Mistakes people make when thinking about units
post by Isaac King (KingSupernova) · 2024-06-25T03:39:20.138Z · LW · GW · 14 commentsContents
^ ^ ^ ^ ^ ^ None 14 comments
This is a linkpost for Parker Dimensional Analysis. Probably a little elementary for LessWrong, but I think it may still contain a few novel insights, particularly in the last section about Verison's error.
A couple years ago, there was an interesting clip on MSNBC.
A few weeks later, Matt Parker came out with a video analyzing why people tend to make mistakes like this. Now I'm normally a huge fan of Matt Parker. But in this case, I think he kinda dropped the ball.
He does have a very good insight. He realizes that people are treating the "million" as a unit, removing it from the numbers before performing the calculation, then putting it back on. This is indeed the proximate cause of the error. But Matt goes on to claim that the mistake is the treating of "million" as a unit; the implication being that, as a number suffix or a multiplier or however you want to think of it, it's not a unit, and therefore cannot be treated like one. This is false.
So what is a unit, really? When we think of the term, we probably think of things like "meters", "degrees Celcius", "watts", etc.; sciency stuff. But I think the main reason we think of those is due to unit conversion; when you have to convert from meters to feet, or derive a force from mass and acceleration, this makes us very aware of the units being used, and we associate the concept of "unit" with this sort of physics conversion.
In reality, a unit is just "what kind of thing you're counting". Matt uses two other examples in his video: "dollars" and "sheep". Both of these are perfectly valid units! If I say "50 meters", that's just applying the number "50" to the thing "meters", saying that you have 50 of that thing. "50 sheep" works exactly the same way.
So what about "millions"? Well, we can definitely count millions! 1 million, 2 million, etc. You could imagine making physical groupings of a million sheep at a time, perhaps using some very large rubber bands, and then counting up individual clusters. "Millions" is a unit![1]
So if millions is a perfectly valid unit, why do we get an incorrect result if we take it off and then put it back on again after the calculation? Well, because you can't do that with other units either! 100 watts divided by 20 watts does not equal 5 watts. It equals the number 5, with no unit.
This is a somewhat subtle distinction, and easy to miss in a casual conversation. But it makes sense when you think about the actual things you're counting. 50 sheep is certainly not the same thing as 50 horses. And 50 sheep is also not the same thing as the abstract number 50; one is a group of animals, the other a mathematical concept. If someone were to say something to you involving the number 50, you would not simply assume that they're talking about sheep.
This perfectly solves the problem. If 100 watts / 20 watts equals only the number 5, with no "watts", then 100 million / 20 million also equals only the number 5, with no "million".
But what about Matt's example? 80 million sheep - 50 million sheep = 30 million sheep; not just 30. That's because this is subtraction, not division. Units work differently depending on what operation you're performing! If you're doing addition or subtraction, the units are preserved; you can take them off at the beginning and then put them back on at the end. But for multiplication and division, this is not the case. Division cancels out the units, removing them entirely, and multiplication gives you a new unit, equal to the previous unit squared.
This seems kind of arbitrary, right? Why do they work differently depending on the operation? To understand this, let's go back to a different example that Matt used in his video. Near the beginning, when he's performing the division of $500 million / 327 million, he moves the dollar sign off to the left, then puts it back on afterwards to get the correct answer of $1.529. Why did that work? Didn't I just say that you can't do that for division?
The difference is in the units of the denominator. If the top and bottom of the fraction are both in the same unit, that unit cancels out and the resulting answer is just a number.[2] But in that calculation, the numerator was in dollars, but the denominator was in people. Dollars and people don't cancel out, so the resulting number is in the unit "dollars/people", or dollars per person.
Think about what it means to multiply "5 sheep" by 2. You start with a row of 5 sheep. Then you take another of those rows and put it next to the first, such that you have 2 rows. Count up the sheep, and you get 10. So 5 sheep * 2 = 10 sheep. But what if you multiply 5 sheep by 2 sheep? We can start with the same thing, a row of 5 sheep. Now I need to take "2 sheep" many rows. What is a "sheep's worth" of rows? Nobody knows. It's a meaningless question. If you really wanted to do this calculation, you'd just keep the units unmultiplied and report that as the answer, saying "10 sheep2". But really, if you ever find yourself doing a calculation like this, you should take that as a hint that something has gone wrong.
But not all units are meaningless when multiplied together. A million times a million is a trillion; a perfectly useful new unit. More abtract but still very useful, force = mass times acceleration. And of course it always makes sense to divide a unit by itself; if you try to divide some number of sheep by some other number of sheep, your answer is going to be in "sheep per sheep". Anything divided by itself is 1, and since multiplication by 1 always returns the same number you started with, we can ignore this.[3]
This sort of doing math with units and getting different units out is called dimensional analysis, and comes up a lot in physics. One of my favorite examples is that if you think about how efficient your car is, you might phrase that in gallons of gas used per mile driven. But gallons is a unit of volume, which is length3, and mile is a unit of distance, or length. But anything cubed divided by itself is just itself squared. So car efficiency is measured in square length, also known as area. This seems weird at first, but unlike the earlier "square sheep", this actually has a very intuitive physical meaning! If you were to lay out the gas you burn in a tube on your route, the cross sectional area of that tube is equal to your car's efficiency in area.
Dimensional analysis can get complicated, but I think learning the basics is worth it. Knowing that you preserve units when you add or subtract two numbers of the same unit, but you remove the units when you divide them, is very helpful, as it helps you avoid making mistakes like the one above.
It can also help with other kinds of mistakes. Take this tweet that was going around a while back:
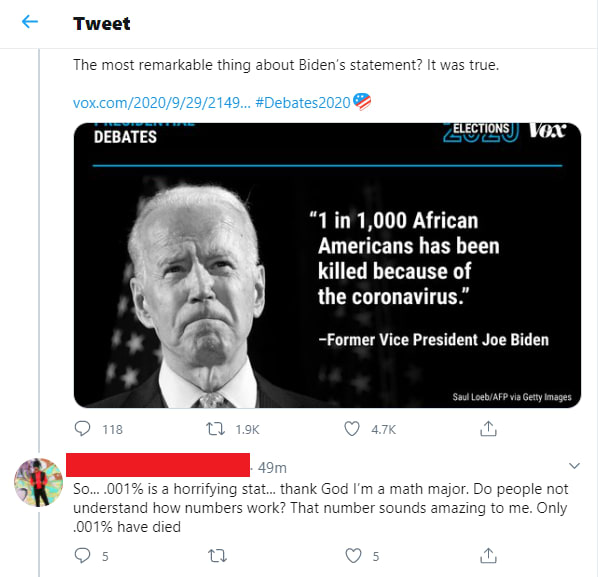
What this person seems to have done is thought to themselves "I want this number as a percentage", so they divided 1 by 1000 and then popped the percent sign on at The End.
This is easy to do, but uh... that's not how this works. That's not how any of this works. Units mean something. If the original numbers were unitless, the resulting answer isn't going to magically be of the unit "percent".
How do we convert an arbitrary quantity into another quantity of a desired unit? Well if you recall above, for a number to be "of" a unit means that the number is being multiplied by that unit. "10 sheep" means "sheep" times "the number 10". Doing some simple algebra, if you start with a quantity X and you want to represent that in the form N * Y, where Y is some preset constant, you derive N by dividing X by Y.
The input number is 0.001, so the result as a percentage is "(0.001/%)%". We can them simplify this by remembering that the definition of a percent is 1/100. Calculating 0.001/(1/100) gives us 0.1, so the final answer is 0.1%.
The most fascinating unit conversion mistake I'm aware of was made by Verison in 2006. They quoted a price of 0.002 cents per kilobyte of data, and then charged 0.002 dollars per kilobyte.
What I found unique about this error was its persistence. In the MSNBC and Covid examples above, someone make a mistake, but once it was pointed out, they went "oops, ok I see where I went wrong".[4] Verison, by contrast, had 5+ different people call in about this, speaking to 5+ different customer service reps (sometimes escalated to supervisors), and, since this was being shared on the 2006 blogosphere, all the people calling in were geeks who were happy to spend 20+ minutes giving detailed explanations of basic math to the reps who picked up the phone. Still, not a single person at Verison seemed capable of understanding that these are different amounts of money.
There are a few points in the conversation that make it clear what's going on in their heads.
- Both supervisors would agree that 1 cent was different from 1 dollar, and that 0.5 cents was different from 0.5 dollars, but would deny that 0.002 cents was different from 0.002 dollars, explicitly claiming them to be the same quantity.
- When the customer asked the rep to confirm the price, the supervisor would frequently just say "0.002", without seeming to think that the unit was important.
- The customer asks "how do you write down 1 cent", and the supervisor says ".01".
- One of the supervisors said "what do you mean .002 dollars?", "there's no .002 dollars", "I've never heard of .002 dollars", and "you were quoted 0.002 cents; that's 0.002."
What seems to have happened is that none of these reps actually understand what a dollar or a cent are. Rather, they've learned a heuristic of "if the number is big I should describe it with the word 'dollars', and if the number is small I should describe it with the word 'cents'". For numbers in between they'd sometimes be able to do math properly, but for a number as small as 0.002 the rep would hear "0.002 dollars" and think to themselves "small number therefore cents", disregarding the fact that it said "dollars". This is how you get things like the rep saying "our price is 0.002 cents per kilobyte, and you used 35,893 kilobytes, so multiplying those numbers together on my calculator gives me 71.786 dollars". They saw a result bigger than 1 on their calculator, and went "big number therefore dollars".[5]
Understanding what a unit is would have helped here too. These reps were treating dollars and cents as being redundant descriptive qualifiers added to a number. If a store is 1 mile away from me, I could describe it as "1 mile away", but I could also say "it's only 1 mile away". The "only" serves to highlight the smallness of 1, but doesn't add any other information. The reps were acting as though saying "cents" were simply a way to highlight that a number is small, rather than actually describing what that number is counting.
Yes, the majority of humanity is completely incompetent at what we would consider to be elementary school level arithmetic. But that doesn't mean that they're just answering randomly. There's still an underlying pattern to their answers, and the first step to teaching people how to reason properly is to identify that pattern.
And in fact this is a critical part of the metric system. A kilometer is just 1000 meters. When you're counting something in kilometers, you're counting in "thousands of meters".
Referred to as a "dimensionless" number.
In other words, what we think of as a "unitless" or "dimensionless" number is the same thing as it having a unit of 1.
Though the journalist on MSNBC tried to blame the criticism on "racism", and the Covid guy claimed that 0.1% of a population dying is "insignificant", so neither of them is a paragon of intellectual honesty.
They were also bad at math in many other ways, like the rep who claimed that "0.002" is a different number from ".002". But that's besides the point, I'm focusing on the unit conversion issues.[6]
And to be fair, the frustrated customer also messed up once, claiming that ".002 dollars, if you do the math, is .00002 cents".
14 comments
Comments sorted by top scores.
comment by cubefox · 2024-06-25T15:52:02.643Z · LW(p) · GW(p)
I liked this post. All this sounds obvious enough when you read it like that, but it can't be too obvious when even someone like Matt Parker got it wrong.
A further question: What type of units are probabilities? They seem different from from e.g. meters or sheep.
For example, probabilities are bounded below and above (0 and 1) while sheep (and meters etc) are only bounded below (0). (And "million" isn't bounded at all.) So the expression "twice as many" does make sense for sheep or meters, but arguably not for probabilities, or at least not always. Because a 0.8 probability times two would yield a "1.6 probability", which is not a probability. And then it seems also questionable whether doubling the probability 0.01 is "morally the same" as doubling the probability 0.5. Yet e.g. in medical testing and treatment trials, ratios of probabilities are often used, e.g. the likelihood ratio for some hypothesis H and some evidence E, or the risk ratio . Which say one probability is (for example) "double" the other probability, while implicitly assuming doubling a small probability is comparable to doubling a relatively large one. Case in point: Doubling the probability of survival doesn't imply anything about the factor with which the probability of death changes, except that it is between 0 and 1.
Another thing I found interesting is that probabilities can only be added if they are "mutually exclusive". But that's actually the same as for meters and sheep. If there are two sheep on the yard and three sheep on the property, they can only be added if "sheep on the yard" and "sheep on the property" are mutually exclusive. Otherwise we would be double counting sheep. And when adding length measurements, we also have to avoid double counting (double measuring).
Moreover, two probabilities can be validly multiplied when they are "independent". Does this also have an analogy for sheep? I can't think of one, as multiplying sheep seems generally nonsensical. But multiplying meters does indeed make sense in certain cases. It yields an area if the multiplied lengths were measured in a right angle to each other. I'm not sure whether there is any further connection to probability, but both this and being independent are sometimes called "orthogonal".
Replies from: JenniferRM, notfnofn↑ comment by JenniferRM · 2024-06-25T18:26:02.364Z · LW(p) · GW(p)
Log odds, measured in something like "bits of evidence" or "decibels of evidence", is the natural thing to think of yourself as "counting". A probability of 100% would be like having infinite positive evidence for a claim and a probability of 0% is like having infinite negative evidence for a claim. Arbital has some math and Eliezer has a good old essay [LW · GW] on this.
A good general heuristic (or widely applicable hack) to "fix your numbers to even be valid numbers" when trying to get probabilities for things based on counts (like a fast and dirty spreadsheet analysis), and never having this spit out 0% or 100% due to naive division on small numbers (like seeing 3 out of 3 of something and claiming it means the probability of that thing is probably 100%), is to use "pseudo-counting" where every category that is analytically possible is treated as having been "observed once in our imaginations". This way, if you can fail or succeed, and you've seen 3 of either, and seen nothing else, you can use pseudocounts to guesstimate that whatever happened every time so far is (3+1)/(3+2) == 80% likely in the future, and whatever you've never seen is (0+1)/(3+2) == 20% likely.
Replies from: cubefox↑ comment by cubefox · 2024-06-26T23:01:45.933Z · LW(p) · GW(p)
Log odds, measured in something like "bits of evidence" or "decibels of evidence", is the natural thing to think of yourself as "counting". A probability of 100% would be like having infinite positive evidence for a claim and a probability of 0% is like having infinite negative evidence for a claim. Arbital has some math and Eliezer has a good old essay on this.
Odds (and log odds) solve some problems but they unfortunately create others.
For addition and multiplication they at least seem to make things worse. We know that we can add probabilities if they are "mutually exclusive" to get the probability of their disjunction, and we know we can multiply them if they are "independent" to get the probability of their conjunction. But when can we add two odds, or multiply two odds? (Or log odds) And what would be the interpretation of the result?
On the other hand, unlike for probabilities, the multiplication with constants does indeed seem unproblematic for odds. (Or the addition of constants for logs.) E.g. "doubling" some odds makes always sense due to them being unbounded from above, while doubling probabilities is not always possible. And when it is, it is questionable whether it has any sensible interpretation.
But the way Arbital and Eliezer handle it doesn't actually make use of this fact. They instead treat the likelihood ratio (or its logarithm) as evidence strength. But, as I said, the likelihood ratio is actually a ratio of probabilities, not of odds, in which case the interpretation as evidence strength is shaky. The likelihood ratio assumes that doubling a small probability of the evidence constitutes the same evidence strength as doubling a relatively large one, which seems not right.
As a formal example, assume the hypothesis doubles the probability of evidence compared to . That is, we have the likelihood ratio . Since , is interpreted to constitute 1 bit of evidence in favor of .
Then assume we also have some evidence that is doubled by compared to . So is interpreted to also be 1 bit of evidence in favor of .
Does this mean both cases involve equal evidence strength? Arguably no. For example, the probability of may be quite small while the probability of may be quite large. This would mean hardly decreases the probability of compared to , while strongly decreases the probability of compared to . So .
So according to the likelihood ratio theory, would be moderate (1 bit) evidence for , and would be equally moderate evidence for , but would be very weak evidence against while would be very strong evidence against .
That seems implausible. Arguably is here much stronger evidence for than .
Here is a more concrete example:
= The patient actually suffers from Diseasitis.
= The patient suffers from Diseasitis according to test 1.
= The patient suffers from Diseasitis according to test 2.
Log likelihood ratio :
Log likelihood ratio :
So this says both tests represent equally strong evidence.
What if we instead take the ratio of conditional odds, instead of the ratio of conditional probabilities (as in the likelihood ratio)?
Log odds ratio :
Log odds ratio :
So the odds ratios are actually pretty different. Unlike the likelihood ratio, the odds ratio agrees with my argument that is significantly stronger evidence than .
↑ comment by notfnofn · 2024-06-25T19:08:39.277Z · LW(p) · GW(p)
I was thinking about this a few weeks ago. The answer is your units are related to the probability measure, and care is needed. Here's the context:
Let's say I'm in the standard set-up for linear regression: I have a bunch of input vectors and for some unknown and the outputs are independent with distributions
Let denote the matrix whose th row is , assumed to be full rank. Let denote the random vector corresponding to the fitted estimate of using ordinary least squares linear regression and let denote the sum of squared residuals. It can be shown geometrically that:
(informally, the density of is that of the random variable corresponding to sampling a multivariate gaussian with mean and covariance matrix , then sampling an independent distribution and dividing by the result). A naive undergrad might misinterpret this as meaning that after observing and computing :
But of course, this can't be true in general because we did not even mention a prior. But on the other hand, this is exactly the family of conjugate priors/posteriors in Bayesian linear regression... so what possibly-improper prior makes this the posterior?
I won't spoil the whole thing for you (partly because I've accidentally spent too much time writing this comment!) but start with just and and:
- Calculate the exact posterior density of desired in terms of
- Use Bayes theorem to figure out the prior
I personally messed up several times on step 2 because I was being extremely naive about the "units" cancelling in Bayes theorem. When I finally made it all precise using measures, things actually cancelled properly and got the correct improper prior distribution on .
(If anyone wants me to finish fleshing out the idea, please let me know).
Replies from: cubefoxcomment by Steven Byrnes (steve2152) · 2024-06-26T13:15:28.466Z · LW(p) · GW(p)
If you treat units as literal multiplication (…which you totally should! I do that all the time.), then “5 watts” is implied multiplication, and the addition and subtraction rule is the distributive law, and the multiplication and division rules are commutativity-of-multiplication and canceling common factors.
…So really I think a major underlying cause of the problem is that a giant share of the general public has no intuitive grasp whatsoever on implied multiplication, or the distributive law, or commutativity-of-multiplication and canceling common factors etc. :-P
(I like your analogy to the word “only” at the end.)
comment by martinkunev · 2024-06-27T14:20:15.656Z · LW(p) · GW(p)
"force times mass = acceleration"
it's "a m = F"
Units are tricky. Here is one particular thing I was confused about for a while: https://martinkunev.wordpress.com/2023/06/18/the-units-paradox/
comment by Steven Joyce (steven-joyce) · 2024-06-25T06:39:34.710Z · LW(p) · GW(p)
"A million times a million is a billion" should be "A million times a million is a trillion"
Replies from: roger-d-1, KingSupernova↑ comment by RogerDearnaley (roger-d-1) · 2024-06-25T07:21:57.199Z · LW(p) · GW(p)
There was, at least in the UK a few decades ago, a definition were this was true, since a billion was 10^12 and a trillion was 10^24 and numbers like 'two thousand million billion' were meaningful (that's 2 * 10^39). The American definition where a billion is 10^9 and a trillion is 10^12 has long since taken over, however.
Replies from: JenniferRM, Dacyn↑ comment by JenniferRM · 2024-06-25T18:10:56.548Z · LW(p) · GW(p)
That's fascinating and I'm super curious: when precisely, in your experience as a participant in a language community did it feel like "The American definition where a billion is 10^9 and a trillion is 10^12 has long since taken over"?
((I'd heard about the British system, and I had appreciated how it makes the the "bil", "tril", "quadril", "pentil" prefixes of all the "-illion" words make much more sense as "counting how many 10^6 chunks were being multiplied together".
The American system makes it so that you're "counting how many thousands are being multiplied together", but you're starting at 1 AFTER the first thousand, so there's "3 thousands in a billion" and "4 thousands in a trillion", and so on... with a persistent off-by-one error all the way up...
Mathematically, there's a system that makes more sense and is simpler to teach in the British way, but linguistically, the American way lets you speak and write about 50k, 50M, 50B, 50T, 50Q, and finally 50P (for fifty pentillion)...
...and that linguistic frame is probably going to get more and more useful as inflation keeps inflating?
Eventually the US national debt will probably be "in the quadrillions of paper dollars" (and we'll NEED the word in regular conversation by high status people talking about the well being of the country)...
...and yet (presumably?) the debt-to-gdp ratio will never go above maybe 300% (not even in a crisis?) because such real world crises or financial gyrations will either lead to massive defaults, or renominalization (maybe go back to metal for a few decades?), or else the government will go bankrupt and not exist to carry those debts, or something "real" will happen.
Fundamentally, the ratio of debt-to-gdp is "real" in a way that the "monetary unit we use to talk about our inflationary script" is not. There are many possible futures where all countries on Earth slowly eventually end up talking about "pentillions of money units" without ever collapsing, whereas debt ratios are quite real and firm and eventually cause the pain that they imply will arrive...
One can see in teh graph below how these numbers mostly "clustering together because annual-interest-rates and debt-to-gdp-ratios are directly and meaningfully comparable and constrained by the realities of sane financial reasoning" much more clearly when you show debt ratios, over time, internationally...
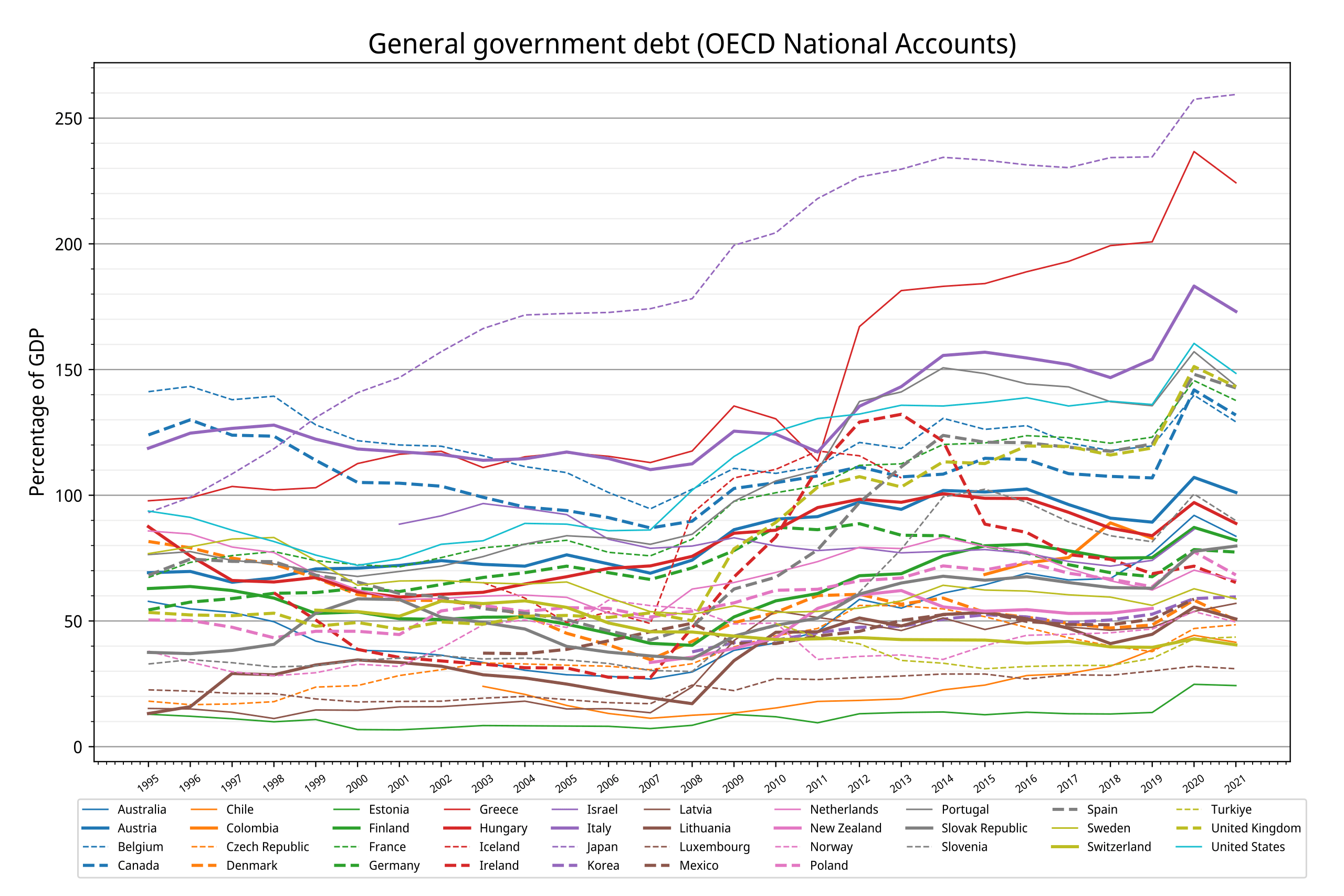
...you can see in that data that Japan, Greece, and Israel are in precarious places, just with your eyeballs in that graph with nicely real units.
Then the US, the UK, Portugal, Spain, France, Canada, and Belgium are also out into the danger zone with debt well above 100% of GDP, where we better have non-trivial population growth and low government spending for a while, or else we could default in a decade or two.
A small part of me wonders if "the financial innumeracy of the median US and UK voter" are part of the explanation for why we are in the danger zone, and not seeming to react to it in any sort of sane way, as part of the zeitgeist of the English speaking world?
For both of our governments, they "went off the happy path" (above 100%) right around 2008-2011, due to the Great Recession. So it would presumably be some RECENT change that switched us from "financial prudence before" and then "financial imprudence afterwards"?
Maybe it is something boring and obvious like birthrates and energy production?
For reference, China isn't on wikipedia's graph (maybe because most of their numbers are make believe and its hard to figure out what's going on there for real?) but it is plausible they're "off the top of the chart" at this point. Maybe Xi and/or the CCP are innumerate too? Or have similar "birthrate and energy" problems? Harder to say for them, but the indications are that, whatever the cause, their long term accounting situation is even more dire.
Looping all the way back, was it before or after the Great Recession, in your memory, that British speakers de facto changed to using "billion" to talk about 10^9 instead of 10^12?))
↑ comment by Isaac King (KingSupernova) · 2024-06-25T06:56:18.716Z · LW(p) · GW(p)
Oh whoops, thank you.
comment by Ben (ben-lang) · 2024-06-28T11:16:29.660Z · LW(p) · GW(p)
That Verizon call is terrifying. The caller made a critical mistake a couple of times though, he asked for his bill in dollars. He should have asked them to, starting blank, calculate how many cents he owed them. I think that may have potentially clarified it for them. (I still don't understand how they can continue to fail at this for some long though).
A big contributor is the fact that $ signs (or £ or whatever) go at the beginning of numbers, when every other unit goes at the end. If we were used to prices like 100$, or 0.99$ or whatever then they would have immediately seen that 0.002c was different from 0.002$. (But in their head it was $0.002c). So, the real culprit is inconsistent notation.
comment by jmh · 2024-06-26T03:20:32.947Z · LW(p) · GW(p)
Why is a million not a legitimate unit? I don't really get that as I see pretty much every financial statement using millions (or in some cases billions) as the unit of reporting amounts (with specific and clearly identified exceptions like per share data). As you say, units mean something and million means 6 zeros after whatever numbers are stated. Additional units can also be present, dollars, people or sheep.
The problem (and one I glossed over myself initially) was in the treatment of the units when dividing. They should have cancelled but they were not. If the numbers were presented as units of 1, so all the trailing zeros were considered I don't think the mistaken claim would have been made. So I do think the issue is about how we keep track of the units and how we need to treat them in different contexts.
I think Matt Parker could have illustrated the problem better by including people as a unit in his breakdown. That would have made it very clear that the end result was the 1.5x $/person and not the > 1 million $/person as claimed.