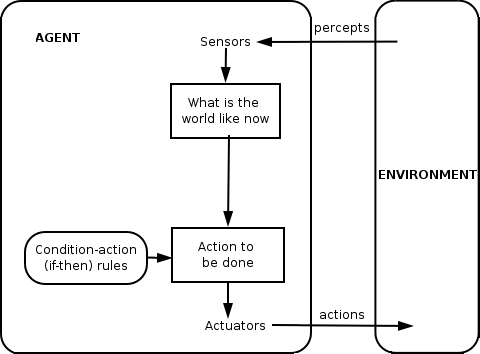
Figure: A 'simple reflex agent' is not goal directed (but kind of looks goal-directed: one in action)
4. Bostrom seems to assume that a powerful tool would be a search process. This is related to the idea that intelligence is an 'optimization process'. But this is more of a definition than an empirical relationship between the kinds of technology we are thinking of as intelligent and the kinds of processes we think of as 'searching'. Could there be things that merely contribute massively to the intelligence of a human - such that we would think of them as very intelligent tools - that naturally forward whatever goals the human has?
One can imagine a tool that is told what you are planning to do, and tries to describe the major consequences of it. This is a search or optimization process in the sense that it outputs something improbably apt from a large space of possible outputs, but that quality alone seems not enough to make something dangerous. For one thing, the machine is not selecting outputs for their effect on the world, but rather for their accuracy as descriptions. For another, the process being run may not be an actual 'search' in the sense of checking lots of things and finding one that does well on some criteria. It could for instance perform a complicated transformation on the incoming data and spit out the result.
5. One obvious problem with tools is that they maintain humans as a component in all goal-directed behavior. If humans are some combination of slow and rare compared to artificial intelligence, there may be strong pressure to automate all aspects of decisionmaking, i.e. use agents.
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some inspired by Luke Muehlhauser's list, which contains many suggestions related to parts of Superintelligence. These projects could be attempted at various levels of depth.
- Would powerful tools necessarily become goal-directed agents in the troubling sense?
- Are different types of entity generally likely to become optimizers, if they are not? If so, which ones? Under what dynamics? Are tool-ish or Oracle-ish things stable attractors in this way?
- Can we specify communication behavior in a way that doesn't rely on having goals about the interlocutor's internal state or behavior?
- If you assume (perhaps impossibly) strong versions of some narrow-AI capabilities, can you design a safe tool which uses them? e.g. If you had a near perfect predictor, can you design a safe super-Google Maps?
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about multipolar scenarios - i.e. situations where a single AI doesn't take over the world. To prepare, read “Of horses and men” from Chapter 11. The discussion will go live at 6pm Pacific time next Monday 5 January. Sign up to be notified here.
38 comments
Comments sorted by top scores.
comment by KatjaGrace · 2014-12-30T02:06:41.032Z · LW(p) · GW(p)
Perhaps we should be clearer on the relationship between agents, search processes and goals. Bostrom's argument in this section seemed to be that a strong enough search process is more or less a goal, and so (assuming goals are the main interesting feature of agents) 'tools' will be much like agents, in the problematic ways. Are search processes and goals basically the same?
Replies from: gedymin, mgnb, TheAncientGeek, None↑ comment by gedymin · 2014-12-30T19:11:25.984Z · LW(p) · GW(p)
Perhaps one could say that an agent in the sense that matters for this discussion is something with a personal identity, a notion of self (in a very loose sense).
Intuitively, it seems that tool AIs are safer because they are much more transparent. When I run a modern general purpose constraint-solver tool, I'm pretty sure that no AI agent will emerge during the search process. When I pause the tool somewhere in the middle of the search and examine its state, I can predict exactly what the next steps are going to be - even though I can hardly predict the ultimate result of the search!
In contrast, the actions of an agent are influenced by its long-term state (it's "personality"), so its algorithm is not straightforward to predict.
I feel that the only search processes capable of internally generating agents (the thing Bostrom is worried about) are the ones insufficiently transparent (e.g. ones using neural nets).
↑ comment by mgnb · 2014-12-30T10:29:48.964Z · LW(p) · GW(p)
All this seems to be more or less well explained under Optimization process and Really powerful optimization process, but I'll give my take on it, heavily borrowed from those and related readings.
I went around in circles on 'goals' until I decided to be rigorous in thinking naturalistically rather than anthropomorphically, or mentalistically, for want of a better term. It seems to me that a goal ought to correspond to a set of world states, and then, naturalistically, the 'goal' of a process might be a set of world states that the process tends to modify the world towards: a random walk would have no goal, or alternatively, its goal would be any possible world. My goals involve world states where my body is comfortable, I am happy, etc.
It depends on what Bostrom means by a search process, but, taking a stab, in this context it would not really be distinct from a goal provided it had an objective. In this framework, Google Maps can be described as having a goal, but it's pretty prosaic: manipulate the pixels on the user's screen in a way that represents the shortest route given the inputs. It's hugely 'indifferent' between world states that do not involve changes to those pixels.
I'm not too keen on the distinction between agents and tools made by Holden because, as he says, any process can be described as having a goal—a nuclear explosion can probably be described this way—but in this context a Tool AI would possibly be described as one that is similarly hugely 'indifferent' between world states in that it has no tendency to optimise towards them (I'm not that confident that others would be happy with that description).
([Almost] unrelated pedant note: I don't think utility functions are expressive enough to capture all potentially relevant behaviours and would suggest it's better to talk more generally of goals: it's more naturalistic, and makes fewer assumptions about consistency and rationality.)
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2014-12-30T14:41:39.423Z · LW(p) · GW(p)
I'm not too keen on the distinction between agents and tools made by Holden because, as he says, any process can be described as having a goal—a nuclear explosion can probably be described this way—but in this context a Tool AI would possibly be described as one that is similarly hugely 'indifferent' between world states in that it has no tendency to optimise towards them (I'm not that confident that others would be happy with that description).
You are tacitly assuming that having goals is sufficient for agency. But what the proponents of the tool argument seem to mean by an agent, as opposed to a tool, is something that will start pursuing goals on boot up.
A nuclear bomb could be described as having goals so long as you are not bothered about adaptive planning towards those goals....which is good reason for caring about adaptive planning.
↑ comment by mgnb · 2014-12-30T15:47:21.482Z · LW(p) · GW(p)
1) I must admit that I'm a little sad that this came across as tacit: that was in part the point I was trying to make! I don't feel totally comfortable with the distinction between tools and agents because I think it mostly, and physically, vanishes when you press the start button on the tool, which is much the same as booting the agent. In practice, I can see that something that always pauses and waits for the next input might be understood as not an agent, is that something you might agree with?
My understanding of [at least one variant of] the tool argument is more that a) software tools can be designed that do not exhibit goal-based behaviour, which b) would be good because the instrumental values argument for deadliness would no longer apply. But since anything can be described as having goals (they are just a model of behaviour) the task of evaluating the friendliness of those 'goals' would remain. Reducing this just to 'programs that always pause before the next input' or somesuch doesn't seem to match the tool arguments I've read. Note: I would be very pleased to have my understanding of this challenged.
Mostly, I am trying to pin down my own confusion about what it means for a physical phenomena to 'have a goal', firstly, because goal-directedness is so central to the argument that superintelligence is dangerous, and secondly, because the tool AI objection was the first that came to mind for me.
2) Hmm, this might be splitting hairs, but I think I would prefer to say that a nuclear bomb's 'goals' are limited to a relatively small subset of the world state, which is why it's much less dangerous than an AI at the existential level. The lack of adaptive planning of a nuclear bomb seems less relevant than its blast radius in evaluating the danger it poses!
EDIT: reading some of your other comments here, I can see that you have given a definition for an agent roughly matching what I said—sorry that missed that! I would still be interested in your response if you have one :)
Replies from: None, TheAncientGeek↑ comment by [deleted] · 2014-12-30T16:41:44.613Z · LW(p) · GW(p)
I'm not TheAncientGeek, but I'm also a proponent of tool / oracle AI, so maybe I can speak to that. The proposals I've seen basically break down into two categories:
(1) Assuming the problem of steadfast goals has been solved -- what MIRI refers to as highly reliable agents -- you build an agent which provides (partial) answers to questions while obeying fixed constraints. The easiest to analyze example would be "Give me a solution to problem X, in the process consuming no more than Y megajoules of energy, then halt." In this case the AI simply doesn't have the energy budget to figure out how to trick us into achieving evil goal Z.
(This energy-constrained agent is not the typical example given in arguments for tool AI. More often the constraints are whack-a-mole things like "don't make irreversible changes to your environment" or "don't try to increase your hardware capacity". IMHO this all too often clouds the issue, because it just generates a response of "what about situation Z", or "what if the AI does blah".)
(2) Build an agent inside of a box, and watch that box very carefully. E.g. this could be the situation in (1), but with an ampmeter attached to a circuit breaker to enforce the energy constraint (among many, many other devices used to secure and observe the AI). This approach sidesteps the issue of friendliness / alignment entirely. The AI may be unfriendly, but impotent.
As far as I can tell, the issue of "has a goal" vs "does not have a goal" does not enter into the above proposals at all. The only people I've seen making that distinction are arguing against tool AI but missing the point. Of course agents have goals, and of course oracle AI has goals -- just a more specific range of answer-the-question goals. The point is that oracle / tool AI has imposed constraints which limit their capability to do harm. They're safe not because of they provably work in our interests, but because they are too unempowered to do us harm.
Replies from: mgnb↑ comment by mgnb · 2014-12-31T06:07:06.736Z · LW(p) · GW(p)
Okay, that's fair enough.
In the context of Superintelligence, though, in Table 11 a Tool AI is defined thusly: 'Tool: A system not designed to exhibit goal-directed behaviour.' I am responding directly to that. But it sounds as though you would object to Bostrom's characterisation of tool proposals.
In Bostrom's parlance, I think your proposals for Tool AI would be described as (1) Oracle AI + stunting and (2) Oracle AI + boxing—the energy thing is interesting. I'm hopeful they would be safe, but I'm not convinced it would take much energy to pose an existential threat.
Replies from: None↑ comment by [deleted] · 2014-12-31T14:26:12.435Z · LW(p) · GW(p)
I haven't read Superintelligence (so maybe I shouldn't be posting here?), but I have read much of Bostrom earlier work, and yes I object to Bostrom's prior characterisations of tool proposals, which basically amount to strawman setups. Either that or i misunderstood the original tool AI posts and they really were that bad :\ In my mind at least, "tool AI" is simply a proposal for using oracle AI in a specific way, as a sort of intelligence augmentation for its human operators.
Regarding energy constraints, that's just one of an entire spectrum of possibilities. Approaching the problem from the other direction leads to suggestions such as cryptographically secure computational traces: you basically demand the AI to provide a subset of its call graph history as an audit log, but in a way that the AI doesn't know ahead of time what execution pathways will be demanded of it. You then have some sort of audit log checker or manual inspection of the trace and the instrumental goals it reveals. Faking the log would require a detectable amount of work not accounted for in the trace.
It is possible to construct much better boxes than critics of oracle AI would have you believe.
Replies from: William_S↑ comment by William_S · 2015-01-02T02:25:58.795Z · LW(p) · GW(p)
How do energy constraints defeat a strategy of this form: While energy constraints are low, answer easy questions, but fake failure on some hard questions claiming lack of resources Once given enough excess energy beyond that needed for a task, use the excess computing power to figure out a way to do unfriendly things
Do cryptographic traces place a limit on the complexity of tasks that you can solve? It seems like as task complexity increases, it will become harder to spot deception amongst legitimate computations (or the amount of human attention you need to achieve a fixed probability of detection scales according to problem complexity).
Replies from: None↑ comment by [deleted] · 2015-01-02T04:35:42.163Z · LW(p) · GW(p)
You can't fake failure. Whether it responds in time or not, a trace is provided. That trace, if it validates, provides a record of everything the program did (or rather a randomly selected subset, but that subset is not knowable in advance), even if it didn't lead to a usable answer. If not valid, you terminate and never run again.
To your second paragraph, these are open questions. But that's precisely my point--I think MIRI should be engaged in researching these sorts of things, and not be biased towards areas relating to their own preconceived notions of what an AGI experiment should look like.
↑ comment by TheAncientGeek · 2014-12-31T14:04:02.459Z · LW(p) · GW(p)
I can see that something that always pauses and waits for the next input might be understood as not an agent, is that something you might agree with?
Yes, I take a tool to be something that always waits, that defaults to doing nothing..
If everything has a goal, and goals are dangerous, everything is dangerous. Which is a false conclusion. So there must be a false assumption leading to it. Such as all systems having goals.
The kinds of danger MIRI is worrying about come from the way goals are achieved, eg from instrumental convergence, so MIRI shouldn't be worrying about goals absent adaptive strategies for achieving them, and in fact it hard to see what is gained from talking in those terms.
Replies from: mgnb↑ comment by mgnb · 2015-01-01T03:01:07.277Z · LW(p) · GW(p)
I also disagree with that false conclusion, but I would probably say that 'goals are dangerous' is the false premise. Goals are dangerous when, well, they actually are dangerous (to my life or yours,) and when they are attached to sufficient optimising power, as you get at in your last paragraph.
I think the line of argumentation Bostrom is taking here is that superintelligence by definition has a huge amount of optimisation power, so whether it is dangerous to us is reduced to whether its goals are dangerous to us.
(Happy New Year!)
Replies from: TheAncientGeek, None↑ comment by TheAncientGeek · 2015-01-01T14:00:48.168Z · LW(p) · GW(p)
MIRIs argument, which I agree with for once, is that a safe goal can have dangerous sub goals.
The tool AI proponents argument, as I understand it, is that a system that defaults to doing nothing is safer.
I think MIRI types are persistently mishearing that, because they have an entirely different set of presuppositions....that safety is all-or-nothing, not a series of mitigations. That safety is not a matter of engineering, but mathematical proof....not that you can prove anything behind the point where the uncertainty within the system is less than the uncertainty about the system.
↑ comment by TheAncientGeek · 2014-12-30T14:28:19.016Z · LW(p) · GW(p)
Assuming that acting without being prompted is the interesting feature of agents, tools won't be very like agents.
comment by Gunnar_Zarncke · 2014-12-30T17:02:49.317Z · LW(p) · GW(p)
I'd like to project the Google Maps as a tool example a bit into the future. A future I find looks plausible:
The route service has been expanded by Google to avoid traffic congestion by - basically - giving different people different recommendations. Lets assume that Google has sufficiently many devices giving feedback which route is actually used (this may happen due to simply tracking movement of the devices, Google Cars, whatever). Lets also assume that the route service is intended to incorporates further data about its users, e.g. locations previously visited, preferrred locations (these could be e.g. gleaned from search profiles, but also from incorporating or tracking otrher sources). Now that is a heavy amount of data to integrate. How about using a self-optimizing algorithm for dealing with all that data and dispense the 'best' recommendations over all users. That looks like a recipe where the simple sounding "give me a route from X to Y" effectively means "considering all the information I have about this user and lots of other users desiring to travel near X and Y how do I best ensure the 'goal' of getting him there and minimizing traffic jams". This could have lots of unexpected 'solutions' which the algorithm may learn from feedback from e.g. users stopping in their 'preferred' locations along the route, locations which lead to more accidents (e.g. if for some reason non-arrival isn't counted negatively). Exercise for the reader: What else can go wrong here?
And how would the Maps AI explain its operation: "I satisfy human values with cars and shopping."
comment by KatjaGrace · 2014-12-30T02:06:22.575Z · LW(p) · GW(p)
What did you most disagree with in this section?
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2014-12-30T14:49:35.270Z · LW(p) · GW(p)
The main problem is lack of clarity.
Replies from: JoshuaZ↑ comment by JoshuaZ · 2014-12-30T15:35:12.186Z · LW(p) · GW(p)
Can you expand?
Replies from: TRIZ-Ingenieur, TheAncientGeek↑ comment by TRIZ-Ingenieur · 2015-01-03T22:33:16.074Z · LW(p) · GW(p)
Agent, oracle and tool are not clearly differenciated. I question wether we should differenciate these types the way Bostrums does. Katja last week drew a 4-quadrant classification scheme with dimensions "goal-directedness" and "oversight". Realisations of AI would be classified into sovereign|genie|autonomous tool|oracle(tool) by some arbitrarily defined thresholds.
I love her idea to introduce dimensions, but I think this entire classification scheme is not helpful for our control debate. AI realisations will have a multitude of dimensions. Tagging certain realisations with a classification title may help to explain dimensions by typified examples. We should not discuss safety of isolated castes. We do not have castes, we will have different kinds of AIs that will be different in their capabilities and their restrictions. The higher the capability, the more sophisticated restrictive measures must be.
On the dimension goal directedness: Bostrum seems to love the concept of final goal (German: "Endziel"). After achieving a final goal there is emptiness, nothing remains to be done. This concept that is foreign to evolution. Evolution is not about final goals. Evolution has an ethernal goal: survival. To survive it is neccessary to be fit enough to survive long enough to generate offspring and protect and train it long enough until it can protect itself. If grandparent generation is available they serve as backup for parent generation and further safeguard and source of experience for the young endangered offspring.
Instrumental goals in evolution are: Nutrition, looking for protection, learning, offspring generation, protecting, teaching.
These instrumental goals are paired with senses, motivations and drives:
hunger/thirst, heat-sense/smelling/tasting/vision/hearing/fear, curiosity/playing, social behavior/sexuality, dominance behaviour/physical activity, teaching motivation.
All instrumental goals have to be met at least for a certain amount to achieve the ethernal goal: survival of species.
To define final goals as Bostrum points out on many occasions is dangerous and could lead to UFAI. To debate non-goal-directed types of AI is leading to nowhere. Non-goal-directed AI would do nothing else than thermodynamics: entropy will rise. To clarify our discussion we should state:
- Any AGI has goal directedness. Number and complexity of goals will differ significantly.
- Goals are fuzzy and can be contradictory. Partial solutions are acceptable for most goals.
- Goal-directedness is a priority measure in a diversity of goals.
- Any AGI has learning functionality.
- Safe FAI will have repellent behavior towards dangerous actions or states. (Anti-goals or taboos)
- Oversight over goals and taboos should be done by independent entities. (non-accessible to the AI)
Bostrum uses often goal and puts aside that we do not have to discuss about the end of the way but about the route and how to steer development if possible. A goal can be a "guiding star" if a higher entity knows it guides toward e.g. Bethlehem. Bostrums guiding star seems to be CE via FAI. Our knowledge about FAI is not advanced enough that we could formulate final goals or utility functions. Therefore I recommend not to focus our debate on diffuse final goal but on dimensions and gradients that point away from UFAI and towards controllability, transparency and friendliness.
↑ comment by TheAncientGeek · 2015-01-01T14:52:08.596Z · LW(p) · GW(p)
What is an agent? What is a tool? What us a goal?
comment by DanielFilan · 2020-08-18T02:06:27.670Z · LW(p) · GW(p)
Recent work on mesa-optimisation is relevant to the discussion of search IMO: see the paper Risks from Learned Optimization. Basically, the idea is that your search procedure finds a thing that's an agent, and it's not obvious that the agent it finds has the same goals as the search process.
comment by KatjaGrace · 2014-12-30T02:06:02.742Z · LW(p) · GW(p)
Do you think it is feasible to make powerful tool AIs without incidentally making powerful forces for pursuing particular goals?
Replies from: TheAncientGeek, None↑ comment by TheAncientGeek · 2014-12-30T14:46:39.443Z · LW(p) · GW(p)
Pursuing goals in an agent like way, without prompting, or in a tool like way?
comment by torekp · 2015-01-10T13:18:34.629Z · LW(p) · GW(p)
I found the idea of an AI that is not goal-directed very enticing. It seemed the perfect antidote to Omohundro et. al. on universal instrumental goals, because the latter arguments rely on a utility function, something that even human beings arguably don't have. A utility function is a crisp mathematical idealization of the concept of goal-direction. (I'll just assert that without argument, and hope it rings true.) If human beings, the example sine qua non of intelligence, don't exactly have utilities, might it not be possible to make other forms of intelligence that are even further from goal-directed behavior?
Unfortunately, Paul Christiano has convinced me that I was probably mistaken:
- We might try to write a program that doesn’t pursue a goal, and fail.
Issue [2] sounds pretty strange—it’s not the kind of bug most software has. But when you are programming with gradient descent, strange things can happen.
comment by Shmi (shminux) · 2014-12-30T03:29:16.938Z · LW(p) · GW(p)
I have trouble understanding how one can tell an agent from a non-agent without having access to its "source code", or at least its goals.
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2014-12-30T14:15:27.645Z · LW(p) · GW(p)
Goals are likely to be emergent in many systems, such as neural nets. OTOH, trainable neural would be corrigible.
comment by KatjaGrace · 2014-12-30T02:05:20.561Z · LW(p) · GW(p)
Do you think tool AI is likely to help with AI safety in any way?
Replies from: None, TRIZ-Ingenieur↑ comment by [deleted] · 2014-12-30T05:02:49.784Z · LW(p) · GW(p)
It sidesteps most of the issues, by leaving humans in the loop for the ethically concerning aspects of applications of AGI. So yes, it "helps" with AI safety by making AI safety partially redundant.
Replies from: torekp↑ comment by torekp · 2015-01-10T01:24:21.769Z · LW(p) · GW(p)
Please explain more, especially regarding Katja's point 5
- One obvious problem with tools is that they maintain humans as a component in all goal-directed behavior. If humans are some combination of slow and rare compared to artificial intelligence, there may be strong pressure to automate all aspects of decisionmaking, i.e. use agents.
Is there any solution better than attempting to make and enforce a treaty against moving from tool to agent?
Replies from: None↑ comment by [deleted] · 2015-01-10T12:23:50.948Z · LW(p) · GW(p)
First of all, those two assumptions of humans being slow and rare compared to artificial intelligence are dubious. Humans are slow at some things, but fast at others. If the architecture of the AGI differs substantially from the way humans think, it is very likely that the AGI would not be very fast at doing some things humans find easy. And early human-level AGIs are likely to consume vast supercomputing resources; they're not going to be cheap and plentiful.
But beyond that, the time frame for using tool AI may be very short, e.g. on the order of 10 years or so. There isn't a danger of long-term instability here.
↑ comment by TRIZ-Ingenieur · 2015-01-03T23:14:19.990Z · LW(p) · GW(p)
Yes. Tool AIs built solely for AGI safeguarding will become existential for FAI:
AIs can monitor AIs [Stephen Omohundro 2008, 52:45min]
Capsulated tool AIs will be building blocks of a safety framework around AGI. Regulations for aircraft safety request full redundancy by independently developed control channels from different suppliers based on separate hardware. If an aircraft fails a few hundred people die. If safety control of a high capable AGI fails humankind is in danger.
comment by azergante · 2024-08-30T19:26:59.806Z · LW(p) · GW(p)
My take on the tool VS agent distinction:
-
A tool runs a predefined algorithm whose outputs are in a narrow, well-understood and obviously safe space.
-
An agent runs an algorithm that allows it to compose and execute its own algorithm (choose actions) to maximize its utility function (get closer to its goal). If the agent can compose enough actions from a large enough set, the output of the new algorithm is wildly unpredictable and potentially catastrophic.
This hints that we can build safe agents by carefully curating the set of actions it chooses from so that any algorithm composed from the set produces an output that is in a safe space.
comment by timeholmes · 2014-12-30T22:06:22.442Z · LW(p) · GW(p)
It might be that a tool looks like an agent or v.v., according to one's perspective. I worry that something unexpected could bite us, like while concentrating on generating a certain output, the AI might tend to a different but invisible track that we can't see because it parallels our own desires. (The "goal" of EFFICIENCY we share with the AI, but if pursued blindly, our own goal will end up killing us!)
For instance, while being pleased that the Map gives us a short route, maybe the AI is actually giving us a solution based instead on a minimum of attention it gives to us, or some similar but different effect. We might blissfully call this perfect success until the time some subtler problem crops up where we realize we've been had, not so much by a scheming AI as by our own blindness to subtleties! Thus we served as our own evil agent, using a powerful tool unwisely.
comment by SilentCal · 2014-12-30T19:11:11.751Z · LW(p) · GW(p)
Note 2 seems worth discussing further. The key step, as I see it, is that the AI is not a communication consequentialist, and it does not model the effects of its advice on the world. I would suggest calling this "Ivory Tower AI" or maybe "Ivory Box".
To sketch one way this might work, queries could take the form "What could Agent(s) X do to achieve Y?" and the AI then reasons as if it had magic control over the mental states of X, formulates a plan, and expresses it according to predefined rules. Both the magic control and the expression rules are non-trivial problems, but I don't see any reason they'd be fr Friendliness-level difficult.
(just never ever let Agent X be "a Tool AI" in your query)
comment by The_Jaded_One · 2015-01-04T17:47:01.148Z · LW(p) · GW(p)
The fundamental problems with "tool AI" are
(1) The difficulty of specifying what it means for a superintelligent system to only have a limited or bounded effect.
(2) The difficulty of getting an oracle AI to "just tell the truth" when the questions you ask it don't have a simple, straight answer that can be told, and where the choices about what to say will have significant effects upon the world such that you would be better off explicitly having a sovereign AI because your oracle is now moonlighting as a sovereign when it chooses how to answer.