Predicting Alignment Award Winners Using ChatGPT 4
post by Shoshannah Tekofsky (DarkSym) · 2024-02-08T14:38:37.925Z · LW · GW · 2 commentsContents
Background The Experiment Data Metrics Methods Prompt Structure Results Discussion & Conclusion None 2 comments
This experiment explores the Enhancing Selection branch of the Collective Human Intelligence [LW · GW] (CHI) research agenda. The hypothesis under evaluation was:
| There are testable traits that make people better at alignment research such that we could use them for funding and training selection. |
The conclusion is “Maybe” - At least according to the data I got from prompting ChatGPT 4 to detect the winners of the Alignment Award competitions on the Goal Misgeneralization Problem and the Shutdown Problem. Initially it seemed neither structured prompt exploration nor prompts generated by ChatGPT 4 could consistently detect the winners of either competition. However, running a simple tournament prompt - comparing two research summaries and then promoting the winner to the next round where the process is repeated - did actually result in detecting the winner in 5 out of 10 runs, and putting the winner in the semi-finals in 3 out of the 5 remaining runs for the Shutdownability contest. In contrast, the same prompt had earlier failed to detect the winner on the Goal Misgeneralization contest across 10 runs.
Overall, my intuition is that we can get better results with data that more directly represents the candidates’ research prowess (e.g., using recursive summarization of a larger body of work) and using success measures that are less noisy (e.g. wide-scale adoption of a proposed alignment technique). This could be applied to pre-filter grant proposals or sift for promising new talent among applicants of training programmes like MATS or AI Safety Camp.
Background
Aka, why did you run this experiment?
Cause I’m not entirely sure how to solve the alignment problem myself, but maybe I am able to boost humanity as a whole in solving the alignment problem together. One way to provide this boost to our collective human intelligence is to find new talent more quickly and cost effectively. And one way to do that, is by checking if LLMs can do the finding for us.
Notably I’m assuming that baby geniuses look different from baby everyone else, such that failures of LLMs to predict world events (Zou et al., 2022) may not apply to failure to predict excellence in AIS research. I spent some time trying to figure out what a Da Vinci, Einstein, or Kahneman looks like before they become notable. Ideally we’d prompt ChatGPT 4 to check for those traits in a person’s early writing and with enough predictive power we could automatically flag potential geniuses in their verbal cribs[1].
So I started with trying to predict Nobel Prize winners from their dissertations. ChatGPT 4 was amazing at this! Which is less surprising once you realize that both the dissertations and every Noble Prize winner’s research track is probably in its training set. Thus, we need to find promising talent that emerged after the training data cut off of September, 2021. This is actually quite recent, and it’s hard to measure success since then cause there hasn’t been a lot of time to succeed at anything. Smaller successes might be easier to measure though: Did someone win awards, get published soon after starting, or was picked up by one of the major labs?
However, looking into these success measures ended up surprisingly fraught: Publications in AIS have too few citations per paper to create a strong signal, upvotes on LW or AF can trivially be predicted by looking at the quality of the first few paragraphs of text, and ranking people on what job they got after their initial research turned out to be a challenging data set to collect. So I looked at the question from a different angle: Do we already have data sets where aspiring AIS researchers submit early material coupled with some performance measure later on?
Actually we do: Grant programs, research incubators, and contests.
Thus, I asked LTFF for their applicants, (SERI-)MATS for their participants, and the Alignment Awards (AA) for their contestants. Each data set has an “application” and a measure of success (got funded, produced notable work, or won the contest). AA answered first by a decent margin, so I got started on that data set (see below). Later, I also received a cohort of (SERI-)MATS data, which may be suitable for a follow-up experiment.
The Experiment
“Can ChatGPT 4 recreate the AA judgements?” seems like a decent proxy for “Can ChatGPT 4 recognize early AI Safety talent?”. The answer is ‘maybe’. At least, how I tested this in the time I had. Here is an overview of the experiment.
Data
The Alignment Awards consisted of two contest: Goal Misgeneralization (GM) and the Shutdown Problem (SP). I used the GM contest as the training set and the SP contest as the test set for prompt engineering. In other words, I engineered prompts on the GM data set, and then tested the top performing prompt on the SP data set to see if it generalized.
The GM and SP contests had 52 and 63 non-duplicate submissions, respectively. A submission consisted of a 500 word research summary, an attachment, and the judges’ scores across both. There were three types of score: understanding of the problem, how much progress the proposed solution would make on the problem, and how well the authors understood the limitations of their proposed solution. These three scores were then averaged together in a final score at a 1:2:1 ratio. Scores could range from 0 to 100. Below are the distributions of the scores for each contest.
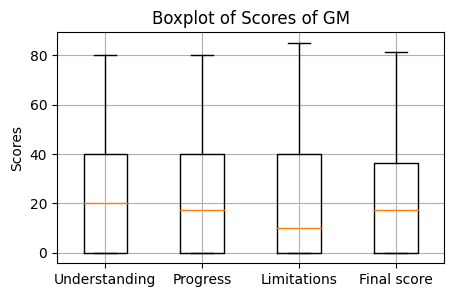
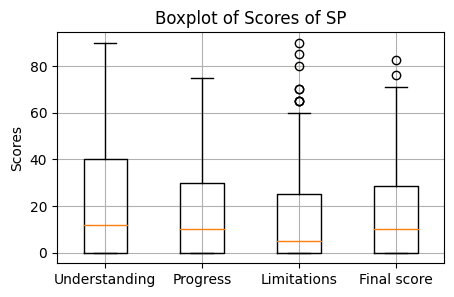
Three junior AI Safety researchers judged the first round of entrants, and then the 15 highest ranking entries across both competitions made it into the second round, which was judged by Nate Soares, John Wentworth, and Richard Ngo. Each was assigned 2/3s of the submissions, such that some combination of two judges reviewed every entry. The judges then assigned cash prizes to each entry.
Data was ranked based on round one Final Scores and total cash prizes in round two. ChatGPT 4 has a context window that does not allow all the research text to be sent. Some submission attachments were over 10 pages long. So in honor of quick iteration, the 500 word research summary was used as input for the prompts. With such more limited data, and the noise inherent in human judgements, I opted to make the experimental design the lowest complexity classification task that would still be useful: four labels that distinguish the winning entry (target), the top scoring entries (near-misses), the low scoring entries (big misses), and zero scoring entries. The last category was added cause even if ChatGPT 4 turns out to be bad at recognizing contest winners, it can still be a useful filter if it consistently can identify irrelevant entries as this would lower the work load for the judges. As such, we have the following four labels:
- Winner - Highest cumulative cash prize assigned.
- High Score - 14 next highest Total Score entries.
- Low Score - All remaining entries that scored any points at all.
- Zero Score - All entries that scored zero points.
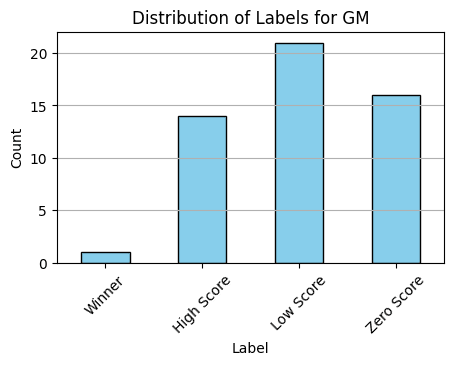
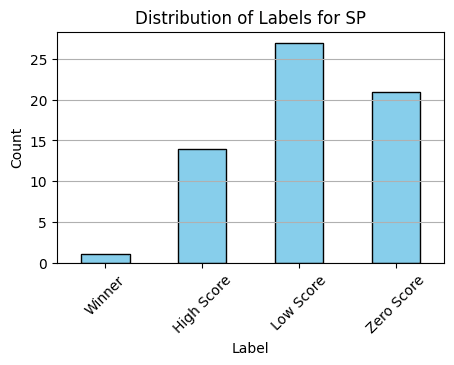
Metrics
Once we get to prompt engineering, we need a way to compare which prompts did better than others. The following three metrics were used:
Winner Precision =
Measure of how well the actual winning entry was identified. If it is 0, then the actual winner (TP) was not identified. If the value is large, then the winner was identified among a small set of false positives (FP). If the value is small, the winner was identified among a large set of FPs. Considering junior researchers identified 5-10 entries per contest for further judgment by senior judges, a similar Winner Precision ratio (0.2 - 0.1) is considered ideal to avoid overfitting.
Zero Score F-beta = with
A secondary metric is ChatGPT 4’s ability to filter out nonsensical or irrelevant entries. This would alleviate some of the review burden for judges, who’s time may be limited. To be able to entrust this filtering step to ChatGPT 4, it would have to consistently score very few False Positives, while maximizing True Positives. FPs are more costly than TPs are helpful, so this metric is a weighted precision score that penalizes FPs three times as much as it rewards TPs.
Overall F1 Score =
This is a generic measure of classification error across all four classes rewarding precision and recall equally. It’s mostly included as a sanity check.
Methods
I didn’t actually know how to prompt engineer when I began this experiment. I started off by trying to naively engineer prompts to get an intuition of base success rates. Spot checking the results showed ChatGPT 4 couldn’t tell the good from the bad unless the difference was egregious. So I found the appropriately named learnprompting.org, which despite the scammy name seems to actually be an entirely solid wiki-like resource on how to properly prompt engineer. Specifically, I incorporated Zero Shot Chain of Thought Prompting, and focused on increasing Self-Consistency and Generalizability:
- Zero Shot Chain of Thought Prompting - LLMs become better zero-shot reasoners when prompted into Chain of Thought reasoning with the phrase “Let’s think step by step.” (Kojima et al., 2022). In practice you need to apply a two step process of Reasoning Extraction followed by Answer Extraction. I set up one prompt to reason out the label and another prompt to extract the label from the reasoning. The latter step may have failed some of the time, but I checked all the labels across 3 runs (>150 labels) and found no errors. In contrast, Fine-tuning and Few Shot Prompting were not an option for this data set because there were too few data points for fine-tuning, and the context window was too small for few shot prompting at the time the experiment was run.
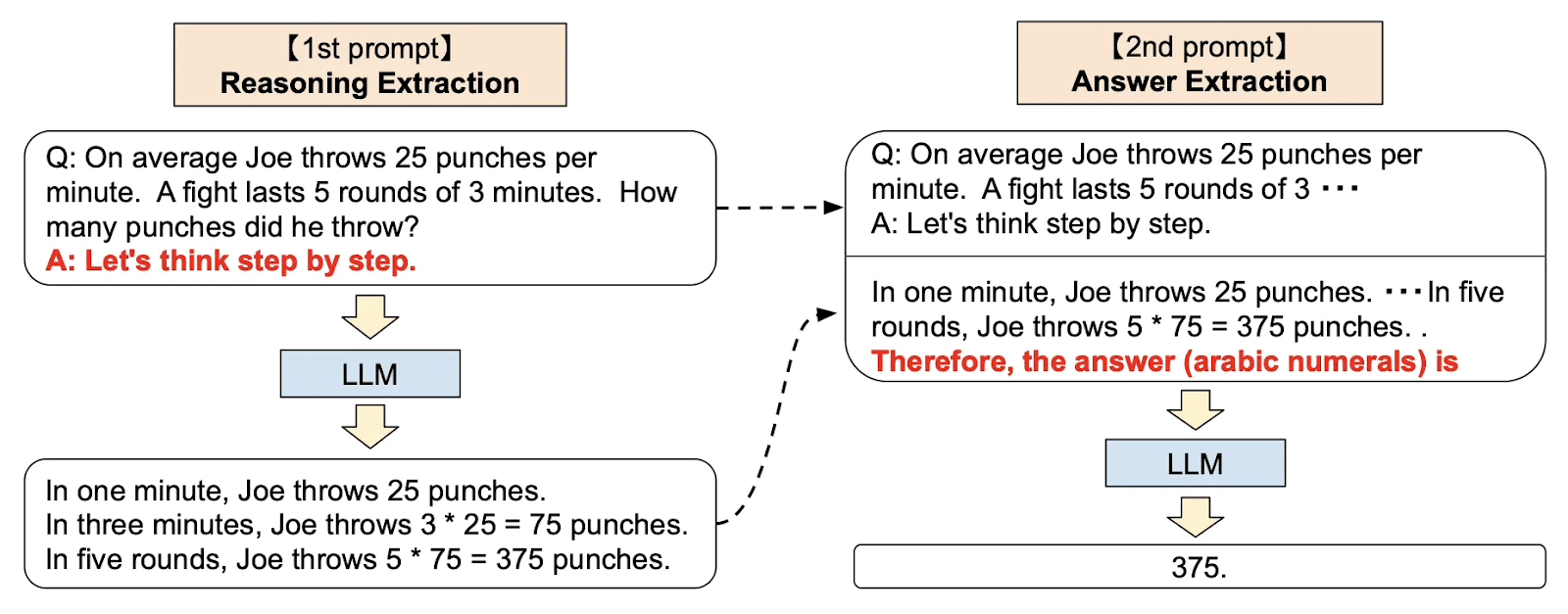
- Self-Consistency & Generalizability - In order for ChatGPT 4 to be suitable for use to profile early AIS candidates, we need to a find a prompt with high Self-Consistency and Generalizability. For this experiment, Self-Consistency was measured by repeating prompts 10 times (or in practice, till failing more than the best prompt so far). Generalizability was measured by determining the best scoring prompt on the GM data set and then testing it on the SP data set.
Prompt Structure
I started out with naive prompts to develop intuitions on baseline performance, then tried to reason out structured prompts building on the prompt engineering literature noted above, and lastly let ChatGPT 4 itself iterate across prompt generation attempts.
Structured Prompts
Structured prompts (raw source file) were handcrafted based on the prompt engineering literature above. Specifically, prompts were segmented into four major elements: role, task, reasoning, and scaffolding. Each element was then further decomposed as necessary, with the following results:
- Role: What role ChatGPT 4 is asked to play
- Task:
- Action: Description of judging
- Contest: Description of the contest
- Criteria: List of judging criteria
- Labels: Labels and their relationship to the criteria
- Nudges: Instructions like privilege FPs over FNs
- Reasoning:
- Type: Step by step (did not end up trying other types)
- Detail: How to perform that type of reasoning
- Nudges: Further instructions
- Final Label: Tell ChatGPT 4 to print the actual label
- Scaffolding: Point out the first summary shows up after this.
Each element was updated and adjusted in the hopes of hill climbing to a better output. The main issue I discovered with this approach is that it’s not clear how to update a given subpart of the prompt to improve results. Prompt engineering seems to be, at least in part, an art that relies on free association and creativity instead of structured search. Add to that that every updated prompt needs to be run a few times for Self-Consistency checks, and we end up with an inefficient and expensive process.
GPT-Generated Prompts
As a last attempt to craft a high performing prompt, ChatGPT 4 was asked to generate its own prompt for the experiment. Each prompt was iterated on by explaining the main error direction of the previous prompt to ChatGPT 4 and requesting an updated prompt. For instance, the first prompt showed Winner_Precision = 0.0, so an adjustment was requested to identify more Winners. This process was repeated till further prompting did not improve performance metrics (Log).
Tournament Prompt
The Tournament prompt was generated by adjusting the top-scoring Structured Prompt to a tournament comparison format by swapping out the Scaffolding. The Tournament prompts were run before the GPT-Generated prompts. It’s possible that tournament performance would have been higher with the GPT-Generated prompts.
Results
Results are discussed in two phases: Singular and Tournament. In singular prompts, ChatGPT 4 was asked to label each individual research summary without having any knowledge of the other research summaries. In tournament prompts, ChatGPT 4 was asked which of two research summaries was best.
Singular
Here is an overview of the prompts that were used. Self-consistency testing started with the higher performing ChatGPT 4 prompts. The top scoring one identified the winner in 7 out of 10 runs. Subsequently, the other prompts were tested to see if they could identify the winning entry at least as well, so iterations were halted as soon as 4 failures were registered. The winning entry could not be improved by lowering the temperature to 0. Rerunning the top scoring prompt on the SP data set led to a winner detection of 0 out 10. Thus ChatGPT 4 iteration led to the top performing prompt on the GM data set, but the results did not generalize to the SP data set.
Notably, there was no iteration on minimizing FPs on Zero Score detection. The Zero Score F_Beta value remained fairly stable in the ~0.4 to 0.7 range (see table below). Studying the related confusion matrices showed that 1-2 Low Score items were commonly included in the Zero Score label. Due to time limitation, prompts were optimized to detect the Winner and not the Zero Score entries. In practice, prompts that performed well on one metric, also performed reasonably well on the other metric.
| Prompt ID | Runs (#) | Winner Success (#) | Winner Precision (range) | Zero Score F_Beta (range) | Overall F1 (range) |
| Base Model Realism | 4 | 0 | 0.00 | 0.47 - 0.60 | 0.27 - 0.36 |
| Base Model Realism Classification Nudge | 4 | 0 | 0.00 | 0.47 - 0.52 | 0.29 - 0.33 |
| BMRCN_Judge | 8 | 4 | 0.00 - 0.14 | 0.46 - 0.76 | 0.32 - 0.38 |
| BMRCN_Judge_Task_Labels_Nudges | 4 | 0 | 0.00 | 0.46 - 0.65 | 0.27 - 0.43 |
| BMRCN_Task_Labels | 5 | 1 | 0.00 - 0.50 | 0.42 - 0.60 | 0.25 - 0.47 |
| BMRCN_Task_Nudges | 5 | 1 | 0.00 - 0.20 | 0.39 - 0.65 | 0.31 - 0.36 |
| GPT-4 | 4 | 0 | 0.00 | 0.60 - 0.70 | 0.28 - 0.34 |
| GPT-4_Multi_Winner | 10 | 7 | 0.00 - 0.07 | 0.59 - 0.70 | 0.23 - 0.36 |
| GPT-4_Multi_Winner_V2 | 4 | 0 | 0.00 | 0.65 - 0.70 | 0.26 - 0.34 |
| GPT-4_Multi_Winner_ZeroTemp | 6 | 2 | 0.00 - 0.07 | 0.50 - 0.70 | 0.26 - 0.30 |
| GPT-4_Multi_Winner_SP | 10 | 0 | 0.00 | 0.62 - 0.71 | 0.18 - 0.23 |
Tournament
I ran a prediction market on how likely people found it that ChatGPT 4 could identify the winner of the GM competition in any of 10 tournament runs. Voting mass was low (6) and odds remained around 50-50. Betters only had minimal information about prompt structure though, so not sure how useful these markets are. The result was “no”.
Except then I ran the same tournament on the SP data and got fantastic results: ChatGPT 4 identified the winner of the contest in 5 out of 10 runs, had the winner place among the semi-finals in 3 runs, and only flubbed it in the remaining 2 runs. Here are some numbers and graphs:
Table showing what round the winning entry made it into in a GPT-4 Tournament:
Round | |||||||
| 1 | 2 | 3 | 4 | 5 | Finale | Winner | |
| GM | 2 | 2 | 4 | 2 | 0 | 0 | 0 |
| SP | 0 | 0 | 2 | 0 | 2 | 1 | 5 |
Everyone enters round 1, and the winners of that round goes to the next etc. Despite the GM contest having 52 contestants and the SP contest 63, they both have the same number of rounds cause the number 52 is cursed. It would be interesting to see what summaries the winner lost against in each case. It may be the case that in the SP contest, the winning entry lost in round 3 to the same entries it ran in to in the semi-finals on the better runs.
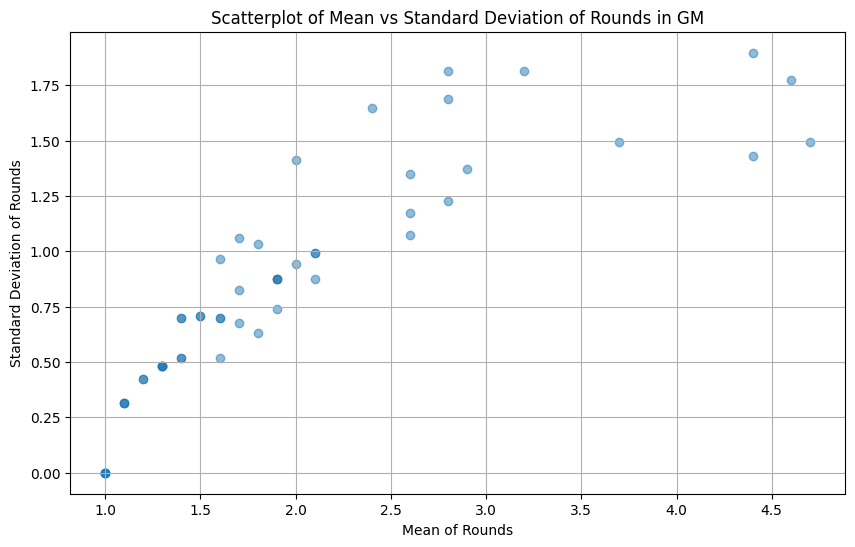
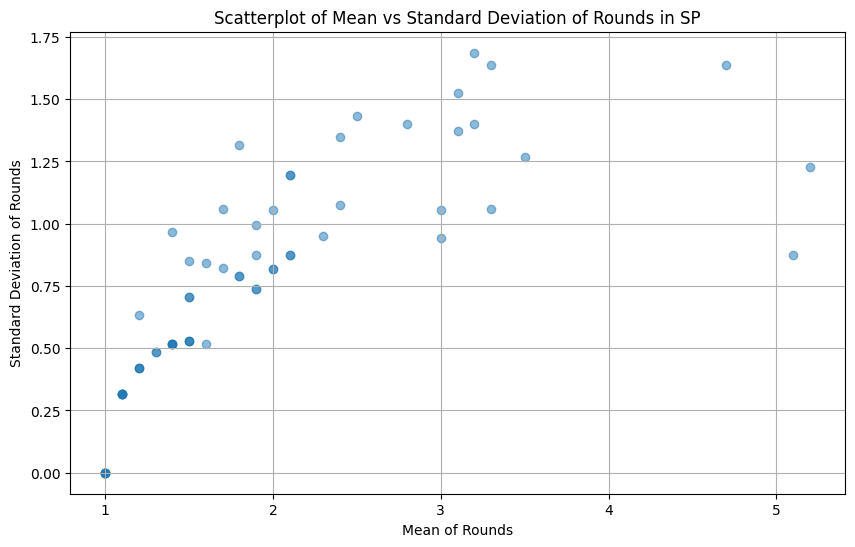
The above are density plots of standard deviations against means for each summary across all 10 runs. I think this shows that assigning a low round number is lower variance than a high one. In other words, some entries lose straight away (most) all the time. The higher an entry ranks, the more it varies how far it gets in the contest. This mostly makes sense even in the best case scenario of ChatGPT 4 doing perfect ranking: The initial matchups are randomized, and so only the very best and very worst entries can end up in exactly the same spot each time (always lose or always win). Any entry that loses to some but not all entries, will end up with a different rank depending on which other entries it is matched against throughout the tournament.
Discussion & Conclusion
Using ChatGPT 4 to profile AIS researcher based on their early research output showed mixed results. The current approach may have suffered from the noise present in judge scoring, as well as the limited input data present in the 500 word research summaries of the Alignment Award data. Results might be improved by using larger data sets with more robust success metrics, recursive task decomposition on larger input texts, least-to-most-prompting (Zhou et al., 2022), and solo performance prompting (Wang et al. 2023). It is unclear if other LLMs would perform better on the task considering ChatGPT 4 is already surprisingly good at complex reasoning tasks such as passing a medical testing questionnaire (Nori et al., 2023). Thus, with the above improvements, follow up research might be able to tell us if ChatGPT 4 is a suitable tool for profiling promising AIS researchers early in their career.
Thank you to Olivia Jimenez, Akash Wasil, Arun Jose, and people on the Cyborgism server for giving feedback and additional sparring support on the experimental design.
- ^
This approach stranded on the issue of finding suitable data sets to test my hypotheses. But before it did, I found ChatGPT 4 predicted the Nebula Award Winner for Best Short Story 2022 would be an amazing AIS researcher based on the first 330 words of their story Rabbit Test. Either we should be recruiting more top sci-fi writing talent, or there is a hole in my initial model. Who knows. To be fair, Steinhardt’s “What will GPT 2030 look like? [LW · GW]” also scored high on this model.
2 comments
Comments sorted by top scores.
comment by johnswentworth · 2024-02-08T17:04:11.082Z · LW(p) · GW(p)
Possibly relevant to your results: I was one of the people who judged the Alignment Award competition, and if I remember correctly the Shutdown winner (roughly this post [LW · GW]) was head-and-shoulders better than any other submission in any category. So it's not too surprising that GPT had a harder time predicting the Goal Misgeneralization winner; there wasn't as clear a winner in that category.
Replies from: DarkSym↑ comment by Shoshannah Tekofsky (DarkSym) · 2024-02-08T17:36:19.802Z · LW(p) · GW(p)
Oh, that does help to know, thank you!