Parsing Chris Mingard on Neural Networks
post by Alex Flint (alexflint) · 2021-05-06T22:16:14.610Z · LW · GW · 26 commentsContents
Outline Introduction Simple mappings occupy larger volumes in parameter space Mappings occupying larger parameter space volumes are more likely to be selected Scalability Relevance to AI safety None 26 comments
This is independent research. To make further posts like this possible, please consider supporting me.
Epistemic status: This is my understanding of multiple years of technical work by several researchers in just a few days of reading.
Outline
-
I attempt to summarize some of Chris Mingard’s recent work on why neural networks generalize so well.
-
I examine one chunk of work that argues that mappings with low Kolmogorov complexity occupy large volumes in neural network parameter space.
-
I examine a second chunk of work that argues that standard neural network training algorithms select mappings with probability proportional to their volume in parameter space.
Introduction
During the 2000s, very few machine learning researchers expected neural networks to be an important part of the future of their field. Papers were rejected from major machine learning conferences with no reason given other than that neural networks were uninteresting to the conference. I was at a computer vision conference in 2011 at which there was a minor uproar after one researcher suggested that neural networks might replace the bespoke modelling work that many computer vision professors had built their careers around.
But neural networks have in fact turned out to be extremely important. Over the past 10 years we have worked out how to get neural networks to perform well at many tasks. And while we have developed a lot of practical know-how, we have relatively little understanding of why neural networks are so surprisingly effective. We don’t actually have many good theories about what’s going on when we train a neural network. Consider the following conundrum:
-
We know that large neural networks can approximate almost any function whatsoever.
-
We know that among all the functions that one might fit to a set of data points, some will generalize well and some will not generalize well.
-
We observe that neural networks trained with stochastic gradient descent often generalize well on practical tasks.
Since neural networks can approximate any function whatsoever, why is it that practical neural network training so often selects one that generalizes well? This is the question addressed by a recent series of papers by Chris Mingard.
The basic up-shot of Chris’ work, so far as I can tell, is the following:
-
The optimization methods that we use to train neural networks are more likely to select mappings that occupy large volumes of neural network parameter space than functions that occupy small volumes of neural network parameter space.
-
Most of the volume of neural network parameter space is occupied by simple mappings.
These are highly non-obvious results. There is no particular reason to expect neural networks to be set up in such a way that their parameter space is dominated by simple mappings. The parameter space of polynomial functions, for example, is certainly not dominated by simple mappings.
Chris’ work consists of a combination of empirical and theoretical results that suggest but do not decisively prove the above claims. In this post I will attempt to explain my understanding of these results.
Simple mappings occupy larger volumes in parameter space
Chris’ work is all about volumes occupied by different functions in parameter space. To keep things simple, let’s consider a machine learning problem in which the inputs are tiny 2x2 images with each pixel set to 0 or 1, and the output is a single 0 or 1:
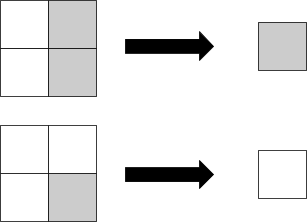
Since there are 4 input pixels and each one can be either a 0 or a 1, there are 16 possible inputs. Each one of those inputs could be mapped to either a 0 or 1 as output, so there are 2^16 = 65,536 possible mappings from inputs to outputs. Any neural network with four input neurons and one output neuron is going to express one of these 65,536 possible mappings[1]. We could draw out the whole space of possible neural network parameters and label each point in that space according to which of the 65,536 mappings it expresses:
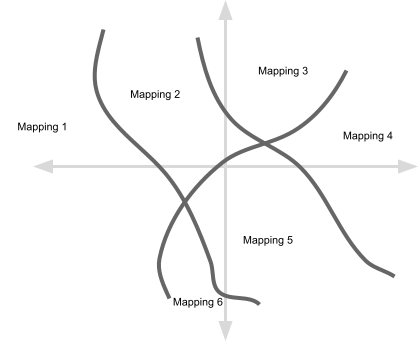
Each point in the above diagram represents a particular setting of the parameters in a neural network. I have drawn just two dimensions but there will be far more parameters than this. And I have drawn out volumes for 6 mappings but we would expect all 65,536 mappings to show up somewhere within the parameter space.
So given the picture above, we can now ask: do each of the 65,536 mappings occupy equal-sized volumes? Or do some occupy larger volumes than others? And if some mappings do occupy larger volumes than others then is there any pattern to which mappings occupy larger versus smaller volumes?
Chris’ work suggests that some mappings do in fact occupy larger volumes than others, and that it is the mappings with low Kolmogorov complexity that occupy larger volumes. What does it mean for a mapping to have a low Kolmogorov complexity? It means that there is a short computer program that implements the mapping. For example, the mapping that outputs 0 if there are an even number of black pixels in the input image and otherwise outputs 1 has a low Kolmogorov complexity because this mapping can be computed by XOR’ing all the input pixels together, whereas the mapping that outputs 0 for some randomly chosen arrangements of input pixels and otherwise outputs 1 has high Kolmogorov complexity because any computer program that computes this mapping will have to include a big lookup table within its source code. It is important to understand that when we talk about complexity we are talking about the length of a hypothetical computer program that would compute the same mapping that a given neural network computes. Also, (John reminds us)[https://www.lesswrong.com/posts/5p4ynEJQ8nXxp2sxC/parsing-chris-mingard-on-neural-networks?commentId=fzkGYmHsKdFx5dyzb [LW(p) · GW(p)]] that the paper uses a proxy for simplicity that is actually pretty different from Kolmogorov complexity.
In order to demonstrate this, Chris worked with the well-known MNIST dataset, which contains images of handwritten digits of 28x28 pixels. This means that the number of possible images is 2^56, since in this dataset there are two possible pixel values, and the number of possible mappings is 10(256), since in this dataset there are 10 possible outputs. This is a very large number, which makes it infeasible to explore the entire space of mappings directly. Also, Kolmogorov complexity is uncomputable. So there was quite a bit of analytical and experimental work involved in this project. This work is summarized in the blog post "Deep Neural Networks are biased, at initialisation, towards simple functions", with references to the underlying technical papers. The conclusions are not definitive but they are highly suggestive, and they suggest that mappings with lower Kolmogorov complexity occupy relatively larger volumes in parameter space.
This sheds some light on the question of why trained neural networks generalize well. We expect that mappings with low Kolmogorov complexity will generalize better than mappings with high Kolmogorov complexity, due to Occam’s razor, and it seems that mappings with low Kolmogorov complexity occupy larger parameter space volumes than mappings with high Kolmogorov complexity.
Mappings occupying larger parameter space volumes are more likely to be selected
The next question is: do the optimization algorithms we use to train neural networks care at all about the volume that a given mapping occupies in parameter space? If the optimization algorithms we use to train neural networks are more likely to select mappings that occupy large volumes in parameter space then we are one step closer to understanding why neural networks generalize, since we already have evidence that simpler mappings occupy larger volumes in parameter space, and we expect simpler mappings to generalize well. But they might not be more likely to select mappings that occupy large volumes in parameter space. Optimizations algorithms are designed to optimize, not to sample in an unbiased way.
A second blog post by Chris summarizes further empirical and theoretical work suggesting that yes, the optimization algorithms we use to train neural networks are in fact more likely to select mappings occupying larger volumes in parameter space. That blog post is called "Neural networks are fundamentally Bayesian", but it seems to me that viewing this behavior as Bayesian, while reasonable, is actually not the most direct way to understand what’s going on here.
What is really going on here is that within our original parameter space we eliminate all mappings except for the ones that perfectly classify every training image. We don’t normally train to 100% accuracy in machine learning but doing so in these experiments is a nice way to simplify things. So our parameter space now looks like this:
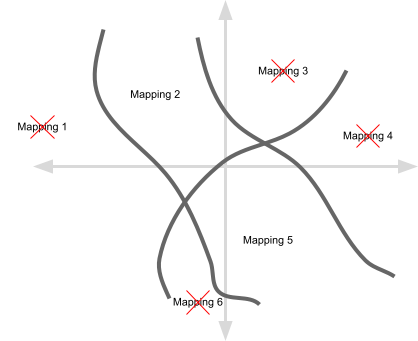
The question is now: for the mappings that remain, is the standard neural network training algorithm (stochastic gradient descent) more likely to select mappings that occupy larger volumes in parameter space?
To investigate this, Chris compared the following methods for selecting a final set of neural network parameters:
-
Select neural network parameters at random until we find one that perfectly classifies every image in our training set, and output those parameters.
-
Train a neural network using the standard neural network training algorithm (stochastic gradient descent) and output the result.
We know that method 1 is more likely to select mappings that occupy larger volumes in parameter space because it is sampling at random from the entire parameter space, so a mapping that occupies twice the parameter space volume as some other mapping is twice as likely to be selected. So by comparing method 1 to method 2 we can find out whether practical neural network training algorithms have this same property.
But actually running method 1 is infeasible since it would take too long to find a set of neural network parameters that perfectly classify every image in the training set if sampling at random, so much of the work that Chris did was about finding a good approximation to method 1. To read about the specific methods that Chris used, see the blog post linked above and the technical papers linked from that post.
The basic picture that emerges is nicely illustrated in this graphic from the blog post linked above:
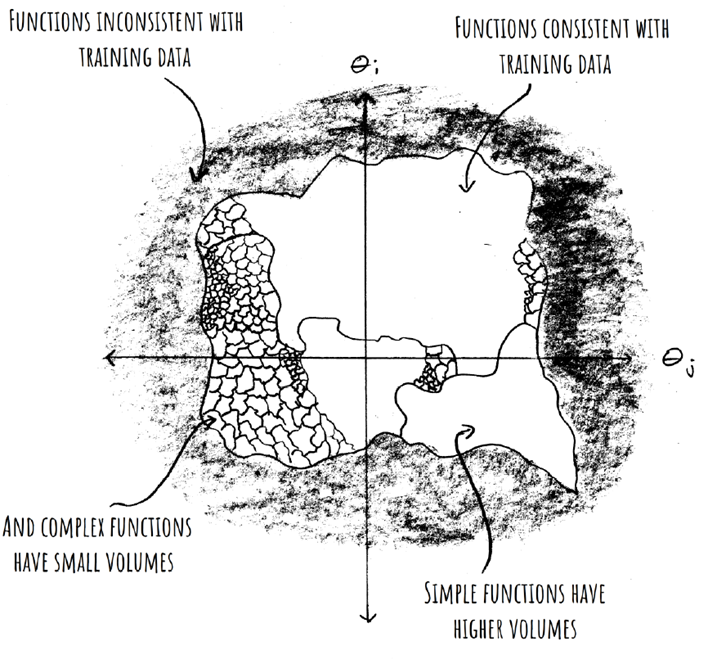
Scalability
This section added based on this helpful comment by interstice [LW(p) · GW(p)].
Both of the claims discussed above are supported by a mixture of theoretical and empirical results. The empirical results are based on machine learning tasks that are relatively small-scale. This is understandable because the experiments involve re-training networks hundreds of thousands of times from scratch, which would be very expensive for the largest networks and problems being tackled today. However, it leaves open the question of whether these results will continue to hold as we run experiments with larger-scale networks and problems.
For further discussion of the likely reach of the results discussed here see this excellent post and its associated comments [LW · GW].
Relevance to AI safety
If we want to align contemporary machine learning systems, we need to understand how and why those systems work. There is a great deal of work in machine learning that aims to find small "tips and tricks" for improving performance on this or that dataset. This kind of work does not typically shed much light on how or why our basic machine learning systems work, and so does not typically help move us towards a solution to the alignment problem. Chris’ work does shed light on how and why our basic machine learning systems work. It also provides an excellent example of how to perform the kind of empirical and theoretical work sheds light on how and why our basic machine learning systems work. I am excited to follow further developments in this direction.
the output neuron will be treated as a 1 if is positive or a 0 otherwise ↩︎
26 comments
Comments sorted by top scores.
comment by johnswentworth · 2021-05-06T23:02:52.505Z · LW(p) · GW(p)
Minor note: I think "mappings with low Kolmogorov complexity occupy larger volumes" is an extremely misleading way to explain what the evidence points to here. (Yes, I know Chris used that language in his blog post, but he really should not have.) The intuition of "simple mappings occupy larger volumes" is an accurate summary, but the relevant complexity measure is very much not Kolmogorov complexity. It is a measure which does not account for every computable way of compressing things, only some specific ways of compressing things.
In a sense, the results are more interesting in this light, since they tell us something about which specific ways of compressing things are relevant to our particular world. Since we cannot compute all the various ways of compressing things (i.e. Kolmogorov complexity and basically everything adjacent to it is uncomputable), this is a useful thing to know.
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-05-07T16:19:10.418Z · LW(p) · GW(p)
Thanks for this clarification John.
In a sense, the results are more interesting in this light, since they tell us something about which specific ways of compressing things are relevant to our particular world
But did Mingard et al show that there is some specific practical complexity measure that explains the size of the volumes occupied in parameter space better than alternative practical complexity measures? If so then think we would have uncovered an even more detailed understanding of which mappings occupy large volumes in parameter space, and since neural nets just generally work so well in the world, we could say that we know something about what kind of compression is relevant to our particular world. But if they just used some practical complexity measure as a rough proxy for Kolmogorov complexity then it leaves open the door for mappings occupying large volumes in parameter space to be simple according to many more ways of compressing things than were used in their particular complexity measure.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-05-08T16:46:22.510Z · LW(p) · GW(p)
Yeah, I don't think there was anything particularly special about the complexity measure they used, and I wouldn't be surprised if some other measures did as-well-or-better at predicting which functions fill large chunks of parameter space.
Replies from: Chris Mingard↑ comment by Chris Mingard · 2021-05-12T18:16:51.928Z · LW(p) · GW(p)
I 100% agree that Kolmogorov complexity is not the best measure of complexity here - and I would refer anyone to yours and Joar's comments at https://www.lesswrong.com/posts/YSFJosoHYFyXjoYWa/why-neural-networks-generalise-and-why-they-are-kind-of [LW · GW] for an excellent discussion of this. I am aware that Kolmogorov complexity is defined wrt a UTM, and I should have offered clarification in the blog that a lot of steps were used to make the link between Kolmogorov complexity and these types of input-output maps, and state that we only talk about Kolmgorov complexity because of the Levin bound (somewhat repurposed for input-output maps), which interestingly appears to capture the relationship between probabilities of functions and their complexities for several different complexity measures quite accurately.
comment by drocta · 2021-05-07T20:10:15.126Z · LW(p) · GW(p)
This comment I'm writing is mostly because this prompted me to attempt to see how feasible it would be to computationally enumerate the conditions for the weights of small networks like the 2 input 2 hidden layer 1 output in order to implement each of the possible functions. So, I looked at the second smallest case by hand, and enumerated conditions on the weights for a 2 input 1 output no hidden layer perceptron to implement each of the 2 input gates, and wanted to talk about it. This did not result in any insights, so if that doesn't sound interesting, maybe skip reading the rest of this comment. I am willing to delete this comment if anyone would prefer I do that.
Of the 16 2-input-1-output gates, 2 of them, xor and xnor, can't be done with the perceptrons with no hidden layer (as is well known), for 8 of them, the conditions on the 2 weights and the bias for the function to be implemented can be expressed as an intersection of 3 half spaces, and the remaining 6 can of course be expressed with an intersection of 4 (the maximum number that could be required, as for each specific input and output, the condition on the weights and bias in order to have that input give that output is specified by a half space, so specifying the half space for each input is always enough).
The ones that require 4 are: the constant 0 function, the constant 1 function, return the first input, return the second input, return the negation of the first input, and return the negation of the second input.
These seem, surprisingly, among the simplest possible behaviors. They are the ones which disregard at least one input. It seems a little surprising to me that these would be the ones that require an intersection of 4 half spaces.
I haven't computed the proportions of the space taken up by each region so maybe the ones that require 4 planes aren't particularly smaller. And I suppose with this few inputs, it may be hard to say that any of these functions are really substantially more simple than any of the rest of them. Or it may be that the tendency for simpler functions to occupy more space only shows up when we actually have hidden layers and/or have many more nodes.
Here is a table (x and y are the weights from a and b to the output, and z is the bias on the output):
outputs for the different inputs when this function is computed
0000 (i.e. the constant 0) z<0, x+y+z<0, x+z<0, y+z<0
0001 (i.e. the and gate) x+y+z>0, x+z<0, y+z<0
0010 (i.e. a and not b) z<0, x+y+z<0, x+z>0
0011 (i.e. if input a) z<0, x+y+z>0, x+z>0, y+z<0
0100 (i.e. b and not a) z<0, x+y+z<0, y+z>0
0101 (i.e. if input b) z<0, x+y+z>0, x+z<0, y+z>0
0110 (i.e. xor) impossible
0111 (i.e. or) z<0, x+z>0, y+z>0
1000 (i.e. nor) z>0, x+z<0, y+z<0
1001 (i.e. xnor) impossible
1010 (i.e. not b) z>0, x+y+z<0, x+z>0, y+z<0
1011 (i.e. b->a ) z>0, x+y+z>0, x+z<0
1100 (i.e. not a) z>0, x+y+z<0, x+z<0, y+z>0
1101 (i.e. a->b ) z>0, x+y+z>0, y+z<0
1110 (i.e. nand ) x+y+z<0, x+z>0, y+z>0
1111 (i.e. constant 0) z>0, x+z>0, y+z>0, x+y+z>0
↑ comment by Alex Flint (alexflint) · 2021-05-08T14:55:56.297Z · LW(p) · GW(p)
Very very cool. Thank you for this drocta. What would it take to map out the sizes of the volumes corresponding to each of these mappings? Also, could you perhaps compute the exact Kolmogorov complexity of these mappings in some particular description language, since they are so small? It would be super interesting to me to assemble a table of volumes and Kolmogorov complexities for each of these small mappings. It may then be possible to write some code that does the same for 3-input and 4-input mappings.
Replies from: drocta↑ comment by drocta · 2021-05-25T05:23:29.540Z · LW(p) · GW(p)
For the volumes, I suppose that because scaling all of these parameters by the same positive constant doesn't change the function computed, it would make sense to compute the volumes of the corresponding regions of the cube, and this would handle the issues with these regions having unbounded size.
(this would still work with more parameters, it would just be a higher dimensional sphere)
Er, would that give the same thing as the limit if we took the parameters within a cube?
Anyway, at least in this case, if we use the "projected onto the sphere" case, we could evaluate the areas by splitting the regions (which would be polygons of some kind, with edges being arcs of great circles) into triangles, and then using the formulas for the areas of triangles on a sphere. Actually, they might already be triangles, I'm not sure.
Would this work in higher dimensions? I don't know of formulas for computing the measure of a n-simplex (with flat facets or whatever the right terminology is) within an n-sphere, but I suspect that they shouldn't be too bad?
I'm not sure which is the more sensible thing to measure, the volumes of the intersection of the half spaces (intersected with a large cube centered at the origin and aligned with the coordinate axes), or the volume (one dimension lower) of that intersected-with/projected-onto the unit sphere.
Well, I guess if we assume that the coefficients are identically and independently distributed with a Gaussian distribution, then that would be a fairly natural choice, and should result in things being symmetric about rotations in the origin, which would seem to point to the choice of projecting it all to the (hyper-)sphere.
Well, I suppose in either case (whether on the sphere or in a cube), even before trying to apply some formulas about the area of a triangle on a sphere, there's always the "just take the integral" option.
(in the cube option, this would I think be more straightforwards. Just have to do a triple integral (more in higher dimensions) of 1 with linear inequalities for the bounds. No real issues should show up.)
I'll attempt it with the conditions for "and" for the "on the sphere" case, to check the feasibility.
If we have x+y+z>0, x+z<0, y+z<0, then we necessarily also have z<0 , x>0, y>0 , in particular x<-z , y<-z . If we have x,y,z on the unit sphere, then we have x^2+y^2+z^2=1 . So, for each value of z (which must be strictly between -1 and 0) we have x^2 + y^2 = 1 - z^2 , and because we have x>0 and y>0 , for a given z, for each value of x there is exactly one value of y, and visa versa.
So, y = sqrt(1 - z^2 - x^2) , and so we have x + sqrt(1 - z^2 - x^2) > -z , ...
this is somewhat more difficult to calculate than I had hoped.
Still confident that it can be done, but I shouldn't finish this calculation right now due to responsibilities.
It looks like, at least in this case with 3 parameters, that it would probably be easier to use the formulas for the area of triangles on a sphere, but I wouldn't be surprised if, when generalizing to higher dimensions, doing it that way becomes harder.
It looks like Chris Mingard's reply has nice results which say much of what I think one would want from this direction? Well, it is less "enumerate them specifically", and more "for functions which have a given proportion of outputs being 1", but, still. (also I haven't read it, just looked briefly at it)
I don't know what particular description language you would want to use for this. I feel like this is such a small case that small differences in choice of description language might overwhelm any difference in complexity that these would have within the given description language?
Replies from: alexflint, drocta↑ comment by Alex Flint (alexflint) · 2021-05-25T17:06:04.924Z · LW(p) · GW(p)
Yes it does seem challenging to compute realistic complexity measures for such small functions. Perhaps we could just look at the mappings ordered by their volume in parameter space, and check whether the mappings at the top of that ordering "seem" less complex than the mappings at the bottom.
↑ comment by drocta · 2021-05-26T02:40:09.271Z · LW(p) · GW(p)
I've now computed the volumes within the [-a,a]^3 cube for and, or, and the constant 1 function. I was surprised by the results.
(I hadn't considered that the ratios between the volumes will not depend on the size of the cube)
If we select x,y,z uniformly at random within this cube, the probability of getting the and gate is 1/48, the probability of getting the or gate is 2/48, and the probability of getting the constant 1 function is 13/48 (more than 1/4).
This I found quite surprising, because of the constant 1 function requiring 4 half planes to express the conditions for it.
So, now I'm guessing that the ones that required fewer half spaces to specify, are the ones where the individual constraints are already implying other constraints, and so actually will tend to have a smaller volume.
On the other hand, I still haven't computed any of them for if projecting onto the sphere, and so this measure kind of gives extra weight to the things in the directions near the corners of the cube, compared to the measure that would be if using the sphere.
↑ comment by Chris Mingard · 2021-05-12T13:50:56.909Z · LW(p) · GW(p)
Check out https://arxiv.org/pdf/1909.11522.pdf where we do some similar analysis of perceptrons but in higher dimensions. Theorem 4.1 shows that there is an anti-entropy bias - in other words, functions with either mostly 0s or mostly 1s are exponentially more likely to show up than expected under a uniform prior - which holds for perceptrons of any dimension. This proves a (fairly trivial) bias towards simple functions, although it doesn't say anything about why a function like 010101010101... appears more frequently than other functions in the maximum-entropy class.
comment by interstice · 2021-05-07T03:03:14.564Z · LW(p) · GW(p)
For reasons elaborated upon in this post [LW · GW] and its comments, I'm kinda skeptical of these results. Basically the claims made are
(A) That the parameter->function map is "biased towards simple functions". It's important to distinguish simple --> large volume and large volume --> simple [LW(p) · GW(p)]. Simple --> large volume is the property that Solomonoff induction has and what makes it universal, but large volume-->simple is what is proven in these papers(plus some empirical evidence of unclear import)
(B) SGD being equivalent to random selection. The evidence is empirical performance of Gaussian processes being similar to neural nets on simple tasks. But this may break down on more difficult problems [LW(p) · GW(p)](link is about the NTK, not GP, but they tend to perform similarly, indeed NTK usually performs better than GP)
Overall I think it's likely we'll need to actually analyze SGD in a non-kernel limit to get a satisfactory understanding of "what's really going on" with neural nets.
Replies from: Chris Mingard, alexflint↑ comment by Chris Mingard · 2021-05-11T19:10:58.991Z · LW(p) · GW(p)
I agree that "large volume-->simple" is what is shown by the evidence in the papers, as opposed to "simple--> large volume" which is in fact not a claim we do not make anywhere (if we do accidentally please let me know and I will fix it) - see https://arxiv.org/abs/1910.00971 for more detail on this, or Joar Skalse's comments on https://www.alignmentforum.org/posts/YSFJosoHYFyXjoYWa/why-neural-networks-generalise-and-why-they-are-kind-of, [AF · GW] where he discusses functions which don't obey this rule - such as the identity function, which has small volume and is very simple. If optimisers find functions approximately proportional to their volume in parameter-space, this would be a good explanation for why neural networks struggle to learn identity functions. (In fact, theoretical reasons exist which suggest that such low-probability low-complexity functions should exist, but should be rare https://arxiv.org/abs/1910.00971).
Also, very briefly on your comment on feature learning - the GP limit is used to calculate the volume of functions locally to the initialisation. The fact that kernel methods do not learn features should not be relevant given this interpretation - although there are some interesting corollaries of this - and it is something we are investigating.
Replies from: interstice↑ comment by interstice · 2021-05-12T05:02:50.779Z · LW(p) · GW(p)
Yeah, I didn't mean to imply that you guys said 'simple --> large volume' anywhere. I just think it's a point worth emphasizing, especially around here where I think people will imagine "Solomonoff Induction-like" when they hear about a "bias towards simple functions"
Also, very briefly on your comment on feature learning—the GP limit is used to calculate the volume of functions locally to the initialization. The fact that kernel methods do not learn features should not be relevant given this interpretation
But in the infinite-width setting, Bayesian inference in general is given by a GP limit, right? Initialization doesn't matter. This means that the arguments for lack of feature learning still go through. It's technically possible that there could be feature learning in finite-width randomly-sampled networks, but it seems strange that finiteness would help here(and any such learning would be experimentally inaccessible). This is a major reason that I'm skeptical of the "SGD as a random sampler" picture.
Replies from: Chris Mingard↑ comment by Chris Mingard · 2021-05-12T16:47:39.591Z · LW(p) · GW(p)
[First thank you for your comments and observations - it's always interesting to read pushback]
First, I think my point about using the GP to measure the volume occupied functions locally to where SGD trained networks are initialised is important. We are not really comparing NNs to NNGPs (well, technically we are, but we are interpreting what the NNGP does differently). We are trying to argue that SGD acts as a random sampler - it will find functions with probability proportional to the volume of those functions local to where the optimiser is in parameter-space. We argue that this quantity is well approximated by the NNGP.
This is relevant to the comments on features: if you look at the definition of $P_B(f|S)$ it's fairly clear that (assuming training by random sampling) initialising and freezing all but the last layer and then random sampling over that will, in expectation, give precisely the same posterior distribution as if you were to random sample over the whole network. This property holds for finite and infinite width networks. This may seem counterintuitive, but the term P(S|f) in the definition of $P_B(f|S)$ ensures that if the random initialisation of the frozen layers does not allow for 100% training accuracy, that random initialisation is ignored. Therefore, if an optimiser samples functions proportional to their volume, you won't get any difference in performance if you learn features (optimise the whole network) or do not learn features (randomly initialise and freeze all but the last layer and then train just the last).
Given therefore that the posteriors are the same, it implies that feature learning is not aiding inductive bias - rather, feature learning is important for expressivity reasons. The reason why you can't just use frozen initial layers and obtain the same inductive bias on SOTA architectures is most likely because you can't make the layers wide enough, to ensure that the network is expressive enough with high probability. Imagenet for example has input dimension of ~200000 so you would need some very wide layers to approach the wide-layer limit.
Furthermore (and on a slightly different note), it is known that infintesimal GD converges to the Boltzmann distribution for any DNN (very similar to random sampling) https://arxiv.org/abs/2004.01190. This means that the coloured noise in SGD is the only possible source for drastically improved inductive bias (which would have to emerge only on large scales, as we do not observe it at smaller scales). I have also not heard as good a theoretical justification for why this noise would dramatically aid generalisation.
Given this, I think it a sensible null hypothesis that optimisers are approximately performing random sampling from a well-biased parameter-space (with some subtleties, see my other comment about tempered posteriors), at substantially larger scales. This to me makes more sense than "optimisers perform random sampling at small/medium scales, but as you move to bigger scales coloured noise in SGD is the dominant source of inductive bias".
Finally, I would like to point out that this is my impression from the literature, and my work. I am aware that there's a lot I don't know, and if anyone can point out why this line of argument is not correct, or can steelman a case for SGD inductive bias appearing at larger scales, I would be very interested to hear it.
Replies from: interstice↑ comment by interstice · 2021-05-12T20:51:47.251Z · LW(p) · GW(p)
First thank you for your comments and observations—it’s always interesting to read pushback
And thanks for engaging with my random blog comments! TBC, I think you guys are definitely on the right track in trying to relate SGD to function simplicity, and the empirical work you've done fleshing out that picture is great. I just think it could be even better if it was based around a better SGD scaling limit ;)
Therefore, if an optimiser samples functions proportional to their volume, you won’t get any difference in performance if you learn features (optimise the whole network) or do not learn features (randomly initialise and freeze all but the last layer and then train just the last).
Right, this is an even better argument that NNGPs/random-sampled nets don't learn features.
Given therefore that the posteriors are the same, it implies that feature learning is not aiding inductive bias—rather, feature learning is important for expressivity reasons
I think this only applies to NNGP/random-sampled nets, not SGD-trained nets. To apply to SGD-trained nets, you'd need to show that the new features learned by SGD have the same distribution as the features found in an infinitely-wide random net, but I don't think this is the case. By illustration, some SGD-trained nets can develop expressive neurons like 'car detector', enabling them to fit the data with a relatively small number of such neurons. If you used an NNGP to learn the same thing, you wouldn't get a single 'car detector' neuron, but rather some huge linear combination of high-frequency features that can approximate the cars seen in the dataset. I think this would probably generalize worse than the network with an actual 'car detector'(this isn't empirical evidence of course, but I think what we know about SGD-trained nets and the NNGP strongly suggests a picture like this)
Furthermore (and on a slightly different note), it is known that infintesimal GD converges to the Boltzmann distribution for any DNN (very similar to random sampling)
Interesting, haven't seen this before. Just skimming the paper, it sounds like the very small learning rate + added white noise might result in different limiting behavior from usual SGD. Generally it seems that there are a lot of different possible limits one can take; empirically SGD-trained nets do seem to have 'feature learning' so I'm skeptical of limits that don't have that(I assume they don't have them for theoretical reasons, anyway. Would be interesting to actually examine the features found in networks trained like this, and to see if they can do transfer learning at all) re:'colored noise', not sure to what extent this matters. I think a more likely source of discrepancy is the lack of white noise in normal training(I guess this counts as 'colored noise' in a sense) and the larger learning rate.
if anyone can point out why this line of argument is not correct, or can steelman a case for SGD inductive bias appearing at larger scales, I would be very interested to hear it.
Not to be a broken record, but I strongly recommend checking out Greg Yang's work. He clearly shows that there exist infinite-width limits of SGD that can do feature/transfer learning.
Replies from: Chris Mingard↑ comment by Chris Mingard · 2021-05-13T10:24:01.089Z · LW(p) · GW(p)
[Advance apologies if I haven't explained stuff well enough here. I think the important theme here is that we should maintain a way of thinking about the random sampling picture that is distinct from NNGPs.]
Right, this is an even better argument that NNGPs/random-sampled nets don't learn features.
Ah I see I need to explain myself further - the following is very counterintuitive but I think it's right. Learning features involves the movement of weights in the early layers, by definition. The claim I am making is that the reason why feature learning is good is not because it improves inductive bias - it is because it allows the network to be compressed. That is probably at the core of our disagreement.
Imagine taking a network and making it so thin that it is only just able to represent the function it needs to. Now try the training with last layer only after randomly initialising the others. You can't - because the randomly initialised first layers will drastically decrease its expressivity, so you can't express the true function. Now do the same, but with very wide layers - by the lottery ticket hypothesis (and in the limit of infinite width) this will work well because of the (near) unlimited expressivity. Hence, for narrow networks you have to "learn features" to make sure you are expressive enough, but for wide ones you do not.
Consider ResNet18 on Imagenet. Imagenet has an input dimension of $3\times256\times256\approx200000$. The widths of the layers within the resnet are at least two orders of magnitude smaller (so you are nowhere near the limit of infinite width). This is the case of the thin network I talked about earlier - you have to learn features precisely because the network isn't expressive enough for you to get away without. I'm pretty sure this is the motivation for making networks deep in the first place - for expressivity reasons.
So my claim is features are important to keep the number of parameters small, but do not in themselves aid inductive bias. I know that the first pushback to this will be "but transfer learning improves inductive bias." Of course - you are basically taking a network that has just been trained on millions of images, and then using this on a set of new images - there will be some information in common across images that has been encoded in the earlier layers. The hierarchical nature of neural networks allows this to happen, but fundamentally not in a way that could not be explained by the random sampling picture.
So, in conclusion, I don't think SGD needs to be doing any "feature learning" beyond what can be achieved in the random sampling fashion. Note that the random sampling arguments apply not only in the limit of infinite width.
[However, it is worth noting that this is conjecture, although I think it is the most natural conclusion from what we know about DNNs. That said, I will only be happy to accept it when we have found a good way of rigorously comparing the posteriors of a random-sample trained finite width neural network and its corresponding SGD trained version]
I think this would probably generalize worse than the network with an actual 'car detector'(this isn't empirical evidence of course, but I think what we know about SGD-trained nets and the NNGP strongly suggests a picture like this)
What do we know about SGD-trained nets that suggests this?
Not to be a broken record, but I strongly recommend checking out Greg Yang's work. He clearly shows that there exist infinite-width limits of SGD that can do feature/transfer learning.
I've read the new feature learning paper! We're big fans of his work, although again I don't think it contradicts anything I've just said.
Replies from: interstice↑ comment by interstice · 2021-05-14T03:14:12.170Z · LW(p) · GW(p)
The claim I am making is that the reason why feature learning is good is not because it improves inductive bias—it is because it allows the network to be compressed. That is probably at the core of our disagreement.
Yes, I think so. Let's go over the 'thin network' example -- we want to learn some function which can be represented by a thin network. But let's say a randomly-initialized thin network's intermediate functions won't be able to fit the function -- that is (with high probability over the random initialization) we won't be able to fit the function just by changing the parameters of the last layer. It seems there are a few ways we can alter the network to make fitting possible:
(A) Expand the network's width until (with high probability) it's possible to fit the function by only altering the last layer
(B) Keeping the width the same, re-sample the parameters in all layers until we find a setting that can fit the function
(C) Keeping the width the same, train the network with SGD
By hypothesis, all three methods will let us fit the target function. You seem to be saying[I think, correct me if I'm wrong] that all three methods should have the same inductive bias as well. I just don't see any reason this should be the case -- on the face of it, I would guess that all three have different inductive biases(though A and B might be similar). They're clearly different in some respects -- (C) can do transfer learning but (A) cannot(B is unclear).
What do we know about SGD-trained nets that suggests this?
My intuition here is that SGD-trained nets can learn functions non-linearly while NTK/GP can only do so linearly. So in the car detector example, SGD is able to develop a neuron detecting cars through some as-yet unclear 'feature learning' mechanism. The NTK/GP can do so as well, sort of, since they're universal function approximators. However, the way they do this is by taking a giant linear combination of random functions which is able to function identically to a car detector on the data points given. It seems like this might be more fragile/generalize worse than the neurons produced by SGD. Though that is admittedly somewhat conjectural at this stage, since we don't really have a great understanding of how feature learning in SGD works.
I’ve read the new feature learning paper! We’re big fans of his work, although again I don’t think it contradicts anything I’ve just said.
ETA: Let me elaborate upon what I see as the significance of the 'feature learning in infinite nets' paper. We know that NNGP/NTK models can't learn features, but SGD can: I think this provides strong evidence that they are learning using different mechanisms, and likely have substantially different inductive biases. The question is whether randomly sampled finite nets can learn features as well. Since they are equivalent to NNGP/NTK at infinite width, any feature learning they do can only come from finiteness. In contrast, in the case of SGD, it's possible to do feature learning even in the infinite-width limit. This suggests that even if randomly-sampled finite nets can do feature learning, the mechanism by which they do so is different from SGD, and hence their inductive bias is likely to be different as well.
Replies from: guillefix, Chris Mingard↑ comment by guillefix · 2021-05-25T00:04:52.233Z · LW(p) · GW(p)
I'd like to add some points to this interesting discussion:
As far as I understand, feature learning is not necessary for some standard types of transfer learning. E.g.: one can train an NNGP on a large dataset, and then use the learned posterior as prior for "fine-tuning" on some new dataset. This is hard to scale using actual GP techniques, but if wide neural nets (with random sampling or SGD) do approximate NNGPs, this could be a way they achieve transfer learning without feature learning.
You say
In contrast, in the case of SGD, it's possible to do feature learning even in the infinite-width limit
That is true, but one of the points in Greg Yang's paper, as far as I remember, was also to say that people weren't using the scaling limit that would lead to that. That has made me wonder whether feature learning may be happening in our biggests models or not. The work on multimodal neurons in CLIP suggests there is feature learning. But what about GPT-3? In any case, I don't think it'll be happening by the mechanism Yang proposes as people aren't using his initialization scheme. Perhaps, then the mechanism by which finite randomly-sampled NNs could conceivably feature-learn, could be the same as the one SGD is using. I am not sure either way. For me to evaluate the empirical evidence better, I'd need a sense about whether the evidence we have is in sufficiently large models or not (as I do think that randomly-sampled NNs for infinite width won't do feature learning -- though I'm not sure how to prove that, without a better definition of feature learning).
Another point is in answer to your comment that NNGP often underpeforms NTK. I think there's actually more evidence on the contrary (see https://arxiv.org/abs/2007.15801 ), even if there're instancs of both ways.
Overall, I think the work in Jascha Sohl-Dickstein's groun (e.g. the paper linked above) has been great for disentangling these issues, and they seem to point at a complex/nuanced picture, which really leads me to believe we don't have a clear answer about whether NNGPs will be a good model of SGD in practice (as of today; practice may also change). However, my general observation is that I'm not aware of any evidence that shows that SGD-trained nets beat architecture-equivalent NNGPs by a significant margin, consistently over a wide range of tasks in practice. Chris' work on Bayesian picture of SGD tried to do this, but the problems are indeed, not quite large enough to be confident. In here https://arxiv.org/abs/2012.04115 we also explore NNGPs (but through a different lens), over SOTA architectures, but still small tasks. So I think the question still remains open as to how would NNGPs perform for more complex datasets.
↑ comment by Chris Mingard · 2021-05-15T11:45:25.150Z · LW(p) · GW(p)
By hypothesis, all three methods will let us fit the target function. You seem to be saying[I think, correct me if I'm wrong] that all three methods should have the same inductive bias as well.
Not exactly the same - it is known that there is a width dependence on inductive biases. I believe that typically wide networks are better, although I know of some counterexamples.
They're clearly different in some respects -- (C) can do transfer learning but (A) cannot
I think this is the main source of our disagreement. First of all, while the posterior of an NNGP is equivalent to that of a trained-by-random-sampling infinitely wide NN, it does not contain all the same information. It is a collapsed version of an infinitely wide neural network that does not contain any information about the weights in each layer. This was one of Greg Yang's points - by definition, a kernel method cannot learn features as you are ignoring the effects of the initial layers, as from a function perspective they are irrelevant - in other words, you have just thrown that information away.
This is not the same as saying that an extremely wide trained-by-random-sampling neural network would not learn features - there is a possibility that the first time you reach 100% training accuracy corresponds to effectively randomly initialised initial layers + trained last layer, but in expectation all the layers should be distinct from an entirely random intialisation.
(B is unclear).
Assuming that the network is so compressed that it can barely represent the true function without substantial fine-tuning of weights in all layers, weights in early layers would absolutely have to be very different from random initialisation.
However, the way they do this is by taking a giant linear combination of random functions which is able to function identically to a car detector on the data points given. It seems like this might be more fragile/generalize worse than the neurons produced by SGD. Though that is admittedly somewhat conjectural at this stage, since we don't really have a great understanding of how feature learning in SGD works.
You can make arguments that this is what would happen for very wide networks - but then SGD is probably doing the same thing, unless you're assuming that it learns a few (e.g.) car detector neurons and then the rest are completely redundant. I would expect the car detector neurons to show up in narrower networks, but by my point immediately above, I don't see why this has to be an SGD-only property.
My intuition here is that SGD-trained nets can learn functions non-linearly while NTK/GP can only do so linearly.
Yes but again an NNGP has thrown away all information about the weights. The NTK limit effectively passes all the gradient to the last layer, so again, by definition, it is a linear model.
Since they are equivalent to NNGP/NTK at infinite width, any feature learning they do can only come from finiteness. In contrast, in the case of SGD, it's possible to do feature learning even in the infinite-width limit.
Same point as above. The Greg Yang paper shows you need to do the clever reparameterisation to make sure not all the gradient gets passed to the last layer (as it does in NTK). The NNGP flattens the neural network so again there can be no feature learning by that representation. So I think the conclusion "can only come from finiteness" is wrong. The second point is correct, but only because you haven't collapsed the network into a kernel. If you were to take an extremely wide neural network and train the whole thing by random sampling with some extra steps (e.g. encouraging orthogonality of intermediate outputs between different classes), I don't see why you wouldn't have some degree of 'feature learning' here.
Perhaps this is a physicist vs mathematician type of thinking though. I think I see where you are coming from, but I don't think the no feature learning arguments are valid, as I think I outlined.
Replies from: interstice↑ comment by interstice · 2021-05-15T21:13:44.031Z · LW(p) · GW(p)
Perhaps this is a physicist vs mathematician type of thinking though
Good guess ;)
This is not the same as saying that an extremely wide trained-by-random-sampling neural network would not learn features—there is a possibility that the first time you reach 100% training accuracy corresponds to effectively randomly initialised initial layers + trained last layer, but in expectation all the layers should be distinct from an entirely random intialisation.
I see -- so you're saying that even though the distribution of output functions learned by an infinitely-wide randomly-sampled net is unchanged if you freeze everything but the last layer, the distribution of intermediate functions might change. If true, this would mean that feature learning and inductive bias are 'uncoupled' for infinite-width randomly-sampled nets. I think this is false, however -- that is, I think it's provable that the distribution of intermediate functions does not change in the infinite-width limit when you condition on the training data, even when conditioning over all layers. I can't find a reference offhand though, I'll report back if I find anything resolving this one way or another.
Replies from: Chris Mingard↑ comment by Chris Mingard · 2021-05-15T21:25:40.385Z · LW(p) · GW(p)
Good guess ;)
Haha some things are pretty obvious - it's always really nice to get a very different perspective on an idea, thank you for continuing the conversation!
I see -- so you're saying that even though the distribution of output functions learned by an infinitely-wide randomly-sampled net is unchanged if you freeze everything but the last layer, the distribution of intermediate functions might change. If true, this would mean that feature learning and inductive bias are 'uncoupled' for infinite randomly-sampled nets
That is exactly what I'm saying. I don't know if it is testable in practice, but it is in theory ... I would be very interested to see anything about this - let me know if you find anything!
If it turns out that, in the limit of infinite width, feature learning does not work, what are your thoughts about my case for feature learning for the narrow (but trained-by-random-sampling) case? I would guess you find this case significantly more compelling than the infinite width case?
Replies from: interstice↑ comment by interstice · 2022-06-18T05:32:57.035Z · LW(p) · GW(p)
I just came across this paper which derives an expression for the posterior distribution of the weights in each layer in the infinite-width limit. The result: the distribution is unchanged from the prior in every layer but the last. So it indeed seems that there is no feature learning in this limit.
↑ comment by Alex Flint (alexflint) · 2021-05-07T16:51:59.427Z · LW(p) · GW(p)
Thanks for these pointers.
but large volume-->simple is what is proven in these papers(plus some empirical evidence of unclear import)
Is that the empirical evidence attempts to demonstrate simple --> large volume but is inconclusive, or is it that the empirical evidence does not even attempt to demonstrate simple --> large volume?
The evidence is empirical performance of Gaussian processes being similar to neural nets on simple tasks.
Well they do take many samples from what they call P_SGD and P_B and compare these as distributions, so it seems a little unfair to say that the evidence is that the performance is similar, since that would suggest that they were just comparing max performance by SGD to max performance by NNGP.
Re breaking down on more difficult problems: yes, I agree, we will have to wait and see and we shouldn't be too optimistic given the paper you point to in your own post.
[from your post on NTK/GP not learning features] it seems possible that they [neural networks] could be doing something much more interesting -- perhaps even implementing something like a simplicity prior over a large class of functions, which I'm pretty sure NTK/GP can't be
It sounds like you do think there is some chance that neural network generalization is due to an architectural bias towards simplicity. I would be very interested in your take on other (non-Mingard) research on this overall question if you have time to jot down some notes.
Replies from: interstice↑ comment by interstice · 2021-05-07T20:11:06.486Z · LW(p) · GW(p)
Is that the empirical evidence attempts to demonstrate simple --> large volume but is inconclusive, or is it that the empirical evidence does not even attempt to demonstrate simple --> large volume?
They don't really try to show simple --> large volume. They show is that there is substantial 'clustering, so some simple functions have large volume. I like nostalgebraist's remarks [LW(p) · GW(p)] on their clustering measures.
so it seems a little unfair to say that the evidence is that the performance is similar, since that would suggest that they were just comparing max performance by SGD to max performance by NNGP.
Fair point, they do compare the distributions as well. I don't think it's too surprising that they're similar since they compare them on the test points of the distribution which they were trained to fit.
It sounds like you do think there is some chance that neural network generalization is due to an architectural bias towards simplicity
I do, although I'm not sure if I would say 'architectural bias' since I think SGD might play an important role. Unfortunately I don't really have too much substantial to say about this -- Mingard is the only researcher I'm aware of explicitly trying to link networks to simplicity priors. I think the most promising way to make progress here is likely to be analyzing neural nets in some non-kernel limit like Greg Yang's work or this paper.
Replies from: Chris Mingard↑ comment by Chris Mingard · 2021-05-11T19:06:45.772Z · LW(p) · GW(p)
I think a lot of the points you raise here have good answers at https://www.alignmentforum.org/posts/YSFJosoHYFyXjoYWa/why-neural-networks-generalise-and-why-they-are-kind-of [AF · GW] - see in particular replies by Joar Skalse (the author of that post). You say that you don't think it surprising that the posteriors of NNs are similar to NNGPs on the data on which they were trained to fit - I think this statement is only unsurprising if you assume that SGD is not playing a particularly big role in the inductive bias (for small/medium scale datasets and architectures). In the main paper https://jmlr.org/papers/v22/20-676.html we do review a substantial amount of literature on topic. Some results that rely on "different hyperparameters result in different generalisation" type arguments were found later to be due to different effective training times (see Hoffer et al 2017). We also show that optimiser hyperparameter tuning can affect the generalisation - although in a fashion similar to changing the temperature in fully tempered posteriors (see eqn 1 in https://openreview.net/pdf?id=cu6zDHCfhZx) - in other words, still fundamentally due to the architecture.
Beyond the pretty conclusive evidence that SGD is a much smaller source of inductive bias than the architecture on small/medium scale tasks, I think there is a lot of evidence that the architecture is responsible for the first-order generalisation capabilities of the network elsewhere. For example, https://arxiv.org/abs/2012.04115 shows that architecture-only bounds are excellent predictors of performance on SOTA networks (e.g. wide resnets), as does https://arxiv.org/pdf/2002.02561.pdf (from a different group). For more circumstantial evidence, it is known that CNNs typically outperform fully connected nets for image classification, and transformers outperform lstms for sentiment analysis etc, even though the same type of optimisers are used.
I think there are very interesting questions remaining about the role of the optimiser in narrow networks, feature learning and very large scale models. Clearly though, the methods we used on the small/medium scale architectures and datasets will not scale to these questions without some major changes. For the meantime, we are using current methods to investigate some edge cases, none of which are yet to show strong deviation from our predictions.
I would suggest that the architecture being the main source of inductive bias might be a sensible null hypothesis for the cases we are yet to directly probe. I also think that the comparative simplicity of the hypothesis - that SGD finds functions with probability proportional to their volume in parameter space/performs random sampling (very closely when there is strong bias in the parameter-function map and progressively less closely the weaker it gets), and a strong architectural bias towards simplicity (again with some subtleties) causes the good generalisation - is quite compelling.
Replies from: interstice↑ comment by interstice · 2021-05-12T05:32:34.359Z · LW(p) · GW(p)
I think we basically agree on the state of the empirical evidence -- the question is just whether NTK/GP/random-sampling methods will continue to match the performance of SGD-trained nets on more complex problems, or if they'll break down, ultimately being a first-order approximation to some more complex dynamics. I think the latter is more likely, mostly based on the lack of feature learning in NTK/GP/random limits.
re: the architecture being the source of inductive bias -- I certainly think this is true in the sense that architecture choice will have a bigger effect on generalization than hyperparameters, or the choice of which local optimizer to use. But I do think that using a local optimizer at all, as opposed to randomly sampling parameters, is likely to have a large effect.