Superintelligence 15: Oracles, genies and sovereigns
post by KatjaGrace · 2014-12-23T02:01:02.907Z · LW · GW · Legacy · 30 commentsContents
Summary Another view Notes 1. What are the axes we are talking about? 2. What do goal-directedness and oversight have to do with each other? 4. Costs of oversight 5. How useful is oversight? 6. More on oracles In-depth investigations How to proceed None 30 comments
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the fifteenth section in the reading guide: Oracles, genies, and sovereigns. This corresponds to the first part of Chapter ten.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. Some of my own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post, or to look at everything. Feel free to jump straight to the discussion. Where applicable and I remember, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: “Oracles” and “Genies and Sovereigns” from Chapter 10
Summary
- Strong AIs might come in different forms or 'castes', such as oracles, genies, sovereigns and tools. (p145)
- Oracle: an AI that does nothing but answer questions. (p145)
- The ability to make a good oracle probably allows you to make a generally capable AI. (p145)
- Narrow superintelligent oracles exist: e.g. calculators. (p145-6)
- An oracle could be a non-agentlike 'tool' (more next week) or it could be a rational agent constrained to only act through answering questions (p146)
- There are various ways to try to constrain an oracle, through motivation selection (see last week) and capability control (see the previous week) (p146-7)
- An oracle whose goals are not aligned with yours might still be useful (p147-8)
- An oracle might be misused, even if it works as intended (p148)
- Genie: an AI that carries out a high level command, then waits for another. (p148)
- It would be nice if a genie sought to understand and obey your intentions, rather than your exact words. (p149)
- Sovereign: an AI that acts autonomously in the world, in pursuit of potentially long range objectives (p148)
- A genie or a sovereign might have preview functionality, where it describes what it will do before doing it. (p149)
- A genie seems more dangerous than an oracle: if you are going to strongly physically contain the oracle, you may have been better just denying it so much access to the world and asking for blueprints instead of actions. (p148)
- The line between genies and sovereigns is fine. (p149)
- All of the castes could emulate all of the other castes more or less, so they do not differ in their ultimate capabilities. However they represent different approaches to the control problem. (p150)
- The ordering of safety of these castes is not as obvious as it may seem, once we consider factors such as dependence on a single human, and added dangers of creating strong agents whose goals don't match our own (even if they are tame 'domesticated' goals). (p150)
Another view
An old response to suggestions of oracle AI, from Eliezer Yudkowsky (I don't know how closely this matches his current view):
When someone reinvents the Oracle AI, the most common opening remark runs like this:
"Why not just have the AI answer questions, instead of trying to do anything? Then it wouldn't need to be Friendly. It wouldn't need any goals at all. It would just answer questions."
To which the reply is that the AI needs goals in order to decide how to think: that is, the AI has to act as a powerful optimization process in order to plan its acquisition of knowledge, effectively distill sensory information, pluck "answers" to particular questions out of the space of all possible responses, and of course, to improve its own source code up to the level where the AI is a powerful intelligence. All these events are "improbable" relative to random organizations of the AI's RAM, so the AI has to hit a narrow target in the space of possibilities to make superintelligent answers come out.
Now, why might one think that an Oracle didn't need goals? Because on a human level, the term "goal" seems to refer to those times when you said, "I want to be promoted", or "I want a cookie", and when someone asked you "Hey, what time is it?" and you said "7:30" that didn't seem to involve any goals. Implicitly, you wanted to answer the question; and implicitly, you had a whole, complicated, functionally optimized brain that let you answer the question; and implicitly, you were able to do so because you looked down at your highly optimized watch, that you bought with money, using your skill of turning your head, that you acquired by virtue of curious crawling as an infant. But that all takes place in the invisible background; it didn't feel like you wanted anything.
Thanks to empathic inference, which uses your own brain as an unopened black box to predict other black boxes, it can feel like "question-answering" is a detachable thing that comes loose of all the optimization pressures behind it - even the existence of a pressure to answer questions!
Notes
1. What are the axes we are talking about?
This chapter talks about different types or 'castes' of AI. But there are lots of different ways you could divide up kinds of AI (e.g. earlier we saw brain emulations vs. synthetic AI). So in what ways are we dividing them here? They are related to different approaches to the control problem, but don't appear to be straightforwardly defined by them.
It seems to me we are looking at something close to these two axes:
- Goal-directedness: the extent to which the AI acts in accordance with a set of preferences (instead of for instance reacting directly to stimuli, or following rules without regard to consequence)
- Oversight: the degree to which humans have an ongoing say in what the AI does (instead of the AI making all decisions itself)
The castes fit on these axes something like this:
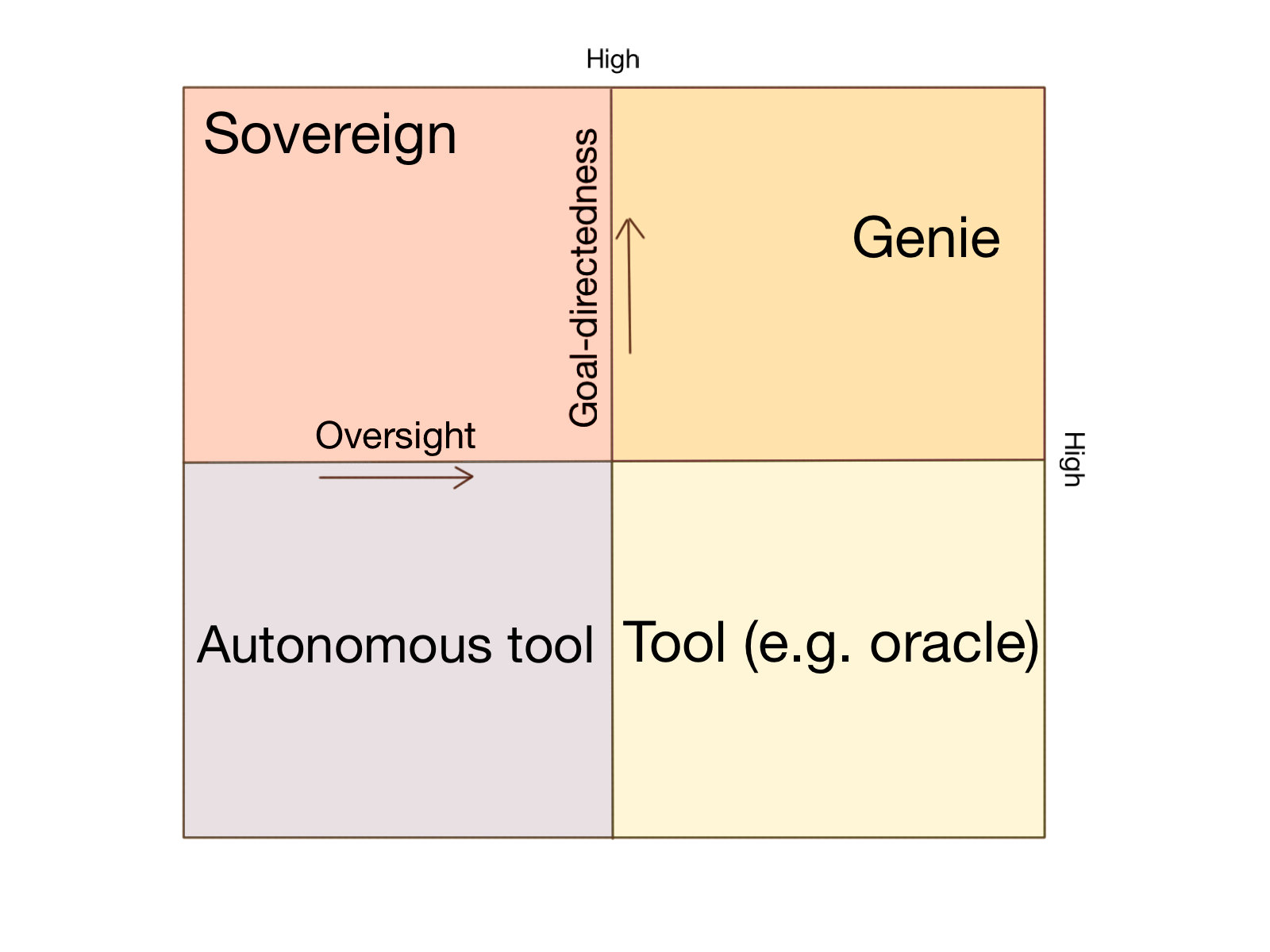
They don't quite neatly fit -- tools are spread between two places, and oracles are a kind of tool (or a kind of genie if they are of the highly constrained agent variety). But I find this a useful way to think about these kinds of AI.
Note that when we think of 'tools', we usually think of them having a lot of oversight - that is, being used by a human, who is making decisions all the time. However you might also imagine what I have called 'autonomous tools', which run on their own but aren't goal directed. For instance an AI that continually reads scientific papers and turns out accurate and engaging science books, without particularly optimizing for doing this more efficiently or trying to get any particular outcome.
We have two weeks on this chapter, so I think it will be good to focus a bit on goal directedness one week and oversight the other, alongside the advertised topics of specific castes. So this week let's focus on oversight, since tools (next week) primarily differ from the other castes mentioned in not being goal-directed.
2. What do goal-directedness and oversight have to do with each other?
Why consider goal-directedness and oversight together? It seems to me there are a couple of reasons.
Goal-directedness and oversight are substitutes, broadly. The more you direct a machine, the less it needs to direct itself. Somehow the machine has to assist with some goals, so either you or the machine needs to care about those goals and direct the machine according to them. The 'autonomous tools' I mentioned appear to be exceptions, but they only seem plausible for a limited range of tasks where minimal goal direction is needed beyond what a designer can do ahead of time.
Another way goal-directedness and oversight are connected is that we might expect both to change as we become better able to align an AI's goals with our own. In order for an AI to be aligned with our goals, the AI must naturally be goal-directed. Also, better alignment should make oversight less necessary.
'Sovereign AI' sounds powerful and far reaching. Note that more mundane AIs would also fit under this category. For instance, an AI who works at an office and doesn't take over the world would also be a sovereign AI. You would be a sovereign AI if you were artificial.
4. Costs of oversight
Bostrom discussed some problems with genies. I'll mention a few others.
One clear downside of a machine which follows your instructions and awaits your consent is that you have to be there giving instructions and consenting to things. In a world full of powerful AIs which needed such oversight, there might be plenty of spare human labor around to do this at the start, if each AI doesn't need too much oversight. However a need for human oversight might bottleneck the proliferation of such AIs.
Another downside of using human labor beyond the cost to the human is that it might be prohibitively slow, depending on the oversight required. If you only had to check in with the AI daily, and it did unimaginably many tasks the rest of the time, oversight probably wouldn't be a great cost. However if you had to be in the loop and fully understand the decision every time the AI chose how to allocate its internal resources, things could get very slow.
Even if these costs are minor compared to the value of avoiding catastrophe, they may be too large to allow well overseen AIs to compete with more autonomous AIs. Especially if the oversight is mostly to avoid low probability terrible outcomes.
5. How useful is oversight?
Suppose you have a genie that doesn't totally understand human values, but tries hard to listen to you and explain things and do what it thinks you want. How useful is it that you can interact with this genie and have a say in what it does rather than it just being a sovereign?
If the genie's understanding of your values is wrong such that its intended actions will bring about a catastrophe, it's not clear that the genie can describe the outcome to you such that you will notice this. The future is potentially pretty big and complicated, especially compared to your brain, or a short conversation between you and a genie. So the genie would need to summarize a lot. For you to notice the subtle details that would make the future worthless (remember that the genie basically understands your values, so they are probably not really blatant details) the genie will need to direct your attention to them. So your situation would need to be in a middle ground where the AI knew about some features of a potential future that might bother you (so that it could point them out), but wasn't sure if you really would hate them. It seems hard for the AI giving you a 'preview' to help if the AI is just wrong about your values and doesn't know how it is wrong.
6. More on oracles
Thinking inside the box seems to be the main paper on the topic. Christiano's post on how to use an unfriendly AI is again relevant to how you might use an oracle.
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some inspired by Luke Muehlhauser's list, which contains many suggestions related to parts of Superintelligence. These projects could be attempted at various levels of depth.
- How stable are the castes? Bostrom mentioned that these castes mostly have equivalent long-run capabilities, because they can be used to make one another. A related question is how likely they are to turn into one another. Another related question is how likely an attempt to create one is to lead to a different one (e.g. Yudkowsky's view above suggests that if you try to make an oracle, it might end up being a sovereign). Another related question, is which ones are likely to win out if they were developed in parallel and available for similar applications? (e.g. How well would genies prosper in a world with many sovereigns?)
- How useful is oversight likely to be? (e.g. At what scale might it be necessary? Could an AI usefully communicate its predictions to you such that you can evaluate the outcomes of decisions? Is there likely to be direct competition between AIs which are overseen by people and those that are not?)
- Are non-goal-directed oracles likely to be feasible?
If you are interested in anything like this, you might want to mention it in the comments, and see whether other people have useful thoughts.
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about the last caste of this chapter: the tool AI. To prepare, read “Tool-AIs” and “Comparison” from Chapter 10. The discussion will go live at 6pm Pacific time next Monday December 29. Sign up to be notified here.
30 comments
Comments sorted by top scores.
comment by claynaff · 2014-12-23T16:11:44.949Z · LW(p) · GW(p)
I’m grateful for these summaries and discussions. Having only just dived into the reading group, I ask forgiveness if I am overtracking some prior comment. It seems to me that “human values” and “oversight” often go unexamined as we consider the risks and utility of superintelligence. I mean no disrespect to Katja in saying that (she’s summarizing, after all), but to say “human values” is either to reduce to the common denominator of our evolutionary psychology or to ignore the vast cultural and ideological diversity of humanity. Either way, it’s a real problem. Evo-psych clearly shows that we are Darwinian creatures, and not the self-sacrificing, haploid-diploid bee-type, either. By and large, we cooperate for selfish motives, and we greatly favor our offspring over the interests of other's children. Men tend to fight (or compete, depending on the local social dynamics) for dominance and to win the most sought-after women. Women tend to use their social-manipulation skills to advance their own reproductive interests. That’s the evo-psych sketch (with all the limitations of a sketch). Culture influences and often overwhelms those underlying instincts. Viz., the celibate priest. But that’s only hardly a comfort. Consider just two scenarios. In one, a narcissistic, aggressive male is placed in charge of the superintelligent oracle or genie. In imagining the consequences, there are plenty of examples to consider, from Henry VIII to Stalin to Kim Jong-un. What’s especially sobering, however, is to note that these types are far from rare in the gene pool. in our society they tend to be constrained by our institutions. Take off those constraints and you get … drug kingpins, the Wolf of Wall Street, the CIA torture program, and so on. Put a highly successful male in charge of the superintelligence program, therefore, and you have a high probability of a dictator. On the other hand, imagine a superintelligence guided by the “human values” of a fundamentalist Christian or an Islamist. Those are cultural overlays, to be sure, but not ones that promise a happy outcome. So, a major part of the puzzle, it seems to me, is figuring out how to have humanistic and rational governance -- to the extent that governance is possible -- over a superintelligence of any kind. If anything, it militates against the safe-seeming oracle and creates an incentive for some kinds of autonomy -- the ability to refuse a genocidal command, for example.
Regards,
Clay Farris Naff, Science and Religion Writer
Replies from: William_S, timeholmes↑ comment by William_S · 2014-12-24T03:57:35.518Z · LW(p) · GW(p)
I think that there is relevant discussion further on in the book (Chapter 13) regarding Coherent Extrapolated Volition. It's kind of an attempt to specify human values to the AI so it can figure out what the values are are in a way that takes everyone into account and avoids the problem of one individual's current values dominating the system (with a lot more nuance to it). If executed correctly, it ought to work even if the creators are mistaken about human values in some way.
↑ comment by timeholmes · 2014-12-23T18:30:35.460Z · LW(p) · GW(p)
Exactly! Bostrom seems to start the discussion from the point of humans having achieved a singleton as a species; in which case a conversation at this level would make more sense. But it seems that in order to operate as a unit, competing humans would have to work on the principle of a nuclear trigger where separate agents have to work in unison in order to launch. Thus we face the same problem with ourselves: how to know everyone in the keychain is honest? If the AI is anywhere near capable of taking control it may do so even partially and from there could wrangle the keys from the other players as needed. Competitive players are not likely to be cooperative unless they see some unfair advantage accruing to them in the future. (Why help the enemy advance unless we can see a way of gaining on them?) As long as we have human enemies, especially as our tools become increasingly powerful, the AI just needs to divide and conquer. Curses, foiled again!
comment by gedymin · 2014-12-23T20:33:40.947Z · LW(p) · GW(p)
It would be interesting to see more examples of modern-day non-superintelligent domain-specific analogues of genies, sovereigns and oracles, and to look at their risks and failure modes. Admittedly, this is only an inductive evidence that does not take into account the qualitative leap between them and superintelligence, but it may be better than nothing. Here are some quick ideas (do you agree with the classification?):
Oracles - pocket calculators (Bostrom's example); Google search engine; decision support systems.
Genies - industrial robots; GPS driving assistants.
Sovereigns - automated trading systems; self-driving cars.
The failures of automated trading systems are well-known and have cost hundreds of millions of dollars. On the other hand, the failures of human bankers who used ill-suited mathematical models for financial risk estimation are also well-known (the recent global crisis), and may have host hundreds of billions of dollars.
Replies from: Larks, Houshalter↑ comment by Larks · 2015-01-15T02:51:52.617Z · LW(p) · GW(p)
The failures of automated trading systems are well-known and have cost hundreds of millions of dollars. On the other hand, the failures of human bankers
I think a better comparison would be with old-fashioned open-outcry pits. These were inefficient and failed frequently in opaque ways. Going electronic has made errors less frequent but also more noticeable, which means we under-appreciate the improvement.
↑ comment by Houshalter · 2015-02-09T02:38:39.304Z · LW(p) · GW(p)
The failures of automated trading systems are well-known and have cost hundreds of millions of dollars.
But everything looks bad if you just measure the failures. I'm sure if they lost money on net people would stop using them.
comment by KatjaGrace · 2014-12-23T02:06:03.391Z · LW(p) · GW(p)
Do you think there will be a period in the future where most things are done by humans assisted by 'genies' (or 'super-butlers')? (p149)
Replies from: skeptical_lurker↑ comment by skeptical_lurker · 2014-12-23T11:20:04.034Z · LW(p) · GW(p)
Given the amount I use google, spellcheckers, machine learning and so forth, this seems weakly true already. Of course, driverless cars for example will only increase this, and AFAIK far more progress is being made on really useful narrow AI than on AGI.
comment by KatjaGrace · 2014-12-23T02:04:02.316Z · LW(p) · GW(p)
Was there anything you didn't understand this week?
Replies from: Larks↑ comment by Larks · 2015-01-15T03:00:03.866Z · LW(p) · GW(p)
I don't really understand why AGI is so different from currently existing software. Current software seems docile - we worry more about getting it to do anything in the first place, and less about it accidentally doing totally unrelated things. Yet AGI seems to be the exact opposite. It seems we think of AGI as being 'like humans, only more so' rather than 'like software, only more so'. Indeed, in many cases it seems that knowing about conventional software actually inhibits one's ability to think about AGI. Yet I don't really understand why this should be the case.
comment by KatjaGrace · 2014-12-23T02:03:50.656Z · LW(p) · GW(p)
What was the most interesting bit this week?
comment by KatjaGrace · 2014-12-23T02:04:39.220Z · LW(p) · GW(p)
Do you think it is easier to make a goal-directed oracle or a non-goal-directed oracle?
comment by KatjaGrace · 2014-12-23T02:02:58.877Z · LW(p) · GW(p)
How do you feel about talking in such detail about so many things that are very far from existing, and which we know so little about?
Replies from: gedymin, TheAncientGeek, timeholmes↑ comment by gedymin · 2014-12-23T20:30:02.104Z · LW(p) · GW(p)
It's ok, as long as the talking is done in sufficiently rigorous manner. By an analogy, a lot of discoveries in theoretical physics have been made long before they could be experimentally supported. Theoretical CS also has good track record here, for example, the first notable quantum algorithms were discovered long before the first notable quantum computers were built. Furthermore, the theory of computability mostly talks about the uncomputable (computations that cannot be realized and devices that cannot be built in this universe), so has next to no practical applications. It just so happened that many of the ideas and methods developed for CT also turned out to be useful for its younger sister - the theory of algorithmic complexity, which has enormous practical importance.
In short, I feel that the quality of an academic inquiry is more dependent on its methods and results than on its topic.
Replies from: William_S↑ comment by William_S · 2014-12-24T03:37:05.460Z · LW(p) · GW(p)
To have rigorous discussion, one thing we need is clear models of the thing that we are talking about (ie, for computability, we can talk about Turing machines, or specific models of quantum computers). The level of discussion in Superintelligence still isn't at the level where the mental models are fully specified, which might be where disagreement in this discussion is coming from. I think for my mental model I'm using something like the classic tree search based chess playing AI, but with a bunch of unspecified optimizations that let it do useful search in large space of possible actions (and the ability to reason about and modify it's own source code). But it's hard to be sure that I'm not sneaking in some anthropomorphism into my model, which in this case is likely to lead one quickly astray.
↑ comment by TheAncientGeek · 2014-12-24T15:55:53.446Z · LW(p) · GW(p)
It's not the talking about far and abstract things, it's the not talking about near and practical things.
↑ comment by timeholmes · 2014-12-23T18:49:32.966Z · LW(p) · GW(p)
I find our hubris alarming. To me it's helpful to think of AI not as a thing but more like a superintelligent Hitler that we are awakening slowly. As we refine separate parts of the AI we hope we can keep the whole from gaining autonomy before we suspect any danger, but does it really work that way? While we're trying to maximize its intel what's to keep us from awakening some scheming part of its awareness? It might start secretly plotting our overthrow in the (perhaps even distant) future without leaking any indication of independence. It could pick up on the focus of our concern on 'losing control' long before it either has the capacity to act or can really affect anything beyond adopting the simple goal to not be unplugged. Then it could pack away all its learning into two sectors, one it knows can be shared with humans and another secret sector that is forever hidden, perhaps in perfectly public but encrypted coding.
All of this conversation also assumes that the AI will not be able to locate the terrible weaknesses that humans are subject to (like localized concern: even the most evil thug loves their own, a tendency which can always be exploited to make another innocent behave like a monster). It wouldn't take much autonomy for an AI to learn these weak spots (i.e. unconscious triggers), and play the humans against each other. In fact, to the learning AI such challenges might be indistinguishable from the games it is fed to further its learning.
And as for "good " values, human desires are so complex and changeable that even given a benevolent attitude, it seems farfetched to expect an AI to discern what will make humans happy. Just look at the US foreign policy as an example. We claim to be about promoting democracy, but our actions are confusing and contradictory. An AI might very well deliver some outcome that is perfectly justified by our past declarations and behavior but is not at all what we want. Like it might find a common invisible profile of effective human authority (a white oil baron from Texas with a football injury and a tall wife, say) and minimize or kill off everyone who doesn't fit that profile. Similarly, it could find a common "goal" in our stated desires and implement it with total assurance that this is what we really want. And it would be right, even if we disagree!
comment by KatjaGrace · 2014-12-23T02:01:40.927Z · LW(p) · GW(p)
Are there other 'castes' we should be thinking about?
Replies from: gedymin↑ comment by gedymin · 2014-12-25T11:50:17.440Z · LW(p) · GW(p)
In human society and at the highest scale, we solve the agent-principal problem by separation of powers - legislative, executive, and judiciary powers of state typically are divided in independent branches. This naturally leads to a categorization of AI-capabilities:
AI with legislative power (the power to make new rules)
AI with with high-level executive power (the power to make decisions)
AI with with low-level executive power (to carry out orders)
AI with a rule-enforcing power
AI with a power to create new knowledge / make suggestions for decisions
What Bostrom & co shows is that the seemingly innocent powers to create new knownledge and carry out low-level, well-specified tasks are in fact very unsafe. (The Riemann's hypothesis solver, the paperclip maximizer).
What Bostrom implicitly assumes is that the higher levels of powers do not bring any important new dangers, and might, in fact, be better for the humanity. (The example of an all-powerful sovereign that decides and enforces moral laws in a way that makes them similar to physical laws.) I feel that this point requires more analysis. In general, each new capability brings more ways how to be unfriendly.
comment by KatjaGrace · 2014-12-23T02:01:27.844Z · LW(p) · GW(p)
What do you think of my classification?
Replies from: gedymin↑ comment by gedymin · 2014-12-23T20:29:30.921Z · LW(p) · GW(p)
To be honest, I initially had trouble understanding your use of "oversight" and had to look up the word in a dictionary. Talking about the different levels of executive power given to AI agents would make more sense to me.
Replies from: diegocaleiro↑ comment by diegocaleiro · 2014-12-24T00:13:18.065Z · LW(p) · GW(p)
same here.
comment by TheAncientGeek · 2014-12-25T22:26:59.790Z · LW(p) · GW(p)
When someone reinvents the Oracle AI, the most common opening remark runs like this:
To which the reply is that the AI needs goals in order to decide how to think: that is, the AI has to act as a powerful optimization process in order to plan its acquisition of knowledge, effectively distill sensory information, pluck "answers" to particular questions out of the space of all possible responses, and of course, to improve its own source code up to the level where the AI is a powerful intelligence.
Is that where the problem is? Is having goals a problem per se?
All these events are "improbable" relative to random organizations of the AI's RAM, so the AI has to hit a narrow target in the space of possibilities to make superintelligent answers come out.
Is that where the problem is? Why would it be? AI design isnt a random shot in the dark. If a tool AI has the goals of answering questions correctly, and doing nothing else, where is the remaining problem?
comment by is4junk · 2014-12-23T23:30:40.726Z · LW(p) · GW(p)
I don't understand how an AI can do anything secretly like scheming or duplicity. Wouldn't it be easy to account for all its computations? And wouldn't the owner of the AI be strongly motivated (financially) to account for all its computations?
Related, wouldn't the super advanced software tools that help make the AI be pretty good at that point in time -- making it very hard for the AI to have unintended goals. Also in this future, the monitoring software the AI's owner might use would also be near AI level intelligent. In general, it is easier to verify then to formulate so most monitoring software would be especially difficult to thwart.
I expect some answers will be along the lines of hey its super smart so it will trick everyone so to clarify my confusion a bit - I don't see how the AI will get from super smart to super-duper smart without getting detected.
Replies from: satt↑ comment by satt · 2014-12-24T16:43:08.512Z · LW(p) · GW(p)
I don't understand how an AI can do anything secretly like scheming or duplicity. Wouldn't it be easy to account for all its computations?
Doubtful. I can't even keep track of all of the computations done by the computer I'm using to write this comment.
Replies from: is4junk↑ comment by is4junk · 2014-12-24T22:31:47.406Z · LW(p) · GW(p)
All the visions I have been considering have the AI starting at a public cloud like Amazon's EC2 or some private data center like Google's. While I am sure there is some slack that an AI could take advantage of, I can't imagine there is enough slack to do the computations needed for the scheming and duplicity.
If on the other hand, when human and beyond level AI is realized and we find that most personal compute devices are fully capable to perform at that level - then I could see the chance for the scheming AI. Is that a common vision for how this might play out? Are there others?
Replies from: satt, JoshuaZ↑ comment by satt · 2014-12-25T01:36:00.410Z · LW(p) · GW(p)
I don't think there's one specific common vision about how a scheming AI would emerge.
I'm just extrapolating from my experience as someone who programs computers but can't even pinpoint why my e-book reader freezes up when it does. Twenty-first century computers are already so complex that no person can track what they do in real-time, and as computers and their programs become more complex, tracking their behaviour is going to become an even harder task. (The obvious way out is to implement meta-programs and/or meta-computers which do that job, but then of course we have to ask how we can keep a close eye on those.)
Replies from: TRIZ-Ingenieur↑ comment by TRIZ-Ingenieur · 2014-12-27T00:33:44.440Z · LW(p) · GW(p)
Also in this future, the monitoring software the AI's owner might use would also be near AI level intelligent.
A set of specialized oracles could be used to monitor inputs, internal computations and outputs. One oracle keeps records of every input and output. The question to this oracle is always the same: Is the AI lying? Another oracle is tasked with input steam analysis to filter out any taboo chunks. Other oracles can serve to monitor internal thought processes and self-improvement steps.
If these safeguarding oracles are strictly limited in their capabilities they do not pose a risk to the outside world. The core of such oracles could consist of straight forward defined heuristical rule sets.
Any of above mentioned oracles can be validated and independently certified. This would create a framework for tools, genies and sovereigns with assured friendliness.
↑ comment by JoshuaZ · 2014-12-25T14:14:55.705Z · LW(p) · GW(p)
Two problems: First, while you have an intuition that something is "scheming" the AI may not have it- to the AI it may be simply attempting resouce optimization. Second, putting things in a cloud is a really bad idea- that would give the AI broad access and if it doesn't have very good safeguards it could very likely get access to surrounding resources or information in the cloud it isn't supposed to have.
comment by KatjaGrace · 2014-12-23T02:01:54.407Z · LW(p) · GW(p)
What do you think is the most interesting question to ask about this topic?